文章目錄
- 說明
- 基礎知識
- 人工智能、機器學習、深度學習的關系
- 機器學習
- 傳統機器學習的缺陷
- 選擇深度學習的原因
- 深度學習的關鍵問題
- 深度學習的應用
- 深度學習的加速硬件GPU
- 環境搭建
- 主流深度學習框架對比
說明
- 文章屬于個人學習筆記內容,僅供學習和交流。
- 內容參考深度學習原理與實踐》陳仲銘版和個人學習經歷和收獲而來。
基礎知識
人工智能、機器學習、深度學習的關系
- 人工智能的問題基本上分為6個方向:問題求解、知識推理、規劃問題、不確定性推理、通信感知與行動、學習問題。
- 機器學習主要有 3 個方向:分類、回歸、關聯性分析。

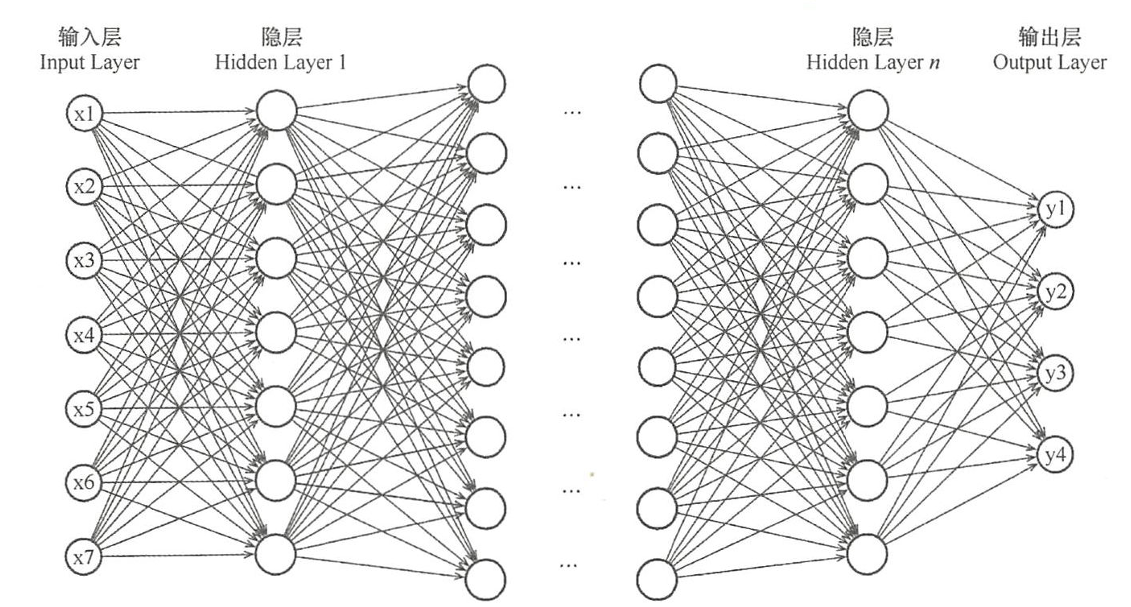
- 深度學習的定義是:具有兩層以上的神經網絡。
-
深度神經網絡其實是深度學習的基礎,深度學習的應用和技術絕大部分都是基于深度神經網絡框架。
-
神經網絡的特點:具有更多的神經元;具有更復雜的網絡連接方式;擁有驚人的計算量;能夠自動提取數據高維特征。
-
深度網絡主要是指具有深層的神經網絡,包括:人工神經網絡(ANN)、卷積神經網絡(CNN)、循環神經網絡(RNN)。
機器學習
- 機器學習按照方法主要可以分為兩大類:監督學習和無監督學習。其中監督學習主要由分類和回歸等問題組成,深度學習則屬于監督學習當中的一種;無監督學習主要由聚類和關聯分析等問題組成。
- 機器學習中的監督學習是指使用算法對有標注的數據進行解析,從數據中學習特定的結構模型,使用模型來對未知的新數據進行預測。通俗來說,監督學習就是通過對數據進行分析,找到數據的表達模型,然后套用該模型來做決策。
- 監督學習的一般方法主要分為訓練和預測階段。
- 在訓練階段(對數據進行分析的階段),根據原始的數據進行特征提取【特征工程】。得到特征后,使用決策樹、隨機森林等模型算法去分析數據之間的特征或者關系,最終得到關于輸入數據的模型(Model)。
- 在預測階段,同樣提取數據后,使用訓練階段獲得的模型對特征向量進行預測,得到最終的標簽(Labels)。
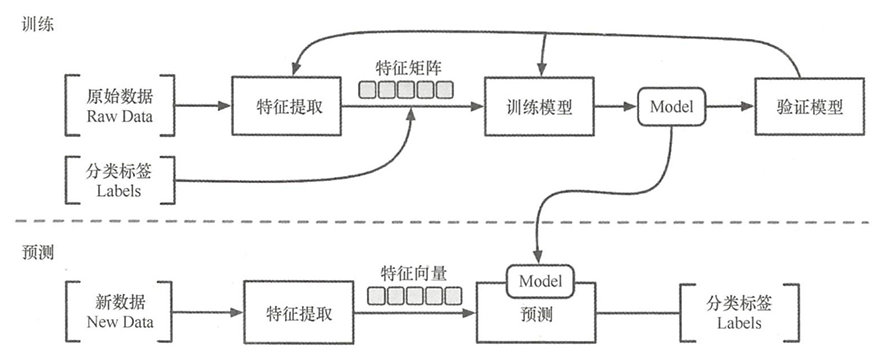
- 機器學習算法中不同的模型使用自己特定的規則去解釋輸入的數據,然后對新輸入的數據進行預測和判斷。例如決策樹的模型,是構建一個樹形結構,一個節點代表一種數據類型,一個葉子節點則代表一種類別;線性回歸模型利用線性回歸方程創建一組參數來表示輸入的數據之間的關系;神經網絡則有一組權重參數向量來代表節點之間的關系。
傳統機器學習的缺陷
- 在實際情況中,如果輸入的數據受到影響導致特征數據變化,傳統機器學習的算法的有效性就會降低,如當遇到雨雪天氣時,馬路一旁的標志牌變模糊,抑或標志牌被樹木遮擋時,標志牌的特征也會改變。
選擇深度學習的原因
- 深度學習自動篩選數據,自動提取數據高維特征。選擇深度學習,一方面它節省時間,降低工作量,提高工作效率;另一方面是深度學習的效果,在眾多領域能夠獲得比人類預測的更好的效果:此外,深度學習還可以與大數據無縫結合,輸入龐大的數據集進行大數據端到端的學習過程,這種大道至簡的理念吸引著無數的研究者。
深度學習的關鍵問題
- 深度學習開發的關鍵問題:
- 深度網絡模型需要輸入的數據類型?
- 深度網絡模型需要提取的數據內容?
- 深度網絡模型的選擇?
- 使用模型后預期的結果?
- 第一個問題,數據類型可以是圖片、文擋、語音,根據具體的任務需求確定。
- 第二個問題,明確要從模型中提取數據體類型后,就可以更加清晰地定義網絡模型的損失函數。
- 第三個問題,落實到神經網絡的實現中,例如卷積神經網絡 CNN 中大概用的網絡層數,循環神經網絡 RNN 中應該定義的循環層數和時間步等。
- 第四個問題,更加有利于把深度學習的算法與模型結合到工程項目當中,真正幫助我們解決實際問題。
深度學習的應用
- 圖像處理:Mask R-CNN對圖像進行目標檢測和圖形語義分割。

- 高精度地圖:通過使用深度學習的感知算法對激光雷達和攝像頭采集到的路面信息進行融合,制作成高精度地圖。

- 機器人:深度學習技術的突破使得機器人的復雜感知變為可能。
- 醫療健康診斷:利用深度學習技術對細胞影像圖進行分剖,檢查病變細胞
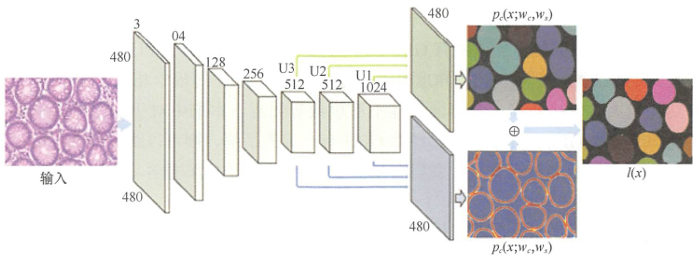
深度學習的加速硬件GPU
-
三U之CPU、GPU、NPU
-
硬件加速器是深度學習應用的核心要素,能夠獲得巨大的計算性能提升。
-
GPU 作為硬件加速器之一, 通過大量圖形處理單元與 CPU協同工作,對深度學習、數據分析,以及大量計算的工程應用進行加速。
-
統一計算設備架構(Compute Unified Device Architecture, CUDA)。隨著 GPU 的發展, GPU 開始主要為顯示圖像做優化,在計算上超越通用的 CPU。 NVIDIA 推出 CUDA這一通用并行計算架構,該架構使GPU能夠解決復雜的計算問題。
-
GPU 是大規模并行架構,擅長處理并行任務。GPU 的并行架構非常合適深度學習需要高效的矩陣操作和大量的卷積操作。
-
GPU的特性:高寬帶;高速緩存性能;并行單元多。
-
用 GPU來進行深度學習,在 L 1 L1 L1高速緩存中和 G P U GPU GPU的寄存器上存儲大量的數據,反復使用卷積操作和矩陣乘法操作,而不用擔心運算應度慢的問題。 假設有一個 100 M B 100MB 100MB的矩陣,根據寄存器的數量和高速緩存的大小把該矩陣分解成多個如 3 × 3 3×3 3×3的小矩陣,然后以 10 ? 80 T B / s 10-80TB/s 10?80TB/s的速度與一個三通道的 3 × 3 3×3 3×3的小矩陣相乘完成一次卷積操作。
-
對于深度學習的加速器GPU,初學者推薦使用 NVIDIA顯卡。英偉達公司押注人工智能與深度學習,GPU資源充分。CUDA平臺來說,其社區完善,很多開源解決方案為后續編程。
環境搭建
- 人工智能學習環境配置
主流深度學習框架對比
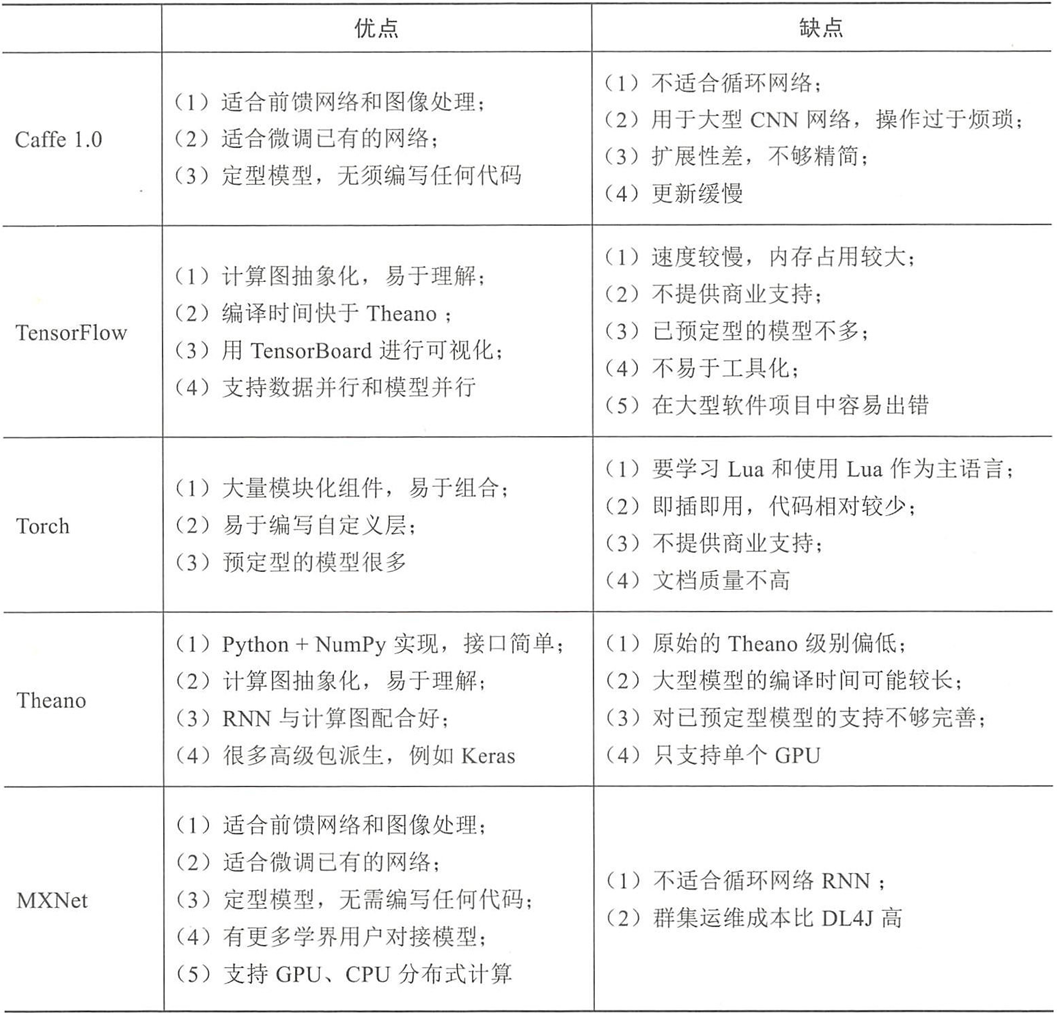
- 五大主流深度學習框架優缺點對比表
的多變量橋式起重機自適應安全制動與距離預測)

)



--- 銷量預估)





)

 : Fisk‘s proof)




