一、產生的原因
使用緩存,在進行寫操作的時候就會出現不一致的問題。
一致性分為三類:強一致性,弱一致性,最終一致性
二、方案
2.1 延時雙刪
在更新數據庫的操作前后分別進行一次刪除緩存的操作,并在更新數據庫之后線程休眠一段時間。
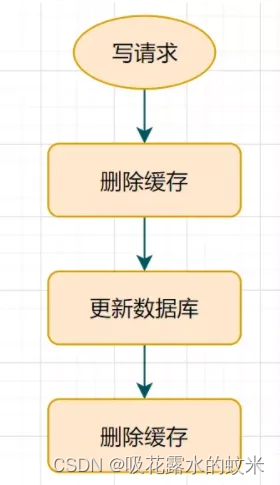
- 先刪除緩存
- 再更新數據庫
- 休眠一會(比如1秒),再次刪除緩存。
這個休眠一會,一般多久呢?都是1秒?
休眠時間 = 讀業務邏輯數據的耗時 + 幾百毫秒。為了確保讀請求結束,寫請求可以刪除讀請求可能帶來的緩存臟數據。
該方法優缺點思考:
這種方案還算可以,只有休眠那一會(比如就那1秒),可能有臟數據,一般業務也會接受的。但是如果第二次刪除緩存失敗呢?
緩存和數據庫的數據還是可能不一致,對吧?
給Key設置一個自然的expire過期時間,讓它自動過期怎樣?
那業務要接受過期時間內,數據的不一致咯?還是有其他更佳方案呢?
2.2 刪除緩存重試機制
當第二次刪除緩存失敗怎么辦?那就再刪一次唄,還不行就再刪一次!

- 寫請求更新數據庫
- 緩存因為某些原因,刪除失敗
- 把刪除失敗的key放到消息隊列
- 消費消息隊列的消息,獲取要刪除的key
- 重試刪除緩存操作
2.3 讀取biglog異步刪除緩存
刪除緩存重試機制雖然能夠解決一致性的問題,但是對代碼的侵入性較大,可以進行如下優化:通過數據庫的binlog來異步淘汰key。
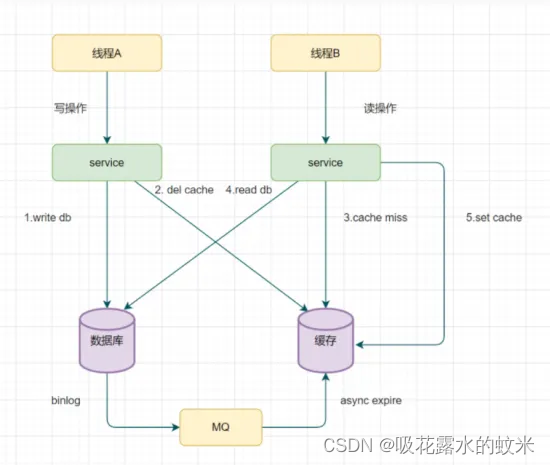
以mysql為例,
可以使用阿里的canal將binlog日志采集發送到MQ隊列里面
然后通過ACK機制確認處理這條更新消息,刪除緩存,保證數據緩存一致性
三、可能出現的疑問
3.1 為什么先操作數據庫,再操作緩存?
假設先操作緩存再操作數據庫,可能會出現如下情況:
線程A先刪除緩存,在A更新數據庫的操作結束前,線程B去讀數據,發現緩存沒數據了,那么B就會去數據庫中查詢,結果讀到的就是臟數據并存在緩存中,然后A更新完數據庫,導致數據庫和緩存中的值不一致。
如果先操作數據庫再操作緩存,能保證一致性。


)

















