目錄
依賴環境
代碼
導入依賴包
定義數據集路徑:
創建訓練集、驗證集和測試集的文件夾:
代碼的作用:
設置新的數據集路徑與類別名稱
代碼的作用:
定義數據預處理和增強變換:
代碼的作用:
定義數據集評估劃分與batch大小
代碼的作用:
可視化
代碼的作用:
?評估可視化
代碼的作用:
網絡結構定義
代碼的作用:
定義損失函數和優化器,并訓練模型
?模型可視化評估
代碼的作用:
下載地址:
python深度學習pytorch水稻圖像分類完整案例
依賴環境
!pip install split-folders
!pip install torch-summary
!pip install torch matplotplib代碼
導入依賴包
import os
import pathlib
import numpy as np
import splitfolders
import itertools
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
from termcolor import colored
from datetime import datetime
import warnings
from tqdm.notebook import tqdm
from sklearn.metrics import confusion_matrix, classification_report
from torchsummary import summary
from numpy import asarray
from PIL import Image
os和pathlib用于文件和目錄操作。numpy用于數組和數值計算。splitfolders用于分割數據集。itertools提供迭代生成器。matplotlib.pyplot用于繪圖和數據可視化。torch、torch.nn、torch.nn.functional、torch.optim、torchvision和torchvision.transforms用于構建和訓練神經網絡模型。termcolor用于終端中的彩色輸出。datetime用于時間操作。warnings用于忽略警告信息。tqdm.notebook用于顯示進度條。sklearn.metrics提供評估指標,包括混淆矩陣和分類報告。torchsummary用于總結模型結構。numpy.asarray和PIL.Image用于圖像處理。
定義數據集路徑:
data = './Rice_Image_Dataset'
data = pathlib.Path(data)
創建訓練集、驗證集和測試集的文件夾:
splitfolders.ratio(input=data, output='rice_imgs', seed=42, ratio=(0.7, 0.15, 0.15))
- 使用
splitfolders.ratio函數將數據集按照 7:1.5:1.5 的比例劃分為訓練集、驗證集和測試集。 input參數指定輸入數據集的路徑。output參數指定輸出文件夾的名稱'rice_imgs',劃分后的數據集將保存在這個文件夾中。seed參數設置隨機種子,以確保劃分結果的可重復性。ratio參數指定訓練集、驗證集和測試集的比例,分別為 70%、15% 和 15%。
代碼的作用:
這段代碼通過 splitfolders 庫將原始的水稻圖像數據集劃分為訓練集、驗證集和測試集,以便在模型訓練、驗證和測試過程中使用不同的數據子集,從而提高模型的泛化能力和評估準確性。
設置新的數據集路徑與類別名稱
root_dir = './rice_imgs'
root_dir = pathlib.Path(root_dir)
Arborio='./Rice_Image_Dataset/Arborio'Arborio_classes=os.listdir(Arborio)
Rice_classes = os.listdir(root_dir)
batchsize=8from colorama import Fore, Styleprint(Fore.GREEN +str(Rice_classes))
print(Fore.YELLOW +"\nTotal number of classes are: ", len(Rice_classes))
root_dir定義為之前劃分后的數據集路徑'./rice_imgs',并轉換為路徑對象。Arborio定義為原始數據集中某個類別的路徑。- 使用
os.listdir(Arborio)獲取Arborio類別中的所有文件和文件夾名稱。 - 使用
os.listdir(root_dir)獲取新的數據集路徑中的所有類別名稱。 - 導入
colorama庫中的Fore和Style,用于終端輸出的顏色設置。
代碼的作用:
這段代碼的主要作用是設置新的數據集路徑,并獲取數據集中各個類別的名稱,以便在后續的數據加載和處理過程中使用。此外,代碼還打印出了類別名稱和總數,以便進行檢查和驗證。
定義數據預處理和增強變換:
transform = transforms.Compose([transforms.Resize((250,250)),transforms.ToTensor(),transforms.Normalize((0),(1)),transforms.RandomHorizontalFlip(),transforms.RandomRotation(30),]
)
transforms.Compose:將多個變換操作組合在一起。transforms.Resize((250,250)):將圖像調整為 250x250 的固定尺寸。transforms.ToTensor():將圖像轉換為 PyTorch 的張量格式,并將像素值歸一化到 [0,1] 的范圍。transforms.Normalize((0),(1)):標準化圖像,使圖像的每個通道均值為 0,標準差為 1。transforms.RandomHorizontalFlip():隨機水平翻轉圖像,用于數據增強,以增加模型的泛化能力。transforms.RandomRotation(30):隨機旋轉圖像最多 30 度,用于數據增強。
代碼的作用:
這段代碼通過定義一個數據預處理和增強的變換流水線,在加載圖像數據時自動對圖像進行調整大小、轉換為張量、標準化、隨機水平翻轉和隨機旋轉等操作。這些預處理和增強操作有助于提高模型的訓練效果和泛化能力。
定義數據集評估劃分與batch大小
import torch.utils.data
batch_size = 32# Read train images as a dataset
train_set = torchvision.datasets.ImageFolder(os.path.join(root_dir, 'train'), transform=transform
)
# Create a Data Loader
train_loader = torch.utils.data.DataLoader(train_set, batch_size = batch_size, shuffle=True
)
print(colored(f'Train Folder :\n ', 'green', attrs=['bold']))
print(train_set)
print('_'*100)############################################################## Read validation images as a dataset
val_set = torchvision.datasets.ImageFolder(os.path.join(root_dir, 'val'), transform=transform
)
# Create a Data Loader
val_loader = torch.utils.data.DataLoader(val_set, batch_size = batch_size, shuffle=True
)
print(colored(f'Validation Folder :\n ', 'red', attrs=['bold']))
print(val_set)
print('_'*100)############################################################## Read test images as a dataset
test_set = torchvision.datasets.ImageFolder(os.path.join(root_dir, 'test'), transform=transform
)
# Create a Data Loader
test_loader = torch.utils.data.DataLoader(test_set, batch_size = batch_size, shuffle=True
)
print(colored(f'Test Folder :\n ', 'yellow', attrs=['bold']))
print(test_set)
-
設置批量大小:
- 首先導入
torch.utils.data,并設置批量大小為 32,用于后續的數據加載器中。
- 首先導入
-
加載訓練集數據并創建數據加載器:
- 使用
torchvision.datasets.ImageFolder函數加載訓練集圖像數據,并應用之前定義的變換transform。os.path.join(root_dir, 'train')指定了訓練集數據的路徑。 - 創建一個數據加載器
train_loader,它從train_set中以批量的形式讀取數據,batch_size設置為 32,并啟用了隨機打亂shuffle=True。
- 使用
-
打印訓練集信息:
- 使用
colored函數將輸出文本設置為綠色,并打印訓練集文件夾的信息和訓練集數據集對象。
- 使用
-
加載驗證集數據并創建數據加載器:
- 類似于加載訓練集,使用
torchvision.datasets.ImageFolder函數加載驗證集圖像數據,并應用相同的變換transform。os.path.join(root_dir, 'val')指定了驗證集數據的路徑。 - 創建一個數據加載器
val_loader,從val_set中以批量的形式讀取數據,batch_size設置為 32,并啟用了隨機打亂shuffle=True。
- 類似于加載訓練集,使用
-
打印驗證集信息:
- 使用
colored函數將輸出文本設置為紅色,并打印驗證集文件夾的信息和驗證集數據集對象。
- 使用
-
加載測試集數據并創建數據加載器:
- 類似于加載訓練集和驗證集,使用
torchvision.datasets.ImageFolder函數加載測試集圖像數據,并應用相同的變換transform。os.path.join(root_dir, 'test')指定了測試集數據的路徑。 - 創建一個數據加載器
test_loader,從test_set中以批量的形式讀取數據,batch_size設置為 32,并啟用了隨機打亂shuffle=True。
- 類似于加載訓練集和驗證集,使用
-
打印測試集信息:
- 使用
colored函數將輸出文本設置為黃色,并打印測試集文件夾的信息和測試集數據集對象。
- 使用
代碼的作用:
這段代碼通過加載和處理訓練集、驗證集和測試集的數據,創建了相應的數據加載器。這些加載器將在模型訓練和評估過程中使用,以批量的形式高效地讀取和處理圖像數據,從而提高模型訓練和評估的效率。
可視化
# 可視化數據集以進行檢查
# 首先創建一個包含標簽名稱的字典
labels_map = {0: "Arborio",1: "Basmati",2: "Ipsala",3: "Jasmine",4: "Karacadag",
}figure = plt.figure(figsize=(10, 10))
cols, rows = 5, 5
for i in range(1, cols * rows + 1):sample_idx = torch.randint(len(train_set), size=(1,)).item()img, label = train_set[sample_idx]figure.add_subplot(rows, cols, i)plt.title(labels_map[label])plt.axis("off")img_np = img.numpy().transpose((1, 2, 0))# 將像素值剪輯到 [0, 1] 范圍內img_valid_range = np.clip(img_np, 0, 1)plt.imshow(img_valid_range)plt.suptitle('Rice Images', y=0.95)
plt.show()
-
創建標簽字典:
- 創建一個字典
labels_map,將類別索引映射到類別名稱,方便后續的可視化和檢查。
- 創建一個字典
-
創建可視化圖形:
- 使用
plt.figure創建一個圖形對象,設置圖形大小為 10x10。 - 設置圖形的列數和行數為 5,意味著將顯示 25 個圖像樣本。
- 使用
-
可視化圖像樣本:
- 使用
torch.randint隨機選擇訓練集中圖像樣本的索引。 - 從
train_set中獲取圖像和對應的標簽。 - 將圖像添加到圖形的子圖中,并設置子圖的標題為對應的類別名稱。
- 關閉子圖的坐標軸顯示。
- 將圖像從張量格式轉換為 NumPy 數組格式,并進行轉置以匹配
plt.imshow的輸入格式。 - 使用
np.clip將圖像的像素值限制在 [0, 1] 范圍內,以確保顯示的圖像顏色正常。 - 顯示圖像樣本,并設置圖形的整體標題為 "Rice Images"。
- 使用
代碼的作用:
這段代碼通過隨機選擇并顯示訓練集中的圖像樣本,以及相應的類別名稱,幫助檢查數據是否正確加載,并提供對數據分布的直觀理解。可視化的圖像可以幫助確認圖像增強和預處理步驟是否按照預期執行。

?評估可視化
def train(model, train_loader, validation_loader, device,loss_fn, optimizer, num_epochs, patience=3):"""訓練模型:model: 創建的模型train_loader: 使用DataLoader加載的訓練集validation_loader: 使用DataLoader加載的驗證集device: 訓練模型可用的設備(CPU或CUDA)loss_fn: 定義的損失函數optimizer: 定義的優化器num_epochs (int): 訓練的輪數patience (int): 用于早停的耐心參數"""history = {'train_loss': [],'val_loss': [],'train_acc': [],'val_acc': []}epoch = 0best_val_loss = float('inf')best_model_weights = Noneearly_stopping_counter = 0while epoch < num_epochs and early_stopping_counter < patience:model.train()train_loss = 0.0correct = 0total = 0pbar = tqdm(enumerate(train_loader), ncols=600, total=len(train_loader))for batch_idx, (inputs, labels) in pbar:pbar.set_description(f'Epoch {epoch+1}/{num_epochs} ')inputs, labels = inputs.to(device), labels.to(device)optimizer.zero_grad()outputs = model(inputs)loss = loss_fn(outputs, labels)loss.backward()optimizer.step()train_loss += loss.item()_, predicted = outputs.max(1)total += labels.size(0)correct += predicted.eq(labels).sum().item()train_loss /= len(train_loader)train_acc = correct / totalhistory['train_loss'].append(train_loss)history['train_acc'].append(train_acc)val_loss, val_acc = evaluate(model, validation_loader, device, loss_fn)history['val_loss'].append(val_loss)history['val_acc'].append(val_acc)# 打印進度print(f'train_loss: {train_loss:.4f} | 'f'train_acc: {train_acc:.4f} | ' +f'val_loss: {val_loss:.4f} | ' +f'val_acc: {val_acc:.4f}', '\n')if history['val_loss'][-1] < best_val_loss:best_model_weights = model.state_dict()early_stopping_counter = 0else:early_stopping_counter += 1best_val_loss = history['val_loss'][-1]epoch += 1return history, best_model_weights# ---------------------------------------------------------------def evaluate(model, data_loader, device, loss_fn):"""評估模型并返回損失和準確率:model: 創建的模型data_loader: 測試或驗證集加載器device: 訓練模型可用的設備(CPU或CUDA)loss_fn: 定義的損失函數"""model.eval()total_loss = 0.0correct = 0total = 0with torch.no_grad():for inputs, labels in data_loader:inputs, labels = inputs.to(device), labels.to(device)outputs = model(inputs)loss = loss_fn(outputs, labels)total_loss += loss.item()_, predicted = outputs.max(1)total += labels.size(0)correct += predicted.eq(labels).sum().item()val_loss = total_loss / len(data_loader)val_acc = correct / totalreturn val_loss, val_acc# -------------------------------------------------------------------def plot_comparision_result(model):"""繪制訓練和驗證集準確率和損失的對比圖:model: 創建的模型"""fig, axs = plt.subplots(2, 1, figsize=(10, 12))# 繪制訓練和驗證集的準確率axs[0].plot(model['history']['train_acc'], color="red", marker="o")axs[0].plot(model['history']['val_acc'], color="blue", marker="h")axs[0].set_title('訓練集和驗證集準確率對比')axs[0].set_ylabel('準確率')axs[0].set_xlabel('輪次')axs[0].legend(['訓練集', '驗證集'], loc="lower right")# 繪制訓練和驗證集的損失axs[1].plot(model['history']['train_loss'], color="red", marker="o")axs[1].plot(model['history']['val_loss'], color="blue", marker="h")axs[1].set_title('訓練集和驗證集損失對比')axs[1].set_ylabel('損失')axs[1].set_xlabel('輪次')axs[1].legend(['訓練集', '驗證集'], loc="upper right")plt.tight_layout()plt.show()# -------------------------------------------------------------------# 定義函數以創建包含實際標簽和預測標簽的兩個列表
def get_ture_and_pred_labels(dataloader, model):"""獲取包含實際標簽和預測標簽的兩個列表,用于混淆矩陣:dataloader: 數據加載器model: 創建的模型"""i = 0y_true = []y_pred = []for images, labels in dataloader:images = images.to(device)labels = labels.numpy()outputs = model(images)_, pred = torch.max(outputs.data, 1)pred = pred.detach().cpu().numpy()y_true = np.append(y_true, labels)y_pred = np.append(y_pred, pred)return y_true, y_pred# ------------------------------------------------------------------def plot_confusion_matrix(cm, classes,title='Confusion matrix',cmap=plt.cm.Blues):"""繪制混淆矩陣:cm(array): 混淆矩陣classes(dictionary): 目標類別(key=分類類型,value=數值類型)"""plt.figure(figsize=(10,7))plt.grid(False)plt.imshow(cm, interpolation='nearest', cmap=cmap)plt.title(title)plt.colorbar()tick_marks = np.arange(len(classes))plt.xticks(tick_marks, [f"{value}={key}" for key , value in classes.items()], rotation=45)plt.yticks(tick_marks, [f"{value}={key}" for key , value in classes.items()])thresh = cm.max() / 2.for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):plt.text(j, i, f"{cm[i,j]}\n{cm[i,j]/np.sum(cm)*100:.2f}%",horizontalalignment="center",color="white" if cm[i, j] > thresh else "black")plt.ylabel('實際值')plt.xlabel('預測值')plt.tight_layout()plt.show()
代碼的作用:
-
train函數:- 訓練模型并記錄訓練和驗證集的損失和準確率。
- 實現早停機制以防止過擬合。
-
evaluate函數:- 評估模型在給定數據集上的表現,返回損失和準確率。
-
plot_comparision_result函數:- 繪制訓練和驗證集的準確率和損失隨訓練輪次變化的對比圖。
-
get_ture_and_pred_labels函數:- 獲取實際標簽和預測標簽的列表,用于計算混淆矩陣。
-
plot_confusion_matrix函數:- 繪制混淆矩陣以評估分類模型的性能,顯示分類結果的準確性。
網絡結構定義
# 定義第二個卷積神經網絡模型:包含兩個卷積層和兩個池化層
class Model(nn.Module):def __init__(self, dim_output):super().__init__()self.conv1 = nn.Conv2d(3, 6, 5) # 第一個卷積層,輸入通道數為3(RGB圖像),輸出通道數為6,卷積核大小為5x5self.pool = nn.MaxPool2d(2, 2) # 最大池化層,窗口大小為2x2self.conv2 = nn.Conv2d(6, 16, 5) # 第二個卷積層,輸入通道數為6,輸出通道數為16,卷積核大小為5x5self.fc1 = nn.Linear(16 * 59 * 59, 120) # 第一個全連接層,輸入維度為16*59*59,輸出維度為120self.fc2 = nn.Linear(120, 84) # 第二個全連接層,輸入維度為120,輸出維度為84self.fc3 = nn.Linear(84, dim_output) # 第三個全連接層,輸入維度為84,輸出維度為類別數def forward(self, x):x = self.pool(F.relu(self.conv1(x))) # 第一個卷積層后接ReLU激活函數和池化層x = self.pool(F.relu(self.conv2(x))) # 第二個卷積層后接ReLU激活函數和池化層x = torch.flatten(x, 1) # 展平操作,展平所有維度除了批量維度x = F.relu(self.fc1(x)) # 第一個全連接層后接ReLU激活函數x = F.relu(self.fc2(x)) # 第二個全連接層后接ReLU激活函數x = self.fc3(x) # 第三個全連接層return xmodel_ = Model(5) # 實例化模型,類別數為5summary(model_, (3, 250, 250)) # 打印模型結構和參數信息,輸入圖像尺寸為3x250x250
-
定義卷積神經網絡模型:
__init__方法中定義了兩個卷積層、兩個池化層和三個全連接層。conv1:第一個卷積層,輸入通道數為3,輸出通道數為6,卷積核大小為5x5。pool:最大池化層,窗口大小為2x2。conv2:第二個卷積層,輸入通道數為6,輸出通道數為16,卷積核大小為5x5。fc1:第一個全連接層,輸入維度為165959,輸出維度為120。fc2:第二個全連接層,輸入維度為120,輸出維度為84。fc3:第三個全連接層,輸入維度為84,輸出維度為類別數(即輸出維度)。
-
定義前向傳播:
forward方法定義了前向傳播過程。- 輸入圖像依次通過卷積層、激活函數、池化層、展平操作和全連接層。
- 最后輸出的結果用于分類任務。
-
實例化模型:
model_ = Model(5):實例化模型,類別數為5。
-
顯示模型結構和參數信息:
summary(model_, (3, 250, 250)):使用torchsummary顯示模型的結構和參數信息,輸入圖像尺寸為3x250x250。
代碼的作用:
這段代碼定義了一個用于圖像分類的卷積神經網絡模型,并顯示了模型的結構和參數信息。這有助于了解模型的層次結構和參數量,為后續的模型訓練和評估做準備。
定義損失函數和優化器,并訓練模型
# define a Loss function and optimizer for model_2
loss_fn = nn.CrossEntropyLoss()
optimizer = optim.Adam(model_.parameters(), lr=0.001)# train model_
history_2, best_model_weights_2 = train(model_, train_loader, val_loader,device, loss_fn, optimizer, num_epochs=5, patience=5)
?模型可視化評估
size_histories = {}# 存儲訓練結果
size_histories['Model_'] = {'history': history_2, 'weights': best_model_weights_2}# 繪制模型在每個訓練輪次的準確率和損失圖
plot_comparision_result(size_histories['Model_'])# 檢查混淆矩陣進行錯誤分析
y_true, y_pred = get_ture_and_pred_labels(val_loader, model_)print(classification_report(y_true, y_pred), '\n\n')
cm = confusion_matrix(y_true, y_pred)classes = {"Arborio": 0,"Basmati": 1,"Ipsala": 2,"Jasmine": 3,"Karacadag": 4,
}plot_confusion_matrix(cm, classes, title='Confusion matrix', cmap=plt.cm.Blues)
-
存儲訓練結果:
- 初始化一個字典
size_histories用于存儲不同模型的訓練結果。 - 將
Model_模型的訓練歷史記錄和最佳模型權重存儲在size_histories['Model_']中。
- 初始化一個字典
-
繪制模型的準確率和損失圖:
- 調用
plot_comparision_result函數,繪制模型在每個訓練輪次的準確率和損失圖。該函數將繪制訓練集和驗證集的準確率和損失隨訓練輪次變化的對比圖,以便直觀地評估模型的性能。
- 調用
-
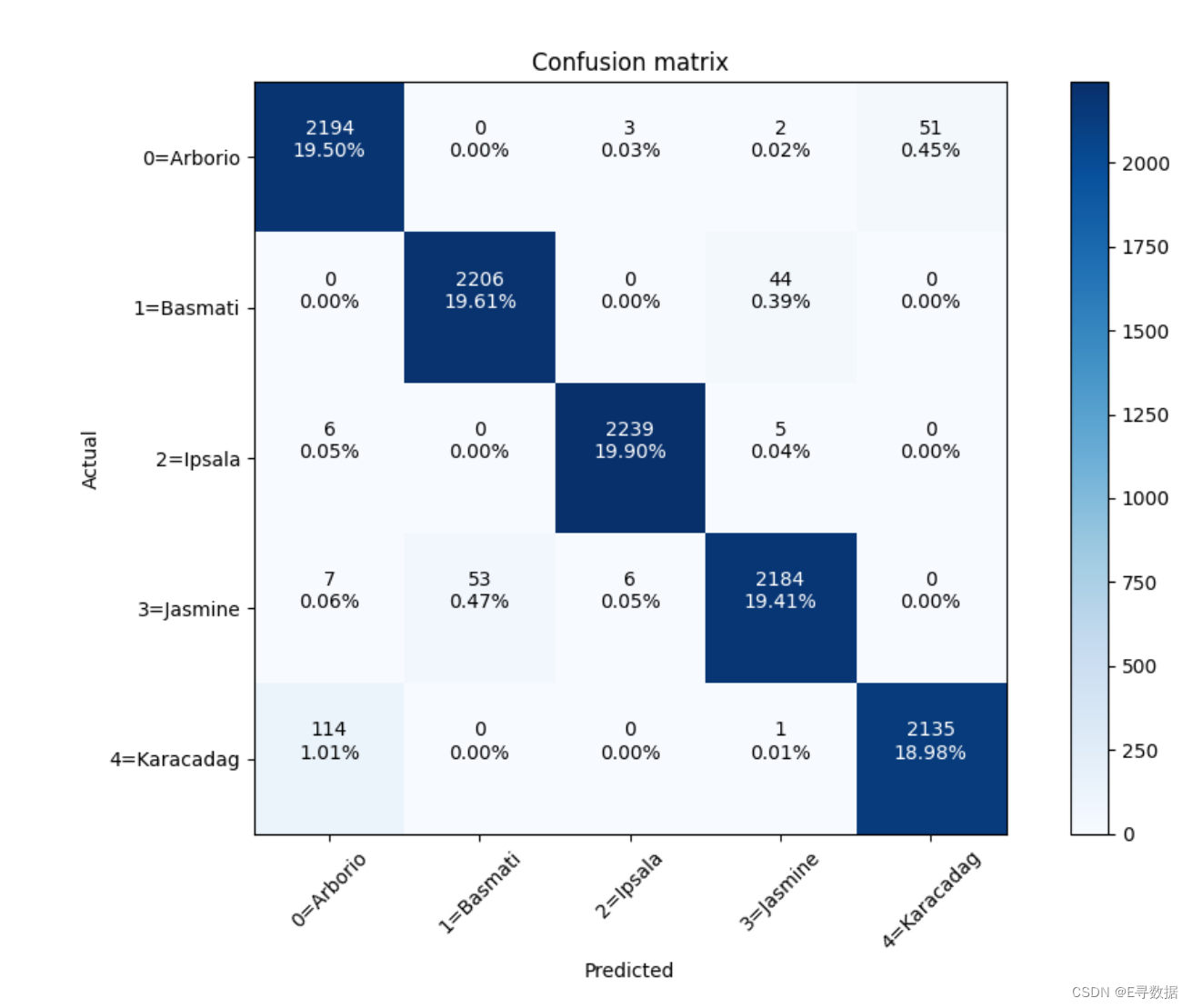
檢查混淆矩陣進行錯誤分析:
- 使用
get_ture_and_pred_labels函數獲取驗證集中真實標簽和預測標簽的列表y_true和y_pred。 - 打印分類報告
classification_report(y_true, y_pred),顯示每個類別的精度、召回率和F1分數。 - 計算混淆矩陣
cm,顯示模型在驗證集上的分類錯誤情況。 - 定義類別名稱和對應的數值標簽字典
classes。 - 調用
plot_confusion_matrix函數,繪制混淆矩陣圖,顯示各類別的分類結果。
- 使用
代碼的作用:
這段代碼將模型的訓練結果進行存儲,并通過繪制準確率和損失圖幫助評估模型在訓練過程中的表現。通過分類報告和混淆矩陣,可以詳細分析模型在驗證集上的分類效果,識別模型在不同類別上的分類準確性以及存在的錯誤,從而為模型的優化提供依據。這種詳細的錯誤分析對于提高模型的性能和泛化能力具有重要意義。

 ?
?
?


:電容觸摸按鍵實驗)


:私有繼承和受保護的繼承)





)


)




