????????
一、什么是神經網絡
人工神經網絡(Articial Neural Network,簡寫為ANN)也稱為神經網絡(NN),是一種模仿生物神經網絡和功能的計算模型,人腦可以看做是一個生物神經網絡,由眾多的神經元連接而成,各個神經元傳遞復雜的電信號,樹突接收到輸入信號,然后對信號進行處理,通過軸突輸出信號。人工神經網絡也是類似,通過模仿人腦的“學習機器”,通過不斷“看”數據(比如圖片,數字),自己總結規律,最終學會預測(比如分類圖片)
1.1、如何構建人工神經網絡中的神經元
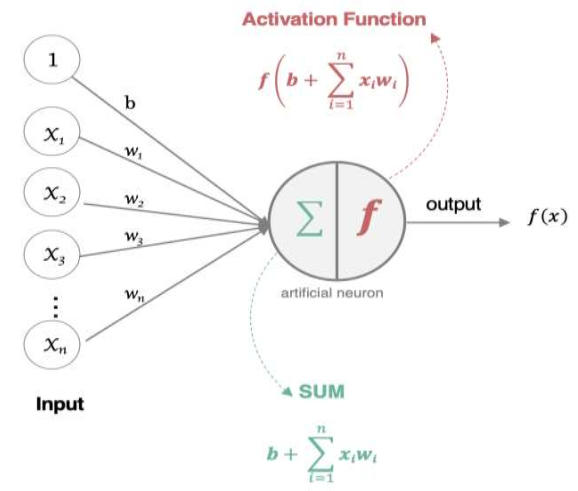
神經元=輸入X權重+偏置->激活函數
權重:調節每個輸入的重要性(類似音量旋鈕)
偏置:調整輸出的基準線(比如天生愛吃甜食)
激活函數:決定是否觸發輸出(比如及格線60分)
權重和偏置怎么來的?
一開始隨機初始化,訓練時通過數據自動調整到最優值
1.1、神經網絡
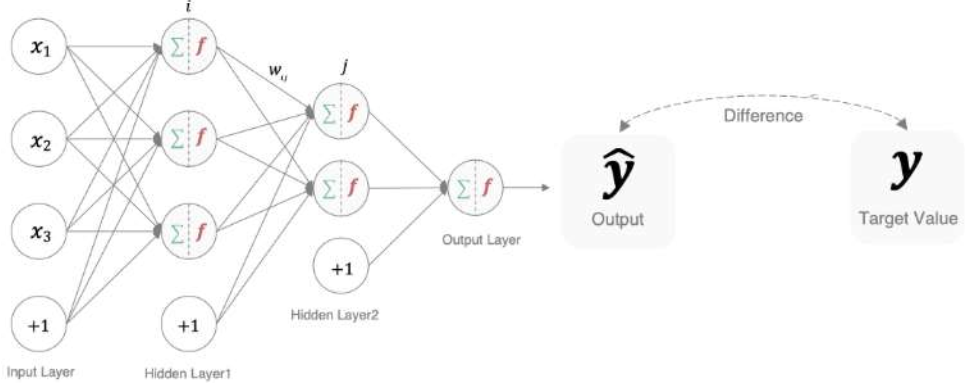
使用多個神經元來構建神經網絡,相鄰之間的神經元相互連接,并給每一個連接分配一個強度,如下圖:
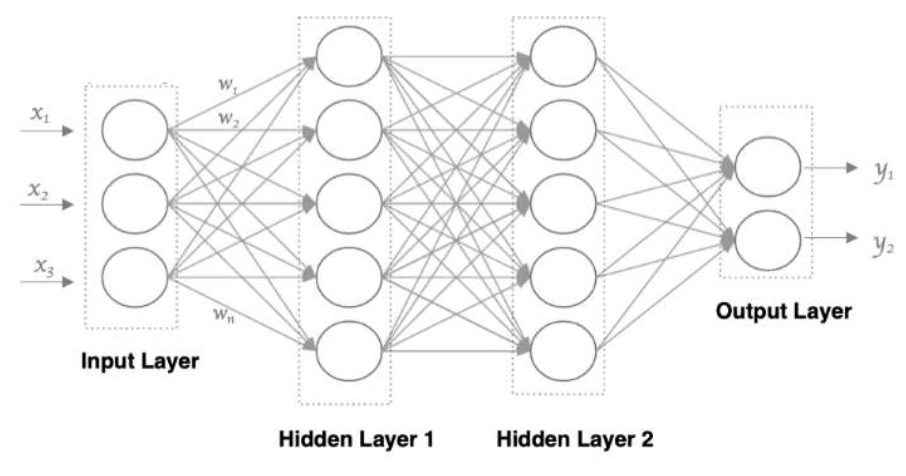
神經網絡中信息只向一個方向移動,即從輸入節點向前移動,通過隱藏節點,再向輸出節點移動,神經元的三層結構:
輸入層:
- 像眼睛一樣接受數據,比如輸入一張3個數字的表格(比如身高,體重,年齡)
- 代碼層面對應的是:my_data = torch.randn(5,3)生成一個5行3列的隨機數據(5個人,每人3個特征)
隱藏層
- 像大腦一樣處理數據,圖中有兩層“腦細胞”(Hidder Layer1和Hidden Layer2)
輸出層:
- 像“嘴巴”一樣給出答案,比如輸出兩個結果,y1,y2
1.2、神經網絡的特點:
- 同一層的神經元之間沒有連接。
- 第N層的每個神經元和第N-1層的所有神經元相連(full conneted的含義),這就是全連接神經網絡
- 第N-1層神經元的輸出就是第N層神經元的輸入
- 每個連接都有一個權重值(w系數和b系數)
深度學習與機器學習的關系
深度學習是機器學習的一個分支,深度學習用多層神經網絡(尤其是深層的網絡)來學習數據,自動從數據中提取復雜特征,不用人工設計規則。
二、激活函數
激活函數用于對每層的輸出數據進行變換,進而為整個網絡注入非線性因素,此時,神經網絡就可以擬合各種曲線,沒有引入非線性因素的網絡等價于使用一個線性模型來擬合
通過給網格輸出增加激活函數,實現引入非線性因素,使得網絡模型可以逼近任意函數,提升網絡對復雜問題的擬合能力
2.1、常見的激活函數
1、sigmoid激活函數
- 可以將任意的輸入映射到(0,1)之間,當輸入的值大致在<-6或者>6時,意味著輸入任何值得到的激活值都是差不多的,這樣會丟失部分信息
- 對于sigmoid函數而言,輸入值在[-6,6]之間輸出值才有明顯差異,輸入值在[3,-3]之間才會有比較好的效果
- sigmoid網絡在5層之內就會產生梯度消失現象,該激活函數并不是以0為中心的,在實踐中這種激活函數使用的很少,一般只用于二分類的輸出層
2、tanh激活函數
- Tanh 函數將輸入映射到 (-1, 1) 之間,圖像以 0 為中心,在 0 點對稱,當輸入 大概<-3 或者>3 時將被映射為 -1 或者 1。其導數值范圍 (0, 1),當輸入的值大概 <-3 或者 > 3 時,其導數近似 0
- 與 Sigmoid 相比,它是以 0 為中心的,且梯度相對于sigmoid大,使得其收斂速度要比Sigmoid 快,減少迭代次數。然而,從圖中可以看出,Tanh 兩側的導數也為 0,同樣會造成梯度消失
- 若使用時可在隱藏層使用tanh函數,在輸出層使用sigmoid函數
3、softMax激活函數
softMax用于多分類過程中,是二分類函數sigmoid在多分類上的推廣,目的是將多分類的結果以概率的形式展示出來,將網絡輸出的logits通過softMax函數,映射成為(0,1)的值,這些值的累加和為1,選取概率最大的節點,作為我們的預測目標類別
4、ReLU激活函數
ReLU 激活函數將小于 0 的值映射為 0,而大于 0 的值則保持不變,它更加重視正信號,而忽略負信號,這種激活函數運算更為簡單,能夠提高模型的訓練效率。
當x<0時,ReLU導數為0,而當x>0時,則不存在飽和問題。所以,ReLU 能夠在x>0時保持梯度不衰減,從而緩解梯度消失問題。然而,隨著訓練的推進,部分輸入會落入小于0區域,導致對應權重無法更新。這種現象被稱為“神經元死亡”。
ReLU是目前最常用的激活函數。與sigmoid相比,RELU的優勢是:
采用sigmoid函數,計算量大(指數運算),反向傳播求誤差梯度時,計算量相對大,而采用
Relu激活函數,整個過程的計算量節省很多。 sigmoid函數反向傳播時,很容易就會出現梯度
消失的情況,從而無法完成深層網絡的訓練。 Relu會使一部分神經元的輸出為0,這樣就造成了
網絡的稀疏性,并且減少了參數的相互依存關系,緩解了過擬合問題的發生
2.2、激活函數的選擇方法
對于隱藏層:
- 優先選擇ReLU激活函數
- 如果ReLu效果,可以嘗試選擇其他激活,如Leakly ReLu等
- 如果你使用了ReLU, 需要注意一下Dead ReLU問題, 避免出現大的梯度從而導致過多的神經元死亡。
- 少用使用sigmoid激活函數,可以嘗試使用tanh激活函數
對于輸出層:
- 二分類問題選擇sigmoid激活函數
- 多分類問題選擇softmax激活函數
- 回歸問題選擇identity激活函數
2.3、參數初始化
- 均勻分布初始化
權重參數初始化從區間均勻隨機取值。即在(-1/√d,1/√d)均勻分布中生成當前神經元的權重,其中d為每個神經元的輸入數量
- 正態分布式初始化
隨機初始化從均值為0,標準差是1的高斯分布中取樣,使用一些很小的值,對參數W進行初始化
- 全0初始化
將神經網絡中的所有權重參數初始化為0
- 全1初始化
將神經網絡中的所有權重參數初始化為1
- 固定值初始化
將神經網絡中的所有權重參數初始化為某個固定值
- kaiming初始化,也叫做HE初始化
HE 初始化分為正態分布的 HE 初始化、均勻分布的 HE 初始化
正態化的he初始化
stddev = sqrt(2 / fan_in)
均勻分布的he初始化
它從 [-limit,limit] 中的均勻分布中抽取樣本, limit是 sqrt(6 / fan_in)
fan_in輸入神經元的個數
xavier初始化,也叫做Glorot初始化
該方法也有兩種,一種是正態分布的 xavier 初始化、一種是均勻分布的 xavier 初始化
正態化的Xavier初始化
stddev = sqrt(2 / (fan_in + fan_out))
均勻分布的Xavier初始化
[-limit,limit] 中的均勻分布中抽取樣本, limit 是 sqrt(6 / (fan_in + fan_out))
fan_in是輸入神經元的個數,fan_out是輸出的神經元個數
初始化代碼:
import torch
import torch.nn.functional as F
import torch.nn as nn#1. 均勻分布隨機初始化
def test01():print(f"均勻分布隨機初始化{'='*30}均勻分布隨機初始化")linear = nn.Linear(5,3)nn.init.uniform_(linear.weight)print(linear.weight.data)# 2、固定初始化
def test02():print(f"固定初始化{'='*30}固定初始化")linear = nn.Linear(5,3)nn.init.constant_(linear.weight,5)print(linear.weight.data)#3、全0初始化
def test03():print(f"全0初始化{'='*30}全0初始化")linear = nn.Linear(5,3)nn.init.zeros_(linear.weight)print(linear.weight.data)def test04():print(f"全1初始化{'='*30}全1初始化")linear = nn.Linear(5,3)nn.init.ones_(linear.weight)print(linear.weight.data)
#適合從正態分布 N(mean,std^2) 采樣權重。
#需手動調整方差,適合淺層網絡或特定分布假設
def test05():print(f"正態分布隨機初始化{'='*30}正態分布隨機初始化")linear = nn.Linear(5,3)# mean:均值,默認0#std 標準差,默認1nn.init.normal_(linear.weight,mean=0,std=1)print(linear.weight.data)#6、kaiming 初始化
#針對ReLU族激活函數設計,根據輸入/輸出維度調整方差
#適合深層網絡(如CNN)、ReLU/Leaky ReLU激活函數
def test06():print(f"kaiming正態分布初始化{'='*30}kaiming正態分布初始化")#kaiming正態分布初始化linear = nn.Linear(5,3)nn.init.kaiming_normal_(linear.weight)print(linear.weight.data)print(f"kaiming均勻分布初始化{'='*30}kaiming均勻分布初始化")#kaiming均勻分布初始化linear = nn.Linear(5,3)#nn.init.kaiming_normal_(tensor, a=0, mode='fan_in', nonlinearity='leaky_relu')#mode:fan_in(前向傳播,默認)或 fan_out(反向傳播)#nonlinearity:激活函數類型(如 relu, leaky_relu)nn.init.kaiming_normal_(linear.weight)print(linear.weight.data)#kaiming均勻分布初始化linear = nn.Linear(5,3)nn.init.kaiming_uniform_(linear.weight)print(linear.weight.data)#7xavier初始化
#正態分布:nn.init.xavier_normal_(tensor, gain=1.0)
#均勻分布:nn.init.xavier_uniform_(tensor, gain=1.0)
#保持輸入輸出方差一致,適用于對稱激活函數(如tanh、sigmoid)
#gain:根據激活函數調整的縮放因子(如tanh的gain=5/3)
def test07():print(f"xavier正態分布初始化{'='*30}xavier正態分布初始化")#xavier正態分布初始化linear = nn.Linear(5,3)nn.init.xavier_uniform_(linear.weight)print(linear.weight.data)print(f"xavier均勻分布初始化{'='*30}xavier均勻分布初始化")liner = nn.Linear(5,3)nn.init.xavier_uniform_(linear.weight)print(linear.weight.data)if __name__ =="__main__":test01()test02()test03()test04()test05()test06()test07()輸出結果:
均勻分布隨機初始化==============================均勻分布隨機初始化
tensor([[0.6716, 0.1197, 0.7008, 0.0801, 0.8953],[0.0483, 0.4593, 0.5607, 0.2824, 0.1307],[0.5942, 0.7758, 0.1852, 0.8597, 0.5166]])
固定初始化==============================固定初始化
tensor([[5., 5., 5., 5., 5.],[5., 5., 5., 5., 5.],[5., 5., 5., 5., 5.]])
全0初始化==============================全0初始化
tensor([[0., 0., 0., 0., 0.],[0., 0., 0., 0., 0.],[0., 0., 0., 0., 0.]])
全1初始化==============================全1初始化
tensor([[1., 1., 1., 1., 1.],[1., 1., 1., 1., 1.],[1., 1., 1., 1., 1.]])
正態分布隨機初始化==============================正態分布隨機初始化
tensor([[-1.0910, -0.4724, -0.6468, -0.0121, -1.1449],[ 0.6663, -0.1809, 1.1174, 0.9543, -0.2671],[ 0.5979, 1.5574, 0.4182, -0.0591, 0.4090]])
kaiming正態分布初始化==============================kaiming正態分布初始化
tensor([[-0.5628, 0.2732, 0.3467, -0.7840, 0.7371],[ 0.0155, 0.6244, 0.1153, 0.1079, 0.4050],[-1.2527, -0.0167, -0.2999, -0.4666, -1.9518]])
kaiming均勻分布初始化==============================kaiming均勻分布初始化
tensor([[ 1.0959, -0.3050, -0.1851, 0.5269, -0.3553],[ 0.1472, -0.4767, 0.0920, -0.2831, -0.0370],[ 0.0023, -0.5695, -0.3103, -0.5530, 1.0353]])
tensor([[-0.4601, -0.1885, 0.3863, -0.9680, -0.8768],[-0.5476, -0.5110, 0.0127, -0.3590, -0.1244],[ 0.0694, -0.5519, -1.0414, 0.5382, -0.5391]])
xavier正態分布初始化==============================xavier正態分布初始化
tensor([[ 0.3084, -0.4327, 0.0733, -0.5733, -0.5567],[ 0.4315, -0.6243, 0.4632, 0.4075, 0.2278],[-0.6804, -0.6680, 0.6128, 0.6658, -0.4149]])
xavier均勻分布初始化==============================xavier均勻分布初始化
tensor([[-0.5401, -0.1223, -0.7067, 0.7691, -0.3456],[-0.4341, 0.1888, 0.0948, 0.5501, 0.4527],[ 0.4234, -0.3090, -0.6213, -0.7041, -0.5588]])三、神經網絡搭建和參數計算
在pytorch中定義深度神經網絡其實就是層堆疊的過程,繼承自nn.Module,實現兩個方法
- __init__方法中定義網絡中的層結構,主要是全連接層,并進行初始化
- forward方法,在實例化模型的時候,底層會自動調用該函數。該函數中可以定義學習率,為初始化定義的layer傳入數據等
3.1、神經網絡模型
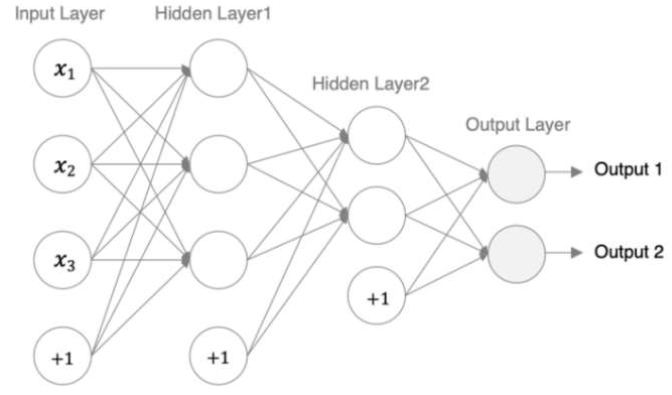
編碼設計:
- 第1個隱藏層:權重初始化采用標準化的xavier初始化 激活函數使用sigmoid
- 第2個隱藏層:權重初始化采用標準化的He初始化,激活函數采用relu
- out輸出層線性層,假若二分類,采用softmax做數據歸一化
import torch # 導入PyTorch主庫
import torch.nn as nn # 導入神經網絡模塊
from torchsummary import summary # 導入模型匯總工具,用于顯示模型結構# 創建神經網絡模型類
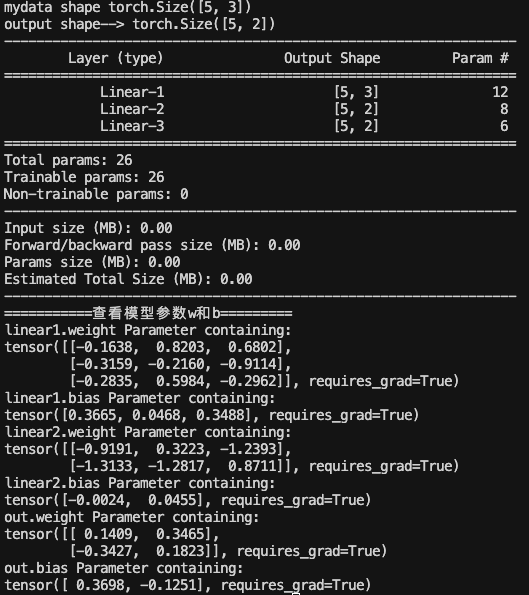
class Model(nn.Module):# 初始化屬性值def __init__(self):super(Model, self).__init__() # 調用父類(nn.Module)的初始化方法self.linear1 = nn.Linear(3, 3) # 創建第一個隱藏層,3個輸入特征,3個輸出特征nn.init.xavier_normal_(self.linear1.weight) # 使用Xavier正態分布初始化權重# 創建第二個隱藏層,3個輸入特征(上一層的輸出特征),2個輸出特征self.linear2 = nn.Linear(3, 2)nn.init.kaiming_normal_(self.linear2.weight) # 使用Kaiming(He)正態分布初始化權重# 創建輸出層,2個輸入特征,2個輸出特征self.out = nn.Linear(2, 2)# 注意:輸出層沒有特別初始化權重,使用了PyTorch默認初始化方法# 定義前向傳播方法,PyTorch會自動調用forward()方法def forward(self, x):x = self.linear1(x) # 輸入數據經過第一個線性層x = torch.sigmoid(x) # 第一層激活函數為sigmoidx = self.linear2(x) # 數據經過第二個線性層x = torch.relu(x) # 第二層激活函數為ReLUx = self.out(x) # 數據經過輸出層x = torch.softmax(x, dim=-1) # 輸出層使用softmax激活函數,在最后一個維度上計算return xif __name__ == "__main__":my_model = Model() # 實例化模型my_data = torch.randn(5, 3) # 創建隨機輸入數據,5個樣本,每個樣本3個特征print("mydata shape", my_data.shape) # 打印輸入數據形狀# 數據經過神經網絡模型前向傳播output = my_model(my_data)print("output shape-->", output.shape) # 打印輸出數據形狀# 使用summary計算每層神經元的權重和偏置總數summary(my_model, input_size=(3,), batch_size=5)# 打印模型參數print("===========查看模型參數w和b=========")for name, parameter in my_model.named_parameters():print(name, parameter) # 打印每一層的權重和偏置參數輸出結果:
3.2、神經網絡的優缺點
優點
- 精度高,性能優于其他的機器學習算法,甚至在某些領域超過了人類
- 可以近似任意的非線性函數隨之計算機硬件的發展
- 近年來在學界和業界受到了熱捧,有大量的框架和庫可供調
缺點
- 黑箱,很難解釋模型是怎么工作的
- 訓練時間長,需要大量的計算資源
- 網絡結構復雜,需要調整超參數
- 部分數據集上表現不佳,容易發生過擬合
四、損失函數
4.1、什么是損失函數
在深度學習中,損失函數是用來衡量模型參數的質量的函數,衡量的方式是比較網絡輸出和真實輸出的差異
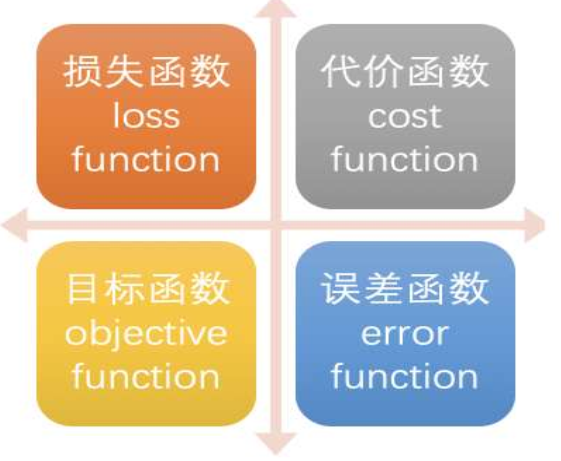
損失函數的不同命名方式
4.2、多分類損失函數
4.2.1、什么是多分類損失函數
專門用于處理多類別問題的損失函數,在這類問題中,模型需要從3個或更多個類別中預測出正確的類別,比如:
- 識別手寫數字(0-9共10個類別)
- 圖像分類(貓、狗、鳥、馬等多個類別)
- 新聞文章分類(體育、政治、科技、娛樂等)
- 語言識別(英語、中文、法語等)
4.2.2、多分類損失函數的計算方法
1、分類交叉熵損失(Catagorical Cross-Entropy)
這是最常用的多分類損失函數,計算步驟:
- 模型輸出每個類別的得分或概率(通常經過softmax函數處理)
- 將真實標簽轉換為"獨熱編碼"(one-hot encoding)形式
- 計算預測概率和真實標簽之間的交叉熵
計算公式:L = -Σ(y_true * log(y_pred))
- y_true是真實標簽的獨熱編碼(只有正確類別為1,其他為0)
- y_pred是模型預測的各類別概率
- log是自然對數
- Σ表示對所有類別求和
符號“-”符號的作用是將結果變成負值,因為對數函數對于小于1的概率值會返回負數,通過符號可以將最終結果變為整數
- 如果模型對正確類別給出高概率(接近1),損失會很小
- 如果模型對正確類別給出低概率(接近0),損失會很大
- 模型被鼓勵對正確類別"充滿信心"
4.2.3、二分類任務損失函數
在處理二分類任務時,我們不再使用softmax激活函數,而是使用sigmoid激活函數,那損失函數也相應的進行調整,使用二分類的交叉熵損失函數
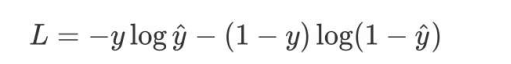
其中:
1. y是樣本x屬于某一個類別的真實概率
2. 而y^是樣本屬于某一類別的預測概率
3. L用來衡量真實值y與預測值y^之間差異性的損失結果
4.2.4、回歸任務損失函數-MAE損失函數
Mean absolute loss(MAE)也被稱為L1 Loss,是以絕對誤差作為距離。損失函數公式:
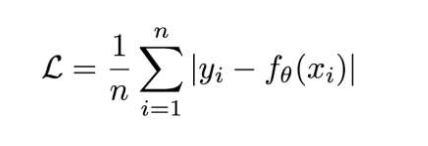
特點:
- 由于L1 loss具有稀疏性,為了懲罰較大的值,因此常常將其作為正則項添加到其他loss中作為約束
- L1 loss的最大問題是梯度在零點不平滑,導致會跳過極小值
4.2.4、回歸任務損失函數-MSE損失函數
Mean Squared Loss/Quadratic Loss(MSE loss)被稱為L2 loss,或歐式距離,以誤差的平方和的均值作為距離損失函數:
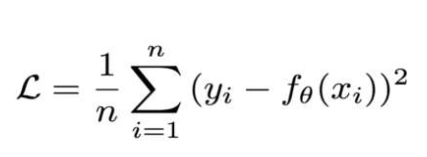
特點:
L2 loss也常常作為正則項。
當預測值與目標值相差很大時, 梯度容易爆炸
4.2.5、回歸任務損失函數-smooth L1損失函數
smooth L1說的是光滑之后的L1,損失函數公式
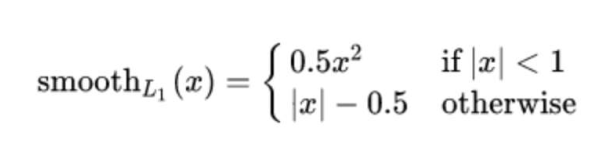
其中:𝑥=f(x)?y 為真實值和預測值的差值。
從下圖中可以看出,該函數實際上就是一個分段函數
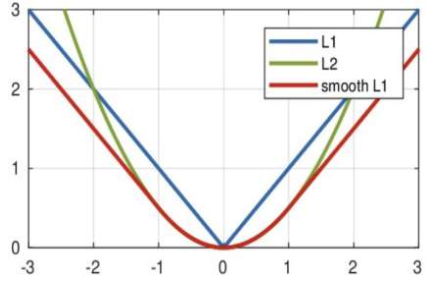
1. 在[-1,1]之間實際上就是L2損失,這樣解決了L1的不光滑問題
2. 在[-1,1]區間外,實際上就是L1損失,這樣就解決了離群點梯度爆炸的問題
損失函數代碼實現:
import torch
from torch import nn
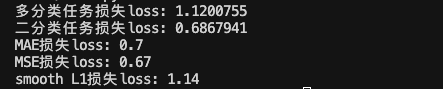
def test1():# 1 設置真實值y_true = torch.tensor([1,2],dtype=torch.int64)#設置預測值,sigmoid輸出的結果y_pred = torch.tensor([[0.2,0.6,0.2],[0.1,0.8,0.1]],dtype=torch.float32)#實例化交叉熵損失loss = nn.CrossEntropyLoss()#計算損失結果my_loss = loss(y_pred,y_true).numpy()print('多分類任務損失loss:',my_loss)
#二分任務
def test2():y_pred = torch.tensor([0.6901, 0.5459, 0.2469],requires_grad=True)y_true = torch.tensor([0,1,0],dtype=torch.float32)# 實例化二分類交叉熵損失criterion = nn.BCELoss()#計算損失my_loss = criterion(y_pred,y_true).detach().numpy()print('二分類任務損失loss:',my_loss)
# 計算算inputs與target之差的絕對值
def test3():#設置真實值和預測值y_pred= torch.tensor([1.0,1.0,1.9],requires_grad=True)y_true = torch.tensor([2.0,2.0,2.0],dtype=torch.float32)#實例MAE損失對象loss = nn.L1Loss()#計算損失my_loss = loss(y_pred,y_true).detach().numpy()print("MAE損失loss:",my_loss)def test4():#設置真實值和預測值y_pred= torch.tensor([1.0,1.0,1.9],requires_grad=True)y_true = torch.tensor([2.0,2.0,2.0],dtype=torch.float32)#實例MSE損失對象loss = nn.MSELoss()#計算損失my_loss = loss(y_pred,y_true).detach().numpy()print('MSE損失loss:',my_loss)def test5():#設置真實值和預測值y_pred= torch.tensor([0.6,0.4],requires_grad=True)y_true = torch.tensor([0,3])#實例MAE損失對象loss = nn.SmoothL1Loss()#計算損失my_loss = loss(y_pred,y_true).detach().numpy()print('smooth L1損失loss:',my_loss)if __name__ == '__main__':test1()test2()test3()test4()test5()
輸出結果:
五、網絡優化方法
5.1、梯度下降算法
梯度下降發事一種尋找損失函數最小化的方法,從數據上的角度來看,梯度的方向就是函數增長速度最快的方向,梯度的反方向就是梯度減少最快的方向
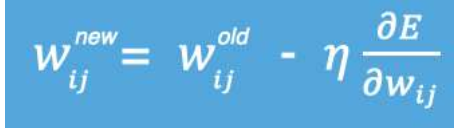
η是學習率,r如果學習率太小,每次訓練之后得到的效果都太小,增大訓練的事件成本,如果學習率太大,就有可能直接跳過最優解,進入無限訓練中,解決方法就是學習率也需要隨著訓練的進行而變化
基礎概念:
- Epoch: 使用全部數據對模型進行以此完整訓練,訓練輪次
- Batch_size: 使用訓練集中的小部分樣本對模型權重進行以此反向傳播的參數更新,每次訓練每批次樣本數量
- Iteration: 使用一個 Batch 數據對模型進行一次參數更新的過程
在深度學習中,梯度下降的幾種方式的區別是Batch Size不同
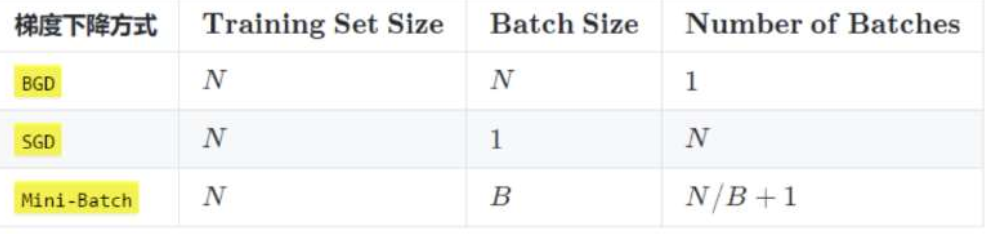
注:上表中 Mini-Batch 的 Batch 個數為 N / B + 1 是針對未整除的情況。整除則是 N / B
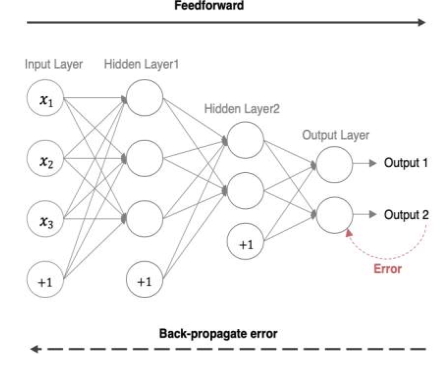
5.2、反向傳播(BP算法)
前向傳播:指的是數據輸入的神經網絡中,逐層向前傳輸,一直運算到輸出層為止
反向傳播(Back Propagation): 利用損失函數ERROR,從后往前,結合梯度下降算法,依次求各個參數偏導,并進行參數更新
import torch
from torch import nn
from torch import optim#創建神經網絡類
class Model(nn.Module):#初始化參數def __init__(self):#調用父類方法super(Model,self).__init__()#創建網絡層self.linear1 = nn.Linear(2,2)self.linear2 = nn.Linear(2,2)#初始化神經網絡參數self.linear1.weight.data = torch.tensor([[0.15,0.20],[0.25,0.30]])self.linear2.weight.data = torch.tensor([[0.40,0.45],[0.50,0.55]])self.linear1.bias.data = torch.tensor([0.35,0.35])self.linear2.bias.data = torch.tensor([0.60,0.60])#前向傳播方法def forward(self,x):#數據經過第一層隱藏層x = self.linear1(x)# 計算第一層激活值x = torch.sigmoid(x)# 數據經過第二層隱藏層x = self.linear2(x)#計算按第二層激活值x = torch.sigmoid(x)return x
if __name__ == '__main__':#定義網絡輸入值和目標值inputs = torch.tensor([[0.05,0.10]])target = torch.tensor([[0.01,0.99]])#實例化神經網絡對接model = Model()output = model(inputs)print("output-->",output)#計算誤差loss = torch.sum((output-target)**2)/2print("loss->",loss)#優化方法和反向傳播算法optimizer = optim.SGD(model.parameters(),lr=0.5)optimizer.zero_grad()loss.backward()print("w1,w2,w4->",model.linear1.weight.grad.data)print("w1,w6,w7,w8",model.linear2.weight.grad.data)optimizer.step()#打印神經網絡參數print(model.state_dict())輸出結果:

梯度下降優化算法,會遇到的情況:
- 碰到平緩區域,梯度值較小,參數優化變慢
- 碰到 “鞍點” ,梯度為 0,參數無法優化
- 碰到局部最小值,參數不是最優
5.3、梯度下降的優化方法
5.3.1、指數加權平均
指數移動加權平均則是參考各數值,并且各數值的權重都不同,距離越遠的數字對平均數計算的貢獻就越小(權重較小),距離越近則對平均數的計算貢獻就越大(權重越大)
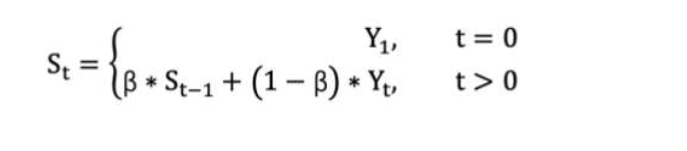
? St 表示指數加權平均值;
? Yt 表示 t 時刻的值;
? β 調節權重系數,該值越大平均數越平緩
隨機產生30天的平均氣溫數據:
1、實際平均溫度
import torch
import matplotlib.pyplot as plt
Element_NUMBER = 30
#指數加權平均
#1 實際平均溫度
def test01():#固定隨機數種子torch.manual_seed(0)#產生30天的隨機溫度temperature = torch.randn(size=[Element_NUMBER,])*10print(temperature)#繪制平均溫度days = torch.arange(1,Element_NUMBER+1,1)plt.plot(days,temperature,color='r')plt.scatter(days,temperature)plt.show()輸出結果:
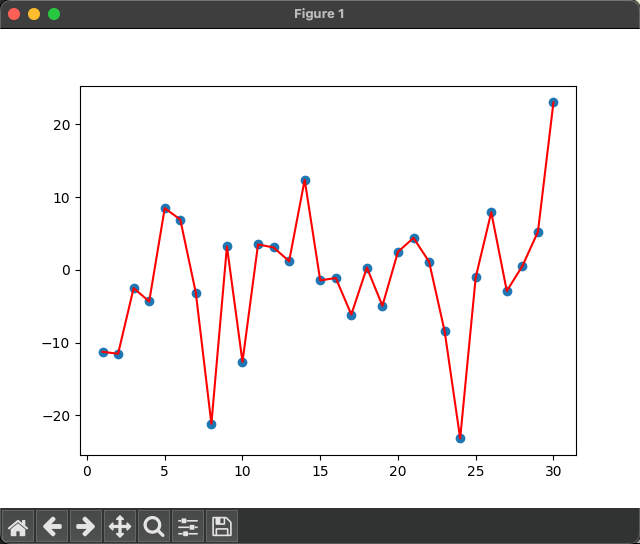
指數加權平均溫度
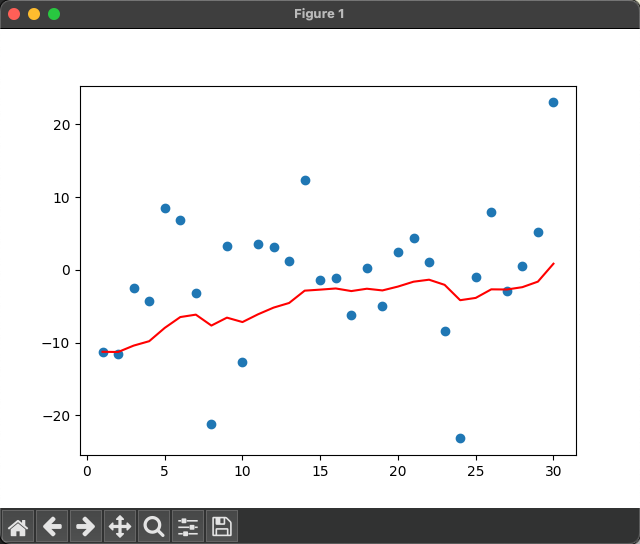
def test02(beta=0.9):torch.manual_seed(0) #固定隨機數種子temperature = torch.randn(size=[Element_NUMBER,])*10 #產生30天的隨機溫度exp_weight_avg = []for idx,temp in enumerate(temperature,1):#第一個元素的EWA值等于自身if idx == 1:exp_weight_avg.append(temp)continue#第二各元素的EWA值等于等于上一個EWA乘以new_temp = exp_weight_avg[idx-2]*beta+(1-beta)*tempexp_weight_avg.append(new_temp)days = torch.arange(1,Element_NUMBER+1,1)plt.plot(days,exp_weight_avg,color='r')plt.scatter(days,temperature)plt.show()β為0.9輸出結果
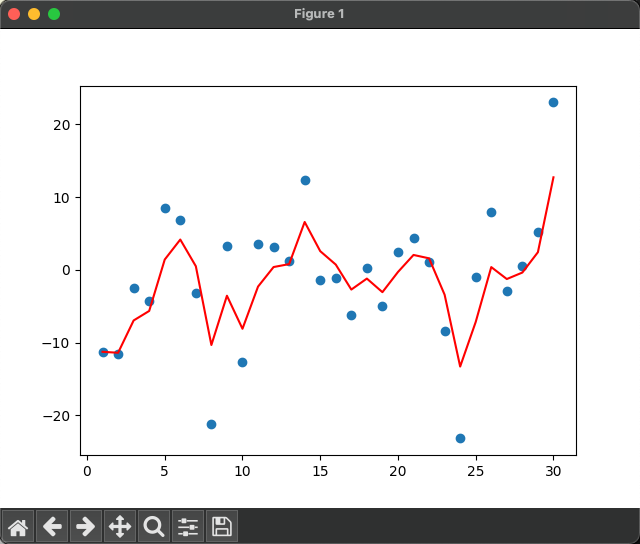
β為0.5的結果:
由結果可知
指數加權平均繪制出的氣溫變化曲線更加平緩
β的值越大,則繪制出的折線越加平緩,波動越小
5.3.2、梯度下降的優化方法-動量算法Momentum
梯度計算公式:Dt = β * St-1 + (1- β) * Wt.
- St-1 表示歷史梯度移動加權平均值
- Wt 表示當前時刻的梯度值
- Dt 為當前時刻的指數加權平均梯度值
- β 為權重系數
假設:權重 β 為 0.9,例如:
第一次梯度值:s1 = d1 = w1
第二次梯度值:d2=s2 = 0.9 * s1 + w2 * 0.1
第三次梯度值:d3=s3 = 0.9 * s2 + w3 * 0.1
第四次梯度值:d4=s4 = 0.9 * s3 + w4 * 0.1
梯度下降公式中梯度的計算,不再是當前時刻的t的梯度值,而是歷史梯度值的指數移動加權平均值
W_t+1 = W_t - a * Dt
5.4、學習率衰減
5.4.1、等間隔學習率衰減
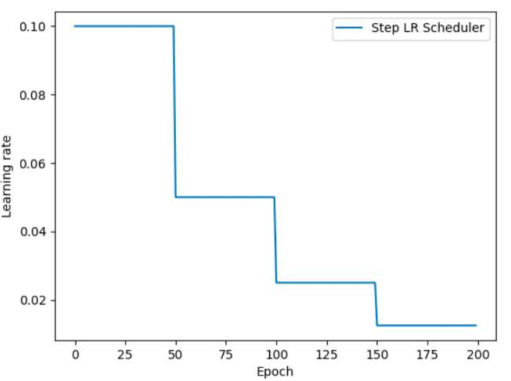

5.4.2、等間隔學習衰減率
import torch
import matplotlib.pyplot as plt
from torch import optimdef test_StepLR():#0參數初始化,設置學習率初始化值LR = 0.1iteration = 10max_epoch = 200#1. 初始化參數y_true = torch.tensor([0])x = torch.tensor([1.0])w = torch.tensor([1.0],requires_grad=True)#優化器optimizer = optim.SGD([w],lr=LR,momentum=0.9)#設置學習率下降策略scheduler_lr = optim.lr_scheduler.StepLR(optimizer,step_size=50,gamma=0.5)#獲取學習率的值和當前的epochlr_list,epoch_list = list(),list()for epoch in range(max_epoch):lr_list.append(scheduler_lr.get_last_lr())#獲取當前lrepoch_list.append(epoch)#獲取當前的epochfor i in range(iteration):loss = ((w*x-y_true)**2)/2.0 #目標函數optimizer.zero_grad()#反向傳播loss.backward()optimizer.step()#更新下一個epoch的學習率scheduler_lr.step()#繪制學習率變化的曲線plt.plot(epoch_list,lr_list,label="Step LR Scheduler")plt.xlabel("Epoch")plt.ylabel("Learning rate")plt.legend()plt.show()if __name__ == '__main__':test_StepLR()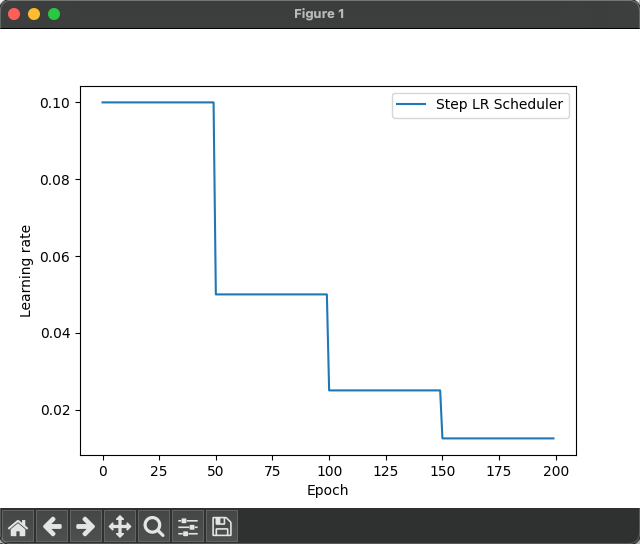
5.4.2、指定間隔學習衰減率

def test_multiStepLr():torch.manual_seed(1)LR = 0.1iteration = 10max_epoch = 200weights = torch.randn((1),requires_grad=True)target = torch.zeros((1))print ('weights-->',weights,'targee-->',target)optimizer = optim.SGD([weights],lr=LR,momentum=0.9)#設定調整時刻數milestones = [50,125,160]#設置學習率下降策略scheduler_lr =optim.lr_scheduler.MultiStepLR(optimizer,milestones=milestones,gamma=0.5)lr_list,epoch_list=list(),list()for epoch in range(max_epoch):lr_list.append(scheduler_lr.get_last_lr())epoch_list.append(epoch)for i in range(iteration):loss = torch.pow(weights-target,2)optimizer.zero_grad()#反向傳播loss.backward()#參數更新optimizer.step()#更新下一個epoch學習率scheduler_lr.step()plt.plot(epoch_list, lr_list, label="Multi Step LR Scheduler\nmilestones:{}".format(milestones))plt.xlabel("Epoch")plt.ylabel("Learning rate")plt.legend()plt.show()輸出結果:
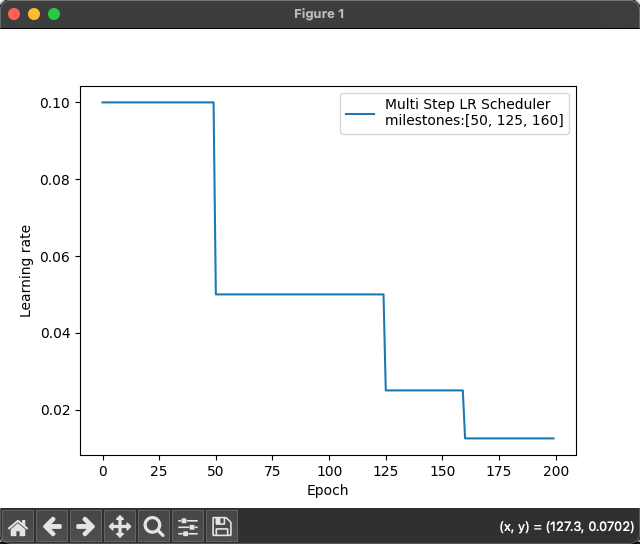
六、正則化
在設計機器學習算法時希望在新樣本上的泛化能力強。許多機器學習算法都采用相關的策略來減小測試誤差,這些策略被統稱為正則化
目前在深度學習中使用較多的策略有范數懲罰,DropOut,特殊網絡層優化等
6.1、Dropout正則化
在訓練過程中,Droupout的實現是讓神經元以超參數p的概率停止工作或者激活被置為0的進行縮放,縮放比例為1/(1-p)
import torch
import torch.nn as nndef test():#初始化隨機失活層droput = nn.Dropout(p=0.4)#初始化輸入數據:表示某一層的weight信息inputs = torch.randint(0,10,size=[1,4]).float()layer = nn.Linear(4,5)y = layer(inputs)print("未失活FC層的輸出結果:\n",y)y = droput(y)print("失活后FC層的輸出結果:\n",y)if __name__=='__main__':test()輸出結果:

6.2、批量歸一化(BN層)
先對數據標準化,再對數據重構(縮放+平移),批量歸一化層在計算機視覺領域使用較多
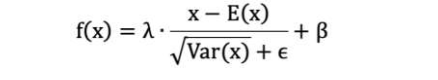
1. λ 和 β 是可學習的參數,它相當于對標準化后的值做了一個線性變換,λ 為系數,β 為偏置;
2. eps 通常指為 1e-5,避免分母為 0;
3. E(x) 表示變量的均值;
4. Var(x) 表示變量的方差;
七、案例-價格分類案例
7.1、需求分析
小明創辦了一家手機公司,他不知道如何估算手機產品的價格。為了解決這個問題,他收集了多家公司的手機銷售數據
。該數據為二手手機的各個性能的數據,最后根據這些性能得到4個價格區間,作為這些二手手機售出的價格區間。主要包括:

7.2、需求分析
我們需要幫助小明找出手機的功能(例如:RAM等)與其售價之間的某種關系。我們可以使用機器學習的方法來解決這個問題,也可以構建一個全連接的網絡。
需要注意的是: 在這個問題中,我們不需要預測實際價格,而是一個價格范圍,它的范圍使用 0、1、2、3 來表示,所以該問題也是一個分類問題。接下來我們還是按照四個步驟來完成這個任務:
? 準備訓練集數據
? 構建要使用的模型
? 模型訓練
? 模型預測評估
7.3、構建數據集
數據共有 2000 條, 其中 1600 條數據作為訓練集, 400 條數據用作測試集。 我們使用 sklearn 的數據集劃分工作來完成。并使用 PyTorch 的 TensorDataset 來將數據集構建為 Dataset 對象,方便構造數據集加載對象。
def create_dataset():#使用pandas讀取數據data = pd.read_csv('/Volumes/My Passport/學習資料/黑馬大模型第三期/3期AI大模型配套資料/01階段:配套資料/03/03-代碼/02-神經網絡/dataset/手機價格預測.csv',encoding="utf-8")#特征值和目標值x,y = data.iloc[:,:-1],data.iloc[:,-1]#類型轉換,特征值,目標值x = x.astype(np.float32)y = y.astype(np.int64)#數據集劃分x_train,x_valid,y_train,y_valid = train_test_split(x,y,train_size=0.8,random_state=88)# 構建數據集,轉換pytorch的形式train_dataset = TensorDataset(torch.from_numpy(x_train.values),torch.tensor(y_train.values))valid_dataset = TensorDataset(torch.from_numpy(x_valid.values),torch.tensor(y_valid.values))#返回結果return train_dataset,valid_dataset,x_train.shape[1],len(np.unique(y))
獲取數據結果:
#獲取數據train_dataset,valid_dataset,input_dim,class_num = create_dataset()print("輸入特征數:",input_dim)print("分類個數:",class_num)
7.4、構建分類網絡模型
由三個線性層來構建,使用relu激活函數:
1.第一層: 輸入為維度為 20, 輸出維度為: 128
2.第二層: 輸入為維度為 128, 輸出維度為: 256
3.第三層: 輸入為維度為 256, 輸出維度為: 4
#構建網絡模型
class PhonePriceModel(nn.Module):def __init__(self,input_dim,output_dim):super(PhonePriceModel,self).__init__()#第一層,輸入維度:20,輸出維度128self.linear1 = nn.Linear(input_dim,128)#第二層:輸入維度128,輸出維度:256self.linear2 = nn.Linear(128,256)#第三層:輸入維度256,輸出維度4self.linear3 = nn.Linear(256,output_dim)def forward(self,x):#前向傳播過程x = torch.relu(self.linear1(x))x = torch.relu(self.linear2(x))output = self.linear3(x)return output模型實例化
#模型實例化model = PhonePriceModel(input_dim,class_num)summary(model,input_size=(input_dim,),batch_size=16)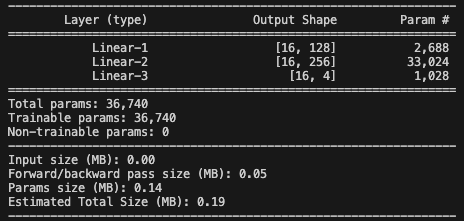
7.5、模型訓練
指的是輸入數據讀取,送入網絡,計算損失,更新參數的流程,該流程較為固定,使用的是多分類交叉生損失函數,使用SGD優化方法,最終將訓練好的模型持久化到磁盤中
#模型訓練
def train(train_dataset,input_dim,class_num,):#固定隨機種子torch.manual_seed(0)#初始化模型model = PhonePriceModel(input_dim,class_num)#損失函數criterion = nn.CrossEntropyLoss()#優化方法optimizer = optim.SGD(model.parameters(),lr=1e-3)#訓練輪數num_epoch = 50#遍歷每個輪次的數據for epoch_idx in range(num_epoch):#初始化數據加載器dataloader = DataLoader(train_dataset,shuffle=True,batch_size=8)#訓練時間start = time.time()#計算損失total_loss = 0.0total_num = 1for x,y in dataloader:#將數據送入網絡中進行預測output = model(x)#計算損失loss = criterion(output,y)#梯度歸零optimizer.zero_grad()#反向傳播loss.backward()#參數更新optimizer.step()#損失計算total_num += 1total_loss += loss.item()#打印損失變換結果print('epoch: %4s loss: %.2f,time: %.2fs' % (epoch_idx+1,total_loss/total_loss/total_num,time.time()-start))torch.save(model.state_dict(),'/Users/zsz/workspace-py/pyTorch/model/phone.pth')訓練結果如下:
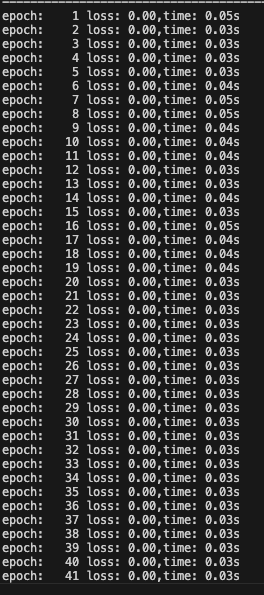
7.6、編寫評估函數
使用訓練好的模型,對未知的樣本進行預測的過程
def test(valid_dataset,input_dim,class_num):#加載model = PhonePriceModel(input_dim,class_num)model.load_state_dict(torch.load('/Users/zsz/workspace-py/pyTorch/model/phone.pth'))#構建加速器dataloader = DataLoader(valid_dataset,batch_size=8,shuffle=False)#評估測試集correct = 0for x,y in dataloader:#將其送入網絡中output = model(x)#獲取類別結果y_pred = torch.argmax(output,dim=1)#獲取預測正確的個數correct += (y_pred == y).sum()#求預測正確的個數print('Acc: %.5f' % (correct.item()/len(valid_dataset)))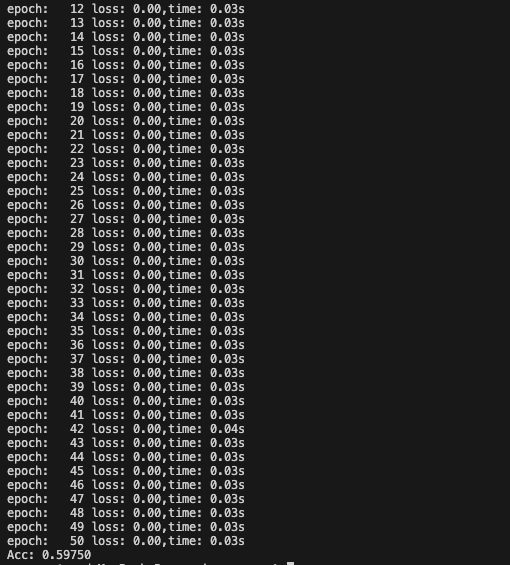
八、優化方案
8.1、數據預處理優化
添加了數據標準化處理(StandardScaler),使模型訓練更穩定
8.2、模型結構優化
- 使用Sequential模塊重構了網絡結構,使代碼更簡潔
- 增加了網絡深度,從3層擴展到5層(輸入層→128→256→512→256→輸出層)
- 添加了BatchNormalization層,加速訓練并提高穩定性
- 增加了Dropout層,防止過擬合
- 豐富了每個網絡層之間的連接,提高了模型的表達能力
8.3、訓練過程優化
- 將優化器從SGD更改為Adam,提高訓練效率
- 學習率從1e-3降低到1e-4,使訓練更穩定
- 添加了權重衰減(weight_decay)參數,減少過擬合
- 增加了學習率調度器(ReduceLROnPlateau),根據驗證損失動態調整學習率
- 訓練輪數從50增加到100,給模型更多學習時間
- 添加了訓練損失曲線可視化
- 每10輪在驗證集上評估一次模型性能
8.4、評估方法優化
- 新增單獨的驗證函數(validate),用于定期評估模型性能
- 強了測試函數(test),記錄所有預測結果,為后續詳細分析做準備
- 更準確地計算批次損失,考慮了批次大小
8.5、代碼實現
import torch
from torch.utils.data import TensorDataset
from torch.utils.data import DataLoader
import torch.nn as nn
import torch.optim as optim
from sklearn.datasets import make_regression
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import time
from torchsummary import summary
#構建數據集
def create_dataset():#使用pandas讀取數據data = pd.read_csv('/Volumes/My Passport/學習資料/黑馬大模型第三期/3期AI大模型配套資料/01階段:配套資料/03/03-代碼/02-神經網絡/dataset/手機價格預測.csv',encoding="utf-8")#特征值和目標值,x特征值取所有行,到倒數第2列,y目標值所有行的最后一列x,y = data.iloc[:,:-1],data.iloc[:,-1]#類型轉換,特征值,目標值x = x.astype(np.float32)y = y.astype(np.int64)#數據集劃分,80%訓練數據,20%的驗證數據,固定隨機種子為88x_train,x_valid,y_train,y_valid = train_test_split(x,y,train_size=0.8,random_state=88)#數據標準化處理scaler = StandardScaler()x_train_scaled = scaler.fit_transform(x_train)x_valid_scaled = scaler.transform(x_valid)## 構建數據集,轉換pytorch的形式train_dataset = TensorDataset(torch.from_numpy(x_train_scaled),torch.tensor(y_train.values))valid_dataset = TensorDataset(torch.from_numpy(x_valid_scaled),torch.tensor(y_valid.values))#返回結果return train_dataset,valid_dataset,x_train.shape[1],len(np.unique(y))#構建網絡模型
class PhonePriceModel(nn.Module):def __init__(self,input_dim,output_dim):super(PhonePriceModel,self).__init__()#構建更深的網絡結構self.model = nn.Sequential(#第一層,輸入維度,input_dim,輸出維度:128nn.Linear(input_dim,128),nn.ReLU(),nn.BatchNorm1d(128),nn.Dropout(0.2),#第二層,輸入維度:128,輸出維度:256nn.Linear(128,256),nn.ReLU(),nn.BatchNorm1d(256),nn.Dropout(0.3),#第三層,輸入維度:256,輸出維度512nn.Linear(256,512),nn.ReLU(),nn.BatchNorm1d(512),nn.Dropout(0.3),#第四層,輸入維度512,輸出維度256nn.Linear(512,256),nn.ReLU(),nn.BatchNorm1d(256),nn.Dropout(0.2),#輸出層,輸入維度:256,輸出維度:output_dim(類別數)nn.Linear(256,output_dim))def forward(self,x):"""前向傳播過程Args:x: 輸入特征張量Returns:輸出預測結果"""return self.model(x)#模型訓練
def train(train_dataset,input_dim,class_num,):#固定隨機種子torch.manual_seed(0)#初始化模型model = PhonePriceModel(input_dim,class_num)#使用交叉熵損失函數criterion = nn.CrossEntropyLoss()#優化方法從SGD改為Adam,學習率從le-3調整為le-4optimizer = optim.Adam(model.parameters(),lr=1e-4,weight_decay=1e-5)#增加學習率調度器scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer,'min',patience=5,factor=0.5,verbose=True)#訓練輪數從50增加到100num_epoch = 100#記錄訓練過程中的損失train_losses = []#遍歷每個輪次的數據for epoch_idx in range(num_epoch):#初始化數據加載器dataloader = DataLoader(train_dataset,shuffle=True,batch_size=8)#訓練時間start = time.time()#設置模型為訓練模式model.train()#計算損失total_loss = 0.0total_samples = 0for x,y in dataloader:#將數據送入網絡中進行預測output = model(x)#計算損失loss = criterion(output,y)#梯度歸零optimizer.zero_grad()#反向傳播loss.backward()#參數更新optimizer.step()#累加損失batch_size = x.size(0)total_samples += batch_sizetotal_loss += loss.item()*batch_size#計算平均損失epoch_loss = total_loss / total_samplestrain_losses.append(epoch_loss)#打印訓練信息print(f'Epoch: {epoch_idx+1:4d} | Loss: {epoch_loss:.4f} | Time: {time.time()-start:.2f}s | LR: {optimizer.param_groups[0]["lr"]:.6f}')#每10輪進行一次驗證if(epoch_idx+1)%10==0:validate(model,valid_dataset,criterion)torch.save(model.state_dict(),'/Users/zsz/workspace-py/pyTorch/model/phone2.pth')#繪制損失曲線plt.figure(figsize=(10,5))plt.plot(train_losses)plt.title('Training Loss Over Epochs')plt.xlabel('Epoch')plt.ylabel('Loss')plt.grid(True)plt.savefig('/Users/zsz/workspace-py/pyTorch/model/training_loss.png')plt.show()#驗證函數
def validate(model,valid_dataset,criterion):"""在驗證集上評估模型性能Args:model: 訓練的模型valid_dataset:驗證數據集criterion:損失函數"""#設置為評估模式model.eval()#構建數據加載器dataloader = DataLoader(valid_dataset,batch_size=8,shuffle=False)#初始化評估指標correct = 0total_samples = 0valid_loss = 0.0#禁用梯度計算with torch.no_grad():for x,y in dataloader:#向前傳播outputs = model(x)#計算損失loss = criterion(outputs,y)#獲取預測結果_,predicted = torch.max(outputs,1)#統計樣本和正確預測數batch_size = y.size(0)total_samples += batch_sizecorrect += (predicted==y).sum().item()valid_loss += loss.item() * batch_size#計算準確率和平均損失accuracy = correct / total_samplesavg_loss = valid_loss / total_samplesprint(f'Validation - Loss: {avg_loss:.4f} | Accuracy: {accuracy:.4f}')#測試函數
def test(valid_dataset,input_dim,class_num):"""測試模型在驗證集上的性能Args:valid_dataset: 驗證數據集input_dim: 輸入特征的維度class_num: 分類的類別數"""#加載model = PhonePriceModel(input_dim,class_num)model.load_state_dict(torch.load('/Users/zsz/workspace-py/pyTorch/model/phone2.pth'))#設置模型model.eval()#構建加速器dataloader = DataLoader(valid_dataset,batch_size=8,shuffle=False)#評估測試集correct = 0total = 0all_predictions = []all_targets = []#禁用梯度計算with torch.no_grad():for x,y in dataloader:#前向轉播outputs = model(x)#獲取預測類別_,predicted = torch.max(outputs,1)#記錄預測結果all_predictions.extend(predicted.numpy())all_targets.extend(y.numpy())#統計準確率total += y.size(0)correct += y.size(0)correct += (predicted==y).sum().item()accuracy = correct/totalprint(f'Test Accuracy:{accuracy:.5f}')if __name__ == '__main__':#獲取數據train_dataset,valid_dataset,input_dim,class_num = create_dataset()print("輸入特征數:",input_dim)print("分類個數:",class_num)#模型實例化model = PhonePriceModel(input_dim,class_num)#打印模型結構summary(model,input_size=(input_dim,),batch_size=16)#模型訓練train(train_dataset,input_dim,class_num)#模型預測test(valid_dataset,input_dim,class_num)輸出結果:
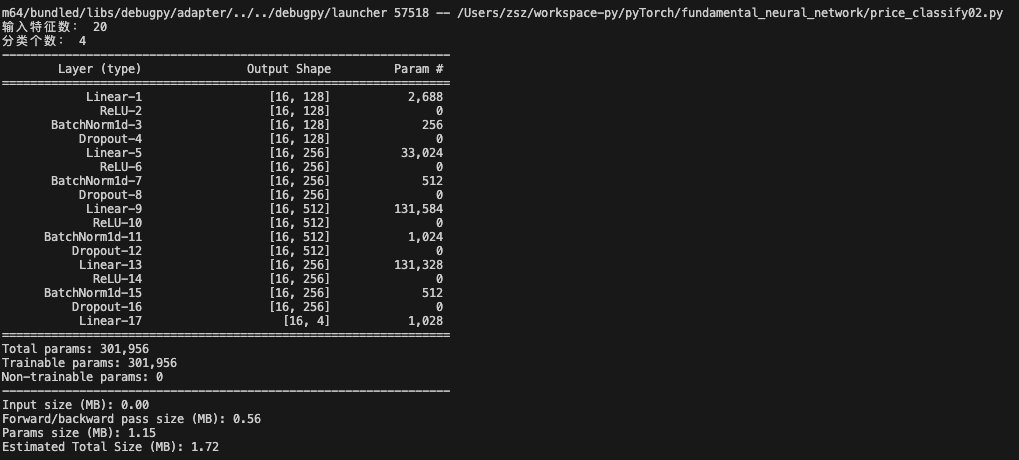
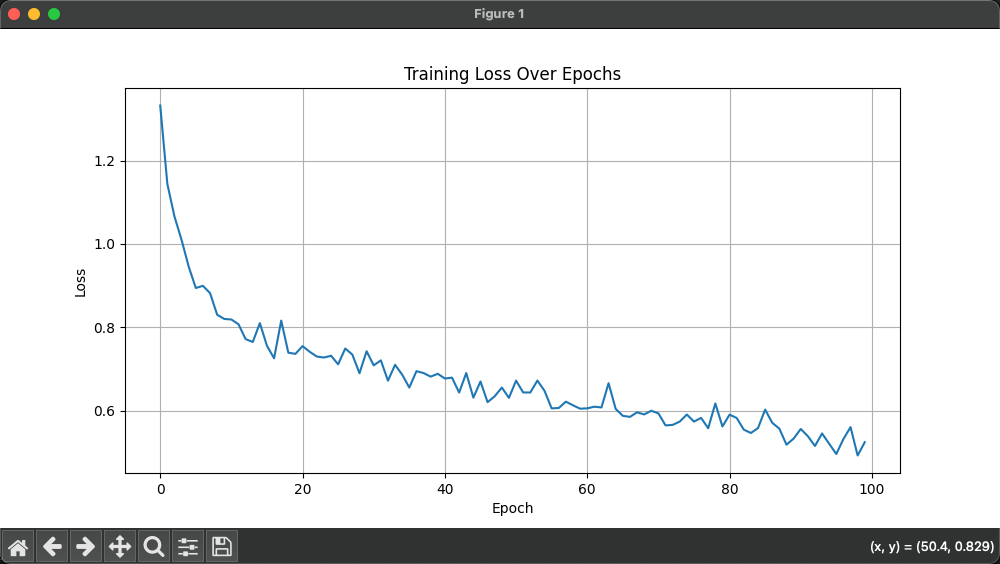
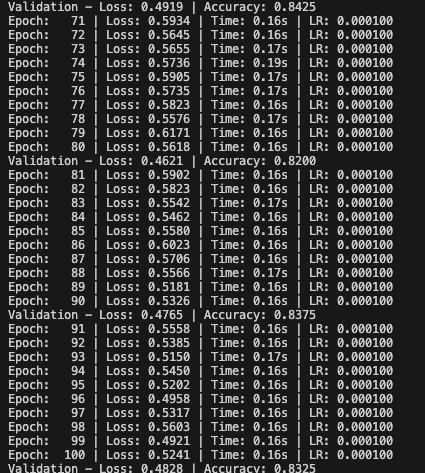
右圖可知,優化后,精度由0.59750提升到0.825,優化效果明顯






)
算法)











