我們程序員寫的一個個解決我們實際問題,滿足我們日常需求的網絡程序,都是在應用層。
前面寫的套接字接口都是傳輸層經過對 UDP 和 TCP 數據發送能力的包裝,以文件的形式呈現給我們,讓我們可以進行應用層編程。換而言之,前面寫的所有套接字代碼全都屬于應用層開發。
一、協議
協議本質就是一種?“約定”。socket api?的接口在讀寫數據時,都是按?“字符串”?的方式來發送接收的。
1、序列化與反序列化的概念
如果我們要傳輸一些 “結構化的數據”?怎么辦呢?
通過前面的學習,知道了 TCP 是面向字節流的方式進行通信的。
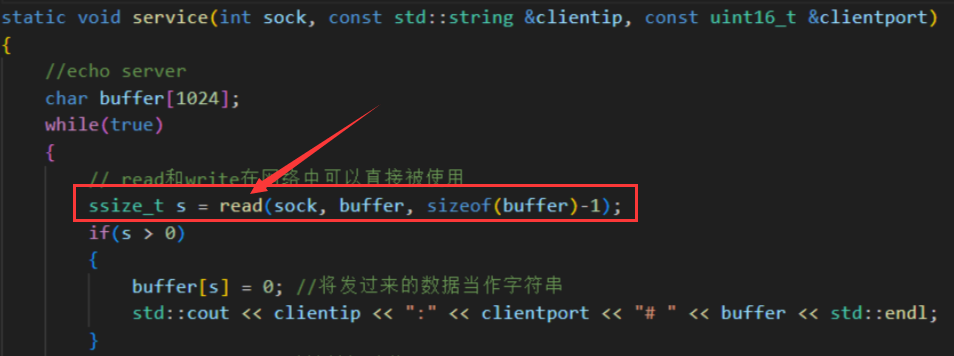
如何保證剛度讀到一個完整的數據呢?
舉例:我們使用 QQ 發送消息時,別人接收到的不只有消息,還包含了用戶昵稱、頭像信息、消息內容、發送時間等,這就叫做結構化的數據。這些結構化的數據可以打包成一個報文(變成一個整體),這個過程就叫作序列化,而把這個整體報文解開的過程就叫做反序列化。
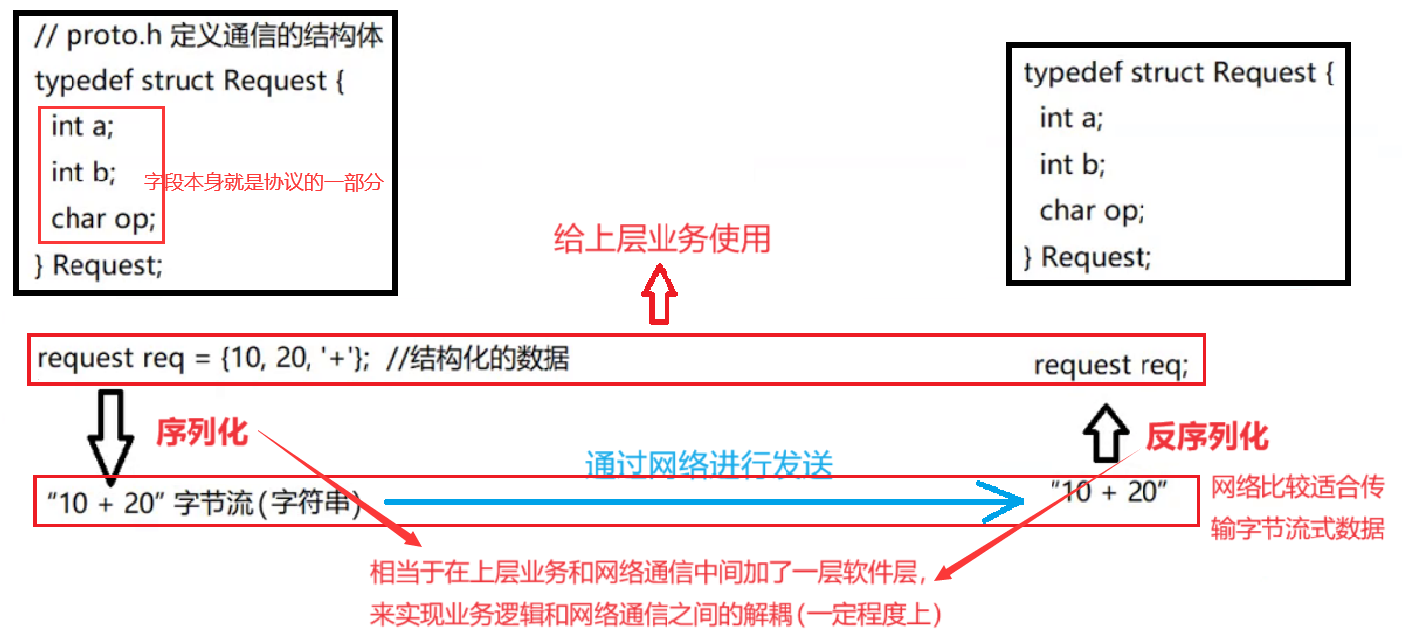
結構化數據要先序列化,再發送到網絡中,收到序列字節流后,要先反序列化再使用。而這里序列化和反序列化的過程用的就是業務協議。
2、自定義協議實現網絡版計算器
例如,我們需要實現一個服務器版的加法器。我們需要客戶端把要計算的兩個加數發過去,然后由服務器進行計算,最后再把結果返回給客戶端。
(1)約定方案
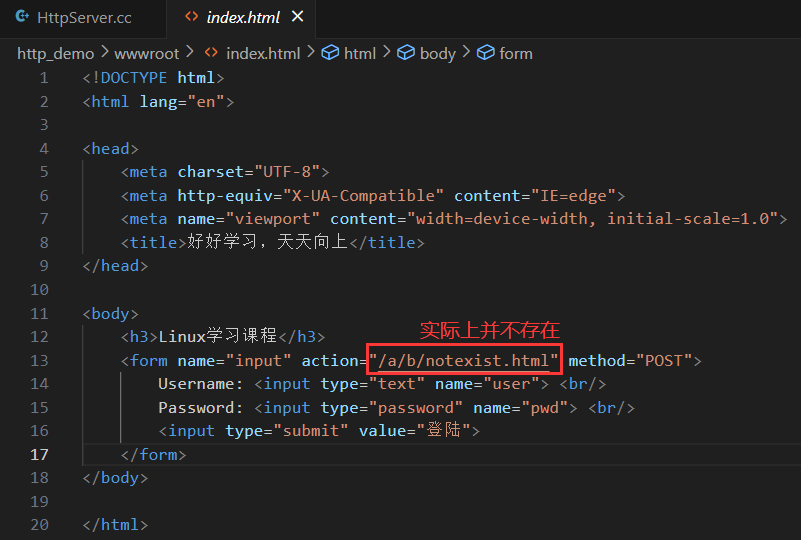
A. 約定方案一
- 客戶端發送一個形如 "1+1" 的字符串。
- 這個字符串中有兩個操作數,都是整形。
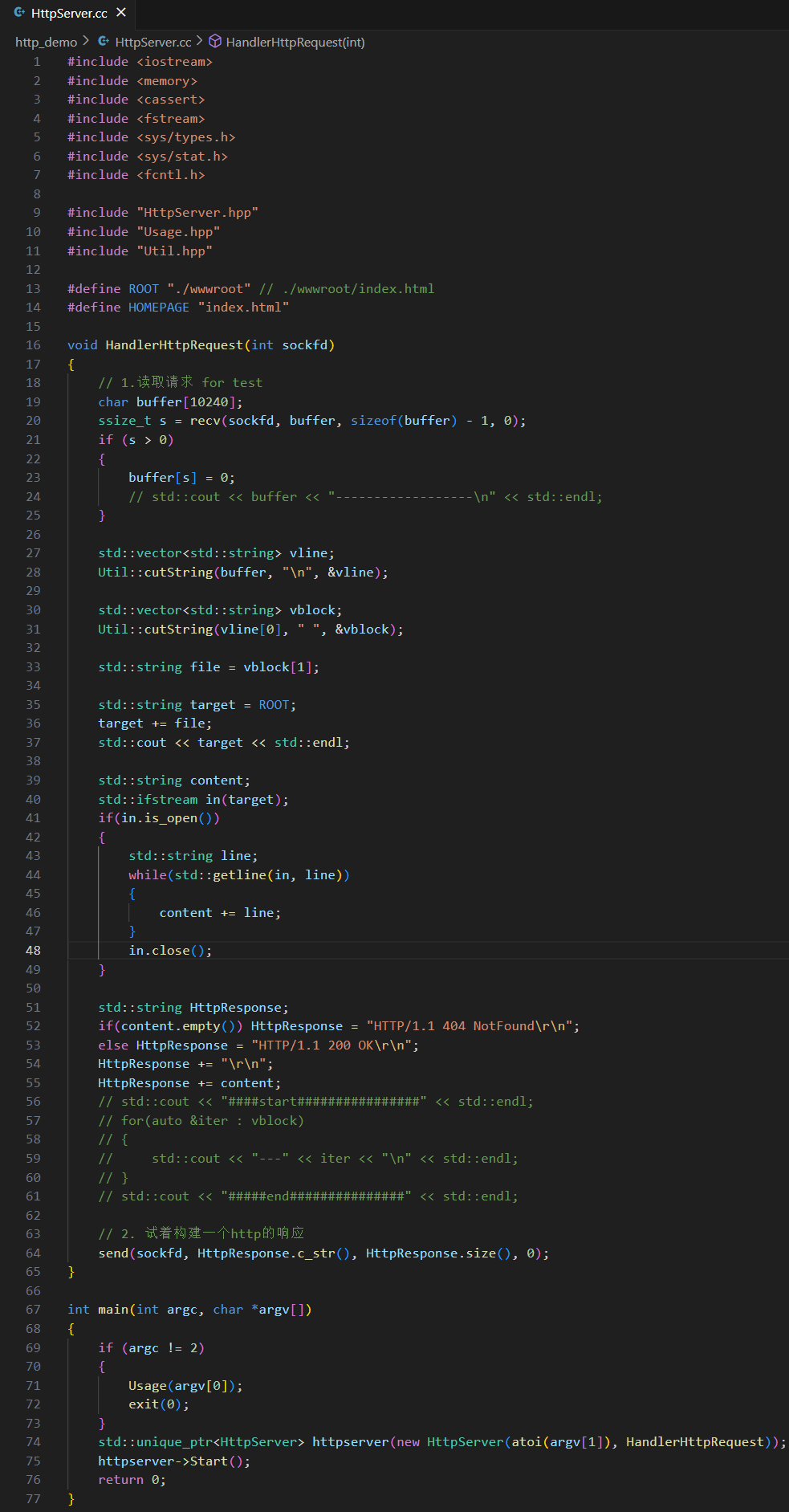
- 兩個數字之間會有一個字符是運算符,運算符只能是 +。
- 數字和運算符之間沒有空格。
- ... ...
B. 約定方案二
- 定義結構體來表示我們需要交互的信息。
- 發送數據時將這個結構體按照一個規則轉換成字符串,接收到數據的時候再按照相同的規則把字符串轉化回結構體,這個過程叫做 “序列化”?和 “反序列化”。
- // proto.h 定義通信的結構體
- typedef struct Request {
- int a;
- int b;
- char op;
- } Request;
-
- typedef struct Response {
- int result;
- int code;
- } Response;
-
- // client.c 客戶端核心代碼
- Request request;
- Response response;
- scanf("%d,%d", &request.a, &request.b);
- write(fd, request, sizeof(Request));
- read(fd, response, sizeof(Response));
-
- // server.c 服務端核心代碼
- Request request;
- read(client_fd, &request, sizeof(request));
- Response response;
- response.sum = request.a + request.b;
- write(client_fd, &response, sizeof(response));
AI寫代碼
無論是采用方案一,還是方案二,亦或是其他的方案,只要保證一端發送時構造的數據在另一端能夠正確的進行解析,就是可以的。這種約定就是應用層協議。?
(2)準備工作?
- const std::string &:輸入型參數
- std::string *:輸出型參數
- std::string &:輸入輸出型參數
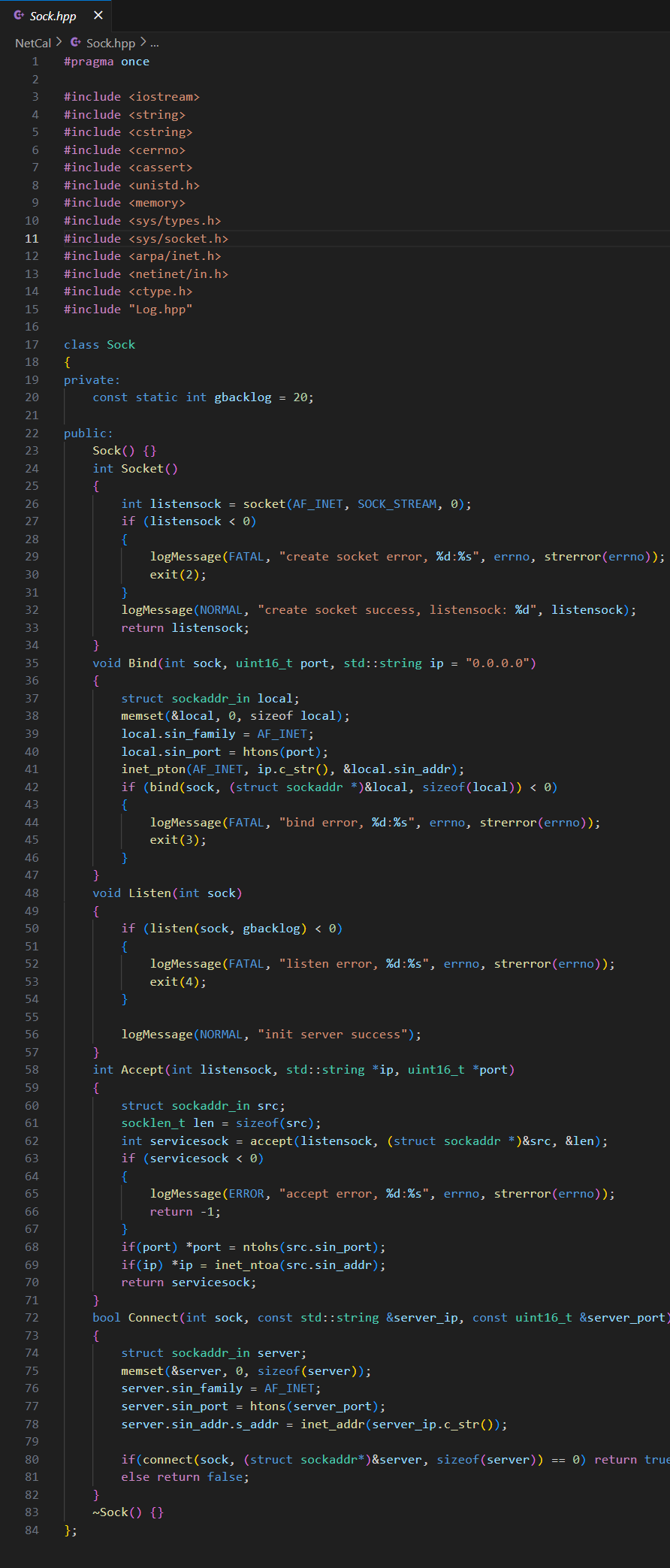
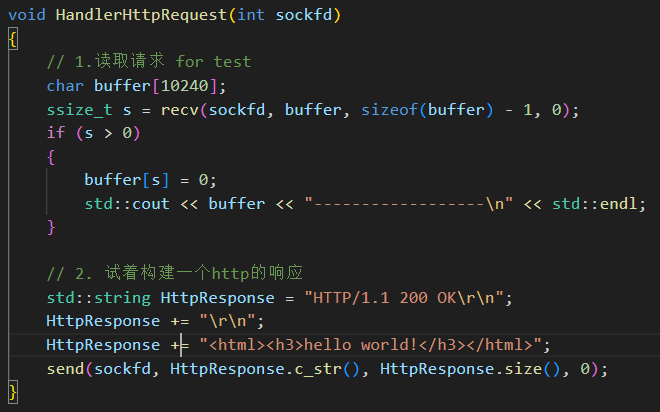
(3)服務端
自定義協議里要包含兩各類,一個是請求,一個是響應。服務端會收到請求,客戶端收到響應。
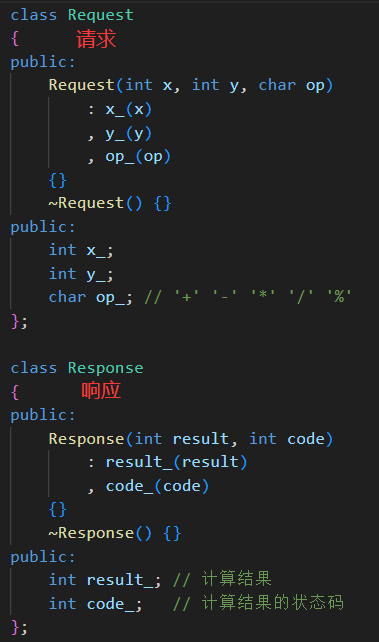
請求就是左操作符、右操作符和符號。
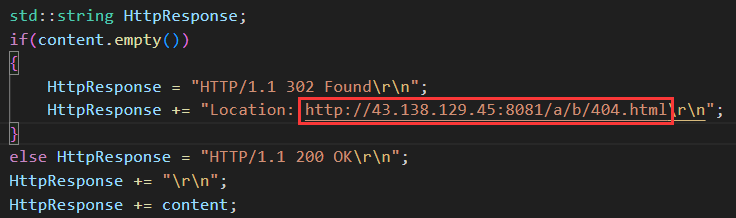
響應包含了退出碼和結果,如果正常結束退出碼為 0,如果有錯誤,可以自定義不同的退出碼表示不同的錯誤。
為什么要有計算結果的狀態碼?
因為在計算的過程中可能會出現異常,比如除 0 或模 0,輸入的操作碼 op 不屬于我們規定的符號。狀態碼為 0 表示計算結果正確,狀態碼為其它數字表示不同出錯含義。
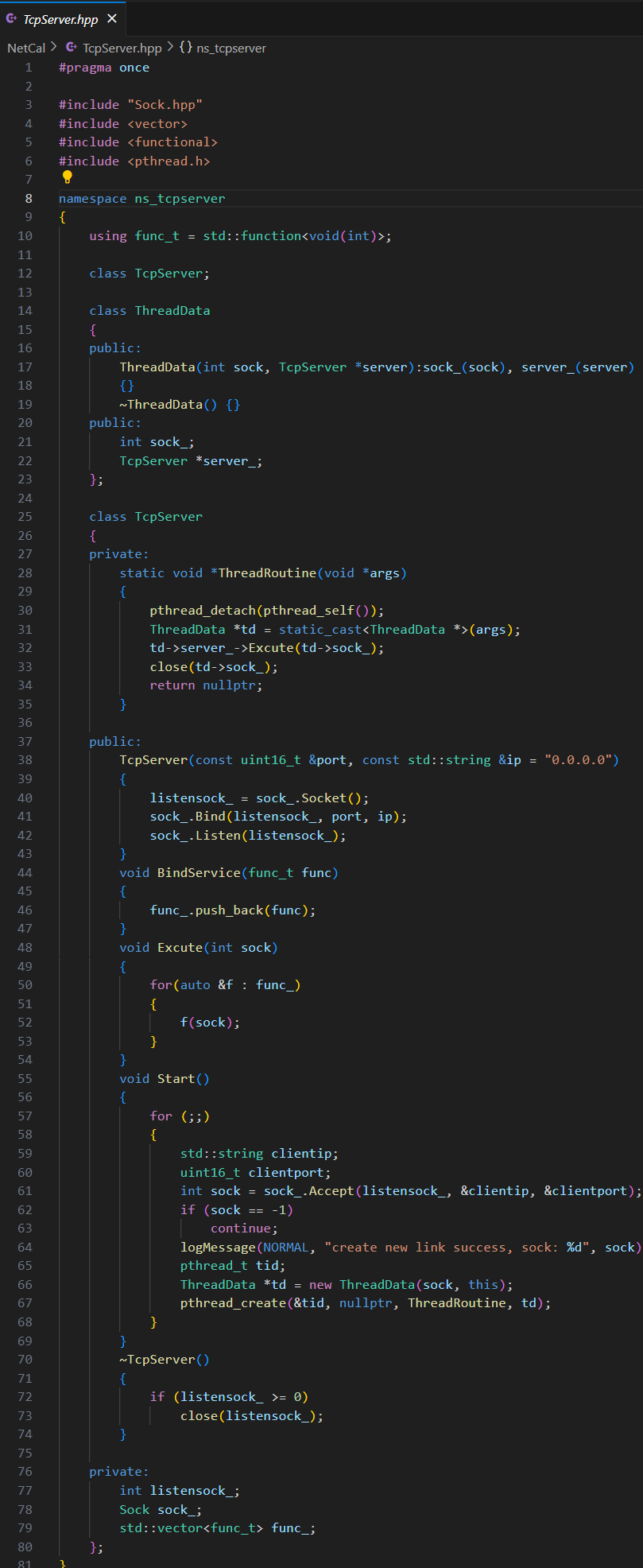
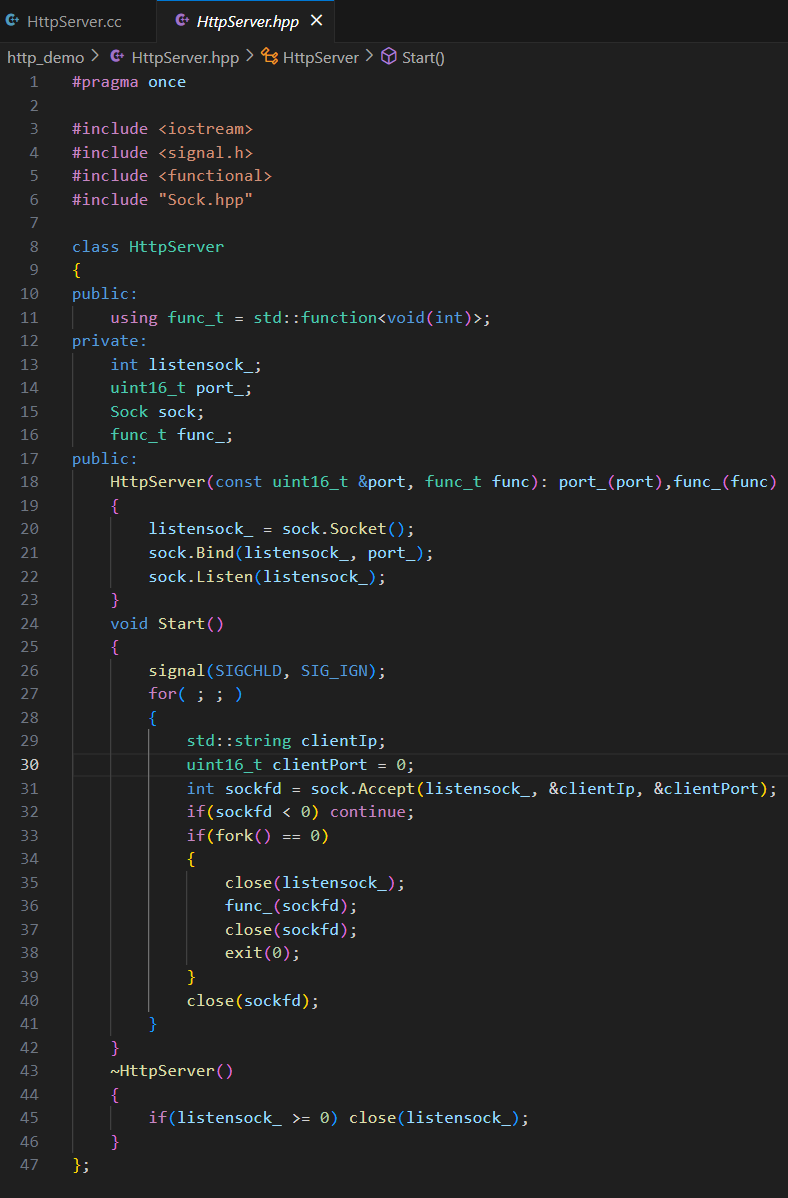
A.?服務端業務處理流程
服務端處理數據流程:
客戶端發過來的數據已經序列化成了一個序列字節流數據(報文),所以服務端要先把報文反序列化,構成一個結構化請求對象 Request,然后就可以進行計算處理,形成一個 Response 對象,再序列化后發送給客戶端。
可以看到計算處理這一步其實跟接收發送消息、序列化與反序列化沒有什么關系,所以可以把計算處理任務在服務端啟動時再傳遞進去。
計算處理函數:typedef std::function<bool(const Request& req, Response& resp)> func_t;
這里的 req 是輸入型參數(已經反序列化好的對象),resp 是輸出型參數,為了獲取計算結果。
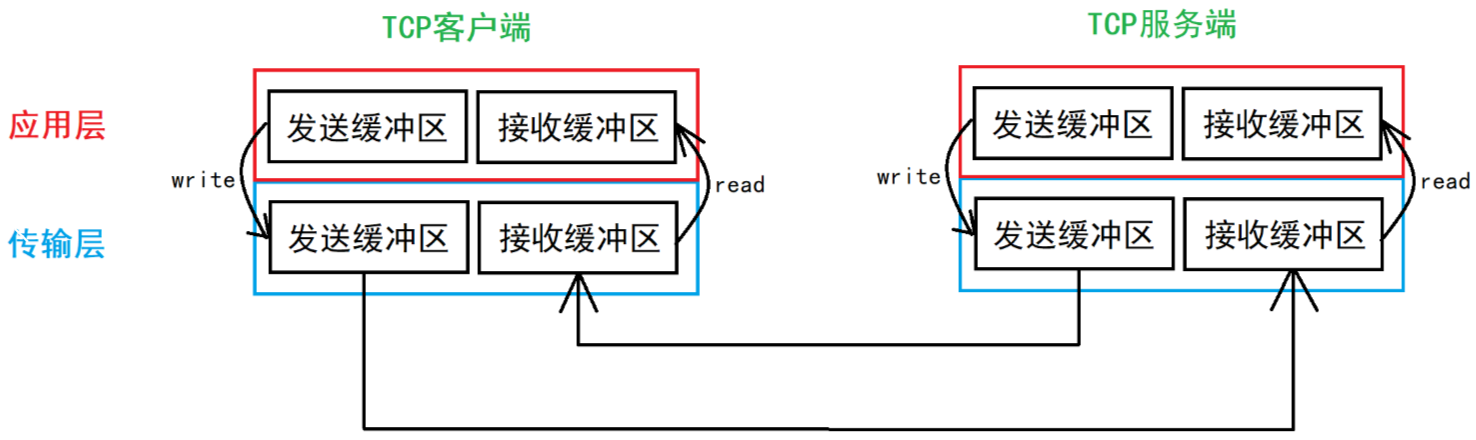
B. TCP 的發送與接收緩沖區
 ???
???
前面使用的 write 和 read 接口并不是直接往網絡里發送數據或者從網絡里讀取數據。write 其實是把數據拷貝到傳輸層的緩沖區,由?TCP 協議決定什么時候把緩沖區的數據發送到網絡中,所以 TCP 協議也叫作傳輸控制協議。
發送數據的本質是將數據從發送緩沖區拷貝到接收緩沖區。
所以,客戶端 / 服務端發送數據不會影響接受數據。所以,TCP 是全雙工的。
這就會導致一個問題,數據可能堆積在緩沖區來不及度,一次會讀取多個報文挨在一起。那該如何保證讀取完整報文呢?
看下面解釋。
C.?保證讀取完整報文
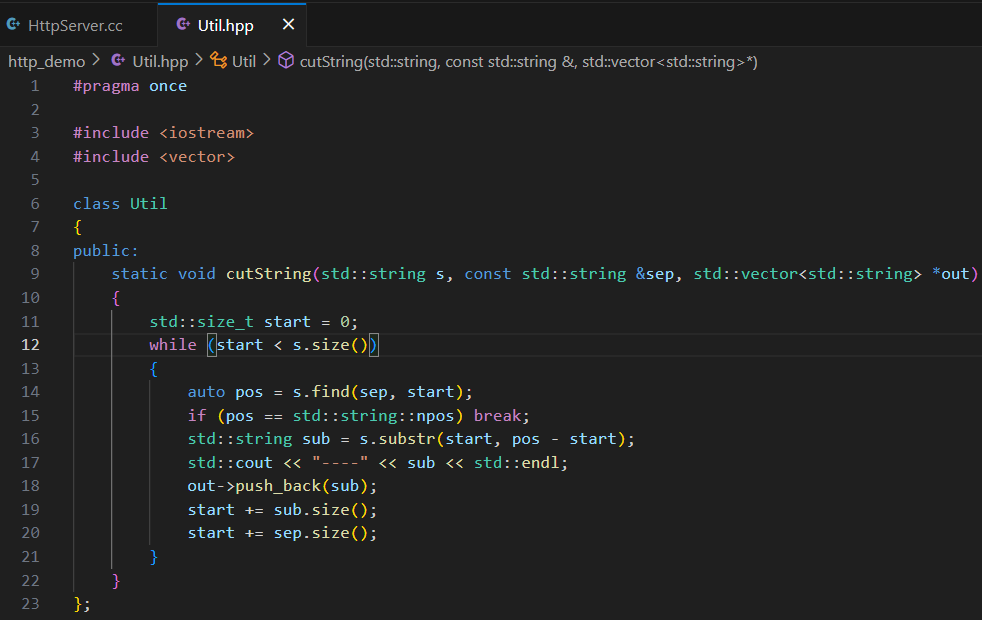
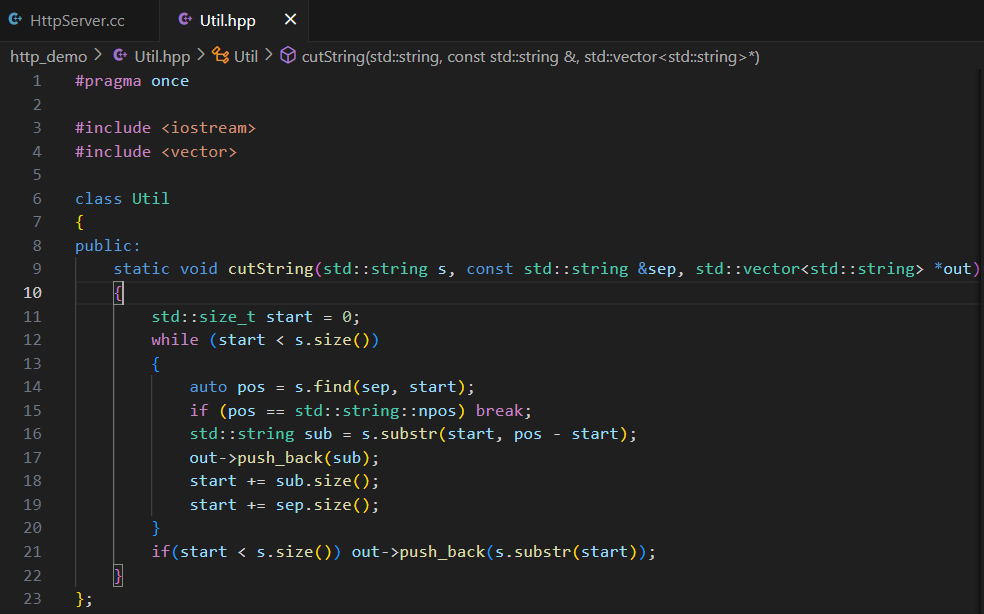
因為 TCP 是面向字節流的,所以要明確報文與報文的分界。
為什么要這樣做呢?
舉例:現在要把兩個數字合并成字符串進行發送:1、12。如果不處理的話就是 "112",如果這樣的話,反序列化時就不知道該怎么組合了。而如果我們選擇在分割的地方加一個符號,比如 ,,那么在序列化后:"1,12",自熱就很容易拆分了。
保證報文讀取完整性的方法:
- 定長: 規定長度,每次就讀取這么多。
- 特殊字符: 就是上面的方法。
- 自描述方式: 比如在報文前面帶上四個字節的字段,標識報文長度。
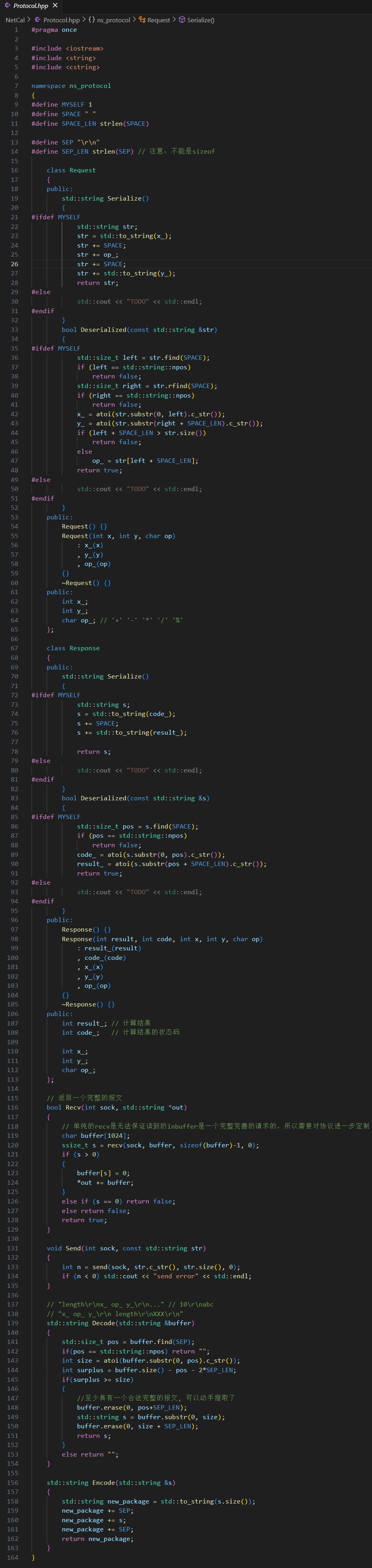
D. 自定義協議 —— 序列化與反序列化?
【請求】
請求的序列化與反序列化:
我們想要的序列化結果?"x_ op_ y_"
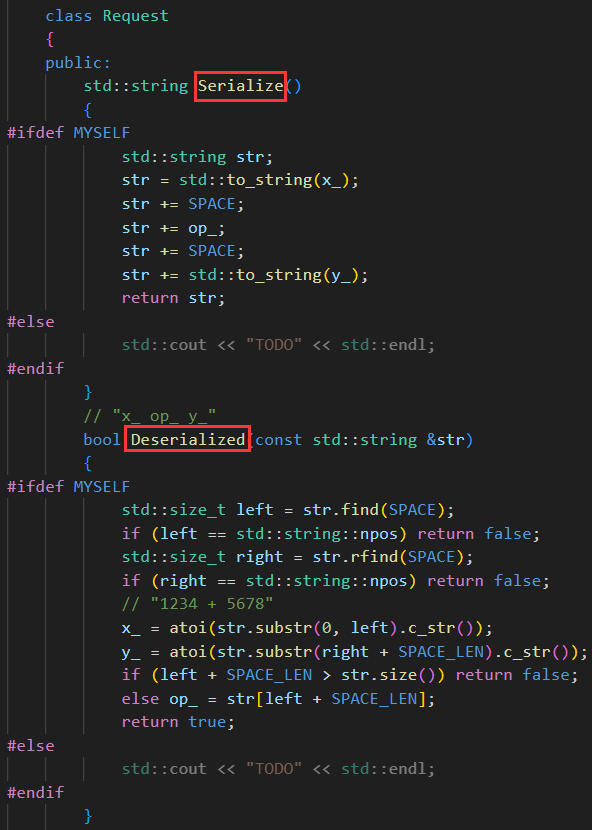
這里的反序列化將傳進去的字符串把 "\r\n"?去掉了。
【響應】
我們想要的序列化結果:"_code?_result"
響應的序列化與反序列化:
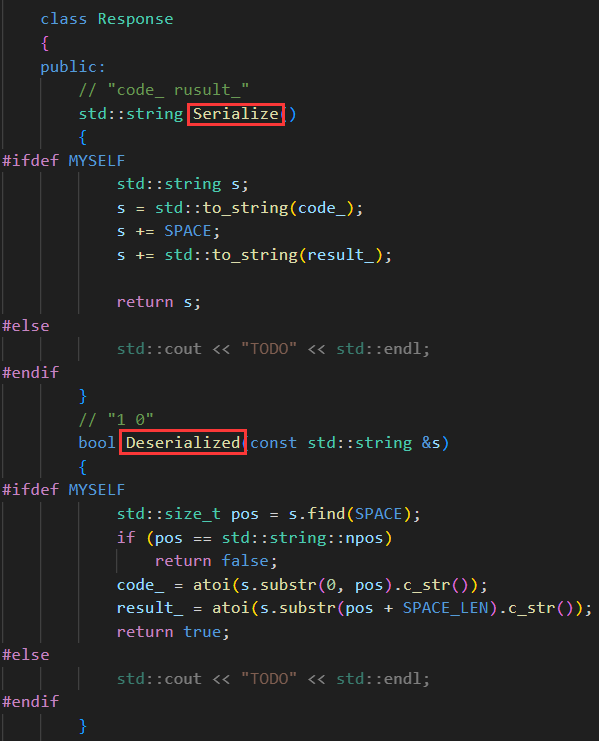
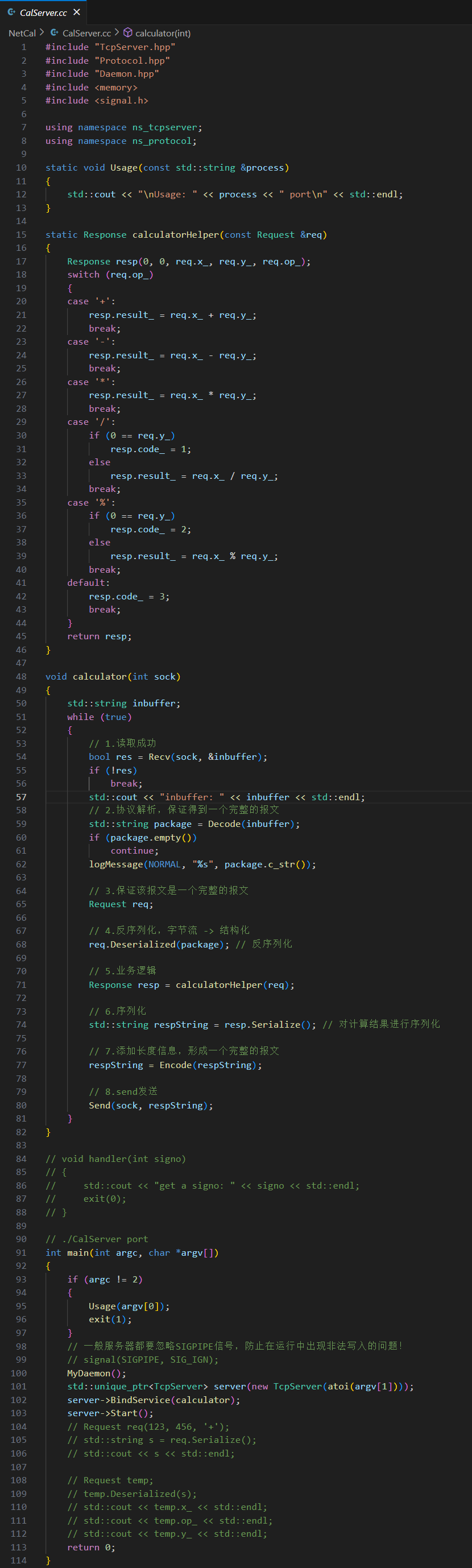
E.?計算流程
計算結果會形成一個 resp 響應,里面包含了退出碼,后續可以自己設置退出碼數值含義。
計算邏輯:
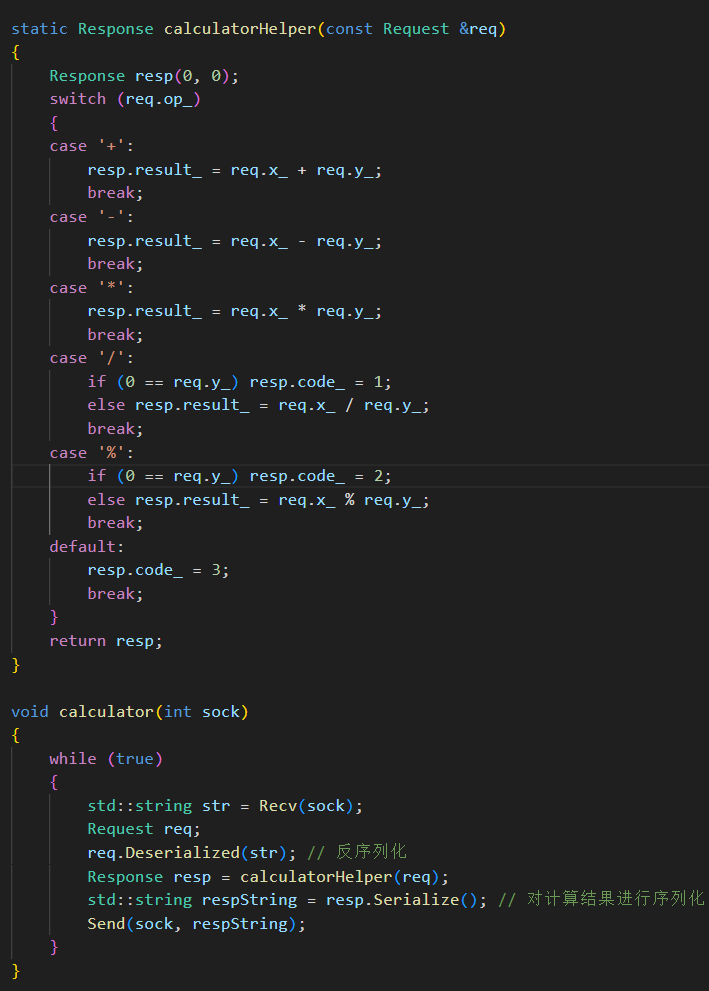
F. 在有效載荷前添加長度報頭(協議報頭)
使用特殊字符來對內容進行區分:
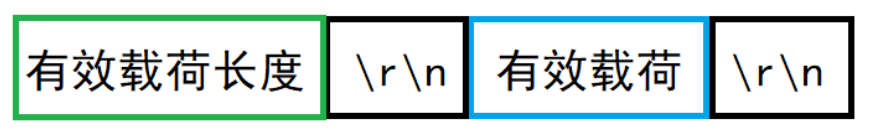
- "x_ op_ y_" -> "length\r\nx_ _op_ y_\r\n"
- "code_ result_" -> "length\r\necode_ result_\r\n"
AI寫代碼能夠保證 length 里面不會出現 '\r' 或 '\n'嗎?
能,因為 length 是一個整數,其內部不會出現任何的特殊符號。
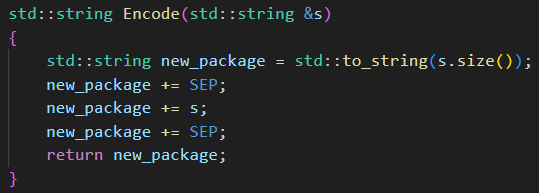
G.?發送響應 send
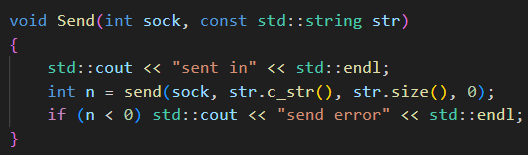
服務端收到請求到把響應發送出去的整個流程:
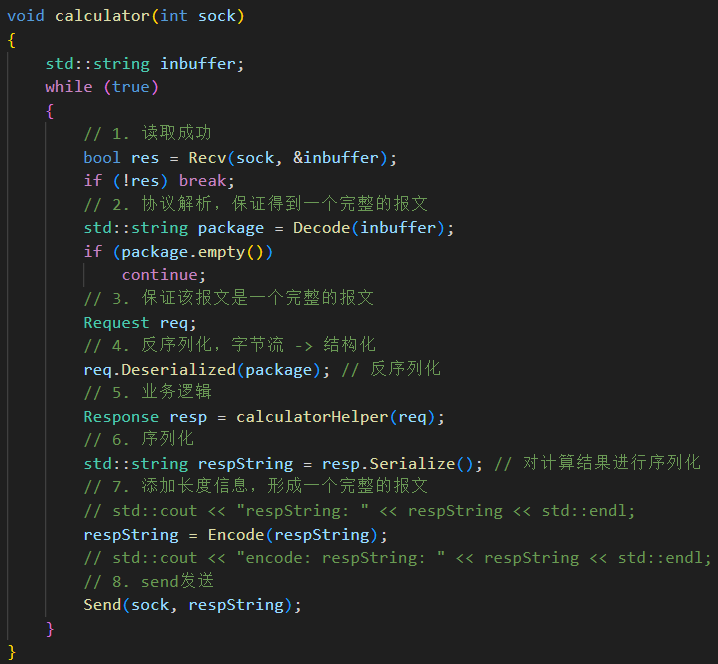
那么這里的第一步是怎么讀取請求的呢?
這個請求必須是恰好一個完整的請求。
H.??讀取一個完整的報文 recv
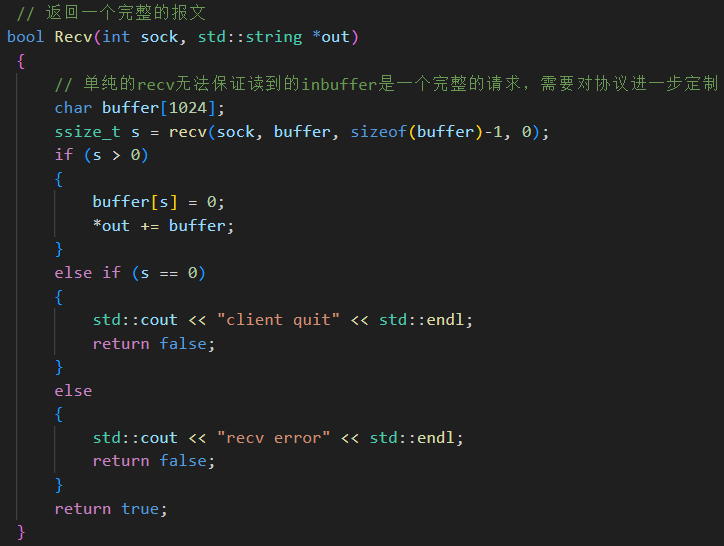
收到的請求還需要去掉報頭:
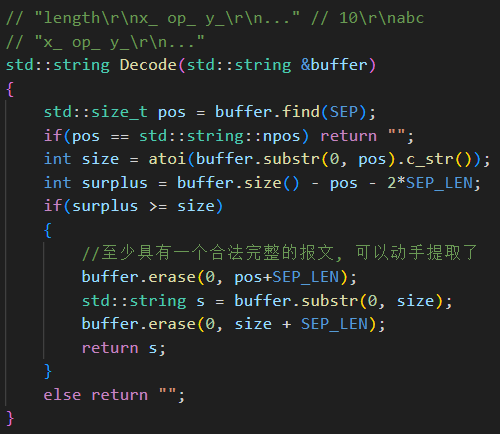
服務端的業務邏輯也就完成了:
(4)客戶端
整體流程跟服務端差不多,就是序列化請求,添加報頭,發送,接收響應,去掉報頭,反序列化,獲取結果。
(5)守護進程(精靈進程)
目前學到的所有服務器都是在前臺運行的。
什么是前臺?
和終端關聯的進程就叫作前臺。
判斷一個進程是否為前臺進程,取決于該進程能否正常獲取輸入,能否正常將輸入的內容進行處理,那么對應的進程就是前臺進程。90% 以上的情況下,bash 就是前臺進程。
只要在終端下能夠輸入內容,能讓我們輸入內容的進程就叫作前臺進程。?
任何 XShell 登陸都只允許一個前臺進程和多個后臺進程。
什么是前臺進程組?
任何時刻都只能有一個前臺進程組,當我們登錄 Windows時,就必須要給我們提供一個圖形化界面,在 Linux 下就需要(前臺進程組(可以只有一個進程))給我們加載 bash(一個任務),這就是為什么我們在登錄時要有 Shell。
如果我們把后臺進程提到前臺,那么我們的 Shell 就無法運行了,是因為只能有一個前臺進程組,bash 就會自己把自己投遞到后臺了,所以命令行解釋器就用不了了。?
所以,在命令行中啟動一個進程,在會話中啟動一個進程組來完成某種任務,所有會話內的進程 fork() 創建子進程,一般而言依舊屬于當前會話。
tips:如果電腦使用的時間長了,那么當前會話占的資源就會比較多,所以就可能會卡,那么我們可以選擇退出,注銷一下賬號,注銷就是把這個會話之前申請的資源全部釋放,然后再重新登陸,這就是為什么卡的時候可以選擇注銷(和重啟類似,但有些任務不一定通過注銷能解決)??。
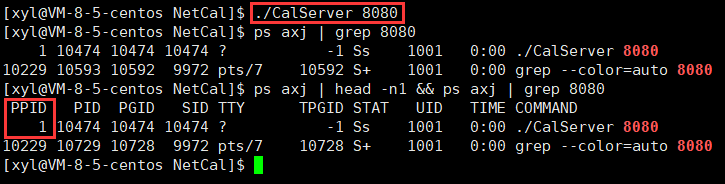
進程除了有自己的 pid、ppid 以外,還有以一個組 ID。

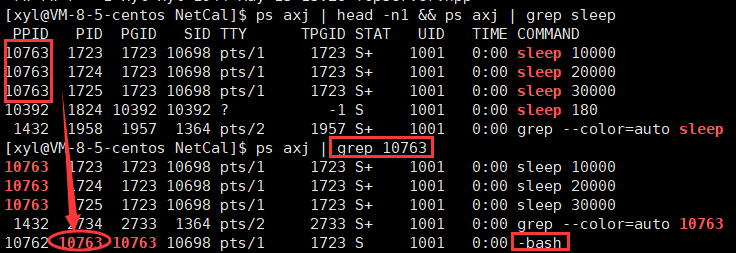
- 它的 PPID 是1(附件特征)
- COMMAND:稱為進程啟動的命令
- TIME:進程啟動時長的問題
- UID:是誰啟動的(ls-n / ls-l 就可以看見用戶的UID和我們看見的用戶名是對應的,就像之前文件名和inode的映射一樣)
- STAT:狀態
- TPGID:當前進程組和終端相關的信息(-1 就是說這個進程和中單沒有任何關系,具體數字就是和終端有關)
- TTY:代表是哪一個終端
- SID:當前進程的會話 id
在命令行中,同時用管道啟動多個進程,多個進程是兄弟關系,父進程是 bash,所以它們之間可以用匿名管道來進行通信。
同時被創建的多個進程可以成為一個進程組的概念,一般第一個進程被稱為組長。
仔細觀察上圖,可以發現還有一個 SID(會話 ID)。
最后一次登陸的用戶需要有多個進程(組)來給這個它提供服務(bash),用戶可以自己啟動很多進程或進程組。將給用戶提供服務的進程或者用戶自己啟動的所有進程或服務,整天都是要屬于一個叫作會話的機制中的。
那么我們的網絡服務器就不能屬于這個會話內,否則就會受這個會話,用戶登錄和注銷的影響(不一定會退出),所以在有網絡服務的時候就應該脫離這個會話,讓它在計算機里面形成一個新的會話(也就是自成進程組,自成新會話),自成一個會話這樣的進程就被稱為守護進程 / 精靈進程。
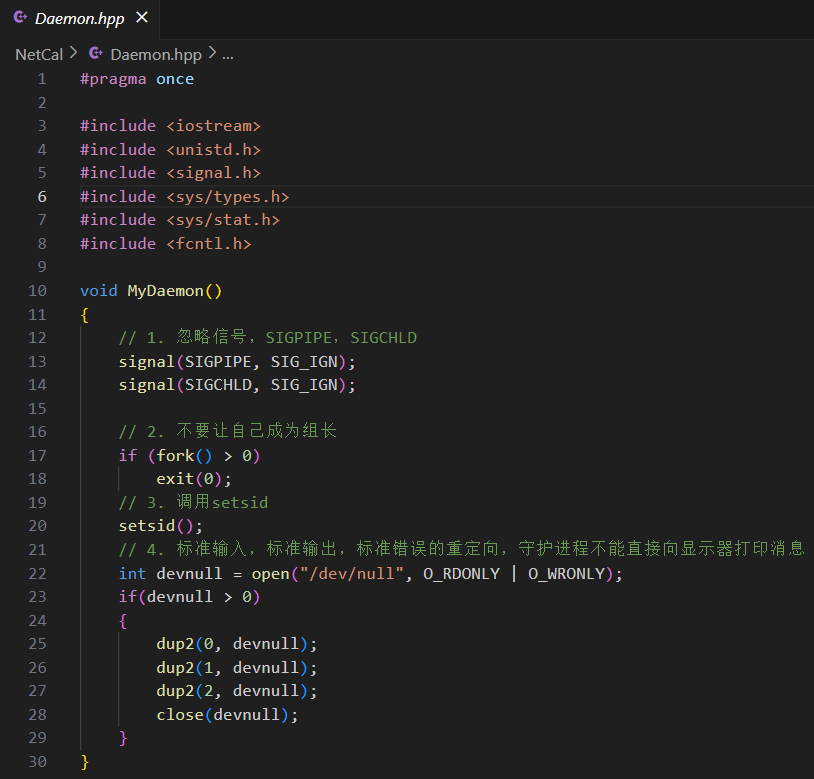
如何將自己變成自成會話呢?
調用 setsid():將調用進程設置成獨立的會話。


注意:setsid 要被成功調用就必須保證當前進程不是進程組的組長。?
如何保證我不是進程組的組長呢?
fork()
如何在 Linux 中正確的寫一個讓進程守護進程化的代碼呢??
通過自己寫一個函數,讓我們的進程調用這個函數,自動變成守護進程。
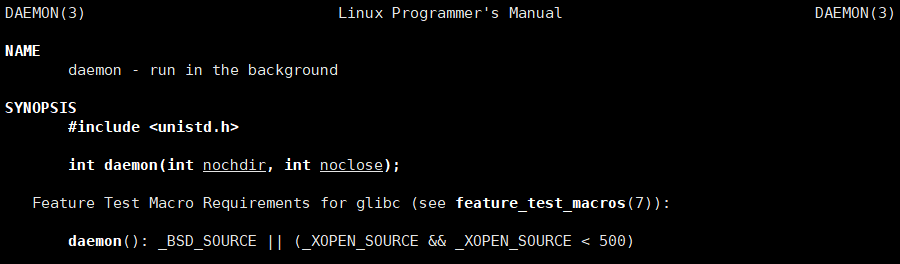

守護進程不能直接向顯示器打印消息,一旦打印就會被暫停、終止。
在 Linux 設備中,存在一個 /dev/null 的文件,它有一個特點:向其寫入的所有內容都會被自動丟棄,想從該文件中讀取內容,它不會阻塞且什么都不會讓我們讀到,如同 Linux 下的一個文件黑洞,可以讓我們進行任意操作而不影響系統運行。
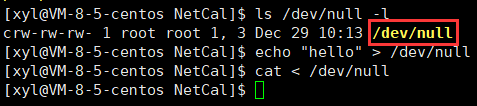
將我們的服務守護進程化,讓它變成一個網絡服務:
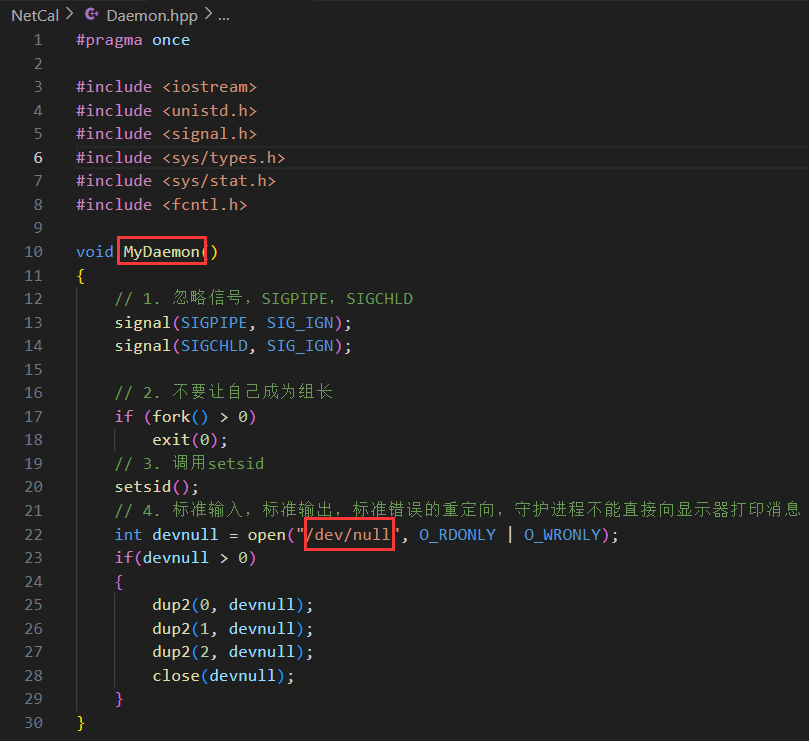
相當于服務部署到了 Linux 當中,哪怕是自己的 XShell 關了也可以 ./client 繼續用,就只能用信號殺了(一般守護進程的命名是 d 結尾)
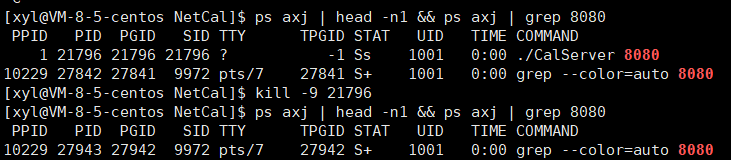
那就只能用 kill -9 殺了。
守護進程的父進程是 1 號進程,叫作被領養了,也就是說,守護進程本質是孤兒進程的一種。他和孤兒進程的區別:孤兒進程可能依舊屬于某一個會話,而守護進程自成會話。
(6)代碼
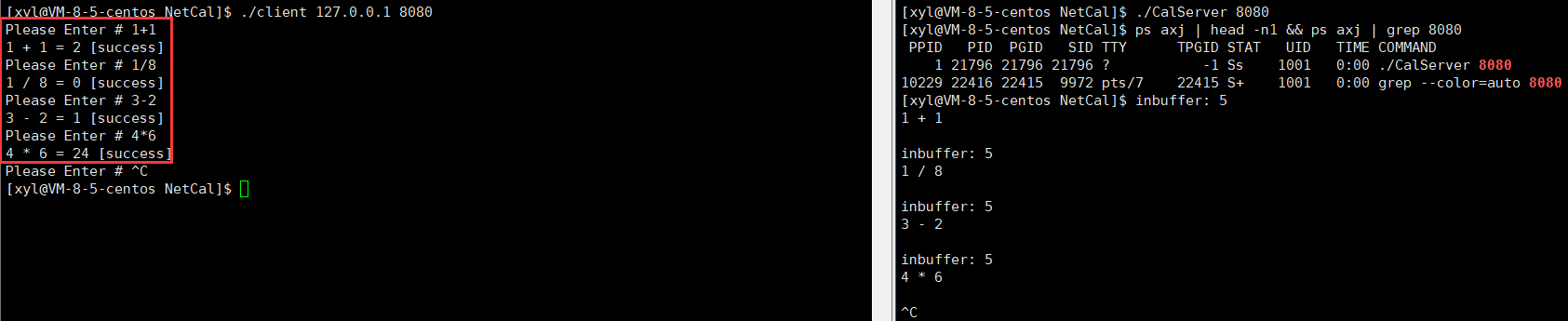
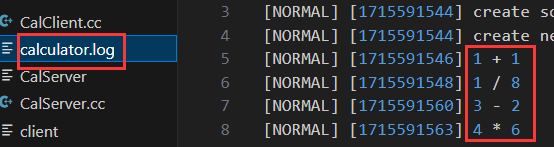
(7)結果顯示
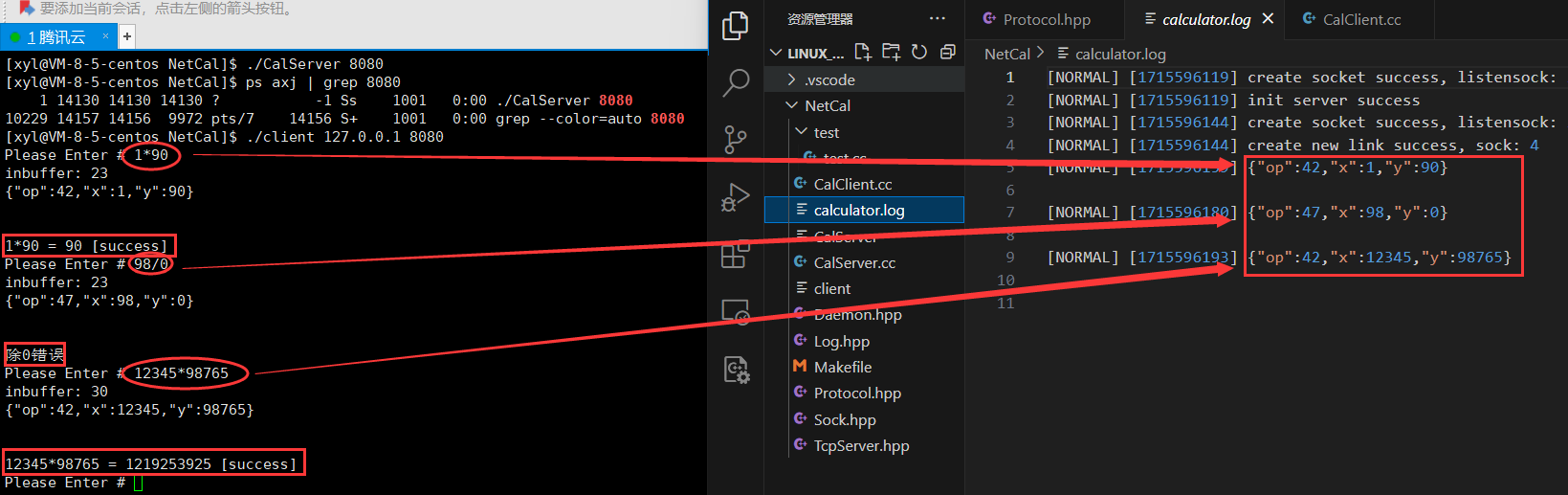
3、使用 Json 進行序列化和反序列化
序列化與反序列化 C++ 都給我們提供了 Json 的庫,可以直接使用:
Json(JavaScript Object Notation)是一種輕量級的數據交換格式,常用于 Web 應用程序中的數據傳輸。它是一種基于文本的格式,易于讀寫和解析。Json 格式的數據可以被多種編程語言支持,包括 JavaScript、Python、Java、C#、C++ 等。Json 數據由鍵值對組成,使用大括號表示對象,使用方括號表示數組。
先安裝 Json 庫:
sudo yum install jsoncpp-develAI寫代碼頭文件:#include <jsoncpp/json/json.h>
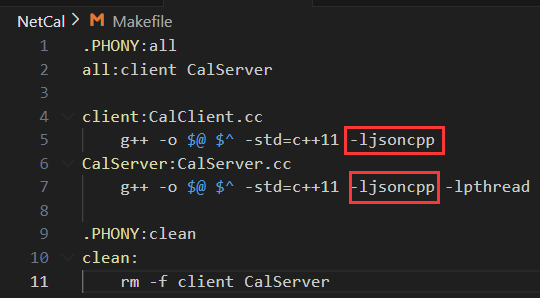
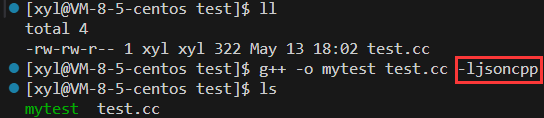
注意:使用 jsoncpp 庫記得在編譯時加上 -ljsoncpp。

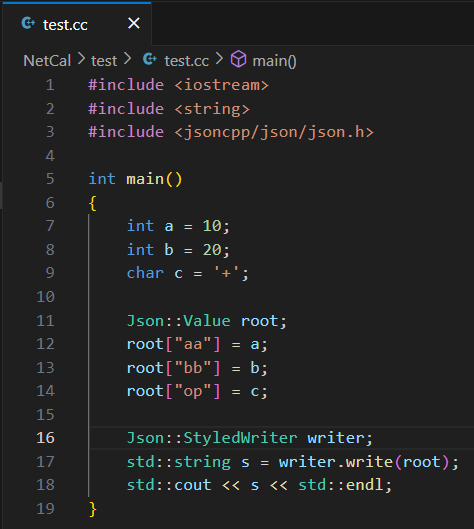
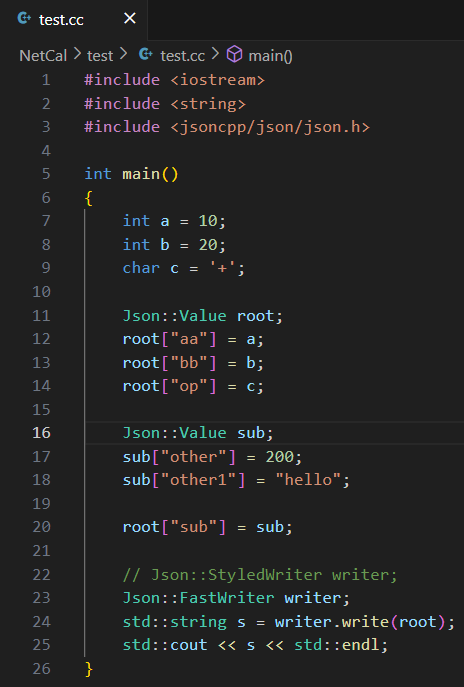
? demo 代碼
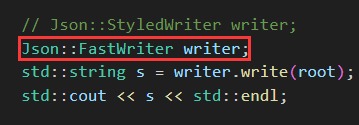
A. Json::StyledWriter
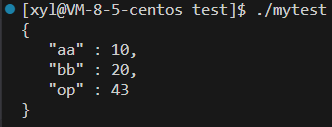
B. Json::FastWriter(顯示結果更加精簡)


二、HTTP?協議
在前面我們已經實現了網絡版的計算器中,其中對數據的處理計算就是我們自己手寫的應用層協議。應用層是程序員基于 socket 接口之上編寫的具體邏輯,做的很多工作都是和文本處理相關的(協議分析與處理),HTTP 協議具有大量的文本分析和協議處理。
在編寫網絡通信代碼時,我們可以自己進行協議的定制,但實際有很多優秀的工程師早就寫出了許多非常成熟且好用的應用層協議來供我們直接參考使用,其中最典型的就是 HTTP(超文本傳輸協議),它是一個簡單的請求-響應協議,通常運行在 TCP 之上。
1、認識URL
URL 就是我們平時俗稱的?“網址”。在全球范圍內,只要找到 url 就能訪問該資源。
協議名稱://server ip[:80]/a/b/c/d/e.html


要訪問一個服務器,ip 地址和端口號是必須要有的,有 ip 地址就可以找到這臺唯一的機器,能夠訪問到端口號就可以找到給我們提供服務對應端口的進程,可是上圖在 url 中并沒有體現出來,是因為一般在請求時,端口號是被省略的(在請求網絡服務時,對應的端口號都是眾所周知的(客戶端知道))。
使用瀏覽器訪問 URL(統一資源定位符):通過域名(server ip)找到唯一一臺網絡主機,而域名后面就是該機器提供服務的進程,接著是客戶想訪問的資源路徑,通過資源路徑找到想要的文件名,可能是圖片或者文本,把資源(客戶想訪問的資源路徑 + 客戶要的文件名)返回給瀏覽器。
HTTP 的本質就是通過 HTTP?協議從服務端拿下文件資源,而因為文件資源的種類特別多,HTTP? 都能搞定,所以叫做超文本傳輸協議。
(1)urlencode 和 urldecode
像 / ? : 等這樣的字符已經被 url 當做特殊意義理解了,所以這些字符不能隨意出現。如果用戶想在 url 中包含 url 本身用來作為特殊字符的字符,那么在 url 形式時,瀏覽器會自動給我們進行編碼 encode。
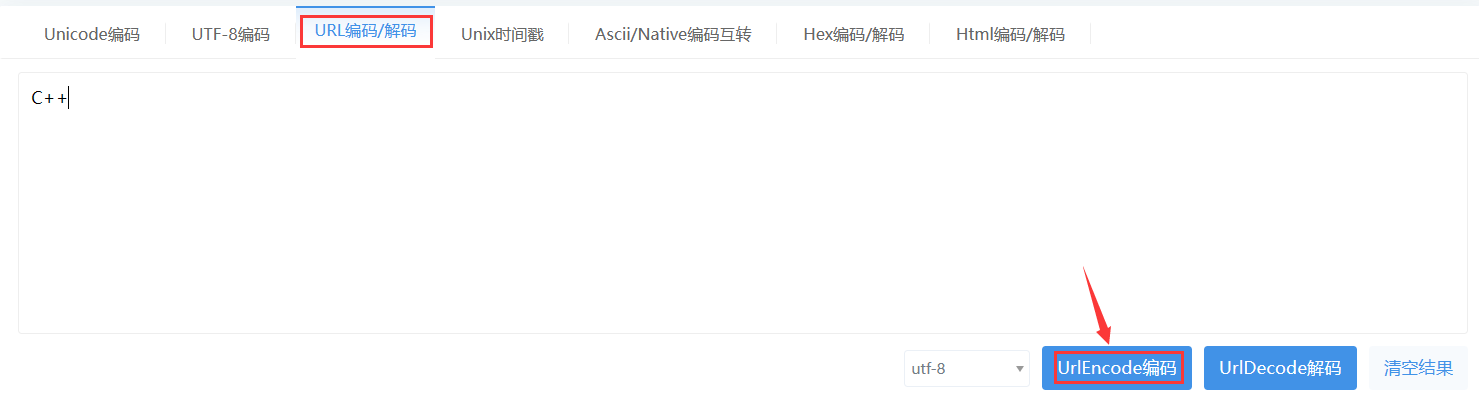
轉義的規則:取出字符的 ASCII 碼,將其轉成 16 進制,然后再在前面加上百分號即可。比如下圖,"+" 被轉成了 "%2B",這個過程就叫做 encode,decode 就是把特殊符號轉回去。
urlencode 工具:UrlEncode編碼/UrlDecode解碼 - 站長工具
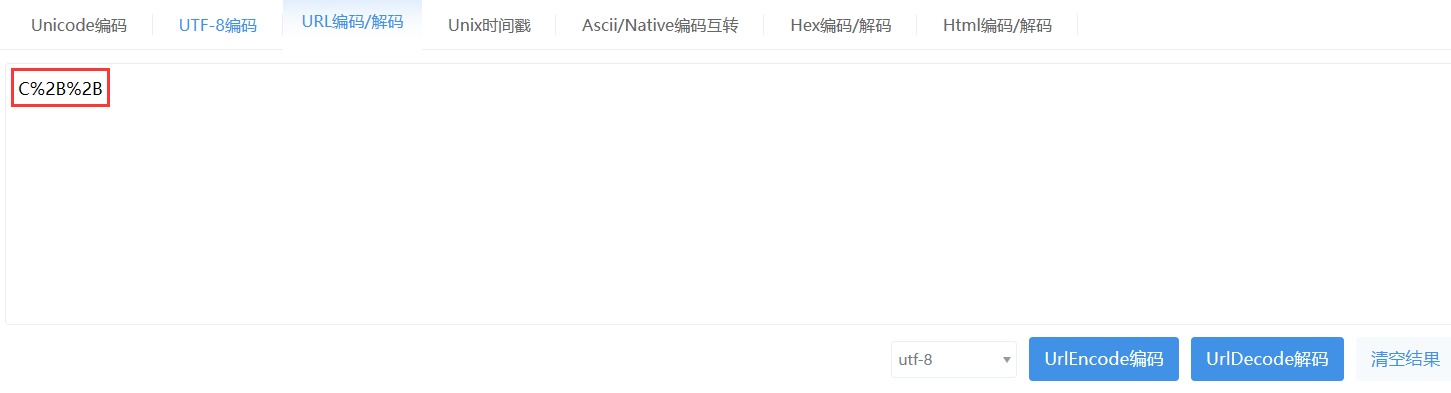
實際當服務器拿到對應的 URL 后,也需要對編碼后的參數進行解碼,此時服務器才能拿到你想要傳遞的參數,解碼實際就是編碼的逆過程。
2、HTTP協議格式
HTTP 是基于請求和響應的應用層服務,底層采用 TCP,作為客戶端可以向服務器發起 request,服務器收到這個 request 之后,會對這個 request 做數據分析,得出你想要訪問什么資源,然后服務器再構建 response,完成這一次 HTTP 的請求,返回響應。
由于 HTTP 是基于請求和響應的應用層訪問,所以必須要知道 HTTP 對應的請求格式和響應格式。
CS 模式:?
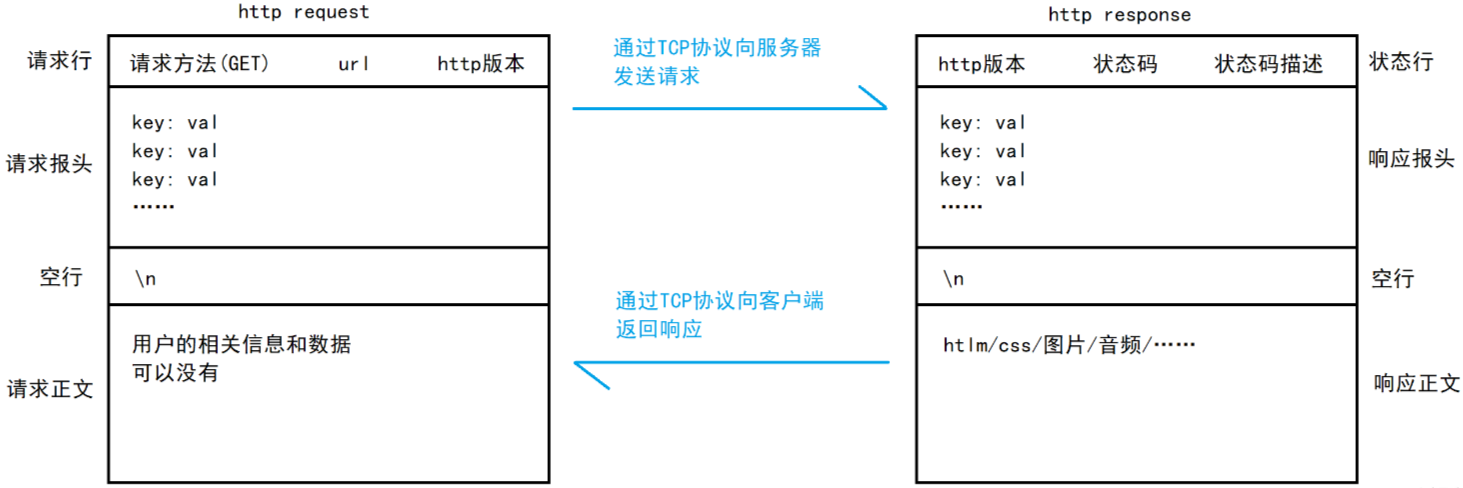
如何保證請求和響應被應用層完整讀取?
HTTP 所有請求字段都是按行為單位的字符串,比如說對于 HTTP?請求,我們使用 while 循環按行讀取,直到遇到空行為止,這樣就可以保證把請求行和請求報頭讀完。而報頭的 key:?val 結構就有一個屬性是 Content-Length: XXX,它表示的是正文的長度,由此,正文的也能完整讀取了。
如果現在我們想獲得 name 的 key 值,如何把數據從字符串中反序列化呢?
- 對于報頭部分,其實請求 / 響應報頭布置包含 name: val 信息,后邊還有字符串分隔符:name: val\r\n,序列化直接發送就行,想要反序列化就可以按照 \r\n 來按行提取,所以 HTTP?報頭是用特殊字符進行信息分離。
- 對于正文部分,不需要做處理,如果需要的話,可以設計自定義序列化與反序列化方案。
(1)HTTP 請求
- 首行:[方法] + [url] + [版本]
- Header:請求的屬性,冒號分割的鍵值對,每組屬性之間使用 \n 分隔,遇到空行表示 Header 部分結束。
- Body:空行后面的內容都是 Body,Body 允許為空字符串。如果 Body 存在,則在 Header 中會有一個 Content-Length 屬性來標識 Body 的長度。
(2)HTTP 響應
- 首行:[版本號] + [狀態碼] + [狀態碼解釋]
- Header:請求的屬性,冒號分割的鍵值對,每組屬性之間使用 \n 分隔,遇到空行表示 Header 部分結束。
- Body:空行后面的內容都是 Body,Body 允許為空字符串。如果 Body 存在,則在 Header 中會有一個 Content-Length 屬性來標識 Body 的長度,如果服務器返回了一個 html 頁面,那么 html 頁面內容就是在 body 中。
3、HTTP?的請求方法
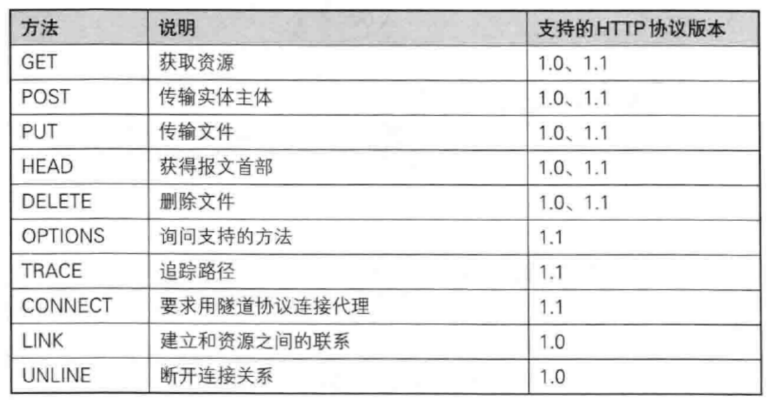
其中最常用的就是? GET? 方法和? POST? 方法。
我們平時上網的行為無非就分為兩種:
- 從服務器端獲取資源數據(GET)
- 把客戶端的數據提交到服務器(POST、GET)?
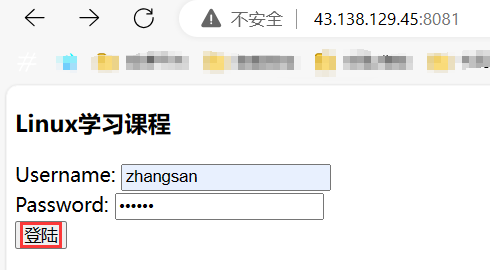
表單負責手機用戶數據并把用戶數據推送給服務器。表單中的數據會被轉成 http request 的一部分,表單被提交需要指明提交方法。
比方說我們在百度里搜索東西,要把數據提交到對應的輸入框里:

其實本質是前端通過 form 表單進行提交的,瀏覽器會自動將 form 表單里的內容轉成 GET/POST 方法請求。

(1)GET 方法
GET 方法通過 URL 傳遞參數,回顯到瀏覽器的域名當中。
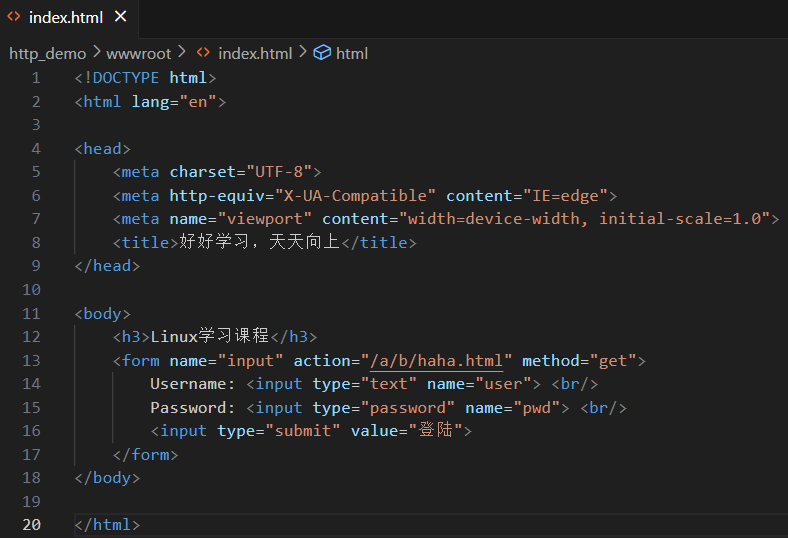
(HTML 默認大小寫不敏感)
這一塊整體就是個 form 表單,可以通過 GET 方法提交。
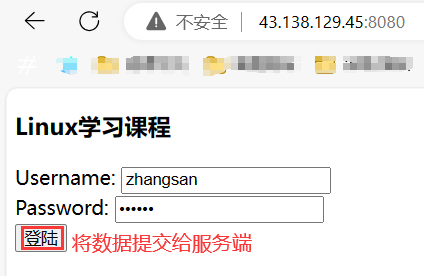
可以看到 GET 方法可以把要提交的參數拼接到到 url 的后邊:
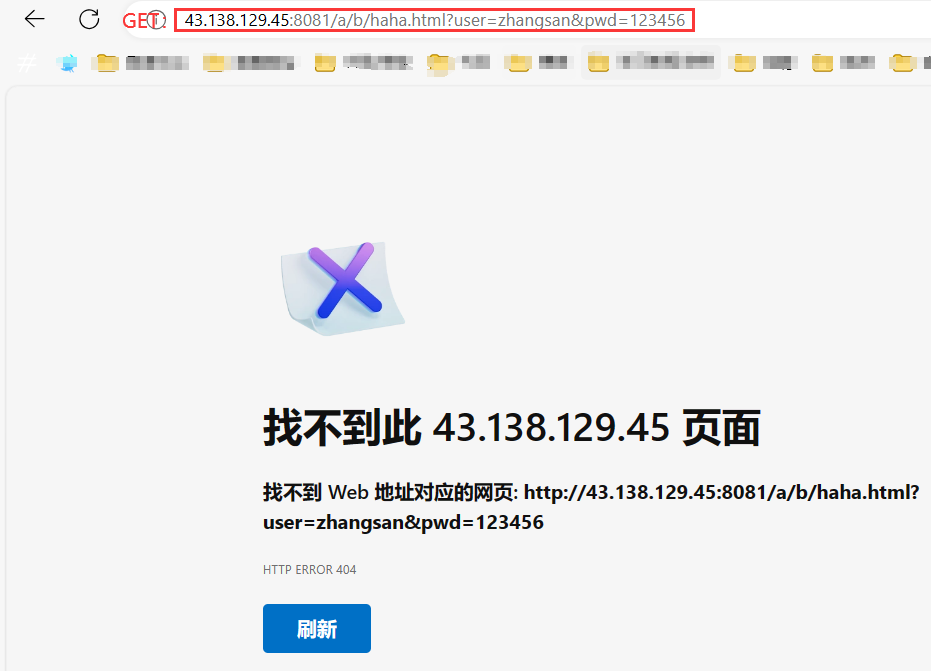

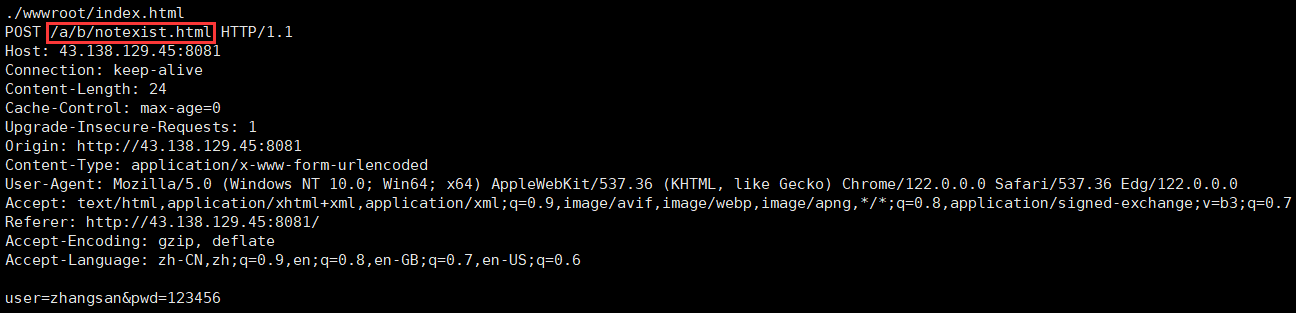
(2)POST 方法
POST 方法通過請求正文提交參數。
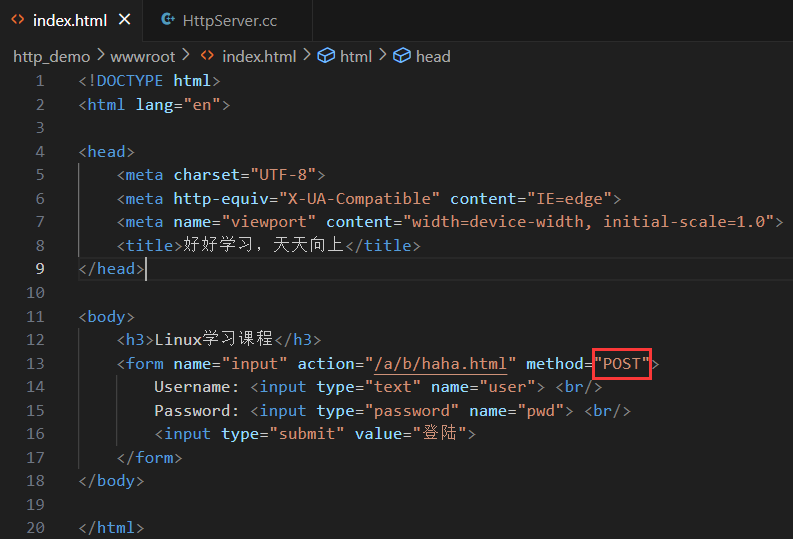
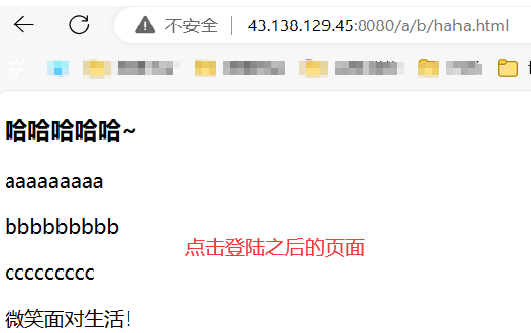
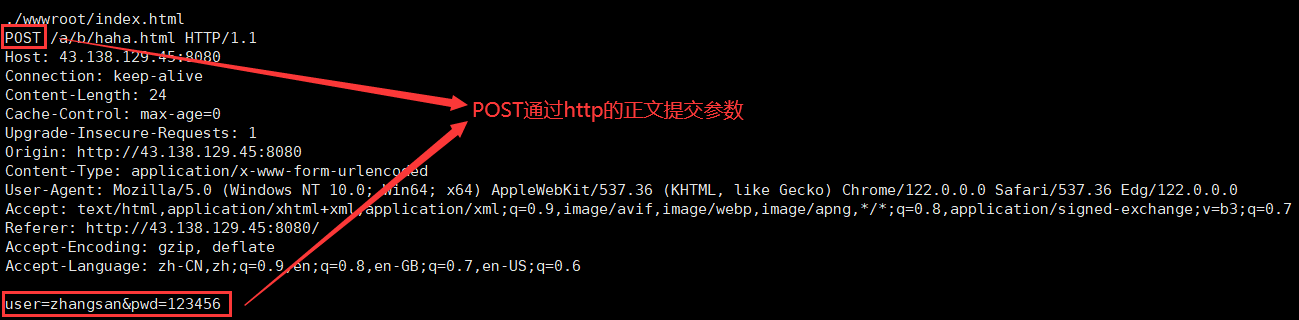
(3)總結
因為 POST 方法是通過正文傳參的,所以一般不會回顯,用戶看不到,私密性(不等于安全性,加解密才具有安全性)更好,而 GET 方法會回顯輸入的私密信息,不夠私密。但無論是 GET 還是 POST 方法都不安全(HTTP 請求都是可以被抓到的,想要安全必須加密,使用 HTTPS 協議)。一般情況下,傳遞大字段或者較為私密的數據的時候使用 POST 方法,其他的使用 GET 方法。
4、HTTP?的狀態碼?
一般情況下,HTTP 的狀態碼都要匹配上狀態碼的描述。
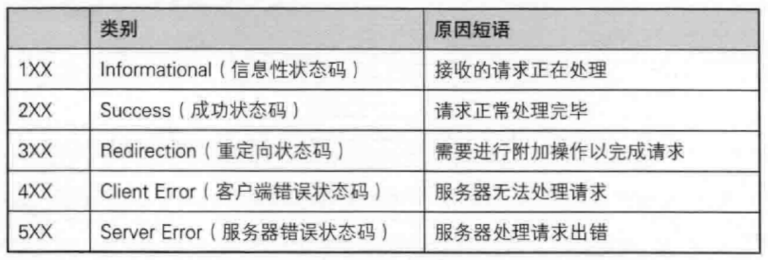
前面我們定義的狀態行中的 200 就是狀態碼:
![]()
常見的狀態碼,比如 200(OK),404(Not Found),403(Forbidden),302(Redirect,重定向),504(Bad Gateway)
(1) 3xx —— Redirection(重定向狀態碼)
重定向就是通過各種方法將各種網絡請求重新定個方向轉到其它位置(跳轉網站),此時這個服務器相當于提供了一個引路的服務。
當我們發送請求給服務端,服務端返回一個新的 url,狀態碼是 3,瀏覽器自動用這個新的 url 繼續發送請求給新的地址,所以重定向是由客戶端完成的。而重定向又分為臨時重定向和永久重定向,其中狀態碼 301(Moved Permanently)表示的就是永久重定向,而狀態碼 302(Found)和 307(Temporary Redirect)表示的是臨時重定向。
臨時重定向和永久重定向本質是影響客戶端的標簽,決定客戶端是否需要更新目標地址。
- 如果某個網站是永久重定向,那么第一次訪問該網站時由瀏覽器幫你進行重定向,但后續再訪問該網站時就不需要瀏覽器再進行重定向了,此時訪問的就是重定向后的網站。
- 如果某個網站是臨時重定向,那么每次訪問該網站時如果需要進行重定向,都需要瀏覽器來幫我們完成重定向跳轉到目標網站。
A.?臨時重定向演示
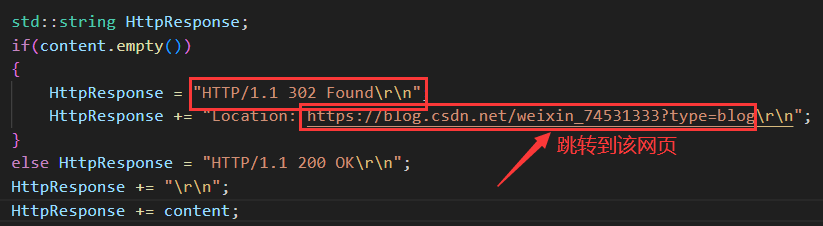
當我們訪問瀏覽器的時候自動會跳轉到我們指定的網站:
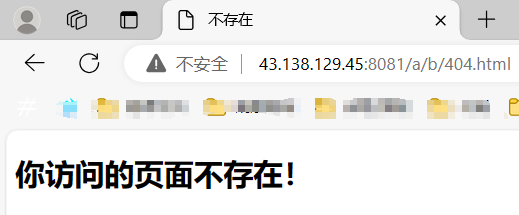
5、HTTP?常見的?Header 信息
- Content-Type:數據類型(text / html 等)。
- Content-Length:Body 的長度。
- Host:客戶端告知服務器, 所請求的資源是在哪個主機的哪個端口上。
- User-Agent:聲明用戶的操作系統和瀏覽器版本信息。
- referer:當前頁面是從哪個頁面跳轉過來的。
- location:搭配 3xx 狀態碼使用,告訴客戶端接下來要去哪里訪問。
- Cookie:用于在客戶端存儲少量信息,通常用于實現會話(session)的功能。
(1)?Content-Length
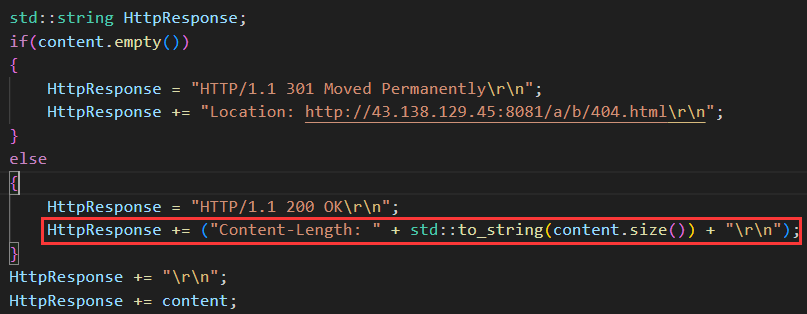
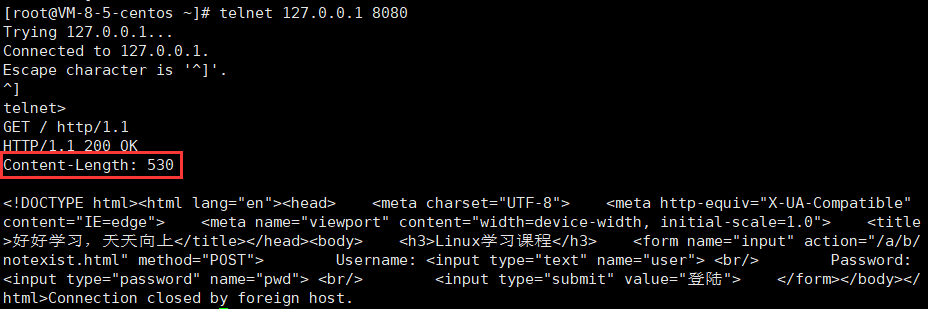
6、HTTP 會話保持(Cookie &?Session)
HTTP 的特征:
- 簡單快捷
- 無連接
- 無狀態
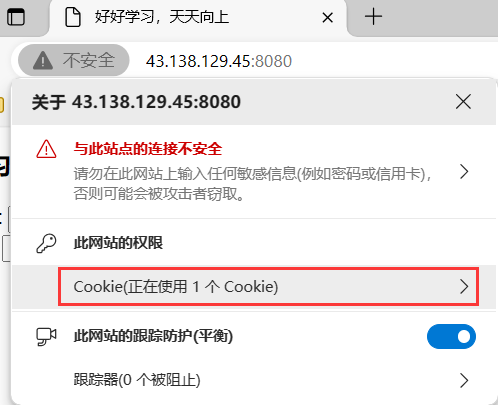
HTTP 實際上是一種無狀態協議,每次請求并不會記錄它歷史上請求過什么。HTTP 的每次請求/響應之間是沒有任何關系的,但在使用瀏覽器時發現并不是這樣的,比如在登錄一次 CSDN 后,就算把 CSDN 網站關閉甚至重啟電腦,當再次打開 CSDN 網站時,CSDN 并沒有要求我們再次輸入賬號和密碼,這實際上是通過 Cookie 技術實現的,點擊瀏覽器當中鎖的標志就可以看到對應網站的各種 Cookie 數據。
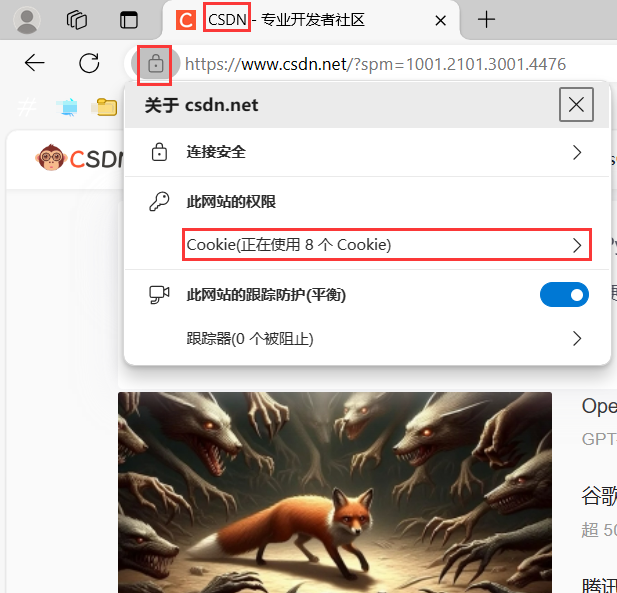
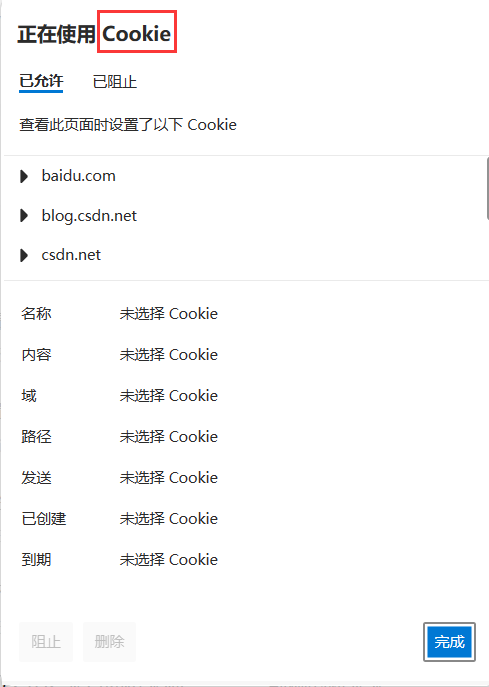
這些 cookie 數據實際都是對應的服務器方寫的,如果你將對應的某些 cookie 刪除,那么此時可能就需要你重新進行登錄認證了,因為你刪除的可能正好就是你登錄時所設置的 cookie 信息。
結論:會話保持不是 HTTP 協議天然具備的特點,而是瀏覽器為了滿足用戶的使用需求,做了相應的工作。
如何做到的呢?
用戶在第一次輸入賬號和密碼時,瀏覽器會進行保存(Cookie),近期再次訪問同一個網站(發送 http 請求),瀏覽器會自動將用戶信息添加到報頭中推送給服務器。這樣只要用戶首次輸入密碼,一段時間內將不用再做登錄操作了。
這種把用戶名和密碼保存起來的技術叫做 Cookie 技術,而 Cookie 又分為 Cookie 內存和 Cookie 文件。
(1)內存級別與文件級別
Cookie 就是在瀏覽器當中的一個小文件,文件里記錄的就是用戶的私有信息。Cookie 文件可以分為兩種,一種是內存級別的 Cookie 文件,另一種是文件級別的 Cookie 文件。
- 將瀏覽器關掉后再打開,訪問之前登錄過的網站,如果需要你重新輸入賬號和密碼,說明你之前登錄時瀏覽器當中保存的 Cookie 信息是內存級別的。
- 將瀏覽器關掉甚至將電腦重啟再打開,訪問之前登錄過的網站,如果不需要你重新輸入賬戶和密碼,說明你之前登錄時瀏覽器當中保存的 Cookie 信息是文件級別的(真實的文件,保存在磁盤,進程退出也不影響)。
(2)Cookie 安全問題
本地的 Cookie 如果被不法分子拿到了,那么此時這個非法用戶就可以用我們的 Cookie 信息,以我們的身份去訪問我們曾經訪問過的網站,將這種現象稱為 Cookie 被盜取了。
為了保證安全,我們可以把信息保存在服務端,在服務端形成一個文件:Session 文件,而因為有很多 Session 文件,所以給每個文件一個名字:Session ID。并將其返回給瀏覽器,瀏覽器存到 Cookie 的其實是 Session id。接下來我們把 Session ID?放到請求中,然后發送到服務端,在服務端獲取登錄信息(鑒權)。目前只保證了用戶信息的泄漏,接下來只能靠服務端的安全策略保障安全,例如賬號被異地登錄了,服務端察覺后只要讓 session id 失效即可,這樣異地登錄就會讓用戶重新驗證賬號密碼或手機或人臉信息(盡可能確保是本人),一定程度上保障了信息的安全。
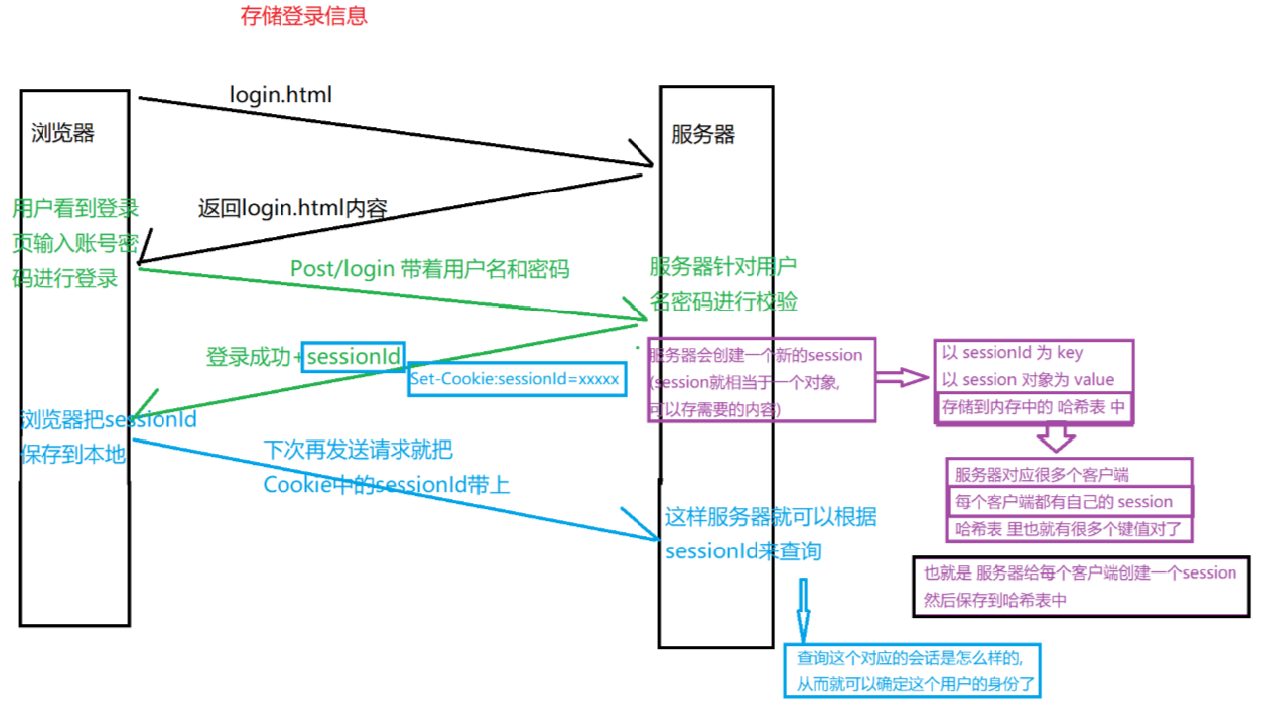
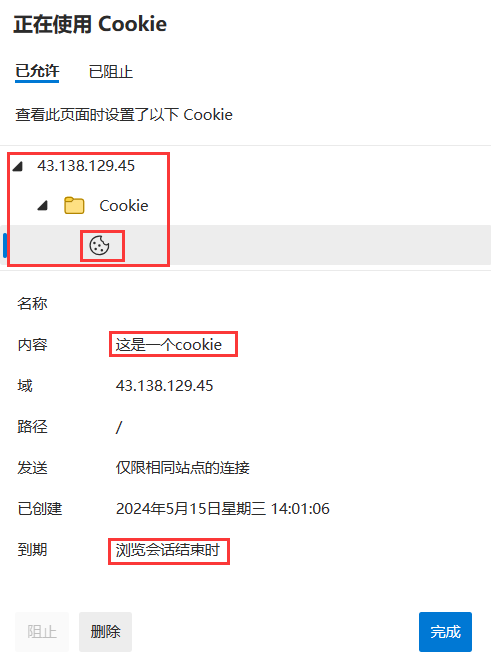
(3)寫入 Cookie 信息
就是向發送給瀏覽器的響應中寫入報頭中。
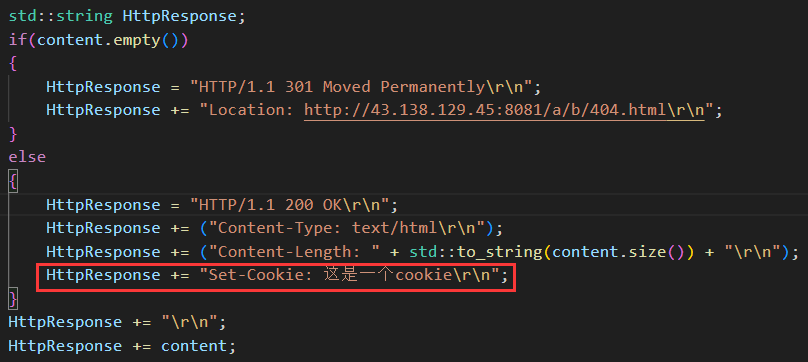
?7、HTTP 長連接
HTTP 請求是基于 TCP 協議的,而 TCP 是需要進行連接的。對于一個完整的網頁來說,可能包含多種元素資源,那就需要發起多次 Connect。為了減少連接次數,需要客戶端和服務器均支持長鏈接,建立一條連接,傳輸完后不斷開連接,一直傳遞資源,不用頻繁創建連接。如果是短連接請求了一份資源后就會自動關閉連接。
客戶端和服務端怎么知道是否是長連接呢?
在報頭信息中會有 Connection 字段。
AI寫代碼
8、簡單的?HTTP 服務器
(1)代碼驗證請求格式
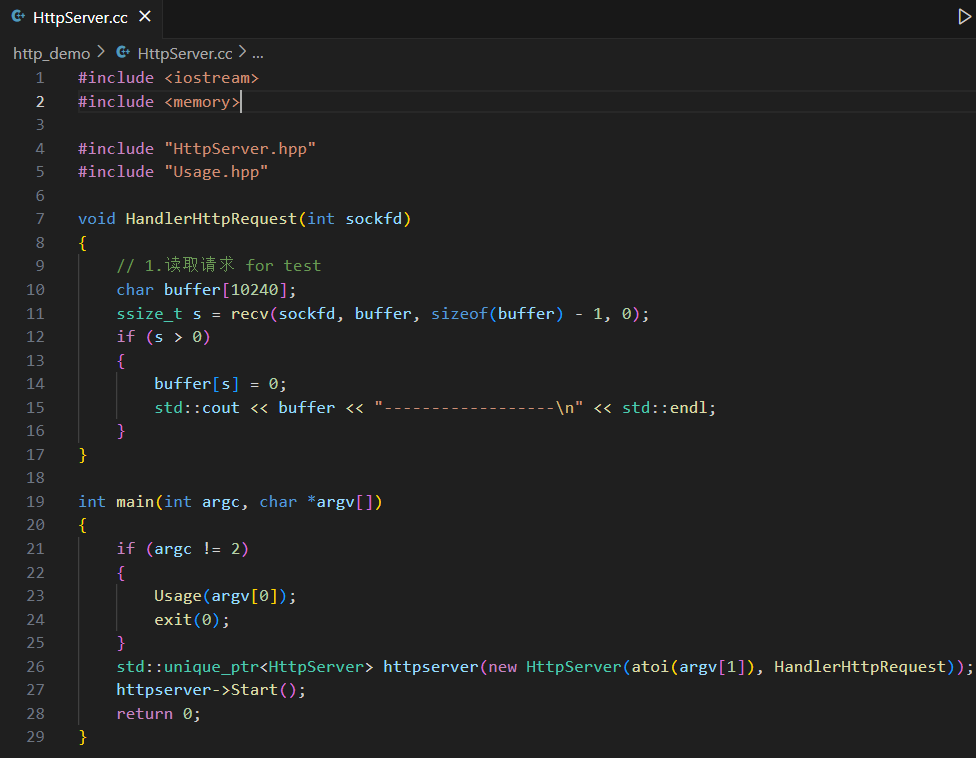
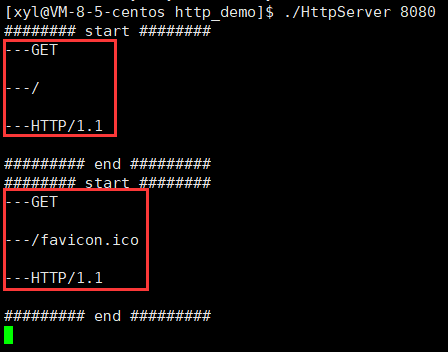
這里實現的就是一個簡單的 TCP 服務器,而處理的任務就是把接收到的 HTTP 請求進行打印即可,服務器會把收到的數據全部放入請求緩沖區,然后直接打印出來。客戶端并不用我們自己實現,有一個現成的客戶端就是瀏覽器。
![]()

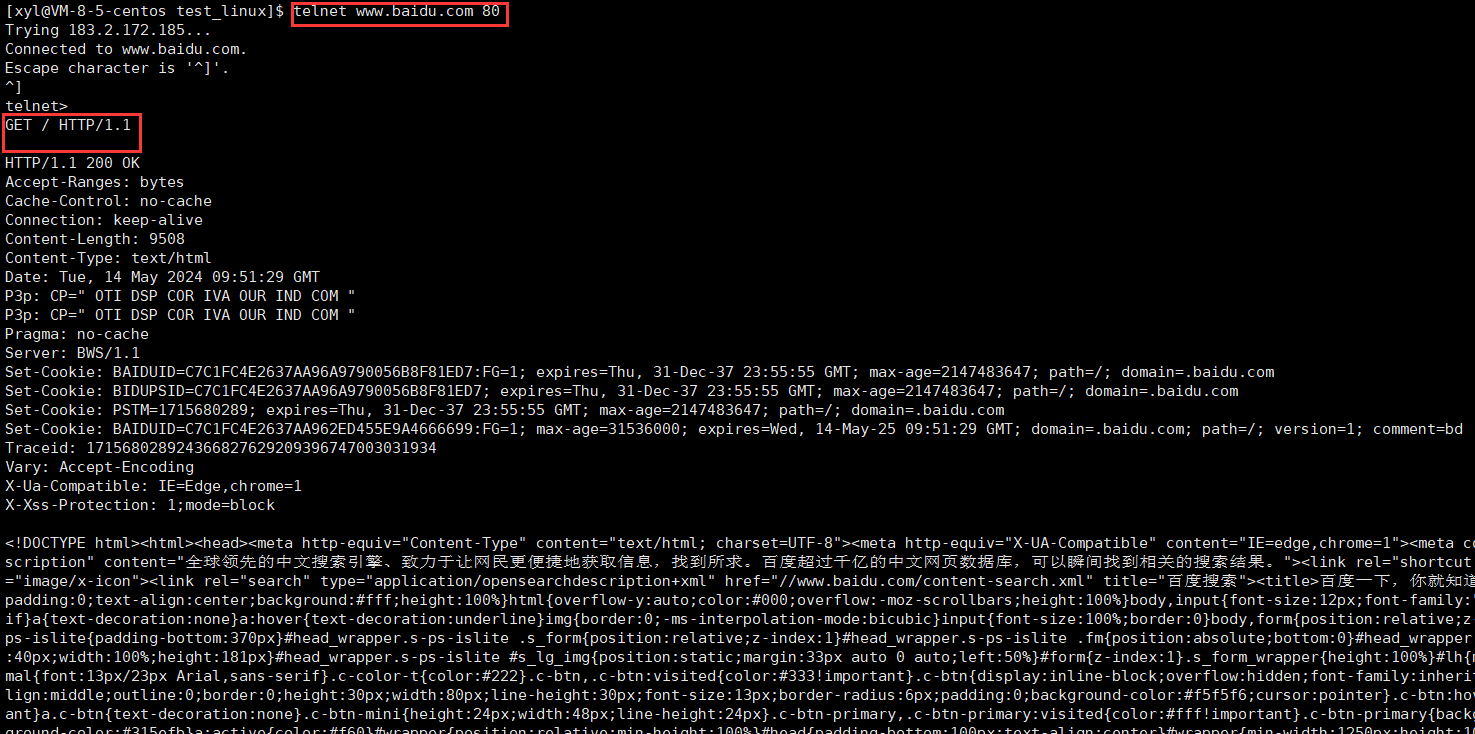
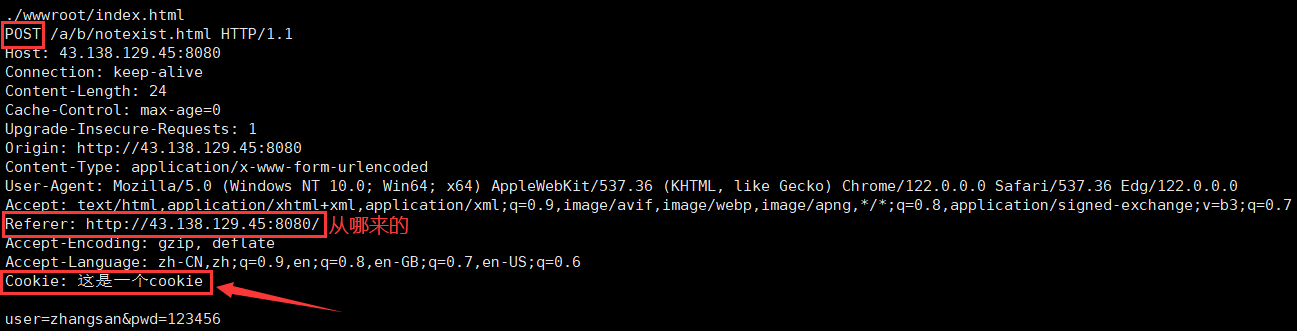
說明以下收到的請求:
對于請求行 GET / HTTP/1.1(Get 表示請求方法)
- / 表示 url:url 當中的 / 不能稱之為我們云服務器上根目錄,這個 / 表示的是 web 根目錄,這個 web 根目錄可以是我們機器上的任何一個目錄,是可以自己指定的,不一定就是 Linux 的根目錄。


- HTTP/1.1?表示協議版本。
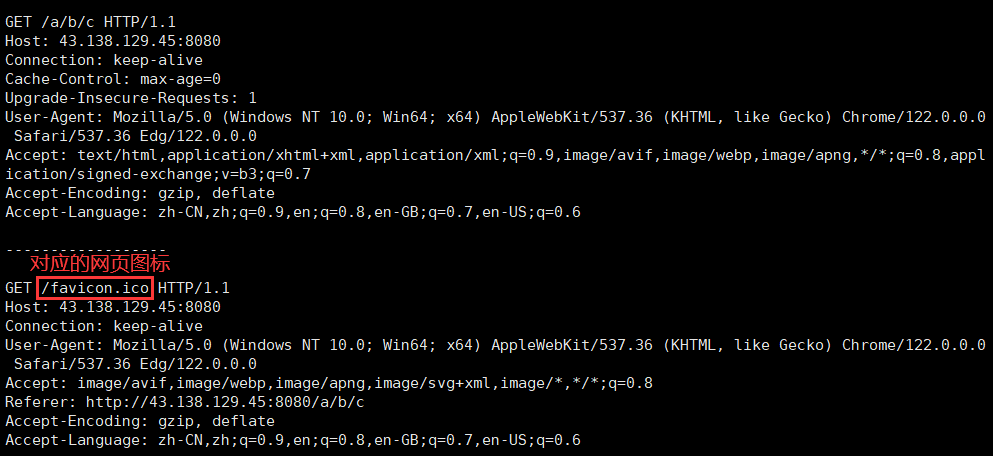
注意 :此處我們使用 9090 端口號啟動了 HTTP 服務器。雖然 HTTP 服務器一般使用 80 端口,但這只是一個通用的習慣,并不是說 HTTP 服務器就不能使用其他的端口號。使用 Chrome 測試我們的服務器時,可以看到服務器打出的請求中還有一個 GET /favicon.ico HTTP/1.1 這樣的請求。
為什么請求要包含版本?
因為客戶端的會存在更新的情況,但是有的客戶端并沒有更新,所以服務端要根據版本來提供不同的服務。
而請求報頭進過驗證也是 name: val?的格式,里面都是屬性字段。?
(2)代碼驗證響應格式
A. telnet 命令
telnet 是一種用于遠程訪問和管理計算機網絡設備、服務器和服務的協議和命令行工具。它可以用于連接到運行 Telnet 服務器軟件的任何計算機,并在遠程計算機上執行命令和操作。
通常我們會使用該命令傳參測試我們自己的服務器與其他的服務器是不是能正常訪問。
- telnet [ip地址] [端口]
-
- telnet 127.0.0.1 8080
AI寫代碼當使用 Telnet 命令連接到遠程 IP 地址和端口時,如果連接成功,則會返回響應:
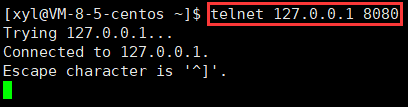
- Trying 127.0.0.1…:表示正在嘗試連接指定的 IP 地址
- Connected to 127.0.0.1.:表示連接已經建立
- Escape character is ‘^]’.:是提示信息,表示可以使用 Ctrl + ] 來退出 Telnet 命令。


(3)解析狀態行信息

目的是把請求狀態行的信息解析出來:
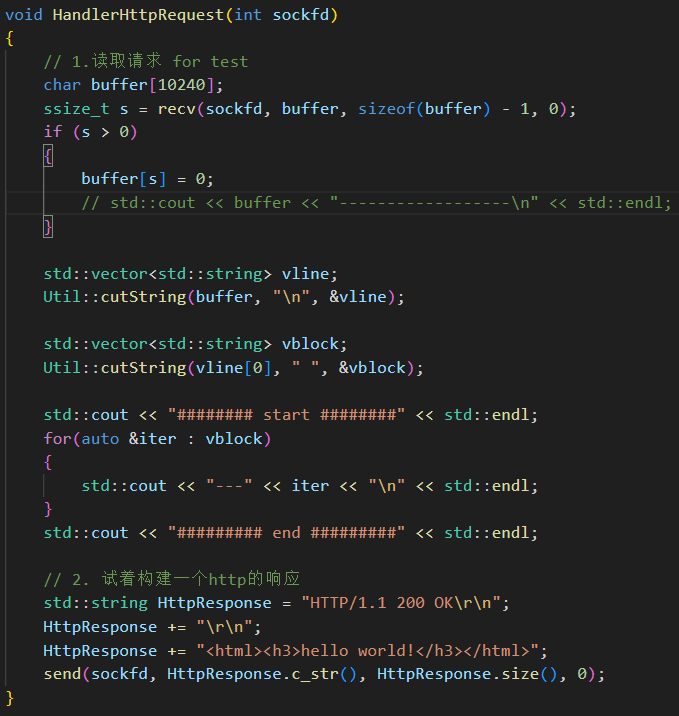
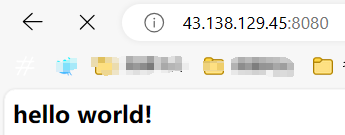
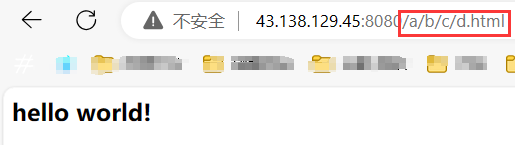
(4)web 根目錄
上圖的 url 中的 / 是 web 根目錄,這個根目錄可以自己設置,比如果我們就設置在當前路徑下:

以后我們想要訪問的資源就從 wwwroot 目錄下開始,未來的所有資源放在這個目錄里,可以通過 url 請求,例如:./wwwroot/a/b/c
如果直接是 ./wwwroot 呢?
此時就可以獲得主頁資源。
(5)獲取服務器資源
讀取資源其實就是讀取文件。
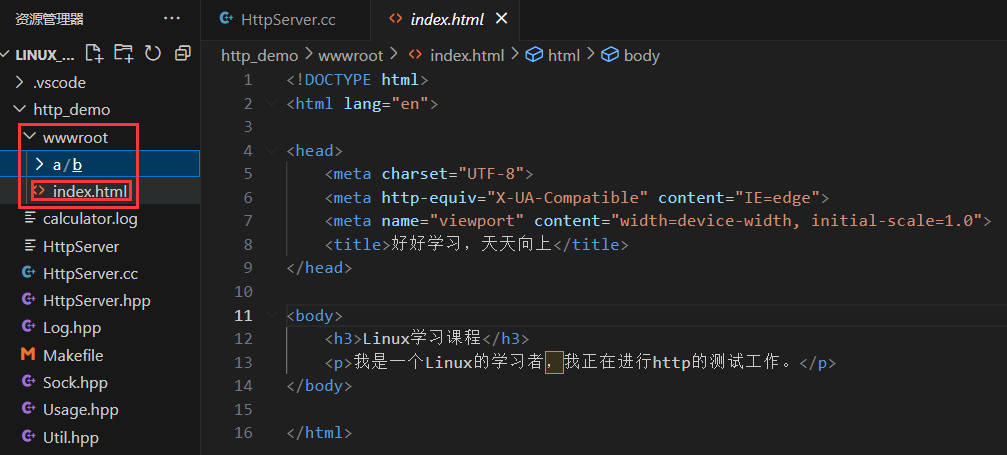
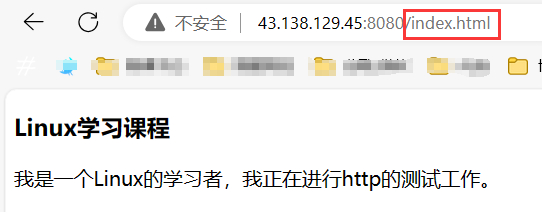
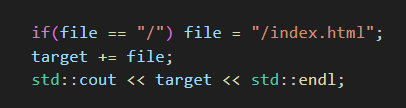
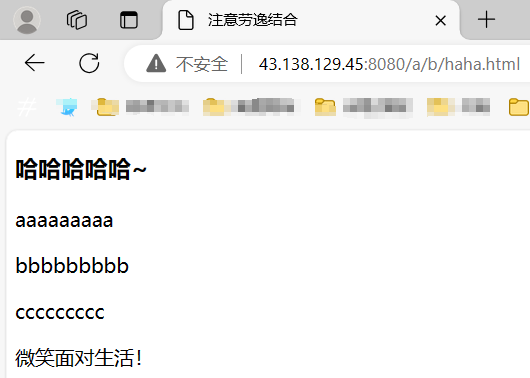
此時,如果客戶端只請求了一個 /,直接返回默認首頁:
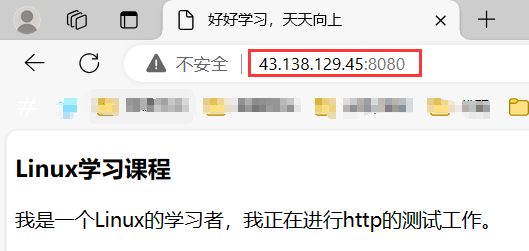
加幾個資源文件來獲取試試看:
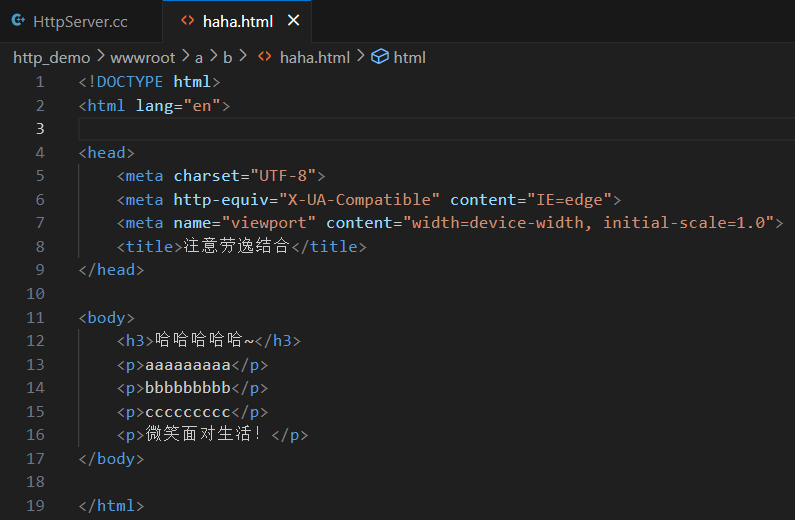
三、HTTPS 協議
1、HTTPS 是什么
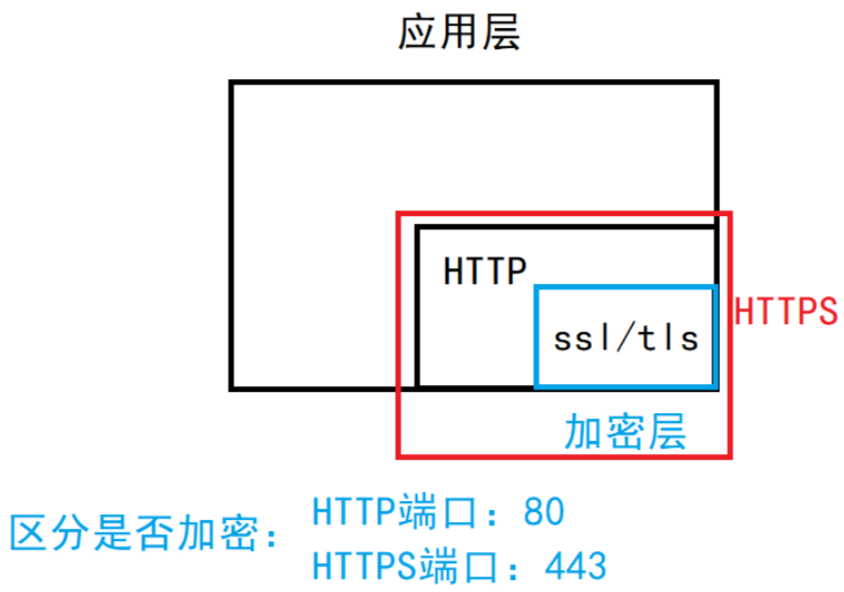
TLS/SSL:可選的,一般負責加密和解密。
HTTPS 也是?個應用層協議,是在 HTTP 協議的基礎上引入了?個加密層。發送和接收必須用同一種方式(HTTP 或者 HTTPS)區分就用端口號。由于經過加密層,所以在 網絡中是密文發送,在應用層是明文的,保證了數據在網絡中的安全。HTTP 協議內容都是按照?本的方式明文傳輸的,這就導致了在傳輸過程中出現?些被篡改的情況。
2、加密和解密
(1)什么是加密和解密
加密 就是把明文(要傳輸的信息)進行?系列變換,生成密文。解密 就是把密文再進行?系列變換,還原成明文。在這個加密和解密的過程中,往往需要?個或者多個中間的數據來輔助進行這個過程,這樣的數據稱為 密鑰 。安全 :破解的成本遠遠大于破解的收益。
舉例:有 a 和 key,現在要對 a 加密,那么就讓它們異或得到密文:b = a^key,當我想要把密文解密時,再異或一次 key 即可:a ^ key ^ key = a。這里我們把 a 叫做原始數據,b 叫做密文,key 叫做密鑰。
加密解密到如今已經發展成?個獨立的學科:密碼學,而密碼學的奠基人也正是計算機科學的祖師爺之?,艾倫·?席森·圖靈,計算機領域中的最高榮譽就是以他名字命名的 “圖靈獎”?。
(2)為什么要加密和解密
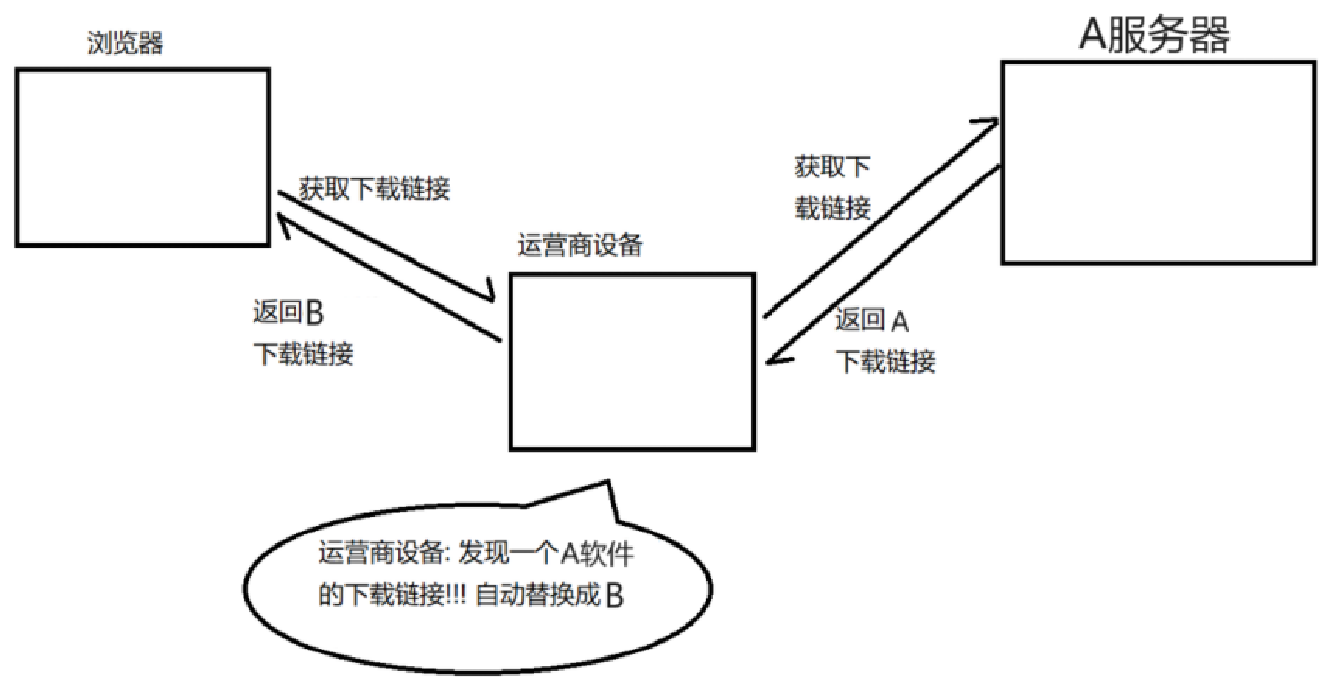
在下載時可能會出現的情況:明明要下載的是 A 軟件,但實際下載下來的卻是 B 軟件。為什么會出現這種情況呢?
由于我們通過網絡傳輸的任何的數據包都會經過運營商的網絡絡設備(路由器,交換機等),那么運營商的網絡設備就可以解析出你傳輸的數據內容并進行篡改。點擊 “下載按鈕” 其實就是在給服務器發送了?個 HTTP 請求,獲取到的 HTTP 響應其實就包含了該 APP 的下載鏈接。運營商劫持之后就發現這個請求是要下載 A 軟件,那么就自動的把交給用戶的響應給篡改成 B 軟件的下載地址了。
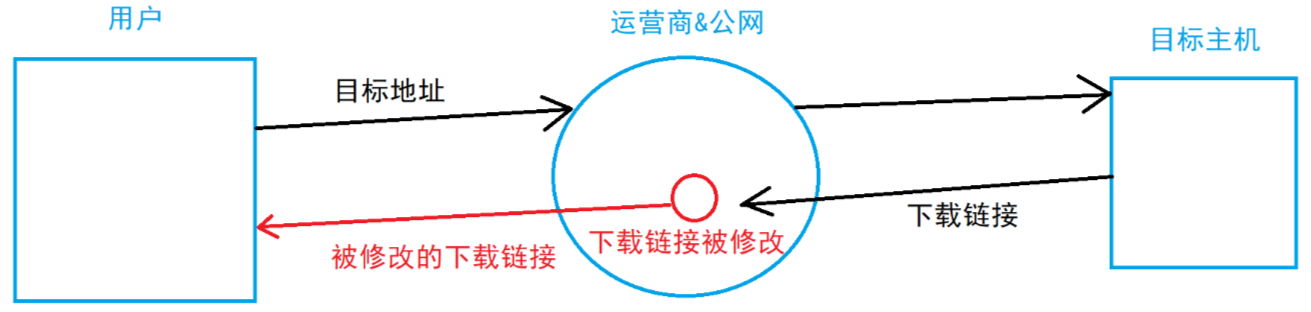
因為?HTTP 的內容是明文傳輸的,明文數據會經過路由器、Wifi 熱點、通信服務運營商、代理服務器等多個物理節點,如果信息在傳輸過程中被劫持,傳輸的內容就完全暴露了。劫持者還可以篡改傳輸的信息且不被雙方察覺,這就是中間人攻擊 ,所以才需要對信息進?加密。
不止運營商可以劫持,其他的黑客也可以用類似的手段進行劫持,以此來竊取用戶的隱私信息或者篡改內容。如果黑客在用戶登陸支付寶時獲取到用戶的賬戶余額,甚至獲取到用戶的支付密碼等。
在互聯網上,明文傳輸是比較危險的事情。
HTTPS 就是在 HTTP 的基礎上進行了加密,進?步的來保證用戶的信息安全。
(3)常見的加密方式
A. 對稱加密
采用單鑰密碼系統的加密方法,同?個密鑰可以同時用作信息的加密和解密,這種加密?法稱為對稱加密,也稱為單密鑰加密。
- 特征:加密和解密所用的密鑰是相同的。
- 常見對稱加密算法(了解):DES、3DES、AES、TDEA、Blowfish、RC2 等。
- 特點:算法公開、計算量小、加密速度快、加密效率高。
按位異或就是一個簡單的對稱加密。假設明? a = 1234,密鑰 key = 8888,則加密 a ^ key 得到的密? b 為 9834,然后針對密文?9834 再次進行運算 b ^ key,得到的就是原來的明文?1234。(對于字符串的對稱加密也是同理,每?個字符都可以表示成?個數字)
當然,按位異或只是最簡單的對稱加密,不過 HTTPS 中并不是使用按位異或。
B. 非對稱加密
需要兩個密鑰 來進行加密和解密,這兩個密鑰是公開密鑰 (public key,簡稱公鑰)和私有密鑰(private key,簡稱私鑰)。
- 特征:公鑰和私鑰是配對的。最大的缺點就是運算速度非常慢,比對稱加密要慢很多。
- 常見非對稱加密算法(了解):RSA,DSA,ECDSA。
- 特點:算法強度復雜、安全性依賴于算法與密鑰但是由于其算法復雜,而使得加密解密速度沒有對稱加密解密的速度快。
通過公鑰對明文加密變成密文,通過私鑰對密文解密變成明文。也可以反著用,通過私鑰對明文加密變成密文,通過公鑰對密文解密變成明文。
非對稱加密的數學原理比較復雜,涉及到?些數論相關的知識。舉例:A 要給 B ?些重要的文件,但是 B 可能不在,于是 A 和 B 提前做出約定:B 說:“我桌子上有個盒子,然后我給你?把鎖,你把文件放盒子里用鎖鎖上,然后我回頭拿著鑰匙來開鎖取?件。”
在上面這個場景中,這把鎖就相當于公鑰,鑰匙就是私鑰。公鑰給誰都行(不怕泄露),但是私鑰只有 B 自己持有,持有私鑰的人才能解密。
如何理解加密的安全性?
不存在不可被破解的加密,我們可以從算力成本角度來分析:比如我們加密的成本是 100 塊,而解密的花費卻要 100 億,這種我們就可以稱為是安全的。
(4)數據摘要 && 數據指紋
現在有一篇很大的文章,我們可以通過哈希函數把這個文章處理成一個固定長度字符串,現在就選修改了一個標點符號,字符串也會變化。把這個固定長度的字符串就叫做 hash 摘要,而這個過程就叫做數據摘要。
- 摘要常見算法:MD5、SHA1、SHA256、SHA512 等。
- 算法把無限的映射成有限,因此可能會有碰撞(兩個不同的信息,算出的摘要相同,但是概率非常低)。
- 摘要特征:和加密算法的區別是:摘要嚴格意義不是加密,因為沒有解密,只不過從摘要很難反推原信息,通常用來進行前后數據對比,觀察數據是否被修改過,也可以用于實現網盤的秒傳功能、公司數據庫密碼存儲等。
A. 網盤秒傳功能
比方說我們很多人都想保存同一個電影到網盤中,如果網盤把每個人的請求全部保存起來, 那么會浪費很多空間。其實只用保存一份形成 hash 摘要,當另一個用戶也要保存同一部電影時,要先形成摘要,然后在網盤中的一大堆摘要中進行對比,如果有這個摘要,那么直接建立映射關系即可,不需要再保存。
數據密碼存儲同理,把密碼形成摘要,因為涉及到密碼的東西都要進行加密。
每次用戶登錄時都將轉換成哈希摘要與數據庫的哈希摘要進行對比,所以數據庫泄露也不怕。因為摘要是把無限變有限,所以可能存在碰撞,但是概率極低,就像指紋一樣。
(5)數字簽名
可能摘要的信息也不想讓別人看到,把對數據摘要 再加密,就得到 數字簽名。
3、HTTPS 的工作過程
既然要保證數據安全, 就需要進行加密。網絡傳輸中不再直接傳輸明文了,而是加密之后的密文。加密的方式有很多,但是整體可以分成兩大類:對稱加密和非對稱加密。
網絡通信的過程中,需要解決以下兩個問題:
- 數據被監聽
- 數據被篡改?
(1)方案一 ——?只使用對稱加密
如果通信雙方都各自持有同?個密鑰 X,且沒有別人知道,這兩方的通信安全當然是可以被保證的(除非密鑰被破解)。
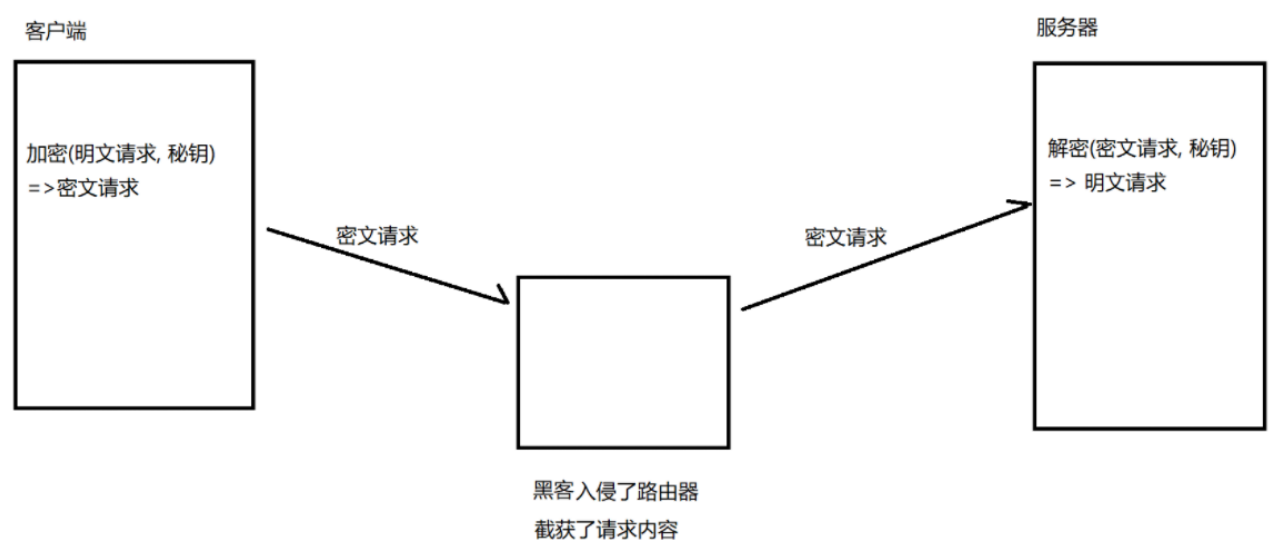
引入對稱加密之后,即使數據被截獲,由于黑客不知道密鑰是什么,也就無法進行解密,自然就不知道請求的真實內容了。如果通信雙方只使用一個密鑰進行加密通信,那么完全可以實現加密通信,除非密鑰被破解。但實際沒這么簡單,服務器同一時刻其實是給很多客戶端提供服務的,每個客戶端用的秘鑰肯定是不同的(如果是相同那密鑰就太容易擴散了,黑客就也能拿到了),所以服務器就需要維護每個客戶端和每個密鑰之間的關聯關系,這也是個很麻煩的事情。
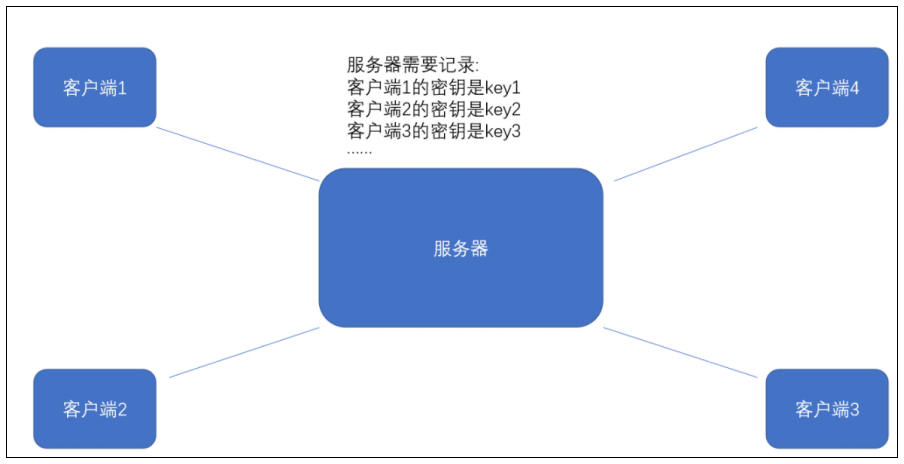
比較理想的做法就是能在客戶端和服務器建立連接時,雙方協商確定這次的密鑰是什么。
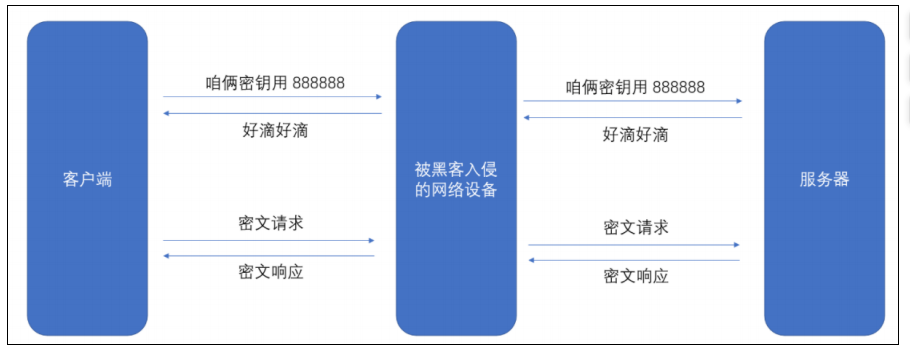
但是如果直接把密鑰明文傳輸,那么黑客也就能獲得密鑰了,此時后續的加密操作就形同虛設了。因此密鑰的傳輸也必須加密傳輸,但是要想對密鑰進行對稱加密,就仍然需要先協商確定一個個 “密鑰的密鑰”,這就成了 “先有雞還是先有蛋”?的問題了,那此時密鑰的傳輸再用對稱加密就行不通了。
所以在進行正常加密數據通信之前,首先要解決的是密鑰如何被對方安全的收到。
(2)方案二 —— 只使用非對稱加密
非對稱加密既可以使用公鑰加密,也可以使用私鑰加密。使用公鑰加密必須使用私鑰解密,使用私鑰加密必須使用公鑰解密。
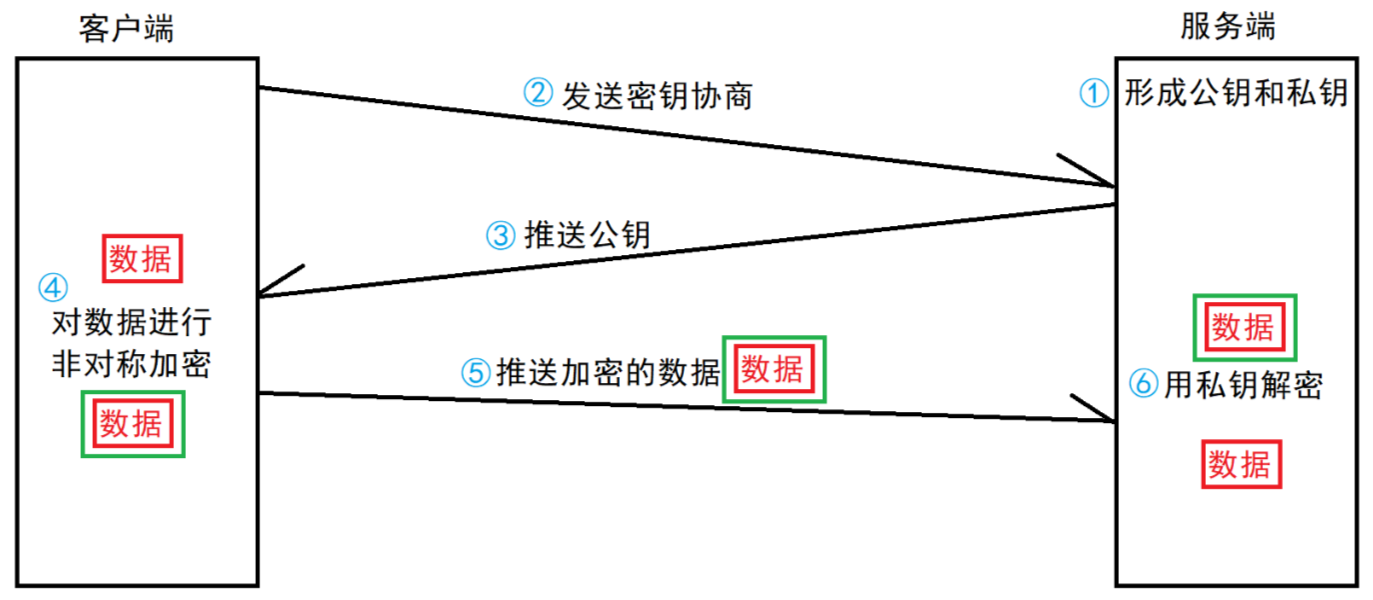
這樣就算中間人在通信過程中獲取了公鑰,但是沒有私鑰也無法進行解密,由此保證了從客戶端發送給服務端數據的安全。
但是客戶端給服務器發送的消息是不安全的,因為使用公鑰加密的密文發給客戶端,客戶端沒有私鑰,解不了密,那能否在響應時把私鑰傳過去?
不行,因為私鑰一但暴露到公網中就可能被劫持,黑客拿到私鑰原地破解密文。
鑒于非對稱加密的機制,如果服務器先把公鑰以明文方式傳輸給瀏覽器,之后瀏覽器向服務器傳數據前都先用這個公鑰加密好再傳,從客戶端到服務器信道似乎是安全的(有安全問題),因為只有服務器有相應的私鑰能解開公鑰加密的數據。
服務器到瀏覽器的這條路該如何保障安全呢?
如果服務器用它的私鑰加密數據傳給瀏覽器,那么瀏覽器用公鑰可以解密它,而這個公鑰是?開始通過明文傳輸給瀏覽器的,若這個公鑰被中間人劫持到了,那他也能用該公鑰解密服務器傳來的信息了。
(3)方案三 ——?雙方都使用非對稱加密
- 服務端擁有公鑰 S 與對應的私鑰 S',客戶端擁有公鑰 C 與對應的私鑰 C'。
- 客戶和服務端交換公鑰。
- 客戶端給服務端發信息:先用 S 對數據加密再發送,只能由服務器解密,因為只有服務器有私鑰 S'。
- 服務端給客戶端發信息:先用 C 對數據加密再發送,只能由客戶端解密,因為只有客戶端有私鑰 C'。
這樣做看似也行,但實則速度慢、效率低,其次是這樣做也會有安全問題。
(4)方案四 —— 非對稱加密 + 對稱加密
A. 解決效率問題
使用非對稱加密讓雙方知道對稱密鑰,后續再使用對稱加密的方式進行通信。
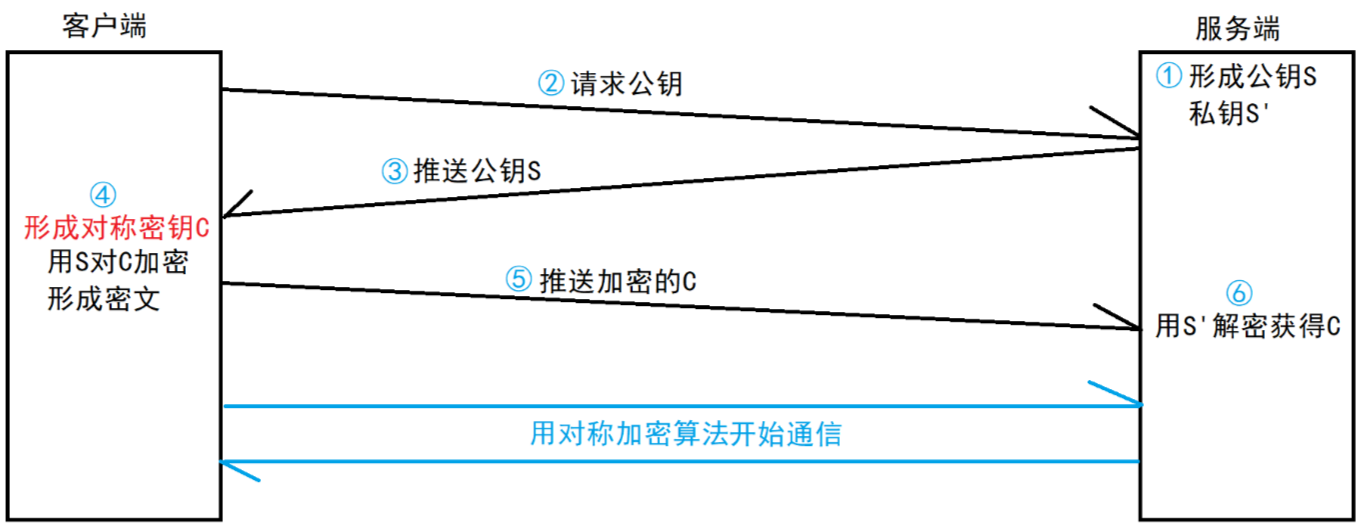
只有首次是使用非對稱加密,后續所有的通信都采用對稱加密。對稱加密的速度快,大大提高了通信速度。
- 服務端具有非對稱公鑰 S 和私鑰 S'。
- 客戶端發起 HTTPS 請求,獲取服務端公鑰 S。
- 客戶端在本地生成對稱密鑰 C,通過公鑰 S 加密,發送給服務器。
- 由于中間的網絡設備沒有私鑰,即使截獲了數據也無法還原出內部的原文,也就無法獲取到對稱密鑰。
- 服務器通過私鑰 S' 解密還原出客戶端發送的對稱密鑰 C,并且使用這個對稱密鑰加密給客戶端返回的響應數據。
- 后續客戶端和服務器的通信都只用對稱加密即可,由于該密鑰只有客戶端和服務器兩個主機知道,其他主機/設備不知道密鑰,所以即使截獲數據也沒有意義。
由于對稱加密的效率比非對稱加密高很多,因此只是在開始階段協商密鑰的時候使用非對稱加密,后續的傳輸仍然使用對稱加密,但依舊有安全問題。
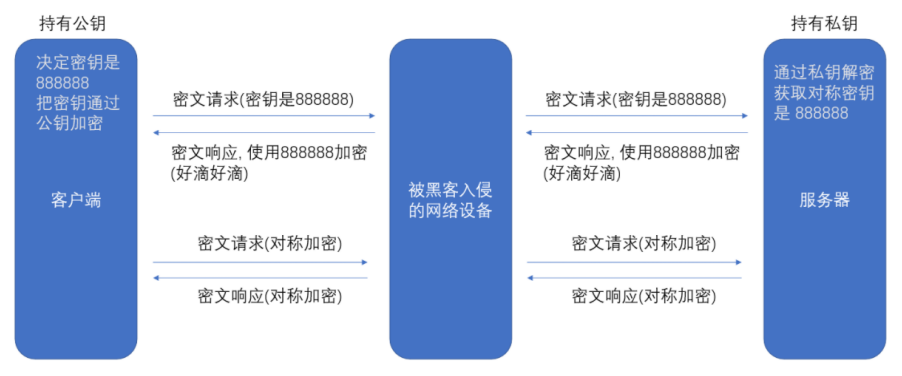
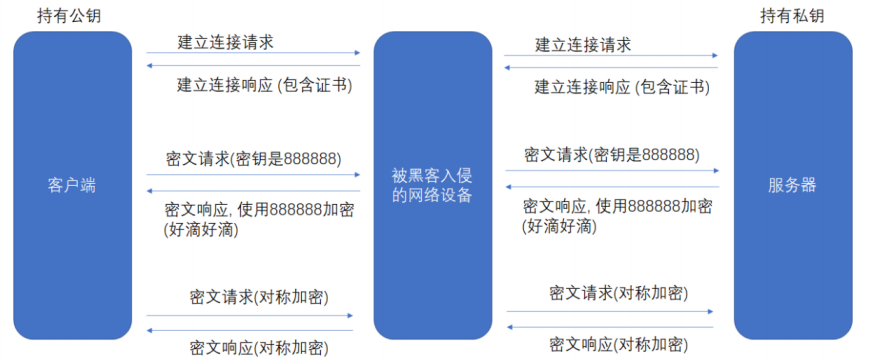
(5)中間人攻擊方式
Man-in-the-MiddleAttack,簡稱 “MITM 攻擊”。
在方案二、三、四中,客戶端獲取到公鑰 S 之后,對客戶端形成的對稱秘鑰 X 用服務端給客戶端的公鑰 S 進行加密,中間人即使竊取到了數據,但此時中間?確實無法解出客戶端形成的密鑰 X,因為只有服務器有私鑰 S'。但是中間人的攻擊如果在最開始握手協商的時候就進行了,那就不?定了,假設 hacker 已經成功成為中間人。
- 服務器具有非對稱加密算法的公鑰 S、私鑰 S'。
- 中間人具有非對稱加密算法的公鑰 M、私鑰 M'。
- 客戶端向服務器發起請求,服務器明文傳送公鑰 S 給客戶端。
- 中間?劫持數據報?,提取公鑰 S 并保存好,然后將被劫持報文中的公鑰 S 替換成為自己的公鑰 M,并將偽造報文發給客戶端。
- 客戶端收到報文,提取公鑰 M(自己不知道公鑰被更換過了),自己形成對稱秘鑰 X,用公鑰 M 加密 X,形成報文發送給服務器。
- 中間人劫持后,直接用自己的私鑰 M' 進行解密,得到通信秘鑰 X,再用曾經保存的服務端公鑰 S 加密后將報?推送給服務器。
- 服務器拿到報文,用自己的私鑰 S' 解密,得到通信秘鑰 X。
- 雙方開始采用 X 進行對稱加密進行通信,但這?切都在中間人的掌握中,劫持數據、進行竊聽甚至修改都是可以的。
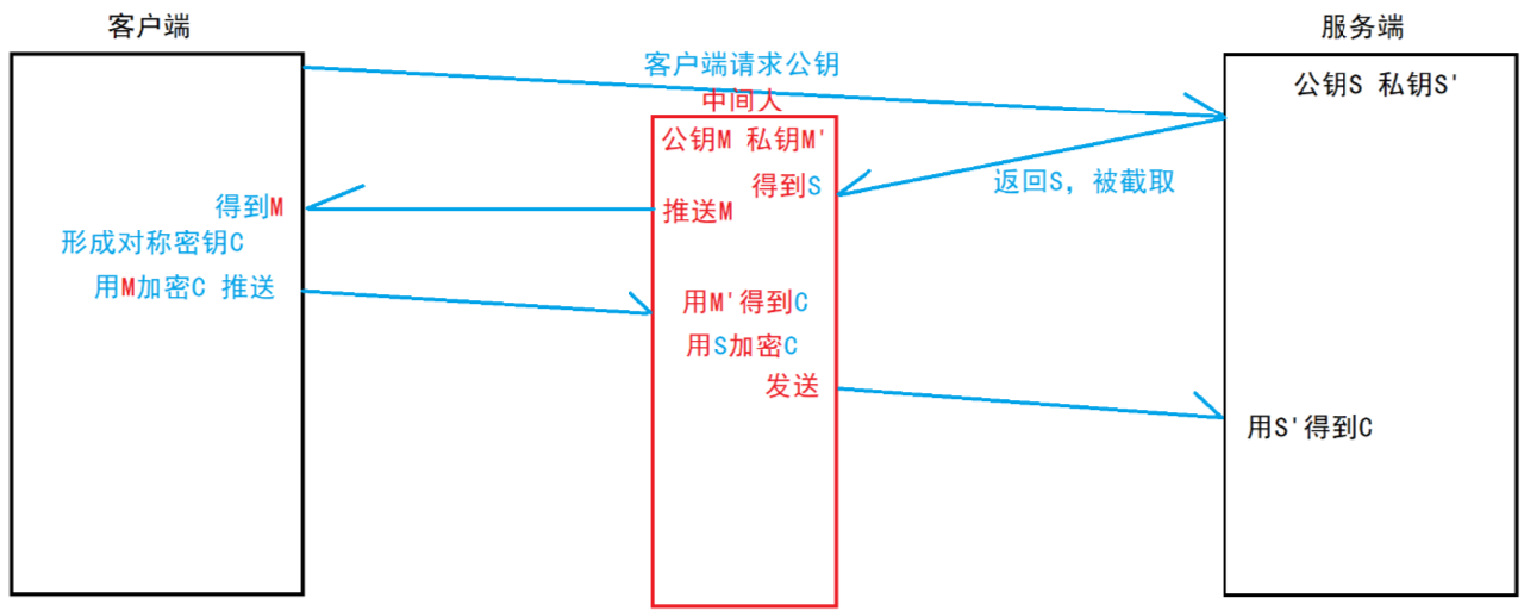
上面的攻擊方案同樣適用于方案二、三。
只要已經交換了密鑰,中間人就來遲了,但中間人如果在最開始的時候就可以進行篡改替換。
中間人攻擊能夠成功,其本質是什么呢?
本質是中間人能夠對數據做篡改且客戶端無法確定收到的公鑰是合法的,也無法確定其含有公鑰的數據報文就是目標服務器發送過來的。
這樣中間人也得到了 C,利用 C 先解密再加密后發送給服務端,那么即使修改了數據客戶端和服務端也不知道中間人的存在。
該場景的本質問題是服務器在返回公鑰的時候,被中間人截取并替換了公鑰,并且客戶端沒有能力辨別公鑰是否合法。 所以需要客戶端具有判別公鑰是否合法的能力。
(6)數字證書
為了解決上面的問題,Client 需要對服務器的合法性進行認證。
A. CA 認證
相關簡介:CA認證_百度百科 (baidu.com)
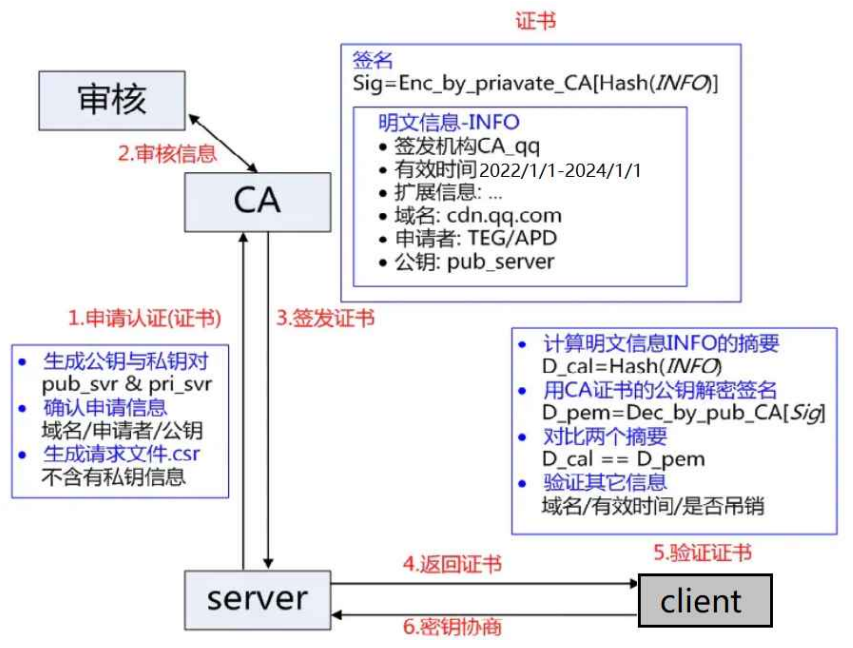
服務端在使用 HTTPS 前,需要向 CA 機構(權威機構)申領?份數字證書(CA 證書),數字證書里含有證書申請者信息、公鑰信息等。服務器把證書傳輸給瀏覽器,瀏覽器從證書里獲取公鑰就行了,證書就如身份證,證明服務端公鑰的權威性, 是服務端公鑰的身份證明。
- 證書發布機構
- 證書有效期
- 公鑰
- 證書所有者
- 簽名
- ......
注意:申請證書時需要在特定平臺生成查,會同時生成?對密鑰對,即公鑰和私鑰。這對密鑰對就是用來在網絡通信中進行明文加密以及數字簽名的。
其中公鑰會隨著 CSR 文件,?起發給 CA 進行權威認證,私鑰服務端自己保留,用來后續進行通信(其實主要就是用來交換對稱密鑰)。
在線生成 CSR 和私鑰:CSR在線生成工具 (myssl.com)?

B. 數據簽名
簽名的形成是基于非對稱加密算法的,數據簽名的本質是防止被篡改。
注意 :目前暫時和 https 沒有關系,不要和 https 中的公鑰私鑰搞混了。
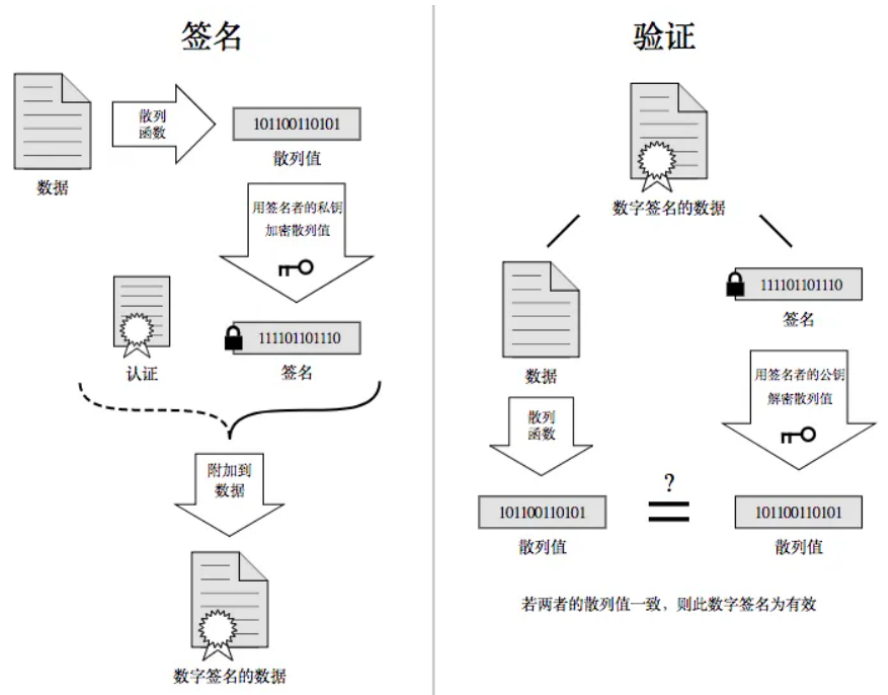
a. 簽名過程?
假設現在我們有了數據(比如明文信息),我們把這個數據進行摘要形成數據摘要(數據指紋),然后把數據指紋用簽名者(比如 CA 機構)的私鑰進行加密形成了簽名,然后再把明文信息和簽名放在一起形成了數字簽名的數據(比如證書)。

b. 驗證過程
首先把數據簽名的數據分成數據和簽名,然后先對數據進行相同的摘要方式形成數據摘要,然后把用公鑰加密過的簽名用私鑰解密,得到數據摘要,兩者比對即可。散列值不一樣說明有人篡改了簽名或者數據,散列值一樣就說明沒有被篡改過。
c.?CA 證書的申請和驗證
當服務端申請 CA 證書時,CA 機構會對該服務端進行審核,并專門為該網站形成數字簽名,過程如下:
- CA 機構擁有非對稱加密的私鑰 A 和公鑰 A'。
- CA 機構對服務端申請的證書明文數據進行 hash 摘要(公開的),形成數據摘要。
- CA 機構用 CA 私鑰 A' 加密數據摘要,得到數字簽名 S。
- CA 機構把明文數據和簽名結合起來形成證書。
因為我們使用的是 CA 形成的數據簽名,所以只有 CA 能形成可信任的證書,此時服務器會把證書響應給客戶端,證書里面包含了公鑰。
服務端申請的證書明文和數字簽名 S 共同組成了數字證書,這樣?份數字證書就可以頒發給服務端了。
驗證證書合法性(公鑰的合法性):
- 先看有沒有過期。
- 把數據簽名和明文信息分開。
- 對明文信息進行 hash 摘要(公開的),形成數據摘要。然后用 CA 的公鑰把數據簽名解密,得到了數據摘要,這里的公鑰是哪來的呢?(CA 會在所有的瀏覽器中內置自己的公鑰)
- 把兩個數據摘要進行對比,相等就說明內容沒有被篡改,不相等說明被篡改了。
有沒有可能原文和簽名全部都被替換了呢?原文中的公鑰確實能被修改,那么簽名呢?
改不了,因為私鑰只有 CA 有,用自己的私鑰的話瀏覽器不認識。
中間人能不能直接把整個證書替換掉?
首先因為瀏覽器里面內置了 CA 的私鑰,那么我們替換的證書必須是一個真正的證書,因為假證書沒有辦法解密。而證書里面的域名信息,域名是唯一的,不可能一樣。所以做不到整體替換。
(7)方案五 —— 非對稱加密 + 對稱加密 + 證書認證
在客戶端和服務器剛建立連接時,服務器給客戶端返回?個證書,證書包含了之前服務端的公鑰,也包含了網站的身份信息,由此可以驗證公鑰的合法性。
所以非對稱加密 + 對稱加密保證了通信的安全,數字證書保證了通信之前交換密鑰的安全。
A. 客戶端進行認證
- 判定證書的有效期是否過期。
- 判定證書的發布機構是否受信任(操作系統中已內置的受信任的證書發布機構)。
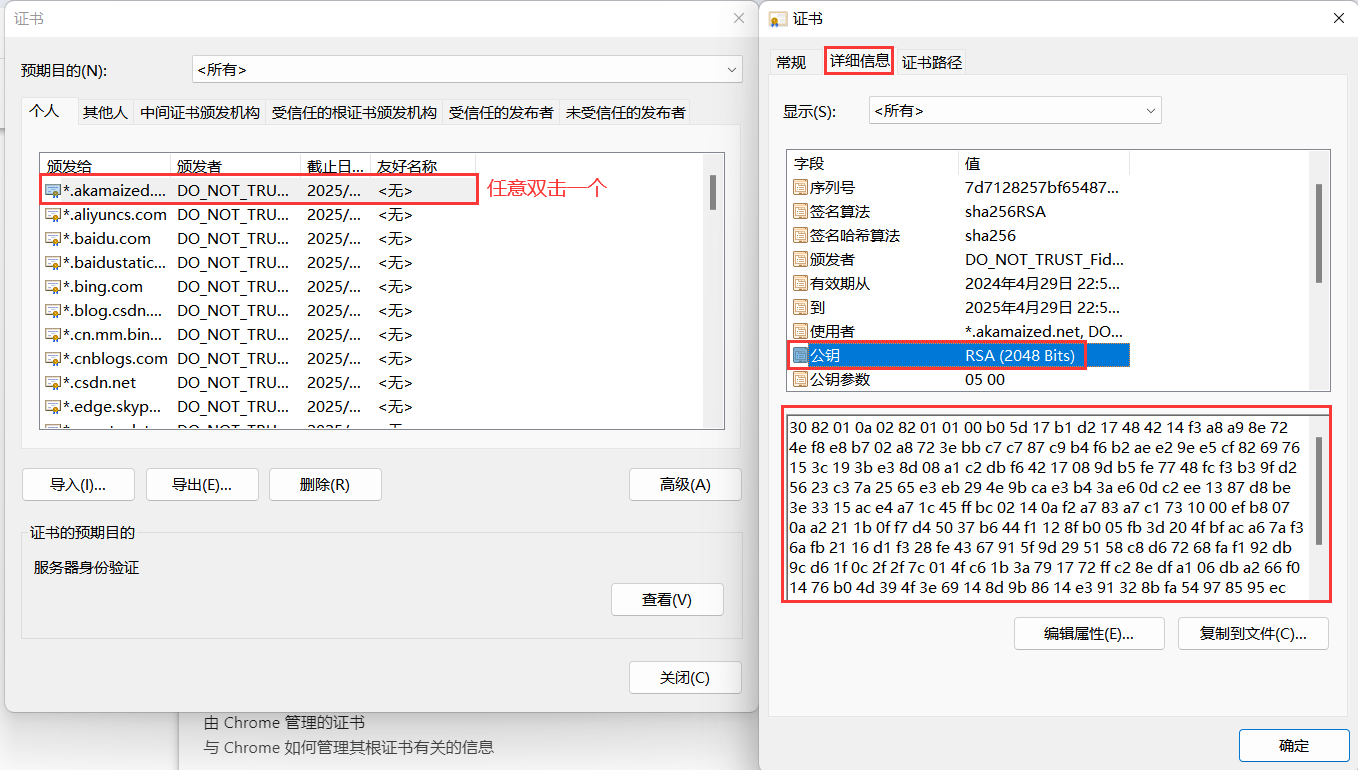
- 驗證證書是否被篡改:從系統中拿到該證書發布機構的公鑰,對簽名解密得到?個 hash 值(數據摘要),設為 hash1。然后計算整個證書的 hash 值設為 hash2,對比?hash1 和 hash2 是否相等。如果相等,則說明證書是沒有被篡改過的。
B.?查看瀏覽器的受信任證書發布機構
Chrome 瀏覽器:
(8)常見問題
中間人有沒有可能篡改該證書?
- 中間?篡改了證書的明文。
- 由于他沒有 CA 機構的私鑰,所以?法 hash 之后?私鑰加密形成簽名,那么也就沒法辦法對篡改后的證書形成匹配的簽名。
- 如果強行篡改,客戶端收到該證書后會發現明?和簽名解密后的值不一致,則說明證書已被篡改,證書不可信,從而終止向服務器傳輸信息,防止信息泄露給中間人。
中間人整個掉包證書?
- 因為中間?沒有 CA 私鑰,所以無法制作假的證書。
- 所以中間?只能向 CA 申請真證書,然后用自己申請的證書進行掉包。
- 這個確實能做到證書的整體掉包,但是證書明文中包含了域名等服務端認證信息,如果整體掉包,客戶端依舊能夠識別出來。
- 記住:中間人沒有 CA 私鑰,所以對任何證書都無法進行合法修改,包括自己的。
為什么摘要內容在網絡傳輸時一定要加密形成簽名?
常見的摘要算法有:MD5 和 SHA 系列。
以 MD5 為例,我們不需要研究具體的計算簽名的過程,只需要了解 MD5 的特點:
- 定長:無論多長的字符串,計算出來的 MD5 值都是固定長度(16 字節版本或者 32 字節版本)。
- 分散:源字符串只要改變?點點,最終得到的 MD5 值都會差別很大。
- 不可逆:通過源字符串?成 MD5 很容易,但是通過 MD5 還原成原串理論上是不可能的。
正因為 MD5 有這樣的特性,我們可以認為如果兩個字符串的 MD5 值相同,則認為這兩個字符串相同。
理解判定證書篡改的過程(好比如判定這個?份證是不是偽造的身份證):
- 假設我們的證書只是?個簡單的字符串 hello,對這個字符串計算 hash 值(比如 md5),結果為 BC4B2A76B9719D91
- 如果 hello 中有任意的字符被篡改了,比如變成了 hella, 那么計算的 md5 值就會變化很大,BDBD6F9CF51F2FD8
- 然后我們可以把這個字符串 hello 和 哈希值 BC4B2A76B9719D91 從服務器返回給客?端, 此時客戶端如何驗證 hello 是否是被篡改過?那么就只要計算 hello 的哈希值,看看是不是 BC4B2A76B9719D91 即可。
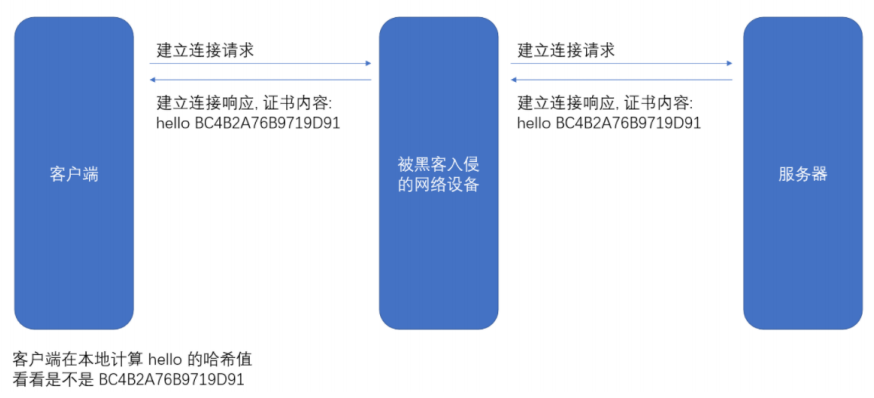
但還有個問題,如果黑客把 hello 篡改了,同時也把哈希值重新計算了一下,那么客戶端就分辨不出來了。?
被傳輸的哈希值不能傳輸明文,需要傳輸密文。所以,對證書明文("hello")hash 形成散列摘要,然后 CA 使用自己的私鑰加密形成簽名,將 hello 和加密的簽名合起來形成 CA 證書頒發給服務端,當客戶端請求時就發送給客戶端,中間人截獲了,因為沒有 CA 私鑰,就無法更改或者整體掉包,就能安全的證明證書的合法性。
最后,客戶端通過操作系統?已經存的了的證書發布機構的公鑰進行解密,還原出原始的哈希值,再進行校驗。
為什么簽名不是選擇直接加密,而是要先 hash 形成摘要?
縮小簽名密文的長度,加快數字簽名的驗證簽名的運算速度。
如何成為中間人?(了解)
- ARP 欺騙:在局域網中,hacker 經過收到 ARP Request 廣播包,能夠偷聽到其它節點的(IP, MAC)地址。例如:黑客收到兩個主機 A、B 的地址,告訴 B(受害者),自己是 A,使得 B 在發送給 A 的數據包都被黑客截取。
- ICMP 攻擊:由于 ICMP 協議中有重定向的報文類型,我們就可以偽造?個 ICMP 信息,然后發送給局域網中的客戶端并偽裝自己是?個更好的路由通路,從而導致目標所有的上網流量都會發送到我們指定的接口上,達到和 ARP 欺騙同樣的效果。
- 假 Wifi && 假網站等。
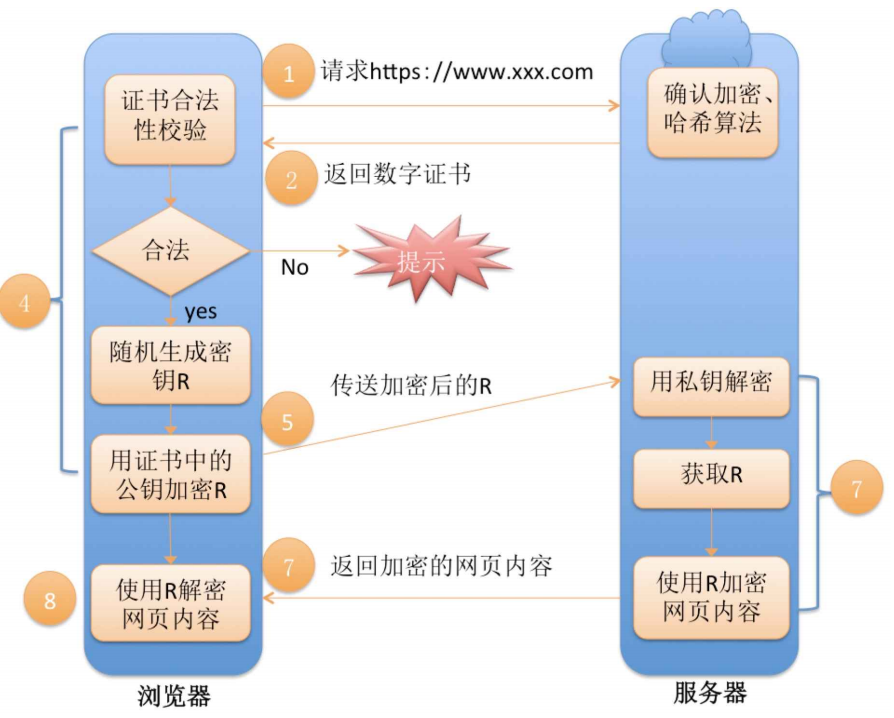
(9)完整流程
左側都是客戶端做的事情,右側都是服務器做的事情:
4、總結
HTTPS 整個工作過程中涉及的密鑰有三組:
- 第?組(非對稱加密):?于校驗證書是否被篡改. 服務器持有私鑰(私鑰在形成CSR?件與申請證書時獲得),客戶端持有公鑰(操作系統包含了可信任的 CA 認證機構有哪些,同時持有對應的公鑰)。服務器在客戶端請求時,返回攜帶簽名的證書。客戶端通過這個公鑰進行證書驗證,保證證書的合法性,進?步保證證書中攜帶的服務端公鑰權威性。
- 第?組(非對稱加密):用于協商?成對稱加密的密鑰。客戶端用收到的 CA 證書中的公鑰(是可被信任的)給隨機生成的對稱加密的密鑰加密,傳輸給服務器,服務器通過私鑰解密獲取到對稱加密密鑰。
- 第三組(對稱加密):客戶端和服務器后續傳輸的數據都通過這個對稱密鑰加密解密。
其實?切的關鍵都是圍繞這個對稱加密的密鑰,其他的機制都是輔助這個密鑰工作的。
第?組非對稱加密的密鑰是為了讓客戶端把這個對稱密鑰傳給服務器,第?組非對稱加密的密鑰是為了讓客戶端拿到第?組非對稱加密的公鑰。
















)

的無人艇制導算法)
