目錄
深度學習簡介
傳統機器學習
深度學習發展
感知機
前饋神經網絡
前饋神經網絡(BP網絡)
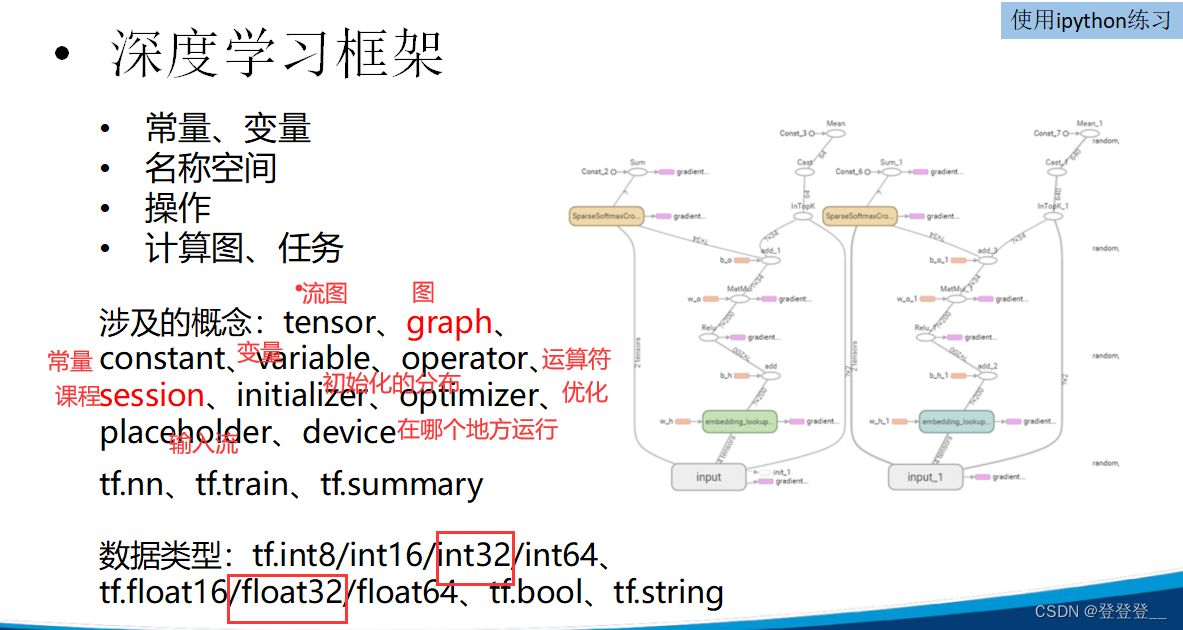
深度學習框架講解
深度學習框架
TensorFlow
一個簡單的線性函數擬合過程
卷積神經網絡CNN(計算機視覺)
自然語言處理NLP
Word Embedding
詞向量
詞向量學習方法:LSA、PLSA
詞向量訓練
詞向量應用
循環神經網絡RNN(語義理解)
基本原理
基本應用
RNN的缺陷
LSTM (特殊的RNN)
練習_聊天機器人實戰
深度學習(Deep Learning,簡稱DL)是機器學習(Machine Learning,簡稱ML)領域中的一個重要研究方向。它被引入機器學習領域,目的是使機器能夠更接近于實現人工智能(Artificial Intelligence,簡稱AI)的原始目標。深度學習通過學習樣本數據的內在規律和表示層次,實現對諸如文字、圖像和聲音等數據的解釋,并提升機器的分析學習能力。
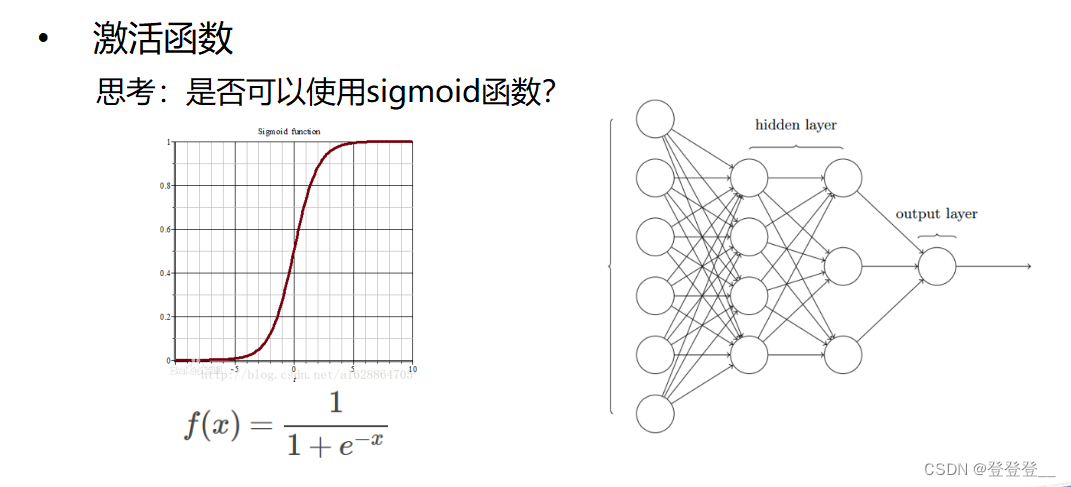
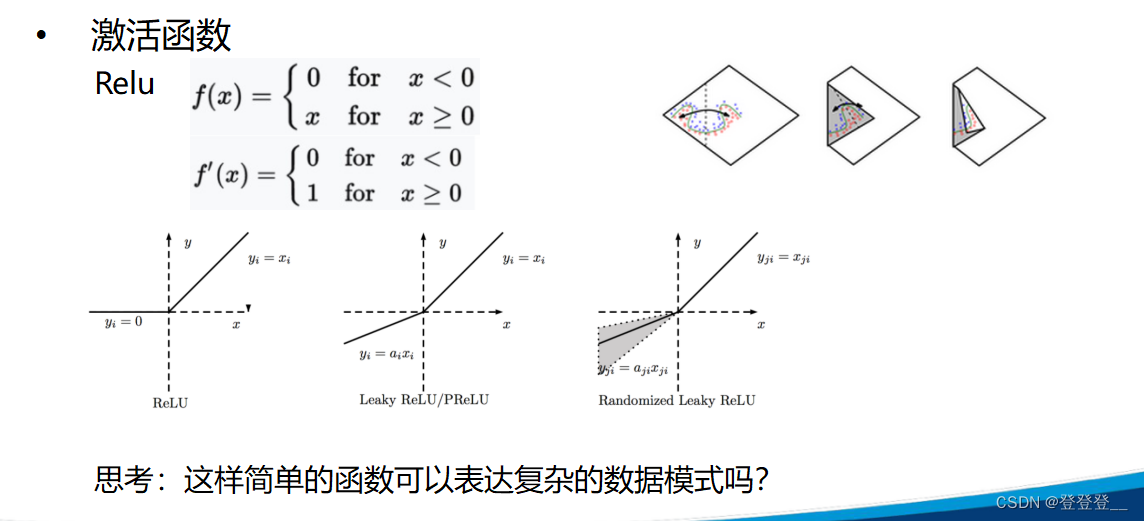
深度學習的核心原理主要包括神經網絡、反向傳播算法、激活函數、損失函數和優化算法等。神經網絡是深度學習的基本結構,它由輸入層、隱藏層和輸出層組成,通過權重和偏置連接各層,逐層傳遞信息并進行處理。反向傳播算法則用于在訓練過程中更新網絡參數,優化網絡性能。激活函數和損失函數則分別用于增加網絡的非線性能力和衡量網絡輸出與真實標簽之間的差異。優化算法則用于在訓練過程中最小化損失函數,更新網絡參數。
深度學習在眾多領域都有廣泛的應用,如計算機視覺及圖像識別、自然語言處理、語音識別及生成、推薦系統、游戲開發、醫學影像識別、金融風控、智能制造、購物領域以及基因組學等。這些應用不僅展示了深度學習的強大能力,也推動了相關領域的進步和發展。
在未來,深度學習將繼續朝著跨學科融合、多模態融合、自動化模型設計、持續優化算法、邊緣計算的應用以及可解釋性和可靠性等方向發展。這些發展將進一步推動深度學習技術的進步,拓寬其應用領域,并提升其在各種復雜任務中的性能。
需要注意的是,深度學習雖然取得了顯著的成果,但仍然存在一些挑戰和限制,如數據需求量大、模型復雜度高、計算資源消耗大等問題。因此,在實際應用中,需要根據具體任務和場景來選擇合適的深度學習方法和模型,并進行合理的優化和調整。

深度學習簡介
傳統機器學習
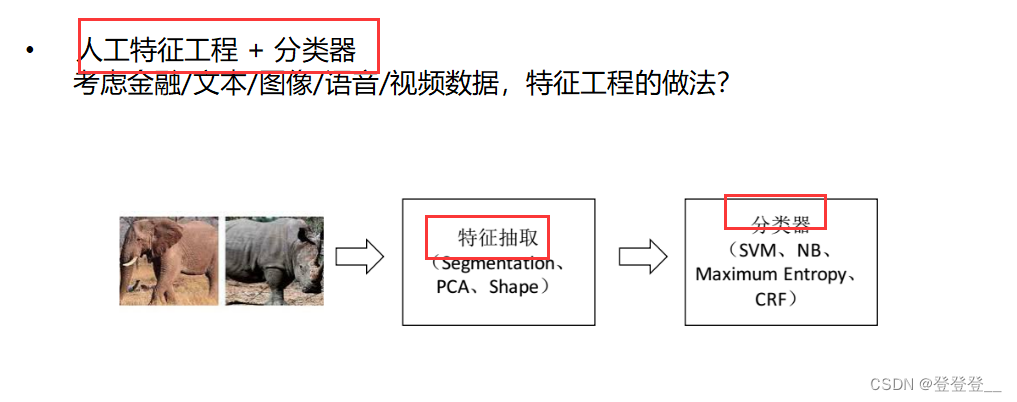

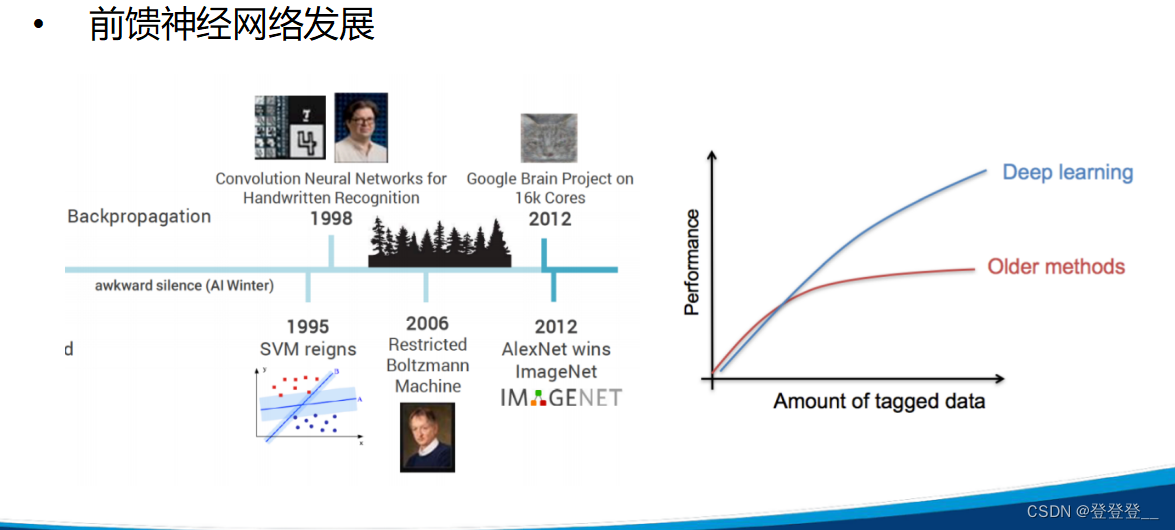
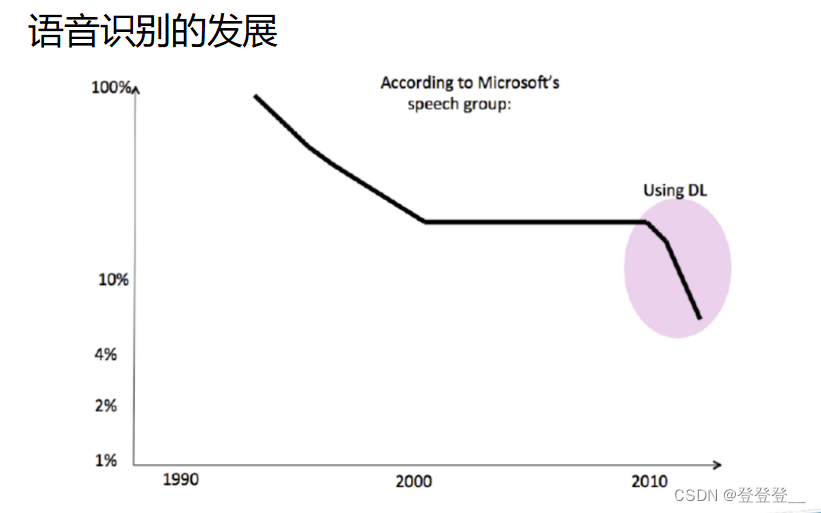
深度學習發展
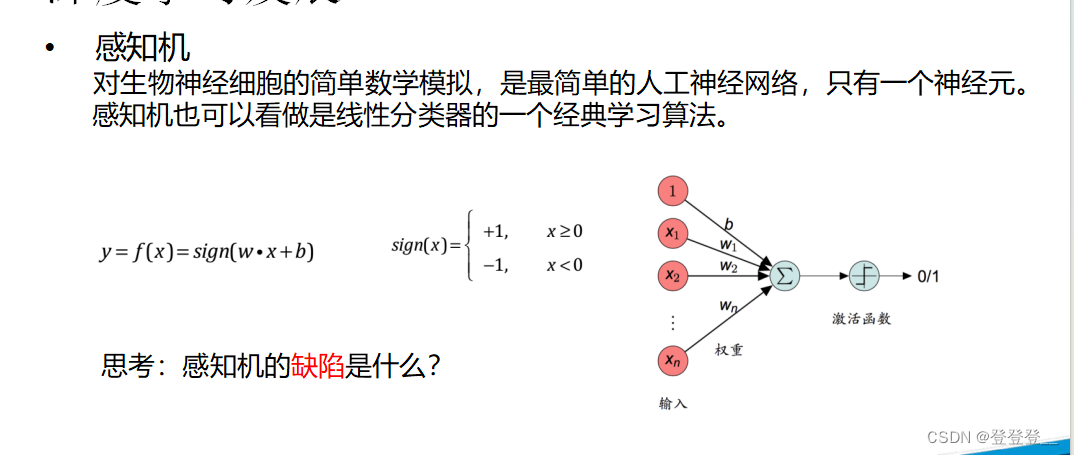
感知機
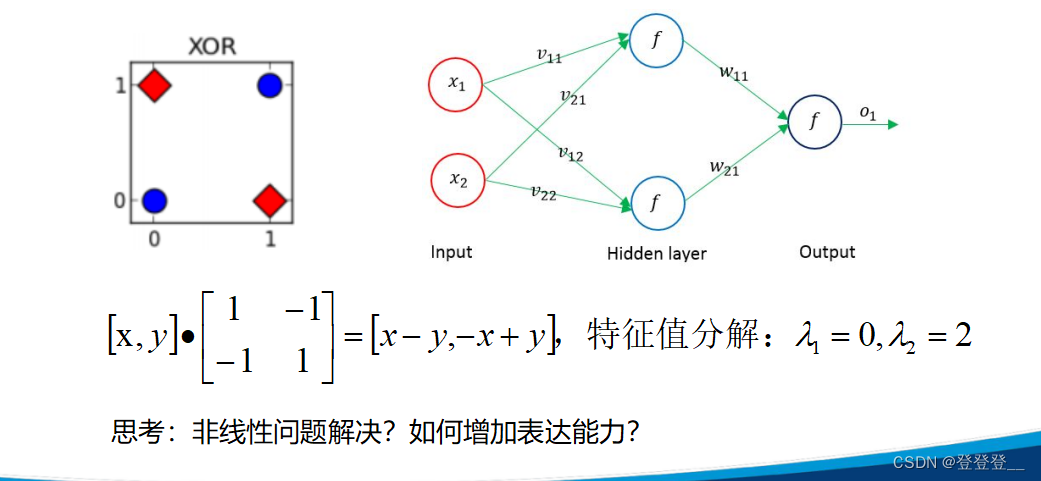
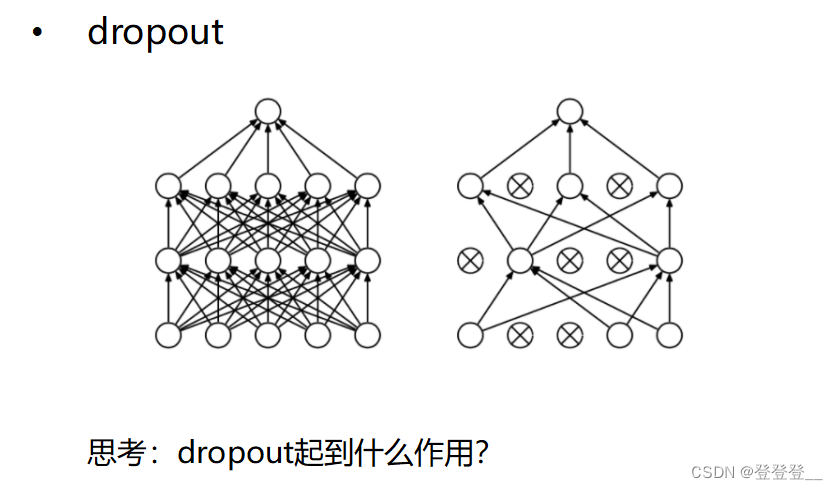
非線性問題解決不能用線性變換
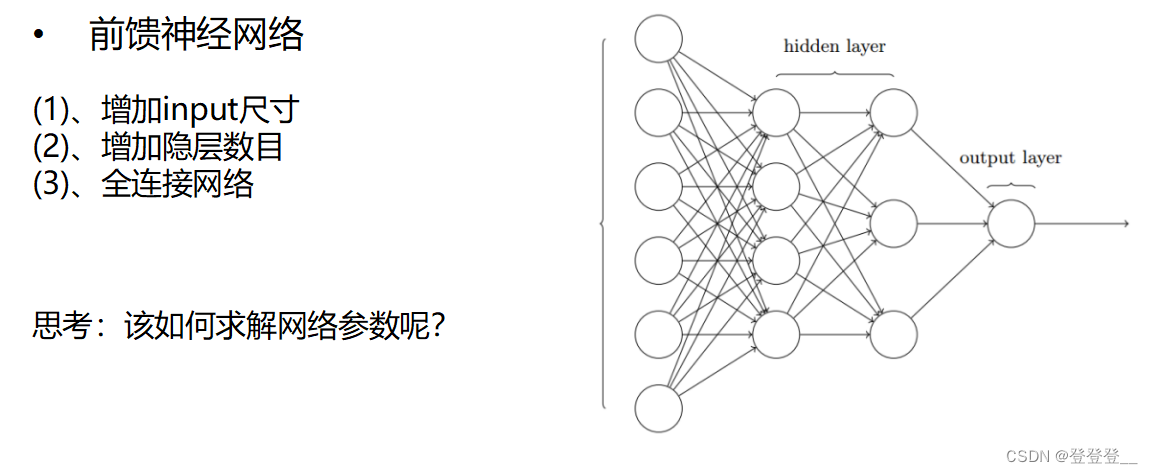
前饋神經網絡
前饋神經網絡(BP網絡)
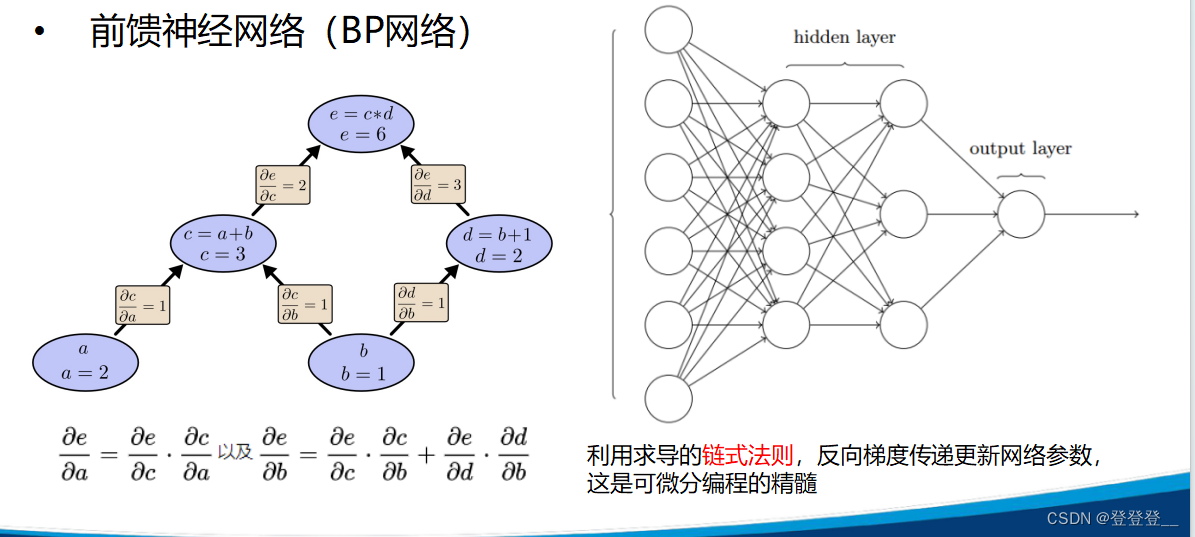

可以通過多調幾次參數和多跑幾次模型


NLP是自然語言處理(Natural Language Processing)的縮寫,是人工智能和語言學領域的交叉學科。它研究能實現人與計算機之間用自然語言進行有效通信的各種理論和方法。自然語言處理是一門融語言學、計算機科學、數學于一體的科學。因此,這一領域的研究將涉及自然語言,即人們日常使用的語言,所以它與語言學的研究有著密切的聯系,但又有重要的區別。自然語言處理并不是一般地研究自然語言,而在于研制能有效地實現自然語言通信的計算機系統,特別是其中的軟件系統。因而它是計算機科學的一部分


深度學習框架講解
深度學習框架
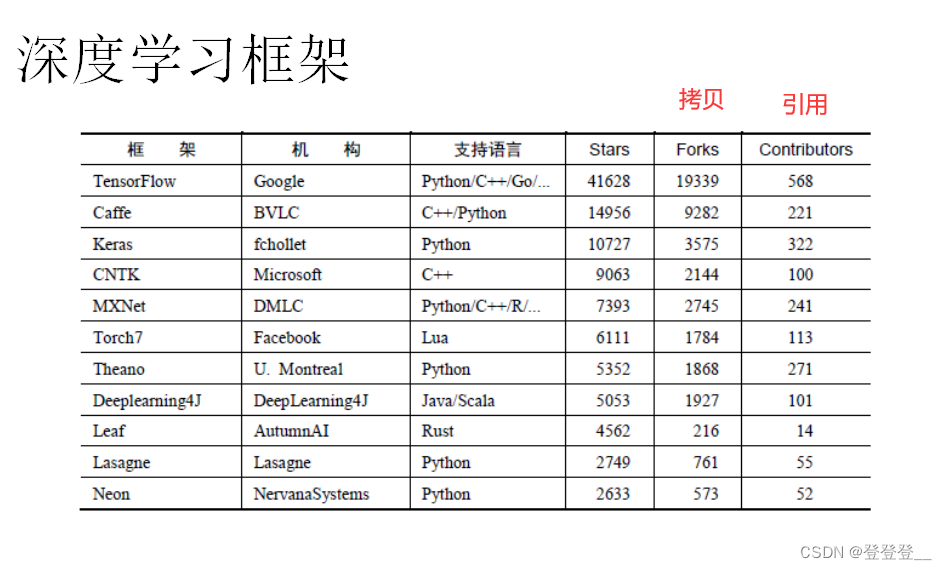
TensorFlow

一個簡單的線性函數擬合過程

下面是代碼的解釋:
- 導入TensorFlow庫。
import tensorflow as tf
- 創建兩個
tf.Variable對象x和y,并分別初始化為[1, 2, 3]和[4, 5, 6]。x = tf.Variable([1, 2, 3], dtype=tf.float32) y = tf.Variable([4, 5, 6], dtype=tf.float32)
- 計算
x和y的逐元素乘積,并求和得到z。z = tf.reduce_sum(x * y)
- 使用
tf.Session來初始化變量并計算z的值。with tf.Session() as sess: sess.run(tf.global_variables_initializer()) # 初始化所有全局變量 z_value = sess.run(z) # 執行計算圖,得到z的值 print(z_value) # 打印結果在
with tf.Session() as sess:的上下文中,首先使用sess.run(tf.global_variables_initializer())來初始化所有全局變量(即x和y)。然后,使用sess.run(z)來執行計算圖并獲取z的值。最后,將z的值打印出來。運行這段代碼將輸出:
32這是因為
(1*4) + (2*5) + (3*6) = 4 + 10 + 18 = 32。


卷積神經網絡CNN(計算機視覺)
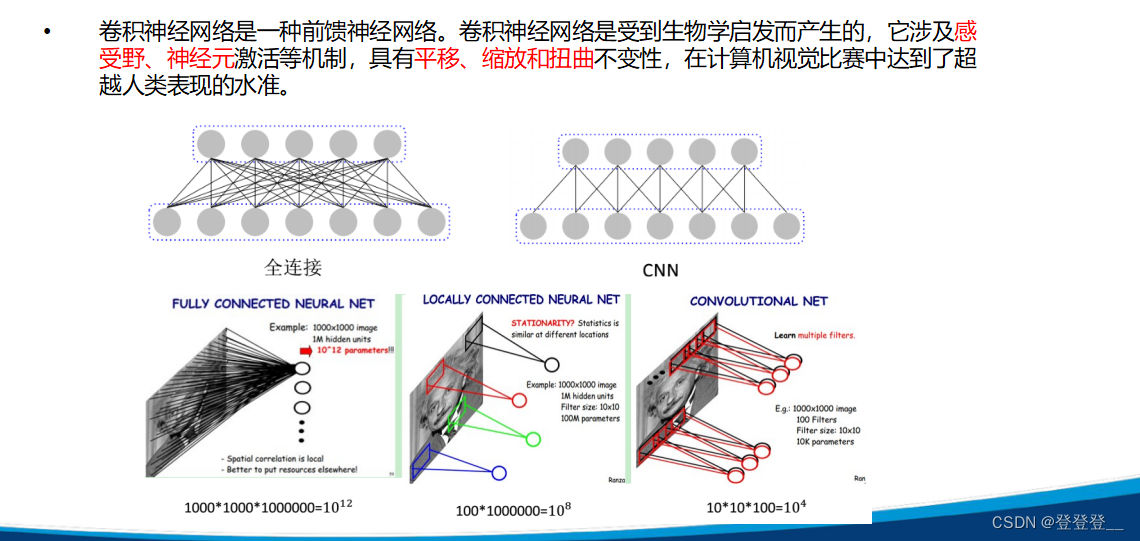
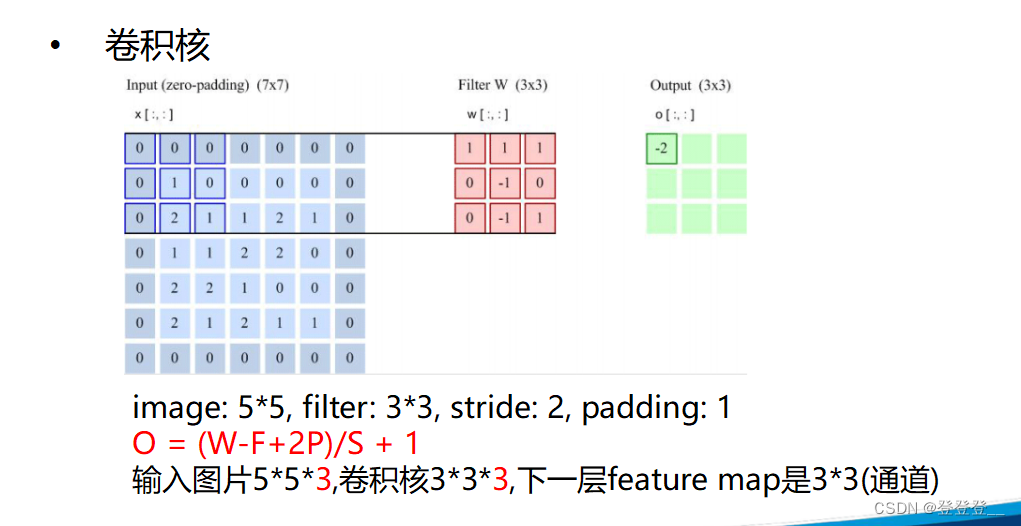
卷積神經網絡(Convolutional Neural Networks,簡稱CNN)是一類包含卷積計算且具有深度結構的前饋神經網絡,是深度學習領域的代表算法之一。卷積神經網絡具有表征學習的能力,能夠按其階層結構對輸入信息進行平移不變分類,因此也被稱為“平移不變人工神經網絡”。
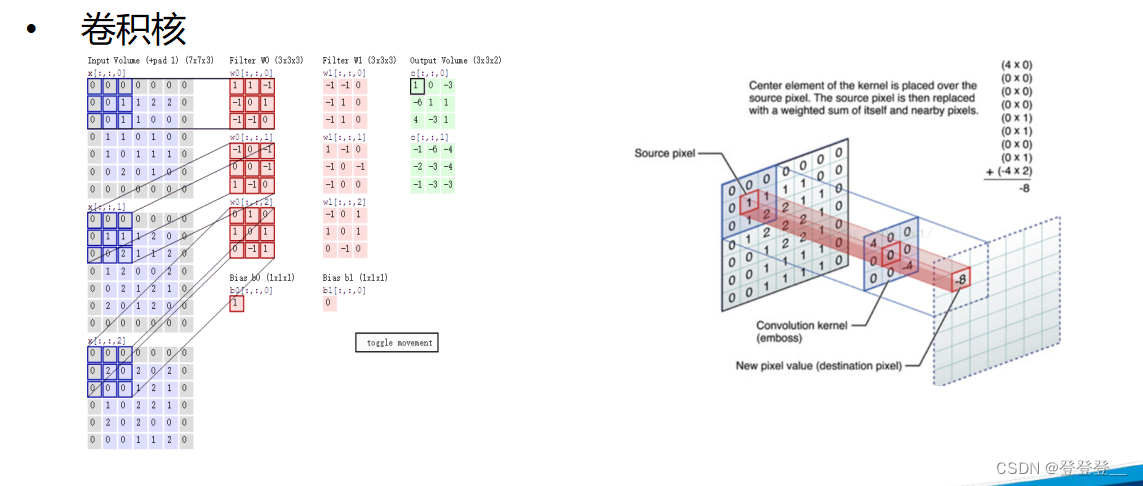
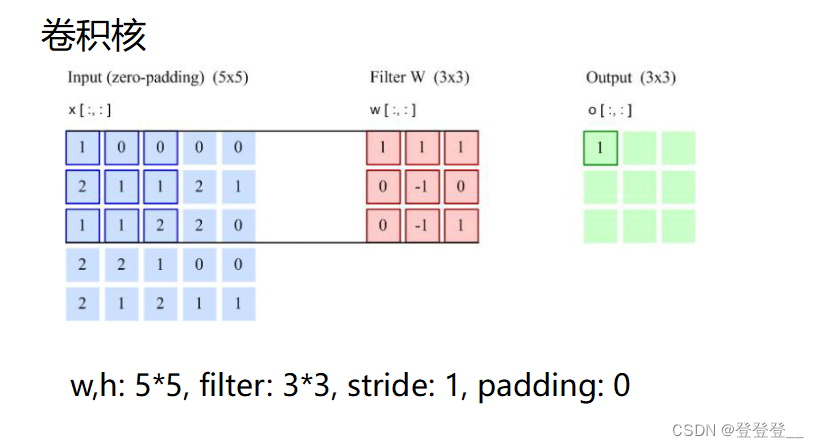
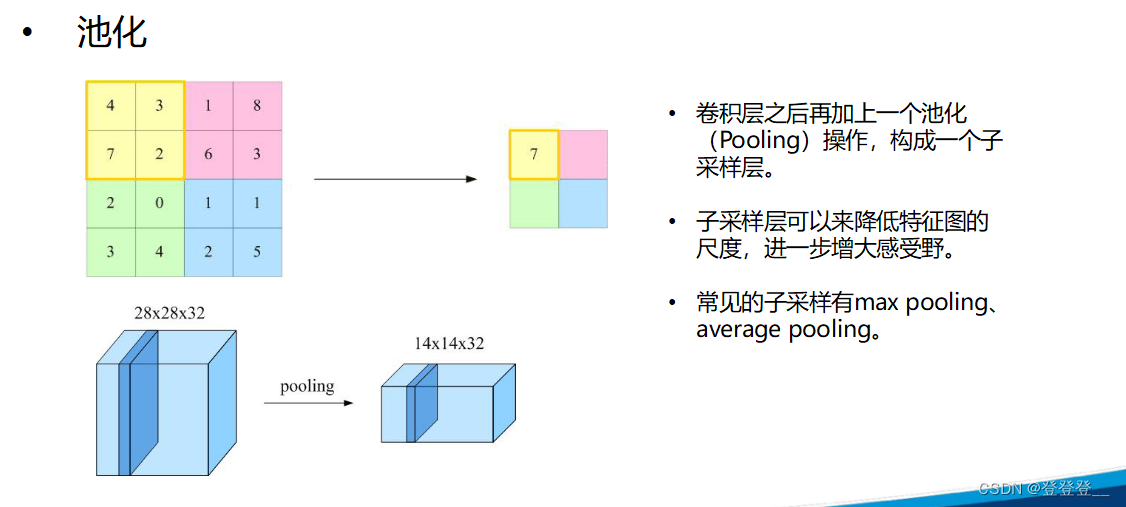
卷積神經網絡的基本結構包括輸入層、卷積層、池化層、全連接層和輸出層。其中,卷積層通過卷積操作提取特征,每個卷積層通常包含多個卷積核,每個卷積核對輸入數據進行卷積運算,得到一個特征圖。池化層則通過降采樣來減少特征圖的尺寸,增強模型的魯棒性和特征提取能力。全連接層將特征映射到一個高維特征空間中,再通過softmax函數進行分類或回歸。
卷積神經網絡的核心特點是權值共享和局部連接。權值共享是指在卷積層中,同一個卷積核在不同位置上的權值是相同的,這可以大大減少模型參數,提高模型泛化能力。局部連接是指在卷積層中,每個卷積核只與輸入數據的一部分進行卷積運算,而不是與整個輸入數據進行卷積運算,這樣可以提取出局部特征,增強模型的特征提取能力。
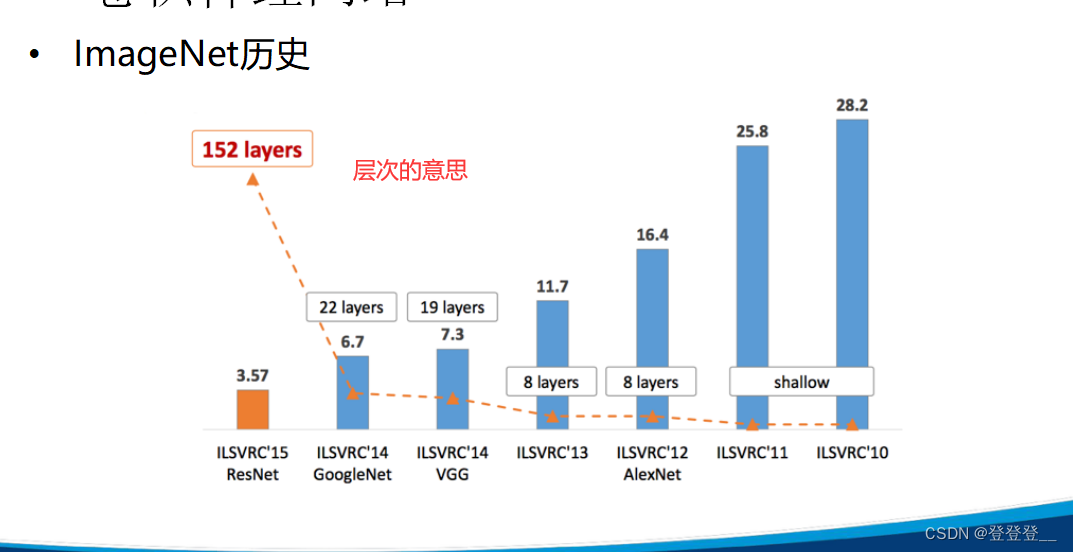
卷積神經網絡在圖像、視頻、語音等信號數據的分類和識別任務中如表現出色,圖像識別、分類、人臉識別、物體識別、交通標志識別等領域。近年來,卷積神經網絡也在自然語言處理任務中展現出有效性。





from PIL import Image
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_datamnist = input_data.read_data_sets('./MNIST_data', one_hot=True)# 定義圖
x = tf.placeholder(tf.float32, shape=[None, 784])
y_ = tf.placeholder(tf.float32, shape=[None, 10])x_image = tf.reshape(x, [-1, 28, 28, 1])W_conv1 = tf.Variable(tf.truncated_normal([5, 5, 1, 32], stddev=0.1))
b_conv1 = tf.constant(0.1, shape=[32])h_conv1 = tf.nn.relu(tf.nn.conv2d(x_image, W_conv1, strides=[1, 1, 1, 1], padding='SAME') + b_conv1)
h_pool1 = tf.nn.max_pool(h_conv1, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')W_conv2 = tf.Variable(tf.truncated_normal([5, 5, 32, 64], stddev=0.1))
b_conv2 = tf.constant(0.1, shape=[64])h_conv2 = tf.nn.relu(tf.nn.conv2d(h_pool1, W_conv2, strides=[1, 1, 1, 1], padding='SAME') + b_conv2)
h_pool2 = tf.nn.max_pool(h_conv2, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')W_fc1 = tf.Variable(tf.truncated_normal([7 * 7 * 64, 1024], stddev=0.1))
b_fc1 = tf.constant(0.1, shape=[1024])h_pool2 = tf.reshape(h_pool2, [-1, 7 * 7 * 64])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2, W_fc1) + b_fc1)keep_prob = tf.placeholder(tf.float32)
h_fc1 = tf.nn.dropout(h_fc1, keep_prob)W_fc2 = tf.Variable(tf.truncated_normal([1024, 10], stddev=0.1))
b_fc2 = tf.constant(0.1, shape=[10])y_conv = tf.matmul(h_fc1, W_fc2) + b_fc2
cross_entropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y_, logits=y_conv))
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
correct_prediction = tf.equal(tf.argmax(y_conv, 1), tf.argmax(y_, 1))
prediction = tf.argmax(y_conv, 1)
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))saver = tf.train.Saver() # defaults to saving all variables
process_train = Falsewith tf.Session() as sess:if process_train:sess.run(tf.global_variables_initializer())for i in range(20000):batch = mnist.train.next_batch(100)_, train_accuracy = sess.run([train_step, accuracy],feed_dict={x: batch[0], y_: batch[1], keep_prob: 0.5})if i % 100 == 0:print("step %d, training accuracy %g" % (i, train_accuracy))# 保存模型參數,注意把這里改為自己的路徑saver.save(sess, './mnist_model/model.ckpt')print("test accuracy %g" % accuracy.eval(feed_dict={x: mnist.test.images,y_: mnist.test.labels, keep_prob: 1.0}))else:saver.restore(sess, "./mnist_model/model.ckpt")pred_file = "./3.png"img_content = Image.open(pred_file)img_content = img_content.resize([28, 28])pred_content = img_content.convert("1")pred_pixel = list(pred_content.getdata()) # get pixel valuespred_pixel = [(255 - x) * 1.0 / 255.0 for x in pred_pixel]pred_num = sess.run(prediction, feed_dict={x: [pred_pixel], keep_prob: 1.0})print('recognize result:')print(pred_num)
自然語言處理NLP
Word Embedding
Word Embedding,即“詞嵌入”或“單詞嵌入”,是自然語言處理(NLP)中的一組語言建模和特征學習技術的統稱,其中詞語或短語從詞匯表被映射為實數的向量。這些向量通常會捕獲詞語之間的某種語義或句法關系,從而實現對詞匯表中單詞的數值化表示。
Word Embedding的主要目標是找到一個低維空間,將每個詞從高維空間(詞匯表)映射到這個低維空間,并使得語義上相似的詞在這個低維空間中的距離較近。這樣的映射可以幫助機器學習模型更好地理解和處理文本數據。
Word Embedding的幾種常見方法包括:
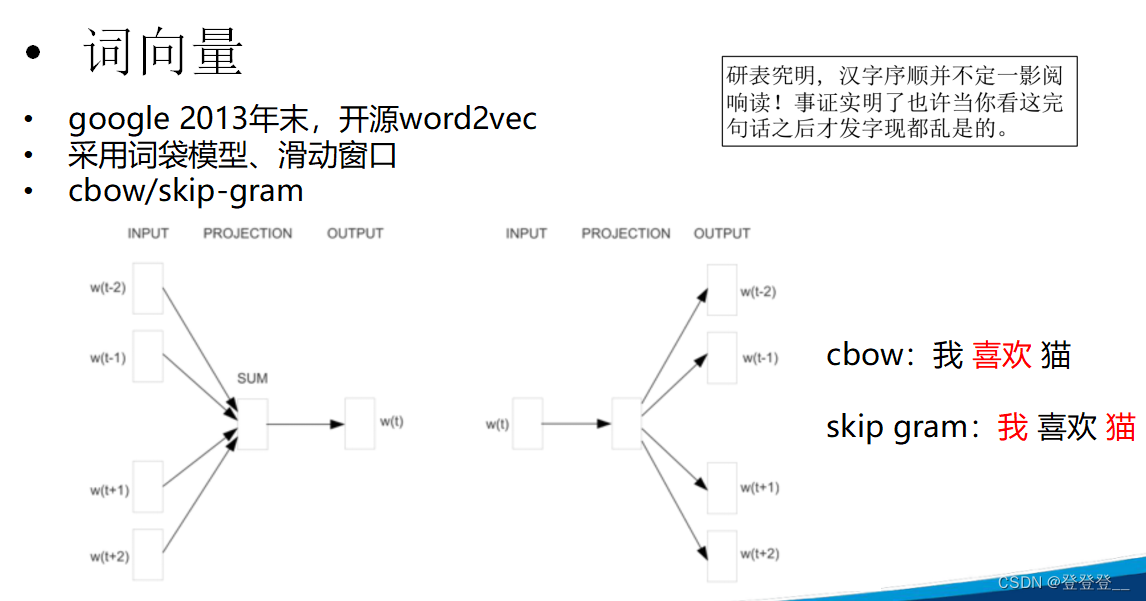
Word2Vec:由Google的研究人員開發,包括Skip-gram和CBOW兩種模型。Word2Vec通過訓練神經網絡來學習詞向量,使得具有相似上下文的詞具有相似的向量表示。
GloVe:全局向量表示法,基于詞語的共現統計信息來生成詞向量。它結合了局部上下文窗口方法和全局統計信息,以捕獲詞的語義關系。
FastText:擴展了Word2Vec,不僅考慮詞本身,還考慮詞的n-gram信息,以更好地處理未登錄詞和形態變化。
BERT(Bidirectional Encoder Representations from Transformers):基于Transformer的預訓練模型,通過大量的無監督文本數據訓練,可以生成上下文相關的詞嵌入。BERT的出現極大地推動了NLP領域的發展,尤其是在各種NLP任務中取得了顯著的性能提升。
Word Embedding在自然語言處理的許多任務中都發揮了重要作用,如文本分類、情感分析、命名實體識別、問答系統等。通過使用這些預訓練的詞嵌入,模型可以更好地捕獲文本的語義信息,從而提高性能。
詞向量





詞向量學習方法:LSA、PLSA
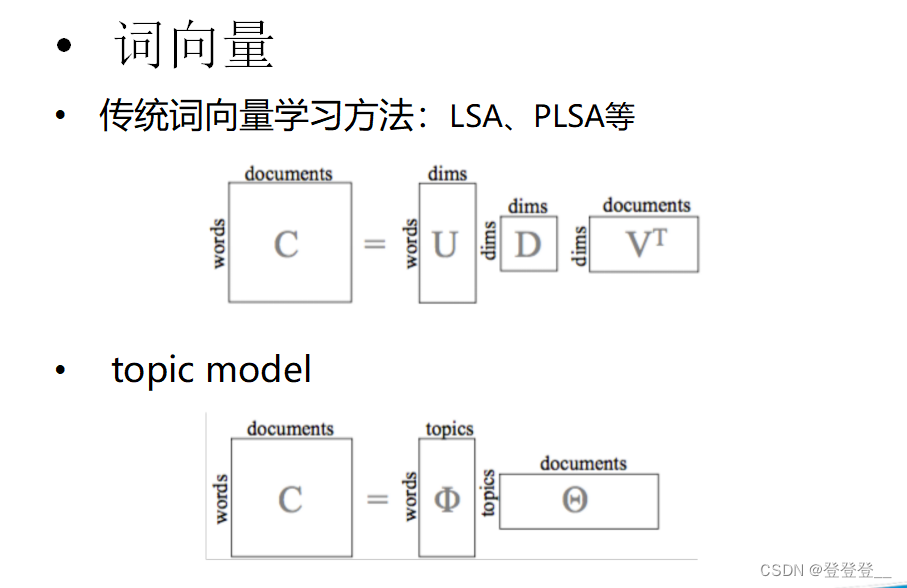
LSA,全稱Latent Semantic Analysis,中文譯為潛在語義分析,是一種基于向量空間模型的文本表示方法。它通過分析文本集合中詞語的共現關系,挖掘出詞語之間的潛在語義結構,并將文本表示為低維的向量空間中的點,從而實現對文本的高效表示和相似度計算。
LSA的核心思想是將文本中的詞語映射到一個低維的潛在語義空間,使得在這個空間中,語義上相似的詞語具有相近的表示。這樣,即使文本中的詞語不完全相同,只要它們具有相似的語義,它們在潛在語義空間中的表示就會很接近。
LSA在文本挖掘、信息檢索、自然語言處理等領域有著廣泛的應用。它可以幫助我們更好地理解文本的語義內容,提高文本分類、聚類、相似度計算等任務的性能。同時,LSA也可以用于構建語義相關的詞典或主題模型,為文本分析和挖掘提供有力的工具。
需要注意的是,雖然LSA在文本表示和語義挖掘方面具有一定的優勢,但它也存在一些局限性。例如,LSA對于文本集合的大小和詞語的數量比較敏感,當文本集合較大或詞語數量較多時,計算量會顯著增加。此外,LSA還需要進行參數的選擇和調整,以得到最佳的文本表示效果。
總的來說,LSA是一種有效的文本表示和語義挖掘方法,它可以幫助我們更好地理解和處理文本數據。在實際應用中,我們可以根據具體的需求和場景選擇合適的LSA算法和參數設置,以得到最佳的文本表示和語義挖掘效果。
PLSA,全稱Probabilistic Latent Semantic Analysis,中文譯為概率潛在語義分析,是一種基于統計的文本主題模型。它是在LSA(潛在語義分析)的基礎上發展而來的,通過引入概率模型來更好地描述文本、詞語和主題之間的關系。
PLSA的基本思想是將文本集合中的每個文本看作是由一組潛在的主題按照某種概率分布生成的,而每個主題則是由一組詞語按照另一種概率分布生成的。這樣,文本、詞語和主題之間就形成了一個概率圖模型。
在PLSA中,每個文本被表示為一個主題的概率分布,而每個主題則被表示為一個詞語的概率分布。通過訓練文本集合,可以學習到這些概率分布,并用于后續的任務,如文本分類、聚類、相似度計算等。
相比于LSA,PLSA具有更強的解釋性和靈活性。它不僅可以描述文本和詞語之間的共現關系,還可以揭示文本和主題、主題和詞語之間的深層關聯。這使得PLSA在處理文本數據時更加精確和可靠。
然而,PLSA也存在一些局限性。例如,它需要預先設定主題的數量,而這個數量通常很難確定。此外,PLSA的模型復雜度較高,計算量較大,對于大規模的文本集合可能不太適用。
盡管如此,PLSA在文本挖掘和信息檢索等領域仍然具有重要的應用價值。它可以有效地挖掘文本的潛在語義結構,提高文本表示和語義理解的準確性。同時,PLSA也可以與其他文本處理技術相結合,形成更強大的文本分析和挖掘系統。
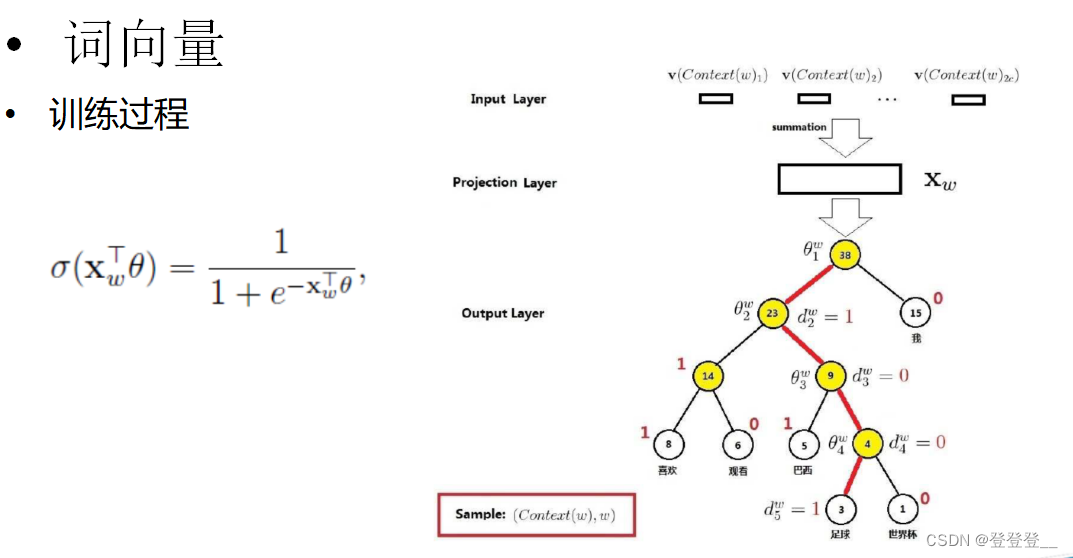
詞向量訓練
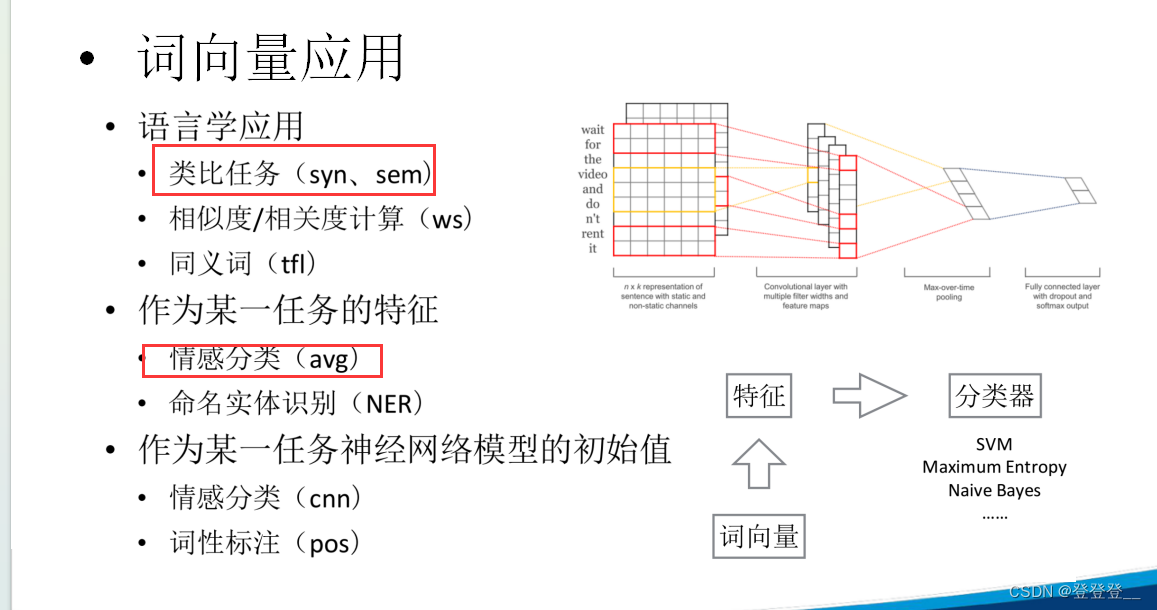
詞向量應用
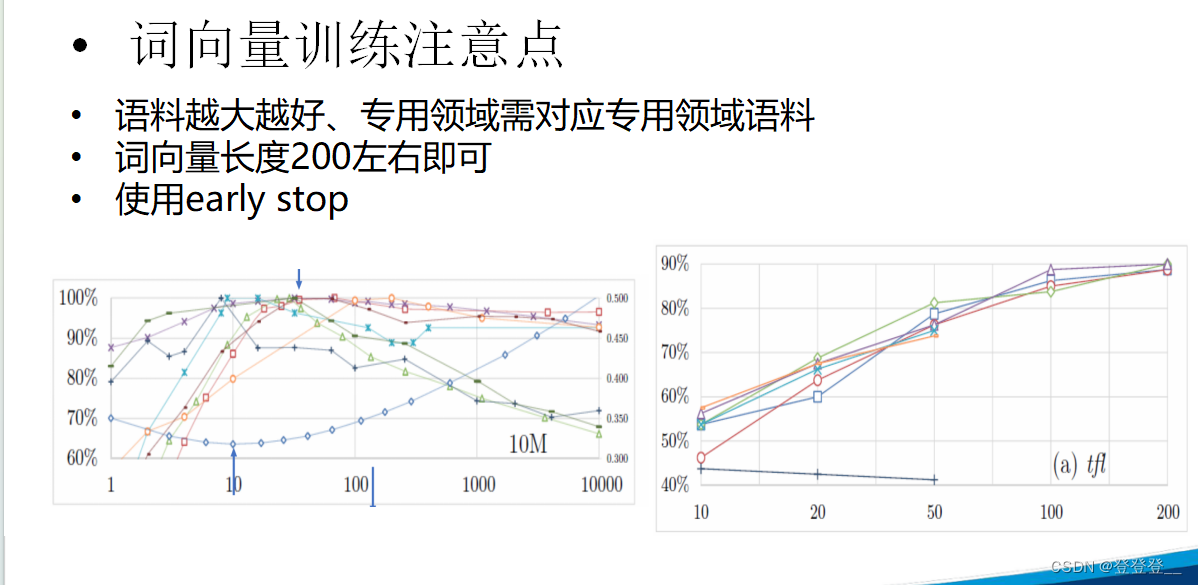
循環神經網絡RNN(語義理解)

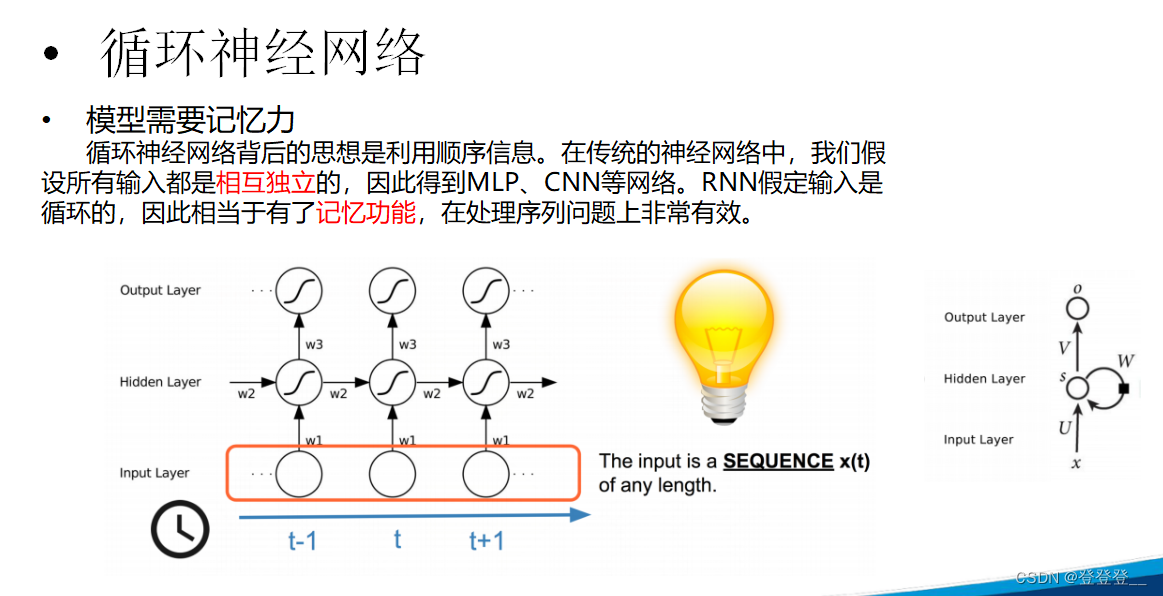
基本原理
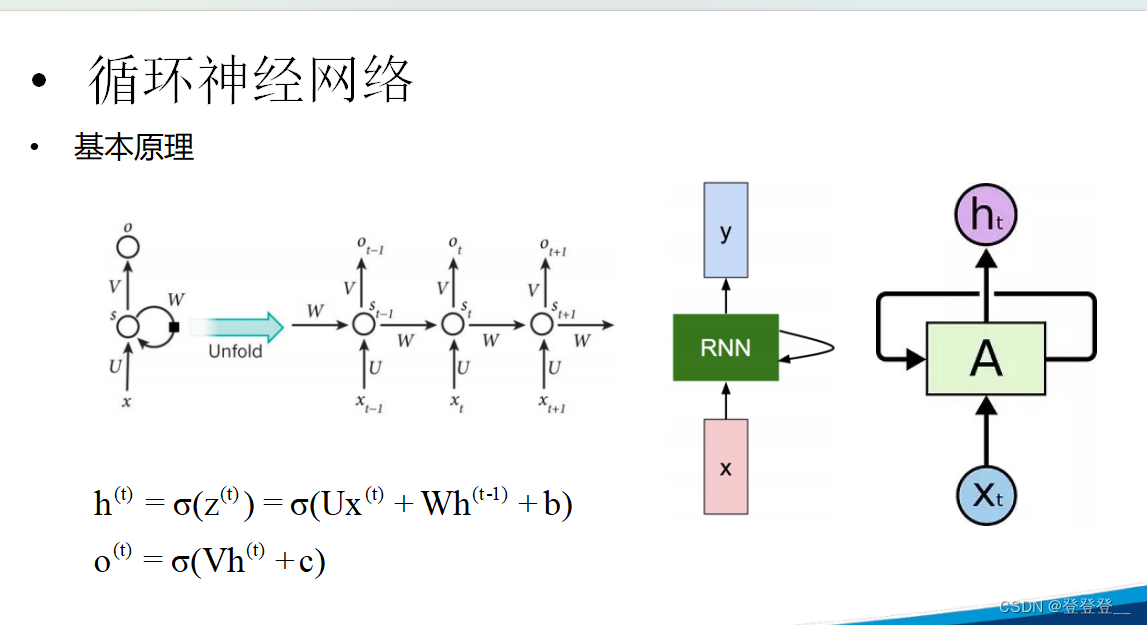

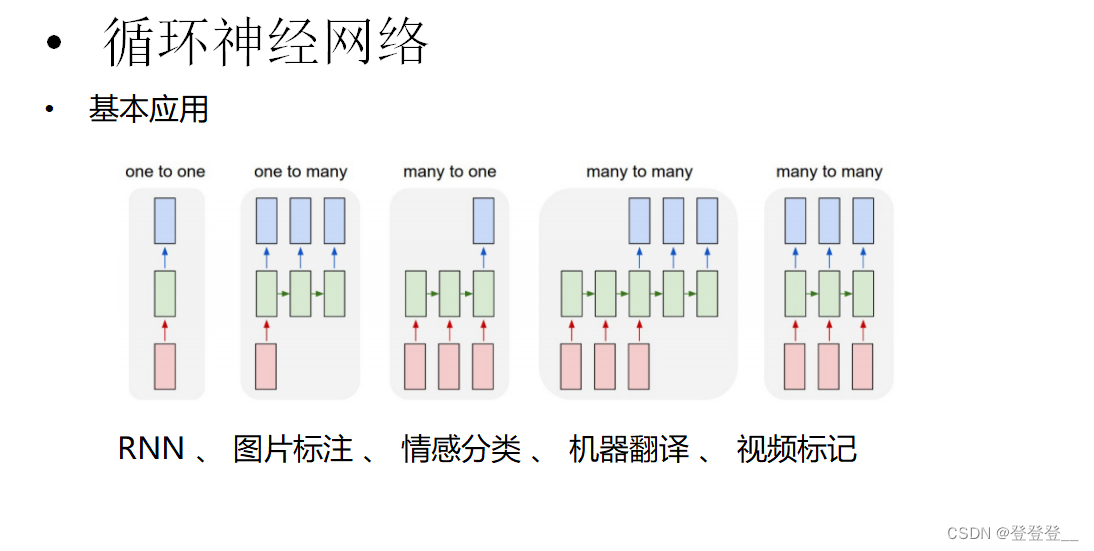
基本應用
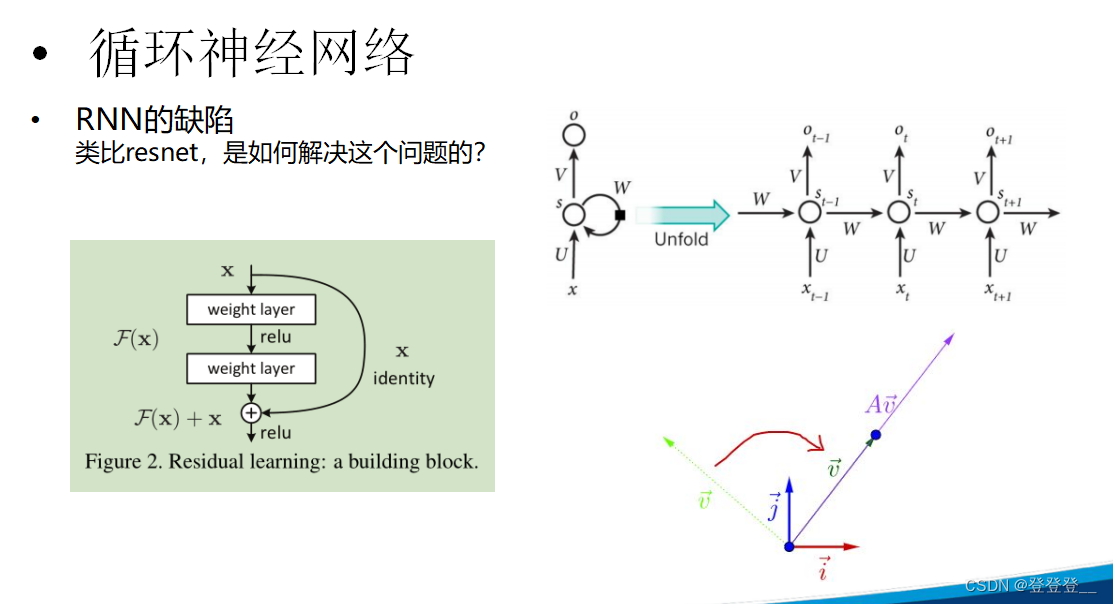
RNN的缺陷
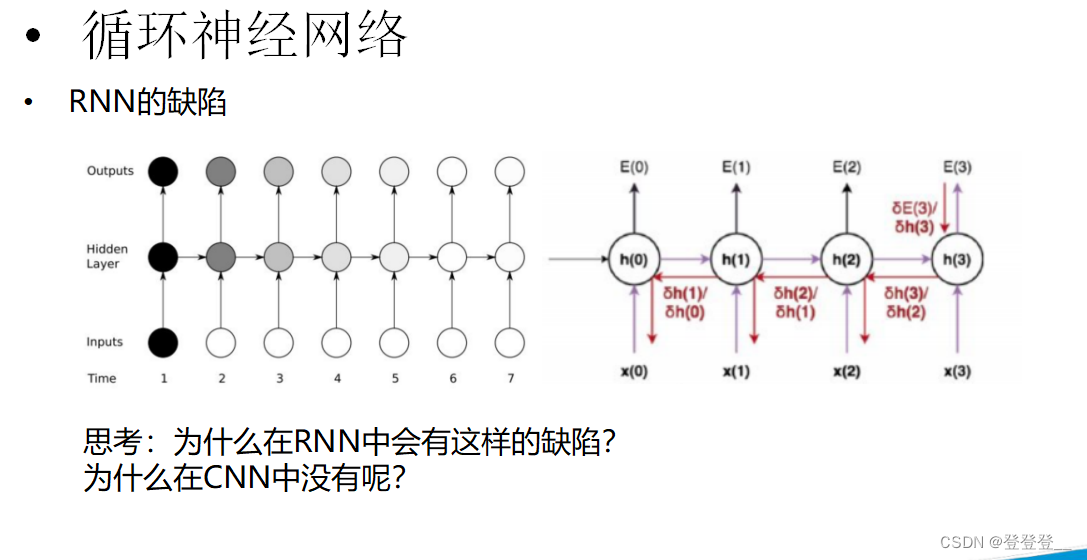
循環神經網絡(RNN)在處理序列數據時具有強大的能力,尤其是處理那些前后依賴關系較強的序列數據時。然而,RNN也存在一些缺陷,這些缺陷限制了其在某些任務上的性能和應用范圍。以下是RNN的一些主要缺陷:
梯度消失與梯度爆炸:在訓練RNN時,梯度在反向傳播過程中可能會變得非常小(梯度消失)或非常大(梯度爆炸)。這主要是因為RNN在序列的每個時間步上共享相同的參數,并且在計算梯度時涉及到多個時間步的累積。梯度消失可能導致RNN無法學習到長距離依賴關系,而梯度爆炸則可能導致訓練過程不穩定。
難以處理長序列:由于梯度消失問題,RNN在處理長序列時可能會遇到困難。長序列中的信息可能無法在RNN的狀態中有效地傳遞和保留,導致模型無法捕捉到序列的遠端依賴關系。
模型結構相對簡單:與更復雜的深度學習模型相比,RNN的模型結構相對簡單。雖然這有助于減少模型的復雜性和計算量,但也限制了其在處理復雜任務時的性能。例如,RNN可能無法充分捕獲序列中的多層次結構和非線性關系。
對輸入順序敏感:RNN在處理序列數據時,對輸入的順序非常敏感。如果序列中的元素順序發生變化,RNN的性能可能會受到很大影響。這種敏感性在某些任務中可能是有益的,但在其他任務中可能會成為限制。
為了克服這些缺陷,研究者們提出了一系列改進方法,如長短時記憶網絡(LSTM)和門控循環單元(GRU)等。這些改進方法通過引入門控機制和記憶單元,增強了RNN處理長序列和捕捉遠程依賴關系的能力。此外,隨著深度學習技術的不斷發展,還涌現出了其他類型的序列模型,如Transformer和BERT等,這些模型在處理序列數據時具有更強的性能和靈活性。
LSTM (特殊的RNN)
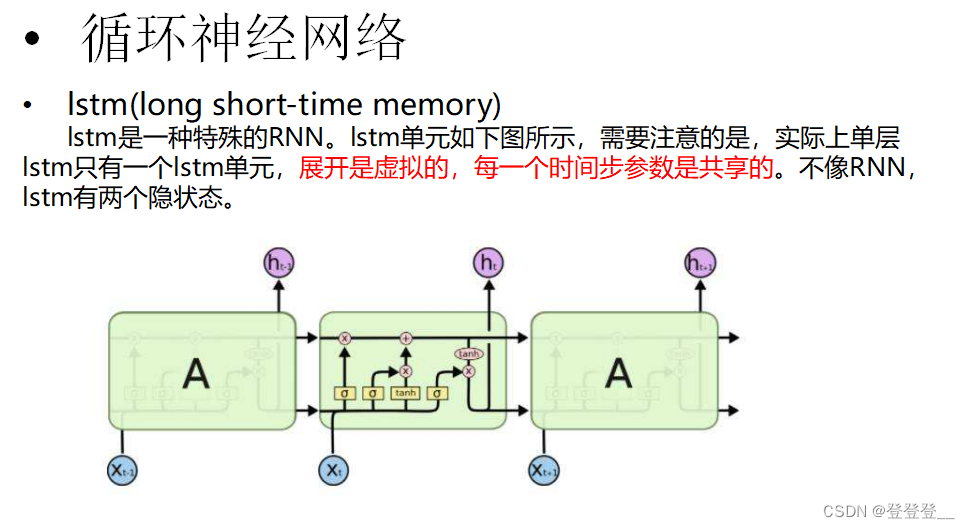
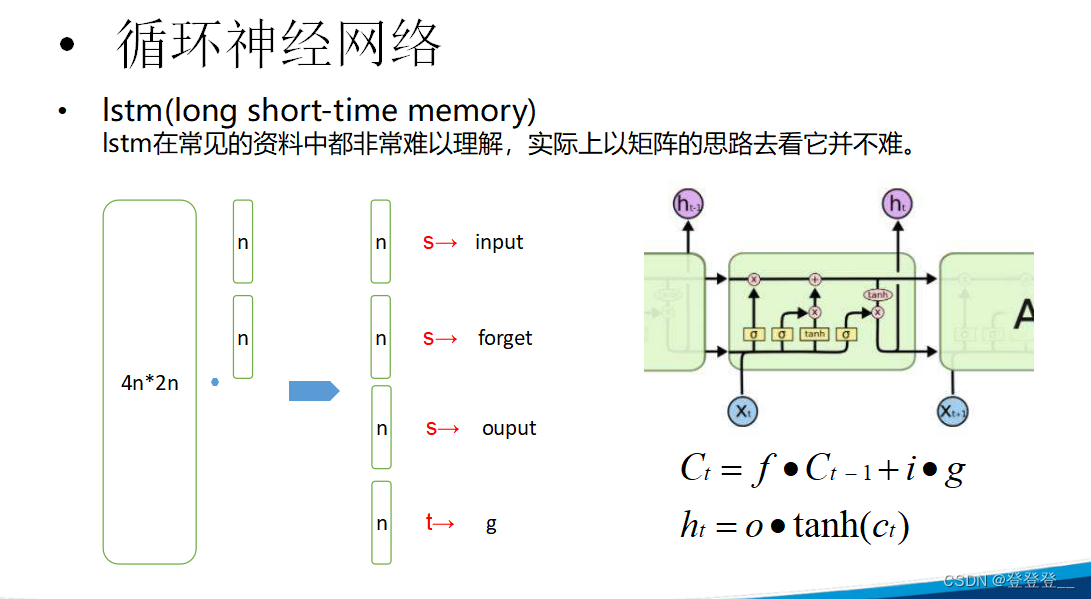
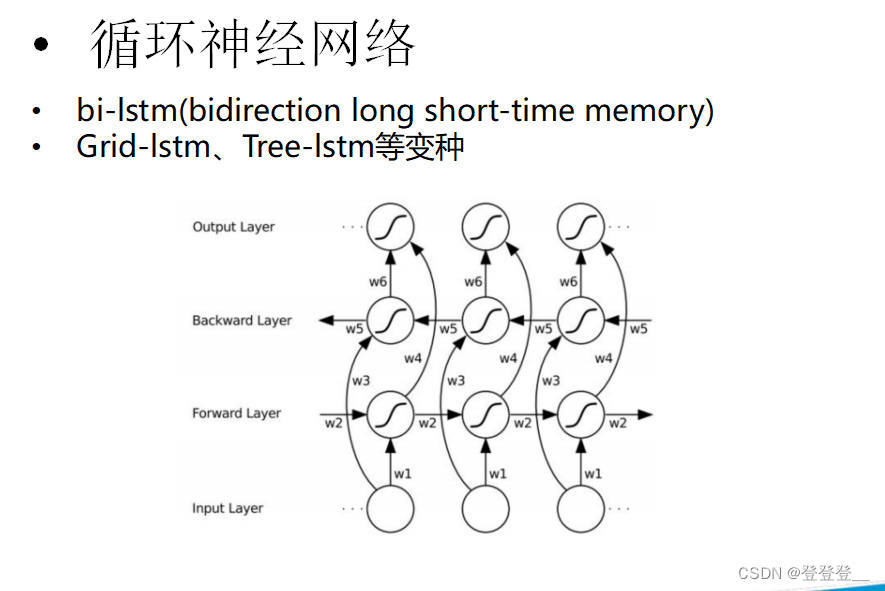
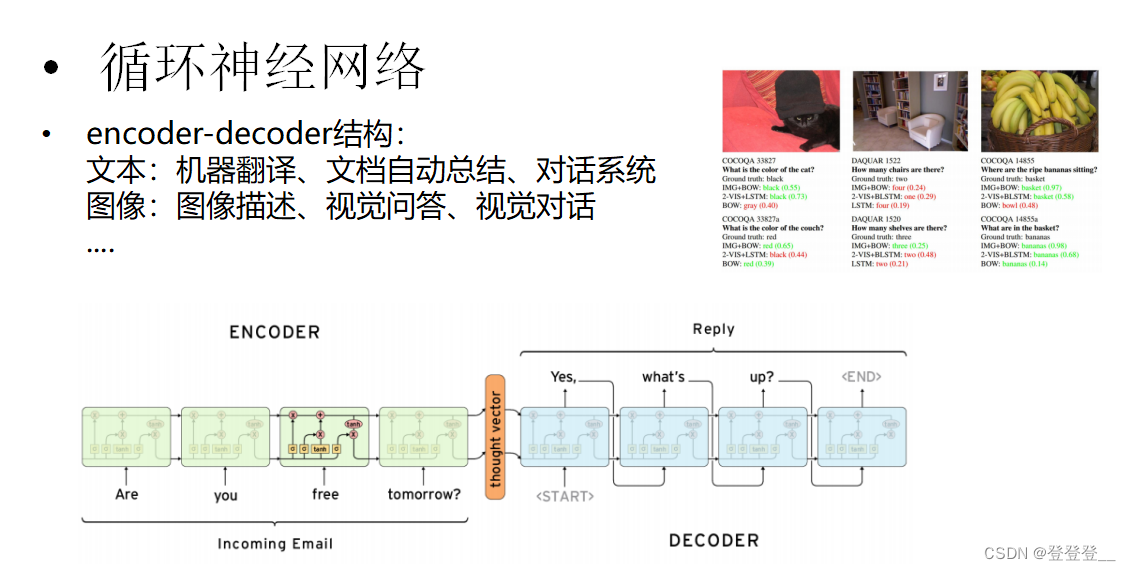








)







)


