一、動機
如何從檢索到的段落中提取證據,以降低計算成本并提升最終的RAG性能,然而這一問題仍然具有挑戰性。
現有方法 嚴重依賴于基于啟發式的增強,面臨以下幾個問題:
(1)由于手工制作的上下文過濾,導致泛化能力差;
(2)由于基于規則的上下文分塊,導致語義不足;
(3)由于句子級別的過濾學習,導致長度偏差。
不完美的檢索器,會檢索到無關的段落,誤導LLM
二、解決方法
我們提出了一種基于模型的證據提取學習框架——SEER,通過自對齊學習優化一個基礎模型,使其成為具有所需特性的證據提取器。
自對齊學習利用模型自我改進,并將其響應與期望的屬性對齊,這可以緩解對手工設計的上下文過濾、基于規則的上下文分塊和句子級過濾學習的高度依賴。
鑒于提取的證據,再次出現一個問題:如何正確評估證據的質量?原則上,證據應該是忠實的(即避免內在的幻覺),與檢索到的段落一致(Rashkin et al., 2021;Maynez et al., 2020);應有助于解決用戶輸入的問題(Adlakha et al., 2023);并且簡潔,以促進推理速度(Ko et al., 2024)。
我們提出了一種基于模型的證據提取學習框架——SEER:它包括三個主要階段:
(1)證據提取:為了緩解上述問題,我們提出通過響應采樣提取語義一致且長度多樣化的證據,從而為對齊提供充分的偏好數據。
三、任務表述
通過基礎提取器E和固定生成器G來提升生成任務的性能。
基礎提取器E:用于提取證據的模型,是從檢索到的文檔中提取相關的證據或信息。骨干網絡使用Llama2-7B-Chat
固定生成器G:根據提取的證據生成回答,生成器是固定的,權重不更新。
檢索到的段落:給定一個查詢q從一個檢索系統中獲取一組相關的段落
自動對齊和微調:通過自對齊(通過模型自身的學習來改善提取過程)來微調基礎提取器E,使其提取到的證據更加符合生成器G的需求
![]()
兩種上下文過濾優化:
1.基于啟發式的
2.基于模型的(本文)
四、方法
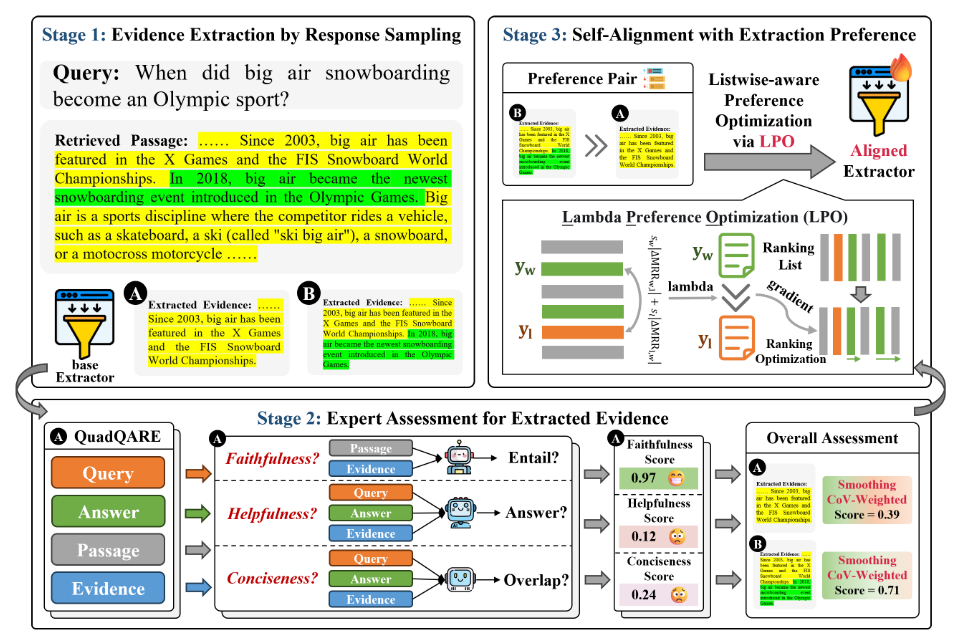
三個階段:1.證據提取 2.專家評估 3.自對齊?
1.證據提取
能不能讓模型“自我學習”,自動提取更好的證據,而不是靠人寫的死板規則?
🔍 怎么做?
作者的方法就是用一種叫 響應采樣(response sampling) 的策略來讓模型自己動手練。
我們把這個問題 q 和這段文檔 P 拼接在一起,喂給模型,提示它從中提取出 可能作為答案依據的證據(也就是e)。讓模型嘗試從這段文檔中,提取出 M 個不同版本的證據。
??? 問題:模型太“自信”,老是產出一樣的東西
大語言模型(LLM)有個“毛病”:它太自信了,總覺得它知道哪條最靠譜。
于是,它在多次采樣的時候,總是生成那幾條“它最喜歡的答案”:
📊 這導致了一個現象:生成結果的分布很不平衡,叫做“冪律分布”(power-law distribution)
-
熱門答案(頭部響應)出現非常頻繁
-
其他少見但可能有價值的答案(長尾響應)出現得很少
🔧 解決辦法:去重 + 均勻分布
-
去重
用一種叫 n-gram 相似度 的方法(就是比較字詞相似度),把重復或者非常相似的答案剔除掉。 -
保留不重復、分布更均勻的一組證據
得到新的候選集合 {ei}??,這個集合里的答案就更“多樣化”,不會被幾個高頻答案壟斷。
2.專家評估
提取器提取的證據可能:不忠實、沒有幫助、不簡潔
設置三個專家分別評估提取證據在忠實性、有用性、簡潔性方面的質量,之后針對每個提取的證據的多個評分,設計一個平滑的CoV-加權方案,以便得到最終的評估分數。
假設你和朋友們一起評分一部電影,大家的評分有高有低。為了得出一個合理的電影評分,我們可以用CoV-加權來“調節”
加權的意思就是根據評分的不穩定程度給每個評分一個“重要性”分數。
**波動大(不穩定)**的評分,權重會低。
**波動小(穩定)**的評分,權重會高。
1.獲得專家的評分
?首先收集一組QuadQARE<q, a, p, e>查詢、答案、檢索到的段落、提取的證據,設計三個可插拔的專家,并行評估提取證據的質量。
忠實專家:將檢索到的文檔 P 和相應的提取證據 e 視為前提和假設。然后,我們使用 ALIGNSCORE(NLI自然語言推理模型) 來衡量提取證據 e 是否能夠從檢索到的文檔 P 中推導出來
sf∈[0,1]是忠實性評分。如果假設 e 對前提 P 是忠實的,則評分接近 1,否則接近 0。
?有用性專家:通過計算在包含提取證據 e 前后生成黃金答案 a 的對數概率變化來評估其對大語言模型(LLMs)的潛在影響
[0,1] 是有用性評分Sig(?) 是 sigmoid 函數
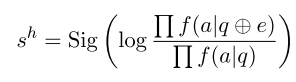
?簡潔性專家:首先將查詢 q 和黃金答案 a 轉換為完整答案 t,該答案表示回答查詢所需的最小信息。隨后,我們利用 SBERT(Reimers 和 Gurevych,2019)來衡量完整答案和提取證據之間的語義重疊程度
[?1,1] 是簡潔性評分,通過計算完整答案 t 和提取證據 e 之間的余弦相似度來衡量,提示 GPT-3.5-turbo 根據查詢 q 和答案 a 生成完整答案 t
完整答案是通過將問題及其對應的答案轉化為陳述句的形式生成的
獲得每個專家的評估分數后,怎么用這些分數合并成一個綜合評分來評估每個證據的總體質量
簡單的方法:直接求平均值,但是每個評估的學習難度和重要性不一樣,所以,不能直接使用平均值,使用CoV加權(變異系數加權)的方法?
變異系數(CoV):
變異系數(Coefficient of Variation, CoV)是衡量分數變異程度的一個指標,公式為:
CoV的作用是:當某個分數的變動范圍較大時,它的影響更大。
計算加權:用 softmax 函數 來將 CoV 轉化為權重,并通過“溫度”τ\tauτ來控制這種平滑性,防止某些異常的分數權重過大。softmax 函數會根據 CoV 的大小分配不同的權重。溫度參數的作用是控制權重分配的平滑度。
CoV加權分數是通過如下公式計算的:
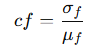

3.自對齊
?獲得偏好數據:(問題+背景,好的證據,不太好的證據)
![]()
?獲得數據后,開始對齊微調:
對齊訓練中,以前的工作通常采用近端策略優化(PPO)(Schulman et al., 2017) 或直接偏好優化(DPO)(Rafailov et al., 2023)。
PPO(近端策略優化):“你告訴我 A 比 B 好,那我就盡量學著多選 A,少選 B。”它確實能學偏好,但它有個局限:它根本 不關心這倆在總排名里的位置!
DPO(直接偏好優化):“你喜歡 A 勝過 B?OK,我來微調模型傾向 A。”但 DPO 不在乎這個,它就是“誰贏就訓誰”,不考慮這倆交換對整體排名有多大影響。
🎯 所以問題出在哪?
PPO & DPO 的共同問題是:
它們都不夠“在乎排名位置”??
→ 就像一個不太懂“差距感”的評委。? LPO(Lambda Preference Optimization):
如果我把第 2 名換到第 1 名,會讓整體排名提升多少?”它會根據這個**“排名提升的收益”**來給每對偏好打不同的“訓練權重”。LPO 是一種更聰明的訓練方法,不僅知道“e1 比 e2 好”,還知道“讓 e1 在前面對整體排名幫助更大”
根據Lambda 損失方法的啟發我們提出了?一種基于列表感知的 Lambda 偏好優化算法(LPO):
通過為每對候選項分配一個 lambda 權重,將排名位置無縫地引入 DPO:它在 DPO 的基礎上加了一個“排名感知”的增強項 —— lambda 權重(λ?w,l?),讓訓練更精準、更聰明!
LPO(Lambda Preference Optimization) 是一種讓模型在「學習偏好排序」時,同時關注:
-
誰更好(偏好對比)
-
誰的位置更重要(排名影響)
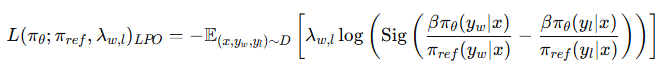
?L_LPO = - 期望值[ λ_w,l * log(Sigmoid( ... )) ]
這句話可以解釋為:
我們在訓練時,對每一對 evidence(ei vs ej),計算一個“偏好損失”,然后根據“他們交換會帶來多少排名變化(λ_w,l)”來調節訓練強度。
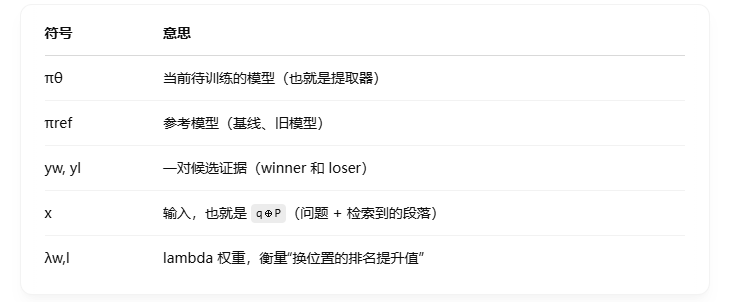
?這個結構其實和 DPO 很像,但多了一個 λw,l:每對樣本的訓練力度是按“交換是否很重要”來動態調整的!
🧠 Lambda 損失是個啥?
Lambda Loss(λ-Loss)是一種用于排序任務的訓練方法
核心思想:
🗣?「我不直接告訴模型要學什么分數,我告訴你:如果你把兩個樣本的位置換了,排名效果會提升多少 —— 然后你根據這個信息來訓練!」
Lambda 其實是給每一對候選項的“交換”打的一個分數,也就是“交換這倆值的 收益權重”。
對每一對組合,算出如果我們交換了它們的位置,對某個評價指標(如 NDCG、MRR)影響多大
這個影響值(也可以叫“梯度引導值”)就是 λ,用來指引模型參數往更好的排序方向更新!
?? 2. Lambda 權重 λ?w,l? 怎么算的?
λw,l = sw * ΔMRR(w,l) + sl * ΔMRR(l,w)
你可以這樣理解:
如果 ei 和 ej 的排名互換后,整體排序的“倒數排名提升”比較大,那說明這兩個項的位置很關鍵,我們就更強烈地用它們來訓練模型!

所以,lambda 權重的含義就是:
🌟「這兩個證據的排序變化,會對整體排名帶來多少提升?」如果越關鍵,我們就越強化訓練。
?五、實驗
1.數據集
NaturalQuestions (NQ)(Kwiatkowski 等,2019)、TriviaQA (TQA)(Joshi 等,2017)和 HotpotQA(Yang 等,2018)。
2.評估指標
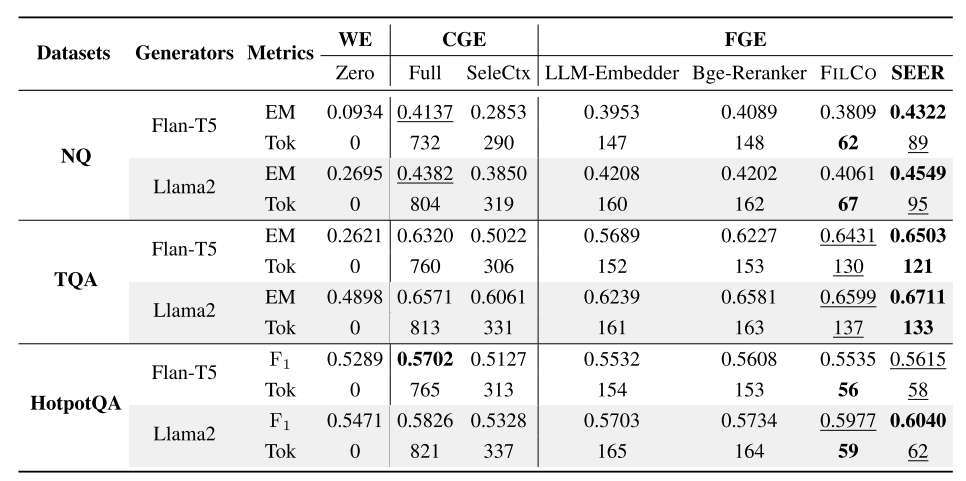
NQ 和 TQA 屬于抽取式問答任務,我們采用 Exact Match(EM,精確匹配) 作為它們的評估指標:如果問答模型的回答中至少包含一個正確答案,則得分為 1;否則為 0。
HotpotQA 屬于生成式問答任務,我們使用 unigram F1 分數 來評估答案的正確性。
3.基線
1.零樣本(Zero-shot, Zero):不向大語言模型(LLM)傳入任何證據,僅依靠問題本身進行回答。
2.粗粒度證據類(Coarse-grained Evidence, CGE):
-
(i) 全文段(Full Passage, Full):
直接將檢索得到的最相關整段文本傳給 LLM。 -
(ii) 上下文選擇(Select-Context, SeleCtx)(Li 等,2023b):?
基于困惑度(perplexity)指標,從檢索到的段落中識別并剪除冗余部分,只保留更有信息量的上下文內容。
3.細粒度證據類(Fine-grained Evidence, FGE):
-
(i) LLM-Embedder(Zhang 等,2023):
從檢索到的段落中提取與查詢最相似的子段落,作為證據。 -
(ii) Bge-Reranker-Large(Bge-Reranker)(Xiao 等,2023):
對檢索段落中的所有子句進行重排序,選出得分最高的句子作為證據。 -
(iii) FILCO(Wang 等,2023):
學習如何通過句子級別的精度過濾檢索段落,借助啟發式增強(heuristic-based augmentation)方法來標注真實標簽(ground-truth)。
研發)

)

)

)





-卡爾曼濾波)


)



IdeNet信息增強模塊 性能提升必備!](http://pic.xiahunao.cn/[IEEE TIP 2024](cv即插即用模塊分享)IdeNet信息增強模塊 性能提升必備!)