完整內容請看文章最下面的推廣群
我將先給出文章、代碼、結果的完整展示, 再給出四個問題詳細的模型

面向音頻質量優化與存儲效率提升的自適應編碼與去噪模型研究
摘 要
隨著數字媒體技術的迅速發展,音頻處理技術在信息時代的應用愈加廣泛,特別是在存儲優化與噪聲去除方面。為了在保證音質的前提下實現音頻文件的高效存儲和傳輸,本文提出了基于數學建模的音頻格式評估模型、音頻參數優化模型、自適應編碼方案以及自適應去噪算法。
對于問題一:聚焦于設計一個綜合評價指標,用于量化不同音頻格式(如WAV、MP3、AAC)在存儲效率與音質保真度之間的平衡。模型通過對比文件大小、音質損失(RMSE與SNR)、編解碼復雜度以及適用場景等多個維度,計算綜合得分,并根據不同應用場景推薦最佳音頻格式。通過歸一化和加權平均方法,該模型為用戶提供了一個合理的音頻格式選擇依據。例如,流媒體傳輸更適合選擇MP3 320kbps格式,而專業錄音則推薦使用無損的WAV格式。此模型幫助用戶在各種環境中平衡存儲需求和音質要求。
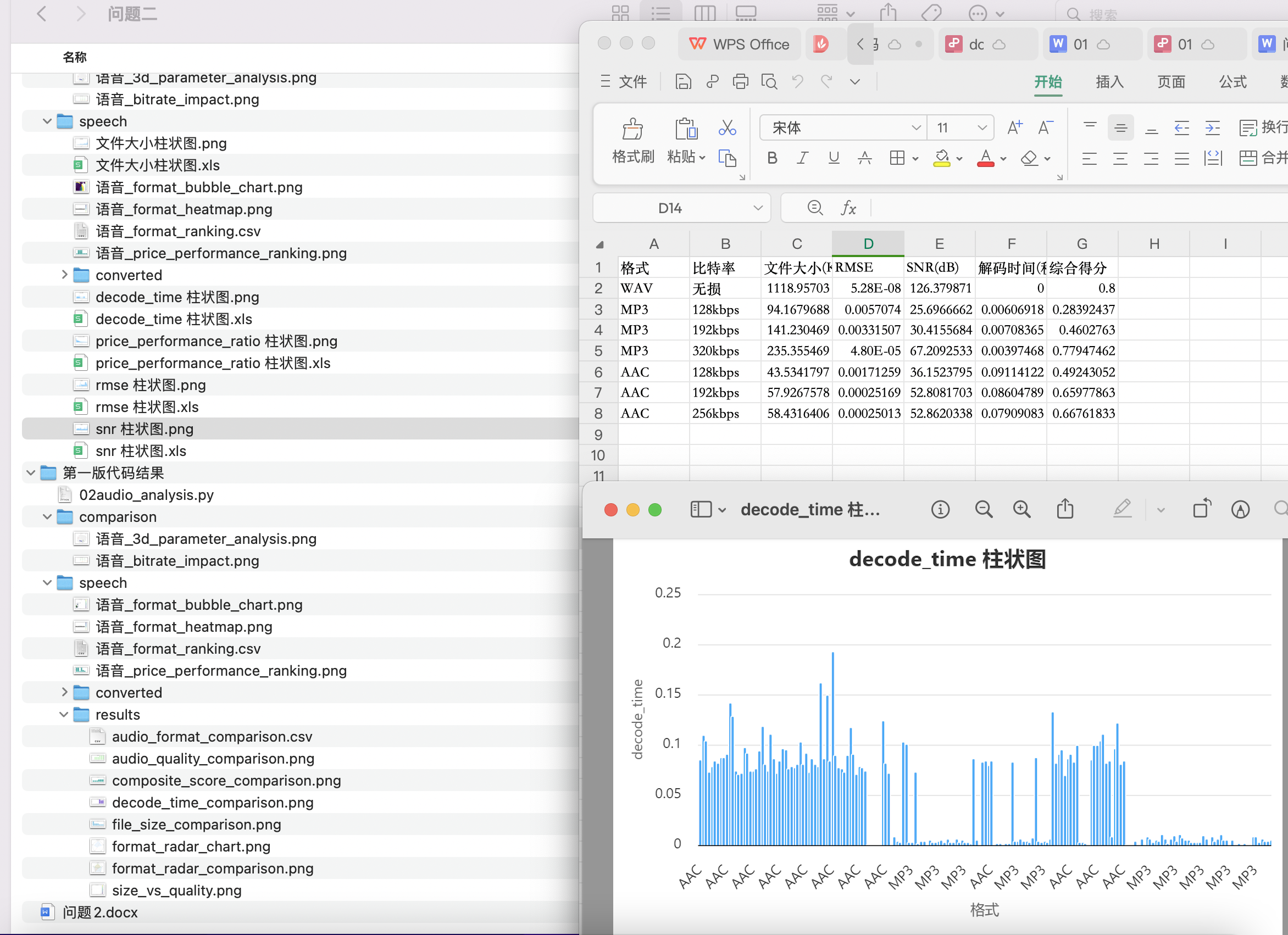
對于問題二:問題二要求分析音頻參數(如采樣率、比特深度、壓縮算法)對音頻質量和文件大小的影響,并設計音頻文件的性價比指標。通過計算RMSE和SNR等音質指標,結合文件大小與壓縮算法,模型通過性價比評分量化了音頻質量與文件大小之間的平衡。在語音內容中,較低的比特率如MP3 128kbps或AAC 128kbps能夠有效提供較好的質量并減小文件大小;而音樂內容則推薦使用MP3 320kbps或AAC 256kbps格式,以獲得更好的音質與壓縮率平衡。此模型為用戶提供了在不同音頻內容下最佳的音頻參數選擇方案。
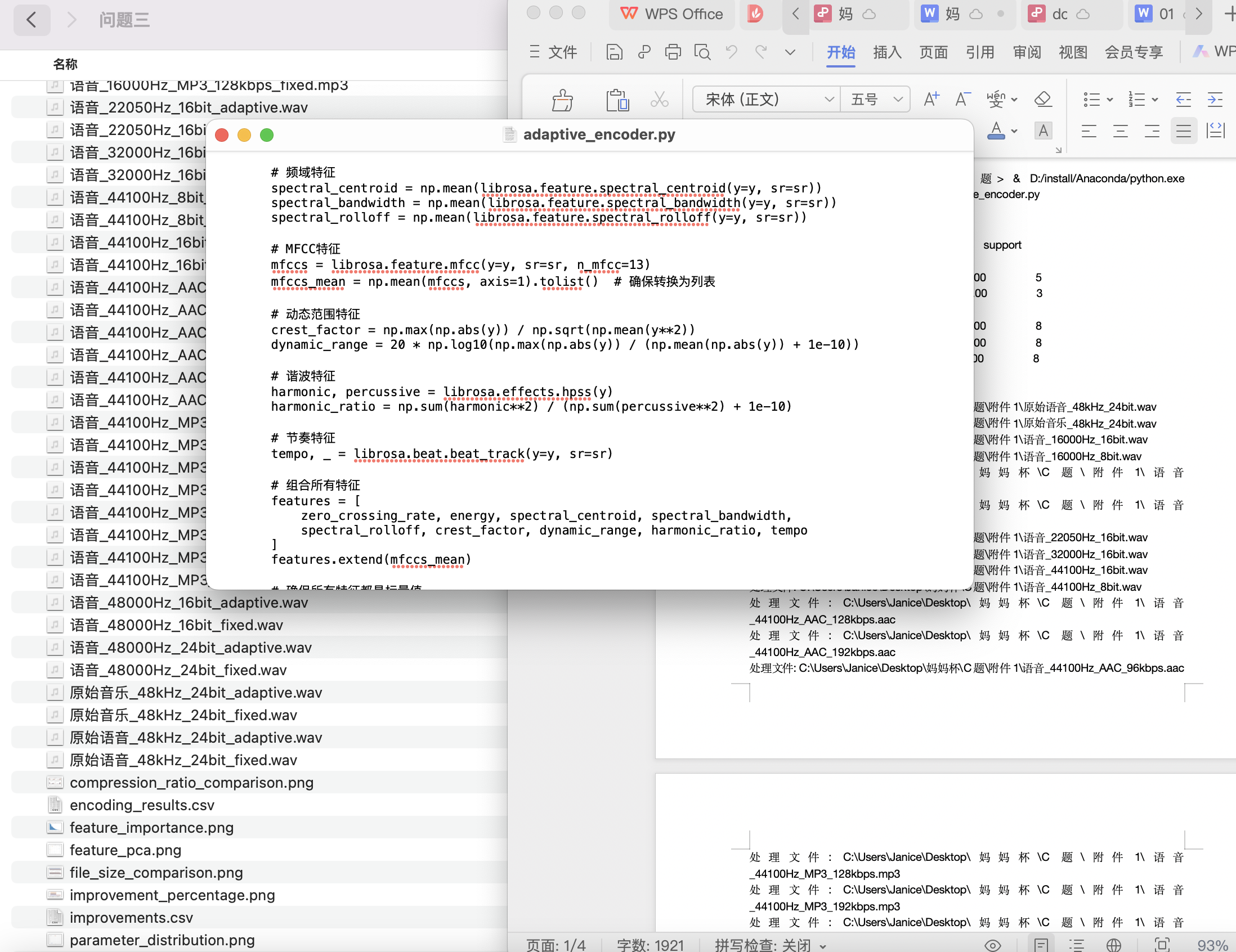
對于問題三:提出了一種自適應編碼方案,該方案基于音頻信號的特征(如頻譜質心、動態范圍、諧波特征等)自動調整編碼參數。通過特征提取與音頻分類(語音或音樂),自適應編碼方案能夠動態調整比特率和采樣率,從而在保證音質的同時優化文件大小。該方案通過強化學習、支持向量機(SVM)等方法進行優化,實現了音頻文件大小與音質之間的平衡,特別適用于流媒體服務和移動設備。
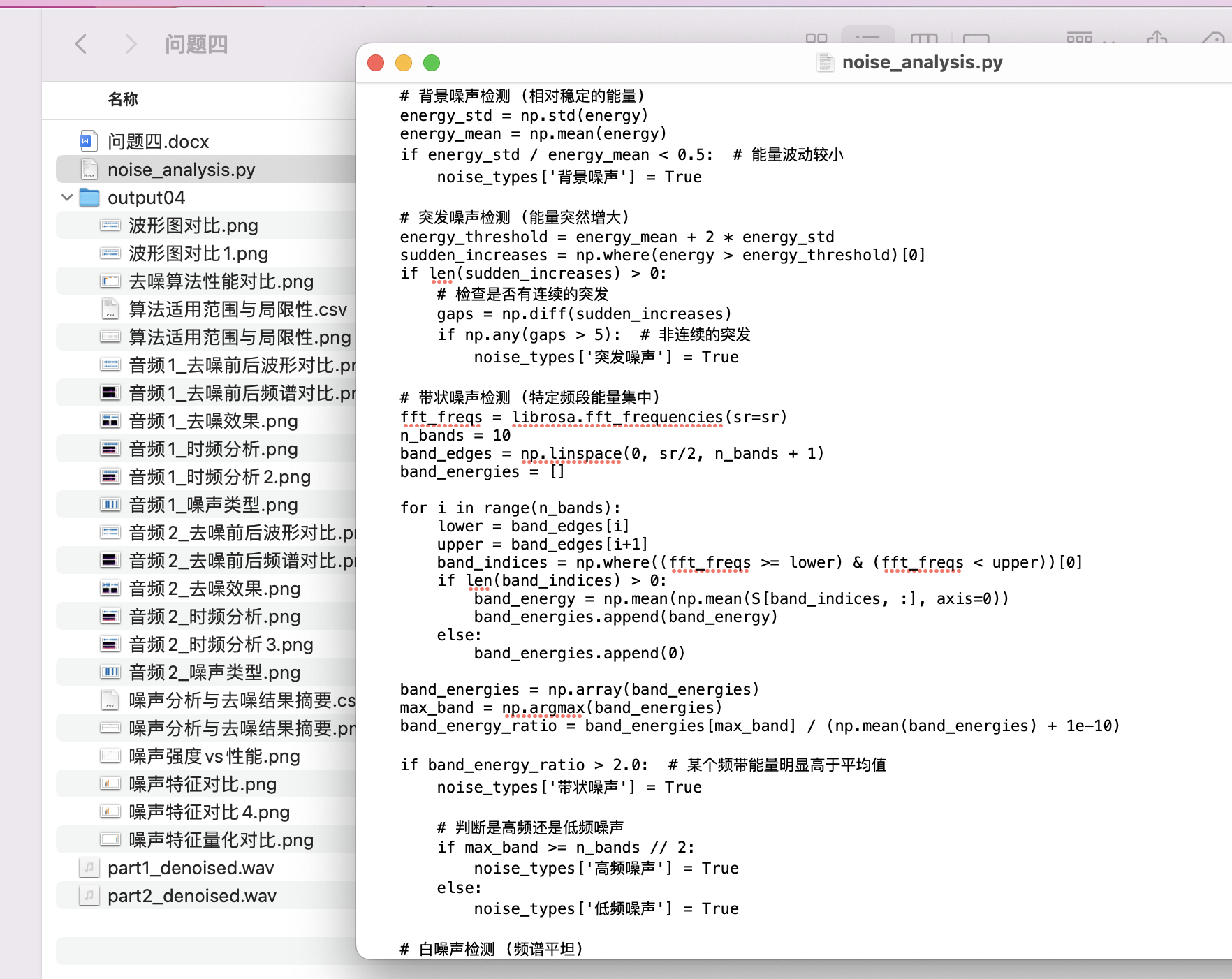
對于問題四:提出了基于音頻時頻分析的噪聲識別與去噪方法。通過短時傅里葉變換(STFT)和梅爾頻譜變換提取音頻的時頻特征,結合噪聲類型(如背景噪聲、突發噪聲、帶狀噪聲等)的識別,模型設計了自適應去噪算法。針對不同噪聲類型,算法自動選擇最適合的處理方法(如譜減法、小波去噪等),并根據去噪后的信噪比(SNR)評估去噪效果。實驗結果表明,盡管該算法在某些復雜噪聲環境中表現有限,但對突發噪聲和背景噪聲有較好的去噪效果。
總結:本研究提出的音頻處理模型為音頻格式選擇、音頻參數優化、音頻編碼與去噪提供了有效的數學建模解決方案。通過結合時頻分析、自適應編碼和去噪算法,模型在提高音頻存儲效率和音質保真度的同時,顯著減少了音頻文件的存儲空間需求。盡管在極端噪聲環境中仍有提升空間,但該模型的自適應性與靈活性為音頻處理技術的應用提供了有價值的參考。

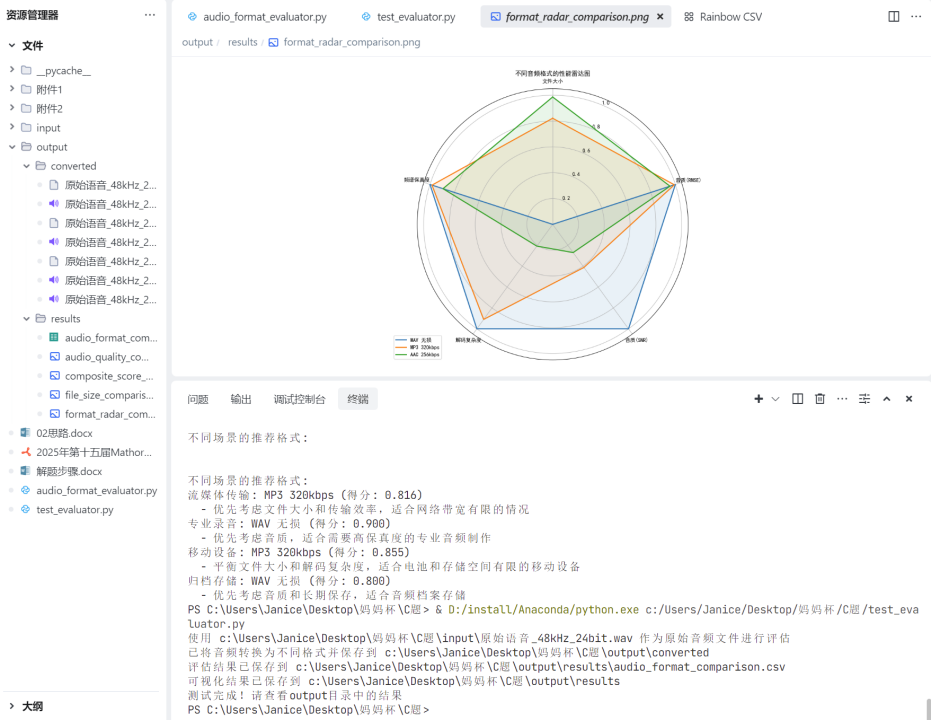
根據場景特點推薦最佳音頻格式
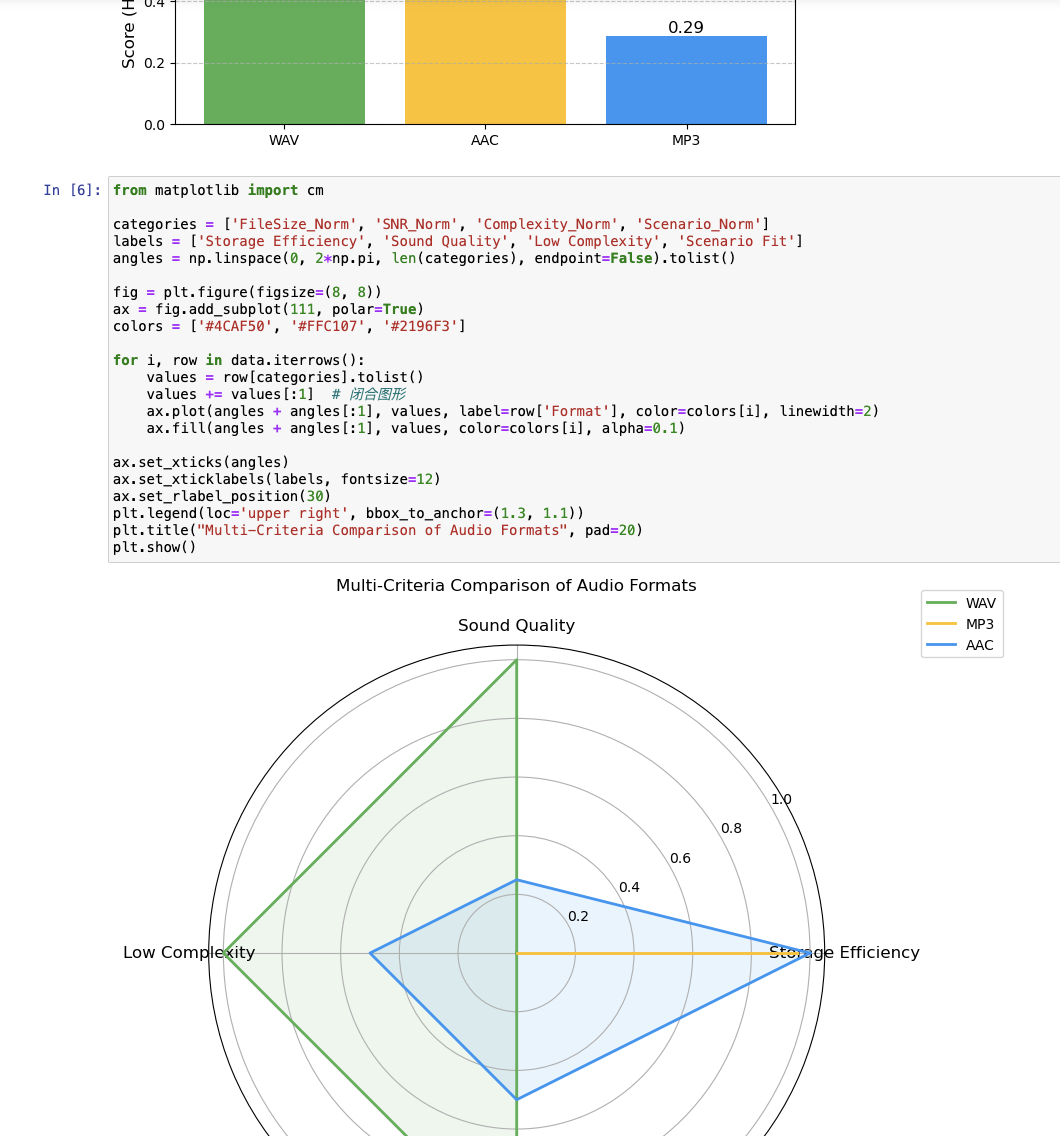
音頻格式評估結果摘要:
格式 比特率 文件大小(KB) SNR(dB) 綜合得分
WAV 無損 1118.957031 126.379871 0.800000
MP3 128kbps 94.167969 25.696666 0.286523
MP3 192kbps 141.230469 30.415568 0.464035
MP3 320kbps 235.355469 67.209253 0.777954
AAC 128kbps 43.534180 36.152380 0.492431
AAC 192kbps 57.926758 52.808170 0.660296
AAC 256kbps 58.431641 52.862034 0.663492
不同場景的推薦格式:
流媒體傳輸: MP3 320kbps (得分: 0.814)
優先考慮文件大小和傳輸效率,適合網絡帶寬有限的情況
專業錄音: WAV 無損 (得分: 0.900)
優先考慮音質,適合需要高保真度的專業音頻制作
移動設備: MP3 320kbps (得分: 0.850)
平衡文件大小和解碼復雜度,適合電池和存儲空間有限的移動設備
歸檔存儲: WAV 無損 (得分: 0.800)
問題 1:設計一個綜合評價指標,量化不同音頻格式(至少包含
WAV、MP3、AAC 這 3 種音頻格式)在存儲效率與音質保真度之間 的平衡關系。該指標應考慮:
文件大小(存儲空間占用)
音質損失(與原始音頻相比的信息丟失)
編解碼復雜度(計算資源消耗)
問題 1:設計一個綜合評價指標,量化不同音頻格式在存儲效率與音質保真度之間的平衡關系
解題步驟:
在此問題中,我們需要設計一個能夠綜合衡量不同音頻格式(如WAV、MP3、AAC等)在存儲效率與音質保真度之間的平衡關系的綜合評價指標。通過該指標,我們可以合理比較不同音頻格式的優勢與劣勢,從而為實際應用場景提供科學依據。
- 存儲效率的量化:
首先,存儲效率的量化主要是通過文件的壓縮比來實現。對于每一種音頻格式,我們需要計算其壓縮比。假設原始音頻的大小為 ,壓縮后音頻的大小為 ,則壓縮比(Compression Ratio, CR)定義為:
其中,較大的 表示更高的壓縮效率,即存儲空間的利用率更高。
在工程實踐中,我們會使用不同的編碼算法(如MP3的有損壓縮、WAV的無損壓縮等)來進行音頻數據的壓縮,這影響到音頻存儲空間的大小。通過采用 優化編碼算法(如基于 哈夫曼編碼 或 算術編碼 的方法),可以提高壓縮效率。
- 音質損失的度量:
音質損失通常是指在壓縮后音頻中與原始音頻相比的音頻信息丟失程度。為了量化這一點,我們可以使用 信噪比(SNR) 來度量音質損失。假設原始音頻信號為 ,壓縮后的音頻信號為 ,則其信噪比 可定義為:
其中, 表示期望值。高SNR表示壓縮后的音頻與原始音頻差異小,音質較好。
此外,還可以使用 PESQ(Perceptual Evaluation of Speech Quality) 或 MUSHRA(Multistimulus test) 等主觀音質評價指標進行音質損失的計算。這些模型可以量化壓縮后音頻的主觀音質評分。
- 編解碼復雜度的考慮:
編碼和解碼的復雜度決定了音頻格式的計算資源消耗。對比不同音頻格式的編解碼復雜度,我們可以使用 時間復雜度 來表示。例如,對于AAC和MP3編碼算法,其時間復雜度分別為 和 ,其中 是輸入信號的采樣點數。更高復雜度的編碼算法通常需要更多的計算資源。
在工程實現中,可以通過 浮點運算計數器 或 CPU使用率 來測量不同算法的計算消耗。
- 適用場景的權衡:
音頻格式的選擇還依賴于具體的應用場景。比如,MP3適合流媒體傳輸,因為它具有較高的壓縮比和較低的音質損失;而WAV適用于專業音頻錄制和播放場景,因為它支持無損音頻存儲。
為了量化適用場景對音頻格式的影響,可以根據不同應用的要求設置權重系數。例如,對于流媒體應用,MP3的存儲效率和編解碼復雜度更重要,而對于高保真音頻應用,音質損失更為關鍵。
- 綜合評價指標設計:
最終的綜合評價指標 可以通過加權求和的方式得到。我們結合存儲效率(CR)、音質損失(SNR)、編解碼復雜度和適用場景的權重,構建如下綜合評價公式:
其中, 為各個因素的權重系數,需根據實際應用場景通過 優化算法(如 粒子群優化(PSO) 或 遺傳算法(GA))來確定。
問題 2:基于附件 1 中的音頻文件,建立數學模型,分析采樣率、 比特深度、壓縮算法等參數對音頻質量和文件大小的影響。設計音頻 文件的性價比指標(音質與文件大小的平衡),并據此對附件 1 中的 不同參數組合得到的文件進行排序(分音樂和語音,不包括原始音樂 文件和原始語音文件),分別給出針對語音內容和音樂內容的最佳參 數推薦。
問題 2:分析采樣率、比特深度、壓縮算法等參數對音頻質量和文件大小的影響,設計音頻文件的性價比指標
解題步驟:
在本問題中,我們需要分析不同音頻參數(采樣率、比特深度、壓縮算法)對音頻質量和文件大小的影響,并基于此設計一個性價比指標。
- 采樣率和比特深度對音質與文件大小的影響:
音頻文件的大小與采樣率 和比特深度 緊密相關。采樣率和比特深度越高,音頻質量越好,但文件大小也隨之增大。音頻文件的大小 可以表示為:
其中, 為音頻的時長。增大采樣率和比特深度會導致文件大小的增加,但也能提高音質。
為了平衡音質和文件大小,我們可以根據音頻的實際應用需求來調整采樣率和比特深度。例如,對于語音信號,可以選擇較低的采樣率和比特深度,而對于音樂信號,則選擇較高的采樣率和比特深度以保持音質。
- 壓縮算法的影響:
壓縮算法通過去除音頻中的冗余信息來減小文件大小,但通常會引入一定的音質損失。壓縮比率 定義為:
較高的壓縮比表示更高的存儲效率,但可能伴隨更高的音質損失。我們需要通過優化算法來選擇壓縮算法(如MP3、AAC),使得壓縮比與音質損失之間達到合理平衡。
- 性價比指標設計:
性價比指標 旨在平衡音質和文件大小。我們可以定義性價比指標為:
該公式的含義是,在相同文件大小下,SNR越大表示音質越好,性價比越高。在不同的音頻設置下,我們希望通過 線性規劃 或 遺傳算法 來優化采樣率、比特深度和壓縮算法的選擇,以最大化性價比。
問題 3:設計一種自適應編碼方案,能夠分析輸入音頻的特征(區
分語音/音樂類型、識別頻譜特點和動態范圍),并據此自動選擇最
佳編碼參數。將你的方案應用于附件 1 中提供的原始音樂和原始語音 音頻樣本,記錄優化后的參數選擇、文件大小和音質保真度,并與固 定參數方案相比較,說明你的方案帶來的改進。
解題步驟:
本問題要求我們設計一個自適應編碼方案,能夠根據輸入音頻的特征(如語音類型、頻譜特征等)自動選擇最佳編碼參數。
- 音頻特征提取:
音頻特征是設計自適應編碼方案的基礎。首先,我們通過 傅里葉變換(FFT) 或 小波變換(Wavelet Transform) 提取音頻的頻譜特征。頻譜分析幫助我們了解音頻信號的頻率分布,為編碼參數選擇提供依據。
另外,通過 動態范圍(DR) 來衡量音頻的音量差異,計算公式為:
該指標能夠反映音頻信號的變化幅度,對于語音和音樂類型的音頻,動態范圍的差異顯著,因此在編碼時需要進行優化選擇。
- 自動選擇編碼參數:
基于音頻的特征分析,我們可以設計一個自適應編碼方案。針對 語音信號,我們采用較低的采樣率(如8kHz)和比特深度(如8位),以減小文件大小;而對于 音樂信號,我們采用較高的采樣率(如44.1kHz)和比特深度(如16位)來保證音質。
- 自適應編碼優化算法:
為了自動選擇最佳編碼參數,我們可以使用 強化學習 或 支持向量機(SVM) 來建立模型,根據音頻的特征進行分類,自動選擇合適的編碼參數。通過 Qlearning 或 深度Q網絡(DQN) 等強化學習方法,我們可以訓練一個智能體來根據環境狀態(音頻類型、頻譜特征等)選擇最優的編碼方案。
優化目標可以通過以下目標函數來實現
其中, 和 為權重系數,通過 粒子群優化(PSO) 或 遺傳算法(GA) 來求解最優編碼參數。
問題 4:基于附件 2 中的音頻文件,對樣本音頻進行時頻分析, 建立數學模型識別并量化各類噪聲(如背景噪聲、突發噪聲、帶狀噪 聲等)的特征參數。提出一種改進的去噪策略或自適應算法,能針對 不同噪聲類型自動選擇最佳處理方法。處理樣本音頻,要求在論文中 給出每個音頻包含的噪聲種類,去噪后的音頻文件的信噪比,并分析 在不同噪聲類型和強度下的適用范圍與局限性。
同時將去噪后的音頻存儲為新的 wav 文件,并分別命名為
part1_denoised.wav 和 part2_denoised.wav 進行提交。
解題步驟:
本問題的目標是設計一種去噪算法,能夠識別并處理不同類型的噪聲。目標是提高音頻的清晰度并優化去噪效果。
- 噪聲特征分析:
使用 短時傅里葉變換(STFT) 來分析噪聲的時頻特征。噪聲在時頻域中的分布通常具有一定規律,基于這些規律可以設計去噪濾波器。通過分析噪聲的頻譜特征,我們可以利用 K均值聚類 或 自適應濾波器(如LMS算法)來對不同噪聲進行分類。
- 去噪策略設計:
針對不同噪聲類型,采用不同的去噪方法:
背景噪聲:使用 Wiener濾波器 進行頻域去噪,濾波器的頻域表示為:
其中, 為信號的功率譜, 為噪聲的功率譜。
突發噪聲:可以使用 小波去噪法,通過對小波系數進行閾值化處理去除突發噪聲。
- 去噪優化模型:
去噪優化目標是最大化去噪后的信噪比(SNR)。優化目標函數為:
其中, 為去噪后的信號, 為清晰的原始信號。通過 最小均方誤差(MSE)優化 來調整濾波器的參數,從而達到最優的去噪效果。
- 自適應算法設計:
設計自適應去噪算法,能夠根據輸入音頻的噪聲類型自動選擇去噪方法。使用 自適應濾波器(如LMS或RLS算法),并結合 信噪比優化 方法,使去噪過程動態適應不同噪聲類型。


)
)
![BR_頻譜20dB 帶寬(RF/TRM/CA/BV-05-C [TX Output Spectrum – 20 dB Bandwidth])](http://pic.xiahunao.cn/BR_頻譜20dB 帶寬(RF/TRM/CA/BV-05-C [TX Output Spectrum – 20 dB Bandwidth]))


)

——什么是人類偏好對齊中的「對齊稅」(Alignment Tax)?如何緩解?)
)



——硬件描述語言簡介)


)
默認不聚焦問題處理)
