1.簡介
本周主要任務是自行查找文獻,針對源代碼進行性能提升,主要包括三個方面:
- 預處理:分詞、關鍵詞提取、詞向量生成;
- 文本分析:從多個關鍵詞的詞向量,如何到一句話的語義理解;問題分類;
- 相似問題匹配:檢索到相似問答對,并對候選答案進行排序。
針對上面三個方面,這一周主要是進行第三條:相似度匹配的性能提升。由于此次任務是在上次的代碼里進行性能提升,所以先進行上次代碼的回顧(具體補充在上一篇博客),再尋找性能提升的方法。
2. 算法回顧
上面三個方面的性能提升,可以在上一篇博客的數據處理圖里面體現。
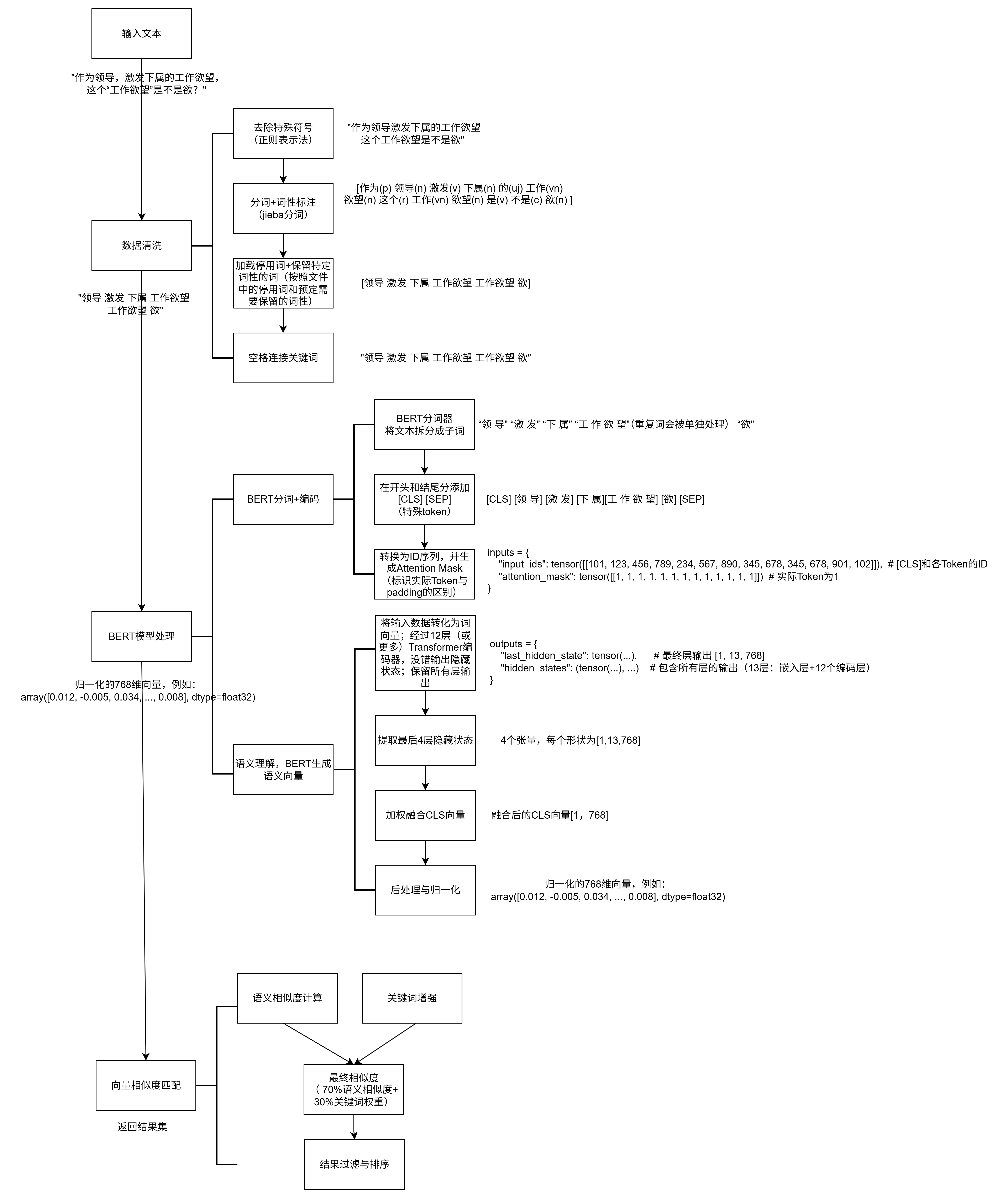
關于相似度匹配的問題,源代碼里主要是采用語義相似度和關鍵詞重疊的混合的相似度得到的,細節如下:
1. 向量準備階段
預計算(系統啟動時):
對庫中每個問題(如?
Q1: "Python怎么學?")生成768維歸一化向量,存儲為矩陣?question_vectors(形狀?[N, 768],N=問題數量)。(_prepare_vectors)不處理答案:相似度僅對比問題文本,答案僅作為最終返回內容。
實時計算(用戶搜索時):
對用戶查詢(如?
"學習Python的技巧")生成768維歸一化向量?query_vector(形狀?[768,])。(_get_embedding)2. 語義相似度計算
(1)計算原始相似度(余弦相似度):
計算公式:
操作步驟:
將?
query_vector?形狀轉為?[1, 768]。與?
question_vectors([N, 768])做矩陣乘法(點積)。輸出?
[1, N]?的相似度數組,每個元素表示用戶查詢與一個庫內問題的余弦相似度。數學展開:
????????其中:
????????????????simi=∑k=1768qk?Qi,ksimi?=∑k=1768?qk??Qi,k?(即余弦相似度)
(2)相似度校準(Sigmoid函數):非線性放大高相似度(>0.88)的結果
原始余弦相似度的范圍是?[?1,1],通過Sigmoid函數將其壓縮到?[0,1],并銳化差異:
作用:將相似度大于0.88的結果推向1,小于0.88的結果推向0,增強區分度。
- 參數選擇:k=25(陡峭度),x0=0.88(閾值) ? ??
(3) 混合相似度(原始+校準):保留20%原始相似度,80%校準后結果
????????
3. 關鍵詞重疊度
計算原理:
關鍵詞提取:
對用戶查詢和庫內問題,使用?
jieba?分詞,返回分詞后的詞語列表例如:
用戶查詢:
"如何快速學習Python"?→ 關鍵詞:{"學習", "Python"}庫內問題:
"怎樣高效掌握Python編程"?→ 關鍵詞:{"掌握", "Python", "編程"}重疊度計算:
?
分子:共有關鍵詞數量(如?
{"Python"}?→ 1個)。分母:用戶查詢的關鍵詞數量(防止除零)。
歸一化:
得分范圍天然在?[0,1][0,1]?之間,無需額外處理。
3. 混合相似度計算
- 最終相似度 = 70%語義相似度 + 30%關鍵詞權重
- 添加微小偏移(0.0266)避免零相似度
4. 結果過濾與排序
- 先將所有的最終結果集進行降序排序
- 四級過濾機制:
- 數量限制:確保不超過TOP-K(默認1000)
- 閾值過濾:丟棄相似度<0.6的結果(可配置)
- 內容去重:基于問題和答案前20字符的哈希值
- 語義去重:新結果與已有結果的相似度>0.93時跳過
- 將過濾后的答案添加到結果列表
- 結果保障機制:確保始終返回足夠數量的結果(即使部分結果相似度較低),避免因嚴格過濾導致空結果
- 最終結果嚴格按相似度降序排列
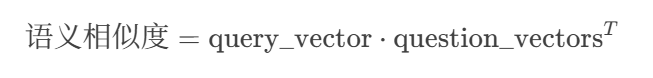

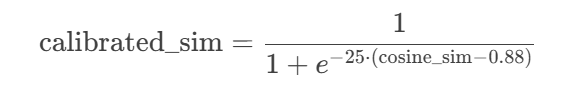
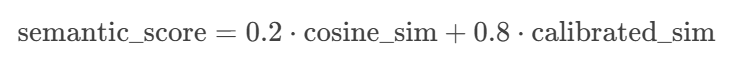
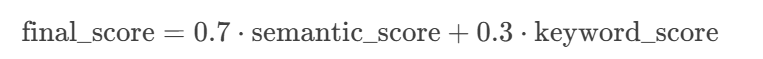
3. 性能提升
3.1?《基于深度學習的水稻知識智能問答系統理論與方法研究》
關于相似度匹配的性能提升,我主要是重新看了之前發過的《基于深度學習的水稻知識智能問答系統理論與方法研究》這一篇論文,這里面的第4章提到了相似度匹配的方法,第5章提到了關于排序的方法。
3.1.1 關于相似度匹配--DenseBiGRU 和協同注意力機制、交互分類層
與傳統深度學習模型相比,首先本文使用 12 層 Transformer 的中文 BERT 預訓練模型得到問句特征向量化表示;其次本文提出的模型利用 DenseBiGRU 和協同注意力機制提取文本不同粒度的局部特征;最后將提取的特征向量輸入到交互分類層(Wang et al.,2021)。模型架構圖如下:
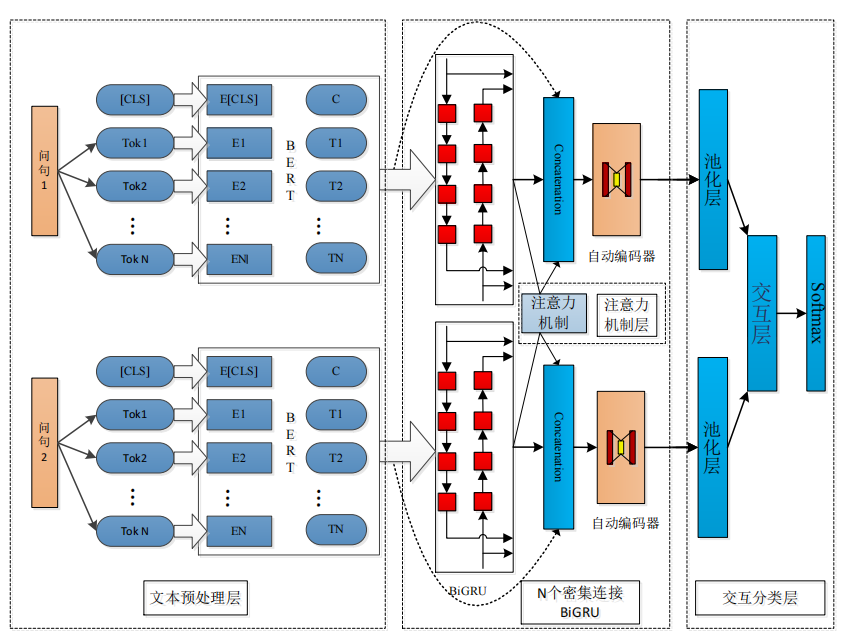
流程:BERT詞向量 → DenseBiGRU多層次編碼 → 協同注意力交互 → 池化聚合 → 全連接分類。
經過BERT生成詞向量后,進入相似度匹配主要包括以下流程:
(1)密集連接BiGRU(DenseBiGRU)特征提取
下面是一些有關概念介紹:
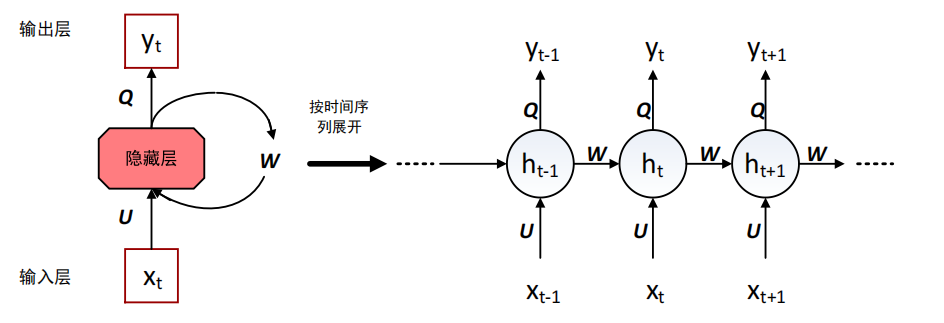
①RNN:循環神經網絡(RNN)是一種用于處理序列數據的神經網絡。RNN 會記住句子前面部分的特征信息,并利用這些特征信息來影響后續節點特征的輸出。RNN 隱藏層之間的節點是拼接在一起的,隱藏層的輸入不僅包括輸入層的輸出,還包括上一時刻隱藏層的輸出。如下圖所示:
②GRU:GRU是特殊的RNN,它引入重置門(Reset Gate)和更新門(Update Gate),解決RNN的長期依賴問題。
- 重置門:決定多少歷史信息參與候選狀態計算。
- 公式:?
rt取值0~1,0表示完全忽略歷史,1表示完全保留。
- 更新門:控制歷史信息保留量(控制歷史信息的當前輸入的權重)。公式如下:
- zt??取值0~1,接近1時保留更多歷史,接近0時傾向新信息。
③BiGRU(雙向GRU),包括:
前向GRU:從左到右處理序列?(x1→xT)(x1?→xT?)
反向GRU:從右到左處理序列?(xT→x1)(xT?→x1?)
保證可以同時捕捉前后文信息。
本文的模型采用了多層 BiGRU 堆疊在一起的結構并循環了 5 次,在每個密集連接的 BiGRU 層都將之前層的輸入和本層的輸出合并之后向后傳遞。
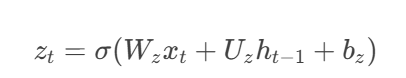
①預處理
輸入:BERT生成的詞向量序列(假設句子長度為N,每個詞768維,形狀為
[N, 768])。預處理:通過線性層將768維向量投影到更低維度(如100維),適配BiGRU的輸入尺寸。
②雙向GRU(BiGRU)
前向GRU:從左到右處理序列,每個時間步
t的隱藏狀態依賴前一時間步t-1。后向GRU:從右到左處理序列,隱藏狀態依賴
t+1。輸出拼接:
若單GRU隱藏單元為100維,BiGRU輸出為[前向100維; 后向100維] = 200維。
????????公式:
????????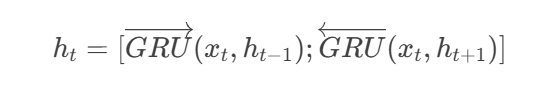
③密集連接(Dense Connection)
輸入來源:
第l層BiGRU的輸入 = 拼接所有前面層的輸出:[H^{l-1}; H^{l-2}; ...; H^0]。例如,若第1層輸出
H^1為[N, 200],第2層輸入為[N, 200 + 200](假設僅兩層)。
數學表達:
????????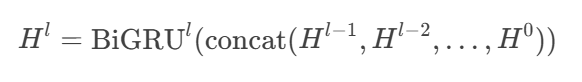
最終輸出:經過5層BiGRU后,每時間步輸出為
[N, 200](假設每層隱藏單元數不變)。
(2)協同注意力機制(Co-attention)
以下是概念介紹:
注意力機制:學習上下文向量在特定序列上匹配的技術。給定 2 個問句,即在每個 BiGRU 層基于協同注意力機制的 2 句話,計算上下文向量。計算出的注意信息值代表了兩句話之間的對齊關系。
本文使用連接操作將注意力機制對 2 個問句交互的信息合并到密集連接的重復特征中。
輸入
輸入:兩個問句P和Q的BiGRU輸出(形狀均為
[N, 200],N為詞數,200為BiGRU隱藏層維度)。
交互對齊步驟如下:
①相似度矩陣計算:
計算問句P的第
i個詞與問句Q的第j個詞的余弦相似度:
????????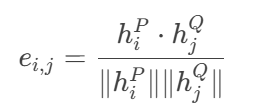
輸出矩陣
E形狀為[N, N],表示所有詞對的相似度。ei ,j ?代表 2 個問句向量的相似度,hpi、hqi 代表問句向量表示。
②注意力權重歸一化:
對矩陣
E的行和列分別做Softmax,得到權重矩陣α:
????????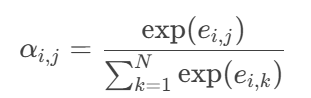
α_{i,j}表示P的第i個詞對Q的第j個詞的關注程度,αi ,j , 代表注意力權重。
③上下文向量生成:
對問句P的每個詞
h_i^P,用權重α_{i,j}加權求和Q的所有詞向量:
????????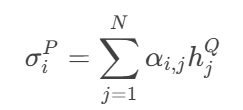
- 輸出:
σ^P形狀與h^P相同([N, 200]),表示P的詞在Q中的語義對齊結果。
④特征增強:
將原始BiGRU輸出
h^P與上下文向量σ^P拼接,得到[h^P; σ^P]([N, 400])。
輸出與傳遞
下一層輸入:拼接后的
[N, 400]向量作為下一BiGRU層的輸入(繼續密集連接,和BiGRU 隱藏特征類似,一共5層)。BiGRU的輸出給交互層維度恢復為
[N, 200]。
(3)交互分類層
輸入
輸入:經過所有BiGRU和注意力層后的兩個問句特征(形狀
[N, 200])。
池化操作
最大池化:沿時間步(詞序列)維度取最大值,得到句子級向量:
輸入
[N, 200]?→ 輸出[200](每個維度保留最顯著特征)。
作用
壓縮變長序列為固定長度,聚焦關鍵語義(如“病蟲害防治”中的“防治”被保留)。
減少噪聲詞影響(如停用詞“的”通常不會被池化選中)。
特征聚合
合并兩個問句的池化向量
p和q:
????????![]()
??p-q:捕捉差異特征(如“水稻”vs“小麥”的種植差異)。|p-q|:強化非線性差異(類似曼哈頓距離)。輸出
v維度為[800](假設p和q各200維)。
作用:顯式編碼相似性和差異性,提升分類器決策邊界清晰度。
全連接分類
第一層全連接:
輸入
[800]?→ 輸出[1000](ReLU激活)。作用:非線性變換,學習高階交互特征。
第二層全連接:
輸入
[1000]?→ 輸出[2](對應相似/不相似兩類)。
Softmax:
輸出概率分布,如
[0.92, 0.08]表示92%概率相似。
監督信號:交叉熵損失函數反向傳播優化模型參數。
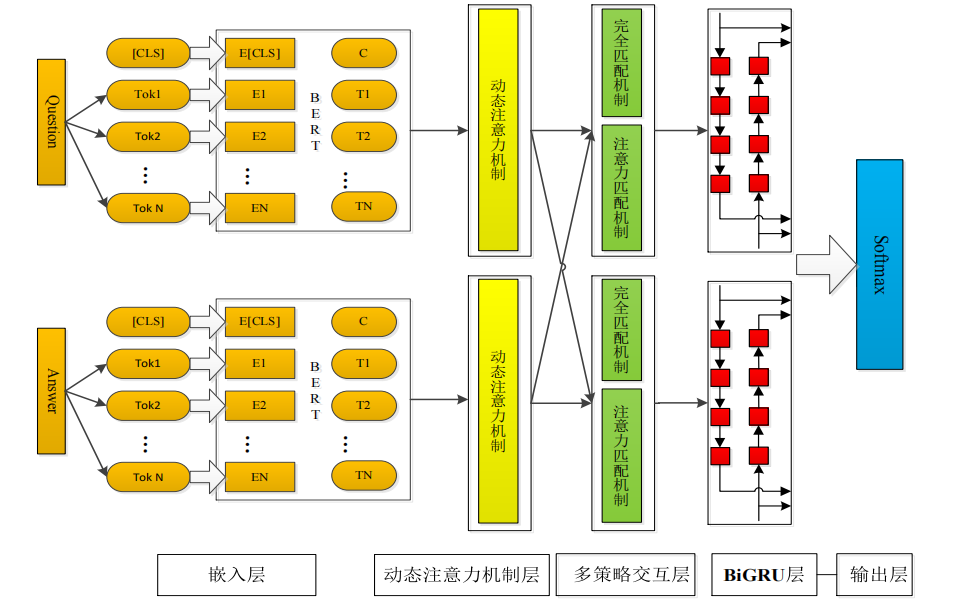
3.1.2 關于答案優化+排序--動態注意力機制和多匹配策略的 BiGRU 答案選擇模型
模型結構圖:
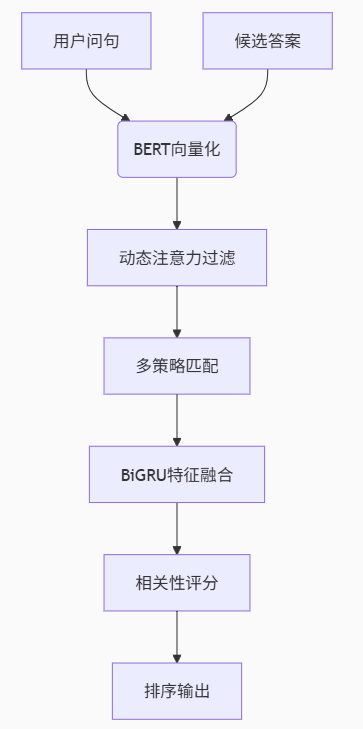
流程圖:
細節:
(1)文本向量化(BERT編碼)
輸入:用戶問句+候選答案(問答對里的答案,不再關注問題)
處理:
使用12層中文BERT模型對問句和答案分別編碼:每個詞生成768維向量(
[CLS]向量作為句子整體表示)。最大序列長度為128,超出部分截斷。輸出形狀:問句
[N_q, 768],答案[N_a, 768](N為詞數)。
(2)動態注意力過濾(過濾文本特征信息的無用信息)
輸入:BERT輸出的問句和答案詞向量。
計算步驟:
計算詞級相似度矩陣:余弦相似度

Softmax歸一化:
問句對答案的注意力權重:
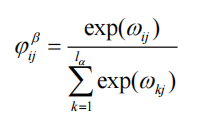
答案對問句的注意力權重:
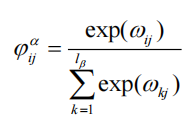
動態過濾:
保留權重Top-K的詞(如
"紋枯病"對"井岡霉素"權重0.85保留(權重高)),其余置零。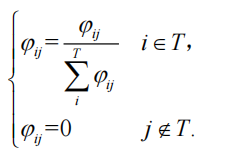
輸出:過濾后的問句向量(
[n詞 × 768])和答案向量([N詞?× 768])。作用:提升關鍵信息的權重,減少無關詞干擾。
(3)多策略匹配交互
輸入:動態注意力過濾后的問句和答案向量。
匹配策略:
① 完全匹配(Full-Matching):計算問句每個詞與答案整體向量的余弦相似度:
例如:
"紋枯病"與答案整體相似度=0.7 → 特征向量部分值[..., 0.7, ...]
② 注意力匹配(Attentive-Matching):問句詞
α_i對答案詞的注意力加權和: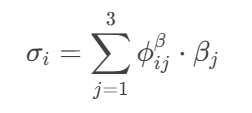
- 計算
α_i與σ_i的相似度: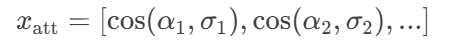
例如:
"防治"與加權答案向量σ_i相似度=0.8 → 特征向量部分值[..., 0.8, ...]
輸出:
每個策略生成4個特征向量(如[x_full, x_att]),拼接后為[N, 1600](假設每策略400維)。
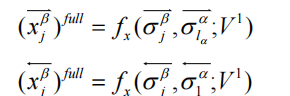
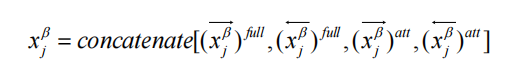
作用:
增強模型對同義表述(如“防治” vs “治療”)和隱含關聯的捕捉能力。
(4)BiGRU特征融合
輸入:多策略匹配后的特征(
[N, 1600])。處理:
雙向GRU分別處理正向和反向序列:
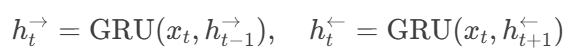
參數示例:
GRU隱藏單元:200(雙向拼接為400維)。
輸出取最后時間步:
[h^{\rightarrow}; h^{\leftarrow}]
輸出:問答對綜合特征向量(
[400])。作用:捕捉特征間的時序依賴,例如:
"噴施"動作需在"井岡霉素"之前才合理。
(5)相關性評分與排序
輸入:BiGRU輸出的特征向量。
處理:
全連接層計算得分:
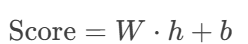
Softmax歸一化為概率:
[0.92, 0.05, 0.03](對應3個候選答案)。Softmax歸一化的核心目的是將模型的原始輸出分數(logits)轉化為概率分布,使得所有候選答案的得分滿足以下條件:
概率和為1:所有答案的分數歸一化為[0,1]之間的值,且總和為1(如0.92+0.05+0.03=1)。
可比性:通過指數函數放大高分項的差距,便于區分最相關答案(如0.92遠高于0.05)。
輸出:按概率降序排序的答案列表。
作用:實現自動化答案推薦,Top-1答案直接返回給用戶。
3.2 《使用分層可導航小世界圖進行高效、穩健的近似最近鄰搜索》
關于相似度匹配,我找了另一篇論文(
《Efficient and robust approximate nearest neighbor search using Hierarchical Navigable Small World graphs》),該論文提出了一種名為“分層可導航小世界圖”(HNSW)的方法,用于解決近似K近鄰搜索(K-ANNS)問題。
該方法犧牲了一些精確度,但是可以在大量的數據集里迅速找到答案。
以下是一些介紹:
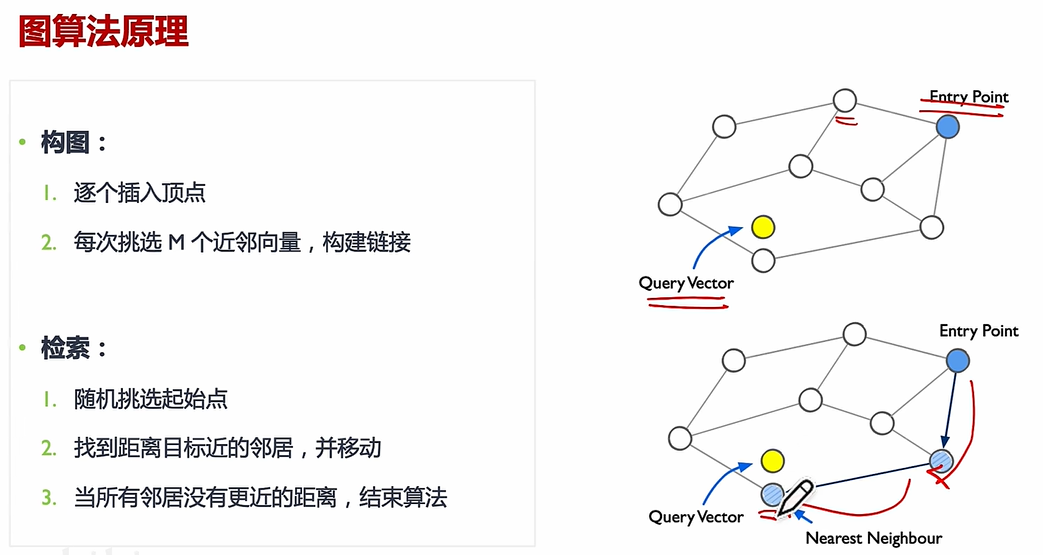
(1)圖算法原理:
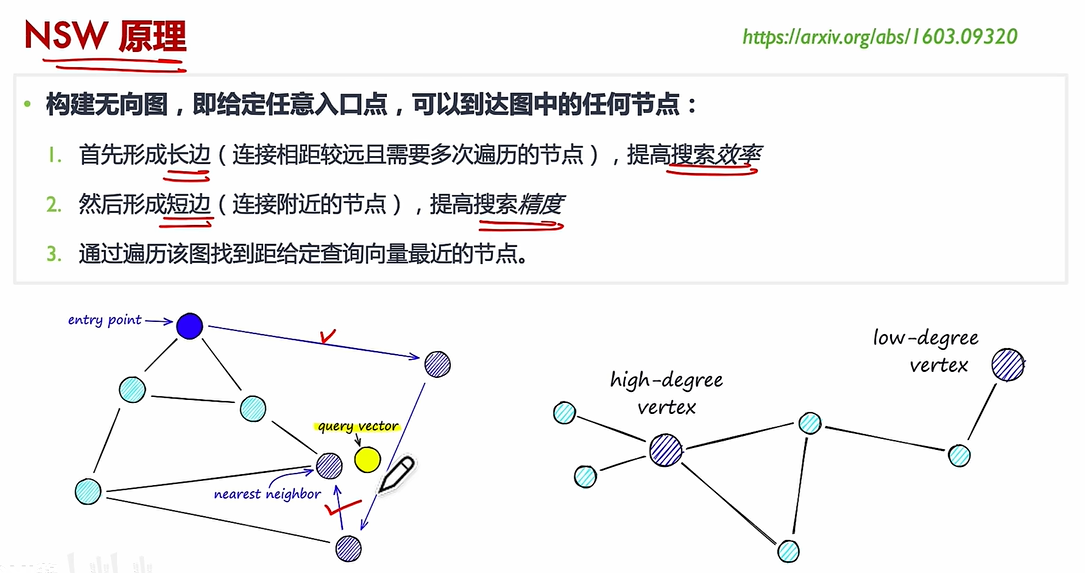
(2)NSW:
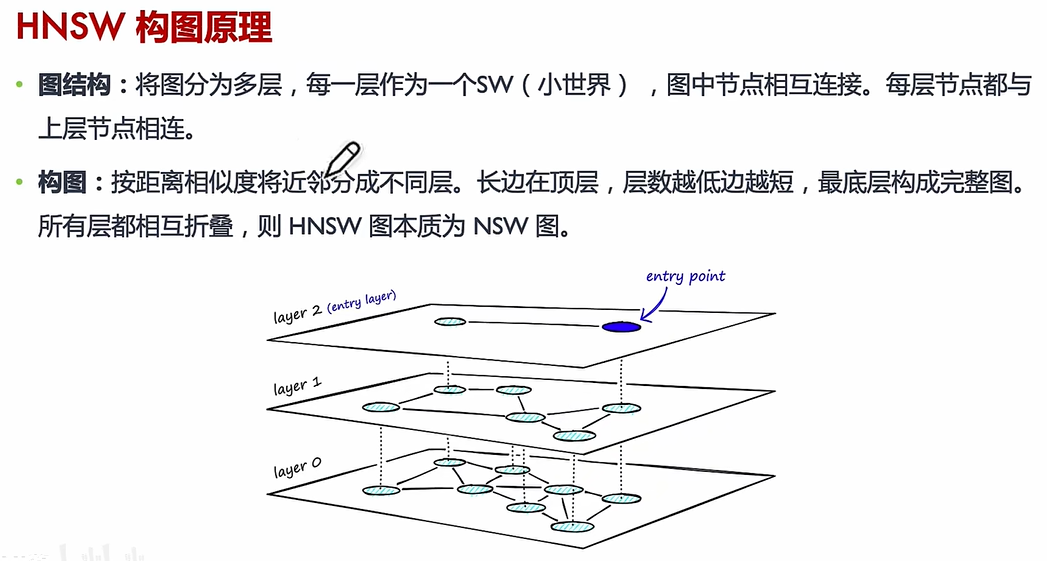
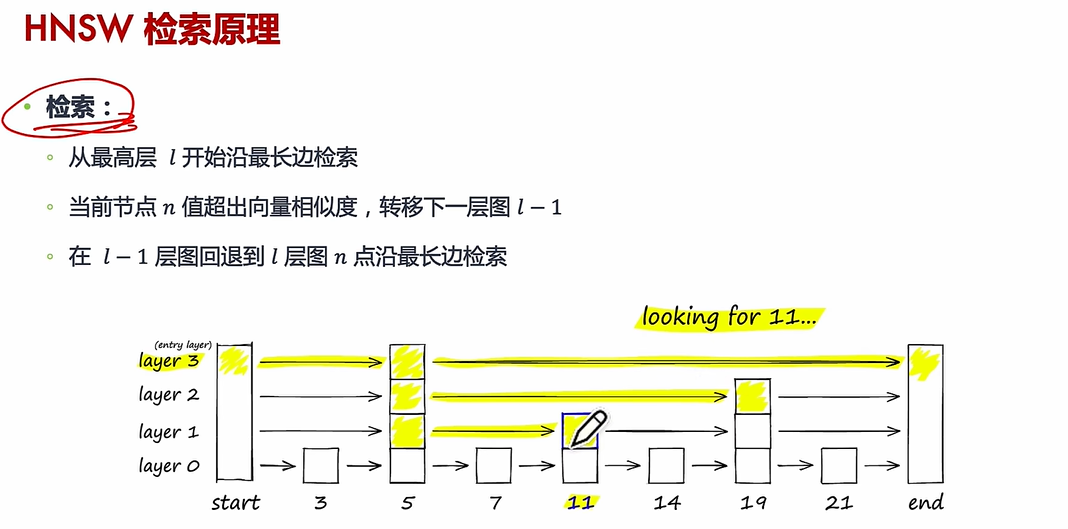
(3)HNSW
核心思想:HNSW 通過構建多層圖結構,將數據點按距離分層組織,高層保留“遠距離”連接(全局結構),低層保留“近距離”連接(局部細節)。
搜索過程:給定一個查詢點,算法從頂層開始逐步向下層搜索,利用貪心策略快速定位最近鄰,最終在底層返回最相似的候選結果。
相似度度量:支持任意可計算的距離函數(如歐氏距離、余弦相似度、Jaccard 相似度等),因此適用于多種相似度匹配任務。
所以如果采用HNSW在相似度計算上并沒有改變,只是改變了候選集的檢索。所以下面是如果采用HNSW的話,在源代碼里需要做的修改:
(1)初始化階段
在
QASystem類初始化時,增加HNSW索引的構建:加載所有問答對的BERT向量后,用這些向量初始化HNSW圖結構
設置參數:每層連接數(
M)、構建時的候選規模(ef_construction)
分層圖結構:
- 高層(稀疏連接):存儲遠距離的“導航邊”,用于快速定位大致區域
- 底層(密集連接):存儲近距離的“細節邊”,用于精確搜索
向量映射表:
- 每個節點(對應一個問答對)關聯其原始BERT向量,用于后續相似度計算
(2)搜索邏輯改造
替換原有的暴力相似度計算(
np.dot全量計算):調用HNSW的
knn_query接口,傳入查詢向量和需要的TopK數量直接獲取候選問題的索引和原始余弦相似度(與原有接口對齊)
1. 直接計算查詢向量與所有向量的相似度
# 偽代碼:原有暴力計算
query_vec = [0.1, 0.3, ...] # 查詢向量
all_vectors = [ # 所有問答對的BERT向量[0.2, 0.4, ...], # 問題0[0.5, 0.1, ...], # 問題1[0.1, 0.3, ...], # 問題2[0.9, 0.0, ...], # 問題3[0.4, 0.2, ...] # 問題4
]
# 全量計算余弦相似度
similarities = [np.dot(query_vec, vec) for vec in all_vectors]
# 排序后返回Top2
top_indices = [3, 0] # 假設問題3和問題0最相似
top_scores = [0.95, 0.88]2. 調用HNSW接口跳過全量計算
# 偽代碼:HNSW近似搜索
top_indices, top_scores = hnsw_index.knn_query(query_vec, k=2)
# 返回結果示例
top_indices = [3, 0] # 直接得到最相似的2個問題的索引
top_scores = [0.95, 0.88] # 對應的余弦相似度分數后續處理完全不變:
校準(Sigmoid)、關鍵詞加權、過濾去重等
(3)增量更新處理
當新增問答對時:
生成新問題的BERT向量后,同步調用HNSW的
add_items插入索引確保新數據可被后續搜索立即訪問
4. 總結
本周主要是對相似度匹配這一塊代碼進行性能提升。可以使用DenseBiGRU (提取多層次文本特征,保留關鍵信息。)和協同注意力機制(動態聚焦問答中相關的詞或短語,抑制噪聲。)、交互分類層(聚合交互特征,輸出匹配概率或排序結果)來從候選答案中快速、準確地識別或排序出最符合問句語義的答案;可以使用動態注意力機制和多匹配策略的 BiGRU 答案選擇模型對候選答案進行精準排序,確保最匹配答案排名靠前;關于HNSW可以使得當有大量數據集時,可以保證快速的搜索到答案。










:字符串操作與多維指針深度解析》)
)
)






和分布式集合(IgniteSet)的介紹)