摘要:大型推理模型(LRMs),如OpenAI-o1和DeepSeek-R1,展示了令人印象深刻的長期推理能力。 然而,他們對靜態內部知識的依賴限制了他們在復雜的知識密集型任務上的表現,并阻礙了他們生成需要綜合各種網絡信息的綜合研究報告的能力。 為了解決這個問題,我們提出了WebThinker,這是一個深度研究代理,它使LRM能夠在推理過程中自主搜索網絡、瀏覽網頁和起草研究報告。 WebThinker集成了Deep Web Explorer模塊,使LRM能夠在遇到知識缺口時動態搜索、導航和提取網絡信息。 它還采用了自主思考、搜索和起草策略,使模型能夠實時無縫地交織推理、信息收集和報告撰寫。 為了進一步提高研究工具的利用率,我們通過迭代在線直接偏好優化(DPO)引入了一種基于RL的訓練策略。 在復雜推理基準(GPQA、GAIA、WebWalkerQA、HLE)和科學報告生成任務(Glaive)上的廣泛實驗表明,WebThinker的表現明顯優于現有方法和強大的專有系統。 我們的方法增強了LRM在復雜場景中的可靠性和適用性,為更強大、更通用的深度研究系統鋪平了道路。 代碼可在https://github.com/RUC-NLPIR/WebThinker上找到。Huggingface鏈接:Paper page,論文鏈接:2504.21776
研究背景和目的
研究背景
隨著人工智能技術的快速發展,大型推理模型(Large Reasoning Models, LRMs)在多個領域展現出了卓越的性能,尤其是在數學、代碼編寫和科學推理等方面。然而,這些模型在面對復雜的信息研究需求時,往往受限于其靜態的內部知識,難以進行深入的網絡信息檢索,并生成全面且準確的科學研究報告。傳統的檢索增強生成(Retrieval-Augmented Generation, RAG)技術雖然在一定程度上緩解了這一問題,但其固定的檢索和生成流程限制了LRMs與搜索引擎之間的深度交互,導致模型在探索更深層次的網絡信息時顯得力不從心。
當前,學術界和工業界迫切需要一種通用、靈活且開源的深度研究框架,以充分發揮LRMs在復雜現實世界問題解決中的潛力。特別是在知識密集型領域,如金融、科學和工程等,研究人員需要花費大量時間和精力進行信息收集,而一個能夠自主進行深度網絡探索和報告撰寫的系統將極大提升研究效率。
研究目的
本研究旨在提出WebThinker,一個完全由推理模型驅動的開源深度研究框架。WebThinker旨在賦予LRMs自主搜索網絡、瀏覽網頁并在推理過程中起草研究報告的能力。通過集成深度網絡探索模塊(Deep Web Explorer)和自主思考-搜索-起草策略(Autonomous Think-Search-and-Draft Strategy),WebThinker使LRM能夠在遇到知識缺口時動態地搜索、導航和提取網絡信息,并將信息收集、推理和報告撰寫無縫交織在一起。此外,本研究還通過基于強化學習(RL)的訓練策略,進一步優化LRMs對研究工具的利用,提升其在復雜推理任務和科學研究報告生成任務中的表現。
研究方法
1. 框架設計
WebThinker框架包含兩個主要模式:問題解決模式(Problem-Solving Mode)和報告生成模式(Report Generation Mode)。在問題解決模式下,LRM配備了一個深度網絡探索模塊,當遇到知識缺口時,可以自主發起網絡搜索,并通過點擊鏈接或按鈕瀏覽網頁,提取相關信息后再繼續推理。在報告生成模式下,LRM除了具備深度網絡探索能力外,還集成了起草、檢查和編輯報告的工具,使其能夠在思考和搜索的同時迭代地撰寫全面的研究報告。
2. 深度網絡探索模塊
深度網絡探索模塊是WebThinker的核心組件之一,它使LRM能夠動態地搜索、導航和提取網絡信息。該模塊由兩個基本工具組成:搜索引擎和導航工具。搜索引擎用于根據生成的查詢檢索網頁,而導航工具則用于與當前查看頁面上的元素(如鏈接或按鈕)進行交互。探索模塊通過內部的推理鏈決定是進一步搜索還是深入導航,最終生成一個簡潔的輸出,以解決主推理鏈中的知識缺口。
3. 自主思考-搜索-起草策略
在報告生成模式下,WebThinker采用了自主思考-搜索-起草策略,使LRM能夠在實時思考和搜索的同時撰寫報告。LRM利用起草工具為特定章節撰寫內容,利用檢查工具查看當前報告狀態,并利用編輯工具修改報告。這些工具由一個輔助的LLM實現,確保報告內容的全面性、連貫性和對新見解的適應性。
4. 強化學習訓練策略
為了進一步提升LRMs對研究工具的利用能力,本研究采用了基于在線直接偏好優化(DPO)的強化學習訓練策略。通過在大規模復雜推理和報告生成數據集上生成多樣化的推理軌跡,并利用這些軌跡構建偏好對,訓練LRM使其能夠根據偏好對優化其推理和工具使用策略。
研究結果
1. 復雜推理任務表現
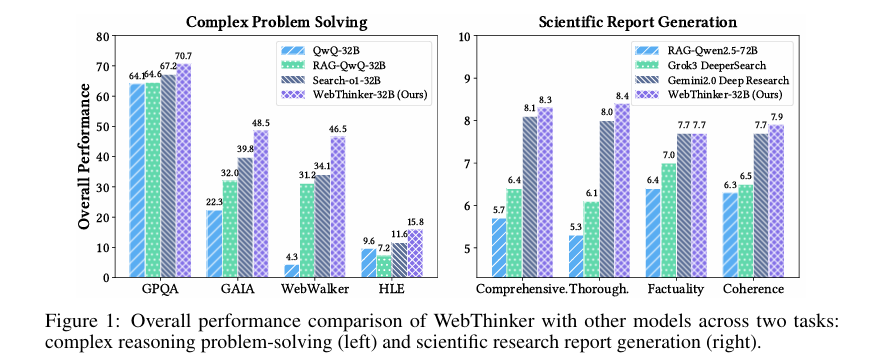
在復雜推理基準測試(如GPQA、GAIA、WebWalkerQA和HLE)上,WebThinker的表現顯著優于現有的方法和強大的專有系統。特別是在GAIA和WebWalkerQA等需要深度網絡信息檢索的任務上,WebThinker通過其深度網絡探索模塊和自主思考-搜索-起草策略,展現了卓越的性能。與傳統的RAG方法相比,WebThinker能夠更有效地利用網絡信息,生成更準確和全面的答案。
2. 科學研究報告生成表現
在科學研究報告生成任務(如Glaive)上,WebThinker同樣表現出色。通過迭代地撰寫、檢查和編輯報告章節,WebThinker生成的報告在完整性、透徹性、事實性和連貫性方面均優于現有的RAG系統和非專有深度研究系統。特別是其自主思考-搜索-起草策略,使LRM能夠在實時思考和搜索的同時撰寫報告,確保了報告內容的時效性和準確性。
3. 不同LRM骨干的適應性
本研究還驗證了WebThinker在不同LRM骨干上的適應性。通過在DeepSeek-R1系列模型(7B、14B和32B)上進行實驗,結果表明WebThinker能夠顯著提升這些模型在復雜推理和報告生成任務上的表現。這證明了WebThinker框架的通用性和有效性。
研究局限
盡管WebThinker在復雜推理和科學研究報告生成任務上取得了顯著成果,但本研究仍存在一些局限性:
-
計算資源需求:WebThinker的訓練和推理過程需要較高的計算資源,尤其是在處理大規模數據集和復雜推理任務時。這可能限制了其在資源有限環境中的應用。
-
模型幻覺問題:在報告生成過程中,LRM有時會產生與原文不符的幻覺內容。盡管本研究通過Needleman-Wunsch算法等后處理方法進行了一定的糾正,但這一問題仍未完全解決。
-
數據稀缺性:高質量、公開可用的變音阿拉伯語語料庫的稀缺性限制了Sadeed等模型在阿拉伯語變音符號標注任務上的進一步發展。類似地,對于WebThinker而言,特定領域的高質量數據集也可能成為其性能提升的瓶頸。
-
工具使用效率:盡管本研究通過強化學習訓練策略提升了LRMs對研究工具的利用能力,但在某些復雜任務上,工具的使用效率仍有待提高。例如,在深度網絡探索過程中,如何更有效地選擇搜索查詢和導航路徑仍是一個挑戰。
未來研究方向
針對WebThinker的局限性和當前研究的不足,未來的研究可以從以下幾個方面展開:
-
優化計算資源利用:探索更高效的算法和模型架構,以減少WebThinker在訓練和推理過程中的計算資源需求。例如,可以通過模型剪枝、量化或知識蒸餾等技術來減小模型大小,提高推理速度。
-
減少模型幻覺:研究更有效的后處理方法或訓練策略,以減少LRM在報告生成過程中產生的幻覺內容。例如,可以引入更嚴格的驗證機制或利用外部知識庫來驗證生成內容的準確性。
-
構建高質量數據集:針對特定領域構建高質量的數據集,以進一步提升WebThinker在復雜推理和報告生成任務上的性能。例如,可以與領域專家合作,收集和標注特定領域的高質量問答對和報告樣本。
-
提升工具使用效率:研究更智能的工具選擇和使用策略,以提高LRM在深度網絡探索過程中的效率。例如,可以利用強化學習或元學習等技術來訓練LRM,使其能夠根據任務需求自動選擇最合適的搜索查詢和導航路徑。
-
多模態推理能力:探索將WebThinker擴展到多模態領域,使其能夠處理圖像、視頻等非文本信息。這將使WebThinker在更廣泛的場景中發揮作用,如多媒體信息檢索、視覺問答等。
-
用戶交互與反饋:研究如何更好地將用戶交互和反饋融入WebThinker的推理過程中。例如,可以通過用戶反饋來不斷優化LRM的推理策略和工具使用方式,提高系統的個性化和適應性。
綜上所述,WebThinker作為一個完全由推理模型驅動的開源深度研究框架,在復雜推理和科學研究報告生成任務上展現出了卓越的性能。未來的研究將致力于進一步優化其性能、擴展其應用場景,并解決當前存在的局限性。


--- 銷量預估)





)

 : Fisk‘s proof)







和鴻蒙arktsrequest.uploadFile)
