Spark-SQL 概述
Spark SQL 是 Spark 用于結構化數據(structured data)處理的 Spark 模塊
Shark 是伯克利實驗室 Spark 生態環境的組件之一,是基于 Hive 所開發的工具,它修改了內存管理、物理計劃、執行三個模塊,并使之能運行在 Spark 引擎上
Shark 的出現,使得 SQL-on-Hadoop 的性能比 Hive 有了 10-100 倍的提高
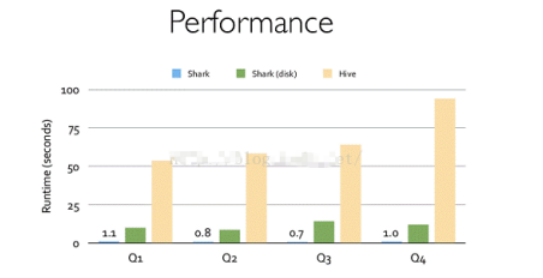
Spark 團隊重新開發了SparkSQL代碼;擺脫了對Hive的依賴性,SparkSQL 無論在數據兼容、性能優化、組件擴展方面都得到了極大的方便
1.數據兼容方面 SparkSQL 不但兼容 Hive,還可以從 RDD、parquet 文件、JSON 文件中 獲取數據,未來版本甚至支持獲取 RDBMS 數據以及 cassandra 等 NOSQL 數據
2.性能優化方面 除了采取 In-Memory Columnar Storage、byte-code generation 等優化技術 外、將會引進 Cost Model 對查詢進行動態評估、獲取最佳物理計劃等等
3.組件擴展方面無論是 SQL 的語法解析器、分析器還是優化器都可以重新定義,進行擴 展
Spark-SQL 特點
1.易整合。無縫的整合了 SQL 查詢和 Spark 編程
2.統一的數據訪問。使用相同的方式連接不同的數據源

3.兼容 Hive。在已有的倉庫上直接運行 SQL 或者 HQL

4.標準數據連接。通過 JDBC 或者 ODBC 來連接

DataFrame
在 Spark 中,DataFrame 是一種以 RDD 為基礎的分布式數據集,類似于傳統數據庫中 的二維表格
DataFrame 與 RDD 的區別
主要區別在于,前者帶有 schema 元信息,即 DataFrame 所表示的二維表數據集的每一列都帶有名稱和類型

?DataSet
DataSet 是分布式數據集合,是 DataFrame 的一個擴展,是 SparkSQL 最新的數據抽象。它提供了 RDD 的優勢(強類型,使用強大的 lambda 函數的能力)以及 Spark SQL 優化執行引擎的優點。DataSet 也可以使用功能性的轉換(操作 map,flatMap,filter 等等)
Spark-SQL核心編程(一)
DataFrame
Spark SQL 的 DataFrame API 允許我們使用 DataFrame 而不用必須去注冊臨時表或者生成 SQL 表達式。DataFrame API 既有 transformation 操作也有 action 操作
創建 DataFrame
在?Spark SQL 中 SparkSession 是創建 DataFrame 和執行 SQL 的入口,創建 DataFrame
有三種方式:通過?Spark 的數據源進行創建;從一個存在的 RDD 進行轉換;還可以從 Hive
Table 進行查詢返回
Spark-SQL支持的數據類型:
![]()
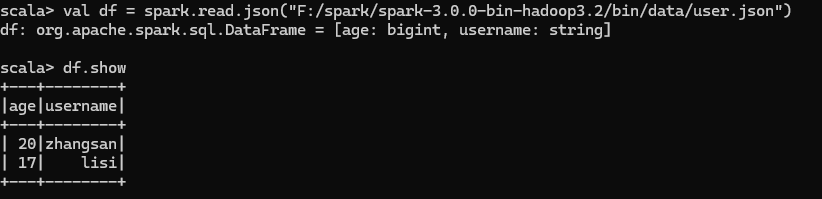
在 spark 的 bin/data 目錄中創建 user.json 文件并在文件中添加數據

讀取 json 文件創建 DataFrame,展示數據
SQL 語法
SQL 語法風格是指我們查詢數據的時候使用 SQL 語句來查詢,這種風格的查詢必須要
有臨時視圖或者全局視圖來輔助
實例:
? 讀取 JSON 文件創建 DataFrame
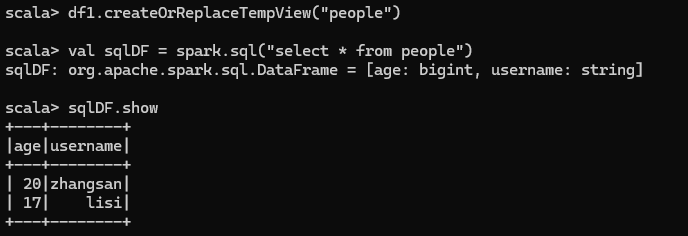
 對 DataFrame 創建一個臨時表,通過 SQL 語句實現查詢全表,結果展示
對 DataFrame 創建一個臨時表,通過 SQL 語句實現查詢全表,結果展示
Spark-SQL核心編程(二)
DSL 語法
DataFrame 提供一個特定領域語言(domain-specific language, DSL)去管理結構化的數據
可以在 Scala, Java, Python 和 R 中使用 DSL,使用 DSL 語法風格
實例:
創建一個 DataFrame
![]()
查看 DataFrame 的 Schema 信息
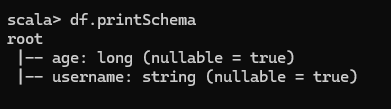
只查看"username"列數據
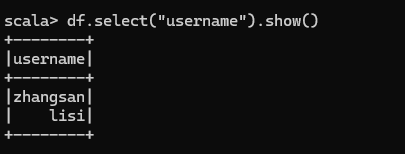
查看"username"列數據以及"age+1"數據
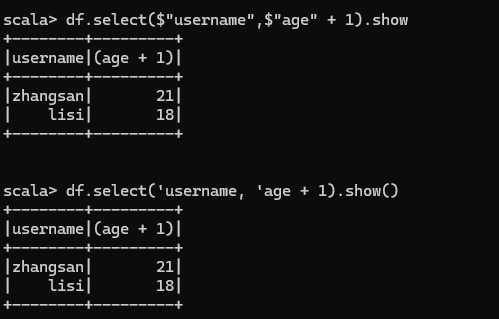
注意:涉及到運算的時候, 每列都必須使用$, 或者采用引號表達式:單引號+字段名
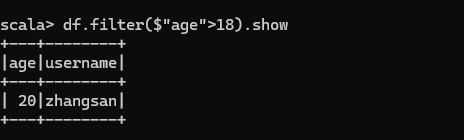
查看"age"大于"18"的數據
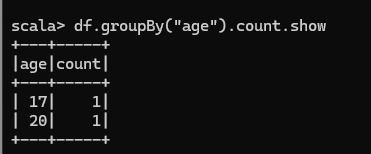
按照"age"分組,查看數據條數
RDD 轉換為 DataFrame
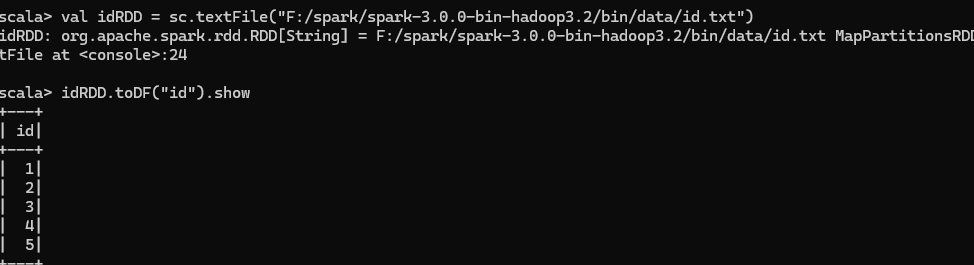
創建id.txt,并添加數據
將數據導入并查詢
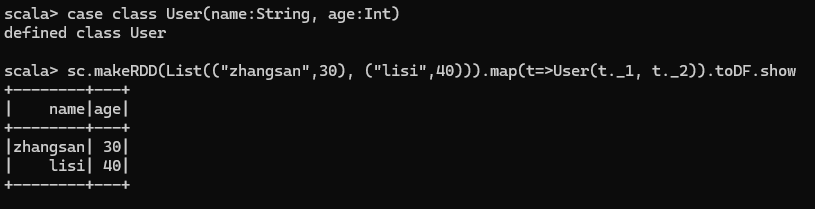
實際開發中,一般通過樣例類將 RDD 轉換為 DataFrame
DataFrame 轉換為 RDD
DataFrame 其實就是對 RDD 的封裝,所以可以直接獲取內部的 RDD
實例:

注意:此時得到的 RDD 存儲類型為 Row
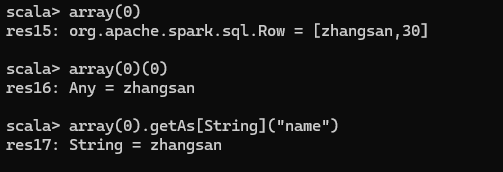
Spark-SQL核心編程(三)
DataSet
創建 DataSet
實例:
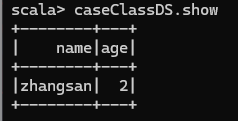
使用樣例類序列創建 DataSet

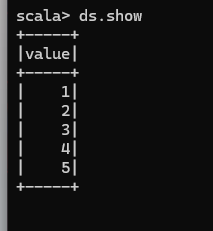
使用基本類型的序列創建 DataSet

注意:在實際使用的時候,很少用到把序列轉換成DataSet,更多的是通過RDD來得到DataSet
RDD 轉換為 DataSet
parkSQL 能夠自動將包含有 case 類的 RDD 轉換成 DataSet,case 類定義了 table 的結 構,case 類屬性通過反射變成了表的列名
實例:

DataSet 轉換為 RDD
DataSet 其實也是對 RDD 的封裝,所以可以直接獲取內部的 RDD
實例:

此處報錯原因是 res3 ?并不存在(從前面代碼看沒有定義過 res3 ?),而且即使存在,如果它的類型不是包含 rdd ?成員的類型(比如不是 Dataset ?等相關類型)
DataFrame 和 DataSet 轉換
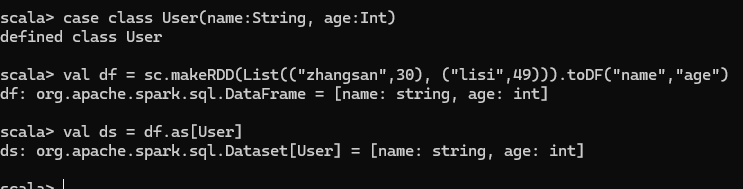
DataFrame 其實是 DataSet 的特例,所以它們之間是可以互相轉換的
DataFrame 轉換為 DataSet
實例
DataSet 轉換為 DataFrame
實例
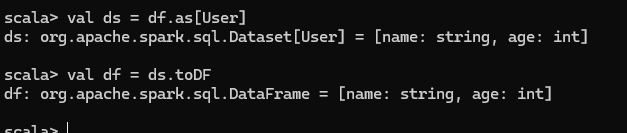
RDD、DataFrame、DataSet 三者的關系
從版本的產生上來看:
Spark1.0 => RDD
Spark1.3 => DataFrame
Spark1.6 => Dataset
同樣的數據都給到這三個數據結構,他們分別計算之后,都會給出相同的結果。不
同是的他們的執行效率和執行方式。在后期的?Spark 版本中,DataSet 有可能會逐步取代 RDD和?DataFrame 成為唯一的 API 接口
三者的共性
1)RDD、DataFrame、DataSet 全都是 spark 平臺下的分布式彈性數據集,為處理超大型數
據提供便利;
2)三者都有惰性機制,在進行創建、轉換,如 map 方法時,不會立即執行,只有在遇到
Action 如 foreach 時,三者才會開始遍歷運算;
3)三者有許多共同的函數,如 filter,排序等;
4)在對 DataFrame 和 Dataset 進行操作許多操作都需要這個包:
????????import spark.implicits._(在創建好?SparkSession 對象后盡量直接導入)
5)三者都會根據 Spark 的內存情況自動緩存運算,這樣即使數據量很大,也不用擔心會
內存溢出
6)三者都有分區(partition)的概念
7)DataFrame 和 DataSet 均可使用模式匹配獲取各個字段的值和類型
三者的區別
1) RDD
??RDD 一般和 spark mllib 同時使用
??RDD 不支持 sparksql 操作
2) DataFrame
??與 RDD 和 Dataset 不同,DataFrame 每一行的類型固定為Row,每一列的值沒法直
接訪問,只有通過解析才能獲取各個字段的值
??DataFrame 與 DataSet 一般不與 spark mllib 同時使用
??DataFrame 與 DataSet 均支持 SparkSQL 的操作,比如 select,groupby 之類,還能
注冊臨時表/視窗,進行 sql 語句操作
??DataFrame 與 DataSet 支持一些特別方便的保存方式,比如保存成 csv,可以帶上表
頭,這樣每一列的字段名一目了然
3) DataSet
??Dataset 和 DataFrame 擁有完全相同的成員函數,區別只是每一行的數據類型不同。
DataFrame 其實就是 DataSet 的一個特例 type DataFrame = Dataset[Row]
??DataFrame 也可以叫 Dataset[Row],每一行的類型是 Row,不解析,每一行究竟有哪
些字段,各個字段又是什么類型都無從得知,只能用上面提到的?getAS 方法或者共性里提到的模式匹配拿出特定字段。而?Dataset 中,每一行是什么類型是不一定的,在自定義了?case class 之后可以很自由的獲得每一行的信息
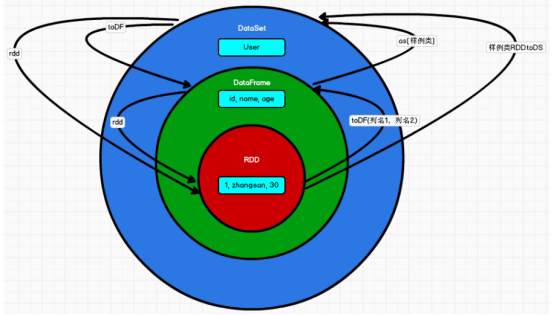
三者可以通過上圖的方式進行相互轉換















)

的無人艇制導算法)

