1.介紹
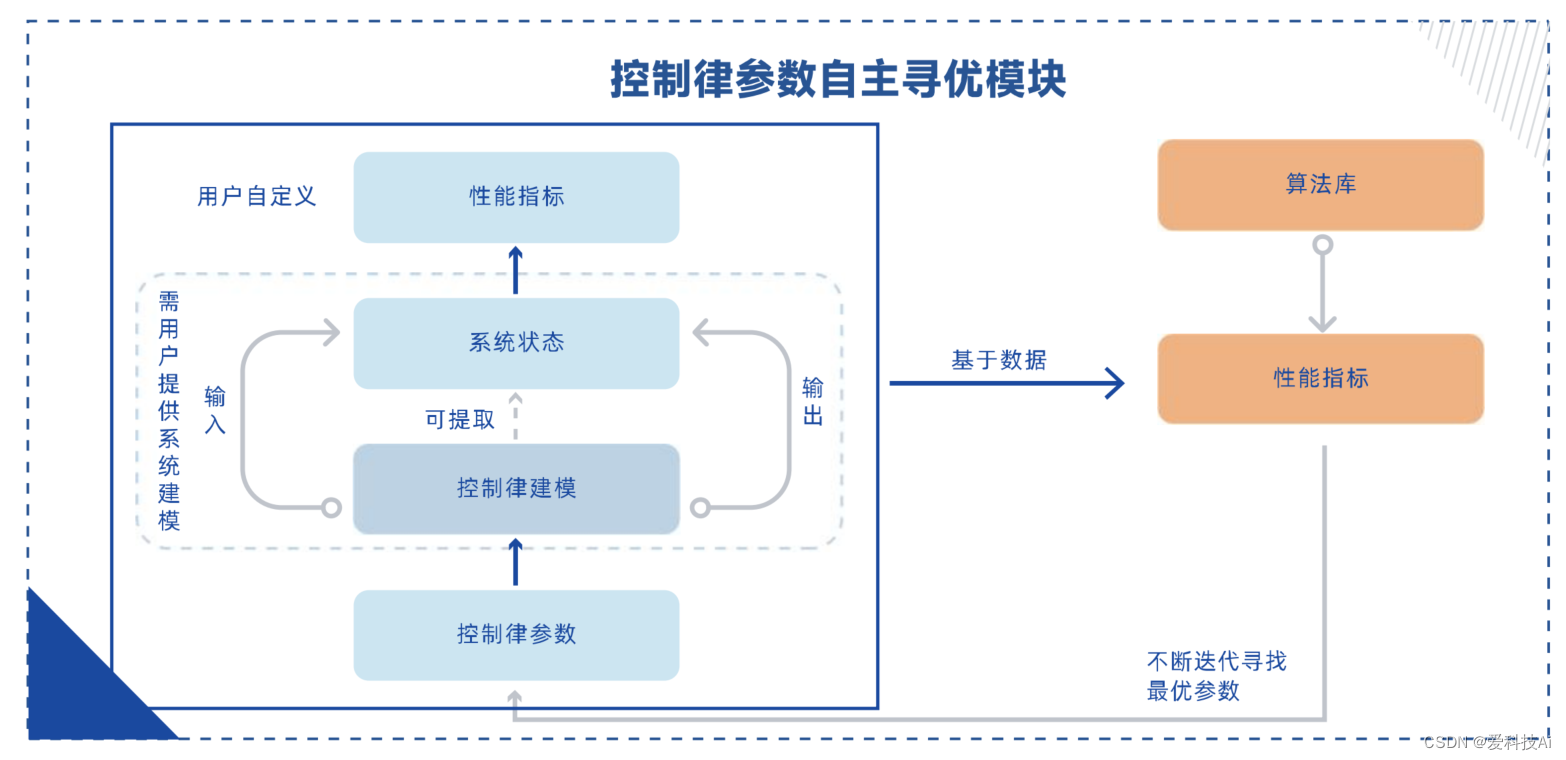
針對控制建模與設計場景中控制參數難以確定的普遍問題,提出了一種基于強化學習的控制律參數自主優化解決方案。該方案以客戶設計的控制律模型為基礎,根據自定義的控制性能指標,自主搜索并確定最優的、可狀態依賴的控制參數組合。
可用于各類飛行器、機器人等類的控制系統優化。無論是經典的PID控制,還是其他先進的控制方法,該模塊都能提供一種通用的參數優化方案。通過與控制律參數自主優化模塊的結合,工程師們將獲得更多的精力用于控制策略的設計和算法的創新,而將繁瑣的參數調試工作交給智能化優化系統完成。
2.應用場景
面向復雜系統的控制建模與控制律設計研發場景,適用于需要頻繁進行控制律設計、控制律調整、控制參數調整的研發場景,包括各類機器人設計(機械臂、機械狗、特殊結構如水上水下機器人、擬人機器人等)、各類飛行器設計(固定翼、四旋翼、航天器等)、其他機械設施(汽車、發動機等)。
3.參考示例-基于強化學習的PID參數整定
在控制系統控制器性能分析中,系統階躍響應對應的超調量、上升時間、調節時間等動態性能指標是關于控制器參數矢量 X 的非線性函數,評價控制器設計優劣的關鍵性因素。
結合強化學習理論和控制理論知識,設計一種基于強化學習(reinforcement learning, RL)的控制器參數自整定及優化算法。算法將控制參數矢量 X作為智能體的動作,控制系統的響應結果作為狀態,引入動態性能指標計算獎勵函數,通過在線學習周期性階躍響應數據、梯度更新控制器參數的方式改變控制器的控制策略,直至滿足優化目標,實現參數的自整定及優化。算法原理如下圖所示。
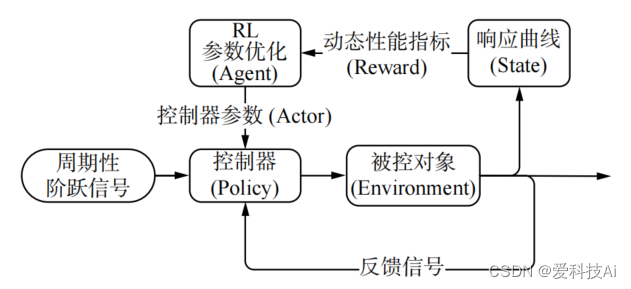
根據原理圖,參數自整定及優化算法將控制器參數整定問題定義為,求解滿足下列不等式約束條件的可行解:
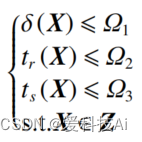
式中: Z為待優化的參數矢量X的取值范圍;Ωi?(i=1,2,3) 為優化目標的約束值。基于控制系統動態性能指標超調量 δ、上升時間 tr、調節時間 ts,算法定義獎勵函數為
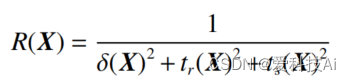
算法的參數整定及優化流程如下:
- 根據實際條件和需求設定優化目標 Ωi和參數 X的搜索范圍 Z,隨機初始化參數 X;
- 返回步驟 2),重復上述步驟。
- 利用梯度下降法更新參數;X=X+α??X+σ,其中 σ為高斯白噪聲,α為自適應學習率;
- 計算 m個樣本的參數平均梯度 ?X;
- 從經驗回放集 S 中隨機批量抽取 m 個經驗樣本,將 2) 中數據存入經驗回放集 S;
- 獲得系統在參數 X下的周期階躍響應數據,計算動態性能指標 δ、tr 、ts和獎勵函數 R;若滿足優化目標,則終止迭代,輸出參數 X;
為了盡可能獲得全局最優的參數,參數自整定及優化算法在更新參數的過程中引入高斯白噪聲,增加參數的探索度。同時,算法利用經驗回放技術,對過去的經驗樣本進行隨機批量抽樣,減弱經驗數據的相關性和不平穩分布的影響,增加優化過程的準確性和收斂速度。實踐試驗中,為避免算法陷入局部死循環,當可行解的變異系數小于一定閾值時,即認為算法已獲得局部收斂(近似全局)的相對最優解,保留當前結果并重新搜索。
案例參考自:







)

)

![錯誤 0x80070570:文件或目錄損壞且無法讀取/無法訪問[拒絕訪問]-解決方法](http://pic.xiahunao.cn/錯誤 0x80070570:文件或目錄損壞且無法讀取/無法訪問[拒絕訪問]-解決方法)





粒子繼承貼圖顏色發射)

)