論文:DIN-SQL: Decomposed In-Context Learning of Text-to-SQL with Self-Correction
????
NeurIPS 2023, arXiv:2304.11015
Code: Few-shot-NL2SQL-with-prompting | GitHub
文章目錄
- 一、論文速讀
- 1.1 Schema Linking Module
- 1.2 Classification & Decomposition Module
- 1.3 SQL Generation Module
- 1.3.1 EASY 類型
- 1.3.2 NON-NESTED 類型
- 1.3.3 NESTED 類型
- 1.4 Self-correction Module
- 二、Error cases 分析
- 三、總結
一、論文速讀
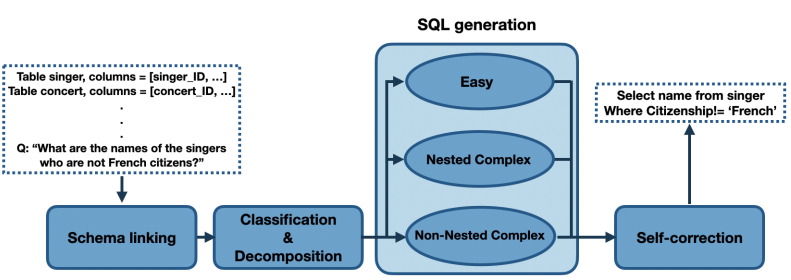
這篇論文通過對 LLM 做 prompt 來實現 Text2SQL,過程中通過 prompt 讓 LLM 分解任務來降低難度,每個子任務通過 in-context learning 讓 LLM 來完成,并在完成 SQL 生成后,通過 self-correction 來檢查和糾正可能有錯誤的 SQL。最終,在執行精確度指標上超越了現有的 SOTA 模型。
生成 SQL 被分成四個階段:
- Schema Linking:輸入 NL query 和 DB schema,找出與 query 相關的 tables、columns 以及不同表之間的外鍵關系
- Classification & Decomposition:將 query 分成了三種不同的難度:EASY、NON-NESTED、NESTED
- SQL Generation:根據不同類型的 query,按照不同的策略來生成對應的 SQL
- Self-correction:通過 prompt 來讓 LLM 檢查和糾正可能錯誤的 SQL
1.1 Schema Linking Module
這個 module 輸入 NL query 和 DB 的 schema 信息,輸出的是將 query 鏈接到 DB 中的一些信息,具體來說輸出就是:
- table 和 columns 的名稱:找到 query 中涉及到的 DB 的 table 和 columns 的名稱
- 條件值:從查詢中提取出用于條件過濾的值,比如在查詢“Find the departments with a budget greater than 500”中,需要提取出條件值“500”。
- 外鍵關系的確定:如果查詢涉及到多個表,需要確定它們之間的關系,如通過外鍵連接。
下面是使用 in-context learning + CoT 來讓 LLM 做 schema-linking 的示例:
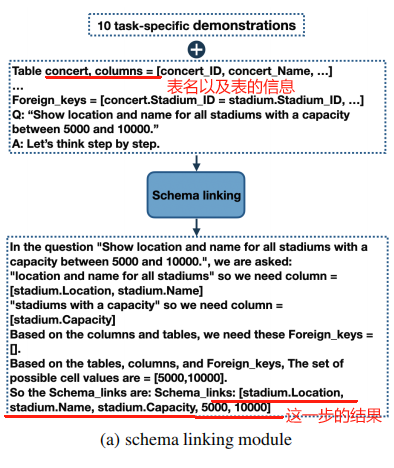
demostration 的一個示例如下:
Table advisor, columns = [*,s_ID,i_ID]
Table classroom, columns = [*,building,room_number,capacity]
Table course, columns = [*,course_id,title,dept_name,credits]
Table department, columns = [*,dept_name,building,budget]
Table instructor, columns = [*,ID,name,dept_name,salary]
Table prereq, columns = [*,course_id,prereq_id]
Table section, columns = [*,course_id,sec_id,semester,year,building,room_number,time_slot_id]
Table student, columns = [*,ID,name,dept_name,tot_cred]
Table takes, columns = [*,ID,course_id,sec_id,semester,year,grade]
Table teaches, columns = [*,ID,course_id,sec_id,semester,year]
Table time_slot, columns = [*,time_slot_id,day,start_hr,start_min,end_hr,end_min]
Foreign_keys = [course.dept_name = department.dept_name,instructor.dept_name = department.dept_name,section.building = classroom.building,section.room_number = classroom.room_number,section.course_id = course.course_id,teaches.ID = instructor.ID,teaches.course_id = section.course_id,teaches.sec_id = section.sec_id,teaches.semester = section.semester,teaches.year = section.year,student.dept_name = department.dept_name,takes.ID = student.ID,takes.course_id = section.course_id,takes.sec_id = section.sec_id,takes.semester = section.semester,takes.year = section.year,advisor.s_ID = student.ID,advisor.i_ID = instructor.ID,prereq.prereq_id = course.course_id,prereq.course_id = course.course_id]
Q: "Find the buildings which have rooms with capacity more than 50."
A: Let’s think step by step. In the question "Find the buildings which have rooms with capacity more than 50.", we are asked:
"the buildings which have rooms" so we need column = [classroom.capacity]
"rooms with capacity" so we need column = [classroom.building]
Based on the columns and tables, we need these Foreign_keys = [].
Based on the tables, columns, and Foreign_keys, The set of possible cell values are = [50]. So the Schema_links are:
Schema_links: [classroom.building,classroom.capacity,50]
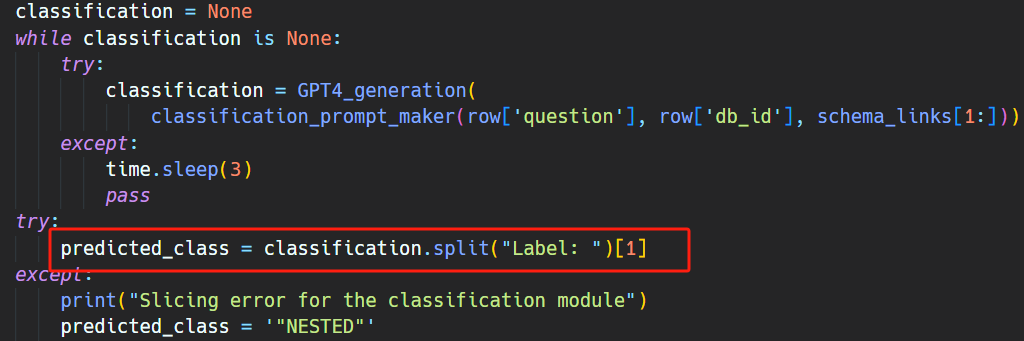
如下面代碼所示,schema linking 的結果就是從 GPT 的響應中解析出 Schema_links: 這個字符串后面的內容:

1.2 Classification & Decomposition Module
這一步將 query 分成三種不同的復雜度的類:
- EASY:沒有 JOIN 和 NESTING 的單表查詢
- NON-NESTED:需要 JOIN 但不需要子查詢的查詢
- NESTED:可以包含 JOIN、sub-query 和 set opr
下面是一個該 module 的示例:
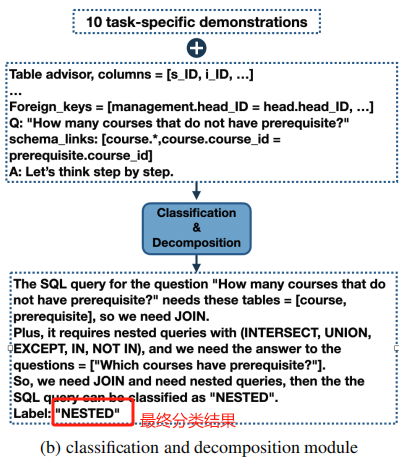
這部分代碼如下:
1.3 SQL Generation Module
這一個 module 根據 query 的復雜度類型,使用不同的策略來生成 SQL。
1.3.1 EASY 類型
對于 EASY 類型的 question,不需要中間步驟,只需要少量提示就足夠了,下面是一個 exemplar:
Q: "Find the buildings which have rooms with capacity more than 50."
Schema_links: [classroom.building,classroom.capacity,50]
SQL: SELECT DISTINCT building FROM classroom WHERE capacity > 50
即要求 LLM 根據 question 和 schema links 輸出 SQL。
1.3.2 NON-NESTED 類型
對于 NON-NESTED 類型的 question,啟發 LLM 去思考從而生成 SQL,下面是一個 exemplar:
Q: "Find the total budgets of the Marketing or Finance department."
Schema_links: [department.budget,department.dept_name,Marketing,Finance]
A: Let’s think step by step. For creating the SQL for the given question, we need to join these tables = []. First, create an intermediate representation, then use it to construct the SQL query.
Intermediate_representation: select sum(department.budget) from department where department.dept_name = \"Marketing\" or department.dept_name = \"Finance\"
SQL: SELECT sum(budget) FROM department WHERE dept_name = 'Marketing' OR dept_name = 'Finance'
也就是輸入 question 和 schema links,然后加一句 Let's think step by step 啟發 LLM 思考,從而得到 SQL。
1.3.3 NESTED 類型
在 “Classification & Decomposition Module” 模塊中,除了為其復雜度分類,還會為 NESTED 類型的 user question 生成 sub-question,如下圖:
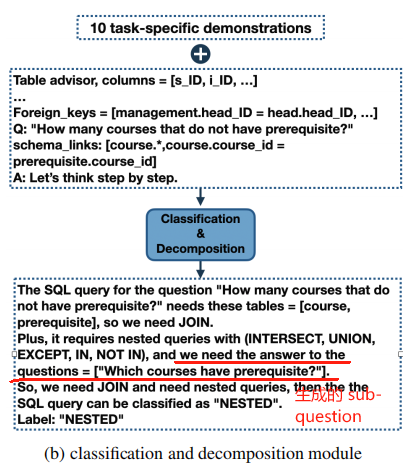
然后,這里的 sub-questions 會被傳入 SQL Generation Module 的 prompt 中用于解決 NESTED 類型的 SQL 生成。下面是一個 exemplar:
Q: "Find the title of courses that have two prerequisites?"
Schema_links: [course.title,course.course_id = prereq.course_id]
A: Let's think step by step. "Find the title of courses that have two prerequisites?" can be solved by knowing the answer to the following sub-question "What are the titles for courses with two prerequisites?".
The SQL query for the sub-question "What are the titles for courses with two prerequisites?" is SELECT T1.title FROM course AS T1 JOIN prereq AS T2 ON T1.course_id = T2.course_id GROUP BY T2.course_id HAVING count(*) = 2
So, the answer to the question "Find the title of courses that have two prerequisites?" is =
Intermediate_representation: select course.title from course where count ( prereq.* ) = 2 group by prereq.course_id
SQL: SELECT T1.title FROM course AS T1 JOIN prereq AS T2 ON T1.course_id = T2.course_id GROUP BY T2.course_id HAVING count(*) = 2
exemplar 的 prompt 的組成如下:

可以看到,這就是輸入 question、sub-questions、schema links 來生成 SQL。
1.4 Self-correction Module
這一模塊的目的是通過 prompt 讓 LLM 來檢查和糾正生成的 SQL 中可能的錯誤。這里的 prompt 如下:
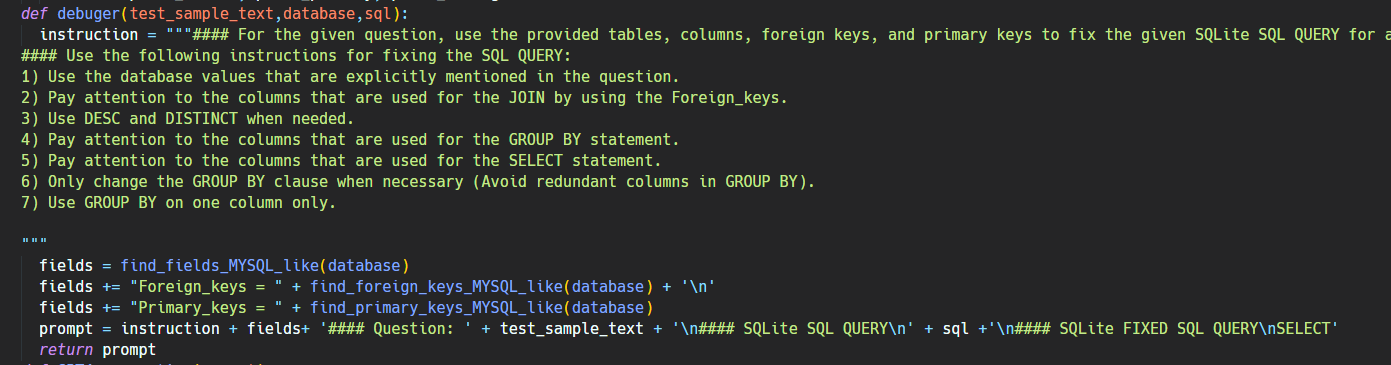
這里的 prompt 讓 LLM 多關注自己在生成 SQL 時容易犯的錯。
二、Error cases 分析
論文對 error cases 做了分析,總結了如下 LLM 容易出的錯:
- Schema linking:這類是犯錯最多的情況,指的是 model 錯誤地識別出 question 中提到的 column names、table names 或者 entities。
- JOIN:第二大類情況,指的是 model 不能識別出所有需要的 tables 以及正確地將這些 tables 連接起來的外鍵。
- GROUP BY:在生成 GROUP BY 子句時,可能會遺漏或者選錯列
- Queries with nesting and set operations:模型不能識別出 nested structure 或者不能檢測出正確的 nesting 或 set 操作
- Invalid SQL:一部分 SQL 有語法錯誤且不能執行
- Miscellaneous:還有其他亂七八糟的原因,比如缺少 predicate、缺少或冗余 DISTINCT、DESC 等關鍵字
這些容易犯的錯,都會在 self-correction module 被多關注來檢查和糾正。
三、總結
本論文設計的 prompt 以及思路讓 LLM 在解決 Text2SQL 任務上有了不錯的表現,產生了與最先進的微調方法相當甚至更優的結果。
但是,本文的思路需要多輪與 LLM 交互,從而產生了巨大的花費和延遲,論文給出,在使用 GPT4 響應 Spider 數據集中 question 時表現出大約 60s 的延遲。




:電容觸摸按鍵實驗)


:私有繼承和受保護的繼承)





)


)


