論文地址:https://ieeexplore.ieee.org/document/10661228
代碼地址:https://github.com/whyandbecause/IdeNet
什么是偽裝目標檢測(COD)?
偽裝目標檢測(Camouflaged Object Detection, COD)是計算機視覺領域的一個新興研究方向,旨在識別和分割那些與背景高度融合、難以被視覺系統察覺的目標物體。這類目標通常在顏色、紋理、形狀等方面與周圍環境非常相似,例如偽裝的動物(如變色龍)、軍事裝備(如偽裝坦克)等。與傳統目標檢測(檢測明顯的目標,如人、車)或顯著性檢測(檢測圖像中最吸引注意力的區域)不同,COD 的核心挑戰在于目標與背景的低對比度和高相似性。
引言
偽裝目標檢測(Camouflaged Object Detection, COD)是計算機視覺領域中的一項高難度任務,其目標是識別和分割那些與背景高度融合、難以察覺的物體。這類任務在軍事偵察、醫學影像分析和野生動物保護等領域有著廣泛應用。近日,一篇題為《IdeNet: Making Neural Network Identify Camouflaged Objects Like Creatures》的論文提出了一個創新的神經網絡框架——IdeNet。該框架從生物視覺系統中汲取靈感,通過模擬生物處理視覺信息的過程,顯著提升了對偽裝目標的檢測能力。本文將深入點評和解析這篇論文,探討其方法論、創新點及對 COD 領域的價值
論文核心內容
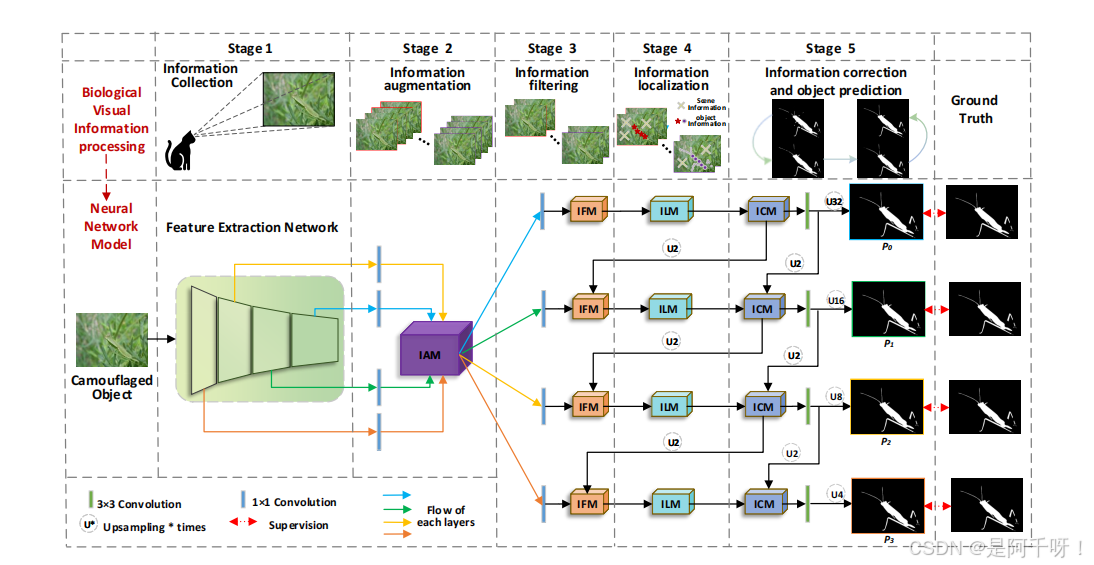
IdeNet 的核心設計靈感來源于生物視覺信息處理的五個階段,作者將這些階段轉化為神經網絡中的模塊化結構,構建了一個完整的檢測流程。以下是 IdeNet 的五個關鍵模塊及其功能:
1.信息收集(Information Collection):利用預訓練的 Pyramid Vision Transformer (PVT) 提取多尺度特征,模仿生物視網膜和視覺皮層處理環境信息的過程,為后續分析提供豐富的特征基礎,提升模型對多樣背景中偽裝目標的適應性。
2.通過多分支結構和混合空洞卷積增強特征表達,解決傳統空洞卷積的網格效應問題。
3.信息過濾:采用無卷積的組池化操作(如通道最大池化和平均池化)減少特征冗余以提升模型對多樣背景中偽裝目標的適應性,在低計算成本下突出偽裝目標的關鍵特征,抑制背景噪聲。
4.信息定位(Information Localization, ILM):結合全局場景信息(通過 Multi-Deconv Head Transposed Attention, MDHTA)和局部目標信息(多分支卷積)定位偽裝目標,讓全局與局部信息的協同作用,顯著提升復雜場景中的檢測精度。
5.信息校正與目標預測(Information Correction and Object Prediction, ICM):利用殘差空間注意力(RSAB)和通道注意力(RCAB)校正不確定區域,優化分割邊界,有效改善邊界模糊區域的分割質量。
創新點分析
1.生物啟發設計
將生物視覺機制融入神經網絡設計,模仿生物感知偽裝目標的過程,為 COD 任務提供了全新視角。
2.模塊化架構
每個模塊針對特定功能優化,結構清晰,便于擴展和改進,為后續研究提供了參考框架。
3.特征增強與過濾的結合
IAM 和 IFM 的協同工作提升了特征表達的質量和效率,克服了傳統方法在處理偽裝目標時的局限性。
4.全局與局部信息融合
ILM 模塊通過 Transformer 變體(MDHTA)和多分支卷積實現全局場景理解與局部目標定位的平衡,顯著提升檢測精度。
5.跨任務泛化能力
IdeNet 在息肉分割等醫學影像任務中的零遷移表現,證明了其強大的適應性。
實驗結果與分析
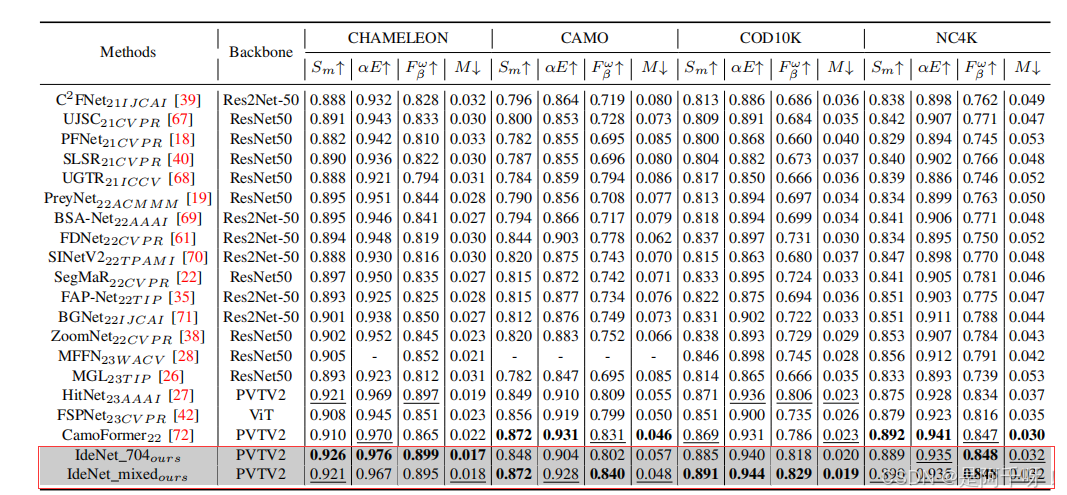
論文在多個 COD 數據集上驗證了 IdeNet 的性能,包括 COD10K、NC4K、CAMO 和 CHAMELEON,結果如下:
COD10K:在多類別偽裝目標檢測中表現最佳。
NC4K:在大規模數據上展現了優異的泛化能力。
CAMO:對復雜背景具有較強的魯棒性。
CHAMELEON:在小規模數據集上同樣表現出色。
此外,IdeNet 在醫學影像任務(如息肉分割)中無需額外訓練即可取得良好效果,顯示出其跨任務的潛力。
模塊分享:IAM 模塊:信息增強的利器
架構圖如下
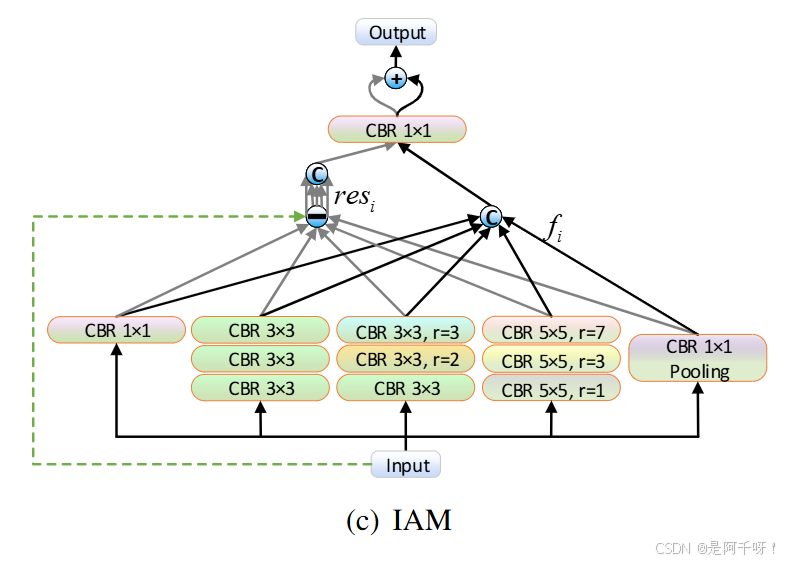
在偽裝目標檢測(Camouflaged Object Detection, COD)任務中,如何讓神經網絡從高度相似的背景中分辨出目標是一個關鍵挑戰。IAM(Information Augmentation Module,信息增強模塊)是一個專門為此設計的 PyTorch 模塊,通過多尺度特征提取和殘差連接增強特征表達能力。以下是它的代碼實現和詳細解析。
class IAM(nn.Module):def __init__(self, in_channels, out_channels=64):super(IAM, self).__init__()modules = []# 1x1 卷積分支modules.append(nn.Sequential(nn.Conv2d(in_channels, in_channels, 1, bias=False),nn.BatchNorm2d(in_channels),nn.ReLU()))# 三個不同 dilation rates 的 IAMConv 分支rate1, rate2, rate3 = [1,1,1], [1,2,3], [1,3,7]modules.append(IAMConv(in_channels, in_channels, rate1, 3, [1, 1, 1]))modules.append(IAMConv(in_channels, in_channels, rate2, 3, [1, 2, 3]))modules.append(IAMConv(in_channels, in_channels, rate3, 5, [2, 6, 14]))# 全局池化分支modules.append(IAMPooling(in_channels, in_channels))self.convs = nn.ModuleList(modules)# 投影層self.project = nn.Sequential(nn.Conv2d(5 * in_channels, out_channels, 1, bias=False),nn.BatchNorm2d(out_channels),nn.ReLU(inplace=True))def forward(self, x):res, full = [], []for conv in self.convs:f = conv(x)res.append(x - f) # 殘差full.append(f) # 特征full = torch.cat(full, dim=1) # 拼接所有特征res = torch.cat(res, dim=1) # 拼接所有殘差return self.project(full) + self.project(res) # 投影并相加
此外,IAM 依賴兩個子模塊:IAMConv 和 IAMPooling:
class IAMConv(nn.Sequential):def __init__(self, in_channels, out_channels, dilation, kernel_size, padding):modules = [nn.Conv2d(in_channels, in_channels//2, kernel_size, padding=padding[0], dilation=dilation[0], bias=False),nn.BatchNorm2d(in_channels//2),nn.ReLU(inplace=True),nn.Conv2d(in_channels//2, in_channels//2, kernel_size, padding=padding[1], dilation=dilation[1], bias=False),nn.BatchNorm2d(in_channels//2),nn.ReLU(inplace=True),nn.Conv2d(in_channels//2, in_channels, kernel_size, padding=padding[2], dilation=dilation[2], bias=False),nn.BatchNorm2d(in_channels),nn.ReLU(inplace=True),]super(IAMConv, self).__init__(*modules)class IAMPooling(nn.Sequential):def __init__(self, in_channels, out_channels):super(IAMPooling, self).__init__(nn.AdaptiveAvgPool2d(1),nn.Conv2d(in_channels, out_channels, 1, bias=False),nn.BatchNorm2d(out_channels),nn.ReLU(inplace=True))def forward(self, x):size = x.shape[-2:]x = super(IAMPooling, self).forward(x)return F.interpolate(x, size=size, mode='bilinear', align_corners=False)
模塊功能
1.增強特征表達
IAM 模塊的核心功能是通過多尺度特征提取增強網絡對偽裝目標的感知能力。它結合了以下幾個關鍵思想:
1.多尺度上下文:通過不同 dilation rates 的空洞卷積和全局池化,捕獲從局部到全局的特征。
2.殘差連接:不僅提取增強特征(f),還保留原始信息(x - f),通過拼接和投影融合兩者。
3.深度特征提取:IAMConv 中的三層卷積結構使得特征提取更加細致。
這種設計特別適合 COD 任務,因為偽裝目標往往與背景高度融合,傳統的單尺度卷積難以有效區分,而 IAM 的多尺度策略和殘差機制能夠顯著提升特征的區分度。
與 ASPP 的區別:
ASPP 通常使用單層空洞卷積,而 IAM 的 IAMConv 是三層卷積,更注重特征的深度提取,IAM 引入了殘差連接,這是 ASPP 所沒有的創新點。
使用場景
IAM 模塊特別適合需要細致特征增強的任務,例如偽裝目標檢測、語義分割等,主要因為其在多尺度能力(通過不同 dilation rates 和全局池化,適應不同大小的目標。),信息保留有優勢。
完整代碼
有困惑或者不知道怎么使用比較好的可以進主頁交流群進行討論
class IAM(nn.Module):def __init__(self, in_channels, out_channels=64):super(IAM, self).__init__()#out_channels = 128modules = []modules.append(nn.Sequential(nn.Conv2d(in_channels, in_channels, 1, bias=False),nn.BatchNorm2d(in_channels),nn.ReLU()))rate1, rate2, rate3 = [1,1,1], [1,2,3], [1,3,7]modules.append(IAMConv(in_channels, in_channels, rate1, 3, [1, 1, 1]))modules.append(IAMConv(in_channels, in_channels, rate2, 3, [1, 2, 3])) #ke = k + (k ? 1)(r ? 1) p = (ke -1)//2modules.append(IAMConv(in_channels, in_channels, rate3, 5, [2, 6, 14]))modules.append(IAMPooling(in_channels, in_channels))self.convs = nn.ModuleList(modules)self.project = nn.Sequential(nn.Conv2d(5 * in_channels, out_channels, 1, bias=False),nn.BatchNorm2d(out_channels),nn.ReLU(inplace=True))def forward(self, x):res, full = [], []for conv in self.convs:f = conv(x)res.append(x-f)full.append(f)full = torch.cat(full, dim=1)res = torch.cat(res, dim=1)return self.project(full)+self.project(res)class IAMConv(nn.Sequential):def __init__(self, in_channels, out_channels, dilation, kernel_size, padding):modules = [nn.Conv2d(in_channels, in_channels//2, kernel_size, padding=padding[0], dilation=dilation[0], bias=False),nn.BatchNorm2d(in_channels//2),nn.ReLU(inplace=True),nn.Conv2d(in_channels//2, in_channels//2, kernel_size, padding=padding[1], dilation=dilation[1], bias=False),nn.BatchNorm2d(in_channels//2),nn.ReLU(inplace=True),nn.Conv2d(in_channels//2, in_channels, kernel_size, padding=padding[2], dilation=dilation[2], bias=False),nn.BatchNorm2d(in_channels),nn.ReLU(inplace=True),]super(IAMConv, self).__init__(*modules)class IAMPooling(nn.Sequential):def __init__(self, in_channels, out_channels):super(IAMPooling, self).__init__(nn.AdaptiveAvgPool2d(1),nn.Conv2d(in_channels, out_channels, 1, bias=False),nn.BatchNorm2d(out_channels),nn.ReLU(inplace=True))def forward(self, x):size = x.shape[-2:]x = super(ASPPPooling, self).forward(x)return F.interpolate(x, size=size, mode='bilinear', align_corners=False)



詳解:從零開始掌握(2))

:字節最新表情+動作模仿視頻生成DreamActor-M1)












