【MATLAB第118期】基于MATLAB的雙通道CNN多輸入單輸出分類預測方法
一、雙通道CNN簡介
在深度學習領域,卷積神經網絡(CNN)憑借其強大的特征提取能力,已成為圖像識別、自然語言處理等任務的核心技術。傳統單通道CNN在處理單一模態數據時表現出色,但在面對多源異構數據時往往力不從心。雙通道CNN分類預測方法通過引入并行特征學習機制,開創性地實現了多維度信息融合,為復雜場景下的智能決策提供了新思路。
1、案例數據
本位使用案例數據輸入特征變量為12個,四分類。?將12維特征分為兩組(前6維和后6維),對應不同來源或類型的特征,將每個通道使用獨立的卷積網絡提取局部特征?,通過拼接(concatenation)整合雙通道信息,增強特征表達能力。雙通道CNN架構示意圖如下,雙通道架構包含兩個獨立特征提取分支與融合模塊。
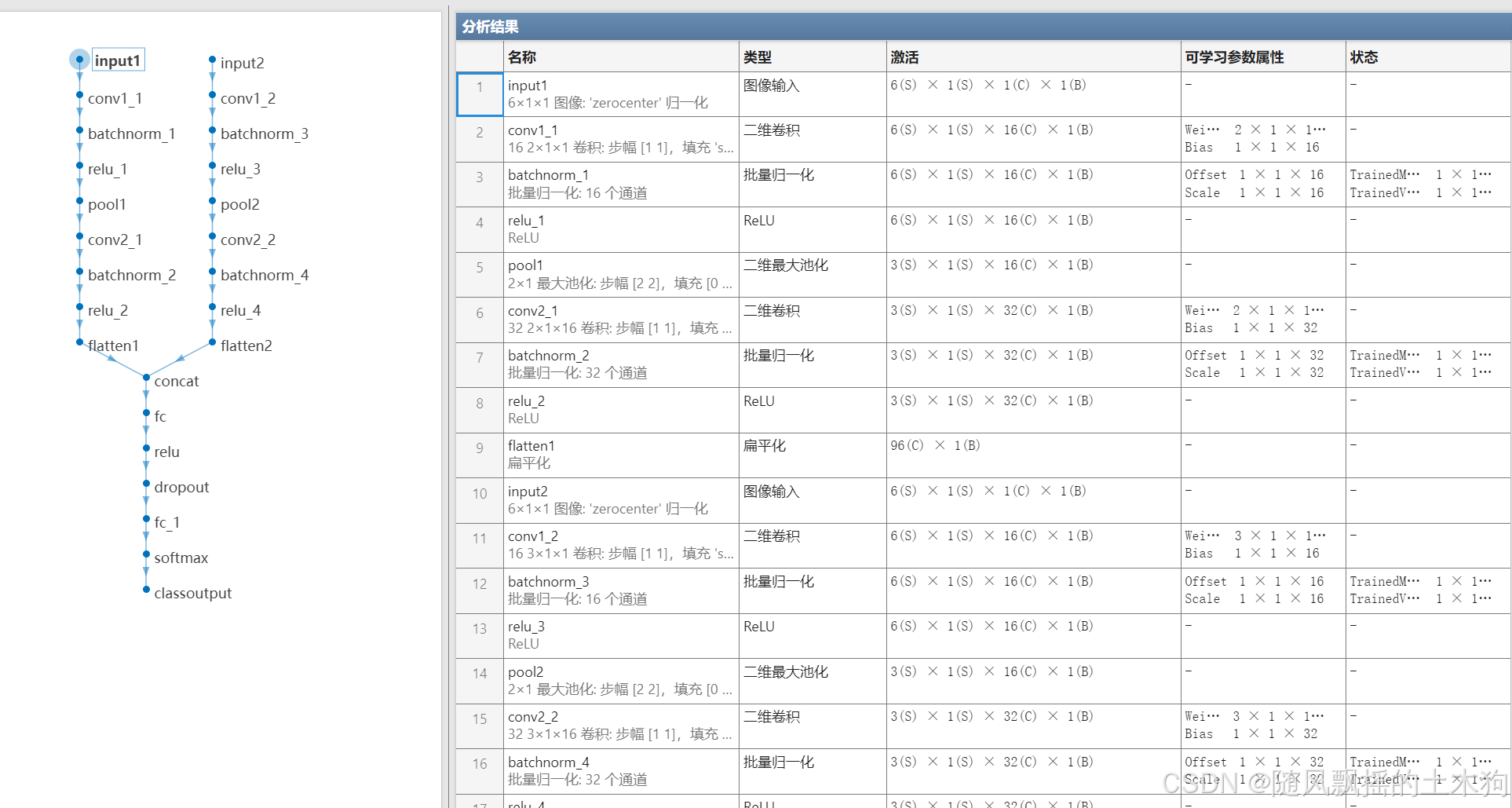
2. 網絡結構特點
?分支結構差異?:
通道1使用2x1卷積核,適合捕捉短距離特征模式
通道2使用3x1卷積核,適合捕捉較長距離的依賴關系
?參數共享?:各通道獨立訓練,避免特征混淆
?融合策略?:拼接(而非相加)保留更多原始特征信息
3. 性能優化措施
?歸一化處理?:各通道獨立歸一化,消除量綱差異
?正則化?:L2正則化(1e-4) + Dropout(0.5) 防止過擬合
?動態學習率?:初始學習率1e-3,每40輪衰減為原來的0.1倍
程,實現了對復雜特征組合的有效建模,在保持較高參數效率的同時提升了模型表達能力。
二、部分代碼展示
%% 環境初始化
clc; clear; close all; % 清除命令窗口、工作區變量和關閉所有圖形窗口
warning off % 關閉警告提示%% 數據加載與預處理(示例數據集)
% 生成演示數據(替換為實際數據)
res = xlsread("分類數據集.xlsx"); % 讀取Excel格式的分類數據集
numSamples = size(res,1); % 獲取樣本總數data = res(:,1:end-1); % 提取前12列作為特征數據(12維特征)
labels = res(:,end); % 最后一列作為分類標簽%% 數據集劃分
rng(0); % 固定隨機種子保證結果可復現
% 使用dividerand函數按7:3比例劃分訓練集和測試集
[trainInd,testInd] = dividerand(size(data,1),0.7,0.3);% 通道分離:將12維特征分為兩個6維通道
trainData1 = data(trainInd,1:6)'; % 通道1特征(訓練集,轉置為行向量)
trainData2 = data(trainInd,7:12)';% 通道2特征
testData1 = data(testInd,1:6)'; % 測試集通道1
testData2 = data(testInd,7:12)'; % 測試集通道2% 標簽處理:轉換為分類數據類型
t_train = categorical(labels(trainInd))'; % 訓練標簽
t_test = categorical(labels(testInd))'; % 測試標簽%% 數據歸一化(雙通道獨立歸一化)
% 使用mapminmax進行[0,1]歸一化,保持通道獨立性
[tr1, ps1] = mapminmax(trainData1, 0, 1); % 通道1訓練集歸一化
[tr2, ps2] = mapminmax(trainData2, 0, 1); % 通道2訓練集歸一化
ts1 = mapminmax('apply', testData1, ps1); % 應用通道1的歸一化參數到測試集
ts2 = mapminmax('apply', testData2, ps2); % 應用通道2的歸一化參數%% 數據重塑(適應雙通道輸入)
% 調整維度順序為 [特征數, 高度, 通道數, 樣本數]
p_train1 = reshape(tr1,6,1,1,[]); % 重塑為4D數組(6個特征,單通道)
p_train2 = reshape(tr2,6,1,1,[]);
p_test1 = reshape(ts1,6,1,1,[]);
p_test2 = reshape(ts2,6,1,1,[]);% 創建標簽數據存儲
labelsTrain = categorical(labels(trainInd));
labelDs = arrayDatastore(labelsTrain);% 驗證集構建同理
labelsTest = categorical(labels(testInd));
valLabelDs = arrayDatastore(labelsTest;%% 雙通道網絡架構
% 通道1支路(使用2x1卷積核)
branch1 = [imageInputLayer([6 1 1], 'Name','input1') % 輸入層:6個特征,單通道convolution2dLayer([2 1],16,'Padding','same','Name','conv1_1') % 2x1卷積核batchNormalizationLayer % 批量歸一化reluLayer % 激活函數maxPooling2dLayer([2 1],'Stride',2,'Name','pool1') % 最大池化convolution2dLayer([2 1],32,'Padding','same','Name','conv2_1') batchNormalizationLayerreluLayerflattenLayer('Name','flatten1')]; % 展平層用于特征融合% 通道2支路(使用3x1卷積核)
branch2 = [imageInputLayer([6 1 1], 'Name','input2')convolution2dLayer([3 1],16,'Padding','same','Name','conv1_2') batchNormalizationLayerreluLayermaxPooling2dLayer([2 1],'Stride',2,'Name','pool2')convolution2dLayer([3 1],32,'Padding','same','Name','conv2_2')batchNormalizationLayerreluLayerflattenLayer('Name','flatten2')];% 分類頭部
fullConn = [fullyConnectedLayer(64, 'Name', 'fc') % 全連接層reluLayerdropoutLayer(0.5) % 隨機失活防止過擬合fullyConnectedLayer(numel(categories(t_train))) % 輸出層(類別數)softmaxLayerclassificationLayer]; % 分類輸出層%% 網絡連接
lgraph = layerGraph();
lgraph = addLayers(lgraph, branch1);
lgraph = addLayers(lgraph, branch2);%% 訓練參數設置
options = trainingOptions('adam',...'MaxEpochs',500,... % 最大訓練輪次'InitialLearnRate',1e-3,... % 初始學習率'LearnRateSchedule','piecewise',... % 分段學習率策略'LearnRateDropFactor',0.1,... % 學習率衰減因子'LearnRateDropPeriod',40,... % 每40輪衰減一次'ValidationData',valDs,... % 驗證數據集'ValidationFrequency',30,... % 每30次迭代驗證一次'L2Regularization',1e-4,... % L2正則化系數'Shuffle','every-epoch',... % 每輪打亂數據'OutputNetwork','best-validation-loss',... % 保存最佳模型'Verbose',true); % 顯示訓練過程%% 網絡訓練
[net,traininfo] = trainNetwork(trainDs, lgraph, options);%% 測試集預測
preds = classify(net, testCombined); % 執行預測
accuracy = mean(preds == labelsTest); % 計算準確率
fprintf('測試集準確率: %.2f%%\n', accuracy*100);%% 結果可視化
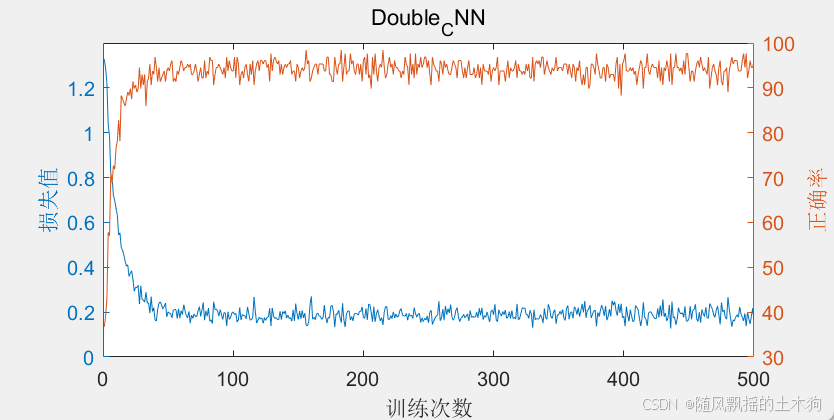
figure();
yyaxis left;
plot(traininfo.TrainingLoss); % 繪制訓練損失曲線
title('Double_CNN');
xlabel('訓練次數');
ylabel('損失值');
yyaxis right;
plot(traininfo.TrainingAccuracy); % 繪制訓練準確率曲線
ylabel('正確率');% 預測結果對比
YTest = double(labelsTest);
YPred = double(preds);
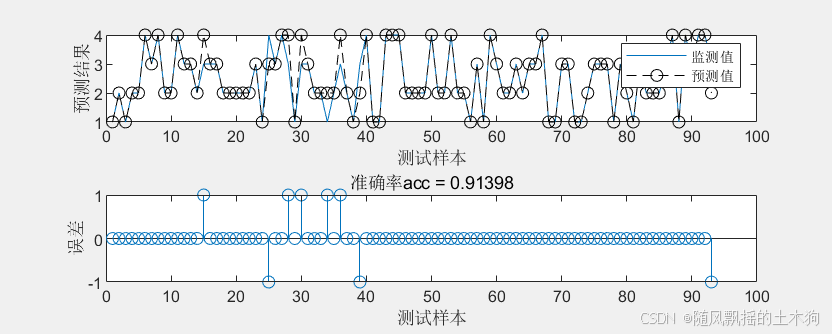
figure()
subplot(2,1,1)
plot(YTest)
hold on
plot(YPred,'--ok') % 繪制預測值與真實值對比
legend(["監測值" "預測值"])
xlabel("測試樣本")
ylabel("預測結果")subplot(2,1,2)
stem(YPred - YTest) % 繪制預測誤差
xlabel("測試樣本")
ylabel("誤差")
title("準確率acc = " + accuracy)
三、代碼獲取
1.閱讀首頁置頂文章
2.關注CSDN
3.根據自動回復消息,回復“118期”以及相應指令,即可獲取對應下載方式。




:原理、應用與實戰)





個人效率)








