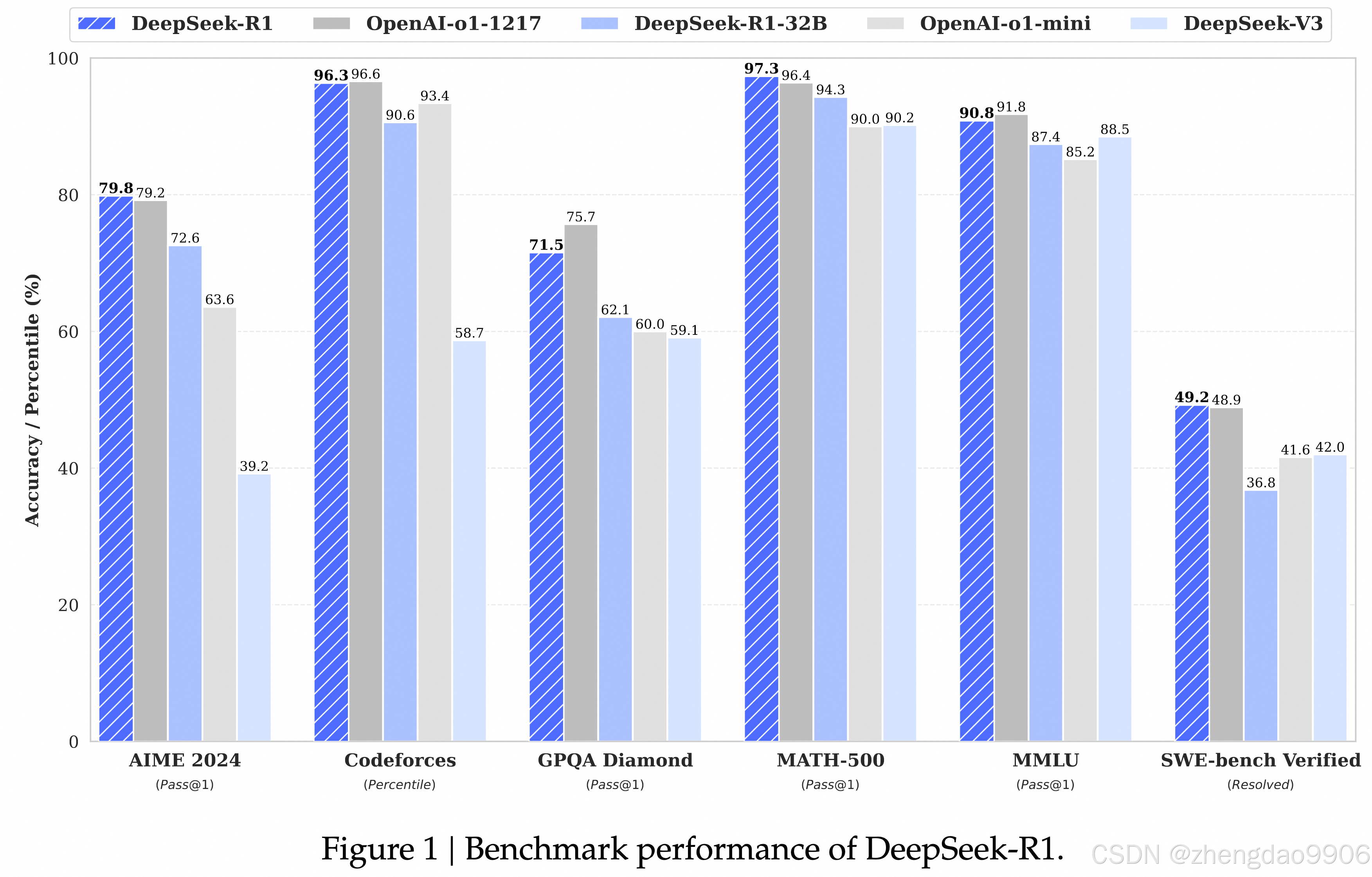
最強開源LLM,性能和效果都很棒;在數學、代碼這種有標準正確答案的場景,表現尤為突出;一些其他場景的效果,可能不如DeepSeek-V3和Qwen。
Deepseek-R1沒有使用傳統的有監督微調sft方法來優化模型,而使用了大規模強化學習RL來實現推理能力的提升。更進一步,通過引入冷啟動解決僅RL遇到的缺陷。
以往的研究工作大多依賴于大量的監督數據來提升模型性能。在本研究中展示了即使不依賴監督微調(SFT)作為預訓練步驟,通過大規模強化學習(RL)也能顯著提升推理能力。此外,我們還展示了通過引入少量冷啟動數據可以進一步提升性能。在接下來的章節中,將按順序介紹:
(1)DeepSeek-R1-Zero,它直接在基礎模型上應用 RL,不依賴任何監督微調數據;介紹了如何直接在基礎模型上進行大規模強化學習,無需監督微調數據。
(2)DeepSeek-R1,它從經過長推理鏈(Chain-of-Thought, CoT)數據微調的檢查點開始應用 RL;介紹了多階段訓練流程如何打造出性能卓越的推理模型。
(3)將 DeepSeek-R1 的推理能力蒸餾到小型dense模型中,介紹了如何將大模型的推理能力有效轉移到小模型中。

DeepSeek-R1-Zero

RL算子
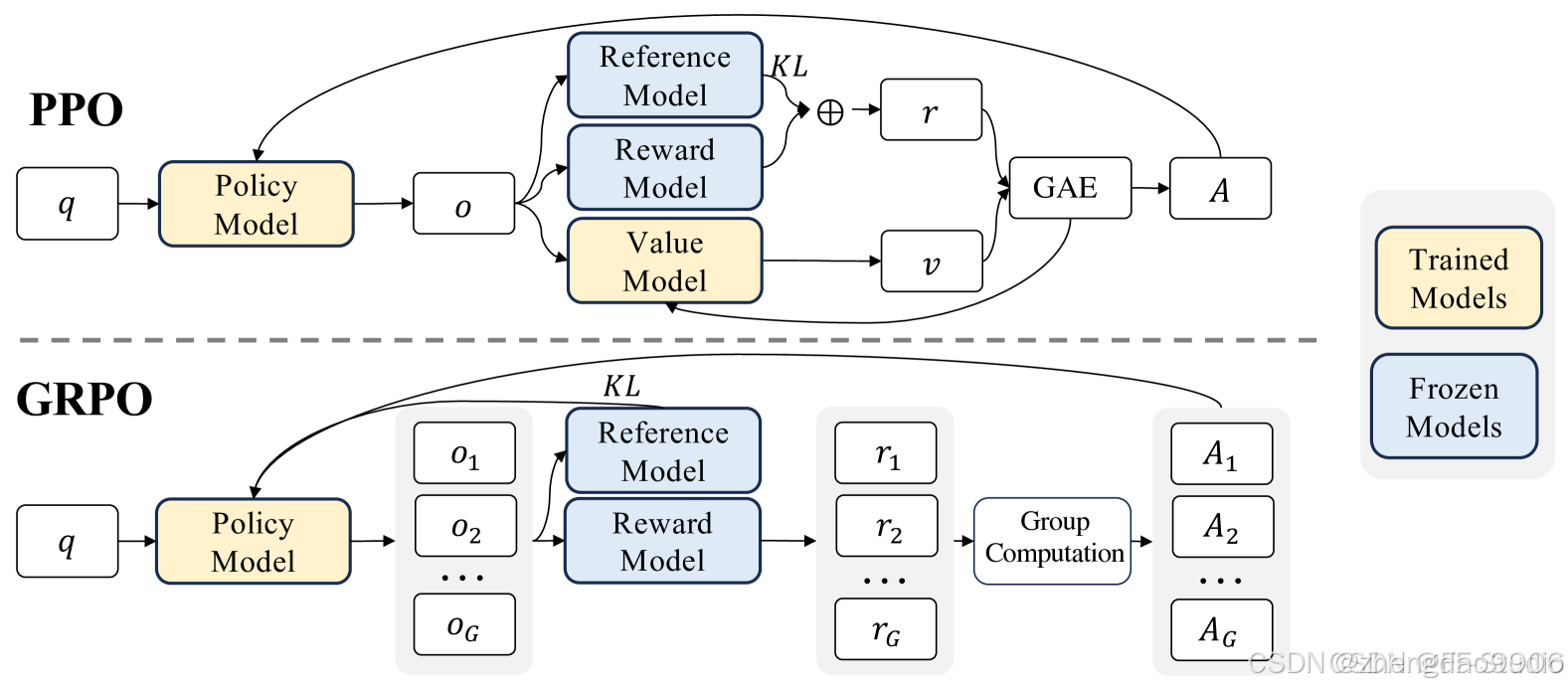
為了節省 RL 的訓練成本,我們采用了 Group Relative Policy Optimization(GRPO)。GRPO 放棄了通常與策略模型大小相同的批判模型(critic model),而是通過組分數來估計Baseline。

獎勵模型
在這一步,只使用了基于規則的獎勵模型。
獎勵是訓練信號的來源,決定了 RL 的優化方向。為了訓練 DeepSeek-R1-Zero,我們采用基于規則的獎勵系統,主要包括以下兩種獎勵:
● 準確性獎勵:準確性獎勵模型用于評估回答是否正確。例如,在數學問題中,模型需要以指定格式(例如在方框內)提供最終答案,以便可靠地通過基于規則的驗證來確認正確性。同樣,在 LeetCode 問題中,可以使用編譯器根據預定義的測試用例生成反饋。
● 格式獎勵:除了準確性獎勵模型外,我們還采用格式獎勵模型,強制模型將推理過程放在 和 標簽之間。
沒有在開發 DeepSeek-R1-Zero 時應用結果或過程神經獎勵模型,因為我們發現神經獎勵模型可能在大規模強化學習過程中出現獎勵劫持(reward hacking)的問題,而重新訓練獎勵模型需要額外的訓練資源,并且會使整個訓練流程復雜化。
為了訓練 DeepSeek-R1-Zero,設計了一個簡單的模板,指導基礎模型按照我們的指定指令進行操作。如上表所示,該模板要求 DeepSeek-R1-Zero 首先生成推理過程,然后提供最終答案。我們故意將約束限制在這一結構化格式上,避免任何內容相關的偏見——例如強制要求反思性推理或推廣特定的解決問題策略——以確保我們能夠準確觀察模型在強化學習(RL)過程中的自然發展。
相關發現&總結
- “頓悟時刻”
在這個階段,DeepSeek-R1-Zero 學會為問題分配更多的思考時間,通過重新評估其初始方法來實現。這種行為不僅是模型推理能力增長的證明,也是研究人員觀察其行為的一個“頓悟時刻”。
它突顯了強化學習的力量和美麗:我們不是明確地教模型如何解決問題,而是僅僅提供正確的激勵,模型就會自主發展出高級的問題解決策略。“頓悟時刻” 有力地提醒我們,RL 解鎖人工系統中智力新水平的潛力,為未來更自主、更適應性強的模型鋪平了道路。 - DeepSeek-R1-Zero 的缺點
盡管 DeepSeek-R1-Zero 展示了強大的推理能力,并且能夠自主發展出意外且強大的推理行為,但它面臨著一些問題。例如,DeepSeek-R1-Zero 在可讀性方面表現不佳,存在語言混用的問題。
DeepSeek-R1
受到 DeepSeek-R1-Zero 令人鼓舞的結果的啟發,自然會提出兩個問題:
1)通過引入少量高質量數據作為冷啟動,是否可以進一步提升推理性能或加速收斂?
2)如何訓練一個用戶友好的模型,使其不僅能夠產生清晰連貫的推理鏈(CoT),還具備強大的通用能力?
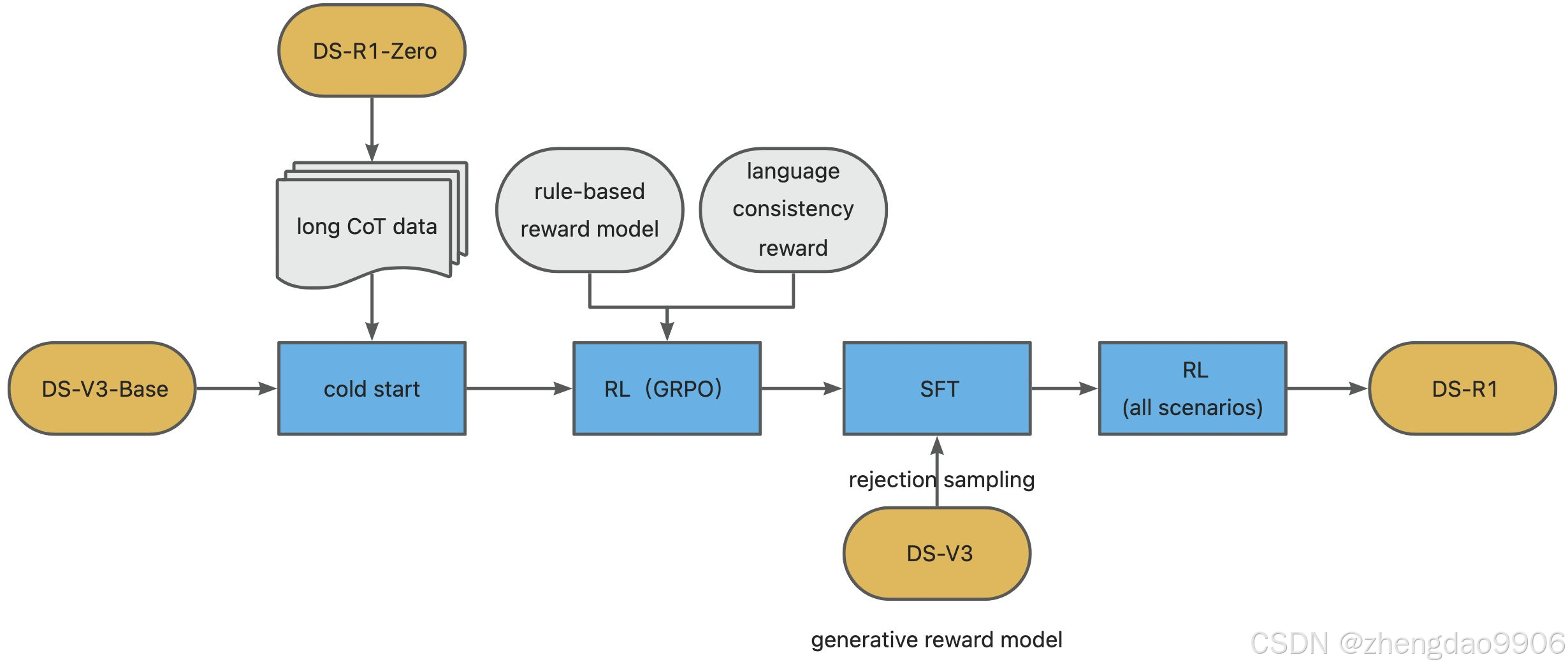
為了解決這些問題,我們重新設計了 DeepSeek-R1 的訓練流程。該流程包括以下四個階段:
● 冷啟動:增加上千條CoT數據,引入人類先驗知識,在DeepSeek-V3的基礎上進行迭代優化,增加整體模型的可讀性。在DeepSeek-V3-Base的基礎上,讓模型具備更好的可讀性、回答模版以及潛力。
● 面向推理的強化學習,引入語言一致性獎勵:計算方法是 CoT 中目標語言單詞的比例。訓練到在歸因任務上收斂。該步驟類似DeepSeek-R1-Zero,但是額外增加了語言一致性獎勵函數。
● 拒絕采樣與監督微調:對于每個提示,采樣多個回答,并僅保留正確的回答,提高數據質量。將標準答案和模型輸出一起輸入給DeepSeek-V3,令其判斷是否采樣該樣本。總共收集了大約 600k 條與推理相關的訓練樣本。
● 面向所有場景的強化學習:旨在提升模型的有用性(泛化性)和無害性,同時優化其推理能力。具體來說,使用組合的獎勵信號和多樣化的提示分布來訓練模型。
知識蒸餾
為了使更高效的小模型具備像 DeepSeek-R1 這樣的推理能力,我們直接使用 DeepSeek-R1 生成的 800k 樣本對開源模型(如 Qwen 和 Llama)進行微調,詳細過程如上節所述。我們的研究結果表明,這種簡單的蒸餾方法顯著提升了小型模型的推理能力。
我們使用的基底模型包括 Qwen2.5-Math-1.5B、Qwen2.5-Math-7B、Qwen2.5-14B、Qwen2.5-32B、Llama-3.1-8B 和 Llama-3.3-70B-Instruct。我們選擇 Llama-3.3 是因為其推理能力略優于 Llama-3.1。
需要注意的是:對于蒸餾模型,我們僅應用了 SFT,并沒有 RL 階段,盡管加入 RL 可能會顯著提升模型性能。我們的主要目標是展示蒸餾技術的有效性,將 RL 階段的探索留給更廣泛的學術界。
結合后文的實驗結果,知識蒸餾主要有兩個結論:
● 將更強大的模型的能力蒸餾到小型模型中可以取得出色的結果,而小型模型僅依靠本文提到的大規模 RL 訓練需要巨大的計算資源,且可能無法達到蒸餾的效果。
● 雖然蒸餾策略既經濟又有效,但要突破智能的邊界,可能仍然需要更強大的基礎模型和更大規模的強化學習。
參考資料:
● Github:https://github.com/deepseek-ai/DeepSeek-R1
● CSDN:https://blog.csdn.net/qq_38961840/article/details/145384852
● 論文:
http://arxiv.org/abs/2401.02954
http://arxiv.org/abs/2501.12948
)


Gorm的數據庫操作)





跨平臺應用程序項目實戰教程 6 — 彈出框)





通用數據集-剪刀石頭布手勢檢測數據集】)



