源代碼在這里RITnet-Github
????????這個模型比較小眾,我們實驗室使用了官方提供的模型進行瞳孔中心位置提取,以實現視線追蹤,效果很好
一、數據集準備
????????RITnet也是那一屆openEDS數據集挑戰賽的冠軍模型,openEDS數據集可以從Kaggle上下載,一共9G,大家不用去找openEDS論文里提供的數據集下載地址,那個需要Facebook賬戶去進行申請,很麻煩
????????從Kaggle上下載下來的數據集長這樣:
????????只需要openEDS,它包括了以下內容:
????????可以看到有很多文件夾,但代碼中只用到了train、test文件夾中的文件,所以其它的先不用管
看看瞳孔圖像的樣子:
展示了上述內容后,相信大家對數據集這塊有足夠的了解了!最重要的一點:只需要把Semantic_Segmentation_Dataset拷貝進代碼項目中(不拷貝也行,重定義一下路徑就好了),文件擺放格式什么的都不用改,妥妥的保姆級
二、環境配置
????????我所用的 IDE 是 Pycharm 。從 Github 上下載下來的項目文件中包含2個對項目所需環境的描述文件:requirements.txt、environment.yml,前者只是記錄了項目所用的包的名字,并沒有各個包的具體版本信息;后者是一種便捷的環境打包文件,記錄的就是原作者運行代碼時的全部環境,但我在淺淺嘗試之后就放棄了這種方法,因為我不會而且也用不好
????????所以我自己新創建了一個 conda 虛擬環境,對新手更友好,條理也非常清晰!
1.創建 python = 3.8 的 Anaconda 虛擬環境
????????沒有經驗的同學可以參考這篇帖子:從零開始創建conda環境及pycharm配置項目環境
????????打開 Anaconda Prompt,使用下面這條指令就能創建新的虛擬環境了
# Success 是自定義的環境名,python=3.8也是自定義的python版本
conda create -n Success python=3.8
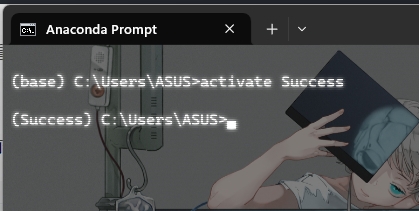
????????再使用下面這條指令看看環境有沒有創建好,出現下圖就是好消息
activate Success
這個環境的具體位置在你之前下載的 Anaconda 文件夾下,看看我的:
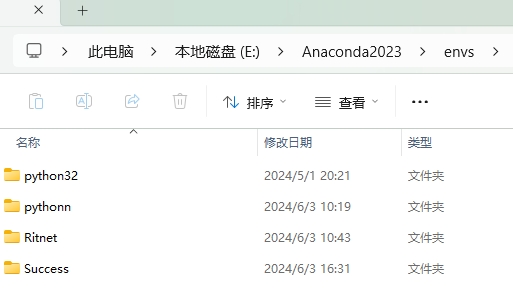
Anaconda2023 是我當時在安裝 Anaconda 時新建的文件夾名,而 envs 中就存放著我們建立過的所有虛擬環境啦
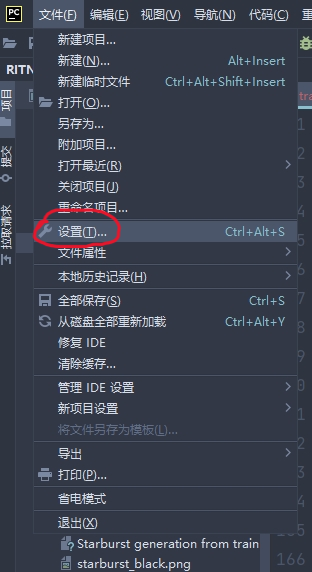
創建好之后,把這個環境配置進?Pycharm 里。步驟為:
左上角 -> 設置
項目:RITNet -> Python解釋器 -> 添加解釋器 -> 添加本地解釋器
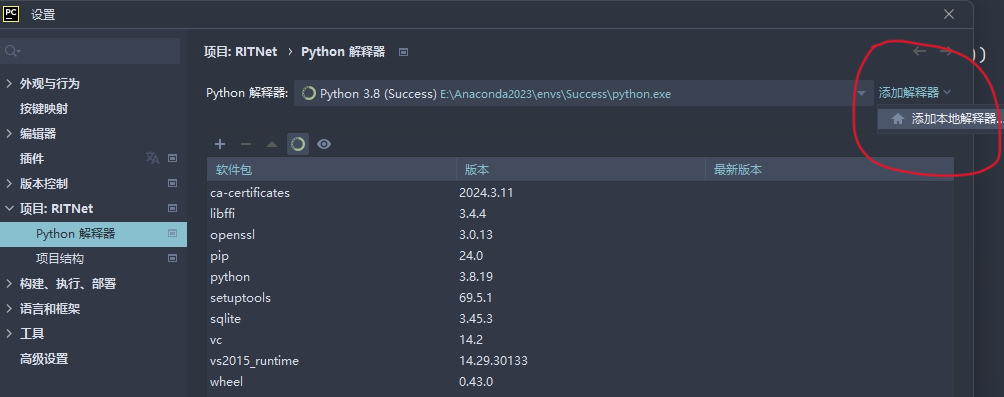
Virtualenv環境 -> 上面提到的 Anaconda 所處位置 -> envs -> 虛擬環境文件夾 -> python.exe(目標文件),選定 python.exe 點“確定”就好了
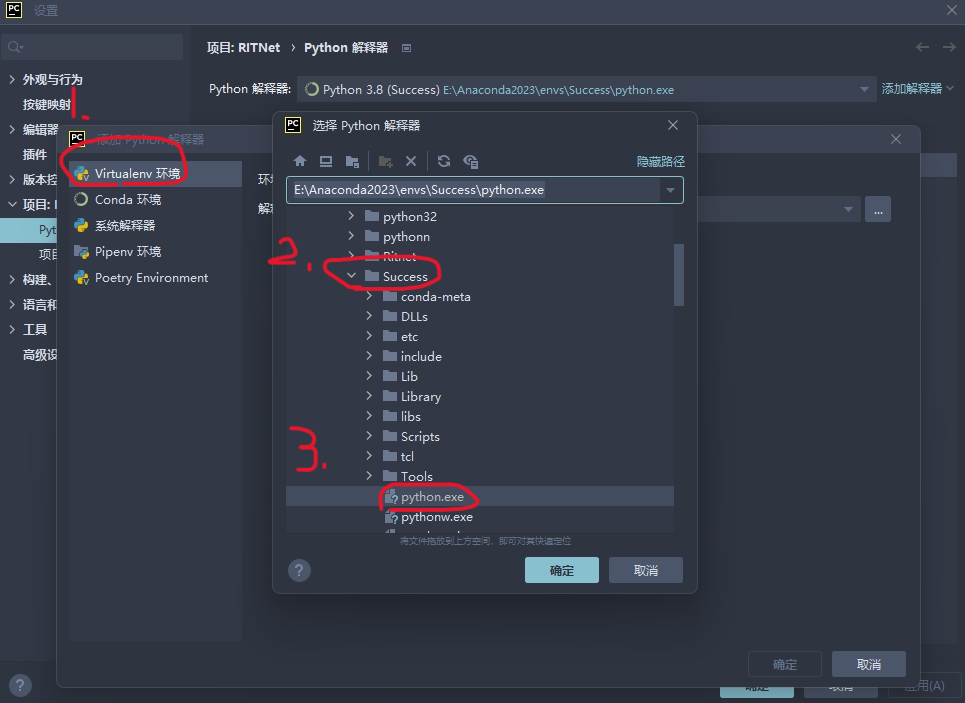
右下角變成這樣就大功告成了

2.在當前虛擬環境中安裝所需包
????????這塊是最復雜最關鍵的部分,所用篇幅較長
a.Pytorch-GPU 安裝
? ? ? ? 在 RITnet 項目中用到了 GPU 來加速模型訓練,需要安裝 GPU 版本的 Pytorch,這里有很多坑,但經過我長時間的摸索已經總結出一套必殺技:
????????大家應該經常在網上看到這2條指令 nvcc -V 、nvidia-smi 它們都是用來查看自己電腦上所安裝的CUDA版本的,區別在于 nvidia-smi?所查看是自己電腦本身的 CUDA 版本,而?nvcc -V 指令只有你的電腦上有 Pytorch 時才能運行成功(不論GPU版本還是CPU版本),這2條語句的差別很大,而我們只需使用?nvidia-smi 來查看自己電腦的 CUDA 信息即可,如:
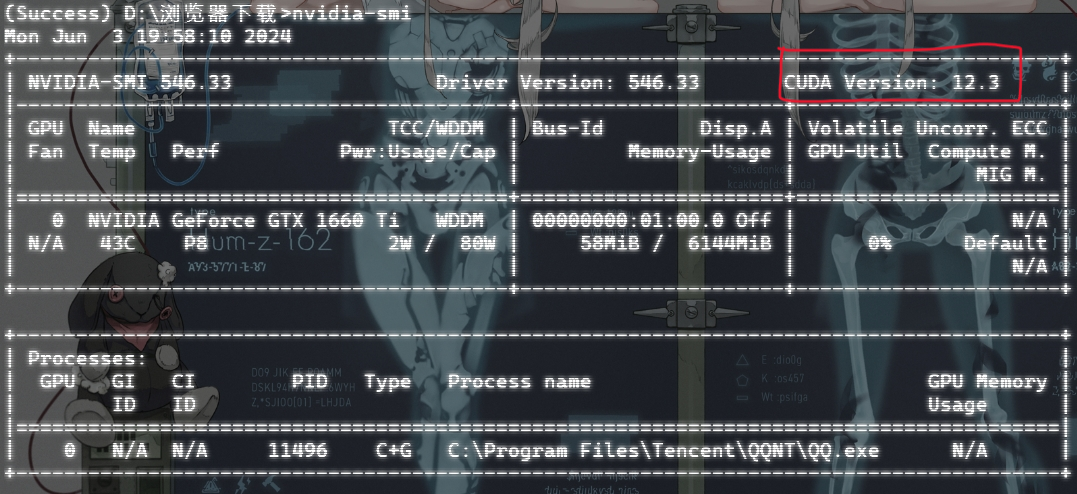
????????我電腦的 CUDA 版本是 12.3,我們需要根據它來安裝 CUDA ,進而安裝對應版本的 Pytorch-GPU.
????????CUDA 安裝總體可以參考這篇帖子:全網最詳細的安裝pytorch GPU方法全網最詳細之如何安裝gpu版的pytorch,但別完全參考,有小坑!
?????而在安裝 CUDA 時我遇到了 “NVIDIA 安裝程序失敗的問題”,很棘手,但解決了,解決方式如下:
????????在選擇組件(自定義安裝)的時候,將 CUDA 中的 Nsight VSE 和 Visual Studio Integration 取消勾選,后選擇下一步,即可安裝成功。此招式來自NVIDIA安裝CUDA在安裝階段提示NVIDIA安裝程序失敗超級有用(給磕了)
????????安裝好 CUDA 后,不要使用 pip install 指令直接從 Pytorch 官網下載 GPU 版本的 Pytorch,我下了超多次,結果下下來的都是 CPU 版本的,參考這個全網最詳細之如何安裝gpu版的pytorch
????????我將安裝的 CUDA 和 torch 等包的對應關系放進下方的表格里,完全按照這個來就行
| CUDA | 12.0.0 |
| torch | 2.0.0 |
| torchvision | 0.15.1 |
| torchaudio | 2.0.1 |
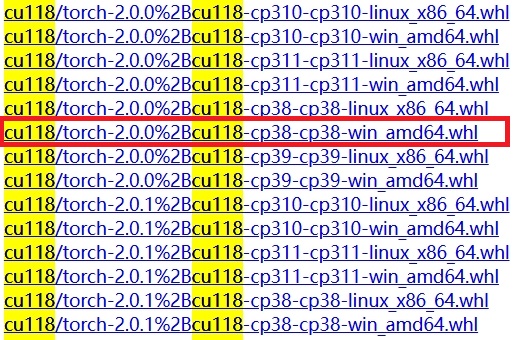
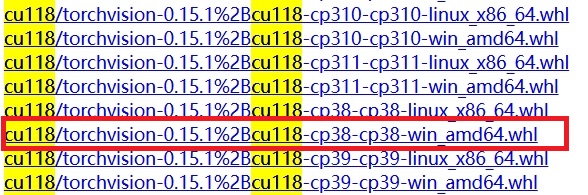
? ? ? ?點擊進入下載地址,我們需要根據上述表格下載以下3個文件(需要VPN,不然超慢)
torch 下載
torchvision 下載
torchaudio 下載
????????將上述3個文件都下載好后,進入文件所在目錄(切記),在上面的搜索欄里輸入 cmd,然后回車即可進入 dos。
????????在 dos 里激活剛剛創建好的虛擬環境后,使用下面這3行指令將上述3個文件都安裝進我們的虛擬環境
pip install "torch-2.0.0+cu118-cp38-cp38-win_amd64.whl"pip install "torchvision-0.15.1+cu118-cp38-cp38-win_amd64.whl"pip install "torchaudio-2.0.1+cu118-cp38-cp38-win_amd64.whl"????????結束了,一切都結束了!最終用下面這段測試代碼美美驗證一下 Pytorch-GPU 到底裝好沒有!
import torch # 測試是否安裝完成torch模塊
import torchvision # 測試是否安裝完成torchvision模塊
import osif __name__ == '__main__':print("安裝torch版本為: ", torch.__version__)print("是否安裝完成Pytorch-GPU : ", torch.cuda.is_available())arr = torch.zeros(5, 5)print("生成全零矩陣:\n", arr)
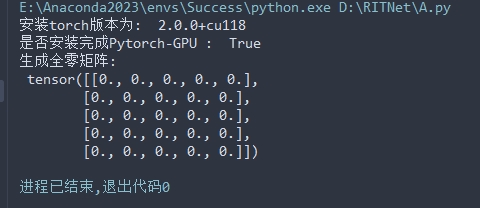
????????可喜可賀,實在是可喜可賀!
b.其它包的安裝
????????全部使用 pip 進行安裝(一定要關掉 VPN)
pip install scikit-learn
pip install numpy
pip install opencv-python # 即cv2
pip install pillow
pip install matplotlib
pip install tqdm
pip install torchsummary
pip install argparse三、代碼調整
????????想要運行 train.py,我們還需對其它 .py 文件進行調整.由于給原始瞳孔圖像添加星爆圖像這部分一直報錯(維度問題),嘗試解決了很多次,但都沒能成功解決,于是把這部分圖像預處理代碼注釋掉了,如果后續有哪位朋友解決了這個問題,還請和大家分享分享!
????????1.將 dataset.py 中的 Starburst_augment 類全部注釋,同時在?IrisDataset 類中的 __getitem__ 函數中注釋掉調用 Starburst_augment 類的代碼
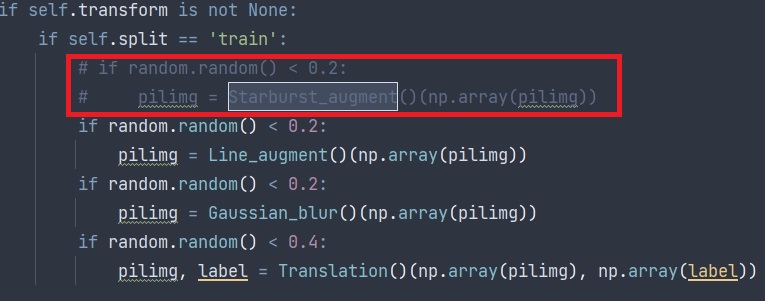
????????2.將 __init__中的一行代碼轉移到__getitem__?中去.具體操作見下方:
class IrisDataset(Dataset):def __init__(self, filepath, split='train', transform=None, **args):self.transform = transformself.filepath = osp.join(filepath, split)self.split = splitlistall = []for file in os.listdir(osp.join(self.filepath, 'images')):if file.endswith(".png"):listall.append(file.strip(".png"))self.list_files = listallself.testrun = args.get('testrun')# 將下面這行代碼換個位置,換到下方的__getitem__函數中去self.clahe = cv2.createCLAHE(clipLimit=1.5, tileGridSize=(8, 8))def __len__(self):if self.testrun:return 10return len(self.list_files)def __getitem__(self, idx):# 從init移過來的self.clahe = cv2.createCLAHE(clipLimit=1.5, tileGridSize=(8, 8))imagepath = osp.join(self.filepath, 'images', self.list_files[idx] + '.png')pilimg = Image.open(imagepath).convert("L")H, W = pilimg.width, pilimg.height????????整體復現流程就是這樣,如果大家自己在復現過程中遇到解決不了的問題可以來私信我(復現論文真的好麻煩好累但別無它選)

ICMPv4協議)
、歡樂的周末))



)


)
【ExtensionAbility組件】)








