1. 概述
人臉識別是一種機器學習技術,廣泛應用于各種領域,包括出入境管制、電子設備安全登錄、社區監控、學校考勤管理、工作場所考勤管理和刑事調查。然而,當 COVID-19 引發全球大流行時,戴口罩就成了日常生活中的必需品。廣泛使用的人臉識別技術受到嚴重影響,傳統人臉識別技術的性能顯著下降。雖然在過去幾年中已有報道稱支持口罩的人臉識別模型達到了一定的準確度,但佩戴口罩對人臉識別的影響尚未得到充分研究。
因此,本文比較并評估了多種人臉識別模型在辨別 "蒙蔽 "和 "未蒙蔽 "人臉圖像時的性能。本文使用了六種傳統的機器學習算法:支持向量機(SVC)、K 近鄰(KNN)、線性判別分析(LDA)、決策樹(DT)、邏輯回歸(LR)和天真貝葉斯(NB)。(深度學習模型尚未經過驗證)。
它研究了蒙面人臉圖像的最佳和最差性能模型。論文還根據一個蒙面和未蒙面人臉圖像數據集以及一個半蒙面人臉圖像數據集對性能進行了評估。與以往的研究相比,本文的獨特之處在于研究了廣泛的面具佩戴數據和機器學習模型。
論文地址:https://arxiv.org/pdf/2306.08549.pdf
2. 機器學習模型和數據集
本文評估了六種模型:支持向量機(SVC/Support Vector Classifier)、線性判別分析(LDA/Linear Discriminant Analysis)、K-近鄰(KNN/K-Nearest Neighbours)、決策樹(DT/Decision Trees)、邏輯回歸(LR/Logistic Regression)和奈夫貝葉斯(NB/Na?ve Bayes)。(DT/決策樹)、邏輯回歸(LR/邏輯回歸)和奈夫貝葉斯(NB/奈夫貝葉斯)。
該數據集還使用了 (ORL),其中包含 41 個受試者和每個受試者 10 張圖像,共計 410 張未掩蓋的人臉圖像。下圖顯示了 ORL 的樣本數據。

本文使用開源軟件 MaskTheFace 為 ORL 人臉圖像添加面具,并制作出佩戴面具的人臉圖像。佩戴的面具是從六個面具模板中隨機選擇并添加的。下圖顯示了添加面具后的樣本數據。

2. 實驗細節
本文使用上述機器學習模型和數據集進行了六項實驗。請注意,在所有實驗中,特征提取都使用了局部二進制模式(LBP)算法。
**(實驗 1)**在為 41 名受試者每人準備的 10 幅圖像中,有 9 幅被用作未戴面罩的人臉圖像,并對 6 個機器學習模型進行訓練。在為 41 名受試者每人準備的 10 張圖像中,剩下的一張也用作無遮罩的人臉圖像,并對每個機器學習模型進行測試。
(實驗 2)在為 41 名受試者每人準備的 10 張圖像中,9 張作為未戴面罩的人臉圖像用于訓練 6 個機器學習模型。在為 41 名受試者每人準備的 10 張圖像中,剩下的一張圖像將與 MaskTheFace 一起使用,作為戴面具的人臉圖像對每個模型進行測試。圖 3
(實驗 3)在為 41 名受試者每人準備的 10 幅圖像中,有 9 幅被用作戴了面具的人臉圖像,并訓練了 6 個機器學習模型。在為 41 名受試者每人準備的 10 張圖像中,剩下的一張也被用作無面具人臉圖像,用于測試每個機器學習模型。
(實驗 4)在為 41 名受試者每人準備的 10 幅圖像中,有 9 幅被用作戴上面具后的人臉圖像,并訓練了 6 個機器學習模型。然后,使用 MaskTheFace 將為 41 名受試者分別準備的 10 幅圖像中的其余一幅圖像作為戴上面具的人臉圖像,對每個模型進行測試。圖 4
(實驗 5)在為 41 名受試者每人準備的 10 幅圖像中,保留一幅圖像用于測試,其余 9 幅圖像中的 4 幅在 MaskTheFace 軟件中組合為戴面具的人臉圖像,4 幅為未戴面具的人臉圖像,總共 8 幅人臉圖像。這樣就形成了一個半數人臉圖像戴有面具的數據集。利用這個數據集,可以訓練出六個機器學習模型,每個模型都要在一張未戴面具的人臉圖像上進行測試。
**(實驗 6)**使用實驗 5 中創建的數據集訓練了六個機器學習模型,該數據集由半張被遮擋的人臉圖像組成,每個模型都在單張被遮擋的人臉圖像上進行了測試。圖 5
3. 實驗結果
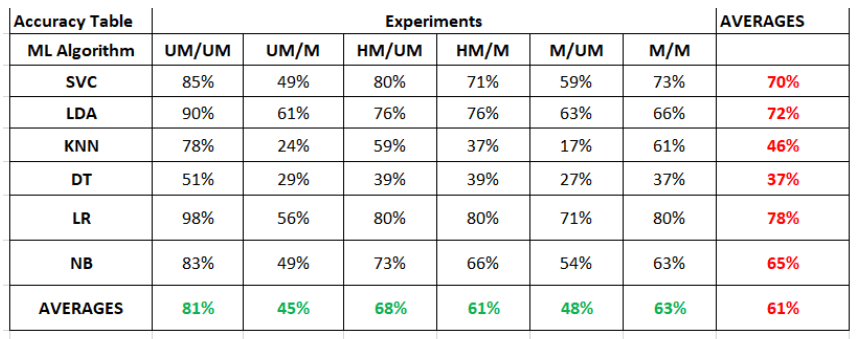
下表顯示了六個機器學習模型在所有六個實驗中的準確率。對于在未屏蔽人臉圖像(UM)上訓練并在屏蔽人臉圖像(M)上測試的機器學習模型(UM/M),LDA 的準確率下降幅度最小,為 61%,而 KNN 的準確率下降幅度最大,為 24%。還可以看出,對于在蒙版人臉圖像(M)上訓練并在蒙版圖像(M)上測試的機器學習模型,LR 的準確率最高,為 80%,而 KNN 的準確率最低,為 37%。
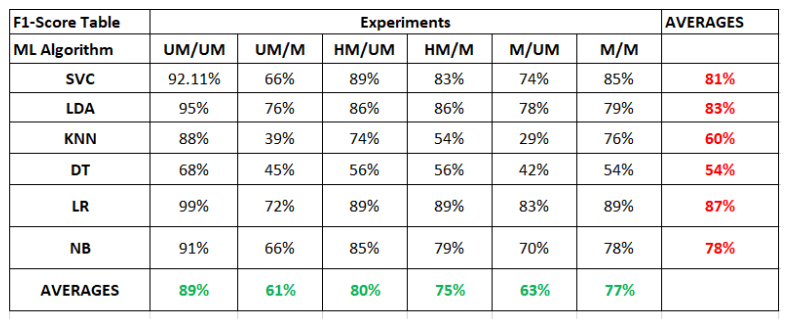
下表顯示了六種機器學習模型在所有六次實驗中的 F1 分數。對于在未遮擋人臉圖像(UM)上訓練并在遮擋人臉圖像(M)上測試的機器學習模型,LDA 的 F1 分數最高,為 76%,KNN 的分數最低,為 39%。而對于一半在蒙蔽人臉圖像(HM)上訓練,一半在蒙蔽圖像(M)上測試的模型,LR 的 F1 得分最高,為 89%,KNN 的得分最低,為 54%。在蒙蔽圖像(M)上訓練并在蒙蔽圖像(M)上測試的模型中,LR 的 F1 得分最高,為 89%,DT 的得分最低,為 54%。
回顧下表(再次),我們可以看到,在未蒙面的人臉圖像(UM)上訓練和在未蒙面的人臉圖像(UM)上測試時,最佳平均性能為 81%。這是很自然的結果,因為機器學習模型是基于人臉圖像沒有戴面具這一假設建立的。另一方面,當模型在未戴面具的人臉圖像上訓練并在戴面具的人臉圖像上測試時,平均性能最低,僅為 45%。這表明,正如 Corona 災難所報告的那樣,在未戴面具的人臉圖像上訓練的模型并不適合識別戴面具的人臉圖像。這與已報告的結果具有可重復性。
我們還發現,如果在一個由不戴面具的人臉圖像或一半戴面具的人臉圖像組成的數據集上進行訓練,機器學習模型在蒙面人臉圖像測試中的平均準確率會下降。如果機器學習模型在戴了面具的人臉圖像上進行訓練,則測試戴了面具的人臉圖像的準確率會提高。
上表還顯示,在所有三種類型的訓練數據上,LR 在識別未蒙蔽人臉圖像方面都優于其他模型。當在帶有遮擋或半遮擋圖像的數據集上進行訓練時,LR 在識別遮擋圖像方面優于其他模型。
對于需要識別遮擋和未遮擋面部圖像的系統來說,最好在由半遮擋面部圖像組成的數據集上進行訓練,并使用 LR,如上表所示。
4. 總結
本文為了研究戴面具對機器學習模型的影響,使用支持向量機(SVC/Support Vector Classifier)、線性判別分析(LDA/Linear Discriminant Analysis)、K-近鄰(KNN/K-Nearest NeighboursSVC/Support Vector Classifier)、線性判別分析(LDA/Linear Discriminant Analysis)、K-Nearest Neighbours(KNN/K-Nearest Neighbours)、決策樹(DT/Decision Trees)、邏輯回歸(Logistic Regression (LR/Logistic Regression)和奈夫貝葉斯(NB/Na?ve Bayes),并使用六種機器學習模型進行了詳盡的實驗。
實驗結果表明,在 "半遮擋和半未遮擋面部圖像數據集 "上進行訓練時,LR 作為同時識別遮擋和未遮擋面部圖像的系統表現最佳。
在識別被遮擋的人臉圖像時,在更多被遮擋的人臉圖像上訓練的模型的準確率呈上升趨勢,但與此同時,在識別未被遮擋的圖像時,準確率呈下降趨勢。












)

)

系列-管理查詢調整)
)

