目錄
【實驗目的】
【實驗原理】
【實驗環境】
【實驗步驟】
一、安裝Python所需要的第三方模塊
二、實驗
【實驗總結】
【實驗目的】
????????1.掌握關系數據在大數據中的應用
????????2.掌握關系數據可視化方法
????????3. python 程序實現圖表
【實驗原理】
????????在傳統的觀念里面,一般都是致力于尋找一切事情發生的背后的原因。現在要做的是嘗試著探索事物的相關關系,而不再關注難以捉摸的因果關系。這種相關性往往不能告訴讀者事物為何產生,但是會給讀者一個事物正在發生的提醒。關系數據很容易通過數據進行驗證的,也可以通過圖表呈現,然后引導讀者進行更加深入的研究和探討。分析數據的時候,可以從整體進行觀察,或者關注下數據的分布。數據間是否存在重疊或者是否毫不相干?也可以更寬的角度觀察各個分布數據的相關關系。其實最重要的一點,就是數據進行可視化后,呈現眼前的圖表,它的意義何在。是否給出讀者想要的信息還是結果讓讀者大吃一驚?
????????就關系數據中的關聯性,分布性。進行可視化,有散點圖,直方圖,密度分布曲線,氣泡圖,散點矩陣圖等等。本次試驗主要是直方圖,密度圖,散點圖。直方圖是反應數據的密集程1度,是數據分布范圍的描述,與莖葉圖類似,但是不會具體到某一個值,是一個整體分布的描述。密度圖可以了解到數據分布的密度情況。密度圖可以了解到數據分布的密度情況。散點圖將序列顯示為一組點。值由點在圖表中的位置表示。散點圖通常用于比較跨類別的聚合數據。
【實驗環境】
????????OS:Windows
????????python:v3.6
【實驗步驟】
數據源:

一、安裝Python所需要的第三方模塊
pip install seaborn二、實驗
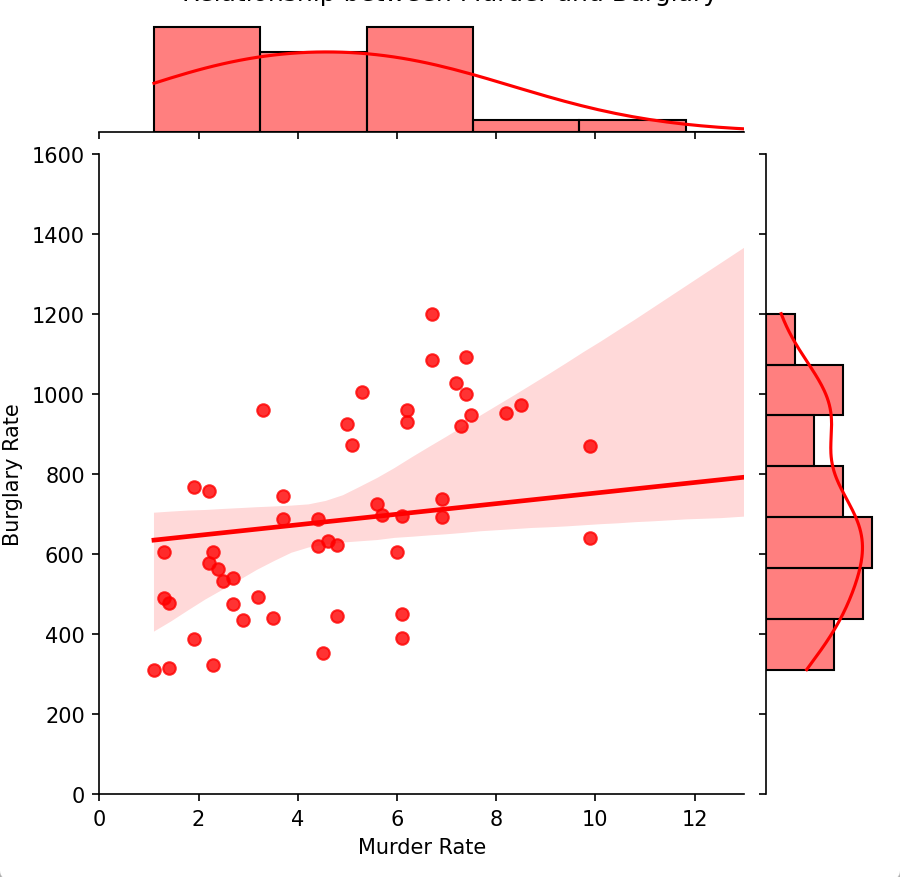
import seaborn as sns
import pandas as pd
import matplotlib.pyplot as plt# 讀取數據
df = pd.read_csv(r"crimeRatesByState2005.csv")# 使用jointplot繪制圖表并設置顏色
g = sns.jointplot(data=df, x='murder', y='burglary', kind='reg', color='red')# 設置圖表標題和軸標簽
g.fig.suptitle('Relationship between Murder and Burglary', y=1.02)
g.set_axis_labels('Murder Rate', 'Burglary Rate')# 設置橫坐標和縱坐標的最大值
g.ax_joint.set_xlim(0, 13)
g.ax_joint.set_ylim(0, 1600)# 顯示圖表
plt.show()
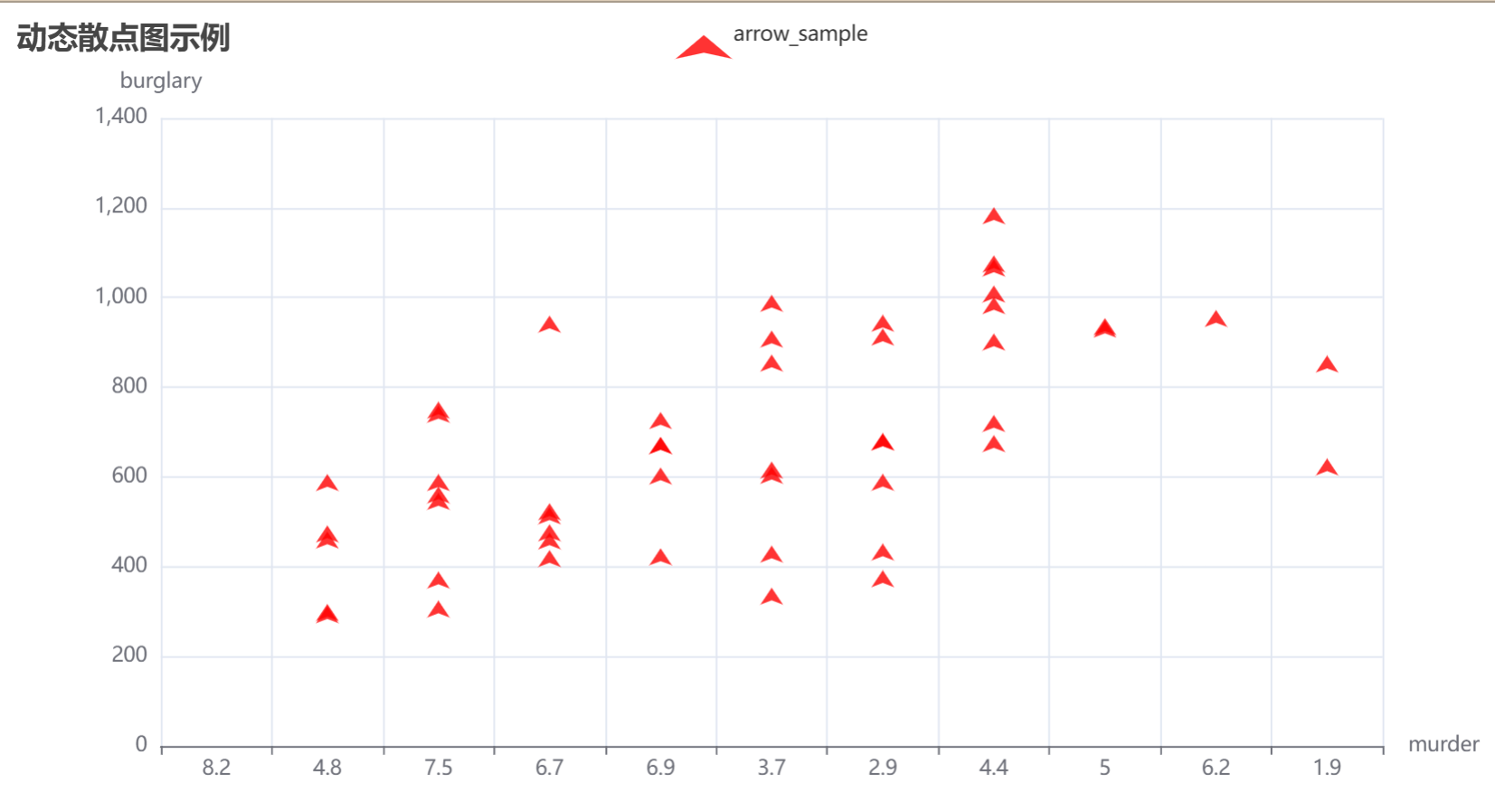
2.動態散點圖
from pyecharts import options as opts
from pyecharts.charts import Scatter
import pandas as pd# 數據加載和預處理函數
def load_and_process_data(file_path):# 讀取數據crime = pd.read_csv(file_path)# 篩選數據,去除 "United States" 和 "District of Columbia"crime_filtered = crime[(crime.state != "United States") & (crime.state != "District of Columbia")]return crime_filtered# 創建 Scatter 圖表函數
def create_scatter_plot(data):# 創建 Scatter 圖表scatter = (Scatter().add_xaxis(data['murder'].tolist()) # 使用 "murder" 列作為 x 軸.add_yaxis("arrow_sample",data['burglary'].tolist(), # 使用 "burglary" 列作為 y 軸symbol="arrow", # 設置為箭頭形狀label_opts=opts.LabelOpts(is_show=False), # 不顯示標簽itemstyle_opts=opts.ItemStyleOpts(color="red") # 設置散點顏色為紅色).set_global_opts(title_opts=opts.TitleOpts(title="動態散點圖示例"),xaxis_opts=opts.AxisOpts(name="murder", min_=0, max_=10), # 設置 x 軸范圍yaxis_opts=opts.AxisOpts(name="burglary") # 設置 y 軸名稱))return scatter# 主程序入口
def main():# 加載和處理數據file_path = "crimeRatesByState2005.csv" # 文件路徑crime_data = load_and_process_data(file_path)# 創建散點圖并渲染scatter_plot = create_scatter_plot(crime_data)scatter_plot.render("scatter_effect.html") # 渲染并保存為 HTML 文件# 執行主程序
if __name__ == "__main__":main()
3、請使用矩陣圖表示數據集中七種犯罪類型之間的相關關系(提示:請剔除 United States 和 District of Columbia 兩行表示均值和異常的數據),效果如下:
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt# 修改文件地址
df = pd.read_csv(r"crimeRatesByState2005.csv")# 剔除 United States 和 District of Columbia 兩行數據
df = df[(df['state'] != 'United States') & (df['state'] != 'District of Columbia')]# 選擇七種犯罪類型的數據
crime_types = ['murder', 'forcible_rape', 'robbery', 'aggravated_assault', 'burglary', 'larceny_theft','motor_vehicle_theft']
df_crime = df[crime_types]# 設置中文字體為黑體(解決中文顯示問題,需確保系統已安裝黑體字體)
plt.rcParams['font.sans-serif'] = ['SimHei']# 解決負號顯示問題
plt.rcParams['axes.unicode_minus'] = False# 設置圖形大小
plt.figure(figsize=(12, 12))# 創建散點圖矩陣,去掉 corner 參數以顯示對角線以上的散點圖,并設置顏色為紫色
g = sns.pairplot(df_crime, plot_kws={'color': 'red'})# 設置圖形標題
g.fig.suptitle('七種犯罪類型之間的相關關系', y=1.02)# 調整子圖布局
plt.tight_layout()# 顯示圖形
plt.show()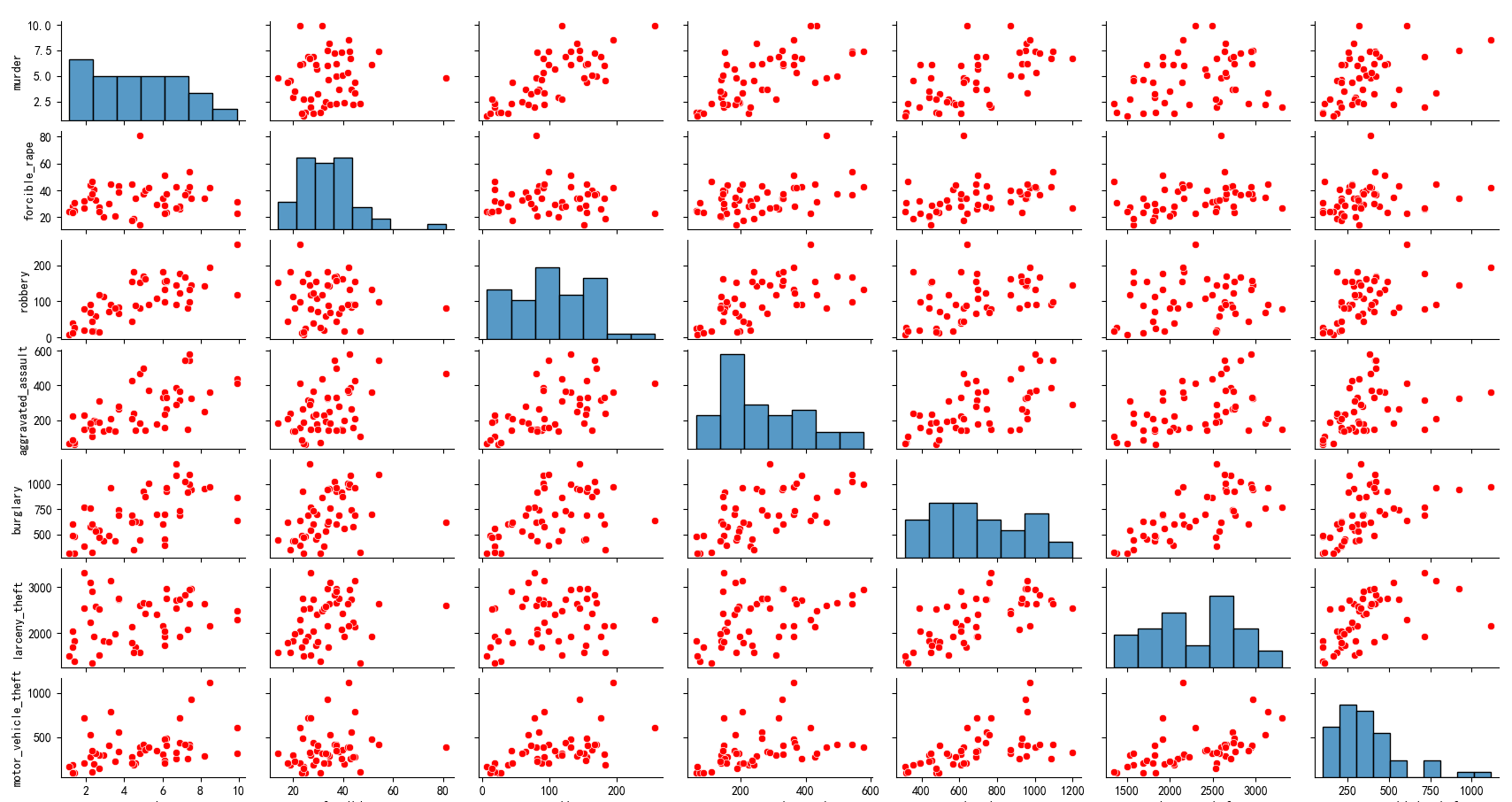
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA# 讀取數據
df = pd.read_csv('crimeRatesByState2005.csv')# 剔除 United States 和 District of Columbia 兩行數據
df = df[(df['state'] != 'United States') & (df['state'] != 'District of Columbia')]# 提取犯罪類型數據列
crime_cols = ['murder', 'forcible_rape', 'robbery', 'aggravated_assault', 'burglary', 'larceny_theft','motor_vehicle_theft']
crime_data = df[crime_cols]# 數據標準化
scaler = StandardScaler()
scaled_data = scaler.fit_transform(crime_data)# 進行主成分分析
pca = PCA(n_components=2)
principal_components = pca.fit_transform(scaled_data)# 繪制雙標圖
fig, ax = plt.subplots(figsize=(10, 8))# 繪制樣本點
ax.scatter(principal_components[:, 0], principal_components[:, 1], alpha=0.5)# 繪制變量箭頭
loadings = pca.components_.T * np.sqrt(pca.explained_variance_)
for i, feature in enumerate(crime_cols):ax.arrow(0, 0, loadings[i, 0], loadings[i, 1], color='r', alpha=0.5, head_width=0.1)ax.text(loadings[i, 0] * 1.15, loadings[i, 1] * 1.15, feature, color='g', ha='center', va='center')# 設置標題和坐標軸標簽
ax.set_title('Biplot of Seven Crime Types')
ax.set_xlabel('Principal Component 1')
ax.set_ylabel('Principal Component 2')# 顯示圖形
plt.show()
代碼解釋:
- 數據讀取與預處理:使用?
pandas?的?read_csv?函數讀取 CSV 文件,并通過布爾索引過濾掉?United States?和?District of Columbia?兩行數據。 - 提取犯罪類型數據:從數據集中選取七種犯罪類型對應的列。
- 數據標準化:使用?
StandardScaler?對數據進行標準化處理,消除量綱影響。 - 主成分分析:使用?
PCA?進行主成分分析,將數據降維到二維(n_components=2)。 - 繪制雙標圖
- 繪制樣本點:將樣本投影到前兩個主成分上并繪制散點圖。
- 繪制變量箭頭:根據主成分的載荷繪制變量箭頭,箭頭的方向和長度表示變量在主成分上的貢獻,箭頭之間的夾角反映變量之間的相關性。
- 設置標題和坐標軸標簽:為圖形添加標題和坐標軸標簽,增強可讀性。
- 顯示圖形:使用?
plt.show()?顯示繪制好的圖形。
運行結果:
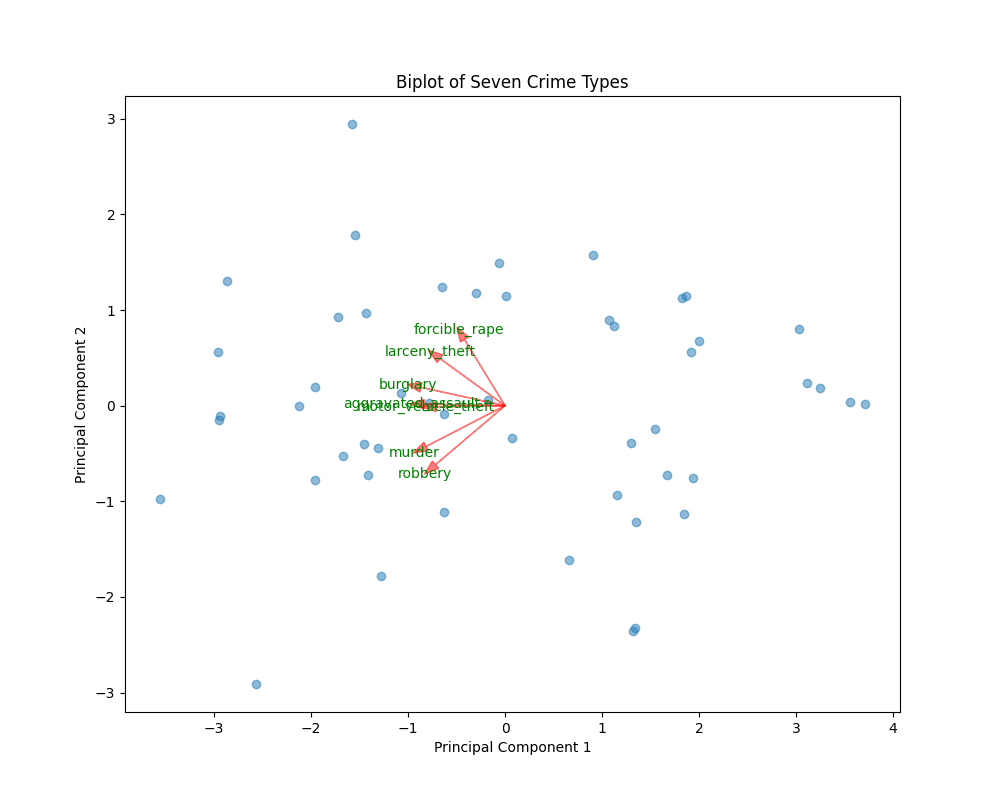
????????運行代碼后,會彈出一個圖形窗口,展示七種犯罪類型的雙標圖。圖中包含樣本點和變量箭頭。樣本點的分布展示了不同樣本在主成分上的分布情況;變量箭頭的方向和長度反映了變量對主成分的貢獻,箭頭之間的夾角越小,說明變量之間的相關性越強。通過觀察雙標圖,可以直觀地探究七種犯罪類型之間的相關關系。
(2)雷達圖
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt# 讀取數據
df = pd.read_csv('crimeRatesByState2005.csv')# 剔除 United States 和 District of Columbia 兩行數據
df = df[(df['state'] != 'United States') & (df['state'] != 'District of Columbia')]# 提取犯罪類型數據列
crime_cols = ['murder', 'forcible_rape', 'robbery', 'aggravated_assault', 'burglary', 'larceny_theft','motor_vehicle_theft']
crime_data = df[crime_cols]# 計算各犯罪類型的均值
mean_values = crime_data.mean().values# 犯罪類型數量
num_vars = len(crime_cols)# 角度
angles = np.linspace(0, 2 * np.pi, num_vars, endpoint=False).tolist()
angles += angles[:1]# 均值數據添加最后一個值以閉合圖形
mean_values = np.concatenate((mean_values, [mean_values[0]]))# 創建畫布
fig, ax = plt.subplots(figsize=(6, 6), subplot_kw=dict(polar=True))# 繪制雷達圖
ax.plot(angles, mean_values, color='b', linewidth=1)
ax.fill(angles, mean_values, color='b', alpha=0.25)# 設置坐標軸標簽
ax.set_xticks(angles[:-1])
ax.set_xticklabels(crime_cols)# 設置標題
ax.set_title('Radar Chart of Seven Crime Types', y=1.1)# 顯示圖形
plt.show()代碼解釋:
-
數據讀取與預處理:借助?
pandas?的?read_csv?函數讀取 CSV 文件,并且通過布爾索引把?United States?和?District of Columbia?兩行數據過濾掉。 -
提取犯罪類型數據:從數據集中選取七種犯罪類型對應的列。
-
計算均值:計算每種犯罪類型的均值,從而在雷達圖里展示整體的情況。
-
確定角度:為了在雷達圖上合理分布各個犯罪類型,計算每個犯罪類型對應的角度。
-
繪制雷達圖:使用?
matplotlib?的?plot?函數繪制折線,使用?fill?函數對圖形進行填充。 -
設置坐標軸標簽和標題:為雷達圖添加坐標軸標簽和標題,增強可讀性。
-
顯示圖形:使用?
plt.show()?顯示繪制好的圖形。
運行結果:
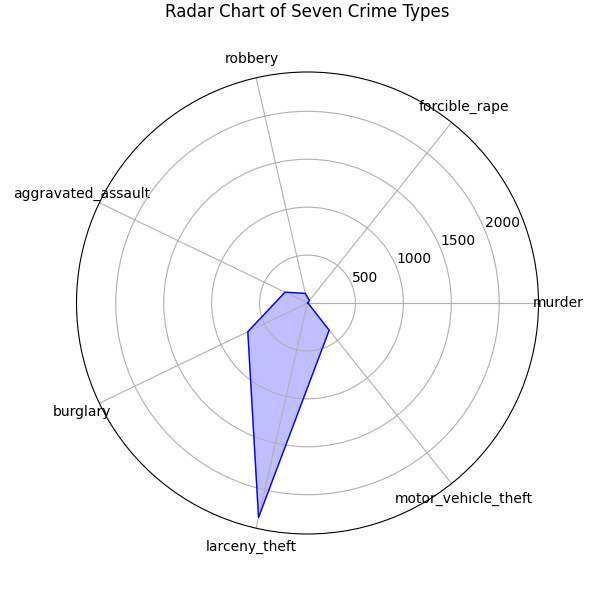
????????運行代碼之后,會彈出一個圖形窗口,展示七種犯罪類型的雷達圖。在雷達圖中,每個坐標軸代表一種犯罪類型,而多邊形的頂點則表示該犯罪類型的均值。通過觀察多邊形的形狀和各個頂點的位置,能夠直觀地對比不同犯罪類型之間的數值大小和相對關系。
(3)熱力圖
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
from scipy.stats import pearsonr
from matplotlib.colors import LinearSegmentedColormapdef create_correlation_matrix():# 讀取數據df = pd.read_csv('crimeRatesByState2005.csv')# 剔除 United States 和 District of Columbia 兩行數據df = df[(df['state'] != 'United States') & (df['state'] != 'District of Columbia')]# 提取犯罪類型數據列crime_cols = ['murder', 'forcible_rape', 'robbery', 'aggravated_assault', 'burglary', 'larceny_theft','motor_vehicle_theft']crime_data = df[crime_cols]# 數據標準化scaler = StandardScaler()scaled_data = scaler.fit_transform(crime_data)# 計算相關系數矩陣corr_matrix = np.zeros((len(crime_cols), len(crime_cols)))for i in range(len(crime_cols)):for j in range(len(crime_cols)):corr, _ = pearsonr(scaled_data[:, i], scaled_data[:, j])corr_matrix[i, j] = corr# 生成自定義顏色映射,從藍色到白色再到紅色cmap = LinearSegmentedColormap.from_list('custom_cmap', ['blue', 'white','red'])# 繪制矩陣圖plt.figure(figsize=(10, 8))plt.imshow(corr_matrix, cmap=cmap, vmin=-1, vmax=1)plt.xticks(range(len(crime_cols)), crime_cols, rotation=45, ha='right')plt.yticks(range(len(crime_cols)), crime_cols)plt.colorbar(label='Correlation Coefficient')plt.title('Correlation Matrix of Crime Types')# 在矩陣圖中添加相關系數數值for i in range(len(crime_cols)):for j in range(len(crime_cols)):plt.text(j, i, f'{corr_matrix[i, j]:.2f}', ha='center', va='center', color='black' if abs(corr_matrix[i, j]) < 0.7 else 'white')plt.tight_layout()plt.show()if __name__ == "__main__":create_correlation_matrix()
代碼解釋:
-
數據讀取與預處理:使用?
pandas?的?read_csv?函數讀取 CSV 文件,然后通過布爾索引過濾掉?United States?和?District of Columbia?兩行數據。 -
提取犯罪類型數據:從數據集中選取七種犯罪類型對應的列。
-
繪制散點圖矩陣:使用?
seaborn?的?pairplot?函數繪制散點圖矩陣,該矩陣會展示每兩種犯罪類型之間的散點圖,同時在對角線上顯示各犯罪類型的單變量分布(通常是直方圖)。 -
設置標題:為整個散點圖矩陣添加標題。
-
顯示圖形:使用?
plt.show()?顯示繪制好的圖形。
運行結果:

????????運行代碼后,會彈出一個圖形窗口,展示七種犯罪類型之間的散點圖矩陣。通過觀察散點圖的分布,可以直觀地了解不同犯罪類型之間的關系。如果散點呈現出某種線性趨勢,說明這兩種犯罪類型可能存在一定的相關性;如果散點比較分散,則說明相關性較弱。對角線上的直方圖可以展示每種犯罪類型的分布情況。
【實驗總結】
????????本次實驗圍繞關系數據在大數據中的應用及可視化展開,通過多種Python程序實現的圖表,深入探究了犯罪類型數據之間的關系。 在實驗過程中,首先利用seaborn模塊的jointplot方法,將散點圖、密度分布圖和直方圖結合,對謀殺(murder)和入室盜竊(burglary)兩種犯罪類型的關系進行探究。這種可視化方式從多個角度展示了數據的分布和相關性,直觀呈現出兩種犯罪類型在不同維度下的特征,為進一步分析提供了基礎。 接著,運用pyecharts創建動態散點圖,不僅展示了謀殺和入室盜竊數據的分布,還通過箭頭形狀和交互功能,使數據可視化更具動態性和趣味性,增強了對數據的理解和探索性。 針對七種犯罪類型之間的關系,分別使用散點圖矩陣、主成分分析雙標圖、雷達圖和熱力圖進行可視化。散點圖矩陣展示了各犯罪類型兩兩之間的散點分布,幫助觀察變量之間的潛在關系。主成分分析雙標圖通過降維,將高維數據在二維平面上展示,樣本點和變量箭頭的結合,直觀反映了變量對主成分的貢獻以及變量之間的相關性。雷達圖則以獨特的方式,將七種犯罪類型的均值在同一圖表中呈現,方便對比不同犯罪類型的數值大小和相對關系。 通過這些實驗,掌握了多種關系數據可視化方法,深入理解了不同圖表在展示數據關系時的特點和優勢。同時,也學會了運用Python中的pandas、seaborn、sklearn、matplotlib和pyecharts等庫進行數據處理和圖表繪制,提升了數據處理和可視化的實踐能力。?


)
















)