目錄
一、網絡爬蟲
1、基本的爬蟲
2、獲取URL
3、查找網頁源碼關鍵字
4、代碼實現
二、requests庫
1、requests的優勢和劣勢
2、獲取網頁的其他庫
(1)selenium庫
(2)pyppeteer庫
三、pyppeteer庫
1、pyppeteer庫的來歷
2、pyppeteer庫的工作原理
3、pyppeteer相關環境安裝
四、協程
1、概念
2、注意事項
五、用pyppeteer獲取網頁
一、網絡爬蟲
網絡爬蟲,簡稱爬蟲,它可以用來在網絡上搜集一些數據(比如在搜索引擎上),也可以模擬瀏覽器的快速操作(比如我們可以用爬蟲來實現搶課)
1、基本的爬蟲
一個基本的爬蟲寫法如下:
(1)首先手動找出我們想要獲取的網址(URL)
(2)在瀏覽器中搜索這個網址,查看網頁的源代碼,在源代碼中找出我們想要的內容的字符串的模式(比如我們想要查找一些圖片,在網頁源碼中,圖片都有一些固定的關鍵字,我們通過抓取這些關鍵字,就可以獲取圖片)
(3)在程序中我們用URL得到對應的網頁
(4)再根據程序中的正則表達式或者BeautifulSoup庫來查找關鍵字,得到對應的內容并保存
2、獲取URL
我們先在瀏覽器上搜索一個關鍵字:
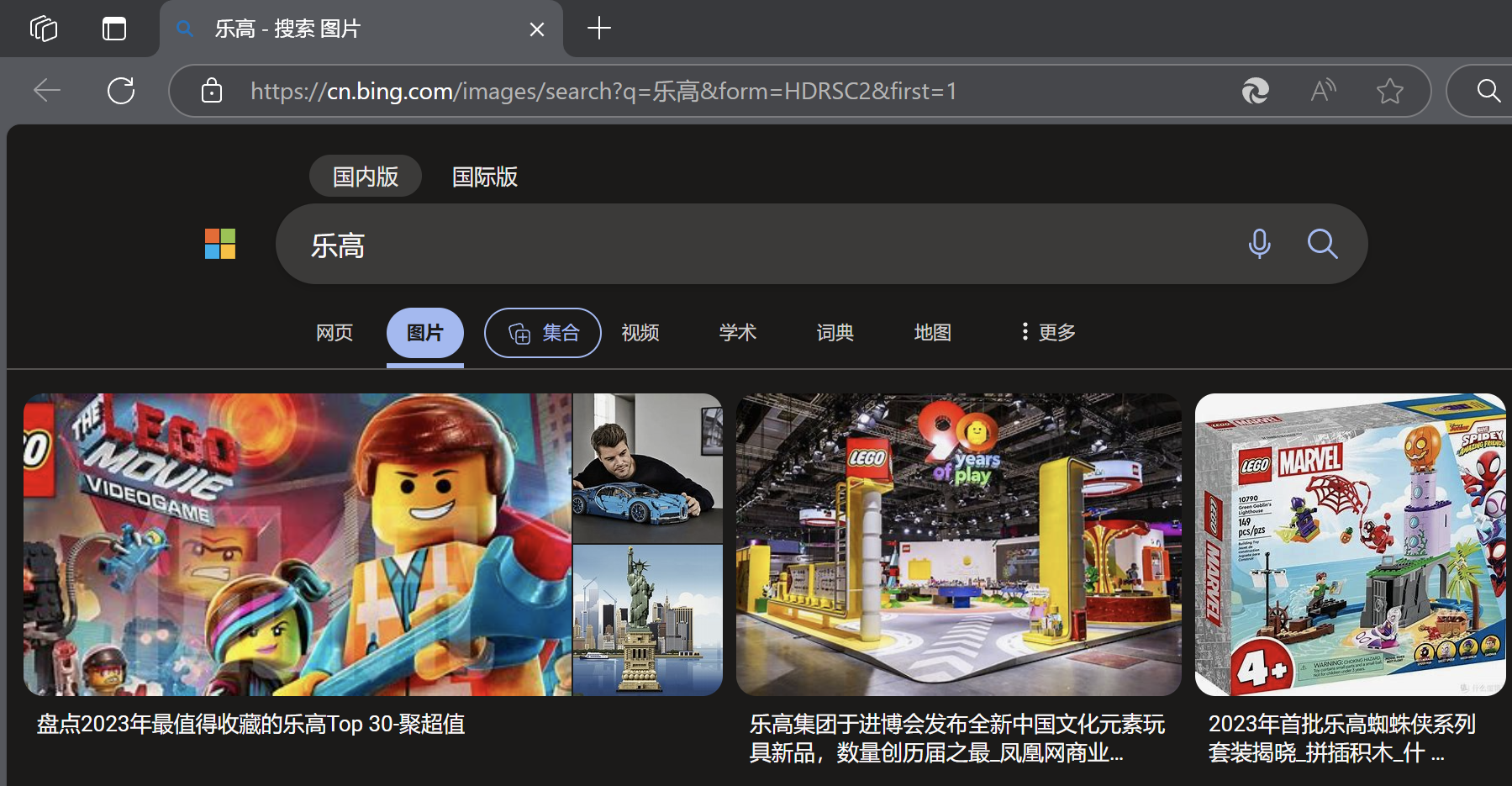
我們觀察這個網頁對應的URL:
可以發現,在這個URL中,有一部分是“q = 樂高”,我們就可以猜想,是不是只要把q后面的文字改成我們想要搜索的關鍵字,就可以到達對應的頁面?
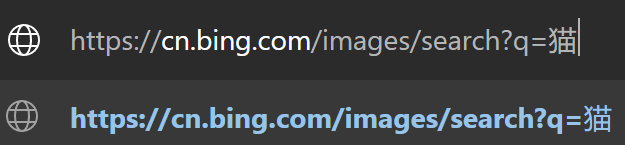
我們直接在URL上把q后面的關鍵詞改成“貓”,然后按下回車:
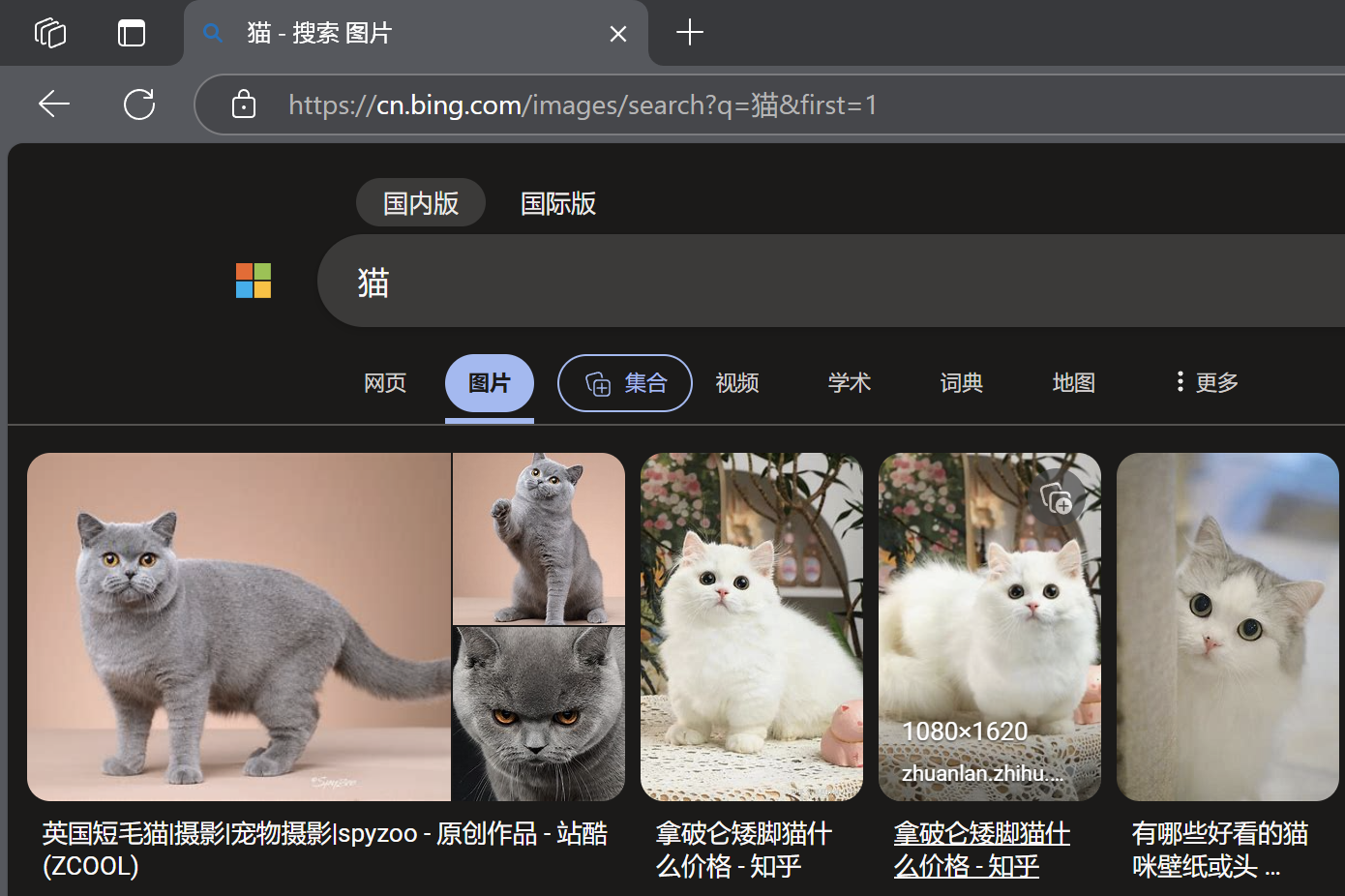
發現果然跳轉到了貓的搜索頁面!
這就意味著我們可以在代碼中,通過修改q后面的數據,來到達對應的目標頁面
3、查找網頁源碼關鍵字
當我們到達了目標頁面,我們想要抓取幾個圖片,就需要通過頁面源碼的關鍵字:
我們在這個“貓”的搜索頁面隨便找一個圖片,右鍵,選擇“復制圖像連接”
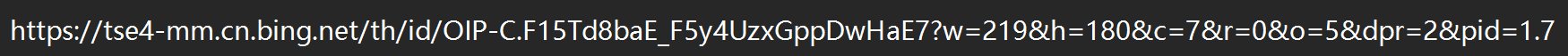
我們會發現th(略縮圖),id等具有標志性的東西,這些都指明了這可能是一個圖片
當然,如果看不出來我們可以多復制幾個圖片的鏈接,來尋找共同點:

不難發現,很多圖片都有/th/id/OIP-這一部分,這可能就是圖片鏈接的共同特點:
右擊網頁空白處,點擊“查看網頁源碼”,按ctrl + F ,?
我們把這串字符復制進去:
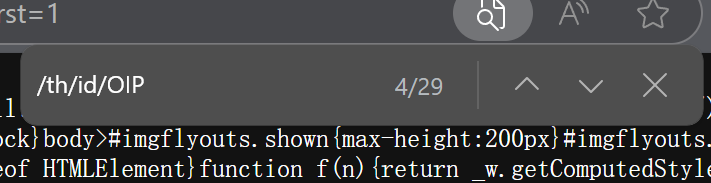
按下回車,就能看見在源碼的地方,很多處都被標記了這個關鍵字符串,我們就可以根據這個來爬取想要的圖片;
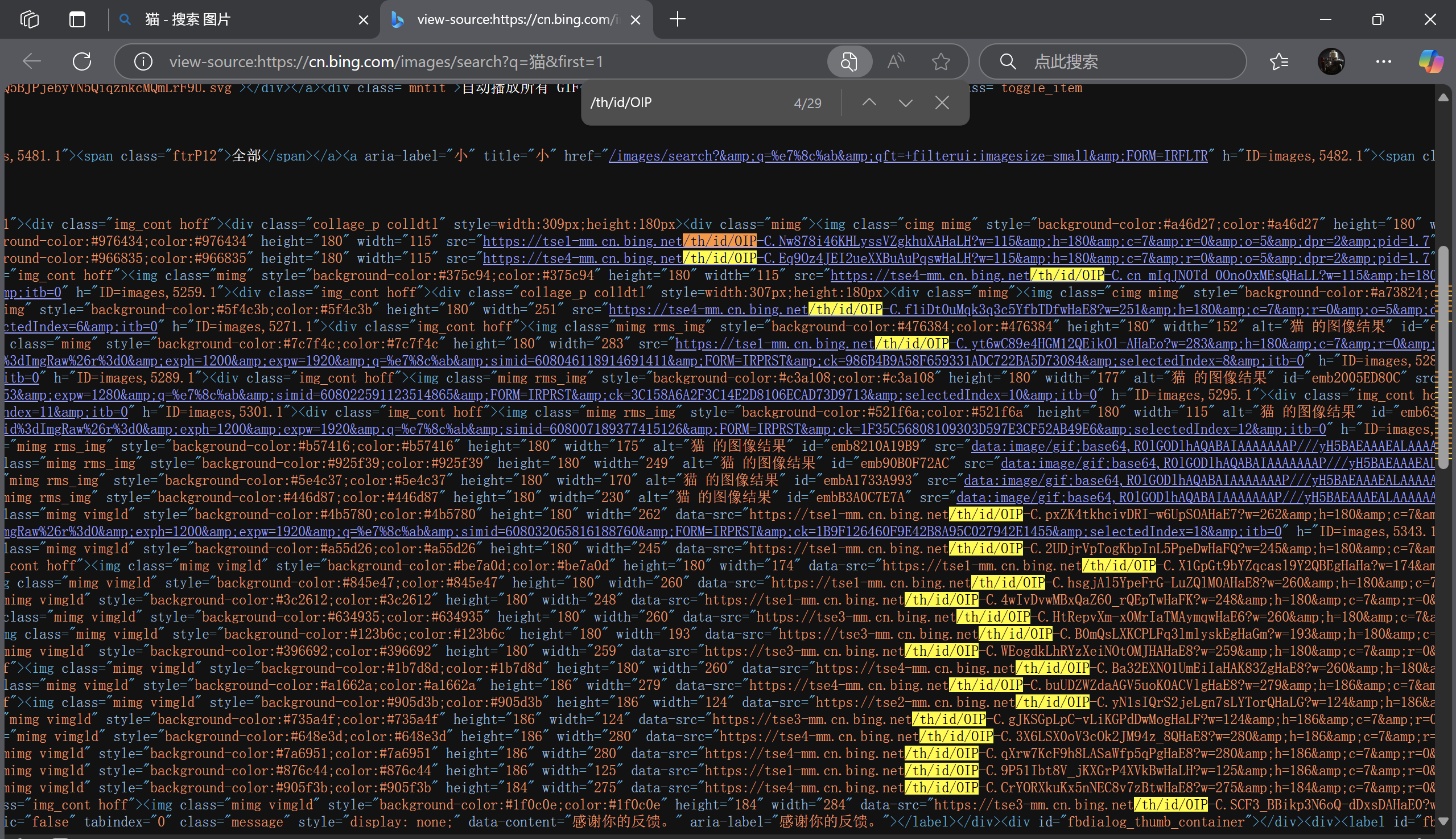
4、代碼實現
我們來找一個專門練習爬蟲的頁面來爬取幾個圖片(很多網頁有反爬技術,最最基礎的爬蟲代碼難以成功)
import re #用來使用正則表達式
import requests #用于HTTP請求
import os #操作文件目錄等def getHTML(url): #用于獲取目標頁面的HTMLfakeHeader = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36 Edg/81.0.416.77'}#定義了一個字典,用來模擬瀏覽器的請求頭,欺騙瀏覽器try:r = requests.get(url, headers=fakeHeader)#發送一個GET請求到指定的url,并使用我們的假頭部r.encoding = r.apparent_encoding#設置編碼格式return r.text #返回網頁的HTML內容except Exception as e:print(e)return ""#------------------------以上內容可以固定的直接使用------------------------def getPicturePro(n):base_url = "https://spiderbuf.cn" #基礎的路徑url = "https://spiderbuf.cn/web-scraping-practice/scraping-images-from-web" #目標網頁的URL(就是包含圖片的)html = getHTML(url) #調用函數,獲取目標頁面的HTML內容pt = r'<img[^>]+src="([^"]+)"' #正則表達式,用于找到HTML里面的img標簽的src屬性的值i = 0 #圖片個數(方便命名)for x in re.findall(pt, html): #使用正則表達式pt找到html中所有符合的圖片路徑if x.startswith("/"):x = base_url + x # 檢查是否是相對路徑,并轉換為完整路徑if not (x.lower().endswith(".jpg") or x.lower().endswith(".png")): #拼接好后,如果不是jpg或png的圖片,跳過不要continuetry:print(x) #輸出經過層層篩選的圖片路徑r = requests.get(x, stream=True) #發送GET請求,獲取圖片,并以流式下載,防止一次性到內存pos = x.rfind(".") #找到文件擴展名的起始位置if not os.path.exists(r"D:\學習\Python\temp"):os.makedirs(r"D:\學習\Python\temp") #若不存在該目錄就創建該目錄f = open(r"D:\學習\Python\temp\{0}{1}{2}".format("image", i, x[pos:]), "wb")#打開該目錄,并且以image和i來命名f.write(r.content) #把圖片寫入文件f.close()except Exception as e:print(f"Error downloading {x}: {e}") #若報錯就返回錯誤信息i += 1getPicturePro(1) #傳入參數,表示開始執行輸出:
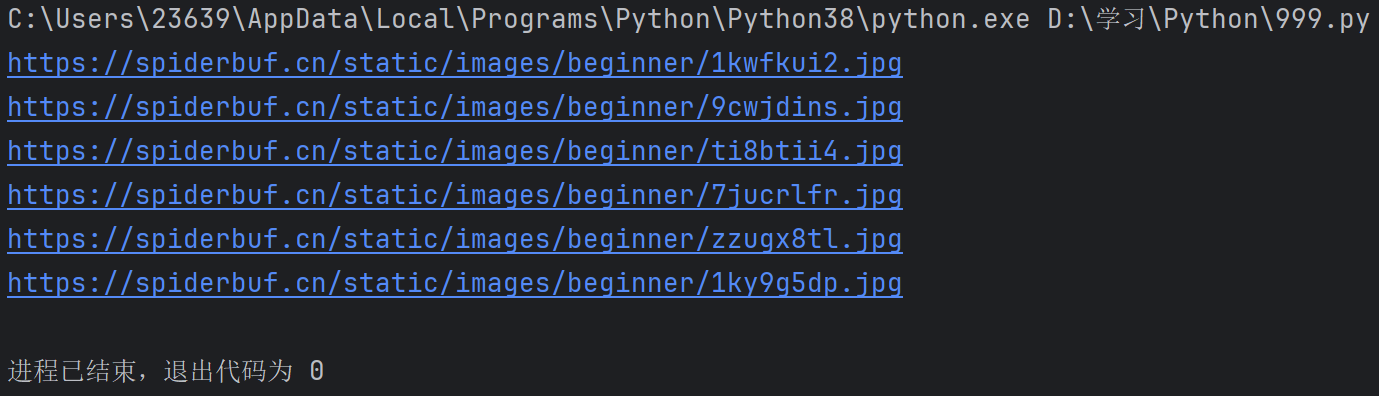
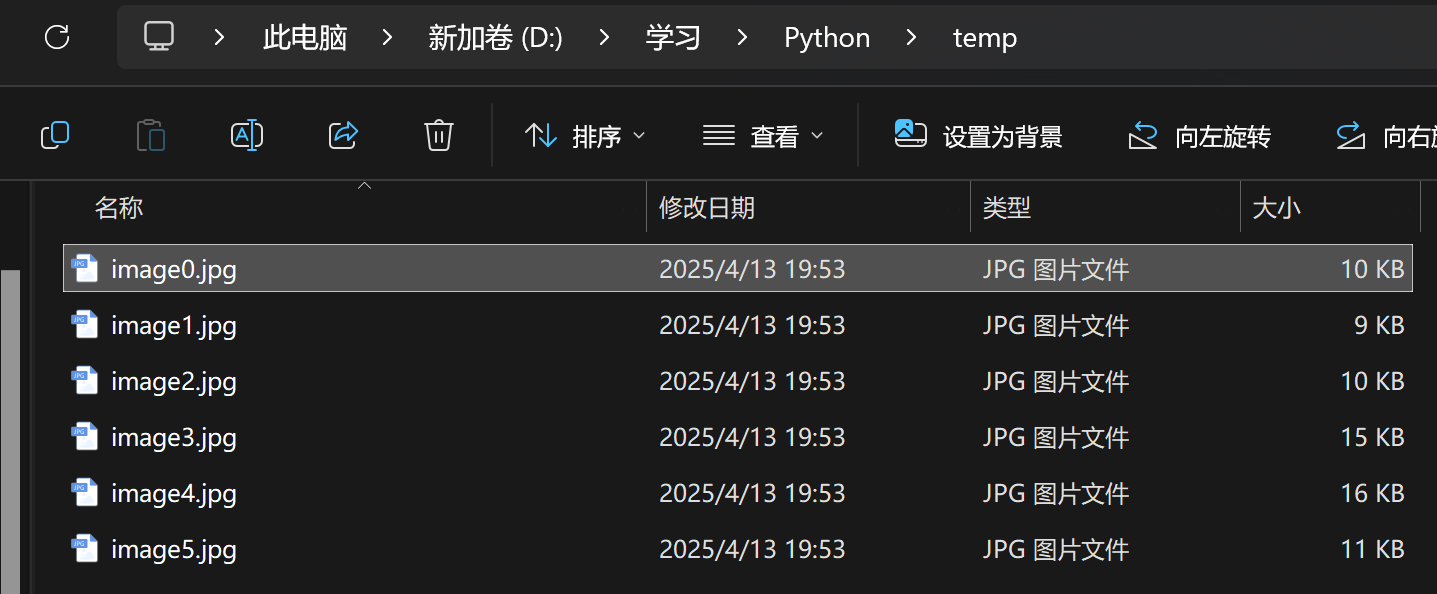
我們再看看文件夾:
二、requests庫
在上面的代碼中,我們可以看見,requests庫的作用是用來發送HTTP請求的,可以完成大量的網絡層面的任務
1、requests的優勢和劣勢
①優勢:速度快,且安裝簡單,我們只需要使用pip命令就能安裝requests庫,很容易把自己的代碼分享給別人使用,即共享性強
②劣勢:requests庫很容易被反爬蟲手段屏蔽,可能一個有一點反爬蟲手段的網頁就能把這個代碼屏蔽掉(比如我們用上面的代碼去爬百度的搜索圖片,是不能成功的,會被反爬),而且不能獲取JavaScript的生成的動態網頁。
2、獲取網頁的其他庫
面對剛剛上面requests的缺陷,我們在Python中,也提供了很多庫來彌補它的不足
(1)selenium庫
selenium庫雖然比requests庫更強一些,但是它的速度很慢,而且已經被許多網站反爬,可能還是無法成功
(2)pyppeteer庫
速度很快,而且目前還沒有被很多網站反爬,是一個比較好的選擇
三、pyppeteer庫
1、pyppeteer庫的來歷
pyppeteer是puppeteer的Python版本,而puppeteer是谷歌公司推出的可以控制Chrome瀏覽器的一套編程工具
2、pyppeteer庫的工作原理
①啟動一個瀏覽器Chromium,用瀏覽器裝入網頁,并且瀏覽器可以用無頭模式(隱藏模式)或者顯式模式啟動(就是在執行爬取操作的時候用戶能否看見瀏覽器操作頁面的具體過程)
②從瀏覽器中可以獲得網頁的源代碼,若網頁就JavaScript程序,獲得到的就是JavaScript被瀏覽器執行后的網頁源碼
③pyppeteer可以向瀏覽器發送命令,模擬用戶在瀏覽器上的鍵盤,鼠標等操作
④selenium和pyppeteer的工作原理相同
3、pyppeteer相關環境安裝
我們先在cmd窗口用pip命令下載pyppeteer
pip install pyppeteer(要求Python版本在3.6及3.6以上)
當然,我們上面提到,我們需要啟動一個特殊的瀏覽器Chromium,所以我們需要下載它:
在安裝之前,我們需要確定我們安裝了Node.js
安裝官網:Node.js — 在任何地方運行 JavaScript
進入之后,我們點擊下載LTS版本的(更加穩定)
在安裝完成后,我們可以在cmd窗口檢查一下是否安裝完成:
node -v
npm -v若安裝成功,應該會類似如下:
安裝完成之后,我們輸入以下命令來安裝:
npx @puppeteer/browsers install chrome@stable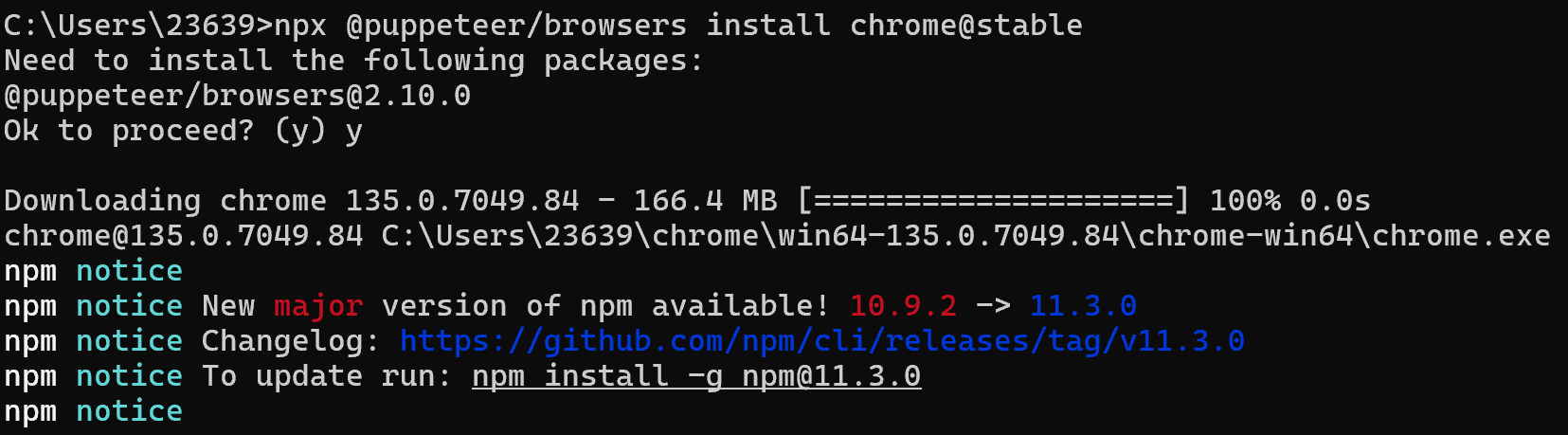
在上圖中的第六行,顯示了安裝的位置,我們定位到具體的目錄,找到exe文件,可以創建一個快捷方式到桌面:

四、協程
1、概念
協程就是在代碼中,前面加了async的函數:
async def scy() :return 0在調用協程時,必須在前面添加await
await scy()2、注意事項
(1)協程只能在協程里面調用,也就是說await關鍵字只能出現在協程里面,出現在外面就會報錯!
(2)協程是一種特殊的函數,多個協程可以并行
(3)pyppeteer中的所有函數都是協程
五、用pyppeteer獲取網頁
代碼如下:
import asyncio #是Python的異步 I/O 框架,用于編寫單線程并發代碼
import pyppeteer as pyp#通過輸入的url,獲取指定的HTML內容
async def getHTML(url) : #構造一個異步函數browser = await pyp.launch(headless = False , executablePath=r'C:\Users\23639\AppData\Local\Google\Chrome\Application\chrome.exe') #啟動一個瀏覽器,headless就是無頭模式,設置成False就會顯示瀏覽器,反之就不會#executablePath指明了Chrom瀏覽器的可執行路徑page = await browser.newPage() #等打開了瀏覽器,再在瀏覽器中獲取我們想要的頁面await page.setUserAgent('Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 safari/537.36')#模擬瀏覽器的請求頭await page.evaluateOnNewDocument(' () => Object. defineProperties (navigator, { webdriver: {get:()=> false } })}')#頁面在加載的時候會被執行里面JavaScript代碼,目的是防止瀏覽器檢測自動化工具await page.goto(url) #導航到指定的URLtext = await page.content() #獲取頁面的HTML代碼await browser.close() #關閉瀏覽器return text #返回text內容def getHTMLpro(url) :return asyncio.run(getHTML(url)) #返回頁面的HTML內容HTML_result = getHTMLpro("https://cn.bing.com") #調用函數
print(HTML_result)執行結果:
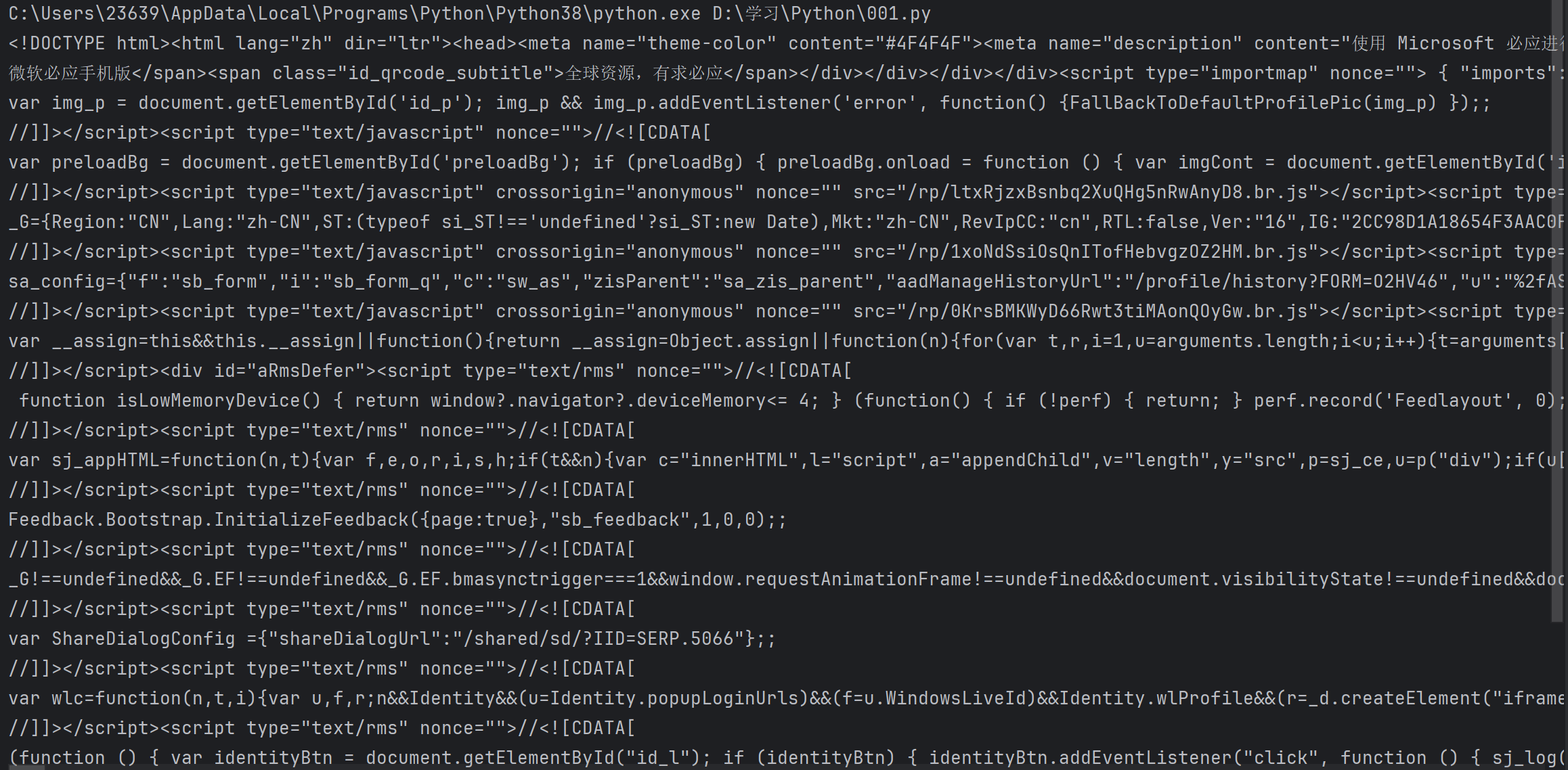
這就是把我們輸入的那個URL的網頁給爬取了下來,如果把這個復制到一個文本文檔中,把后綴改成.html,就是我們想要的那個頁面
以上就是Python網絡爬蟲設計(一)的全部內容:)
![BR_頻譜20dB 帶寬(RF/TRM/CA/BV-05-C [TX Output Spectrum – 20 dB Bandwidth])](http://pic.xiahunao.cn/BR_頻譜20dB 帶寬(RF/TRM/CA/BV-05-C [TX Output Spectrum – 20 dB Bandwidth]))


)

——什么是人類偏好對齊中的「對齊稅」(Alignment Tax)?如何緩解?)
)



——硬件描述語言簡介)


)
默認不聚焦問題處理)




