遙感數據具有高維度、非線性及空間異質性等特點,傳統分析方法往往難以充分挖掘其信息價值。機器學習技術的引入為遙感數據處理與模型預測提供了新的解決方案,其中隨機森林(Random Forest)以其優異的性能和靈活性成為研究者的首選工具之一。作為一種集成學習方法,隨機森林通過構建多棵決策樹并引入隨機性(如Bootstrap抽樣和特征子集選擇),顯著降低了模型的方差與過擬合風險,同時具備處理高維數據、噪聲及異常值的魯棒性。其集成投票或平均機制進一步提升了預測的穩定性和準確性。此外,隨機森林提供的變量重要性評估功能,能夠幫助識別關鍵特征,優化模型結構,為遙感數據建模與空間預測提供科學依據。
R語言憑借其豐富的機器學習生態和高效的計算能力,為隨機森林的實現與應用提供了強大支持。通過randomForest、ranger等擴展包,用戶可以便捷地完成分類、回歸及多類別任務,并靈活調整參數以適應不同場景需求。R語言在數據可視化方面的優勢,進一步增強了模型結果的可解釋性,例如通過變量重要性排序圖(如文中圖表所示)直觀展示特征貢獻度。
第一章、理論基礎與數據準備【夯實基礎】
1.1 遙感數據在生態學中的應用
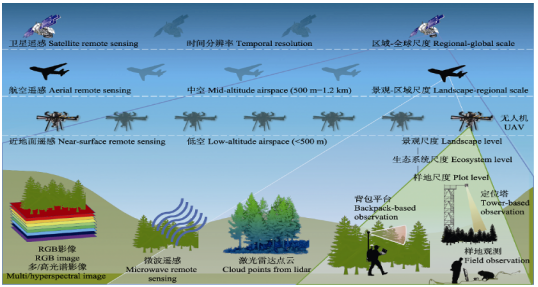
1.2 常見的機器學習算法及其遙感中的應用
機器學習基礎 機器學習是一門研究如何通過數據來自動改進模型和算法性能的學科。
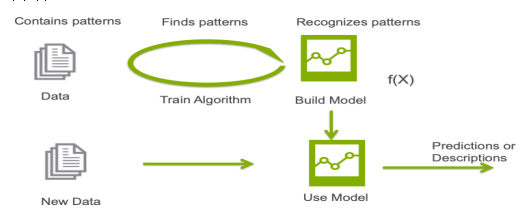
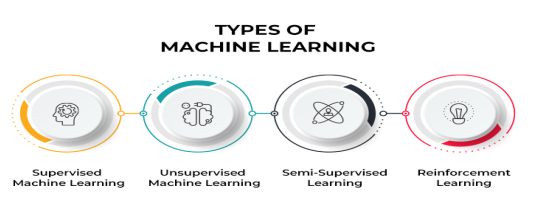
常見的機器學習算法:支持向量機、隨機森林、決策樹等
機器學習算法在生態學中的應用分析
1.3 R語言環境設置與基礎
(1)安裝R及集成開發環境(IDE);
(2)R語言基礎語法與數據結構,包括:程序包安裝、加載、更新,數據讀取與輸出,ggplot2常規畫圖等。
1.4 遙感數據處理與特征提取
(1)柵格數據預處理
柵格數據信息查看、統計和可視化
柵格數據掩膜提取、鑲嵌、重采樣等
(2)植被特征指數解釋與提取:歸一化植被指數、水體指數等數十種植被指數
第二章、隨機森林建模與預測【講解+實踐】
2.1預測模型的建立
隨機森林(RF)、極限梯度提升機(XGBoost)和支持向量機(SVM)等機器學習算法,分別建立預測模型,并參數調優。
2.2 最優模型空間預測
通過R2、RMSE、MAE等指標評價模型效率,選擇最優模型進行空間預測。
2.3 預測變量重要性分析
分析解釋變量對模型預測結果的影響,通過特征重要性分析等方法識別并量化解釋變量與因變量。
2.4 預測結果空間分布制圖
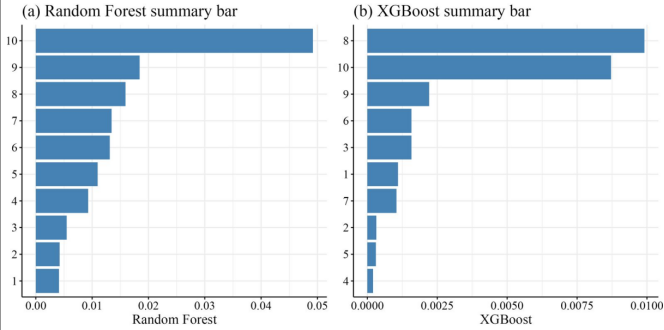
第三章、實踐案例與項目
3.1 實際案例分析
(1)機器學習案例分析:以隨機森林為例,分析高水平論文結構與寫作思路、復現相關圖表
(2)整合、分析機器學習在遙感、生態領域的經典論文。






![每日一題洛谷P1025 [NOIP 2001 提高組] 數的劃分c++](http://pic.xiahunao.cn/每日一題洛谷P1025 [NOIP 2001 提高組] 數的劃分c++)




)


)




)