1.開場白
上一期講了 TF-IDF 的底層原理,簡單講了一下它可以將文本轉為向量形式,并搭配相應分類器做文本分類,且即便如今的企業實踐中也十分常見。詳情請見我的上一篇文章 從One-Hot到TF-IDF(點我跳轉)
光說不練假把式,在這篇文章中,你更加深刻了解TF-IDF是如何做文本分類的。具體有:
- 使用sklearn庫進行TFIDF向量化
- 使用不同的分類器(SVM, 隨機森林, XGBoost)做文本分類
- 搭配不同分類器的效果如何?
在開始之前推薦一個Github的開源項目。里面有很多開源數據集,很適合新手去探索 --> NLP民工樂園(本篇文章的數據集也是取自這里)
2.原理
1.TFIDF
TFIDF的原理雖然之前已經介紹了,但是這里還是簡單講一下好了。
TF-IDF(Term Frequency-Inverse Document Frequency)是一種用于信息檢索和文本挖掘的加權技術,用于評估一個詞在文檔中的重要程度。它由兩部分組成:
1. 詞頻(Term Frequency, TF)
衡量一個詞在當前文檔中出現的頻率:
T F ( t , d ) = f t , d ∑ t ′ ∈ d f t ′ , d TF(t, d) = \frac{f_{t,d}}{\sum_{t' \in d} f_{t',d}} TF(t,d)=∑t′∈d?ft′,d?ft,d??
其中:
- f t , d f_{t,d} ft,d?:詞 t t t 在文檔 d d d 中的出現次數
- ∑ t ′ ∈ d f t ′ , d \sum_{t' \in d} f_{t',d} ∑t′∈d?ft′,d?:文檔 d d d 中所有詞的出現次數總和
2. 逆文檔頻率(Inverse Document Frequency, IDF)
衡量一個詞的普遍重要性(在多少文檔中出現):
I D F ( t , D ) = log ? ( N ∣ { d ∈ D : t ∈ d } ∣ ) IDF(t, D) = \log \left( \frac{N}{|\{d \in D : t \in d\}|} \right) IDF(t,D)=log(∣{d∈D:t∈d}∣N?)
其中:
- N N N:語料庫中文檔的總數
- ∣ { d ∈ D : t ∈ d } ∣ |\{d \in D : t \in d\}| ∣{d∈D:t∈d}∣:包含詞 t t t 的文檔數量
3. TF-IDF 最終公式
將TF和IDF相乘得到最終權重:
T F - I D F ( t , d , D ) = T F ( t , d ) × I D F ( t , D ) TF\text{-}IDF(t, d, D) = TF(t, d) \times IDF(t, D) TF-IDF(t,d,D)=TF(t,d)×IDF(t,D)
4. 變體說明
實際應用中可能存在不同變體,例如:
- TF變體:對數縮放 T F = log ? ( 1 + f t , d ) TF = \log(1 + f_{t,d}) TF=log(1+ft,d?)
- IDF變體:避免除零 I D F = log ? ( N 1 + n t ) + 1 IDF = \log(\frac{N}{1 + n_t}) + 1 IDF=log(1+nt?N?)+1
- 歸一化:對文檔向量進行L2歸一化
2.SVM
全名支持向量機,簡稱SVM,在2000年前后的CPU時代,它也曾是頂流。
具體原理見我的另一篇文章,這是一篇背書于《統計學習方法》的、用嚴謹的數學進行SVM推導的文章 --> 支持向量機
之所以他曾是頂流,主要因為它具備如下優勢:
- SVM不存在現代深度學習反向傳播的過擬合
- 小樣本數據集上表現良好
- CPU環境下就能訓練、推理,邊緣設備(普通電腦)上也能跑起來
- 數學背景好,理論嚴謹
但是現在又被“淘汰”了,原因有:
- 大數據時代,SVM拓展性不足,數據量龐大的情況下訓練很慢,相反深度學習可以利用GPU的并行,加速推理
- 泛化能力有限,SVM需要手動特征,而深度學習可以端到端自動學習特征
- 非線性場景能力有限,即便有核技巧處理非線性場景,但是函數選擇和調參比較麻煩。
- 深度學習可以疊的很深,可以學習到數據中更加抽象、深層的信息,但SVM與之相比是淺層模型,學習到的信息有限。
關于支持向量機的作者 Vapnik,他還和現任人工智能的三駕馬車 LeCun 有一段有趣的軼事,他們兩個同為貝爾實驗室的同事,因為學術之爭處處不合。后來他們兩位之間的爭論某種意義上來說也代表了傳統機器學習和深度學習之間的對碰。具體請見我的另一篇文章 自然語言處理發展史(點我跳轉)
3.XGBoost
XGBoost 是梯度提升樹GBDT的改良版,他們都是樹模型的一種。
什么?你問我什么是樹模型?好吧,這里我來解答一下,其實樹模型是決策樹類模型的簡稱,業內常常管決策樹類的模型叫輸模型。
至于決策樹模型,可以見我另一篇文章 決策樹(點我跳轉)
跳轉文章講了決策樹模型的基本原理,從純數學的角度出發,帶你理解決策樹模型。
有了決策樹的基礎,理解GBDT和XGBoost就不是問題了。
那么讓我們先了解GBDT,再看一看他是如何從GBDT過渡到XGBoost的吧
1.GBDT(梯度提升樹)
GBDT(Gradient Boosting Decision Tree)的核心思想是通過加法模型(Additive Model)將多個弱分類器(通常是決策樹)的預測結果逐步累加,從而逼近真實值。
具體來說, 每一輪迭代都會訓練一個新的弱分類器,使其擬合當前模型的負梯度(即殘差的近似),而非直接擬合殘差本身。
這里的“殘差”可以理解為當前模型的預測值與真實值之間的誤差方向,而GBDT通過梯度下降的策略逐步減少這一誤差。
如圖,Y = Y1 + Y2 + Y3

舉一個非常簡單的例子,比如我今年30歲了,但計算機或者模型GBDT并不知道我今年多少歲,那GBDT咋辦呢?
它會在第一個弱分類器(或第一棵樹中)隨便用一個年齡比如20歲來擬合,然后發現誤差有10歲;
接下來在第二棵樹中,用6歲去擬合剩下的損失,發現差距還有4歲;
接著在第三棵樹中用3歲擬合剩下的差距,發現差距只有1歲了;
最后在第四課樹中用1歲擬合剩下的殘差,完美。
最終,四棵樹的結論加起來,就是真實年齡30歲。
實際工程中,gbdt是計算負梯度,用負梯度近似殘差.
那么為什么用負梯度近似殘差呢?
回歸任務下,GBDT 在每一輪的迭代時對每個樣本都會有一個預測值,此時的損失函數為均方差損失函數,
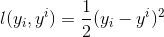
那此時的負梯度是這樣計算的
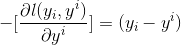
所以,當損失函數選用均方損失函數時,每一次擬合的值就是(真實值 - 當前模型預測的值),即殘差。
此時的變量是 y i y^i yi,即“當前預測模型的值”,也就是對它求負梯度。
2.XGBoost(極度梯度提升)
核心思想如圖
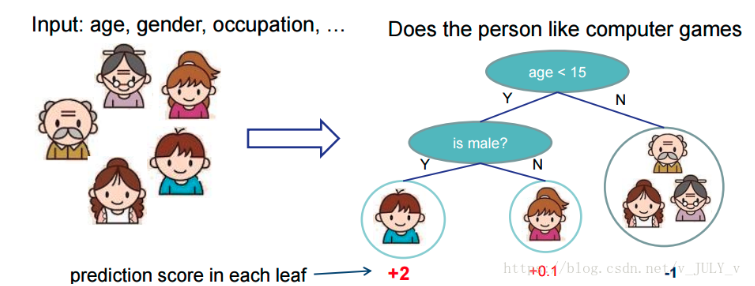

(作者陳天奇大佬的原圖)
可以看到,男孩的計算得分是兩個樹的相加 2+0.9=2.9
這不和GBDT一樣么!
確實,如果不考慮工程實現、解決問題上的一些差異,xgboost與gbdt比較大的不同就是目標函數的定義。
xgboost的目標函數如下圖所示:
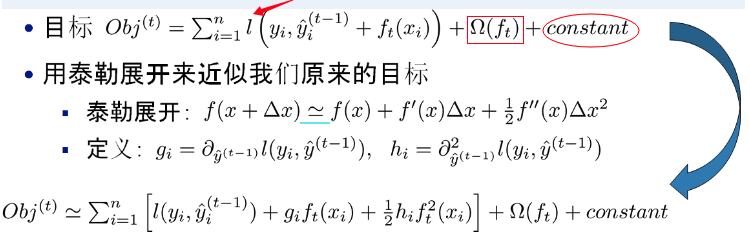

XGBoost的核心算法思想不難,基本就是:
- 不斷地添加樹,不斷地進行特征分裂來生長一棵樹,每次添加一個樹,其實是學習一個新函數f(x),去擬合上次預測的殘差。
- 當我們訓練完成得到k棵樹,我們要預測一個樣本的分數,其實就是根據這個樣本的特征,在每棵樹中會落到對應的一個葉子節點,每個葉子節點就對應一個分數
- 最后只需要將每棵樹對應的分數加起來就是該樣本的預測值。
為什么XGBoost要用泰勒展開,優勢在哪里?
XGBoost使用了一階和二階偏導, 二階導數有利于梯度下降的更快更準. 使用泰勒展開取得函數做自變量的二階導數形式, 可以在不選定損失函數具體形式的情況下, 僅僅依靠輸入數據的值就可以進行葉子分裂優化計算, 本質上也就把損失函數的選取和模型算法優化/參數選擇分開了. 這種去耦合增加了XGBoost的適用性, 使得它按需選取損失函數, 可以用于分類, 也可以用于回歸。
3.數據集
該篇文章數據集地址 酒店評論 (也出自開頭推薦的那個Github開源項目里)
該數據集是一個酒店評價數據集,有兩個字段:
- review為用戶評論
- label為情感的正負類標簽,其中1為正面情緒,0為負面情緒
數據集預覽

4.技術實踐
1.sklearn中的使用TFIDF
前提:安裝sklearn
pip install scikit-learn
在 scikit-learn (sklearn) 中,TfidfVectorizer 是用于 TF-IDF文本特征提取的主要類。它屬于 sklearn.feature_extraction.text 模塊,主要用于將文本數據轉換為數值特征矩陣
下面講一下它的關鍵參數吧~
stop_words{‘english’}, list, default=Nonengram_range: tuple (min_n, max_n)` default=(1, 1)
a. 要提取的不同n-gram的n值范圍的下限和上限。將使用min_n<=n<=max_n的所有n值。max_dffloat or int, default=1.0:
i. 在構建詞匯表時,忽略文檔頻率嚴格高于給定閾值的術語(特定于語料庫的停用詞)。如果在[0.0,1.0]范圍內,則該參數表示文檔的比例,即整數絕對計數。如果詞匯表不是None,則忽略此參數。min_dffloat or int, default=1
i. 在構建詞匯表時,忽略文檔頻率嚴格低于給定閾值的術語。這個值在文獻中也被稱為截止值。如果浮點數在[0.0,1.0]的范圍內,則該參數表示文檔的比例,即整數絕對計數。如果詞匯表不是None,則忽略此參數。max_featuresint, default=None
i. 如果不是None,則構建一個詞匯表,只考慮語料庫中按詞頻排序的頂級max_features。否則,將使用所有功能。
如果詞匯表不是None,則忽略此參數。smooth_idfbool, default=True
i. 通過在文檔頻率上加1來平滑idf權重,就像看到一個額外的文檔包含集合中的每個術語一樣。sublinear_tfbool, default=False
i. 應用亞線性tf縮放,即將 tf 替換為1 + log(tf)。
tfidf = TfidfVectorizer(max_features=5000, stop_words=stopwords, ngram_range=(1,2),min_df=3, # 過濾低頻詞max_df=0.9, # 過濾高頻詞# sublinear_tf=True, # 對數平滑,降低詞頻影響
)
X = tfidf.fit_transform(train_df['processed_text'])
- 總結
a. 注意調整ngram_range和max_features。直接對效率和特征表示能力相關聯。
2.XGBoost
前提:安裝XGBoost
pip install xgboost
下面講講xgboost的使用吧
1. 通用參數:
宏觀函數控制 在 xgboost.config_context() 設置
a. verbosity: Valid values of 0 (silent), 1 (warning), 2 (info), and 3 (debug).
2. 一般參數:
a. booster [default= gbtree ]。使用哪種助推器。可以是gbtree、gblinear或dart;gbtree和dart使用基于樹的模型,而gblinear使用線性函數。
b. device [default= cpu]
c. nthread [如果未設置,則默認為可用的最大線程數]
3. Booster 參數
a. eta [default=0.3, alias(別名): learning_rate]
b. gamma [default=0, alias: min_split_loss][0,∞]
- 在樹的葉子節點上進行進一步分區所需的最小損失減少。gamma越大,算法就越保守。請注意,沒有進行分割的樹可能仍然包含一個非零分數的終端節點。
c. max_depth [default=6][0,∞]
- 樹的最大深度。增加此值將使模型更加復雜,更有可能過度擬合。0表示深度沒有限制。請注意,XGBoost在訓練深層樹時會大量消耗內存。精確樹方法需要非零值。
d. min_child_weight [default=1][0,∞]
- 孩子結點所需實例權重的最小總和。如果樹分區步驟導致葉節點的實例權重之和小于min_child_weight,則構建過程將放棄進一步的分區。在線性回歸任務中,這只對應于每個節點中需要的最小實例數。min_child_weight越大,算法就越保守。
e. subsample [default=1]
- 訓練實例的子樣本比率。將其設置為0.5意味著XGBoost將在種植樹木之前隨機采樣一半的訓練數據。這將防止過擬合。子采樣將在每次增強迭代中發生一次。
f. lambda [default=1, alias: reg_lambda]
- 權重的L2正則化項。增加此值將使模型更加保守。range: [0, ∞]
g. alpha [default=0, alias: reg_alpha]
- 權重上的L1正則化項。增加此值將使模型更加保守。range: [0, ∞]
h. tree_method string [default= auto] auto, exact, approx, hist
- auto: 與hist-tree方法相同。
- exact: 精確貪婪算法。枚舉所有拆分的候選人。
- approx:使用分位數草圖和梯度直方圖的近似貪婪算法。
- hist: 更快的直方圖優化近似貪婪算法。
i. scale_pos_weight [default=1]
- 控制正負權重的平衡,對不平衡的類很有用。需要考慮的典型值:sum(負實例)/sum(正實例)。
4. 特定學習任務參數
指定學習任務和相應的學習目標。目標選項如下
objective[default=reg:squarederror]
a.reg:squarederror: 平方誤差:損失平方的回歸
b.reg:squaredlogerror: 平方對數誤差:具有平方對數損失的回歸。所有輸入標簽都必須大于-1
c.reg:logistic: 邏輯回歸,輸出概率
d. reg:pseudohubererror:偽Huber誤差:使用偽Huber損失的回歸,這是絕對損失的兩次可微替代方案。
e.reg:absoluteerror: 絕對誤差:L1誤差回歸。當使用樹模型時,在樹構建后刷新葉值。如果在分布式訓練中使用,葉值將作為所有工人的平均值計算,這并不能保證是最優的。
f.reg:quantileerror:分位數損失,也稱為彈球損失。
g.binary:logistic: 二元邏輯回歸:用于二元分類的邏輯回歸,輸出概率
h.binary:logitraw: 二元分類的邏輯回歸,邏輯轉換前的輸出分數
i. binary:hinge:二元分類的鉸鏈損失。這使得預測為0或1,而不是產生概率。
j.multi:softmax: 設置XGBoost使用softmax目標進行多類分類,還需要設置num_class(類的數量)
k.multi:softprob: 與softmax相同,但輸出一個 ndatanclass 向量,該向量可以進一步整形為ndatanclass矩陣。結果包含每個數據點屬于每個類的預測概率。- eval_metric [default according to objective] :驗證數據的評估指標,將根據目標分配默認指標(回歸的rmse,分類的logloss,排名的平均精度:映射等)
a.rmse: 均方根誤差
b.mae: 平均絕對誤差
c.logloss: 負對數似然
d.auc: ROC曲線下與坐標軸圍成的面積。可用于分類和學習任務排名。- 用于二分類時,目標函數應為binary:logistic或類似的處理概率的函數。
- 用于多分類時,目標函數應為multi:softprob而非multi:softmax,因為后者不輸出概率。AUC通過1對其余類計算,參考類由類別比例加權。
- 當輸入數據集只包含負樣本或正樣本時,輸出為NaN。具體行為取決于實現,例如scikit-learn會返回0.5。
5. XGBoost調優
1.控制過擬合
當你觀察到訓練精度很高,但測試精度很低時,很可能會遇到過擬合問題
在XGBoost中,通常有兩種方法可以控制過擬合:
第一種方法是直接控制模型的復雜性。
a. 包括 max_depth, min_child_weight and gamma.
第二種方法是增加隨機性,使訓練對噪聲具有魯棒性。
a. 包括 subsample and colsample_bytree
b. 您還可以減小步長 eta。執行此操作時,請記住增加num_round
2.處理不平衡數據集
數據集非常不平衡。這會影響XGBoost模型的訓練,有兩種方法可以改進它。
- 如果你只關心預測的整體性能指標(AUC)
- 通過
scale_pos_weight平衡正負權重
- 通過
- 如果你關心預測正確的概率
- 將參數
max_delta_step設置為有限數(比如1)以幫助收斂
- 將參數
5.使用TFIDF做特征,用SVM或XGBoost做分類器,做酒店評價的情感分析

1.分詞
ps:由于中文和英文不一樣,英文會天然的使用空格進行分詞,但是中文的一句話是連貫的。如:
英文:I want to go to Beijing.
中文:我想去北京。
如果把英語交給模型,模型收到的是 ["I", "want", "to", "go", "to", "Beijing", "."],總共6個詞。
但是如果把中文交給模型,模型收到的是 我想去北京。,總共1個詞。
故在NLP中,中文領域都是要分詞的。
但是中文如果直接以“字”分詞,效果可能很可能不好,因為中文是以詞為單位的。如 北京 (一個詞)和 北、京 (兩個字)是兩個完全不同的概念。
如果是傳統的機器學習文本分類,如SVM和XGBoost通常是采用 Jieba 庫來進行分詞的。
關于這個庫我以后會專門出一篇文章來講。
總之,在這篇文章中先不考慮jieba的原理,你只需要知道他可以進行如下方式的分詞即可。
text = "我要去北京。"
print(jieba.lcut(text))# # ['我要', '去', '北京', '。']
1.這里使用的是
lcut而不是cut,是因為方便打印展示,lcut會直接返回list(迭代器),而cut會返回一個生成器<generator object Tokenizer.cut at 0x164a07a00>.
2.其實業務中大多還是采用生成器cut的形式,因為生成器是惰性迭代計算的,內存效率高。
簡單解釋一下生成器和迭代器的區別。
生成器 vs 迭代器(列表)(以"我要去北京。"為例):
列表:像把所有分詞結果裝進盒子
lcut(“我要去北京。”) → 直接給你 [‘我要’, ‘去’, ‘北京’, ‘。’]
生成器:像現用現做的流水線
cut(“我要去北京。”) → 需要時才一個個生成:
‘我要’ → ‘去’ → ‘北京’ → ‘。’
區別:
列表:一次性全做好(占內存,但能反復用)
生成器:用的時候才做(省內存,但只能用一次)
(如果同學不理解生成器和列表的區別,可以評論或留言,我會迅速轉門出一篇文章來闡述他倆的區別)
2.使用SVM做分類器
import time
import pandas as pd
import jieba
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.svm import SVC
from sklearn.metrics import classification_report# 記錄總開始時間
total_start = time.time()# 1. 數據加載
print("1. 正在加載數據...")
start = time.time()
data = pd.read_csv('/Users/zhangqingjie/Downloads/ChnSentiCorp_htl_all.csv') # 替換為你的文件路徑
print(f"數據加載完成,用時: {time.time() - start:.2f}秒")
print(f"數據樣本數: {len(data)}")# 2. 中文分詞
print("\n2. 正在進行中文分詞...")
start = time.time()def chinese_tokenizer(text):return ' '.join(jieba.cut(text))data['review'] = data['review'].fillna('')
data['tokenized_review'] = data['review'].apply(chinese_tokenizer)
print(f"分詞完成,用時: {time.time() - start:.2f}秒")# 3. 數據劃分
print("\n3. 正在劃分訓練集和測試集...")
start = time.time()
X_train, X_test, y_train, y_test = train_test_split(data['tokenized_review'], data['label'], test_size=0.2, random_state=42,shuffle=True
)
print(f"數據劃分完成,用時: {time.time() - start:.2f}秒")
print(f"訓練集大小: {len(X_train)}, 測試集大小: {len(X_test)}")# 4. TF-IDF特征提取
print("\n4. 正在進行TF-IDF特征提取...")
start = time.time()
tfidf = TfidfVectorizer(max_features=5000)
X_train_tfidf = tfidf.fit_transform(X_train)
X_test_tfidf = tfidf.transform(X_test)
print(f"TF-IDF特征提取完成,用時: {time.time() - start:.2f}秒")
print(f"特征維度: {X_train_tfidf.shape[1]}")# 5. SVM模型訓練
print("\n5. 正在訓練SVM模型...")
start = time.time()
svm_model = SVC(kernel='linear', random_state=42)
svm_model.fit(X_train_tfidf, y_train)
print(f"SVM模型訓練完成,用時: {time.time() - start:.2f}秒")# 6. 模型評估
print("\n6. 正在評估模型...")
start = time.time()
y_pred = svm_model.predict(X_test_tfidf)
print("分類報告:")
print(classification_report(y_test, y_pred))
print(f"模型評估完成,用時: {time.time() - start:.2f}秒")# 總用時
print(f"\n總用時: {time.time() - total_start:.2f}秒")
最終效果
分類報告:precision recall f1-score support0 0.84 0.76 0.80 5051 0.89 0.93 0.91 1049accuracy 0.88 1554macro avg 0.87 0.85 0.86 1554
weighted avg 0.88 0.88 0.88 1554
3.使用XGBoost做分類器
import time
import pandas as pd
import jieba
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
from xgboost import XGBClassifier
from sklearn.metrics import classification_report# 記錄總開始時間
total_start = time.time()# 1. 數據加載
print("1. 正在加載數據...")
start = time.time()
data = pd.read_csv('/Users/zhangqingjie/Downloads/ChnSentiCorp_htl_all.csv') # 替換為你的文件路徑
print(f"數據加載完成,用時: {time.time() - start:.2f}秒")
print(f"數據樣本數: {len(data)}")# 2. 中文分詞
print("\n2. 正在進行中文分詞...")
start = time.time()def chinese_tokenizer(text):return ' '.join(jieba.cut(text))data['review'] = data['review'].fillna('')
data['tokenized_review'] = data['review'].apply(chinese_tokenizer)
print(f"分詞完成,用時: {time.time() - start:.2f}秒")# 3. 數據劃分
print("\n3. 正在劃分訓練集和測試集...")
start = time.time()
X_train, X_test, y_train, y_test = train_test_split(data['tokenized_review'], data['label'], test_size=0.2, random_state=42,shuffle=True
)
print(f"數據劃分完成,用時: {time.time() - start:.2f}秒")
print(f"訓練集大小: {len(X_train)}, 測試集大小: {len(X_test)}")# 4. TF-IDF特征提取
print("\n4. 正在進行TF-IDF特征提取...")
start = time.time()
tfidf = TfidfVectorizer(max_features=5000)
X_train_tfidf = tfidf.fit_transform(X_train)
X_test_tfidf = tfidf.transform(X_test)
print(f"TF-IDF特征提取完成,用時: {time.time() - start:.2f}秒")
print(f"特征維度: {X_train_tfidf.shape[1]}")# 5. XGBoost模型訓練
print("\n5. 正在訓練XGBoost模型...")
start = time.time()
xgb_model = XGBClassifier(n_estimators=100,max_depth=6,learning_rate=0.1,random_state=42,use_label_encoder=False,eval_metric='logloss'
)
xgb_model.fit(X_train_tfidf, y_train)
print(f"XGBoost模型訓練完成,用時: {time.time() - start:.2f}秒")# 6. 模型評估
print("\n6. 正在評估模型...")
start = time.time()
y_pred = xgb_model.predict(X_test_tfidf)
print("分類報告:")
print(classification_report(y_test, y_pred))
print(f"模型評估完成,用時: {time.time() - start:.2f}秒")# 總用時
print(f"\n總用時: {time.time() - total_start:.2f}秒")
效果如下:
precision recall f1-score support0 0.82 0.65 0.73 5051 0.85 0.93 0.89 1049accuracy 0.84 1554macro avg 0.84 0.79 0.81 1554
weighted avg 0.84 0.84 0.84 1554
4.效果對比
| 模型 | 類別 | 精確率 | 召回率 | F1分數 | 準確率 |
|---|---|---|---|---|---|
| SVM | 0 | 0.84 | 0.76 | 0.80 | 0.88 |
| 1 | 0.89 | 0.93 | 0.91 | ||
| XGBoost | 0 | 0.82 | 0.65 | 0.73 | 0.84 |
| 1 | 0.85 | 0.93 | 0.89 |
看起來SVM更勝一籌啊。
調調參,嘗試搶救一下XGBoost
xgb_model = XGBClassifier(n_estimators=800,max_depth=8,subsample=0.8, # 每棵樹隨機采樣80%數據learning_rate=0.03,random_state=42,use_label_encoder=False, objective='binary:logistic',eval_metric='logloss'
)
現在效果如下
分類報告:precision recall f1-score support0 0.82 0.73 0.77 5051 0.88 0.92 0.90 1049accuracy 0.86 1554macro avg 0.85 0.82 0.83 1554
weighted avg 0.86 0.86 0.86 1554
貌似還是差點意思。。。
6. 總結與收獲
通過本篇文章的實踐,我們系統地學習了如何使用TF-IDF結合不同分類器進行文本分類任務。以下是本次實踐的核心收獲:
5.1 關鍵技術掌握
-
TF-IDF特征提取
- 熟練使用sklearn的
TfidfVectorizer進行文本向量化 - 理解了
max_features、ngram_range等關鍵參數對特征空間的影響 - 掌握了中文分詞處理技巧
- 熟練使用sklearn的
-
分類器應用對比
- 實現了SVM和XGBoost兩種主流分類器
- 觀察到SVM在本任務中表現略優(88% vs 86%準確率)
- 實踐了XGBoost的參數調優過程
-
完整Pipeline構建
- 從數據加載、預處理到模型訓練評估的全流程實踐
- 掌握了文本分類任務的標準化開發流程
5.2 實踐洞見
-
SVM的優勢顯現
- 在小規模文本數據上,SVM展現出更好的分類性能
- 特別是對負類(差評)的識別更準確(F1 0.80 vs 0.77)
- 驗證了SVM在高維稀疏特征上的優勢
-
XGBoost的調參經驗
- 通過調整n_estimators、learning_rate等參數提升效果
- 發現樹模型需要更精細的參數調整才能達到理想效果
- 證明了boosting算法在文本分類中的適用性
-
特征工程的關鍵性
- TF-IDF作為基礎特征提取方法仍然非常有效
- 中文分詞質量直接影響最終分類效果
- 特征維度控制(max_features)對模型效率影響顯著
思考題🤔
-
在本實驗中,SVM在文本分類任務上表現略優于XGBoost(88% vs 86%準確率)。結合文章提到的原理,你認為可能是什么原因導致的?如果數據集規模擴大10倍,結果可能會發生怎樣的變化?為什么?
-
TF-IDF的ngram_range沒有特別指定,其實內部是采用默認值的
tfidf = TfidfVectorizer(max_features=5000, ngram_range=(1,1)),(即僅使用單詞)。如果將其改為(1,2)(包含單詞和雙詞組合),你認為會對分類效果產生什么影響?嘗試修改代碼并觀察結果,驗證你的猜想。
下期預告🚀
現在的NLP模型大多是預訓練語言模型BERT類和GPT的衍生,你知道最初的預訓練語言模型是什么樣的么?
在 Transformer 和注意力機制崛起之前,Word2Vec 率先用『詞向量』顛覆了傳統 NLP——它讓單詞不再是孤立的符號,而是蘊含語義的數學向量。
下一期將深入拆解:
🔹 為什么Word2Vec是預訓練模型的雛形
🔹 CBOW和Skip-Gram究竟有什么區別?
🔹 GloVe、FastText 等變體如何改進 Word2Vec?





-卡爾曼濾波)


)



IdeNet信息增強模塊 性能提升必備!](http://pic.xiahunao.cn/[IEEE TIP 2024](cv即插即用模塊分享)IdeNet信息增強模塊 性能提升必備!)



詳解:從零開始掌握(2))

:字節最新表情+動作模仿視頻生成DreamActor-M1)
