集合
集合分為倆大類
- 單列集合
- 每個元素數據只包含一個值
- 雙列集合
- 每個元素包含倆個鍵值對

Conllection單列集合
單列集合常用的主要是下列幾種
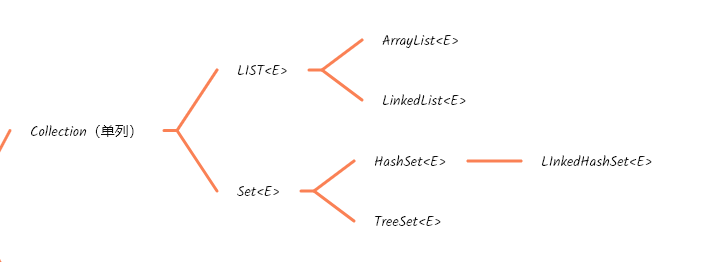
List集合
List系列集合的特點:添加元素是有序、可重復、有索引
這里我們來試一下ArrayList
ArrayList<String> list = new ArrayList<>();list.add("java1");list.add("java2");list.add("java1");list.add("java2");System.out.println(list);

ArrayList底層原理
基于數據實現
特點:索引查詢快,添加刪除慢
-
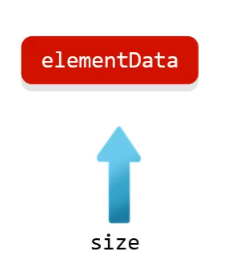
利用無參構造器創建集合,會在底層創建一個默認長度為0的數組
-
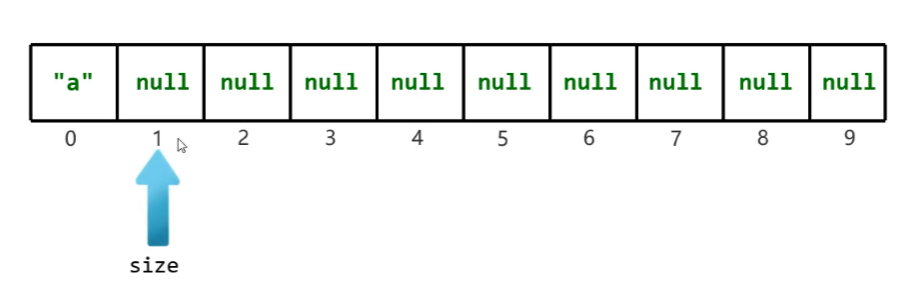
添加第一個元素,底層會創建一個新的長度為10的素組
-
存滿時,會擴容1.5倍
-
如果一次添加多個數據,1.5倍還放不下,則會以實際為準
應用場景
適合:根據索引查詢數據,比如根據隨機索引取數據,或者數據量不是很大的不適合:數據量大的同時,又要頻繁的進行增刪操作
LinkedList底層原理
基于雙鏈表實現
特點:查詢慢、增刪快,尤其是首尾節點速度

應用場景
-
設計隊列 (queue適用于校號系統、排隊系統)
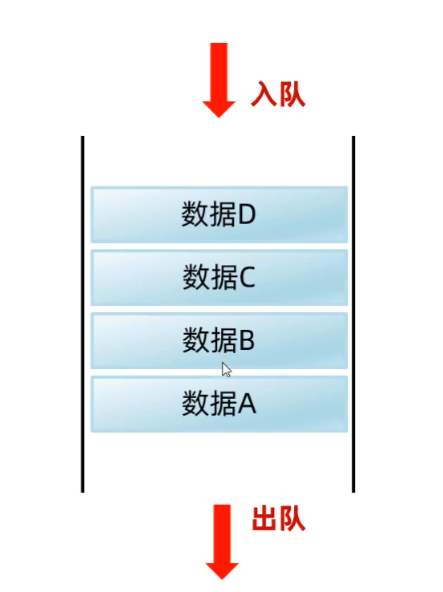
/** * 模擬隊列 */ LinkedList<String> queue = new LinkedList<>();//入隊 queue.addLast("第一個人"); queue.addLast("第二個人"); queue.addLast("第三個人"); queue.addLast("第四個人"); System.out.println(queue);//出隊 System.out.println(queue.removeFirst()); System.out.println(queue.removeFirst()); System.out.println(queue.removeFirst()); System.out.println(queue);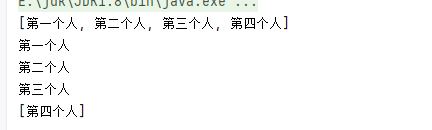
-
設計棧(Stack)
/*
* 模擬棧
* */
LinkedList<String> stack = new LinkedList<>();
//入棧
stack.push("第一顆子彈");
stack.push("第二顆子彈");
stack.push("第三顆子彈");
stack.push("第四顆子彈");
System.out.println(stack);//出棧
System.out.println(stack.pop());
System.out.println(stack.pop());
System.out.println(stack.pop());
System.out.println(stack);
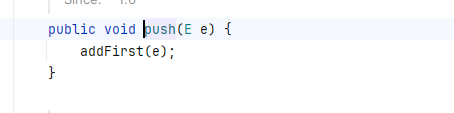
注意這里的 push 和 pop 就是addfirst 和 removeFirst

Set集合
Set系列集合的特點:添加元素是無序、不可重復、無索引
注意這倆個特別:
- LinkedHashSet:
有序、不重復、無索引 - TreeSet:
按照大小默認升序排序、不重復、無索引
然后我們來試一試HashSet集合
HashSet<String> set = new HashSet<>();set.add("java1");set.add("java2");set.add("java1");set.add("java2");System.out.println(set);
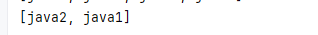
HashSet底層原理
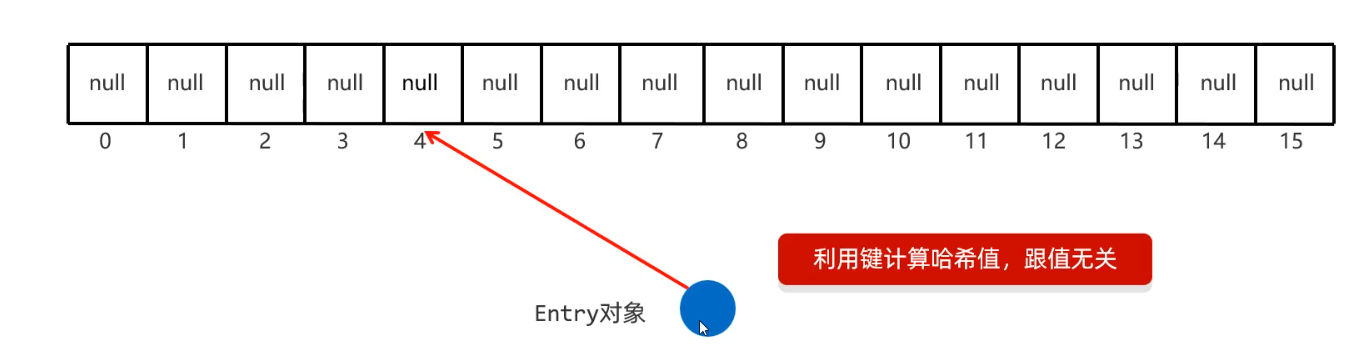
基于哈希表實現
特點:增刪改查都較好
1.8之前
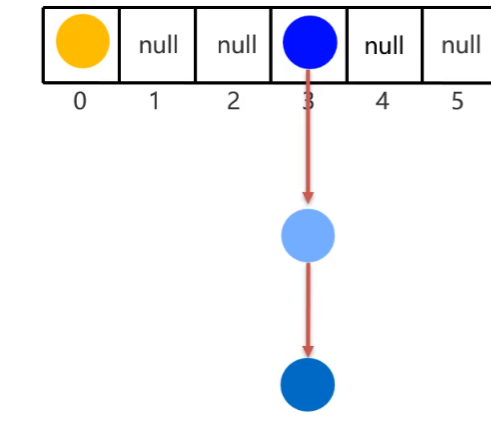
JDK8之前哈希表:數組+鏈表
-
創建一個默認為16的數組
默認加載因子為0.75表名為table
-
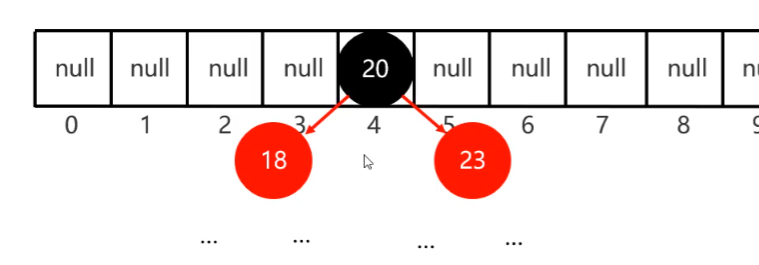
使用元素的
哈希值對數組長度求余計算出應存入的位置(這里的求余是它獨有的算法,并不是我們直接的%求余,確保它為正數) -
判斷當前位置是否為null,如果是null直接存入

-
如果不為null,如果有元素,則調用equals方法比較(相等,則不存;不相等,則存入數組)
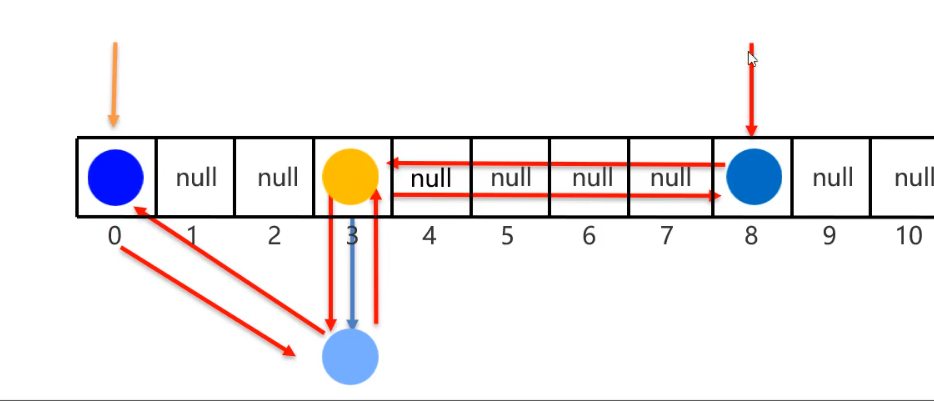
- JDK8之前,新元素會存入數組,占用老元素位置,老元素掛在下面
1.8之后
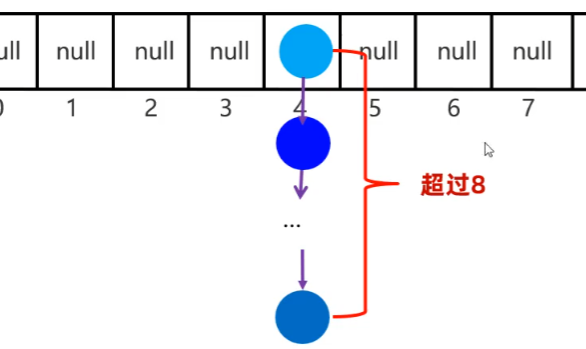
JDK8之后哈希表:數組+鏈表+紅黑樹
當鏈表長度超過8,且數組長度>=64時,自動將鏈表轉為紅黑樹
LinkedHashSet底層原理
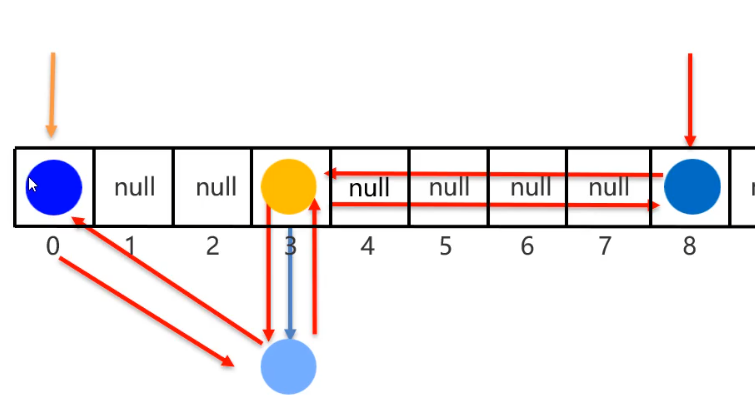
基于哈希表來實現
但是,每個元素都多了一個
雙鏈表機制來記錄前后元素的位置
TreeSet底層原理
特點:可排序(默認升序,按照元素大小,由小到大)
底層基于紅黑樹實現
總結

集合并發修改異常錯誤
使用迭代器遍歷集合時,又同時在刪除集合中的數據,程序就會出現并發修改異常的錯誤。
底層原因是因為集合刪除后會改變原集合的大小,而指針會自動往后移造成數據的漏刪
例如
//刪除名中有李字的
["張三","李四","五李","王五"]i
//第一次["張三","李四","五李","王五"]i
//刪除 后指針指向五李
["張三","五李","王五"] i//繼續
["張三","五李","王五"] i
上面這種情況就會造成異常錯誤
解決方法呢,就是在每次刪除之后將i向前移,迭代器底層也是這樣實現的
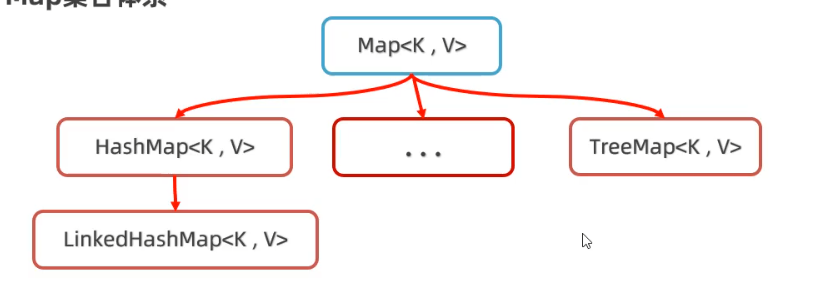
Map雙列集合
每次存儲需要一對數據作為一個元素
Map中的鍵是不允許重復的,但是值可以
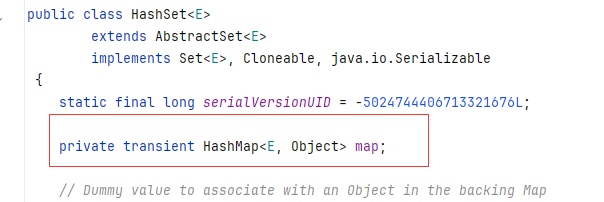
HashMap底層原理
特點:無序、不重復、無索引
底層:基于哈希表實現
實際上:原來所有的Set系列的集合都是基于Map實現的,只是Set集合中的元素只要鍵數據,不要值數據

注意的是底層這里計算hash值是基于鍵來進行hash表計算
LinkedHashMap底層原理
特點:有序、不重復、無索引
底層:基于哈希表實現,但是多了一個
雙鏈表機制來記錄元素順序(保證有序)
實際上:原來學習的LinkedHashSet集合的底層原理就是LinkedHashMap。

TreeMap底層原理
特點:不重復、無索引、可排序(按照鍵的大小默認升序排序,只能對鍵排序)
原理:跟TreeSet一樣基于紅黑樹實現排序
)

系列-管理查詢調整)
)















