自從谷歌推出 Gemini 1.5 Pro,行業內部對于 RAG 的討論就不絕于耳。
Gemini 1.5 Pro 的性能確實令人矚目。根據谷歌公布的技術文檔,該系統能夠穩定處理長達 100 token 的內容,相當于一小時的視頻、十一小時的音頻、超過三萬行的代碼或七十萬個文字。其處理能力上限更是達到驚人的 1000 萬 token,相當于《指環王》三部曲的長度,刷新了上下文窗口長度的記錄。

憑借超長上下文理解能力,Gemini 1.5 Pro 得到了很多用戶的認可。很多測試過 Gemini 1.5 Pro 的人更是直言,這個模型被低估了。有人嘗試將從 Github 上下載的整個代碼庫連同 issue 都扔給 Gemini 1.5 Pro,結果它不僅理解了整個代碼庫,還識別出了最緊急的 issue 并修復了問題。
當然,除了谷歌在卷 “上下文長度”,其他大模型公司也都在卷這個能力。去年下半年,GPT-3.5 上下文輸入長度從 4 千增長至 1.6 萬 token,GPT-4 從 8 千增長至 3.2 萬 token;OpenAI 最強競爭對手 Anthropic 一次性將上下文長度打到了 10 萬 token;LongLLaMA 將上下文的長度擴展到 25.6 萬 token,甚至更多。
在國內,剛剛完成 8 億美元融資的 AI 大模型公司月之暗面,也把 “長文本(Long Context)” 當前主打的技術之一。去年 10 月,當時月之暗面發布了首個模型 Moonshot 和 Kimi 智能助手,支持 20 萬字的輸入。
那么,上下文到底意味著什么,為什么大家都在卷這個能力?
01 上下文長度,大模型好用的關鍵
上下文技術,是指模型在生成文本、回答問題或執行其他任務時,能夠考慮并參照的前置文本的數量或范圍,是一種大模型信息量處理能力的評價維度。用通俗的話來說,如果參數規模大小比喻成模型的計算能力,那么上下文長度更像是模型的 “內存”,決定了模型每輪對話能處理多少上下文信息,直接影響著 AI 應用的體驗好壞。
比如,隨著上下文窗口長度的增加,可以提供更豐富的語義信息,有助于減少 LLM 的出錯率和「幻覺」發生的可能性,用戶使用時,體驗能提升不少。
在業內人士看來,上下文長度增加對模型能力提升意義巨大。用 OpenAI 開發者關系主管 Logan Kilpatrick 話說,“上下文就是一切,是唯一重要的事”,提供足夠的上下文信息是獲得有意義回答的關鍵。
02 這跟 RAG 有啥關系?
RAG,中文翻譯過來就是檢索增強生成,所做的事情并不復雜,就是通過檢索獲取與用戶輸入相關的知識并在上下文中提供給大模型,為大模型提供更多更有效的信息,增強生成內容的質量。
具體來說,在語言模型生成答案前,RAG 先從廣泛的文檔數據庫中檢索相關信息,然后利用這些信息來引導生成過程,極大地提升了內容的準確性和相關性。
舉個例子,作為一名員工,你可以直接問大模型 “我們公司對遲到有什么懲罰措施?”,在沒有讀過《員工手冊》的情況下,大模型沒有辦法回答。但是,借助 RAG 方法,我們可以先讓一個檢索模型到《員工手冊》里去尋找最相關的幾個答案,然后把你的問題和它找到的相關答案都送到生成模型中,讓大模型生成答案。這就解決了之前很多大模型上下文窗口不夠大(比如容不下《員工手冊》)的問題。
不過嘛,現在情況不一樣了。如果一個模型可以直接處理 1000 萬 token 的上下文信息,還有必要再通過額外的檢索步驟來尋找和整合相關信息嗎?用戶可以直接將他們需要的所有數據作為上下文放入模型中,然后像往常一樣與模型進行交互。「大型語言模型本身已經是一個非常強大的檢索器,為什么還要費力建立一個弱小的檢索器,并在分塊、嵌入、索引等方面耗費大量工程精力呢?」愛丁堡大學博士生符堯評論道。
那么,RAG 技術是否已經過時了?它是會被長文本徹底取代,還是維持配角現狀,還是跟大模型共同進化?
為此,我們采訪了 PingCAP AI Lab 的數據科學家孫逸神,以下為他的看法 ——
03 上下文窗口與 RAG 共存共贏
我認為,在假定 LLM 有足夠的閱讀理解能力的前提下,RAG 的本質就是在上下文窗口的約束下,提高 Prompt 的有效信息密度,從而提高生成質量的有力手段。而這兩者,是毫無沖突的。
是的,我認為上下文跟 RAG 并不矛盾。GPT-4o 的回答,基本上表達了我的觀點:
Q:?LLM 的 context window 和 RAG 有什么關系嗎?
A:?LLM(大型語言模型)的 context window 和 RAG(Retrieval-Augmented Generation)是兩個相關但不同的概念。它們在信息處理和生成方面有著不同的作用和機制。
首先來看看他們各自的應用場景和具體作用:
Context Window,指大型語言模型在一次生成或處理過程中能夠看到和使用的文本長度。注意,它是有長度限制的。例如,GPT-4 的 context window 可能是 8,000 或 32,000 個 token(具體長度取決于模型的版本)。
在這個窗口內,模型可以使用上下文信息來理解和生成文本。如果超出上下文窗口限制,模型就無法利用所有相關信息,可能會導致直接報錯退出。
所以,context window 是任何任務的約束條件,即大模型單次最多能讀的內容量,模型在處理當前任務時依賴于它能看到的上下文。
Retrieval-Augmented Generation,一種結合檢索和生成的技術,旨在提高生成文本的質量和信息性。
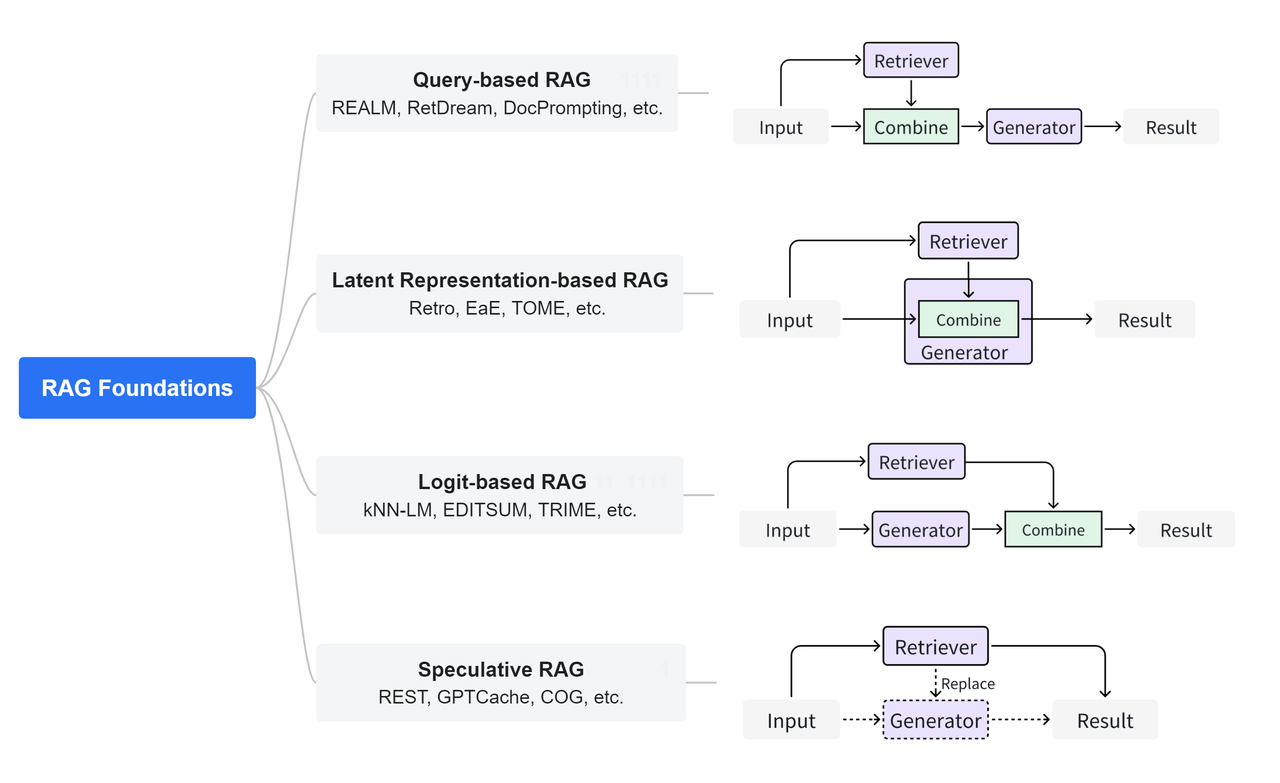
圖源:https://github.com/hymie122/RAG-Survey
在檢索階段,RAG 系統首先從一個大規模的知識庫或文檔數據庫中檢索出與查詢相關的信息。這通常使用信息檢索技術,例如 BM25、TF-IDF 或基于深度學習的檢索模型(如 Dense Passage Retrieval, DPR);當然,也可以是向量檢索,總而言之,檢索并不限定某一種特定方法,甚至可以多種方法進行組合。
在生成階段,RAG 系統會把檢索到的相關文檔或信息作為上下文的一部分提供給生成模型,生成模型使用這些上下文來生成更準確和相關的回答。另外,通過使用檢索到的外部信息,RAG 能生成更具信息性的回答,特別是在模型本身知識庫不足或需要實時信息時。這就是結合上下文生成和增強生成。
那它們倆之間有啥關系?
-
增加有效信息輸入:
??RAG 技術可以在上下文窗口以內,增加有效消息量。LLM 的 context window 有限,但通過檢索相關文檔并將其作為上下文傳遞給生成模型,可以在不直接增加模型 context window 的情況下提供更多的相關信息。
-
提高準確性:
??當需要生成具體領域或最新的信息時,RAG 的檢索機制可以提供精確的上下文,幫助 LLM 生成更準確的回答。這樣可以彌補模型訓練時的數據不足或過時的問題。
所以,LLM 的 context window 和 RAG 在生成文本時都有重要作用,但它們通過不同的方式來增強文本生成的質量和連貫性。context window 提供了模型在單次處理中的上下文范圍,而 RAG 通過檢索相關信息提高了上下文的信息質量,使得模型可以生成更為信息豐富和準確的內容。
04 未來,RAG 也不會被取代
我認為,與其聚焦于現下討論它們之間的優劣勢,不妨以發展的眼光來看 LLM 和 RAG 的關系。
從 OpenAI 推出 ChatGPT 開始,人們體驗到了碾壓以往同類 “智障聊天機器人” 的 AI 產品。ChatGPT 引爆全球以后,大家發現了它巨大潛力的同時,也同樣發現了它很多的能力缺陷,其中首當其沖的就是幻覺。另外,上下文有限也限制了應用的想象力。
如何減輕幻覺?一種方式是重新訓練基礎模型,用更多更高質量的語料,費人費時費能費錢。于是人們又使用了微調的方法,用相對少的訓練量,修改部分深度網絡的參數,來達到質量提升的效果。它的性價比已經是小團隊或個人開發者可以接受的狀態了。
但為什么還會繼續發展到 RAG 呢?其中一方面原因是微調依然需要對語料的質量有要求,雖說微調本身不花太長時間,但是語料的收集和前處理是需要一定時間的;另一方面還有一個原因是,無論是訓練還是微調,大方向上看是總體提升的,但是期待沒有一個點變弱也是不太可控的,它可以定向地學習好的,但是難以定向地遺忘不好的,所以是存在變差的可能性的。
于是,RAG 也很自然地成為大家提高輸出質量的一個研究方向。RAG 能起到作用,本身隱含了一個前提條件,就是 LLM 在上下文窗口內存在較強的 “閱讀理解” 能力。雖說我依然不認為 LLM 有 “邏輯” 能力(為什么 LLM 看起來是有 “邏輯” 的,因為 “邏輯” 的最大載體是語言,如果 LLM 輸入 “學習” 的是大量蘊含正確邏輯的文本,那它作為一個類似馬爾科夫決策過程,它的生成也會傾向于有 “邏輯” 的輸出,但這不等于理解 “邏輯” 并能自如地運用 “邏輯”),但它確實在絕大多數情況下表現出了優秀的 “閱讀理解” 能力以及續寫和回答問題的能力。
既然這個前提在廣泛的實踐上被證實大體有效,那人們可以很自然地想到一個降低 LLM 幻覺,改善 LLM 輸出質量的方法。第一,更充分地利用上下文窗口的長度。這和人類間的交互是類似的,就像提問的智慧一樣,給予更多的信息,通常對于生成的內容是有幫助的。如果輸入內容的有效信息密度提高,同樣也是有益的。這一點很容易直觀地理解。
那接下來,如何提高上下文窗口限制內的有效信息密度,第一種方式就是人工提供。就是一開始大家鉆研玩花的 Prompt 魔法。
但每次手工輸入在工程上是沒法 Scale 的,所以上述方式更多是對直接使用 Chat 的終端用戶有價值,對于要包裝 LLM 為用戶提供更好服務的中間商是不太可行的,于是 RAG 自然就出現了。如果你把它理解成搜索引擎,就是在上下文窗口長度限制內,增加更多與用戶輸入 “相關” 的內容。提供的內容越多,通常 LLM 自由發揮天馬行空的概率就會降低,這也是很樸素的一個結論。RAG 就是一個盡可能提高有效信息密度的工程實現手段。
到這里,其實主要的觀點 —— 上下文窗口與 RAG 沒有任何矛盾的結論已經可以支撐住了。
進一步補充說明的話,RAG 整個系統的目的還是 Generation,Retrieval 是一種提高質量 (Augmented) 的手段,上下文窗口是 Generation 子系統的一個參數或者說約束,Retrieval 是在這個約束內工作的,屬于是帶著鐐銬跳舞的狀態。窗口小就少 Retrieving 一些東西回來,窗口大就多 Retrieving 一些東西回來,就是這么一個樸素的邏輯。
而上下文的拓展本身,與需要表達的觀點無關,需要關注的是,趨勢上來看,上下文越長,LLM 的能力會相應變弱,這是符合直覺的,人類也有同樣的問題。第二是上下文拓展的方法,這個在 LLAMA 上研究得已經很多了。開發 LLM 的人目標一定是更長的上下文且不斷提高在此前提下的輸出質量。
另外要補充說明的一個角度是,LLM 在不斷地進步,很多早期通過包裝 LLM 來為用戶提供價值的中間商被上游新一代的 LLM 直接降維打擊出局,所以圍繞 LLM 做開發的人都不免要擔心自己在做的事情,會不會被下一代 LLM 干掉,這是一個很現實的問題。我的觀點是 RAG 不會,Agent 也不太會?(此處不展開)。RAG 能夠長期立足的原因在于,訓練和微調之間是有時間差的,這個時間差會變小,但長期來看,不會變為 0,在這個時間差以內的信息,只能通過 RAG 的方式注入。同樣的,私域知識也只可能通過 RAG 的方式注入。時效性需求和私有性需求決定了 RAG 會一直存在,大家要做的只是進一步提高 RAG 的搜索質量,讓 LLM 可以更好地為用戶所愛。


)


)













