HunyuanVideo: A Systematic Framework For Large Video Generative Models
-
原文摘要
-
研究背景與問題
-
視頻生成的變革性影響:近期視頻生成技術的進步深刻改變了個人生活與行業應用。
-
閉源模型的壟斷:主流視頻生成模型(如Runway Gen-3、Luma 1.6等)均為閉源,導致工業界與開源社區之間存在顯著的性能差距。
-
-
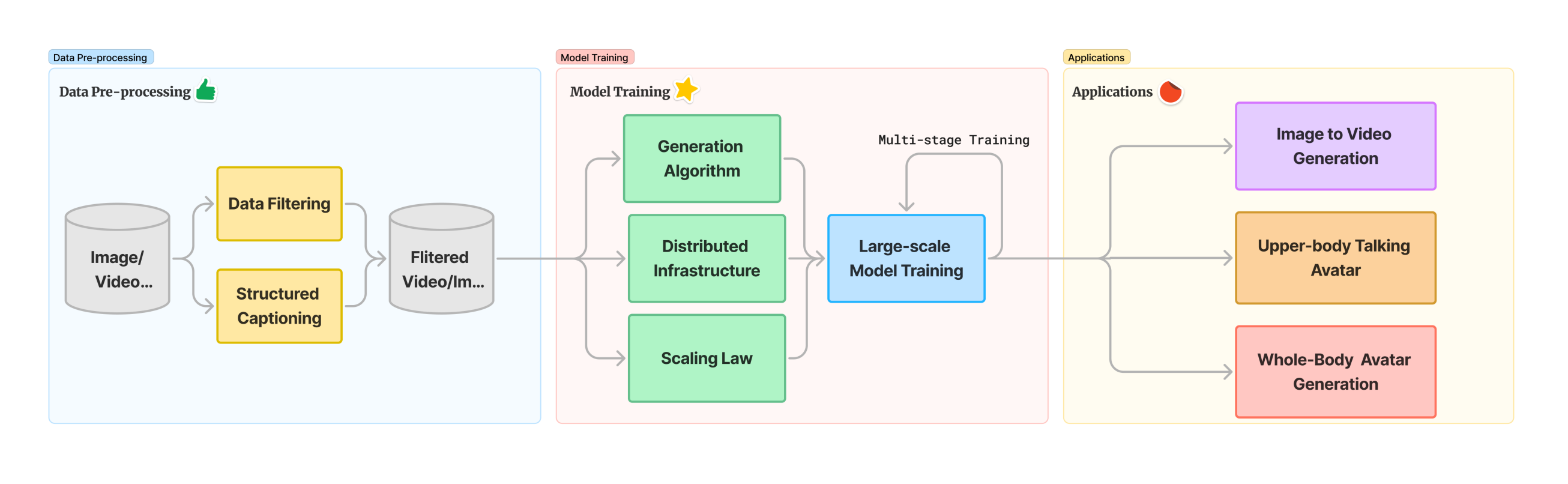
核心貢獻:HunyuanVideo模型
-
開源視頻基礎模型:提出首個性能媲美甚至超越閉源模型的開放視頻生成框架。
-
四大關鍵技術:
- 數據策展(curation):高質量數據集的構建與優化。
- 先進架構設計:創新的模型結構設計。
- 漸進式訓練與擴展:通過分階段訓練和參數縮放提升性能。
- 高效基礎設施:支持大規模訓練與推理的底層系統優化。
-
-
模型規模與性能
-
參數量:超過130億參數,為當前開源領域最大的視頻生成模型。
-
性能優勢:在視覺質量、運動動態、文本-視頻對齊、專業拍攝技巧等方面表現優異,經專業人工評估,超越SOTA閉源模型(如Runway Gen-3)及3個中國頂尖視頻模型。
-
-
實驗與設計亮點
-
針對性優化:通過大量實驗驗證了模型在關鍵指標(如動態效果、文本對齊)上的優越性。
-
專業評估:采用人工評估(非自動化指標)確保結果可靠性。
-
-
-
Hunyuan Training System
1.Introduction
-
技術背景
-
擴散模型的優勢:
- 相比傳統GAN方法,擴散模型在圖像/視頻生成質量上表現更優,已成為主流生成范式。
- 圖像生成領域的繁榮:開源生態活躍(如Stable Diffusion),催生大量算法創新和應用(如ControlNet、LoRA)。
-
視頻生成的滯后:
- 基于擴散模型的視頻生成技術發展緩慢,開源社區缺乏能與閉源模型(如Gen-3)競爭的基礎模型。
- 關鍵瓶頸:缺乏像T2I(Text-to-Image)領域那樣強大的開源視頻基礎模型。
-
-
問題分析:閉源壟斷
-
閉源vs開源的不平衡:
- 閉源視頻模型(如MovieGen)性能領先但未開源,壓制了開源社區的創新潛力。
- 現有開源視頻模型(如MovieGen)雖表現良好,但未形成穩定開源生態。
-
技術挑戰:
- 直接擴展圖像生成方法(如簡單Transformer+Flow Matching)效率低下,計算資源消耗大。
-
-
HunyuanVideo的提出
-
核心目標:
- 構建首個高性能、全棧開源的視頻生成基礎模型,填補開源空白。
-
系統性框架:
- 訓練基礎設施:優化分布式訓練與推理效率。
- 數據治理:互聯網規模圖像/視頻的精選與預處理。
- 架構優化:突破簡單Transformer的局限,設計高效縮放策略。
- 漸進式訓練:分階段預訓練+微調,平衡資源與性能。
-
關鍵技術突破:
- 高效縮放策略:減少5倍計算資源,同時保持模型性能。
- 超大規模訓練:成功訓練130億參數模型(當前開源最大)。
-
-
Hunyuan性能驗證
-
四大核心指標:
- 視覺質量、運動動態、視頻-文本對齊、語義場景切換(scene cut)。
-
評測結果:
- 評測規模:60人團隊使用1,500+文本提示,對比Gen-3、Luma 1.6及3個中國商業模型。
- 關鍵結論:HunyuanVideo綜合滿意度最高,運動動態表現尤為突出。
-
2. Data Pre-processing
- 數據來源&整體策略
- 訓練策略:圖像視頻聯合訓練
- 數據分類:視頻(5類)+ 圖像(2類),針對性優化訓練
- 合規保障:GDPR + 隱私計算技術,確保數據安全
- 高質量篩選:專業級標準(構圖/色彩/曝光)提升模型表現
- 實驗驗證:高質量數據對模型性能有顯著增益
2.1 Data Filtering

2.1.1 視頻數據預處理
-
初始處理(Raw Video Processing)
-
單鏡頭分割:使用 PySceneDetect將原始視頻拆分成單鏡頭片段(single-shot clips),避免跨鏡頭內容干擾。
-
清晰幀提取:通過 OpenCV 的 Laplacian 算子檢測最清晰的幀作為片段的起始幀。
-
視頻嵌入計算:使用內部 VideoCLIP 模型計算每個片段的嵌入向量(embeddings),用于:
- 去重:基于余弦相似度(Cosine distance)剔除重復/高度相似的片段。
- 概念平衡:通過 k-means 聚類生成約 1 萬個概念中心(concept centroids),用于數據重采樣,避免某些概念過擬合。
-
-
分層過濾(Hierarchical Filtering Pipeline)
-
通過多級過濾器逐步提升數據質量,最終生成 5 個訓練數據集(對應后文的 5 個訓練階段)。關鍵過濾器包括:
-
美學質量評估
- 使用 Dover從**美學(構圖、色彩)和技術(清晰度、曝光)**角度評分,剔除低質量視頻。
- 訓練專用模型檢測模糊幀,移除不清晰的片段。
-
運動動態篩選
- 基于光流估計optical flow計算運動速度,過濾靜態或運動過慢的視頻。
-
場景邊界檢測
- 結合 PySceneDetect和 Transnet v2精確識別場景切換,確保片段連貫性。
-
文本與敏感信息處理
-
OCR 模型:移除含過多文字(如字幕)的片段,并裁剪字幕區域。
-
YOLOX類檢測器:去除水印、邊框、logo 等敏感或干擾元素。
-
-
-
實驗驗證
- 用小規模 HunyuanVideo 模型測試不同過濾器的效果,動態調整閾值(如嚴格度),優化最終流程。
-
-
漸進式數據增強
-
分辨率提升:從 256×256(65幀)逐步增加到 720×1280(129幀),適應不同訓練階段需求。
-
過濾嚴格度:早期階段放寬標準保留多樣性,后期逐步收緊(如更高美學/運動要求)。
-
-
微調數據集(Fine-tuning Dataset)
- 人工精選 100 萬樣本,聚焦高質量動態內容:
- 美學維度:色彩協調、光影、主體突出、空間布局。
- 運動維度:速度適中、動作完整性、無運動模糊。
- 人工精選 100 萬樣本,聚焦高質量動態內容:
2.1.2 圖像數據過濾
-
復用視頻的大部分過濾器(排除運動相關),構建 2 個圖像數據集:
-
初始預訓練數據集
- 規模:數十億圖文對,經過基礎過濾(如清晰度、美學)。
- 用途:文本到圖像(T2I)的第一階段預訓練。
-
第二階段預訓練數據集
-
規模:數億精選樣本,過濾閾值更嚴格(如更高分辨率、更優構圖)。
-
用途:提升 T2I 模型的細節生成能力。
-
-
2.2 Data Annotaion
2.2.1 Structured Captioning
-
背景與問題
-
傳統標注的缺陷:
- 簡短標注(Brief Captions):信息不完整(如僅描述主體,忽略背景/風格)。
- 密集標注(Dense Captions):冗余或噪聲多(如重復描述同一物體)。
-
需求:需兼顧全面性(多維度描述)、信息密度(無冗余)和準確性(與視覺內容嚴格對齊)。
-
-
解決方案:基于VLM的結構化標注
-
開發內部視覺語言模型(VLM),生成JSON格式的結構化標注,涵蓋以下維度:
字段 描述 示例 Short Description 場景主要內容摘要 “A woman running in a park.” Dense Description 細節描述(含場景過渡、攝像機運動) “Camera follows a woman jogging through a sunlit park with trees.” Background 環境背景(地理位置、時間、天氣等) “Sunny afternoon in Central Park.” Style 視頻風格(紀錄片、電影感、寫實、科幻等) “Cinematic, shallow depth of field.” Shot Type 鏡頭類型(特寫、中景、航拍等) “Medium shot, low angle.” Lighting 光照條件(自然光、背光、高對比度等) “Golden hour lighting.” Atmosphere 氛圍(緊張、溫馨、神秘等) “Energetic and lively.” Metadata Tags 從元數據提取的附加標簽(來源、質量評分等) “Source: professional DSLR, Quality: 4.5/5” -
實現細節
-
多樣性增強:通過隨機丟棄(Dropout)和排列組合策略,生成不同長度/模式的變體,防止模型過擬合單一標注風格。
-
例如:同一視頻可能生成以下兩種標注:
// 變體1:強調運動與鏡頭 {"Dense Description": "Camera pans left to follow a cyclist...", "Shot Type": "Pan left"} // 變體2:強調風格與氛圍 {"Style": "Documentary", "Atmosphere": "Gritty urban vibe"}
-
-
全數據覆蓋:所有訓練圖像/視頻均通過此標注器處理,確保數據一致性。
-
-
2.2.2 Camera Movement Types
-
研究動機
-
攝像機運動是視頻動態表現的核心,但現有生成模型缺乏對其的顯式控制能力。
-
需高精度分類以支持生成時的運動控制(如“鏡頭向右平移”)。
-
-
訓練運動分類器
-
訓練專用模型,預測以下14種運動類型:
運動類型 描述 應用場景 Zoom in/out 推近/拉遠 突出主體或展示環境 Pan (up/down/left/right) 水平/垂直平移鏡頭 跟隨運動或展示廣闊場景 Tilt (up/down/left/right) 傾斜調整視角 創造戲劇化視角(如仰拍反派) Around left/right 環繞拍攝 3D場景展示(如產品展示) Static shot 固定鏡頭 對話場景或穩定畫面 Handheld shot 手持抖動鏡頭 模擬紀實風格(如戰爭片) -
高置信度預測結果直接寫入結構化標注JSON中
-
3. Model Design
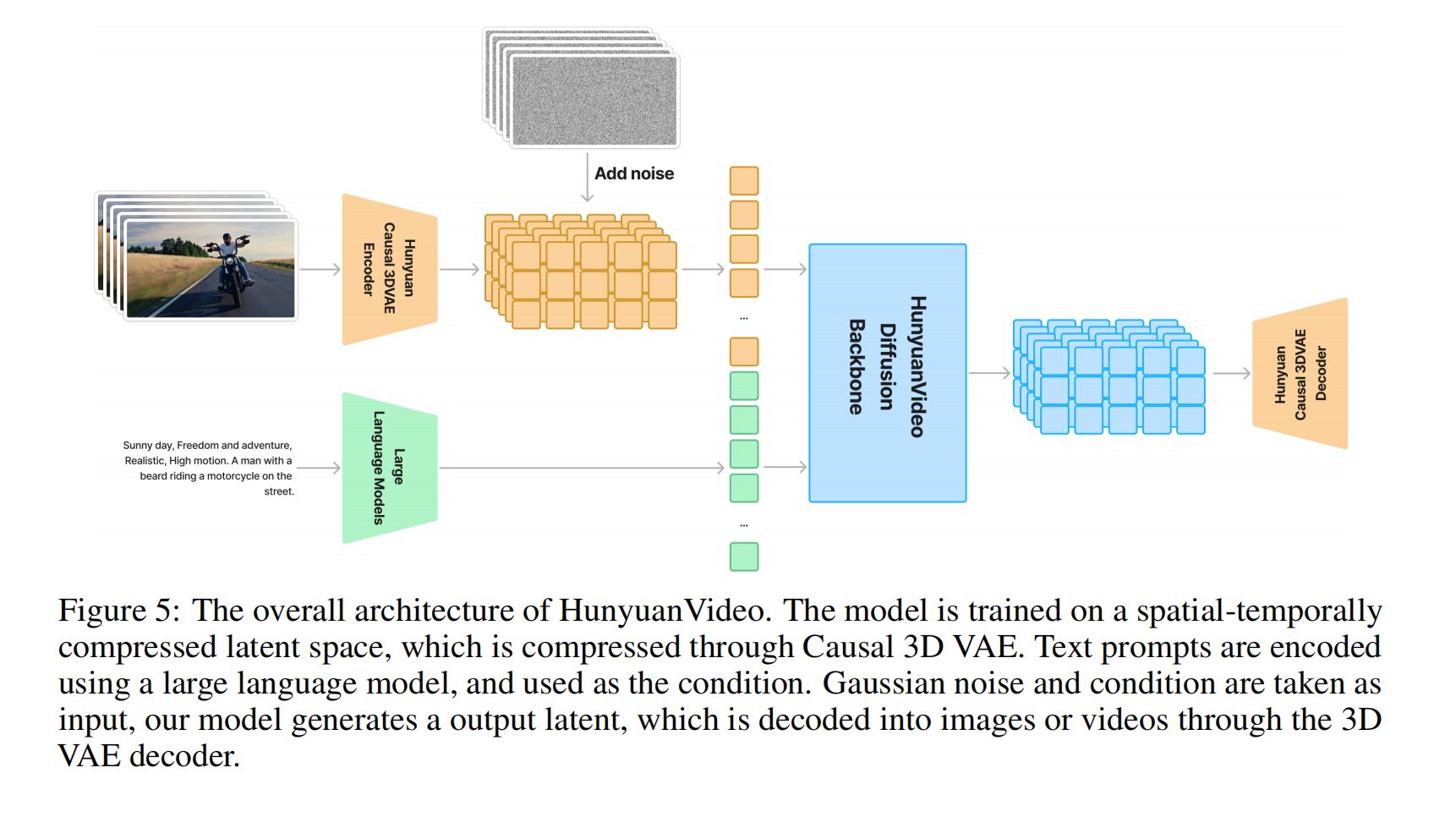
3.1 3D VAE Design
-
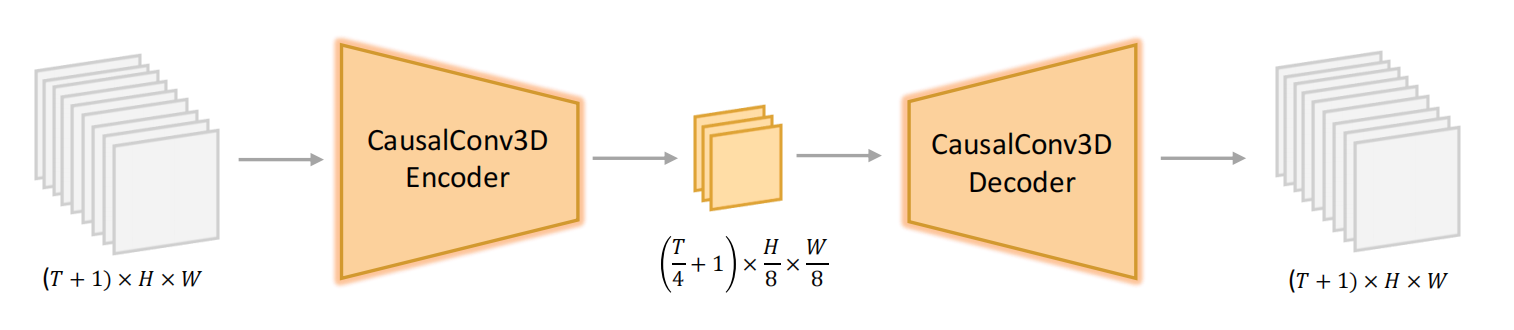
為了同時處理視頻和圖像,文章使用了CausalConv3D
-
網絡架構設計
-
輸入與輸出格式
-
輸入視頻:形狀為 ( T + 1 ) × 3 × H × W (T+1)×3 × H × W (T+1)×3×H×W
-
輸出潛變量:形狀為 ( T / c t + 1 ) × C × ( H / c s ) × ( W / c s ) (T/c? + 1) × C × (H/c?) × (W/c?) (T/ct?+1)×C×(H/cs?)×(W/cs?)
c?:時間下采樣因子(temporal stride),默認為 4(即每4幀壓縮為1個隱變量幀)。c?:空間下采樣因子(spatial stride),默認為 8(如輸入256×256 → 隱空間32×32)。C:隱變量通道數,默認為 16。
-
-
3D卷積編碼器:
- 采用 CausalConv3D(因果3D卷積),確保時間維度上的因果性(當前幀僅依賴過去幀)。
- 層級式下采樣結構,逐步壓縮時空維度(類似3D版U-Net)。
-
3D卷積解碼器:
- 對稱結構,通過轉置3D卷積(Transpose3DConv)重建原始分辨率視頻。
-
為什么輸入是T+1幀
- 要以第一幀作為參考幀,來實現因果卷積
-
3.1.1 Training
-
訓練數據與初始化
-
不從預訓練圖像VAE初始化:
- HunyuanVideo 從頭訓練 3DVAE,避免預訓練圖像VAE的偏差。
- 原因:視頻數據具有時空連續性,直接復用圖像VAE參數會限制模型對運動信息的建模能力。
-
數據混合比例:
- 視頻與圖像數據按 4:1 混合訓練,平衡時空動態(視頻)與靜態細節(圖像)的學習。
-
-
損失函數設計
Loss = L 1 + 0.1 L lpips + 0.05 L adv + 1 0 ? 6 L kl \text{Loss} = L_{1} + 0.1 L_{\text{lpips}} + 0.05 L_{\text{adv}} + 10^{-6} L_{\text{kl}} Loss=L1?+0.1Llpips?+0.05Ladv?+10?6Lkl?-
L1重建損失:
- 約束像素級重建精度,保留低頻結構信息。
-
Llpips感知損失:
- 通過預訓練VGG網絡計算特征相似性,提升細節和紋理質量。
-
Ladv對抗損失:
- 添加判別器區分真實與重建幀,增強生成逼真度。
-
KL散度損失:
- 約束隱變量分布接近標準高斯(權重10??),避免后驗坍塌。
-
-
漸進式課程學習(Curriculum Learning)
-
分階段訓練: 逐步提升分辨率
- 低分辨率短視頻(如256×256,16幀)→ 學習基礎時空特征。
- 逐步提升至高清長視頻(如720×1280,128幀),避免直接訓練高難度數據的收斂問題。
-
動態幀采樣:
- 隨機從 1~8幀間隔 均勻采樣,強制模型適應不同運動速度的視頻(如快速動作或靜態場景)。
- 若
k=1:取所有幀(處理原始運動速度)。 - 若
k=4:每4幀取1幀(模擬4倍速運動)。 - 若
k=8:每8幀取1幀(極端高速運動測試)。
- 若
- 隨機從 1~8幀間隔 均勻采樣,強制模型適應不同運動速度的視頻(如快速動作或靜態場景)。
-
3.1.2 Inference
-
問題背景:
- 高分辨率長視頻(如4K)在單GPU上直接編碼/解碼會內存溢出(OOM)。
-
解決方案:
-
時空分塊(Tiling):
- 將輸入視頻在時空維度切分為重疊塊,各塊單獨編碼和解碼。
- 輸出時通過線性混合重疊區消除接縫。
-
分塊感知微調:
-
問題:直接分塊推理會導致訓練-測試不一致(出現邊界偽影)。
-
改進:在訓練中隨機啟用/禁用分塊,使模型同時適應分塊與非分塊輸入。
-
-
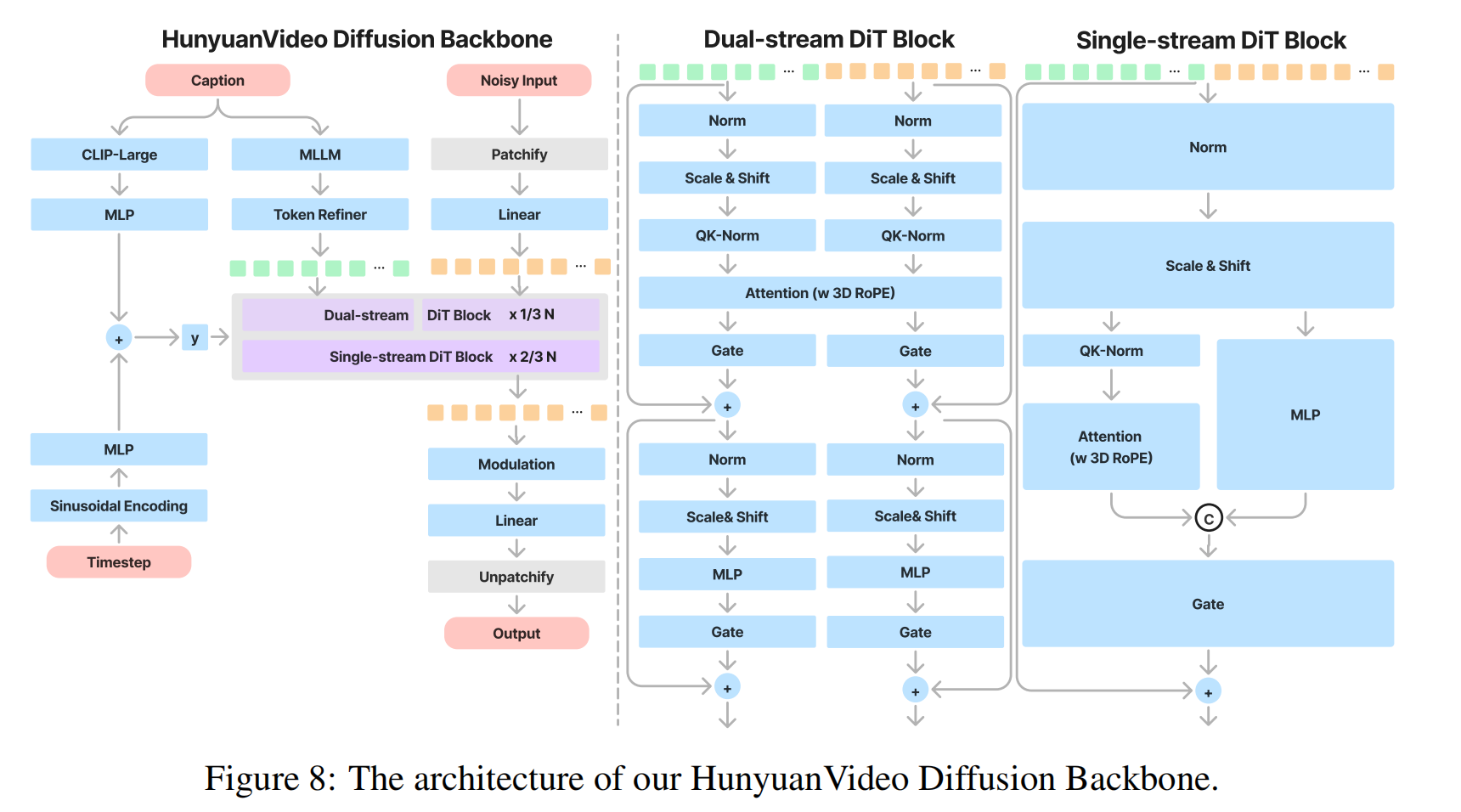
3.2 Unified Image and Video Generative Architecture
-
架構設計動機
-
統一架構的好處
-
性能優勢:實驗證明,全注意力機制(Full Attention)比分離的時空注意力生成質量更高,尤其在跨模態對齊上。
-
訓練簡化:圖像(單幀)和視頻(多幀)使用同一套參數,避免維護多個模型。
-
硬件友好:復用LLM的注意力優化技術(如FlashAttention),提升訓練/推理效率。
-
-
輸入統一化
-
圖像視為單幀視頻:
- 視頻輸入:
T × C × H × W(T幀,C通道,H×W分辨率)。 - 圖像輸入:
1 × C × H × W(T=1)。
- 視頻輸入:
-
潛空間壓縮:通過3DVAE將像素空間映射到低維潛空間
-
-
3.2.1 Inputs
-
視頻
-
3D Patch嵌入:
- 使用 3D卷積(核大小
kt × kh × kw)將潛變量切分為時空塊(Patch)。 - 例如:
kt=2, kh=16, kw=16→ 每2幀×16×16像素區域轉為1個Token。 - Token序列長度:
(T/kt) × (H/kh) × (W/kw)。
- 使用 3D卷積(核大小
-
示例計算:
- 輸入潛變量:
16×16×32×32(T=16, H=W=32),kt=kh=kw=2→ Token數:8×16×16=2048。
- 輸入潛變量:
-
-
文本
-
細粒度語義編碼:
- 用 LLM將文本轉為Token序列(如512維向量)。
-
全局語義補充:
- 通過 CLIP 提取文本的全局嵌入,與時間步嵌入融合后輸入模型。
- 這里和stable diffusion不同,hunyuan將clip的token向量(L,D)進行全局池化后變成了包含全局語義信息的(1,D)向量
- 通過 CLIP 提取文本的全局嵌入,與時間步嵌入融合后輸入模型。
-
3.2.2 Model Design
-
雙流階段(Dual-stream)
-
獨立處理模態:
- 視頻Token流:通過多層Transformer塊學習時空特征。
- 文本Token流:通過另一組Transformer塊提取語言特征。
-
目的:
- 避免早期融合導致模態干擾(如文本噪聲污染視覺特征)。
-
-
單流階段(Single-stream)
-
Token拼接:將視頻Token和文本Token合并為單一序列。
- 例如:
[Video_Tokens; Text_Tokens]→ 總長度2048+512=2560。
- 例如:
-
跨模態注意力:
- 通過Transformer塊計算視頻-文本交叉注意力,實現細粒度對齊(如物體屬性與描述匹配)。
-
3.2.3 Position Embedding
-
RoPE的三維擴展
-
分通道計算:
- 將 Query/Key 的通道分為三組: d t , d h , d w d_t,d_h,d_w dt?,dh?,dw?,對應時間T、高度H、寬度W。
-
旋轉矩陣應用:
- 對每組通道分別乘以對應的旋轉頻率矩陣(如時間頻率、空間頻率)。
-
拼接與注意力:
- 合并三組通道后的Query/Key用于注意力計算,顯式編碼時空位置關系。
- 公式示意:
RoPE3D ( Q , K ) = Concat ( Rotate ( Q d t , T ) , Rotate ( Q d h , H ) , Rotate ( Q d w , W ) ) \text{RoPE3D}(Q,K) = \text{Concat}(\text{Rotate}(Q_{d_t}, T), \text{Rotate}(Q_{d_h}, H), \text{Rotate}(Q_{d_w}, W)) RoPE3D(Q,K)=Concat(Rotate(Qdt??,T),Rotate(Qdh??,H),Rotate(Qdw??,W))
-
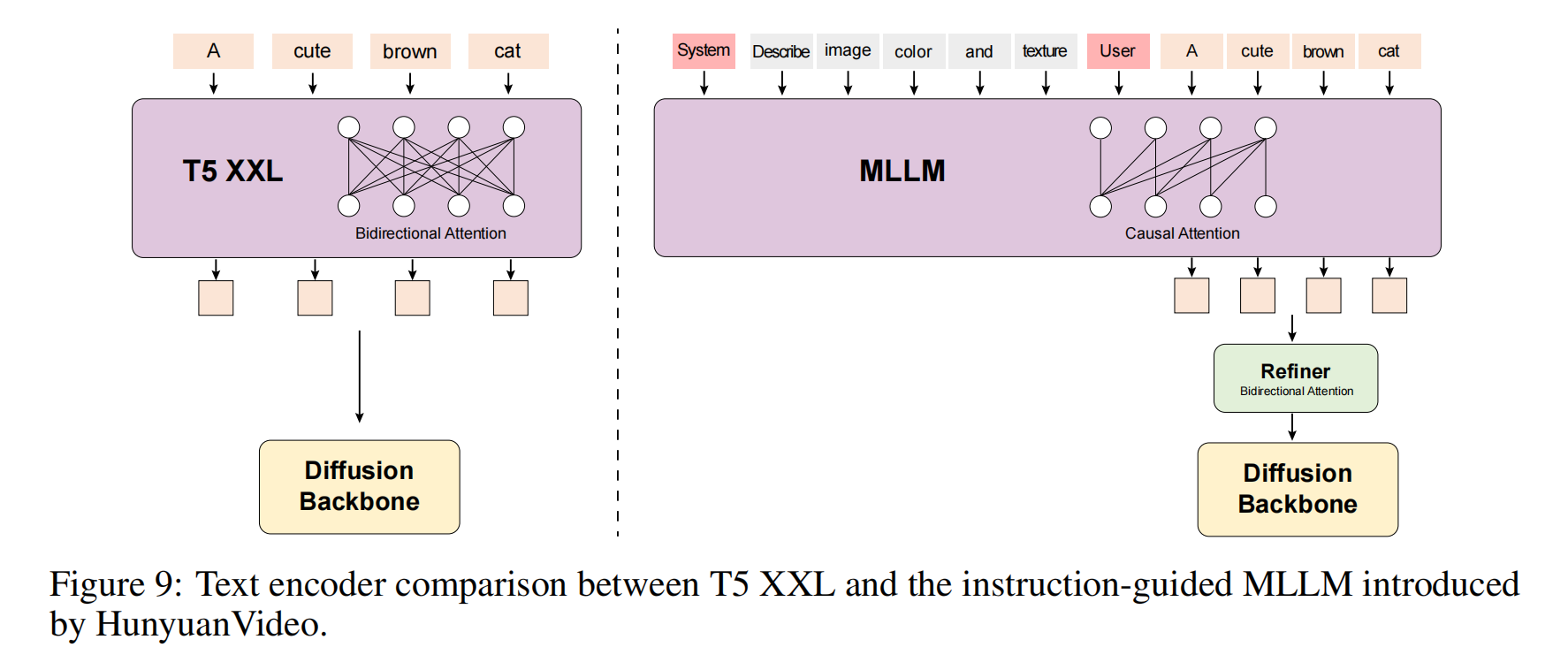
3.3 Text Encoder
-
選擇MLLM的原因
-
圖像-文本對齊優勢:
- MLLM 經過 視覺指令微調,其文本特征在隱空間中與視覺內容對齊更佳,緩解了擴散模型“指令跟隨不準”的問題(如忽略細節描述)。
-
復雜推理能力:
- MLLM 在圖像細節描述(如“貓的綠色眼睛”)和邏輯推理(如“A 在 B 左側”)上優于 CLIP 和 T5。
-
零樣本學習:
- 通過添加系統指令前綴(如“生成一個視頻,包含以下元素:…”),MLLM 能自動聚焦關鍵信息,抑制無關描述。
-
-
MLLM 的設計
-
因果注意力的局限性
-
問題:Decoder-Only 結構(如 GPT)的因果注意力只能關注歷史 Token,導致文本特征缺乏全局上下文。
-
解決方案:
- 引入 雙向 Token 優化器(Bidirectional Token Refiner),對 MLLM 輸出的文本特征進行后處理,增強上下文感知。
-
作用:
- 彌補 Decoder-Only 模型在雙向語義理解上的不足,提升提示詞之間的關聯性(如“紅色”和“蘋果”)。
-
-
-
CLIP 輔助作用
-
CLIP 特征的提取
-
輸入:與 MLLM 相同的文本提示。
-
處理:
- 通過 CLIP-Large 的文本編碼器生成 Token 序列。
- 取最后一個非填充 Token 的向量作為全局特征(形狀
[1, D])。
-
用途:
- 作為全局條件信號,與 MLLM 的細粒度特征互補,注入 DiT 的雙流和單流階段。
-
-
CLIP的作用
-
穩定性:CLIP 的對比學習訓練使其全局特征在風格控制(如“科幻”、“寫實”)上更魯棒。
-
多模態對齊:CLIP 的文本-圖像對齊能力可約束 MLLM 的輸出,避免生成偏離語義的內容。
-
-
3.4 Model-pretraining
3.4.1 Training Objective
HunyuanVideo 采用 Flow Matching 框架訓練圖像和視頻生成模型,其核心思想是通過 概率密度變換 和 速度場預測,將簡單分布(如高斯噪聲)逐步映射到復雜數據分布(如圖像/視頻潛空間)。
-
Flow Matching 的核心思想
-
基本定義
-
目標:學習一個連續變換路徑(Flow),將簡單分布 p 0 p_0 p0?(如高斯噪聲)轉換為數據分布 p 1 p_1 p1?(如真實圖像/視頻的潛變量)。
-
數學形式:通過時間 t ∈ [ 0 , 1 ] t \in [0,1] t∈[0,1] 參數化的概率密度變換:
p t = Transform ( p 0 , t ) p_t = \text{Transform}(p_0, t) pt?=Transform(p0?,t)- 其中 p t p_t pt? 是從 p 0 p_0 p0? 到 p 1 p_1 p1? 的中間狀態。
-
-
-
訓練過程的數學推導
-
樣本構造
-
輸入數據:從訓練集采樣真實潛變量 x 1 x_1 x1?(通過3DVAE編碼的圖像/視頻)。
-
噪聲初始化:采樣 $x_0 \sim \mathcal{N}(0, I) $。
-
時間采樣:從 logit-normal 分布 采樣 t ∈ [ 0 , 1 ] t \in [0,1] t∈[0,1],偏好兩端 ( t ≈ 0 或 t ≈ 1 ) ( t \approx 0 或 t \approx 1) (t≈0或t≈1)以強化困難樣本學習。
-
線性插值:構造中間樣本 ( x_t ):
x t = t x 1 + ( 1 ? t ) x 0 x_t = t x_1 + (1-t) x_0 xt?=tx1?+(1?t)x0?
- 當 t = 0 t=0 t=0: x t = x 0 x_t = x_0 xt?=x0?(純噪聲)。
- 當 t = 1 t=1 t=1: x t = x 1 x_t = x_1 xt?=x1?(真實數據)。
-
-
速度場預測
-
真實速度(Ground Truth):
- 對線性插值路徑,真實速度為:
u t = d x t d t = x 1 ? x 0 u_t = \frac{dx_t}{dt} = x_1 - x_0 ut?=dtdxt??=x1??x0?
-
模型預測:
- 神經網絡 v θ v_\theta vθ? 預測速度場 v t = v θ ( x t , t ) v_t = v_\theta(x_t, t) vt?=vθ?(xt?,t)。
-
損失函數:最小化預測速度與真實速度的均方誤差(MSE):
L generation = E t , x 0 , x 1 ∥ v t ? u t ∥ 2 \mathcal{L}_{\text{generation}} = \mathbb{E}_{t,x_0,x_1} \| v_t - u_t \|^2 Lgeneration?=Et,x0?,x1??∥vt??ut?∥2- 物理意義:強制模型學習如何將任意 x t x_t xt? 推回真實數據 x 1 x_1 x1?。
-
-
-
推理過程的實現
-
從噪聲生成數據
-
初始化:采樣噪聲 x 0 ~ N ( 0 , I ) x_0 \sim \mathcal{N}(0, I) x0?~N(0,I)。
-
ODE求解:
-
使用一階歐拉方法(Euler ODE Solver)數值求解:
x t + Δ t = x t + v θ ( x t , t ) ? Δ t x_{t+\Delta t} = x_t + v_\theta(x_t, t) \cdot \Delta t xt+Δt?=xt?+vθ?(xt?,t)?Δt -
從 t = 0 t=0 t=0 到 t = 1 t=1 t=1 積分,得到最終樣本 x 1 x_1 x1? 。
-
-
輸出:將 x 1 x_1 x1? 輸入3DVAE解碼器,生成圖像/視頻。
-
-
3.4.2 Image Pre-training
-
第一階段:256px 低分辨率訓練
-
目的:建立基礎語義映射(文本→圖像),學習低頻概念(如物體形狀、布局)。
-
關鍵技術:
- 多長寬比訓練(Multi-aspect Training):
- 避免裁剪導致的文本-圖像錯位(如“全景圖”被裁剪后丟失關鍵內容)。
- 示例:256px 錨定尺寸下,支持 1:1(正方形)、16:9(寬屏)等多種比例。
- 多長寬比訓練(Multi-aspect Training):
-
-
第二階段:256px+512px 混合尺度訓練
-
問題:直接微調512px會導致模型遺忘256px生成能力,影響后續視頻訓練。
-
解決方案:
- 動態批量混合(Mix-scale Training):
- 每個訓練批次包含不同分辨率的圖像(如256px和512px),按比例分配GPU資源。
- 錨定尺寸擴展:以256px和512px為基準,分別構建多長寬比桶(Aspect Buckets)。
- 動態批量大小:
- 高分辨率分配較小批量,低分辨率分配較大批量,最大化顯存利用率。
- 動態批量混合(Mix-scale Training):
-
3.4.3 Video-Image Joint Training
-
數據分桶(Bucketization)
-
分桶策略:
- 時長分桶(BT buckets):如 16幀、32幀、64幀。
- 長寬比分桶(BAR buckets):如 4:3、16:9、1:1。
- 總桶數:BT × BAR(如3時長×3比例=9桶)。
-
動態批量分配:
- 每個桶根據顯存限制設置最大批量(如16幀視頻批量大,64幀視頻批量小)。
- 訓練時隨機從不同桶采樣,增強模型泛化性。
-
-
漸進式課程學習
訓練階段 目標 低清短視頻 建立文本-視覺基礎映射,學習短程運動 低清長視頻 建模復雜時序 高清長視頻 提升分辨率與細節質量 - 圖像數據的作用:
- 緩解視頻數據不足,防止模型遺忘靜態場景語義(如物體紋理、光照)。
- 圖像數據的作用:
3.5 Prompt Rewrite
- 訓練無關的上下文重寫
- 多語言適配:該模塊旨在處理和理解各種語言的用戶提示,確保保留意義和上下文。
- 結構標準化:該模塊重述提示,使其符合標準化的信息架構。
- 術語簡化:將口語或專業術語轉化為生成模型熟悉的表達。
- 自修正技術(Self-Revision)
- 對比原始提示與重寫結果,通過語義相似度檢測和自動修正,確保意圖一致性。
- 輕量化微調(LoRA)
- 基于高質量重寫樣本對 Hunyuan-Large 進行低秩適配器(LoRA)微調,提升重寫精度和效率,支持實時處理。
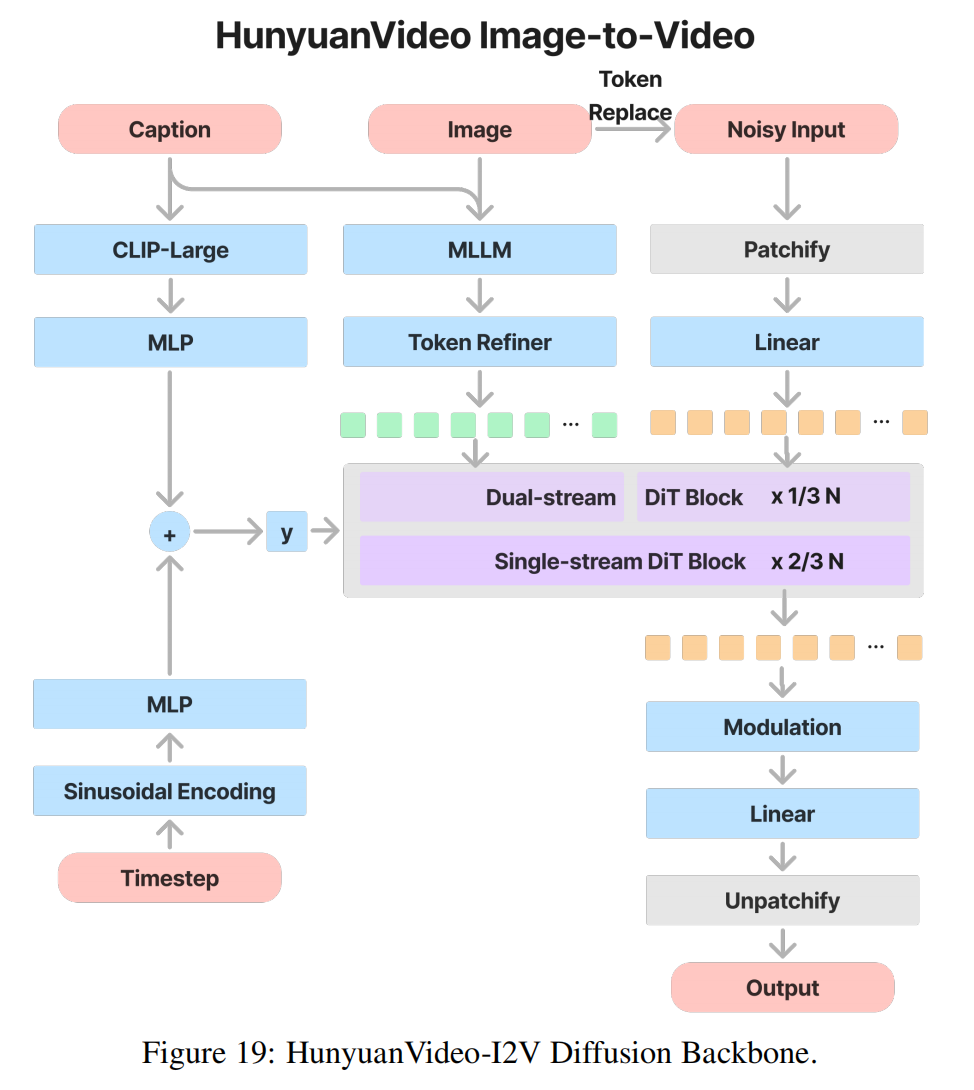
4. Image-to-Video
-
核心架構設計
-
圖像潛變量替換(Token Replace)
- 輸入處理:
- 將參考圖像通過 3DVAE 編碼器 轉換為潛變量 z image z_{\text{image}} zimage?(形狀: C × H × W C \times H \times W C×H×W )。
- 替換首幀:在生成視頻的潛變量序列中,強制將第一幀替換為 z image z_{\text{image}} zimage? ,并設置其時間步 t = 0 t=0 t=0(表示完全保留圖像信息)。
- 該幀參與attention機制,用于被別的幀參考;但不會參與去噪,即每個timestep都不會被更改。
- 后續幀生成:其余幀通過 T2V 的 Flow Matching 框架生成,確保運動連貫性。
- 輸入處理:
-
語義圖像注入模塊(Semantic Image Injection)
- 多模態對齊:
- 將輸入圖像輸入 MLLM(多模態大模型),提取語義 Token
- 將這些 Token 與視頻潛變量拼接,參與 全注意力計算(Full-Attention),確保生成視頻的語義與圖像一致。
- 多模態對齊:
-
-
訓練策略
-
預訓練階段
- 數據:使用與 T2V 相同的數據集,但將部分樣本的首幀替換為圖像,并添加圖像描述作為附加條件。
-
下游任務微調(人像視頻生成)
-
數據篩選:
- 使用 人臉和人體檢測器 過濾訓練視頻:
- 移除超過 5 人的視頻(避免群體動作干擾)。
- 移除主體過小的視頻(確保主要人物清晰)。
- 人工審核保留高質量人像視頻(約 200 萬條)。
- 使用 人臉和人體檢測器 過濾訓練視頻:
-
漸進式微調:
- 初始階段:僅微調與圖像注入相關的模塊(如 MLLM 的投影層)。
- 后期階段:逐步解凍更多層(如時空注意力層),平衡人像生成與通用性。
-
-



)
算法)













![每日一題洛谷P1025 [NOIP 2001 提高組] 數的劃分c++](http://pic.xiahunao.cn/每日一題洛谷P1025 [NOIP 2001 提高組] 數的劃分c++)
