1. MoE 簡介
MoE(Mixed Expert Models),混合專家模型。在 Transformer 的 FFN 中,有一個重要的觀察是,其計算過程中的神經元激活是非常稀疏的,在一次計算中只有 90%的輸入激活不到 5%的神經元,省略計算未激活的神經元就可以大大降低冗余計算。因此,通過訓練可以將相關神經元有效組織在一起,這樣就形成了 MoE 整體框架,它是一個整體參數較大,而推理時參數規模較小的模型。
1.1 密集模型與稀疏模型
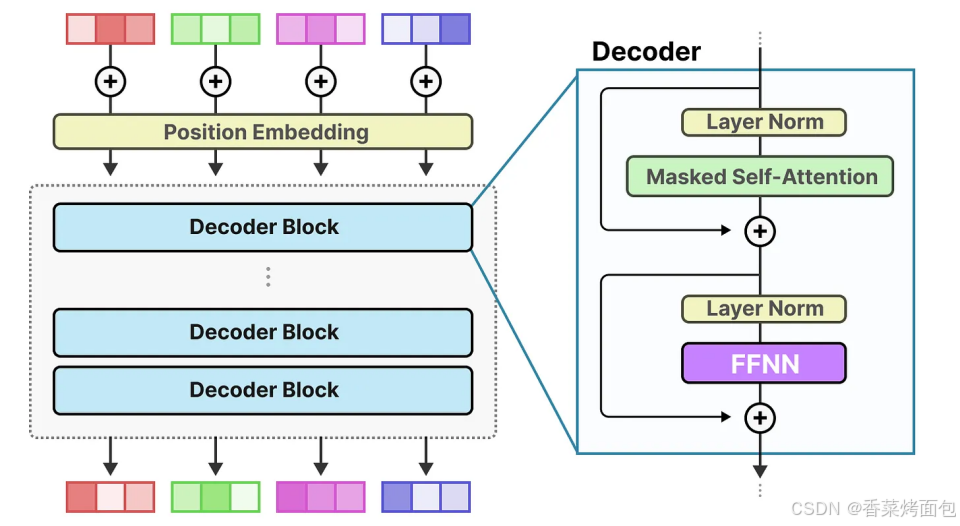
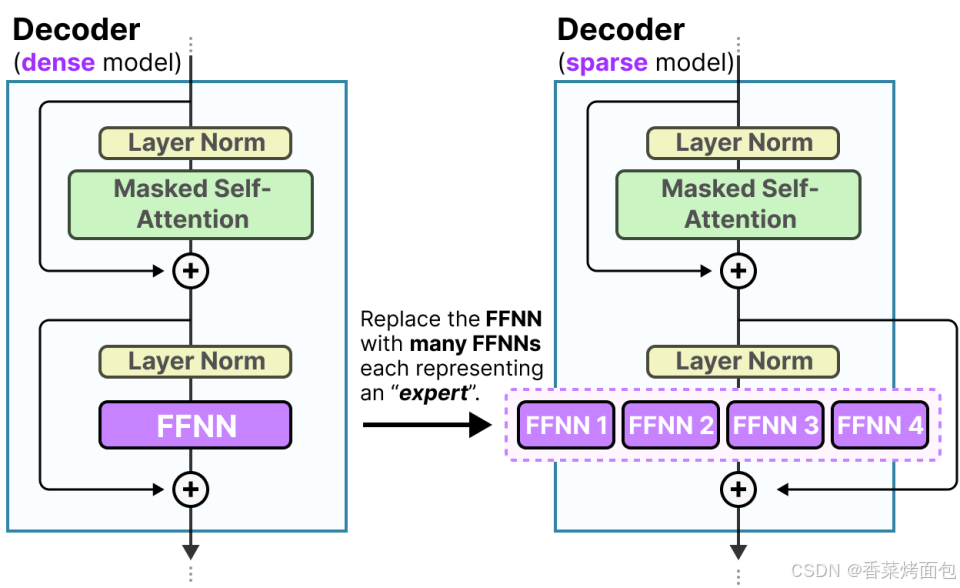
密集模型一般指 Transformer 模型中密集的前饋神經網絡 (Feedforward Neural Network, FFNN) ,下圖為標準的 decoder-only Transformer 模型中 FFNN
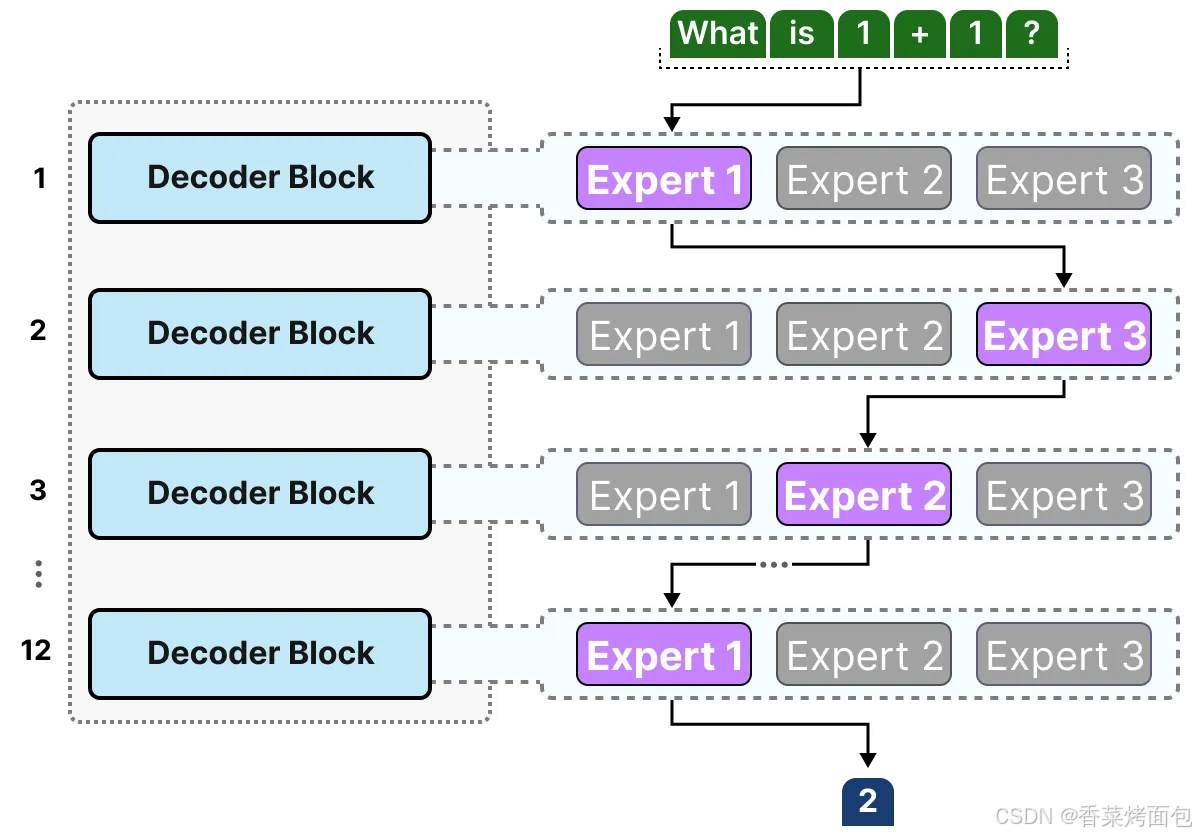
- 整體 Decoder-only Transformer 結構(圖一):每個輸入 token 會被轉換為一個向量(embedding),并加上位置編碼,Decoder Blocks 通常是堆疊的 Transformer 層,每個 decoder block 都包括:Masked Self-Attention 掩碼自注意力、LayerNorm 歸一化層、FFNN
- Encoder 使用標準 Self-Attention 編碼時需要全局上下文信息,Decoder 解碼時按 token 順序生成,不能看到“未來”token,在計算權重時屏蔽掉當前 token 之后的位置
- 每一層 decoder block 有兩個子層(圖二):Masked Self-Attention,通過 attention 機制捕捉 token 間的依賴關系,加入 LayerNorm + 殘差連接(Residual);FFNN 子層也是在 LayerNorm 和殘差連接后使用,輸入是一個長度為 512 的embedding,所有連接都是 密集的,即每個輸入維度都連接到每個輸出神經元
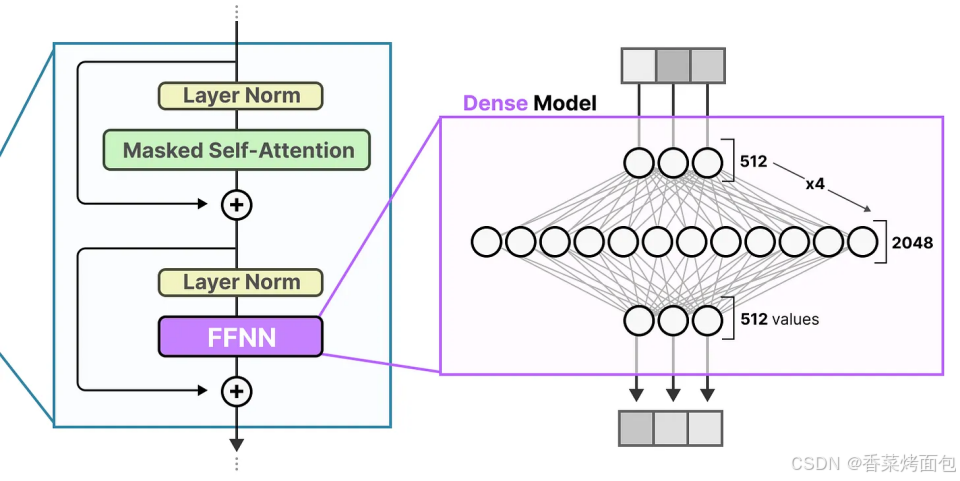
- Dense FFNN 是 Transformer block 中計算最重的部分之一
- 所謂 “密集模型” 指的是:所有 token 的每層 FFNN 都計算完整網絡,所有參數(包括權重和偏置項)都會被激活,所有參數都被用于計算輸出,不跳過任何部分
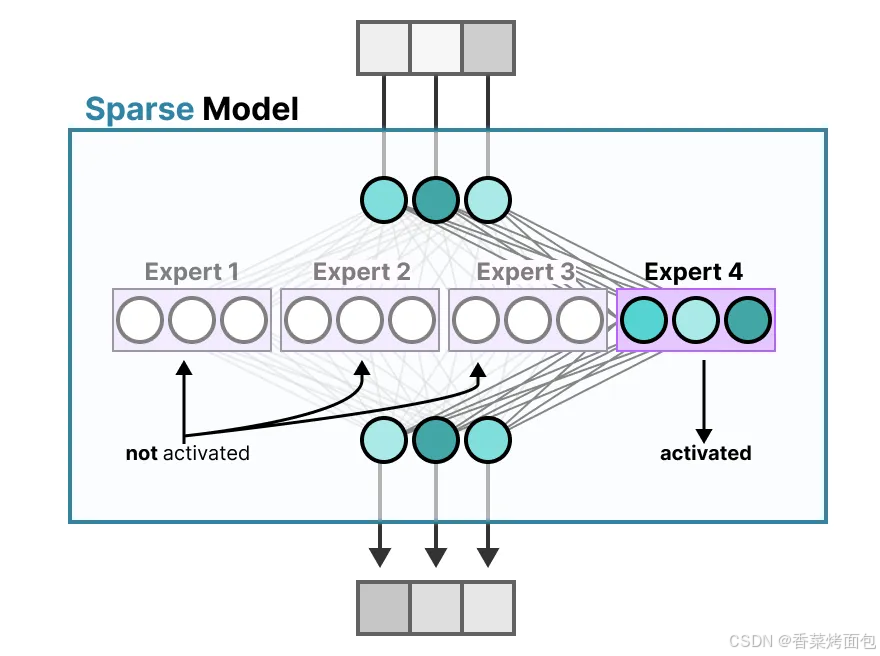
- 相比之下,MoE 模型 會將 FFNN 替換成多個“專家”,并且只激活其中一部分,從而提升參數規模但保持計算量不變(稀疏激活)
稀疏模型(Sparse Models)僅激活總參數中的一部分,可以將密集模型分解為多個部分(稱為專家):
- 其核心思想是,每個專家在訓練過程中學習不同的信息。而在推理時,僅使用與當前任務最相關的特定專家
- MoE 有兩種類型:稀疏專家混合模型(Sparse Mixture of Experts)和密集專家混合模型(Dense Mixture of Experts),兩者都使用路由器來選擇專家,但稀疏 MoE 只選擇少數幾個專家,而密集 MoE 則選擇全部專家,但可能會以不同的分布進行選擇。
- 目前的 LLM 中 MoE 通常指的是稀疏 MoE,MoE 的一個顯著優勢是能夠在遠少于 Dense 模型所需的計算資源下進行有效的預訓練。這意味著在相同的計算預算條件下,可以顯著擴大模型或數據集的規模。特別是在預訓練階段,與稠密模型相比,混合專家模型通常能夠更快地達到相同的質量水平
稠密和稀疏模型小結:以人類分工為例,稠密就是類似手工業時代的生產模式,在這種模式下,每個工人(即神經元)都需要參與處理所有類型的任務,就像手工業時代的工匠需要精通產品制作的各個環節,掌握所有的生產技能,這種方法雖然直觀且易于實現,但在面對復雜多變的任務時,往往效率低下且難以擴展;稀疏 MoE 則是工業革命之后的分工模式:每個崗位(專家)只需要完成一部分生產任務,這種分工的方式大大提高了生產效率
1.2 MoE 架構
MoE 基于 Transformer 架構,主要由兩部分組成:
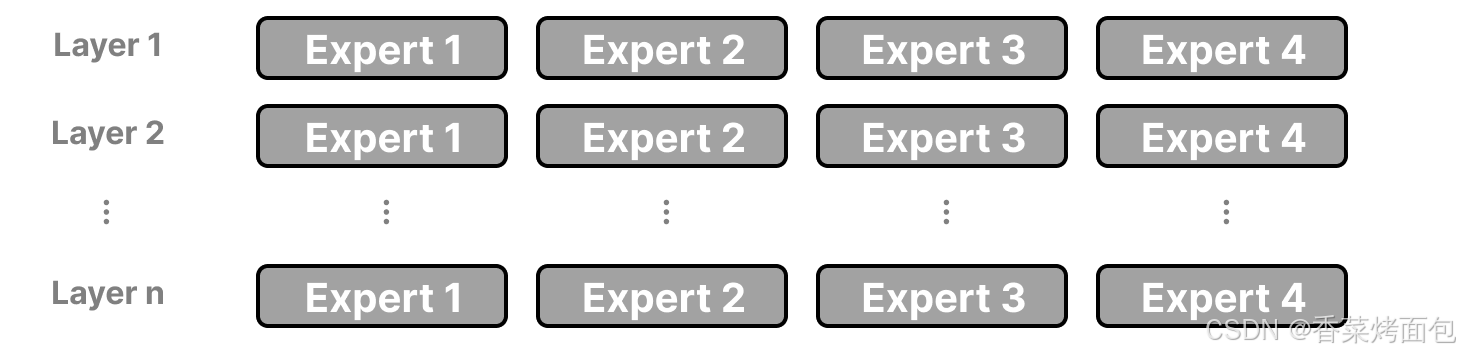
- 稀疏 MoE 層:這些層代替了傳統 Transformer 模型中密集的前饋網絡 (FFN) 層,每個 MoE 層包含一定數量的 expert,每個 expert 都是一個神經網絡,每次只有其中部分 expert 參與計算。從這個角度看,整體上的計算是稀疏的,例如 DeepSeek V3 的 expert 總數為 256,推理 expert 數為 8 個。
- DeepSeek‐V3 的 MoE 模塊中,主要包含兩類專家:
- 路由專家(Routed Experts):每個 MoE 層包含 256 個路由專家,這些專家主要負責處理輸入中某些特定、專業化的特征
- 共享專家(Shared Expert):每個 MoE 層中還有 1 個共享專家,用于捕捉通用的、全局性的知識,為所有輸入提供基本的特征提取支持
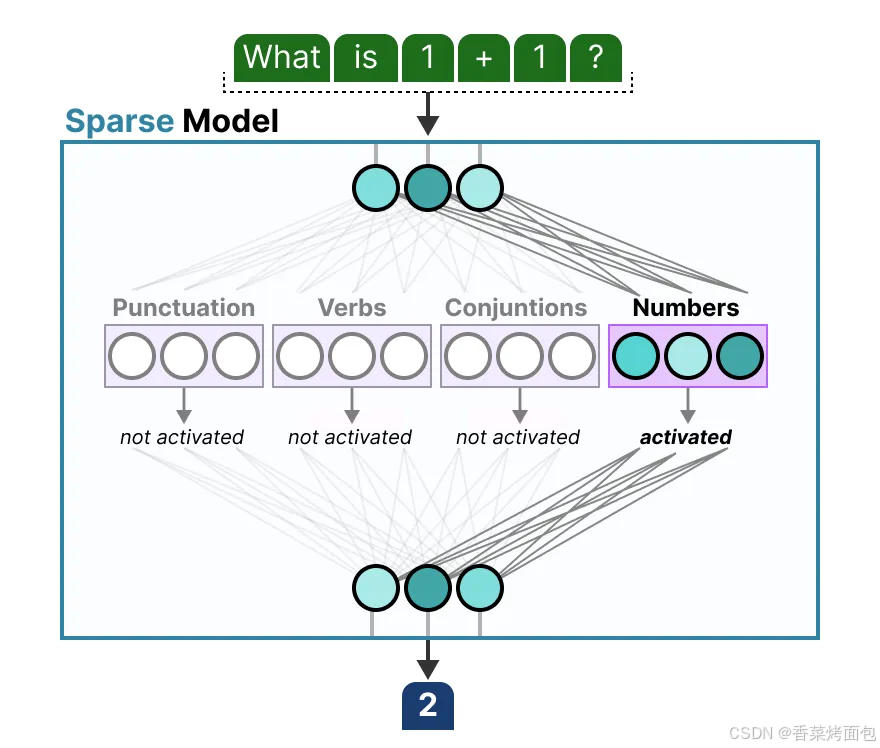
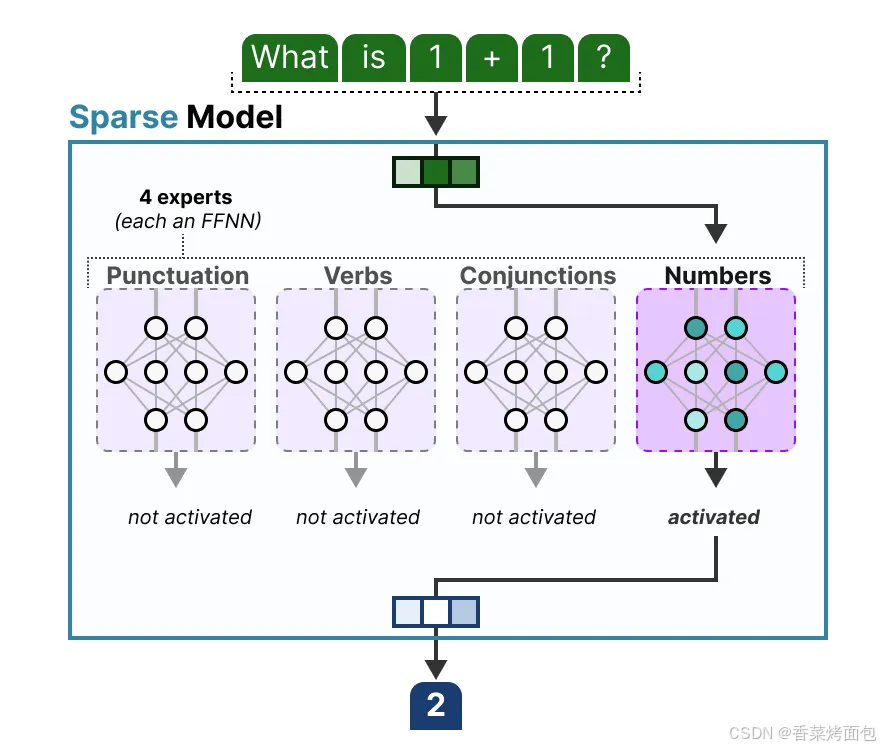
- 注意,專家不是按領域劃分,而是按 token 類型或上下文中的語義功能劃分的。這些“專家”并不像人類領域中的“心理學”或“生物學”專家那樣在特定學科上表現出高度專業化。實際上,它們更多是從詞匯層次上學習句法信息(這種多樣性是通過端到端的訓練自發形成的?),例如:Expert 1 專注于處理標點符號,Expert 2 專注于處理動詞,Expert 3 處理連詞,Expert 4 處理視覺描述相關的詞匯,這些分類只是示意說明,實際訓練過程中,專家會根據 token 使用頻率、上下文分布等自動學習其“擅長”的 token 類型。

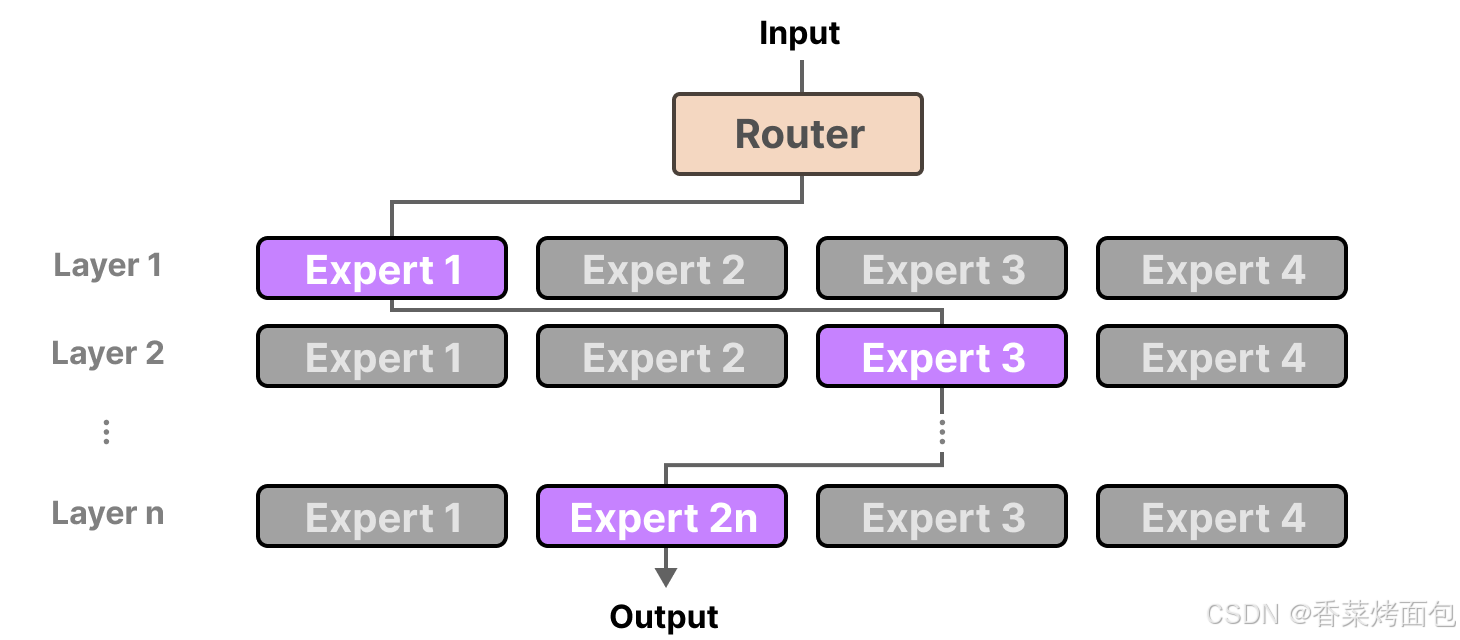
- 門控網絡或路由(Gate Network 或 Router):這個部分用于決定哪些 token 被發送到哪個專家。一個 token 甚至可以被發送到多個專家。
- 門控網絡一開始的路由決策是近似隨機的,但隨著專家逐步積累專長,門控網絡也會調整其路由策略:
- 正反饋循環:如果某個專家因早期獲得較多特定類型數據而表現出色,門控網絡便傾向于將更多此類數據路由給它
- 專家和路由網絡的協同演化:專家因接收到較多特定數據而“專長”,而門控網絡根據反饋不斷更新參數,使得路由更加精準?
- 門控網絡一開始的路由決策是近似隨機的,但隨著專家逐步積累專長,門控網絡也會調整其路由策略:
- MoE 整體框架,它是一個整體參數較大,而推理時參數規模較小的模型,例如 DeepSeek V3 總參數量 671B,推理參數 37B,推理參數占比 5.5%
1.3 專家架構
在 MoE 架構中,專家是指訓練好的子網絡(神經網絡或層),它們專門處理特定的數據或任務,專家和門控機制都通過梯度下降與其他網絡參數一起進行聯合訓練。
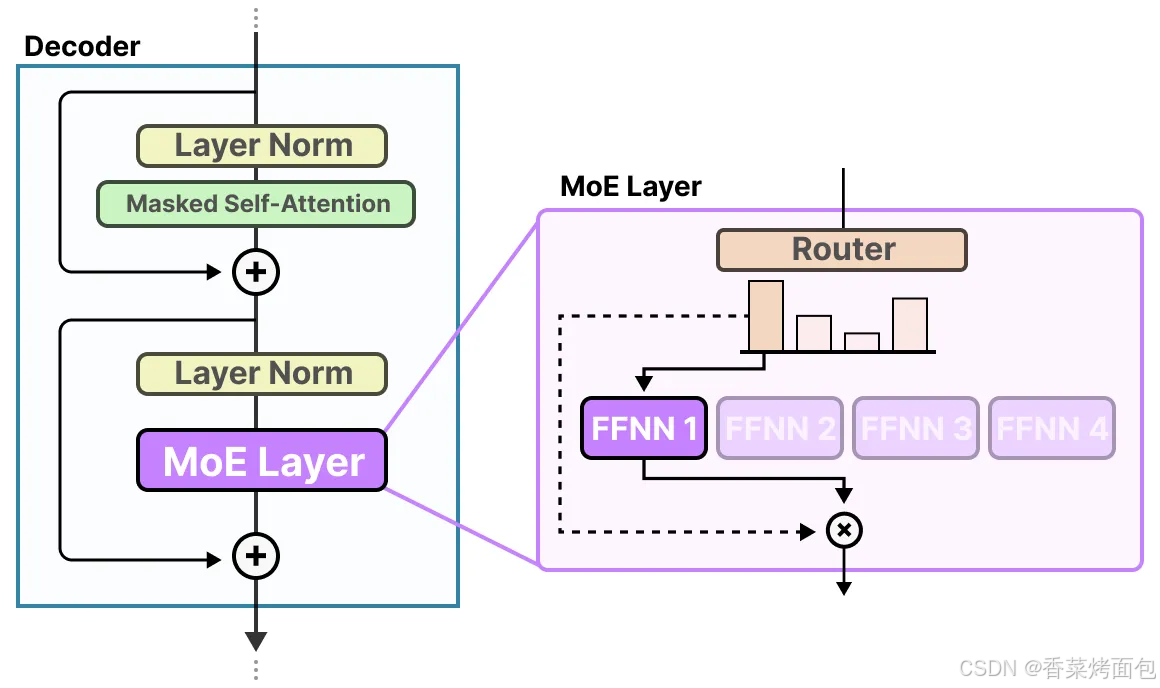
一般來說,MoE 中的每個專家都是具有相同架構的前饋神經網絡 FFNN,替換掉稠密模型中的FFN(圖一),專家本身就是完整的FFNN:
- FFN 層被分解為多個專家,每個專家實際上是 FFN 參數的一個子集。專家并不是對FFN的平均切分,實際上可以任意指定每個expert的大小,每個expert甚至可以大于原來單個FFN層,這并不會改變MoE的核心思想:對于一個token,部分專家的計算量要小于所有專家的計算量
- 不同的專家會專注于不同的主題(圖二),每個專家模型可以專注于處理自己接受到的輸入數據,學習數據中的一種特定模式或特征
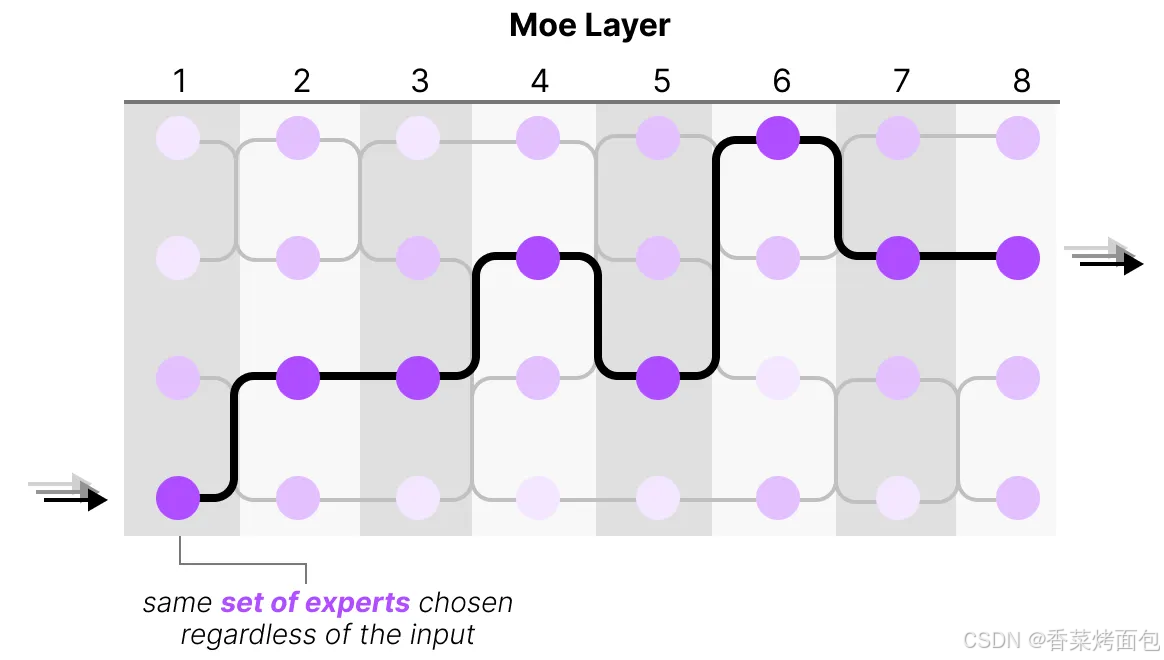
大多數 LLM 有多個 Decoder Blocks,因此在生成文本之前通過多個專家,不同 tokens 被選中的專家可能各不相同,這導致了不同的“路徑”被選擇:
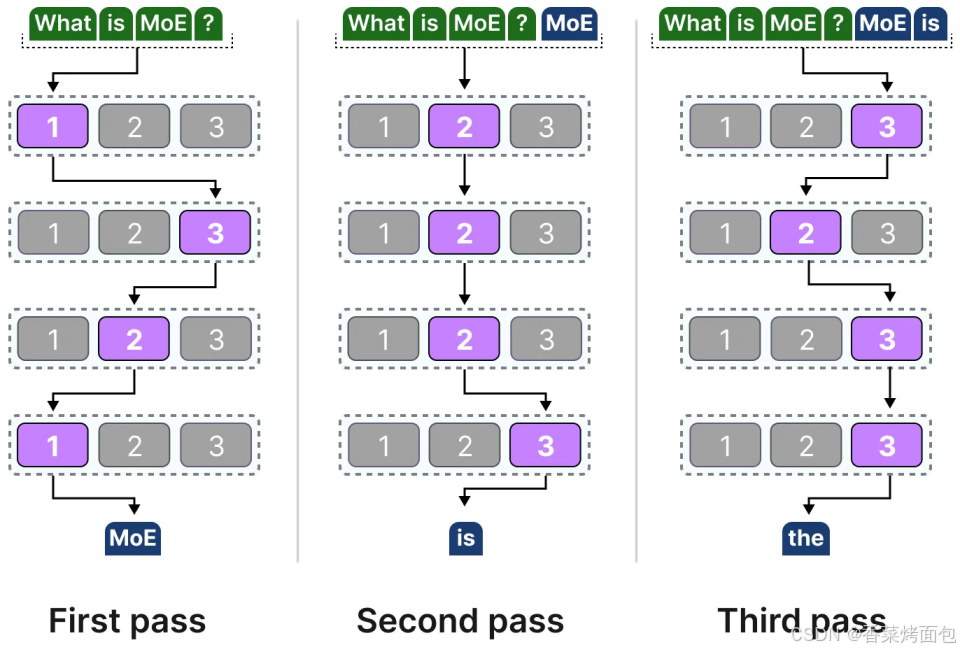
- 專家學習了什么?MoE 里的“專家”是一種擬人的形象化的說法,專家學習的信息比整個領域的信息更加細粒度,并不專攻“心理學”或“生物學”等特定領域,最多只是在單詞層面學習句法信息:更具體地說,它們擅長于在特定上下文中處理特定的 tokens
- 下圖為 Mixtral 8x7B 論文中,每個 token 都被其選擇的第一個專家進行了著色。在代碼中,縮進標記總是分配給相同的專家:

1.4 門控網絡
路由器(或門控網絡)本身也是一個 FFNN,它根據特定的輸入選擇專家。路由器會輸出概率值,并利用這些概率來選擇最匹配的專家,專家層返回被選定專家的輸出,并乘以門控值(選擇概率),路由器和專家(其中僅選擇少部分)共同構成了 MoE 層:
門控網絡可以說是 MoE 中最重要的組件,因為它不僅決定了推理時要選擇哪些專家,還決定了訓練時的選擇。
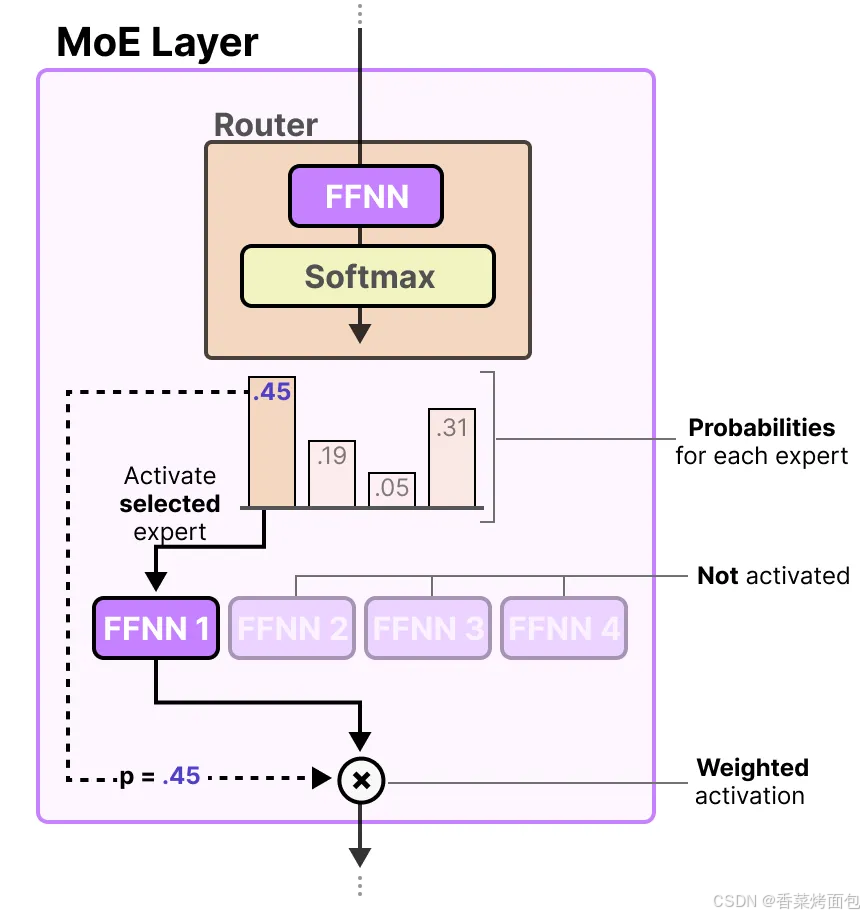
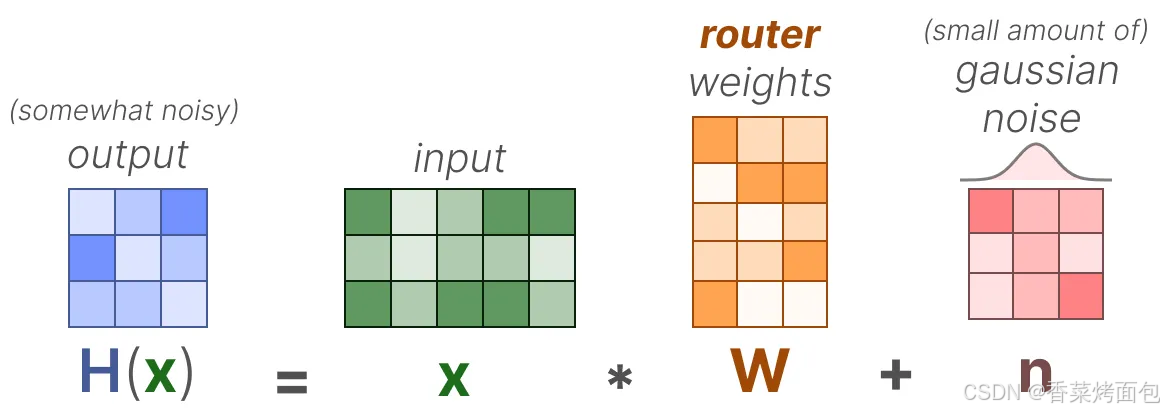
- 最基本的形式是,將輸入(x)與路由器的權重矩陣(W)相乘,然后對輸出應用 SoftMax 操作,為每個專家創建一個概率分布 G(x),路由器利用這個概率分布來為給定的輸入選擇最匹配的專家,最后,將每個路由器的輸出與各自選擇的專家輸出相乘,并將結果相加
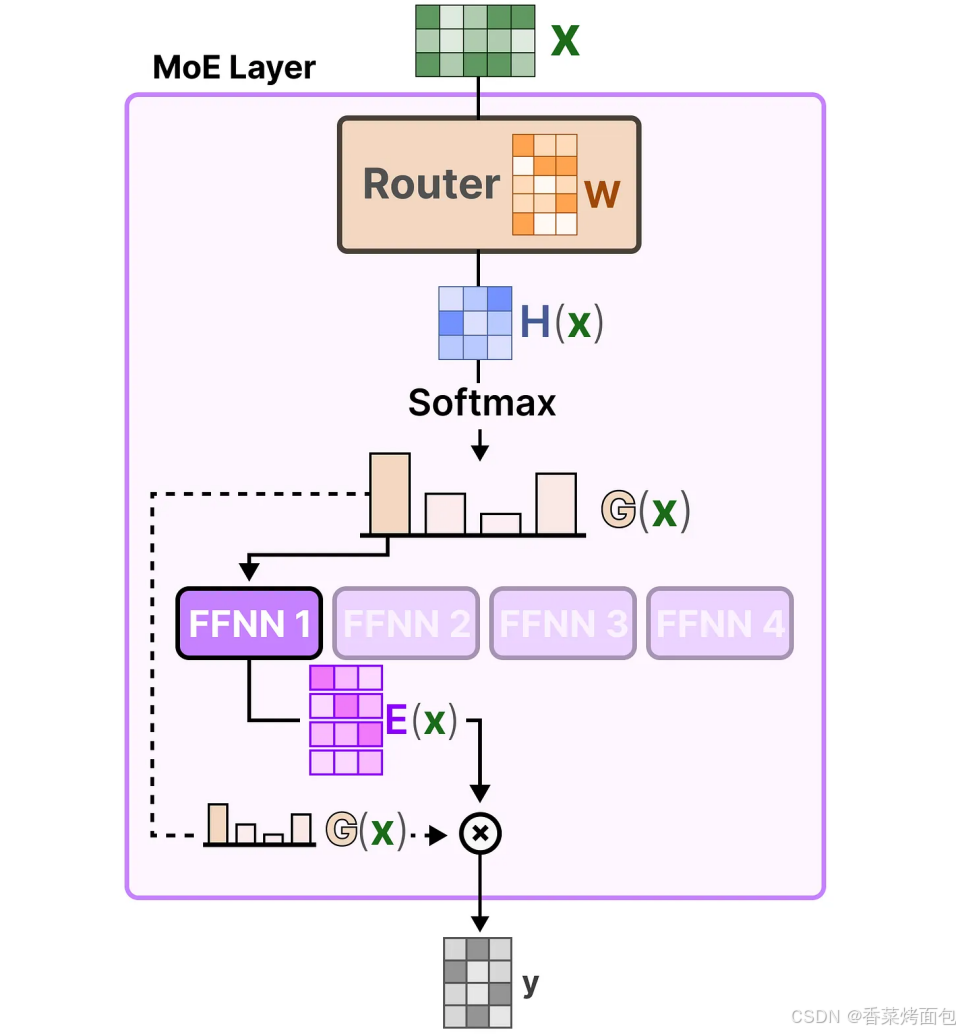
?然而,這個簡單的功能往往會導致路由器總是選擇相同的專家,因為某些專家可能比其他專家學習得更快:這不僅會導致專家選擇的不均勻分布,還會導致某些專家幾乎沒有被訓練過。這會在訓練和推理過程中引發問題。因此,希望在訓練和推理期間,各個專家的使用具有同等的重要性,這就是所謂的負載平衡。某種程度上,這是為了防止模型在同一組專家上過擬合。
1.5 負載均衡
因為 MoE 的結構由多個 expert 構成,每次只選擇部分執行,如果 Expert 的分配不均衡,就可能出現如下局面:某些 Expert 幾乎一直閑置,浪費算力;某些Expert要處理的Token太多,根本忙不過來,只能Token Drop(即放棄處理部分Token)。這樣的話,既浪費了顯存,又使模型沒有達到預期的參數量。
因此負載均衡就顯得非常重要,MoE 的負載均衡問題主要體現在兩個層面:
- expert 的負載均衡
- GPU 的計算均衡
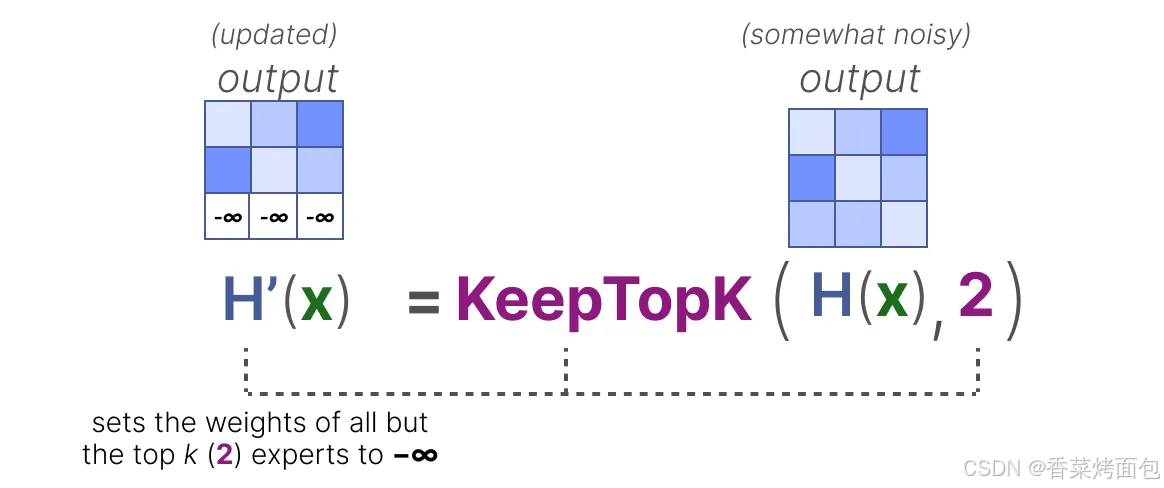
KeepTopK
一種對路由器進行負載平衡的方法是使用一個簡單的擴展策略,稱為 KeepTopK。
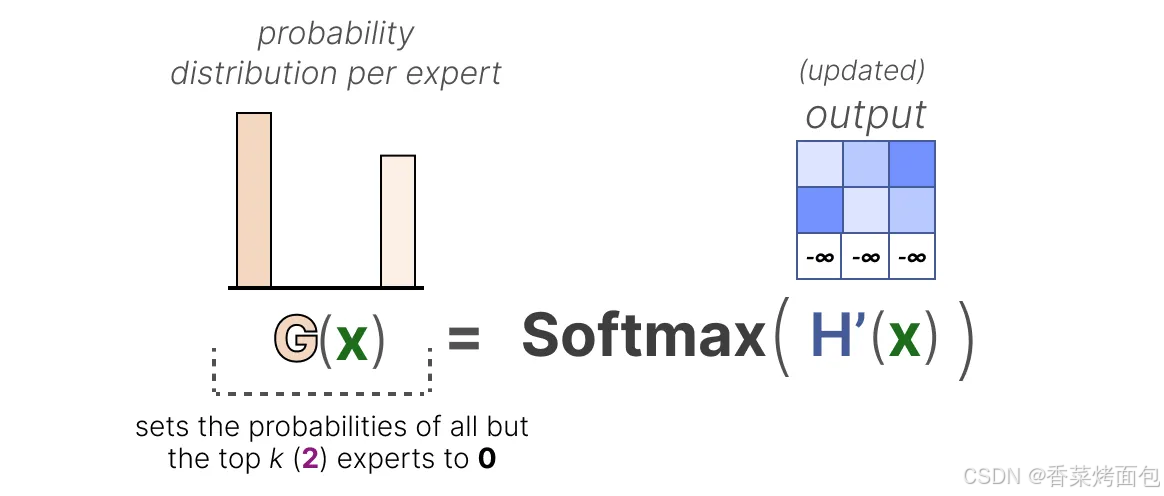
1. 通過引入可訓練的(高斯)噪聲,可以防止總是選擇相同的專家:
除了希望被激活的前 k 個專家(例如 2 個)以外的所有專家權重都將被設為 -∞,將這些權重設為 -∞ 時,SoftMax 操作后的輸出概率將變為 0:
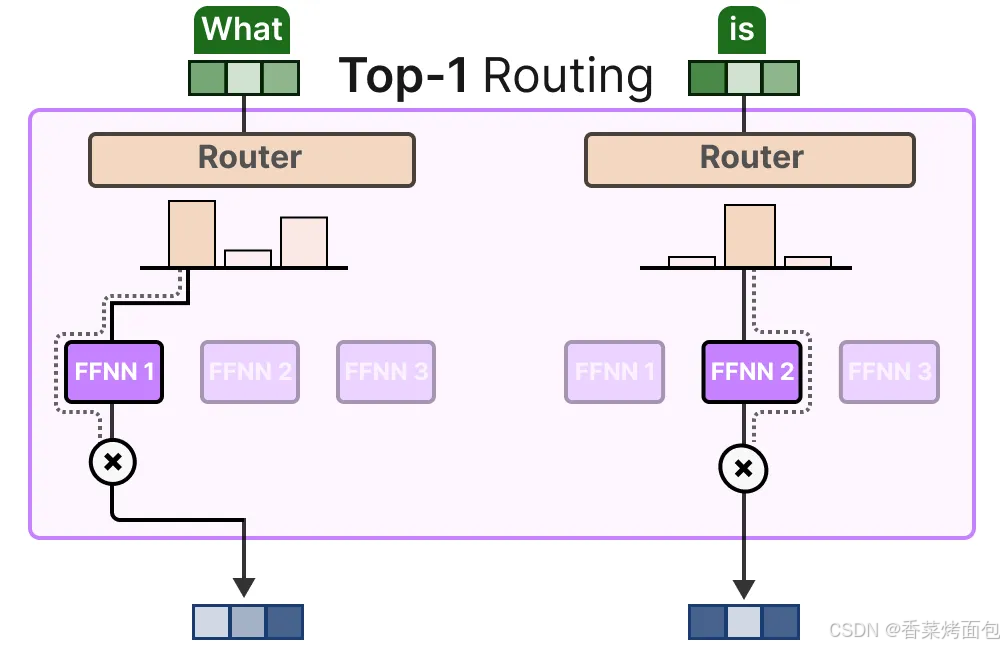
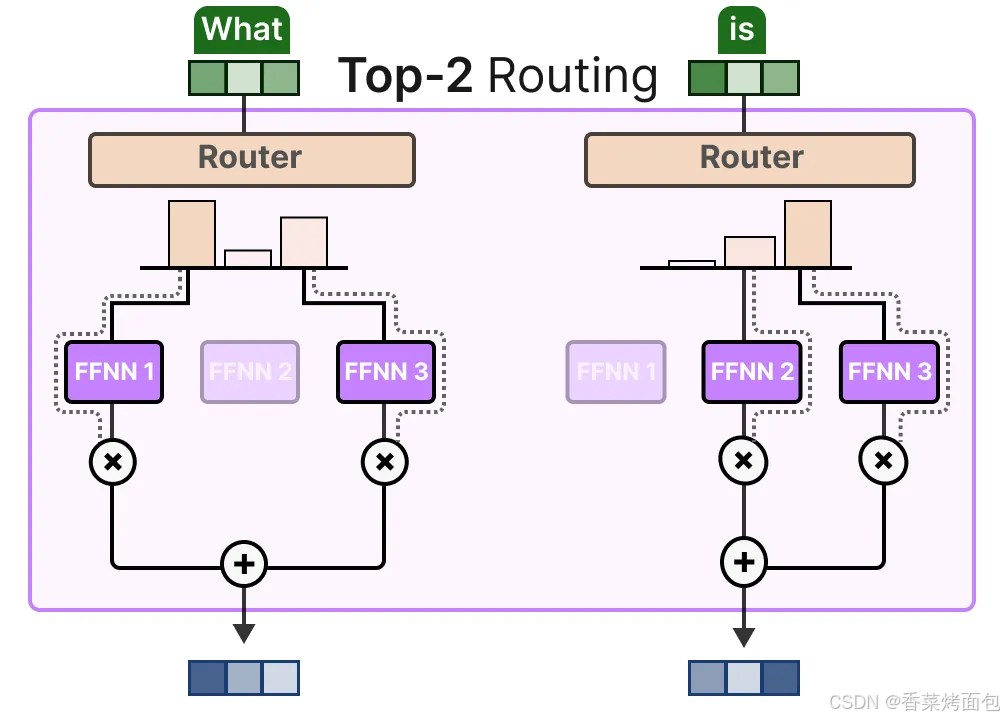
2. 不使用額外的噪聲,KeepTopK 策略會將每個 token 路由到若干選定的專家。這種方法被稱為 Token 選擇策略(Token Choice),它允許一個給定的 token 被路由到一個專家(top-1 路由)或者被路由到多個專家(top-k 路由):
輔助損失
為了在訓練過程中實現專家之間的均衡使用,除了常規損失函數之外,還引入了一個輔助損失(也稱為負載均衡損失)。這個輔助損失起到了約束作用,使模型在訓練時對所有專家賦予相似的重要性,避免某些專家被頻繁調用,而其他專家很少參與計算,鼓勵所有專家被均勻使用,避免“熱門專家”和“閑置專家”的極端情況。
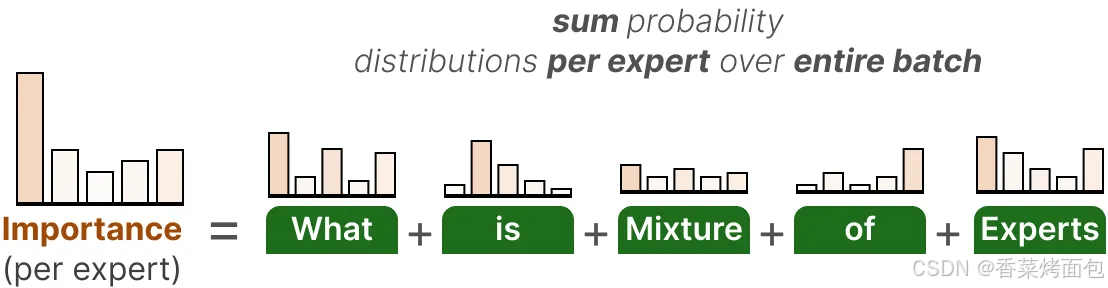
1. 計算每個專家的重要性(Importance)
- 在一個 batch 中,每個 token 都會被路由到少數幾個專家
- 將整個 batch 中每個專家被選中的概率值累加,計算每個專家在整個 batch 中被路由器選中的概率總和,得到這個專家的 Importance(重要性)總和,這個值反映了各個專家在當前批次中的使用頻率
2. 引入 Coefficient of Variation(CV,變異系數),衡量專家使用不均的程度,表示各個專家的重要性得分之間的差異程度(標準差除以均值):
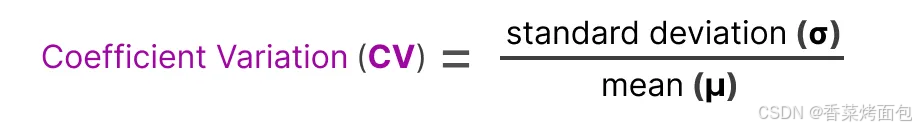
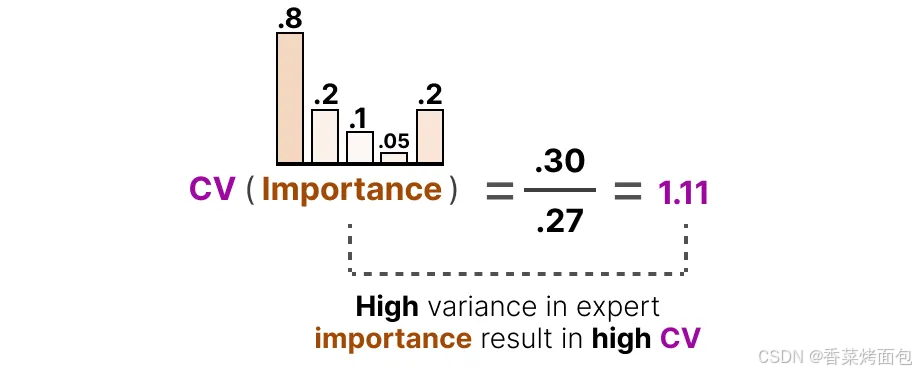
例如,如果重要性得分之間的差異較大,那么 CV 值就會較高,如果所有專家的得分都相似,則 CV 值較低(期望的情況),例如左邊柱狀圖中,重要性差異大(0.8 vs. 0.05),CV = 1.11 ? 不理想;右邊柱狀圖中,專家得分接近(0.3 ~ 0.2),CV = 0.19 ? 理想情況:
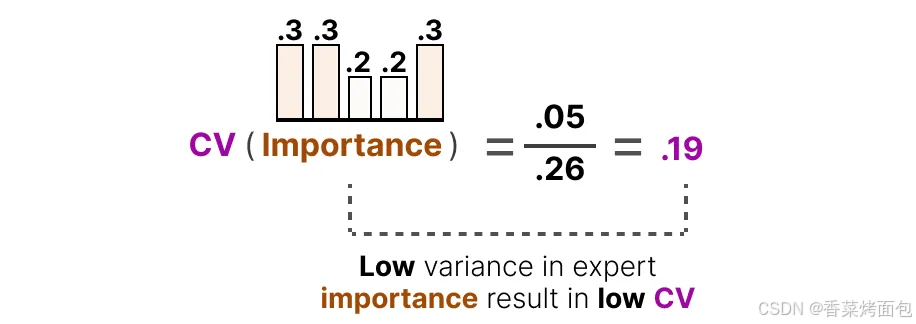
3. 構造輔助損失項(Auxiliary Loss)
通過使用這個 CV 得分,可以在訓練過程中更新輔助損失,使其盡可能降低 CV 得分,其中 w 是一個常數系數(scaling factor),CV 值越大,輔助損失越高,模型就會被懲罰更多,進而優化路由機制,使專家分布趨于均衡:
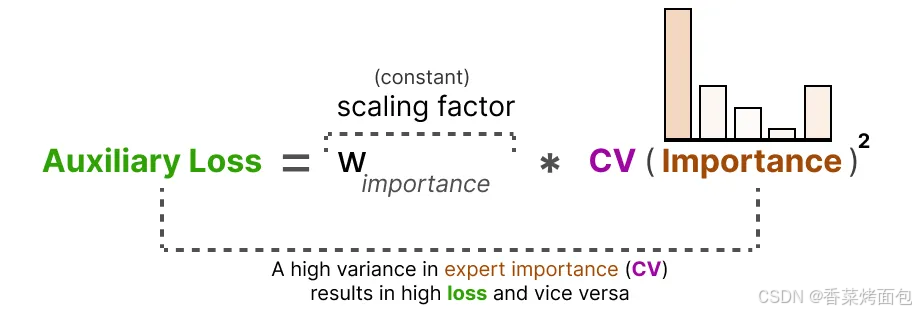
輔助損失將作為一個獨立的損失項(是訓練總 loss 的一部分,但單獨計算),參與訓練優化。
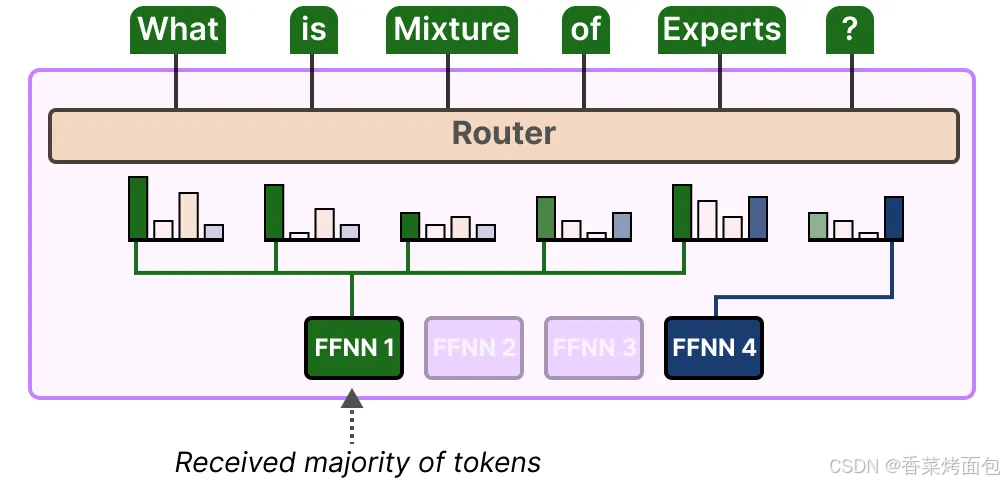
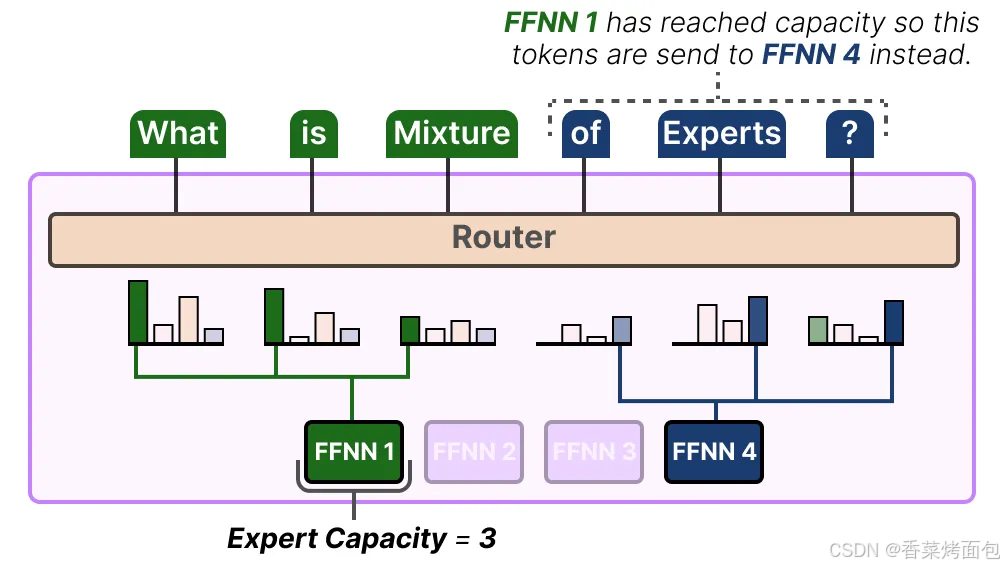
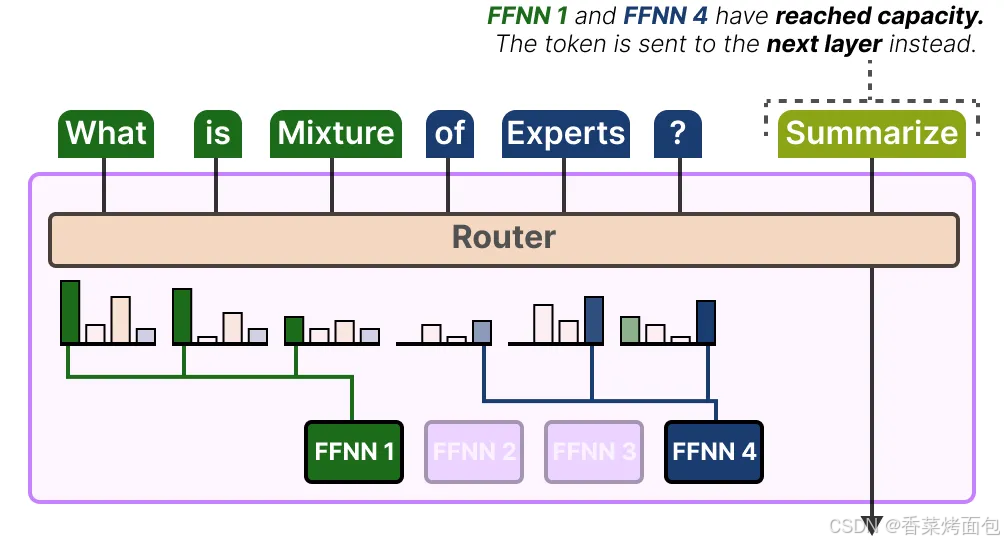
專家容量
專家的不平衡不僅體現在被選中的專家上,還體現在分配給這些專家的 token 分布上。
例如,如果輸入 token 被不成比例地分配到某些專家上,而不是平均分配,這可能導致某些專家的訓練不足(圖一);解決這個問題的方法是限制每個專家能夠處理的 token 數量,即專家容量(Expert Capacity)。當一個專家達到其容量時,多余的 token 將被分配到下一個專家(圖二);如果兩個專家都達到了其容量,token 將不會被任何專家處理,而是直接傳遞到下一層。這種情況被稱為 token 溢出(token overflow)(圖三)。
?以上為MoE的基本原理(門控函數等都沒有具體展開),現在主流的模型架構中基本都有 MoE 變體,也有很多工作對MoE模型做了優化,此處不再一一贅述。
MoE 整體計算流程
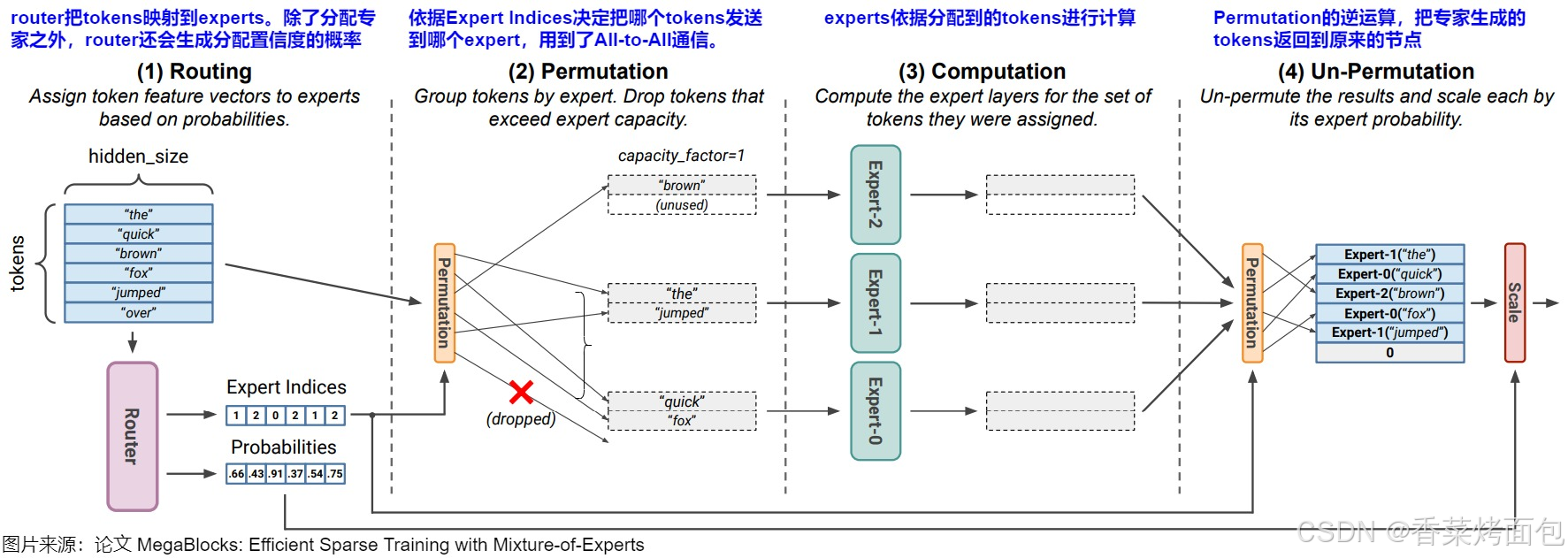
1. Routing:本質是對輸入進行分類的過程,選擇最適合處理輸入的專家模型。在語言模型的應用中,當輸入 token 通過 MoE 層時,Token 通過和 Router 的權重矩陣相乘得到一個 Expert Indices(決策矩陣)和一個概率張量,即索引和概率:
- Expert indices 是 expert-to-token 映射,用于指示每個 token 被分配給了哪個 expert,即張量中第 i 個值代表本 token 應該分配到第 i 個專家
- Probabilities 張量是分配置信度的概率,其中第 i 個值代表這個專家對于該 token 最終結果的權重
2. Permutation(排列/置換):根據路由決策(expert-to-token映射)將 Token 分配給對應的專家,中間可能會有drop操作
3. Computation:每個專家網絡并行處理其分配到的 token,計算輸出。把輸入矩陣 𝑥 與專家網絡的權重矩陣相乘 𝑦 = 𝑥 × 𝑊
4. Un-Permutation:收集專家的計算結果。這是 Permutation 的逆運算,將從各個 experts 收集到的處理后的 tokens 組合成一個完整的序列,這個序列保持了原始 tokens 的順序。即,將每個專家網絡的輸出根據原始的 token 順序重新排列。接著使用 Routing 步驟生成的分配置信度概率對結果進行加權求和,以得到最終的模型輸出,然后將這個結果繼續向下游處理
Permutation 的主要作用:
- 分發 token。Permutation 會依據 Expert Indices 構建本地的置換 Token 位置后的臨時矩陣(將輸入Token根據路由結果重新排列),這樣可以把屬于每個專家的 token 分別放在一起,然后把 tokens 送給對應的專家。比如上圖中,“the” 和 “jumped” 應該分配給專家1,所以就把它們放在一起,“quick” 和 “fox" 都應該被發送給專家2,所以把它們也放在一起
- 維持 token 和 expert 的順序。因為一個batch里有很多token,將這些token發往不同的expert做計算后,專家輸出結果的順序肯定是打亂的,所以需要通過一種方式追蹤順序,把 token permute 回正常的位置再輸入下一層網絡。通過構建的矩陣,Permutation 在計算時,就可以維護住這種順序
- 負載均衡。Permutation 可以實現輸入數據在不同專家之間的合理分配,平衡各個專家的計算負載。不同的輸入樣本可能對不同專家的計算資源需求不同。通過對輸入樣本進行置換,使得每個專家能夠相對均勻地接收到需要處理的樣本,避免某些專家過度使用而其他專家閑置的情況。
- 增加多樣性。Permutation 可以增加模型對輸入數據處理的多樣性。因為不同的置換順序可能會導致不同專家組合對數據進行處理,從而挖掘出數據的不同特征。
從代數的角度來看,MoE 計算實際上是對 token 進行一次置換群的操作,那么MoE實現的本質問題是:基于 Permutation 矩陣后構建的稀疏矩陣乘法如何進行并行。
2. EP 原理
專家并行(Expert Parallelism+, EP)的思路是將 MoE 層中不同的專家分配到不同的計算設備上,每個設備負責存儲和計算部分專家,而所有非專家層則在設備間復制。
如圖所示,一個包含 6 個專家的 MoE 模型在 EP=2 時的專家分布情況:
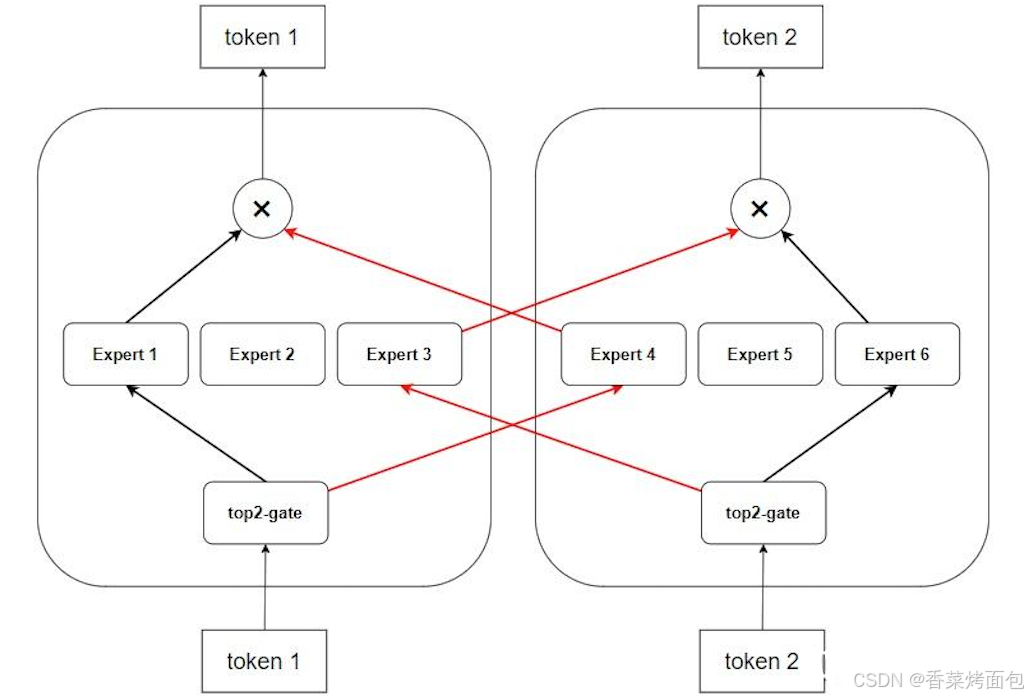
可以把專家并行理解成模型并行的一種形態(模型被切分成多份),但是輸入的數據又是不同的(DP),因此 token 在經過 Router 之后,可能會選中別的卡上的專家,此時就需要將這些 token 發送過去,即 EP 進程組內需要通過 AlI2AII 通信交換 token。
2.1 EP 推理流程
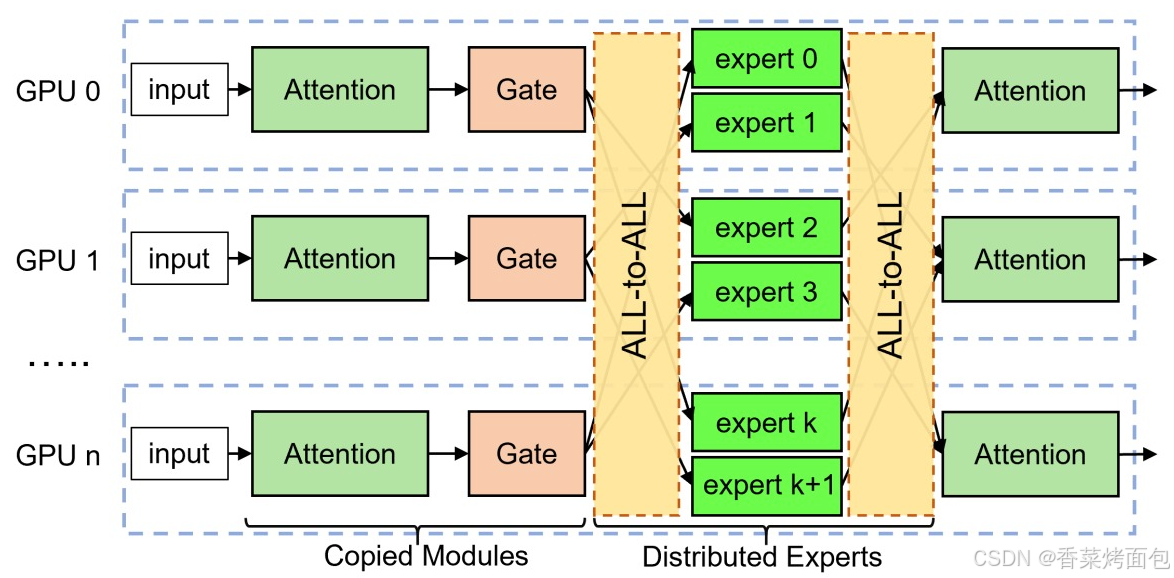
如圖為在一個 MoE 層的推理流程,非專家層(如 Input、Attention、Gate)在所有 GPU 上復制部署,每個 GPU 卡上只包含一部分 expert,token 在一個 MoE 層處理完成后,輸入到下一層進行處理。專家并行的推理流程包括以下幾個順序操作:門控路由、輸入編碼、All-to-All dispatch、專家計算、All-to-All combine和輸出解碼
- 門控路由:每個 GPU 上會有一個門控模塊(Gate),對輸入 token 做出判斷:這個 token 應該被哪個 expert 處理(expert 是稀疏選擇,通常只選擇 top-1 或 top-2)
- 輸入編碼與 Permutation(排列):每一張卡的輸入是一個完整的任務,包含多個 batch 與序列(sequence),被路由到同一個 expert 的所有 token,排列在內存中的一塊連續空間里,這個“排列”過程本質是把原始 token 的順序打亂,把屬于同一個 expert 的 token 聚集在一起,便于發送和批量計算
- All-to-All dispatch(分發):每個設備根據之前的排列,把 token 按照 expert 所在的設備位置,通過 All-to-All 通信機制發送過去。比如:GPU 0 上的某些 token,路由結果是 expert 2,這個 expert 在 GPU 1,那么這些 token 就通過 All-to-All 發送到 GPU 1。
- 專家計算:每個 GPU 上含有多個 expert,所有 token 被傳輸到目標 expert 所在卡之后,expert 在本地計算,每個 expert 僅處理被分配給自己的 token
- All-to-All Combine 與輸出解碼(Output Decode):expert 完成計算后,每個 token 的結果通過 All-to-All 返回到原來的 GPU 卡。然后根據最初記錄的排列順序,進行反排列(de-permutation),將 token 恢復成原始順序,拼接成完整的輸出。最終,token 在一個 MoE 層處理完成后,繼續進入下一層
2.2 EP 與 DP、TP、PP
下圖展示了 四種 MoE(Mixture of Experts)中的并行策略組合示意圖:
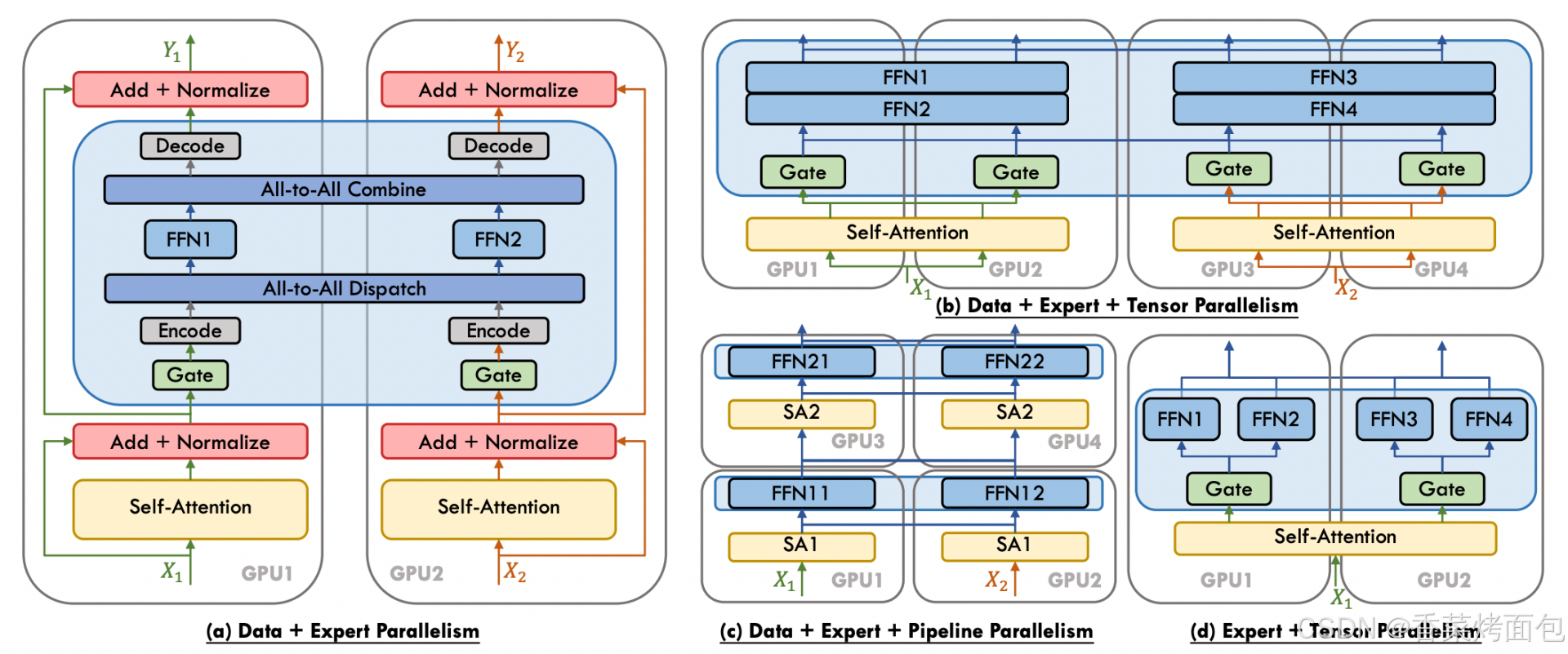
(a) Data + Expert Parallelism(數據并行 + 專家并行):輸入 token X1 X2 分配在兩個 GPU 上,每張卡上的 gate 決定當前 token 應該被分發給哪個 expert,使用 All-to-All Dispatch 把 token 發往 expert 所在的卡,Encode 準備要跨卡傳輸的數據,加上位置等信息,All-to-All Combine 再把結果聚合回來, Decode 將合并后的結果還原到原 token 順序、格式,最后繼續執行后續 Add + Normalize,輸出 Y1 / Y2
(b) Data + Expert + Tensor Parallelism(數據并行 + 專家并行 + 張量并行):加入了 Tensor 并行:模型參數本身被張量切分,不同 GPU 協同完成一個 FFN。Self-Attention 本身也用了 Tensor 并行:比如一個 Attention 權重被橫向切為兩半 → GPU1 和 GPU2 分別算一部分;每個 expert(比如 FFN1)也被橫向拆開,兩張卡各算一半;Gate 還是各自獨立計算(每張卡計算本地 token);沒有 All-to-All,因為 Tensor 并行下,每張卡都需要協同計算同一個 expert 的一部分;所有 GPU 對參數是 切片共享的,非副本;最后通過 All-Reduce 聚合 tensor 切片,才能得到完整輸出
(c) Data + Expert + Pipeline Parallelism(數據并行 + 專家并行 + 流水線并行):把 Transformer 模型切成多個 stage,每張卡負責不同層(層間流水線),并且專家分布在不同卡上,每張 GPU 執行模型的一部分。GPU1 和 GPU2 執行 MoE block 的第 1 層(SA1 → FFN11/12);GPU3 和 GPU4 執行第 2 層(SA2 → FFN21/22);每層內依然有 Expert 并行,每個 FFN expert 只存在于某一張卡上,每一階段處理完后,將結果傳到下一階段卡上,Pipeline 并行讓每張 GPU 專注于一部分層的計算
(d) Expert + Tensor Parallelism(專家并行 + 張量并行):專家部分內部用 Tensor 并行,但不做數據并行或流水線分層。一張卡內有多個專家 FFN,這些 experts 是分別獨立的,但內部每個 expert 的 FFN 由多個 GPU 協同計算,Gate 分配 token 后,在每張卡上 local route,不需要 All-to-All,每張卡只執行本地 expert 負責的 token 部分,Tensor 并行用于分擔一個 expert 的模型計算負擔
關系總結:
- DP是“復制模型,切分數據”
- PP是“切分模型層,數據流式處理”
- TP是“切分層內算子(權重矩陣)”
- EP是“切分MoE層內的專家”
下圖是從模型參數切分和數據切分的角度(只考慮 FFN 層)來比較幾種并行策略:(https://arxiv.org/pdf/2101.03961)
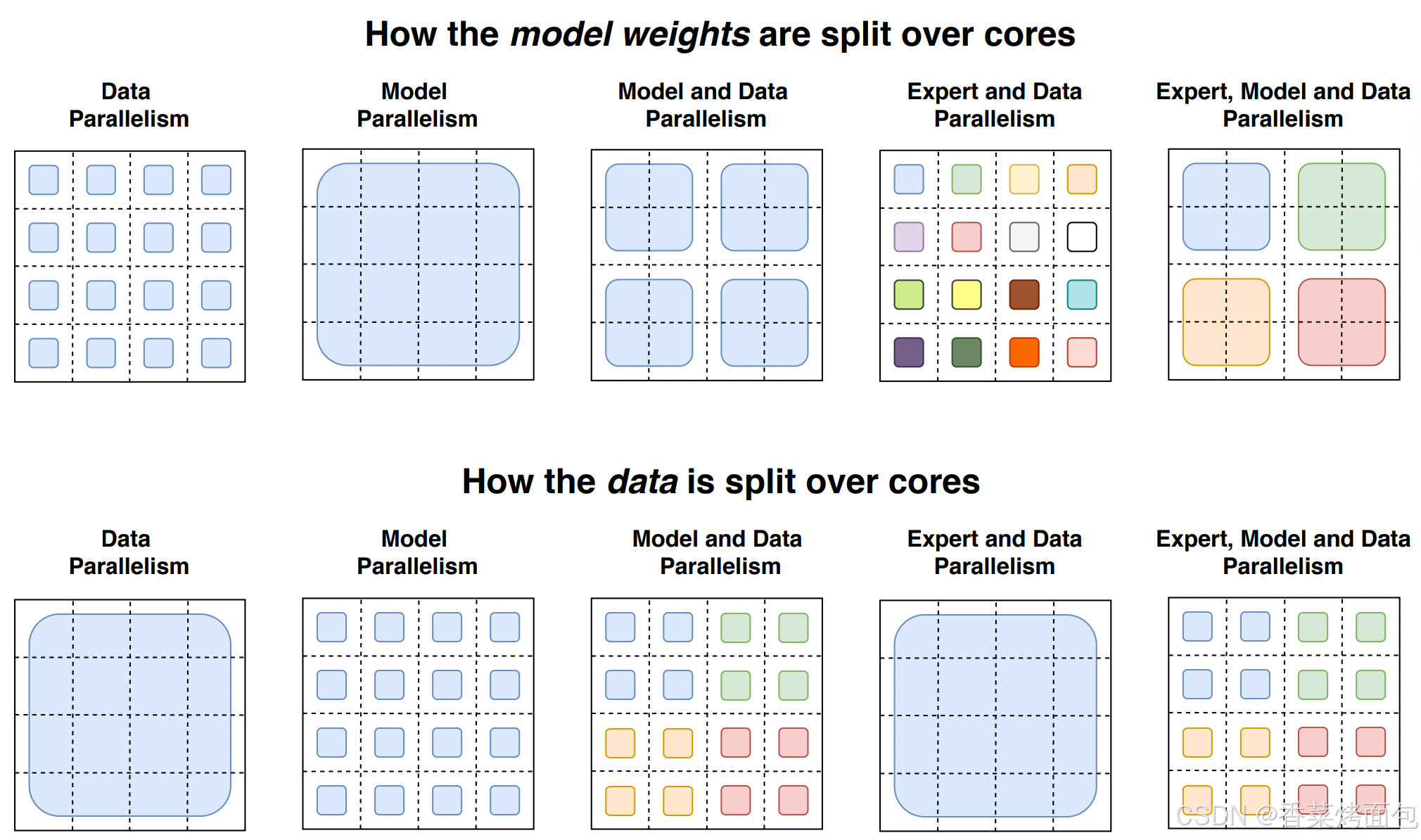
每個 4×4 的虛線網格代表 16 個 Device,陰影方塊是該 Device 上包含的數據(模型權重或token)。第一行:模型權重如何在 Device 之間分配,陰影方塊的大小為不同的權重矩陣大小,每種顏色都標識了一個權重矩陣。第二行:數據batch如何在 Device 之間分割,不同顏色代表不同 token。
- 第一列:數據并行,上方所有設備(1-16)都有相同、全部的模型參數;下方每個設備只有一個數據分片,共 16 個數據片。
- 第二列:模型并行,上方所有設備(1-16)都只有模型參數的一部分,共 16 個分片;下方所有設備使用共同的一份數據。
- 第三列:模型并行+數據并行,設備分為 4 組。上方表明每組都有完整的模型參數副本,但是每組內的設備只有參數的一部分;下方表明數據分為 4 個切片,每組對應一個數據切片。
- 第四列:專家并行+數據并行,設備分為 16 組(1-16)。上方表明每一個設備都有不同的專家,共 16 個專家。下方表明每個設備都有不同的數據分片(Token),共 16 個數據分片,一個專家對應一個分片。
- 第五列:專家并行+模型并行+數據并行,有 4 組設備(1-4,5-8,9-12,13-16)。上方表明有 4 個專家,每個專家分布在對應的 4 個設備上,比如綠色專家分布在 5,6,7,8 設備上。下方表明有 4 個數據分片,每組設備(每個專家)對應一個數據分片,一組里的 4 個設備共享一份數據分片。
2.3 AlltoAll 通信
AlltoAll 是集合通信庫(NCCL)中一種常見的通信機制,用于多個設備之間進行數據交換。AlltoAlll 操作允許每個參與的設備將其本地數據分發到其他設備,同時從其他設備接收數據。AlltoAll 的作用相當于分布式轉置Transpose 操作。具體如下圖所示,可以看到,GPU0 把自己收到的 4 個綠色的塊分配給了全部 4 個 GPU 。
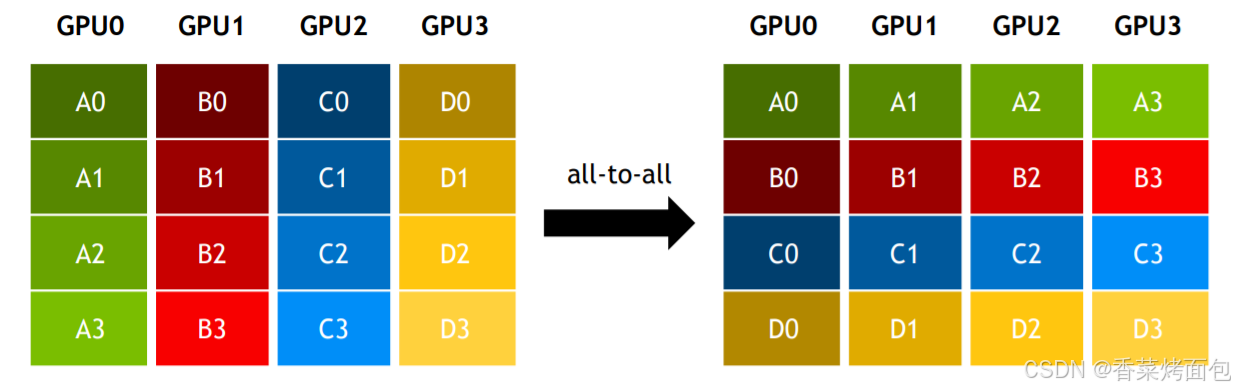
結合MoE來看,需要通過 AlltoAll 將 token 發去指定的 expert 做計算,再通過 AlltoAll 將計算結果返回。假設我們有一個 4 張卡的 GPU 集群。下圖步驟 1 表示首次做 AlltoAll(All-to-All Dispatch)的過程,這個過程的目的是將 token 發去對應的 expert 上進行計算,對比一下左側圖和中間圖的數據塊排布,會發現 AlltoAll 就相當于做了一次矩陣轉置。因此通過 AlltoAll,我們就讓數據塊去到了它對應的位置:A0、B0、C0和D0去GPU0,A1、B1、C1和D1去GPU1,以此類推。而為了實現這種轉置,我們必須提前把 token 做分塊排序,讓它按照要去的專家位置排好。步驟 2 表示第二次做 AlltoAll(All-to-All Combine)的過程,這個過程的目的是將MoE算完的token再返回給各卡,原理和上述一致。

在 All-to-All Dispatch 操作之前準備好 All-to-All 輸入的過程叫輸入編碼,即需要對本 GPU 上的 local token 按照路由結果進行重新排列(permute 或 group),將發往同一個專家的 token 進行分組,讓屬于同一個專家的 token 在 memory 中鄰近,方便批量發送。隨后,這些 token 通過 All-to-All Dispatch 通信發送到對應的 expert rank(每個 EP rank 上只包含一部分 expert)。在 All-to-All Combine 操作之后需要把這些 token 的結果需要送回原先對應的輸入位置,還原順序,這叫輸出解碼。大多數流行的 DL 框架利用 NCCL 的點對點(P2P)通信來實現線性 All-to-All 算法。

這個偽代碼實現的是:在 n 個 GPU 間進行 Linear All-to-All 通信,也就是每張卡將它本地輸入的第 r 塊發給第 r 張卡,同時接收來自第 r 張卡的一塊,是一種 線性復雜度的 All-to-All 實現(每 GPU 發/收 n 次)。這段代碼完成的操作是:每個 GPU 把自己的輸入 input 分成 n 塊,每塊分別發送到 n 個 GPU 的對應位置,同時接收從 n 個 GPU 發來的塊,實現一種簡化版的 All-to-All:每塊數據從 sender 到對應的 receiver,用的是 NCCL 的點對點通信接口(而不是全局的 AllToAll)
2.4 MoE 分布式計算過程
下圖為 TP、DP 和 EP 互相結合的 MoE 分布式計算過程,其中并行劃分為:Transformer layer 在四張 GPU 卡上并行,TensorParallel=2,DataParallel=2,ExpertParallel=2。張量并行組(GPU0 和 GPU1)在處理token 1和 token 2(w1、w2),而張量并行組(GPU 2 和 GPU 3)處理 token 3和 token 4(w3、w4)。
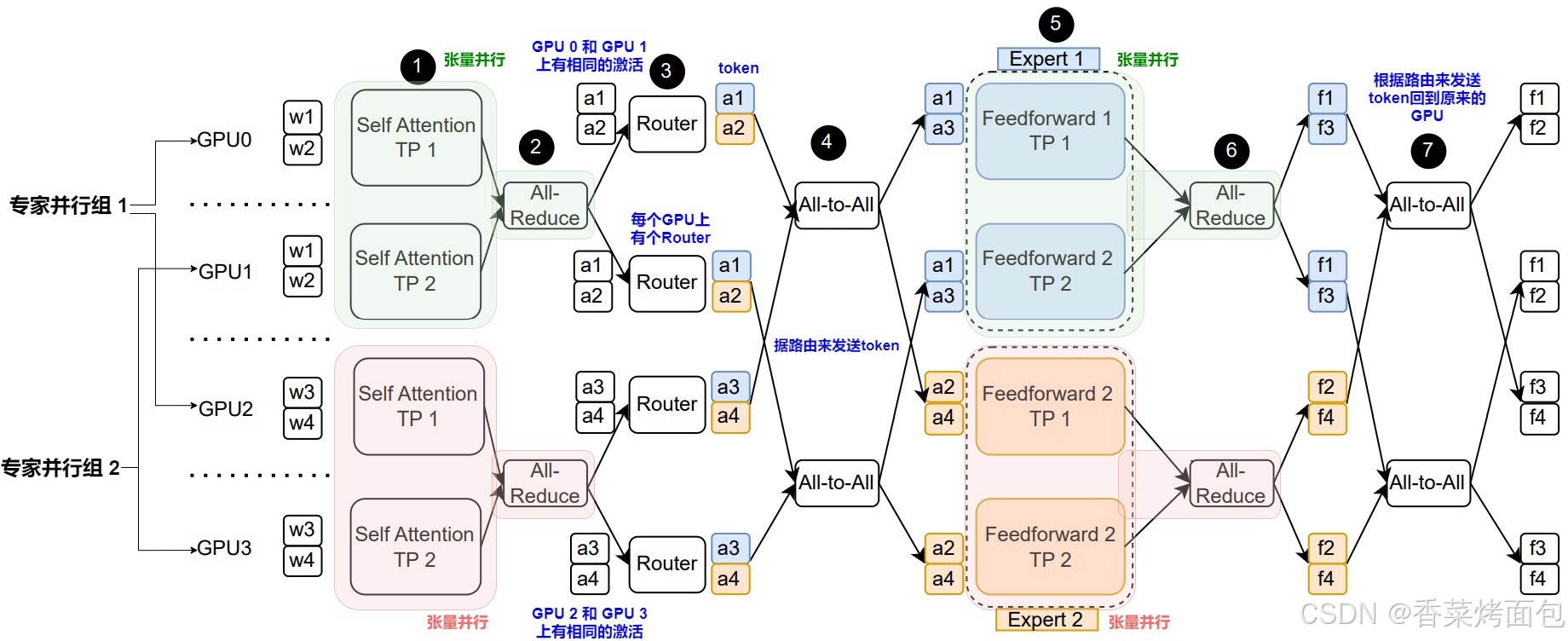
整體計算過程分為7步:
- 每個 GPU 首先計算各自自注意力塊的分區。{GPU0,GPU1} 與 {GPU2,GPU3} 之間是數據并行;
- 在每個自注意力塊的張量并行組內,每個 GPU 執行 All-Reduce 聚合它們各自 token 的完整輸出(a1、a2、a3和a4),聚合自注意力塊的張量并行輸出;
- 每個 GPU 對于自己的本地 token 執行 MoE 路由功能;
- 根據路由結果,將 token 發送到對應的專家。假設路由函數將 a1 和 a3 映射到專家1,且將 a2 和 a4 映射到專家2。
- 在 All-to-All 通信操作完成之后,每個專家分塊在自己所在的 GPU 進行計算;
- 在 FFN 的張量并行組內執行 All-reduce 操作來聚合完整輸出。這一步是聚合FFN的張量并行輸出;
- 執行 All-to-All 通信操作,將 token 發回它們的原始所在 GPU
2.5 通信復雜度
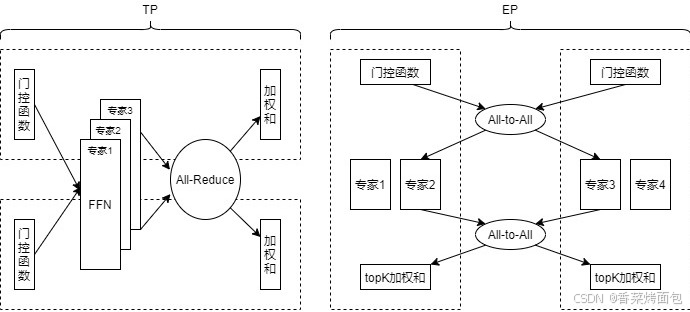
如上圖左邊所示,TP 的基本思路是將模型參數切分到多個 GPU 進行計算。面對參數量大幅增大但計算量不變(每個 token 只激活一小部分專家)的 MoE 架構,TP 方案暴露出兩大核心問題:通信會成為瓶頸,內存也會逐漸成為瓶頸。
1. 通訊會成為瓶頸
- 假設每次推理一個 batch 里一共有 S 個 token,hidden dimension 是 D,每個 GPU 的通信量 = 2 × S × D
- 一次 AllReduce 實際上是一個 scatter + gather,兩次通信:一次發送(send),一次接收(recv)
- 和 TP size(并行粒度)無關 —— 也就是說你分得再細,也改變不了 hidden dim 的維度,也就改變不了通信量,通信開銷不會因為增加 TP size 而減少,TP 的通信開銷與 TP 粒度無關
- TP 的部署方式是每個 GPU 上都需要 AllReduce 來聚合所有 input tokens 的激活值,無論劃分多少份,都是不會改變結果矩陣的大小,TP 中的 AllReduce 的通信量會隨著整個部署實例 batch size 的增大而增大,并且即使增大 TP 并行度,通信量也不會變小——這是因為 TP 是源自稠密模型的設計范式
2. 內存會成為瓶頸
- 由于 TP 劃分的是權重,對同一個實例里的每一張卡都有相同的輸入,TP 中每個 GPU 上處理的都是 相同的 input token(全 batch),所以 TP 的整體通信量是和當前實例的 batch-size 成正比的,且不受 TP劃分粒度的增加而減少。整個實例增大 batchsize,那么對于實例內的每一張卡都需要增加 batchsize,極大限制了推理的batch size(會被單卡顯存限制住)
- 而 MoE 的計算需要足夠多的 token 才能實現有效的 Expert 負載均衡,如果 batch size 小,那每個 expert 分到的 token 可能很少,甚至有的 expert 不被激活,大大降低了GPU的利用率。然而,TP 方案要求所有 GPU 加載全部專家的參數,即使某些專家未參與計算,也會占用顯存資源
3. EP的作用
EP 方案為大規模 MoE 推理提供了一種全新的并行思路,能夠有效解決 TP 方案的兩大核心問題。
- 在通信開銷方面,EP 采用 All-to-All 進行數據交換,通信成本更低:在 EP size 增大的情況下,EP 能大幅降低計算相同數量 token 的情況下單個 GPU 的通訊開銷
- 假設一個 batch 共有 S 個 token,每個 token 會路由到 top-k 個專家,Expert 并行度(EP size)為 M,每個專家的 hidden dim 仍為 D
- 每個 GPU 通信量 ≈ 2 × K × S / M × D,這是因為每張卡只需要處理自己對應專家的 token 子集,token 會被 dispatch 到目標專家(combine 過程同理),如果 K/M < 1,即只有極少部分專家被激活,那么通信量遠低于 TP
- 更好的內存使用 & batch size 支持:每個 GPU 只處理自己專家負責的 token,所以每張卡只需要存儲被分配到的 token,而不是整個 batch,這就意味著 可以增大整個 batch size(在多卡上分發),而不會受單卡內存限制,所有專家都有可能被激活,也能分到更多 token,提高 GPU 利用率
小結:TP 更適合稠密模型;EP 是為稀疏 MoE 模型量身定做的更高效并行方案,能緩解通信瓶頸、顯存瓶頸并擴展推理能力。
在專家并行中,每個 MoE 層在前向和反向傳播階段中,一共需要進行四次 All-to-All 通信,這會產生顯著的開銷,甚至成為效率的主要制約因素。這種通信的效率取決于多個因素,包括通道帶寬的異質性、網絡拓撲結構和集體通信算法。此外,MoE 固有的負載不均衡可能通過引發同步延遲來加劇這些低效。為了優化節點內高帶寬和節點間低帶寬的使用,研究人員做了很多努力,比如:
-
最小化網絡流量并利用高帶寬連接。比如引入分層 All-to-All 、拓撲感知的路由策略、利用專家親和性來進行分配等;
-
考慮到通信和計算的并發性,把流水線并行和專家并行集成,以此協調 All-to-All 通信和專家計算的重疊。也有研究人員利用GPU的大規模并行性和GPU發起的通信,將計算與依賴的集合通信進行融合。或者將通信依賴關系進行解耦來通信與計算之間的重疊。
3. DeepEP
項目地址:https://github.com/deepseek-ai/DeepEP
?DeepEP 是 DeepSeek 專為混合專家模型(MoE)設計的專家并行(EP)通信庫,解決了 Token 在 GPU 之間分發和聚合過程中的效率問題。該庫提供了高吞吐量、低延遲的 All-to-All 的 GPU 內核(通常稱為 MoE 分發與聚合內核),支持 FP8 低精度計算,并通過通信-計算重疊技術實現資源高效利用,內節點通信性能可達到 153-158 GB/s 的 NVLink 帶寬,而跨節點通信可達 43-47 GB/s 的 RDMA 帶寬。
簡單來說,DeepEP 是一個庫,它的目的是幫助加速和改進 GPU 在處理復雜的機器學習任務時的溝通效率,特別是那些涉及到混合專家模型(MoE)的任務,這些模型會使用多個“專家”來處理一個問題的不同部分,而 DeepEP 的作用就是確保數據在這些“專家”之間快速、高效地傳遞。DeepEP 就像機器學習系統中的一個智能交通管理員,確保所有“專家”都能及時收到數據,并協同工作,不會出現延誤,從而讓整個系統更高效、更快速。
3.1 核心功能
DeepEP 的核心功能包括:
- 高效的 All-to-All 通信:通過軟硬件協同優化,DeepEP 實現了專家之間的高速數據傳遞,顯著提升了訓練和推理效率
- 支持 NVLink 和 RDMA:無論是節點內還是節點間通信,DeepEP 都能充分利用 NVLink 和 RDMA 的高帶寬和低延遲特性(針對Hopper架構)
- 高吞吐量與低延遲內核:在訓練和推理預填充階段,DeepEP 提供了高吞吐率計算核;而在推理解碼階段,則提供了低延遲計算核,滿足不同場景的需求
- 原生 FP8 支持:DeepEP 支持包括 FP8 在內的低精度運算,進一步優化了計算資源的利用
- 靈活的 GPU 資源控制:通過計算與通信的重疊處理,DeepEP 實現了資源的高效調度,提升了整體性能
NVLink 與 RDMA
DeepEP 優化了兩種不同通信域之間的數據傳輸:
- NVLink 域:NVIDIA GPU 之間的高速直連通道,帶寬可達約 160 GB/s,適合服務器內部 GPU 間通信
- RDMA 域:遠程直接內存訪問技術,允許計算機不經過操作系統直接訪問遠程內存,帶寬約 50 GB/s,適合服務器間通信
DeepEP 專門為非對稱域帶寬轉發場景提供了優化核心。
3.2 優化原理
DeepEP 提供了兩種主要類型的內核,以滿足不同的操作需求:
1. 常規內核(Normal kernels):這些內核針對需要高吞吐量的場景進行了優化,例如在推理或訓練的預填充階段。它們利用 NVLink 和 RDMA 網絡技術,在 GPU 之間高效地轉發數據。測試顯示,在 Hopper GPU 上,節點內通信的吞吐量約為 153?GB/s,而使用 CX7 InfiniBand(帶寬約為 50?GB/s)的節點間通信性能穩定在 43–47?GB/s 之間。通過最大化可用帶寬,這些內核減少了在 token 分發和結果合并過程中的通信開銷。
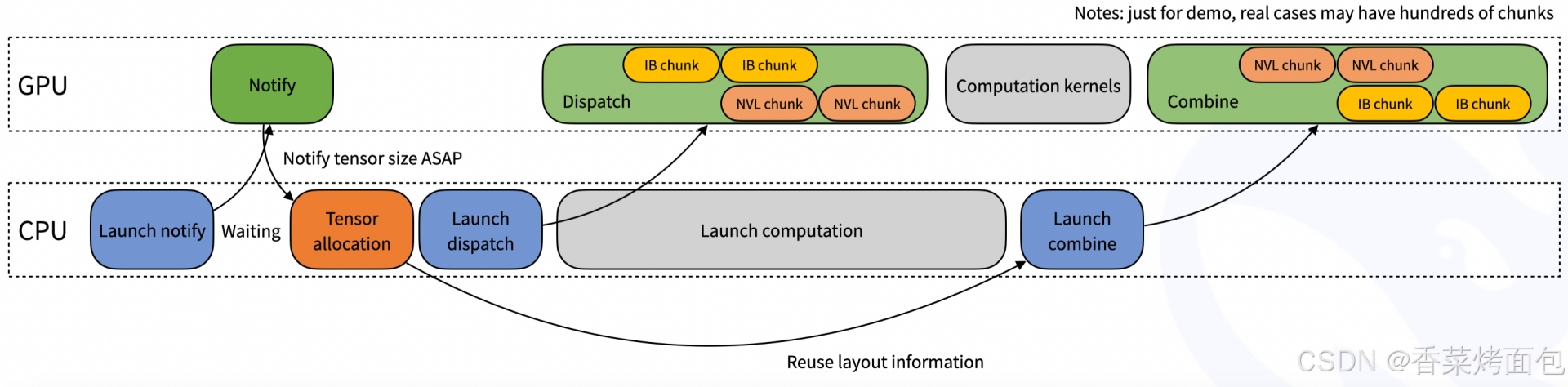
- 上圖為示意圖:IB chunk 和 NVL chunk :表示數據塊來源不同 —— IB chunk 來自節點間(通過 IB),NVL chunk 來自節點內(通過 NVLink)
- 整體流程:CPU 啟動一個 GPU 的通知內核(Notify)后開始等待GPU結果,GPU 執行Notify 內核啟動后返回,CPU 獲得通知后,得知“tensor 大小”——提前知道數據規模,為下一步 tensor 分配做準備;Tensor allocation:根據 Notify 階段得到的信息,CPU 分配好 tensor 空間;Launch dispatch:啟動 GPU 的 dispatch 內核;Launch computation:啟動計算任務,然后 GPU 執行 Dispatch:讀取 IB chunks 和 NVL chunks,Computation kernels:執行計算;在計算完成后,CPU 啟動 GPU 的 combine 操作;GPU 執行Combine,將 IB chunk 和 NVL chunk 的結果合并起來,準備好最終輸出給下游任務
- 通過 notify 提前獲得 tensor 大小,加快后續分配,優化延遲;帶寬利用最大化:節點內用 NVLink,節點間用 InfiniBand;CPU 啟動內核、GPU 并行執行,避免空閑
2. 低延遲內核(Low-latency kernels):DeepEP 提供了僅依賴 RDMA 的低延遲內核,專為處理小批量數據而設計。此外,設計中還引入了一種基于hook(在每個 kernel 結束后判斷是否需要觸發通信操作)的通信與計算重疊技術,使數據傳輸可以與計算同時進行,所有 RDMA 通信在后臺異步完成,而不占用 GPU 的流式多處理器。
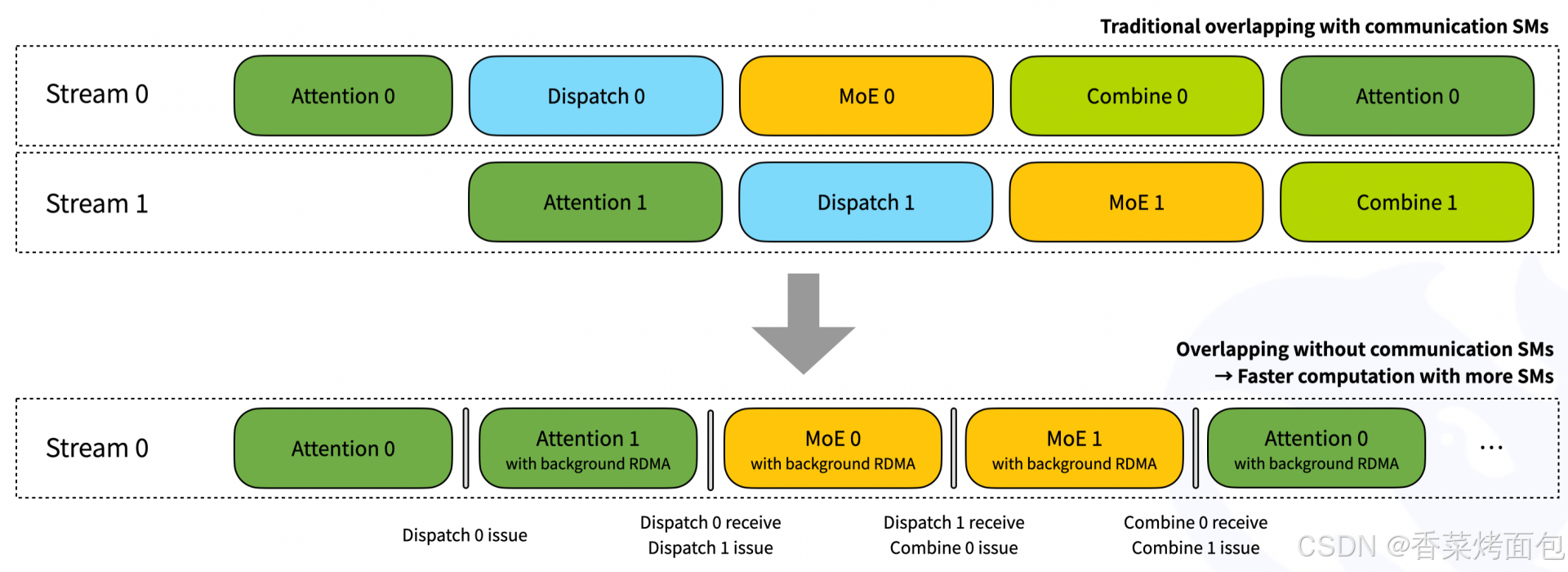
- 上半部分:傳統通信重疊方式(需要 communication SMs),Stream 0 和 Stream 1 分別表示兩個并發 CUDA 流
- 流程如下(每條流):[Attention] → [Dispatch] → [MoE] → [Combine] → [下一步 Attention]
- Dispatch、MoE、Combine 等通信與分發相關的操作在不同 stream 上執行,雖然可以部分重疊,但它們仍占用 SM 資源
- 下半部分:DeepEP 的優化方式 ——“無通信 SM 重疊”,所有任務集中在 Stream 0,計算和調度在一個 stream 中,避免多流同步和切換
- Step 1:在 Stream 0 執行 Attention 0:正常運行的注意力計算模塊,沒有通信,純計算,完成后觸發 Dispatch 0 issue,發出路由請求,將token發給專家
- Step 2: Attention 1 的計算照常進行,同時,RDMA 正在后臺執行 Dispatch 0 的數據路由,將 token 發往專家(RDMA 不用 SM,這兩個操作真正重疊了),Attention 1 計算完成后,觸發 Dispatch 0 接收 + Dispatch 1 issue
- Step 3: MoE 0 計算,RDMA 正在后臺執行 Dispatch 1,Dispatch 0 的遠端數據已到達 GPU,本地 SM 可開始計算,下一步:Combine 0 issue、MoE 1 issue
- Step 5:MoE 1 執行時,Combine 0 開始從遠端收集 MoE 輸出結果,Combine 0 的結果將是下一步 Attention 所需輸入
- Step 6: 又回到了 Attention 階段,所有前序 Combine 操作都在后臺通過 RDMA 執行
3.3 性能表現
使用 NVLink 和 RDMA 轉發的常規內核
DeepSeek 在 H800 GPU 上測試了常規內核(NVLink 最大帶寬約為 160 GB/s),每塊 GPU 連接一張 CX7 InfiniBand 400 Gb/s RDMA 網卡(最大帶寬約為 50 GB/s)。此外,遵循 DeepSeek-V3/R1 的預訓練設置,包括每批 4096 個 token、隱藏層維度 7168、Top-4 分組、Top-8 專家、FP8 分發以及 BF16 結果合并。性能測試的結果如下表所示:
| Type | Dispatch #EP | Bottleneck bandwidth | Combine #EP | Bottleneck bandwidth |
| Intranode | 8 | 153 GB/s (NVLink) | 8 | 158 GB/s (NVLink) |
| Internode | 16 | 43 GB/s (RDMA) | 16 | 43 GB/s (RDMA) |
| Internode | 32 | 58 GB/s (RDMA) | 32 | 57 GB/s (RDMA) |
| Internode | 64 | 51 GB/s (RDMA) | 64 | 50 GB/s (RDMA) |
使用純 RDMA 的低延遲內核
DeepSeek 在 H800 GPU 上測試了低延遲內核,每塊 GPU 連接一張 CX7 InfiniBand 400 Gb/s RDMA 網卡(最大帶寬約為 50 GB/s)。此外,遵循典型的 DeepSeek-V3/R1 生產環境設置,包括每批 128 個 token、隱藏層維度 7168、Top-8 專家、FP8 分發以及 BF16 結果合并。性能測試的結果如下表所示:
| Dispatch #EP | Latency | RDMA bandwidth | Combine #EP | Latency | RDMA bandwidth |
| 8 | 77 us | 98 GB/s | 8 | 114 us | 127 GB/s |
| 16 | 118 us | 63 GB/s | 16 | 195 us | 74 GB/s |
| 32 | 155 us | 48 GB/s | 32 | 273 us | 53 GB/s |
| 64 | 173 us | 43 GB/s | 64 | 314 us | 46 GB/s |
| 128 | 192 us | 39 GB/s | 128 | 369 us | 39 GB/s |
| 256 | 194 us | 39 GB/s | 256 | 360 us | 40 GB/s |
3.4 通信方案
DeepEP 是專門針對 MoE 模型大規模專家并行場景進行優化的高效通信庫,其依賴 NVIDIA 軟件生態的 NVSHMEM GPU通信庫、GDRCopy 低延時 GPU 顯存拷貝庫及 IBGDA 等核心技術,實現了經典的以 NCCL 為主的高效集合通信庫的功能。官方 DeepSeek-R1 的推理系統即是依賴 DeepEP+NVSHMEM+GDRCopy+IBGDA 的方案替代了 NCCL 進行高效通信的。整個軟件棧的架構圖如下:
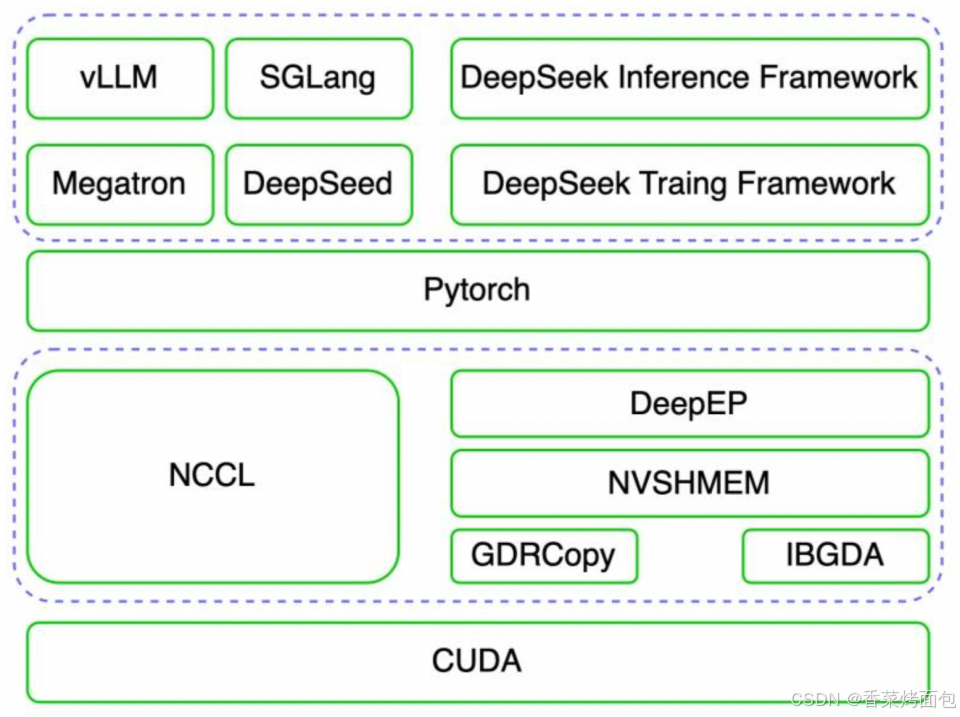
- 最底層:CUDA(NVIDIA GPU 驅動層):CUDA 是 NVIDIA 提供的通用 GPU 編程平臺,為上層通信與計算庫提供基礎執行環境和硬件控制接口
- 第 2 層:通信加速庫:NCCL —— 傳統的 GPU 通信庫;DeepEP + NVSHMEM + GDRCopy + IBGDA —— DeepSeek 通信方案
- 第 3 層:PyTorch 框架層
- 第 4 層:訓練與推理部署框架
NVSHMEM 通信庫
DeepEP 利用了 NVSHMEM 的能力進行高效通信。NVSHMEM(NVIDIA SHared MEMory)是 NVIDIA 專為多 GPU 環境下的高效通信與共享內存訪問開發的一套通信庫。它基于 OpenSHMEM 通信模型,結合了 GPU-Direct、RDMA 和 CUDA 技術,實現了 低延遲、無 CPU 參與、GPU 到 GPU 直接數據傳輸。
其核心思想是將所有 GPU 節點上的顯存視為一個大的顯存池來進行管理即分區全局地址空間(PGAS),所有參與通信的 GPU 都能 訪問全局地址空間中的任意段內存,圖中綠色框內的內存,其他 GPU 可直接讀寫,不依賴 CPU 參與。該庫支持通過GPU共享內存直接進行數據訪問,提供如 shmem_put、shmem_get 等可以進行細粒度數據傳輸的 API 接口。這些 API 都可以從 GPU kernel 內部直接調用,不需 host 配合,是 NVSHMEM 區別于 NCCL 的關鍵能力。
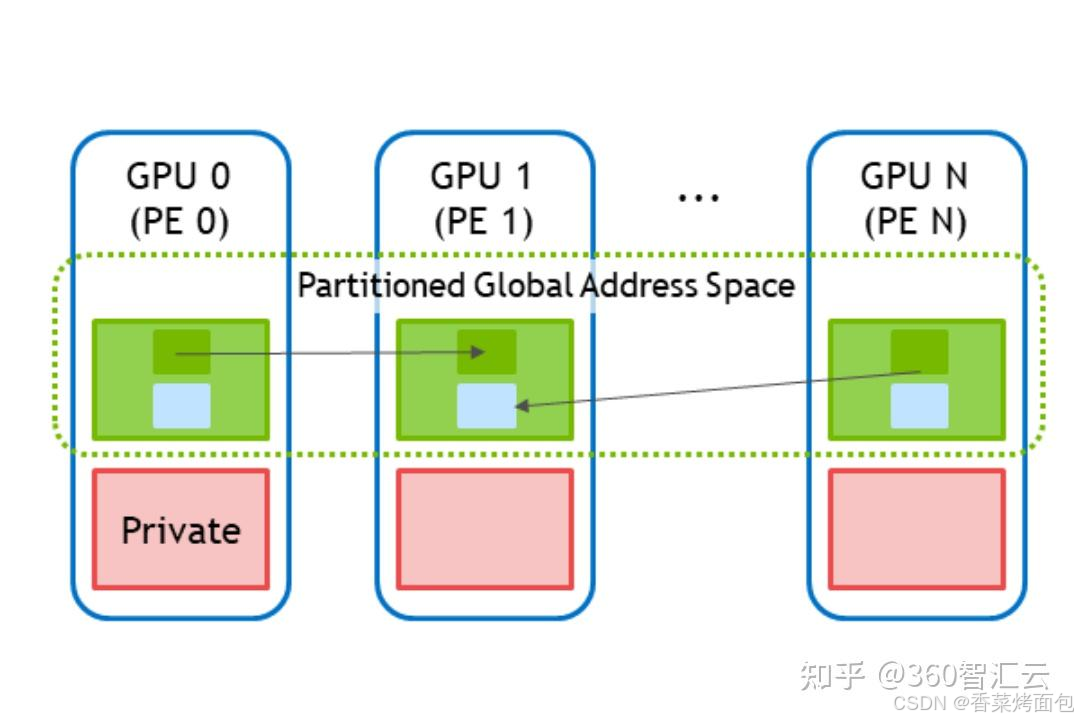
NCCL VS NVSHMEM
NVSHMEM通信庫和經典的NCCL集合通信庫的對比:
| | NCCL | NVSHMEM |
| 設計目標 | GPU集合通信 | GPU共享內存通信 |
| API設計 | 更高級別的API ncclAllReduce、ncclAllGather... API設計簡潔 | 更低級別的API,對共享內存、同步、數據傳輸等進行細粒度控制 shmem_put、shmem_get… |
| 高性能模式 | 支持NVLink、GDR | 支持NVLink、GDR、IBGDA |
| 使用場景 | 大規模分布式數據并行或模型并行 | 應用程序需要直接對內存進行操作 |
GDRCopy 低延時庫
GPU ? CPU 之間數據拷貝方式的原理和性能差異:cudaMemcpy 和 GDRCopy:
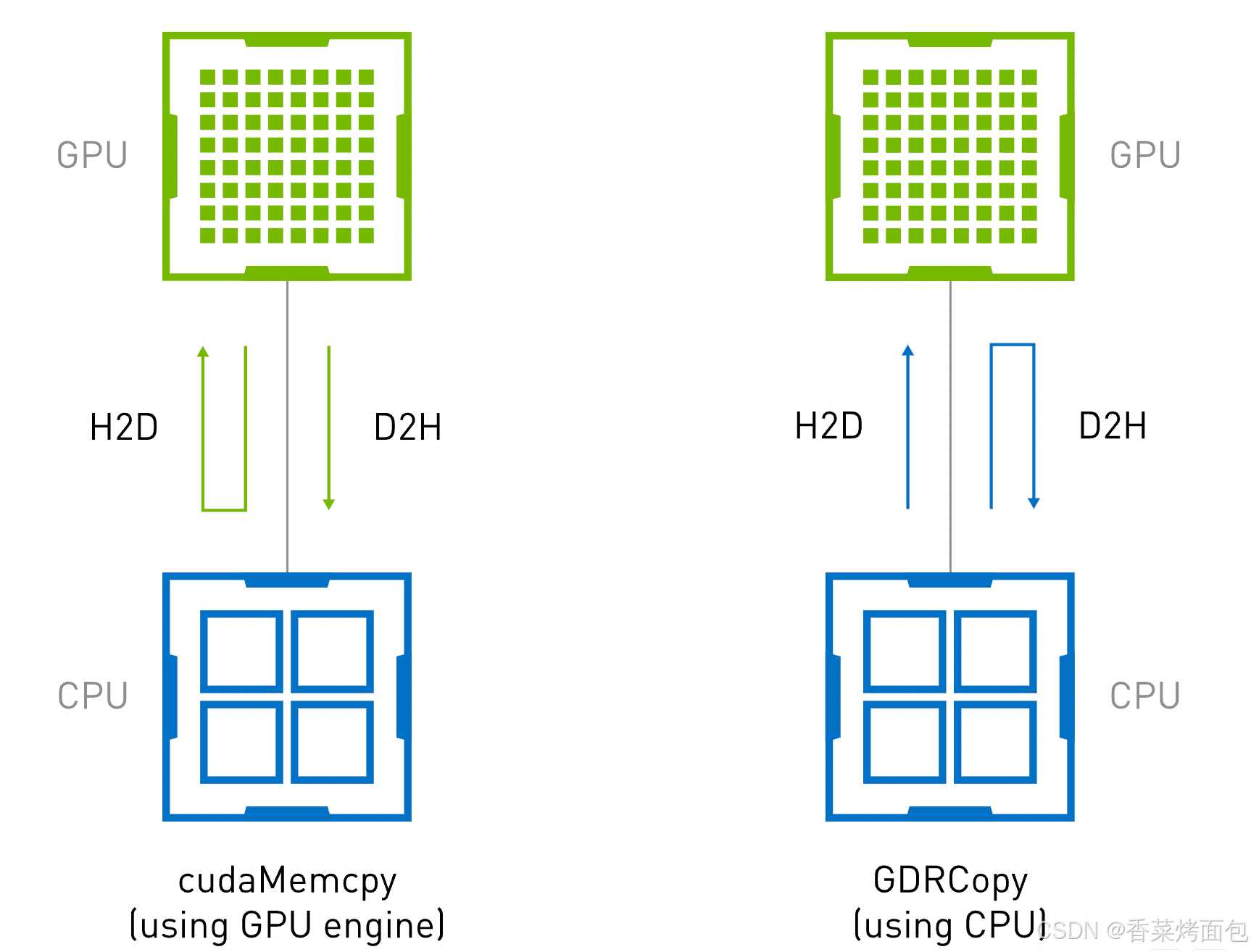
- cudaMemcpy 是 CUDA 提供的標準 API,用于在 GPU 與 CPU 之間傳輸數據。其工作機制是:觸發 GPU 的 DMA 引擎(Direct Memory Access Engine),由它將數據從 GPU 顯存拷貝到 CPU 內存,或反過來。
- GDRCopy 是基于 GPUDirect RDMA 技術的低延時 GPU 顯存拷貝庫,允許 CPU 直接訪問 GPU 顯存。它的關鍵機制是:使用 PCIe 的 BAR(Base Address Register)映射機制,將 GPU 顯存映射到 CPU 地址空間。CPU 可以像訪問普通內存一樣,直接訪問 GPU 顯存,實現低延遲的數據讀取與寫入,不需要觸發 DMA 引擎,也不需要上下文切換
從下圖中可以看出,在使用了 GDRCopy 后,H2D 的鏈路縮短了,這優化了 H2D 的延時。NVIDIA 官方給出的性能測試結果如下:
- 測試環境: NVIDIA DGX-1V 服務器,8 個 Tesla V100 GPU,CUDA 10.1,Driver 418
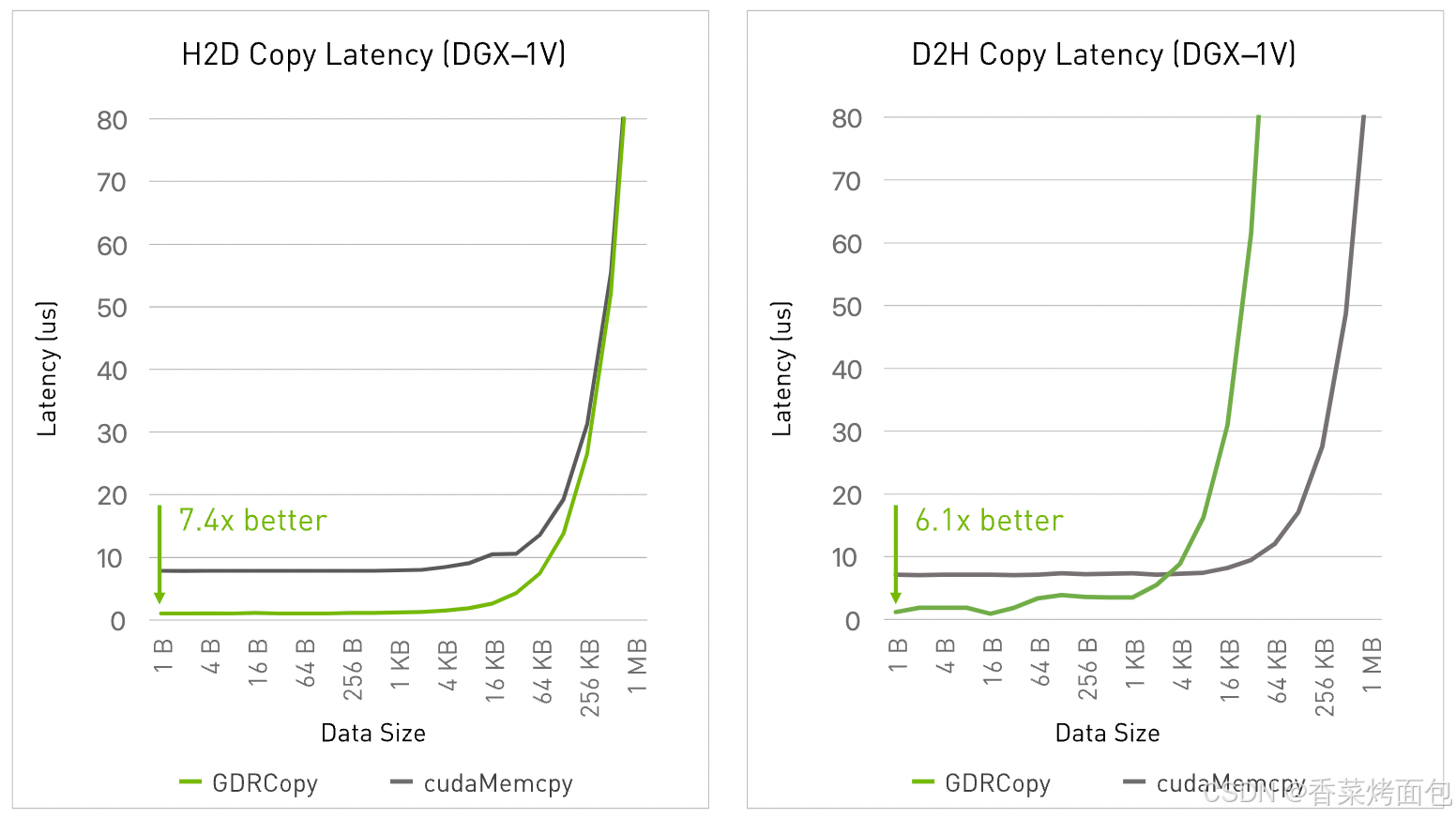
- 在小數據量下實現極低的主機與設備之間的數據傳輸延遲:主機到設備(Host-to-Device)拷貝的延遲大約為 1 微秒,而使用 cudaMemcpy 的延遲約為 7 微秒
- 高帶寬的主機到設備內存拷貝:通過 寫合并(write-combining)(受 NUMA 結構影響)或在部分基于 POWER9 架構的平臺上通過 緩存映射(cached mappings) 實現更高帶寬
在一個 MoE 路由推理中:每個 token 會分發到多個專家 → 分發數據是 小塊 token embedding,使用 cudaMemcpy,每次 token 分發都需要 DMA 調度,延遲高;使用 GDRCopy,CPU 或其他 GPU 線程能 直接寫入目標 GPU 顯存中的 expert buffer,快速且高效。
InfiniBand GPUDirect Async技術
IBGDA 與 IBRC
- InfiniBand GPUDirect Async 簡稱 IBGDA,是 NVIDIA 推出的基于 InfiniBand GPUDirect RDMA(簡稱GDR)技術進一步優化的高效通信技術。
- IBRC(InfiniBand Reliable Connection)是 InfiniBand 協議棧中定義的一種傳輸模式,屬于 InfiniBand 協議自身的通信語義。
技術細節對比:
| | IBRC | IBGDA |
| 通信控制 | 由 CPU 代理線程 發起和管理 | 由 GPU 內核線程(CTA) 直接發起 |
| RDMA 支持 | 使用 GPUDirect RDMA,但依賴 CPU 協調 | 基于 GPUDirect RDMA 的進一步優化版本 |
| 小消息處理 | CPU 線程串行化帶來瓶頸,帶寬低、延遲高 | GPU 線程并發發起,帶寬高、延遲低 |
| 大消息傳輸 | 通過 RDMA pipeline 實現高帶寬,效果好 | 仍可用,但對大消息不如 IBRC 穩定 |
| 通信并行性 | 受限于代理線程調度 | 支持 成百上千個 CTA 并發通信 |
| 自動合并功能 | 無 | 有:在地址連續的 warp 內自動合并消息,減少消息數量,降低開銷 |
| 適配場景 | Prefill(傳輸大 token embeddings) | Decode(高頻小 token 廣播) |
- 打個比方:IBRC 像是讓“前臺客服”用一個電話一個電話撥號傳消息(適合講清楚一個大段內容),慢但穩定;BGDA 像是讓“廣播系統”同時對幾十人喊話,適合快速同步短內容
- IBGDA 主要用于LLM 推理階段的 Decode 中,每生成一個 token,需要將它廣播到多個 GPU(或者多個進程),每條消息的大小很小(通常是幾個 byte 到十幾 KB),通信非常頻繁,每一步 decode 都要同步,IBGDA 是 GPU 多線程并發、無代理線程,能提供更高消息速率,吞吐和延遲表現遠好于 IBRC。
通信流程
在介紹 IBGDA 之前,先看下 NVSHMEM 在引入 IBGDA 之前、使用 CPU 代理線程 + IBRC 傳輸模式 下通信流程:
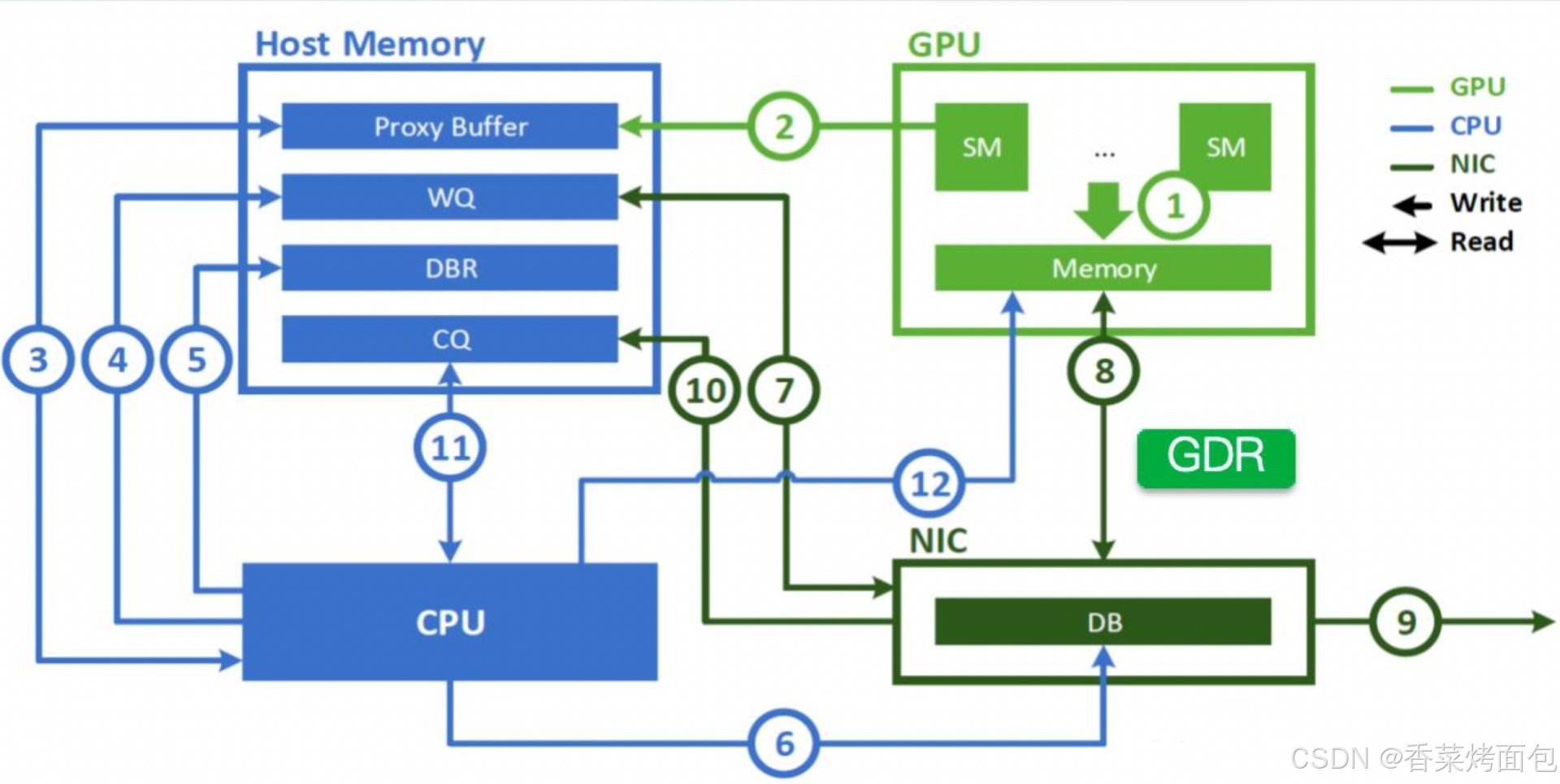
整個流程如下:① GPU 的 SM 通過 CUDA kernel 在本地 GPU memory 中生成需要通信的數據;②GPU 使用 nvshmem_put 等接口,把通信請求寫入主機內存的 Proxy Buffer(給CPU代理線程讀取的任務描述區域);③ CPU代理線程檢測 Proxy Buffer 中的新任務,發現新數據后,開始準備通信;④ CPU 將任務寫入 WQ(Work Queue),WQ 位于主機內存中,由 NIC 網卡讀取;⑤ CPU 寫入 DBR(Doorbell Record),寫入它是為了容錯,如果 NIC 忽略了真實門鈴(DB),可以從 DBR 中恢復;⑥ CPU 通過 PCie 向 NIC 的 Doorbell 寄存器發信號(寫DB);⑦ NIC 讀取 WQ 中的工作請求;⑧ NIC 用 GDR 從 GPU memory 直接讀取數據,不再走 CPU 中轉,直接從 GPU memory 中拷貝要發送的數據;⑨ NIC 通過 InfiniBand 通道將數據發送到其他節點(GPU 或 Host);通信完成后,⑩ NIC 寫入 Completion Queue(CQ)表示操作完成,通知 CPU 當前 RDMA 操作完成;? CPU 代理線程周期性輪詢 CQ,檢測哪些操作已經完成;? CPU 通知 GPU 內存,告訴它數據是否成功發送(使用了 GDRCopy,CPU 直接把狀態寫到 GPU memory,否則寫回 Proxy Buffer,讓 GPU kernel 自己去 poll)
總結:GPU發起通信請求寫入 Proxy Buffer,代理線程讀取請求,準備并通知 NIC,NIC 從 GPU memory 讀取數據并發送,通信完成后,NIC 通知 CPU,CPU 通知 GPU
從上述流程可以看出,多跳通信路徑 GPU → Host 內存 → CPU → NIC,有比較多的非應用數據傳輸的步驟需要 CPU 的參與,由于 GPU 和 Mellanox 高性能網卡的數據處理能力都在快速增長,且遠遠超過 CPU 的處理能力,因此在對延時有極高要求的場景下,經典的 GDR 技術在 CPU 側會成為瓶頸,CPU 不可能每秒處理數十億次通信請求,這也正是 IBGDA 設計要解決的核心問題:讓 GPU 自己直接驅動 NIC,繞過 CPU 全部流程!
為進一步優化通信效率,NVIDIA在GDR的基礎上推出了IBGDA,如下圖所示:
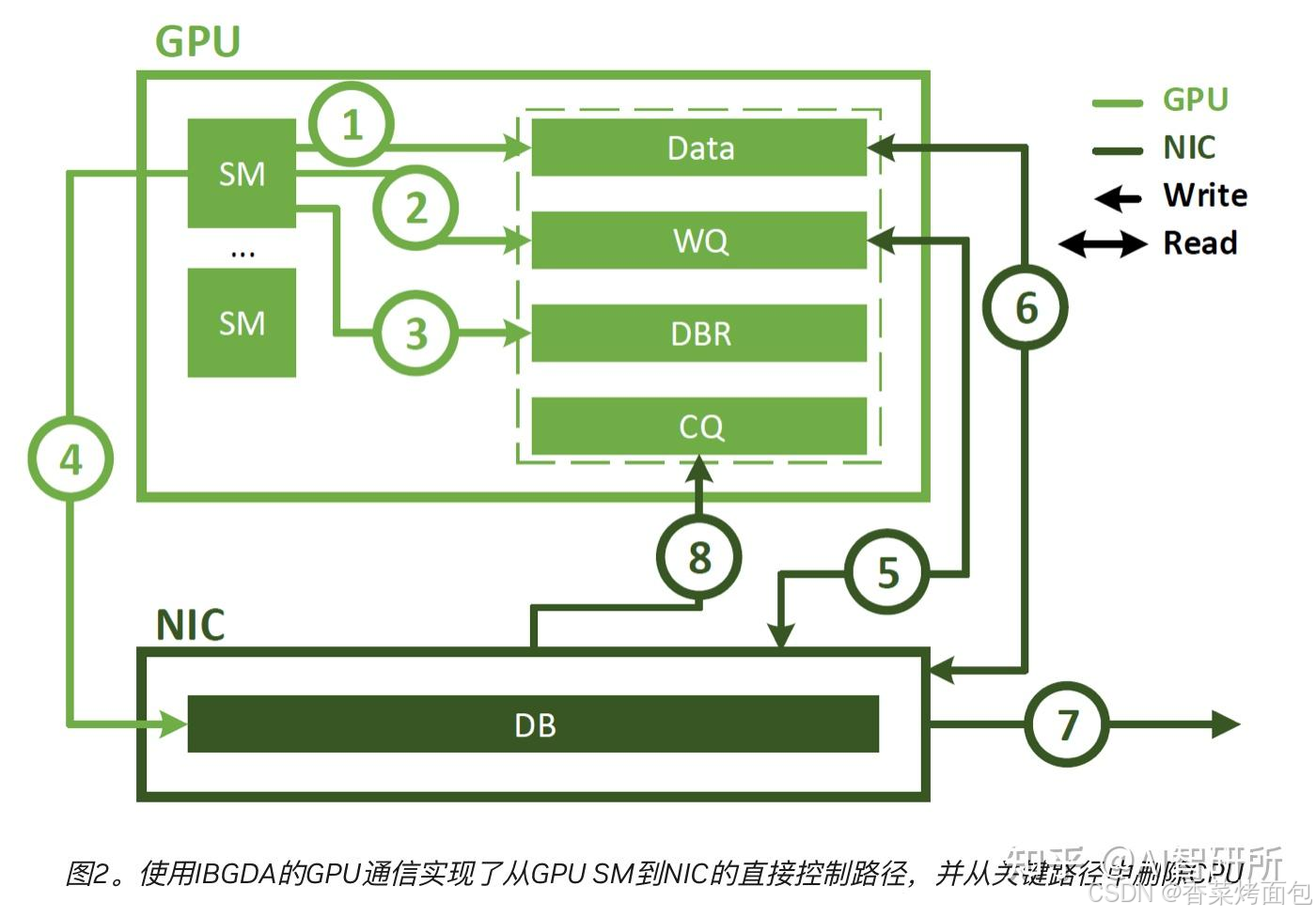
整個流程如下:① CUDA Kernel 在 GPU 的 SM 上運行,生成數據并寫入 GPU memory 中的 Data 緩沖區,準備要傳輸的數據;② SM 直接寫入 GPU memory 中的 WQ,這個步驟是傳統上由 CPU 代理完成的,現在變成了 GPU 自主完成;③ SM 更新 DBR 緩沖區,這個緩沖區用于回退或輔助通知 NIC。和 WQ 一樣,也放在 GPU memory 中,便于 GPU 快速訪問;④ SM 直接寫入 NIC 的 DB(doorbell)寄存器,通知 NIC 去讀取 WQ,開始執行通信操作(?? 這是一個關鍵突破點:GPU 不再需要 CPU 中轉,能像 CPU 一樣直接下發網絡操作!);⑤ NIC 收到 DB 通知后,從 GPU memory 中讀取 SM 寫入的 WQ 描述符(使用GDR),了解該做什么操作。⑥ NIC 根據 WQ 中描述的地址,從 GPU memory 中讀取實際數據(也是通過GDR),準備發送;⑦ 將數據通過 InfiniBand 網絡發送到其他節點的 GPU/Host;⑧ 數據傳輸完成后,NIC 使用 GDR 向 GPU memory 中的 CQ(Completion Queue) 寫入事件,告知 GPU 操作完成。
從上述流程可以看出,IBGDA 將在 CPU 上進行的相關操作全部放到 GPU 中,整個過程完全不需要 CPU 的參與,進一步減少了通信鏈路,提高了通信效率。
小結:
| | 傳統 IBRC + CPU Proxy | IBGDA(Kernel-Initiated) |
| 控制流程 | GPU → Host Proxy Buffer → CPU 代理線程 → NIC | GPU SM → NIC(直接) |
| WQ/DBR/CQ 位置 | Host Memory | GPU Memory |
| Doorbell 發起者 | CPU | GPU |
| 數據路徑 | GDR 從 GPU memory 讀取 | GDR 從 GPU memory 讀取(一樣) |
| 通信延遲 | 高,受 CPU 調度限制 | 低,無中間人 |
| 并發能力 | 限制在 CPU 上 | 支持數千個 GPU CTA 并發 |
| 適合場景 | Prefill、大消息批量傳輸 | Decode、細粒度通信 |
? 什么是 Doorbell?
- Doorbell(門鈴) 是網絡接口卡(NIC)中的一個 特殊寄存器或地址空間,它的作用是通知 NIC 有新的通信請求需要處理
- 發起方(CPU 或 GPU)寫入 Doorbell 寄存器 → 相當于“按了一下門鈴”
- 接收方(NIC)收到這個寫操作后 → 就知道:“哦,有新任務來了,我要去工作隊列看看”
- Doorbell 不傳輸數據,也不是控制命令的詳細內容,它只是一個“輕量級觸發器”
? Doorbell 工作在哪一層?
- Doorbell 是 RDMA / InfiniBand 等 通信協議棧的底層機制之一,用于將 通信請求從主機控制單元(CPU/GPU)提交給 NIC 執行
- 在通信流程中,每次構造了一個 RDMA 操作,將操作信息寫入 Work Queue(WQ),必須寫 Doorbell,告訴 NIC “現在有新任務了,請去看 WQ”,NIC 就會去解析 WQ 中的描述符并發起通信操作
? 什么是 DBR(Doorbell Record)
- Doorbell Record,是一個位于主機或 GPU 內存中的緩沖區,它是 Doorbell(DB)寫操作的副本或備份,用于支持:容錯、重放(replay)、以及 NIC 對 Doorbell 操作的冗余備份讀取。維護一份 DBR,NIC 可以定期從 DBR 中拉取數據,確保不會漏任務
- DBR 是一種冗余機制,作為 Doorbell 寫入的內存記錄副本,用于容錯和冗余恢復,確保 NIC 不會錯過任務
NVIDIA 官方基于 IBGDA 技術在 All-to-All 場景下的延時測試如下:
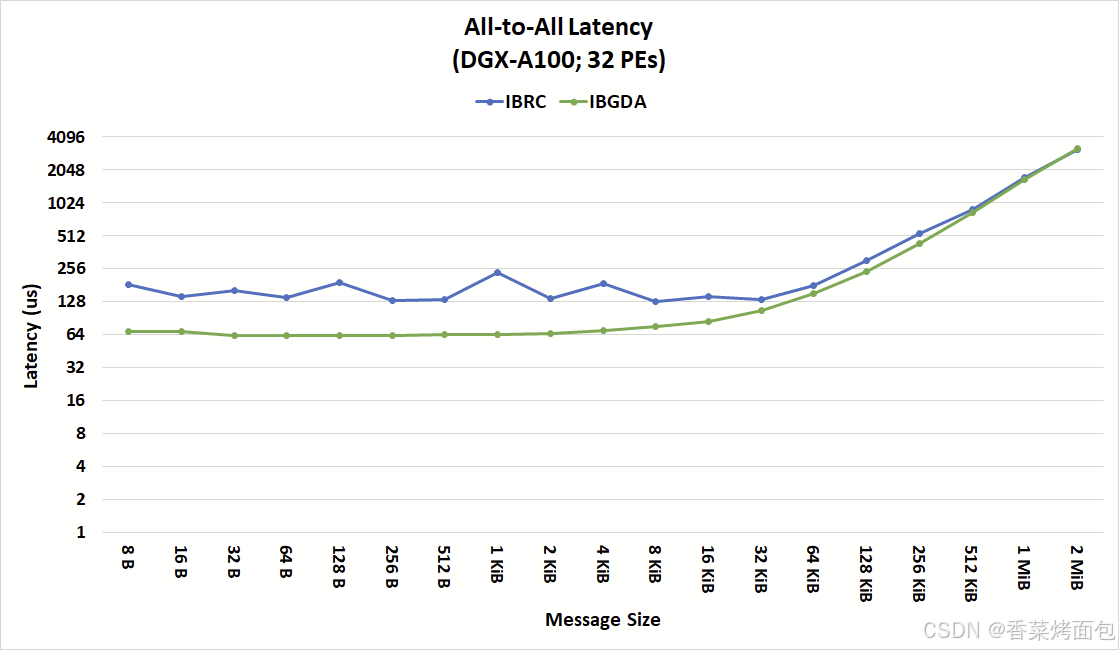
- IBRC 在大消息傳輸時能夠達到高帶寬,但對于小消息存在性能瓶頸,更適合大消息的批量傳輸。
- IBGDA 在小消息傳輸中表現出色,能夠實現更高的吞吐量和更低的延遲,更適合涉及大量小消息的細粒度通信。
通信模式對比:
| 通信方式 | 是否需 CPU | 延遲 | GPU 直達 | 應用場景 |
| NCCL All-to-All | ? 需要 | 高 | ? | 通用集合通信 |
| CUDA Memcpy | ? 可繞過 | 中 | ?? 僅同節點 | 拷貝數據用 |
| NVSHMEM | ? 不需要 | 低 | ? | Token 精細調度、MoE 通信 |
| GDRCopy | ? 不需要 | 低 | ? | 高速內存拷貝 |
| MPI | ? 需要 | 高 | ? | CPU 主導并行 |
4. EPLB
EPLB(Expert Parallel Load Balancing,專家并行負載均衡器)是 DeepSeek 為解決 MoE 模型在分布式訓練和推理中的負載不平衡問題而開發的優化策略。
平衡每張 GPU 上的工作負載:
- 問題:在專家并行中,不同的專家會被分配到不同的 GPU 上運行,導致每張 GPU 上的專家負載不均,部分 GPU 空轉或擁堵
- 解決方案:EPLB 采用了 “冗余專家” 策略,即復制高負載的專家,然后將這些復制后的專家合理分配到各個 GPU 上,以實現負載均衡
在 DeepSeek-V3 的訓練中,EPLB 將 GPU 利用率提升超 30%,減少因負載不均導致的節點空轉現象,通過優化專家任務的本地化計算,跨節點通信量減少約25%,尤其在高稀疏性MoE模型(如每層僅激活8/256個專家)中效果顯著。
基本原理
- 冗余專家策略:實時監控每個專家的計算負載,創建高負載專家副本,從而分散計算壓力
- 通信優化:將關聯性強的專家模塊部署在同一計算節點,降低跨節點通信的數據量,從而減少網絡帶寬占用和延遲
- 無輔助損失的負載均衡:區別于傳統方法需引入額外的負載均衡損失函數,EPLB通過可學習的偏置項(Bias Term),動態調整專家激活概率(降低高負載專家的激活權重,提升低負載專家的優先級),不增加訓練目標復雜性的情況下實現均衡
- 跨并行模式的協同優化:EPLB支持與數據并行(DP)、專家并行(EP)等多種并行策略協同工作,通過全局調度器協調不同并行模式下的資源分配,避免單一策略的局限性
4.1 負載均衡策略
EPLB 負載均衡算法提供了兩種策略,適用于不同的場景:
- 分層負載均衡(Hierarchical Load Balancing):當服務器節點數量能夠整除專家組數量時,使用該策略來利用分組限制專家路由。具體步驟為:首先將專家組均勻分配到各個節點,確保不同節點的負載平衡;然后在每個節點內復制專家;最后將復制后的專家分配到各個 GPU 上,確保不同 GPU 的負載平衡。該策略適用于預填充階段,專家并行規模較小的情況。
- 全局負載均衡全局負載均衡全局負載均衡(Global Load Balancing):在全局范圍內復制專家,不考慮專家組的劃分,然后將復制后的專家分配到各個 GPU 上。該策略適用于解碼階段,專家并行規模較大的情況。
4.2 DeepSeek 負載均衡方案
Prefill 階段:路由專家 EP32、MLA 和共享專家 DP32,一個部署單元是 4 節點,32 個冗余路由專家,每張卡 9 個路由專家和 1 個共享專家
- Prefill 是生成任務中輸入 token 的處理階段,特點是并行度高(多個 token 同時處理),計算密集,容易產生專家負載不均
- EP32(路由專家):每層用 32 個路由專家副本參與計算(實際上是從 256 個專家中按需復制出來的)
- DP32(共享專家):每層有 1 個共享專家,復制到每個 GPU 上,采用 Data Parallel
- 冗余路由專家:32 個 —— 這些是對 負載較高的專家 進行復制,以分擔負載
- GPU 數:部署單元 = 4 節點 × 每節點 8 卡 = 32 卡;專家副本數量:256 + 32 = 288(路由專家副本總數);平均每張卡分配:288 / 32 = 9 個路由專家/卡
- 專家組:32 個專家組,每組 9 個專家(288 / 32 = 9),每個專家組就部署在一個 GPU 上
Decode 階段:路由專家 EP144、MLA 和共享專家 DP144,一個部署單元是 18 節點,32 個冗余路由專家,每張卡 2 個路由專家和 1 個共享專家
- Decode 是生成 token 時逐個處理的階段,token 數量少,但對延遲要求高
- EP144(路由專家):每層有 144 個路由專家副本
- DP144(共享專家):每個 GPU 上也部署一個共享專家
- 冗余專家:32 個副本(和 Prefill 類似,拷貝負載高的專家)
- 節點數 = 18 × 每節點 8 卡 = 144 張卡,所以 144 張卡 × 2 = 288 個路由專家副本
小結:
| 階段 | 路由專家配置 | 節點數 | 每卡專家數(路由 + 共享) | 冗余專家 | 特點說明 |
| Prefill | EP32 + DP32 | 4 | 9 路由 + 1 共享 | 32 | token 多,需高吞吐,專家負載不均,復制高負載專家 |
| Decode | EP144 + DP144 | 18 | 2 路由 + 1 共享 | 32 | token 少,需低延遲,資源分得更分散 |
DeepSeek-R1 為了解決 MoE 推理階段負載不均問題采用了靜態 + 局部冗余復制(32 個專家副本),根據階段切換部署策略(Prefill 更集中,Decode 更分散),每卡部署有限個專家,避免內存溢出,同時提升負載均衡,兼顧了吞吐量(Prefill)與延遲(Decode)。
4.3 源碼分析
項目地址:https://github.com/deepseek-ai/eplb
代碼就一個eplb.py,它實現了負載均衡算法的核心代碼,包含以下主要函數:
- replicate_experts:將邏輯專家復制為物理專家,以最小化所有副本的最大負載
- balanced_packing:將加權對象打包到指定數量的包中,使每個包的權重盡可能平衡
- rebalance_experts_hierarchical:實現分層負載均衡策略
- rebalance_experts:負載均衡算法的入口函數,根據情況選擇合適的負載均衡策略
- inverse:用于計算排列的逆排列
from typing import Tuple # 導入元組類型注解
import torch # 導入 PyTorch 庫def balanced_packing(weight: torch.Tensor, num_packs: int) -> Tuple[torch.Tensor, torch.Tensor]:"""采用貪心算法:將 n 個帶權重的對象打包到 m 個包中,使得每個包恰好包含 n/m 個對象,并且所有包的權重盡可能平衡參數:- weight: 一個形狀為 [X, n] 的 PyTorch 張量,代表權重- num_packs: 包的數量返回: pack_index: [X, n],每個物品所在的包的索引rank_in_pack: [X, n],物品在包中的排名"""# 1.平均分組,從而實現包的權重平衡(R1 的專家數量 256 個比較多,并不是一個一個去分配,首先會進行一個合并,合并成 num_groups 組,然后將 group 分配到不同節點上)num_layers, num_groups = weight.shape # 獲取權重張量的層數和組數assert num_groups % num_packs == 0 # 確保組數能被包數整除groups_per_pack = num_groups // num_packs # 計算每個包中的組數# 2. 特殊情況處理:如果每個包只有一個組,計算每個組的包索引和排名并返回,從而為后續的負載均衡提供信息if groups_per_pack == 1: # 生成每個組的包索引pack_index = torch.arange(weight.size(-1), dtype=torch.int64, device=weight.device).expand(weight.shape)rank_in_pack = torch.zeros_like(weight, dtype=torch.int64) # 生成每個組在包中的排名return pack_index, rank_in_pack # 返回包索引和排名# 3. 處理每個包含有多個分組的情況indices = weight.float().sort(-1, descending=True).indices.cpu()# 對權重張量進行降序排序并獲取索引,從而優先處理權重較大的組pack_index = torch.full_like(weight, fill_value=-1, dtype=torch.int64, device='cpu')# 初始化包索引張量,初始值為-1表示未分配rank_in_pack = torch.full_like(pack_index, fill_value=-1) # 初始化每個組在包中的排名張量,初始值為 -1for i in range(num_layers): # 外層循環遍歷每個包pack_weights = [0] * num_packs # 初始化每個包的權重pack_items = [0] * num_packs # 初始化每個包中的物品數量for group in indices[i]: # 內層循環遍歷當前層的每個組# 核心:對于每個組,找到當前權重最小且物品數量未達到上限的包,將該組分配到這個包中。pack = min((i for i in range(num_packs) if pack_items[i] < groups_per_pack), key=pack_weights.__getitem__)assert pack_items[pack] < groups_per_pack # 確保所選包中的物品數量未達到上限pack_index[i, group] = pack # 記錄當前組所在的包的索引rank_in_pack[i, group] = pack_items[pack] # 記錄當前組在包中的排名pack_weights[pack] += weight[i, group] # 更新所選包的權重pack_items[pack] += 1 # 更新所選包中的物品數量return pack_index, rank_in_pack # 返回包索引和排名def replicate_experts(weight: torch.Tensor, num_phy: int) -> Tuple[torch.Tensor, torch.Tensor, torch.Tensor]:"""創建冗余專家,具體是將 num_log 個邏輯專家復制為 num_phy 個物理專家副本,遍歷冗余專家并將每個冗余專家映射到當前負載最大的邏輯專家參數:weight: [X, num_log] 形狀的張量,代表每個邏輯專家的負載num_phy: 復制后專家的總數返回:phy2log: [X, num_phy] 形狀的張量,phy2log[i][j] 表示在第 i 個場景下,第 j 個物理專家對應的邏輯專家的 IDrank: [X, num_phy] 形狀的張量,rank[i][j] 表示在第 i 個場景下,第 j 個物理專家是其對應邏輯專家的第幾個副本logcnt: [X, num_log] 形狀的張量,logcnt[i][k] 表示在第 i 個場景下,第 k 個邏輯專家有多少個物理專家副本"""# 1. 獲取專家的相關信息n, num_log = weight.shape # 獲取權重張量的行數和邏輯專家數量num_redundant = num_phy - num_log # 計算冗余專家的數量assert num_redundant >= 0 # 確保冗余專家數量非負device = weight.device # 獲取權重張量所在的設備# 2. 初始化映射和phy2log = torch.arange(num_phy, dtype=torch.int64, device=device).repeat(n, 1) # 初始化物理專家到邏輯專家的映射rank = torch.zeros(n, num_phy, dtype=torch.int64, device=device) # 表示每個物理專家在其對應的邏輯專家副本中的次序logcnt = torch.ones(n, num_log, dtype=torch.int64, device=device) # 初始化每個邏輯專家的物理專家副本數量arangen = torch.arange(n, dtype=torch.int64, device=device) # 生成一個從 0 到 n-1 的張量,n 代表組的數量# 3. 復制邏輯專家為物理專家副本for i in range(num_log, num_phy): # 遍歷冗余專家(邏輯專家num_log到物理專家num_phy間為冗余的)redundant_indices = (weight / logcnt).max(dim=-1).indices # 找到負載最大的邏輯專家的索引phy2log[:, i] = redundant_indices # 將當前物理專家映射到負載最大的邏輯專家,更新 phy2log 張量rank[:, i] = logcnt[arangen, redundant_indices] # 記錄當前物理專家的副本排名,更新 rank 張量logcnt[arangen, redundant_indices] += 1 # 更新負載最大的邏輯專家的副本數量,更新 logcnt 張量。# 返回物理專家到邏輯專家的映射、副本排名和邏輯專家的副本數量return phy2log, rank, logcntdef rebalance_experts_hierarchical(weight: torch.Tensor, num_physical_experts: int, num_groups: int, num_nodes: int, num_gpus: int):"""分層負載均衡策略,將邏輯專家復制為物理專家副本,并在節點和 GPU 層面進行負載均衡參數:weight: [num_moe_layers, num_logical_experts] 形狀的張量,代表每個邏輯專家的負載num_physical_experts: 復制后物理專家的總數num_groups: 專家組的數量num_nodes: 服務器節點的數量,節點內網絡(如 NVLink)更快num_gpus: GPU 的數量,必須是 num_nodes 的倍數返回: physical_to_logical_map: [num_moe_layers, num_physical_experts] 形狀的張量,每個物理專家對應的邏輯專家的 IDlogical_to_physical_map: [num_moe_layers, num_logical_experts, X] 形狀的張量,每個邏輯專家對應的物理專家的索引logical_count: [num_moe_layers, num_logical_experts] 形狀的張量,每個邏輯專家的物理專家副本數量"""# 1. 輸入檢查與初始化num_layers, num_logical_experts = weight.shape # 獲取權重張量的層數和邏輯專家數量assert num_logical_experts % num_groups == 0 # 確保邏輯專家數量能被專家組數量整除group_size = num_logical_experts // num_groups # 計算每個專家組中的專家數量assert num_groups % num_nodes == 0 # 確保專家組數量能被節點數量整除groups_per_node = num_groups // num_nodes # 計算每個節點中的專家組數量assert num_gpus % num_nodes == 0 # 確保 GPU 數量能被節點數量整除assert num_physical_experts % num_gpus == 0 # 確保物理專家數量能被 GPU 數量整除phy_experts_per_gpu = num_physical_experts // num_gpus # 計算每個 GPU 上的物理專家數量# 2. 定義逆排列計算輔助函數def inverse(perm: torch.Tensor) -> torch.Tensor:"""計算排列的逆排列,接受一個排列張量 perm 作為輸入,返回其逆排列"""inv = torch.empty_like(perm) # 初始化逆排列張量inv.scatter_(1, perm, torch.arange(perm.size(1), dtype=torch.int64, device=perm.device).expand(perm.shape)) # 計算逆排列return inv # 返回逆排列# 3. 階段的負載均衡# 3.1 將專家組分配到節點上tokens_per_group = weight.unflatten(-1, (num_groups, group_size)).sum(-1) # 計算每個專家組的總權重group_pack_index, group_rank_in_pack = balanced_packing(tokens_per_group, num_nodes) # 使用 balanced_packing 函數將專家組分配到節點上# log2mlog:表示邏輯專家在節點上的位置# mlog2log:表示節點上的位置對應邏輯專家的位置log2mlog = (((group_pack_index * groups_per_node + group_rank_in_pack) * group_size).unsqueeze(-1) + torch.arange(group_size, dtype=torch.int64, device=group_pack_index.device)).flatten(-2) # 計算邏輯專家到中間邏輯專家的映射mlog2log = inverse(log2mlog) # 計算中間邏輯專家到邏輯專家的映射# 3.2 在節點內創建冗余專家tokens_per_mlog = weight.gather(-1, mlog2log).view(-1, num_logical_experts // num_nodes) # 計算每個中間邏輯專家的總權重phy2mlog, phyrank, mlogcnt = replicate_experts(tokens_per_mlog, num_physical_experts // num_nodes) # 在節點內創建冗余專家# 3.3 將物理專家分配到 GPU 上,借助中間物理專家這個中間層,能分階段處理負載均衡問題tokens_per_phy = (tokens_per_mlog / mlogcnt).gather(-1, phy2mlog) # 計算每個物理專家的總權重pack_index, rank_in_pack = balanced_packing(tokens_per_phy, num_gpus // num_nodes) # 使用 balanced_packing 函數將物理專家分配到 GPU 上phy2pphy = pack_index * phy_experts_per_gpu + rank_in_pack # 計算物理專家到中間物理專家的映射pphy2phy = inverse(phy2pphy) # 計算中間物理專家到物理專家的映射pphy2mlog = phy2mlog.gather(-1, pphy2phy) # 計算中間物理專家到中間邏輯專家的映射pphy2mlog = (pphy2mlog.view(num_layers, num_nodes, -1) + torch.arange(0, num_logical_experts, num_logical_experts // num_nodes).view(1, -1, 1)).flatten(-2)pphy2log = mlog2log.gather(-1, pphy2mlog) # 計算物理專家到邏輯專家的映射pphyrank = phyrank.gather(-1, pphy2phy).view(num_layers, -1) # 計算每個物理專家的副本排名logcnt = mlogcnt.view(num_layers, -1).gather(-1, log2mlog) # 計算每個邏輯專家的副本數量return pphy2log, pphyrank, logcnt # 返回物理專家到邏輯專家的映射、副本排名和邏輯專家的副本數量def rebalance_experts(weight: torch.Tensor, num_replicas: int, num_groups: int,num_nodes: int, num_gpus: int) -> Tuple[torch.Tensor, torch.Tensor, torch.Tensor]:"""專家并行負載均衡器的入口點。參數:weight: [layers, num_logical_experts],所有邏輯專家的負載統計信息num_replicas: 物理專家的數量,必須是 `num_gpus` 的倍數num_groups: 專家組的數量num_nodes: 服務器節點的數量,節點內網絡(例如,NVLink)更快num_gpus: GPU 的數量,必須是 `num_nodes` 的倍數返回: physical_to_logical_map: [layers, num_replicas],每個副本對應的專家索引logical_to_physical_map: [layers, num_logical_experts, X],每個專家對應的副本索引expert_count: [layers, num_logical_experts],每個邏輯專家的物理副本數量"""# 1. 數據預處理num_layers, num_logical_experts = weight.shape # 獲取權重張量的層數和邏輯專家數量weight = weight.float().cpu() # 將權重張量轉換為 float 類型并移動到 CPU 上# 2. 策略選擇:如果專家組數量能被節點數量整除使用分層負載均衡,如果不能使用全局負載均衡if num_groups % num_nodes == 0:phy2log, phyrank, logcnt = rebalance_experts_hierarchical(weight, num_replicas, num_groups, num_nodes, num_gpus)else:phy2log, phyrank, logcnt = replicate_experts(weight, num_replicas)# 計算邏輯專家到物理專家的映射maxlogcnt = logcnt.max().item() # 獲取最大的邏輯專家副本數量# 初始化邏輯專家到物理專家的映射log2phy: torch.Tensor = torch.full((num_layers, num_logical_experts, maxlogcnt), -1, dtype=torch.int64, device=logcnt.device)# 計算邏輯專家到物理專家的映射log2phy.view(num_layers, -1).scatter_(-1, phy2log * maxlogcnt + phyrank, torch.arange(num_replicas, dtype=torch.int64, device=log2phy.device).expand(num_layers, -1))# 返回物理專家到邏輯專家的映射、邏輯專家到物理專家的映射和邏輯專家的副本數量return phy2log, log2phy, logcnt# 定義模塊的公共接口
__all__ = ['rebalance_experts']4.4 使用示例
pip install eplbEPLB 支持靈活的專家復制和分配,能夠適配不同規模的模型和硬件配置。
例如,在一個包含 2 個節點、每個節點 4 個 GPU 的集群上,EPLB 可以動態規劃專家副本的分配。兩層 MoE 模型,每層包含 12 名專家,每層引入 4 個冗余專家,總共 16 個副本放置在 2 個節點上:
# 使用 eplb.rebalance_experts 這個函數為一個兩層 MoE 模型進行專家負載均衡
import torch
import eplbweight = torch.tensor([[ 90, 132, 40, 61, 104, 165, 39, 4, 73, 56, 183, 86],[ 20, 107, 104, 64, 19, 197, 187, 157, 172, 86, 16, 27]]) # [2, 12]的張量表示兩層MoE模型中每個專家的當前負載(token調度次數)num_replicas = 16 # 每層總共有 16 個專家副本(原始12 + 冗余4)
num_groups = 4 # 每個 node 擁有的專家組數
num_nodes = 2 # 兩個物理節點(machines)
num_gpus = 8 # 總共 8 塊 GPU(每節點4塊)phy2log, log2phy, logcnt = eplb.rebalance_experts(weight, num_replicas, num_groups, num_nodes, num_gpus)
print(phy2log)# Output:
# tensor([[ 5, 6, 5, 7, 8, 4, 3, 4, 10, 9, 10, 2, 0, 1, 11, 1], # 第 1 層的 16 個副本對應的邏輯專家編號
# [ 7, 10, 6, 8, 6, 11, 8, 9, 2, 4, 5, 1, 5, 0, 3, 1]]) # 第 2 層的 16 個副本對應的邏輯專家編號
-
第 0 層:16 個物理副本分別負責專家 5, 6, 5, 7, ... 等(例如專家 5 被分配了兩個副本,專家 1 被分配了三個副本,等等)
style="display: none !important;">





:字符串操作與多維指針深度解析》)
)
)






和分布式集合(IgniteSet)的介紹)




