目錄
簡介
?1.下采樣
2.過采樣?
簡介
????????接上兩篇篇博客最后,我們使用了K折交叉驗證去尋找最合適的C值,提升模型召回率,對于選取C的最優值,我們就要把不同C值放到模型里面訓練,然后用驗證集去驗證得到結果進行比較,發現最后模型得到很大的提升 ,但是相對與召回率還是差了很多
機器學習第二課之邏輯回歸(一)LogisticRegression
機器學習第二課之邏輯回歸(一)LogisticRegression
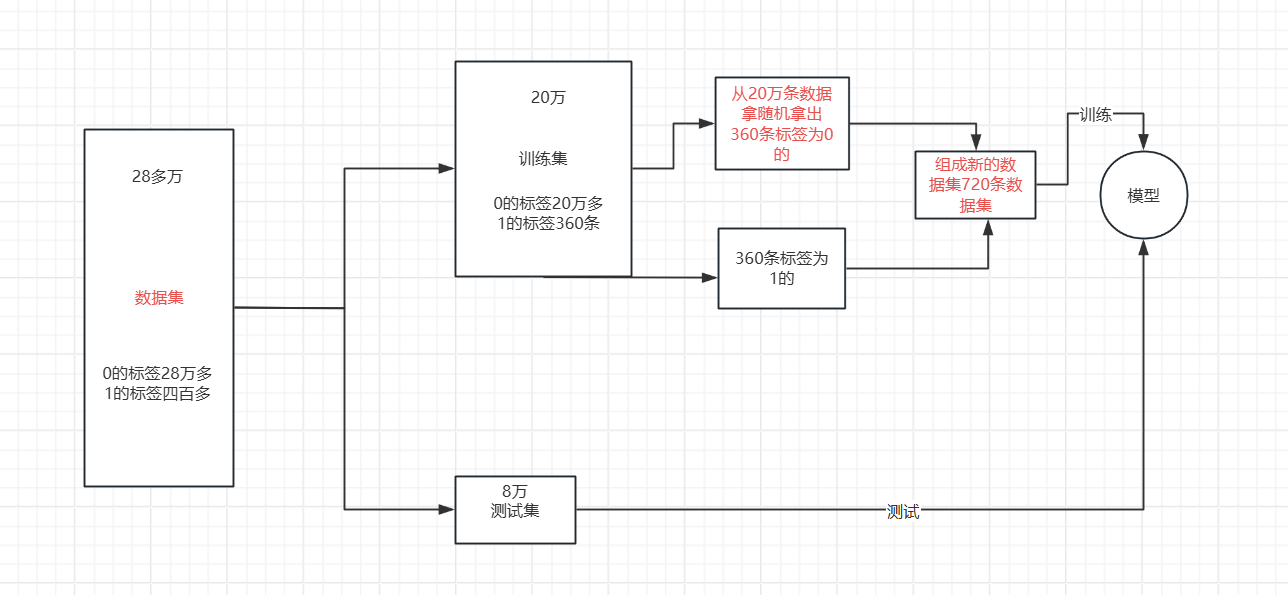
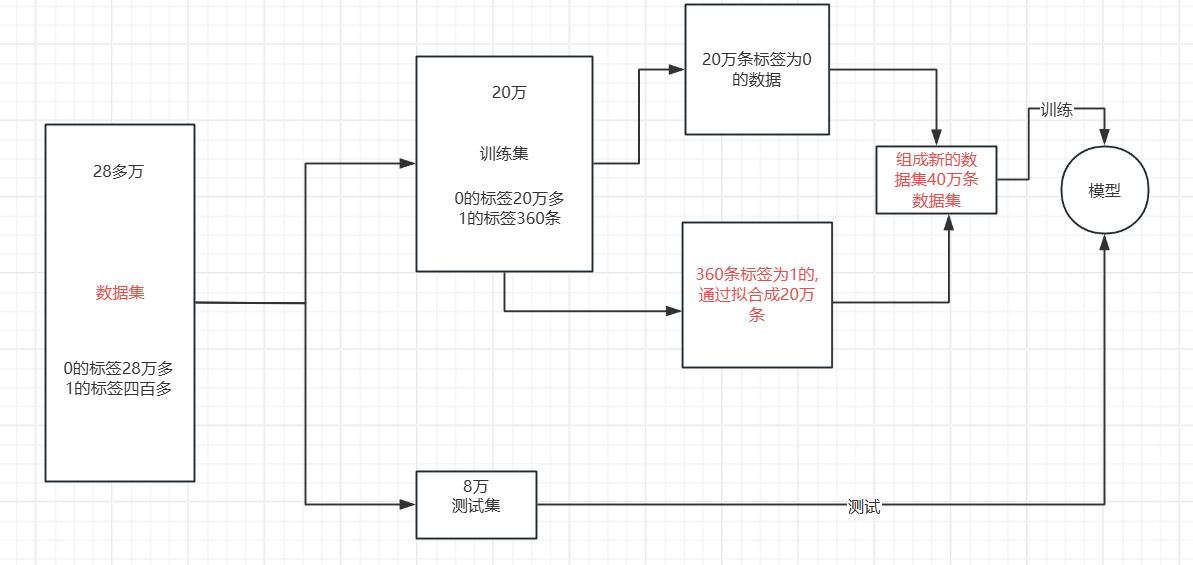
????????我們可以清楚的發現我們雖然有28萬條數據集,但是相對于標簽為1的數據集卻只有四百多條,數據集分布及其不均勻,想要對于暫時學習的模型進行進一步提升沒有太大的效果,只能對數據集進行一些處理,使得模型的效果得到提升,使用今天我來介紹兩種對于數據集分布不均勻的優化處理。
?1.下采樣
????????我們要想用這樣的數據去建模顯然是存在問題的。尤其是在我們更關心少數類的問題的時候數據分類不均衡會更加的突出,例如,信用卡詐騙、病例分析等。在這樣的數據分布的情況下,運用機器學習算法的預測模型可能會無法做出準確的預測,最后的模型顯然是趨向于預測多數集的,少數集可能會被當做噪點或被忽視,相比多數集,少數集被錯分的可能性很大。從本質上講,機器學習算法就是從大量的數據集中通過計算得到某些經驗,進而判定某些數據的正常與否。但是,不均衡數據集,顯然少數類的數量太少,模型會更傾向于多數集。
針對多樣本的類篩選一部分樣本參與訓練。?下采樣的具體流程就是下圖所示
?代碼分析:
1.導入庫、數據標準化、劃分數據集。(跟前面都一樣)
import numpy as np
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn import metrics
from sklearn.model_selection import cross_val_scoredata = pd.read_csv("creditcard.csv")# 數據預處理
scaler = StandardScaler()
data["Amount"] = scaler.fit_transform(data[["Amount"]])
data = data.drop(["Time"], axis=1) # 移除時間列# 劃分特征和標簽
x = data.iloc[:, :-1] # 特征
y = data.iloc[:, -1] # 標簽# 拆分訓練集和測試集
x_train_w, x_test_w, y_train_w, y_test_w = train_test_split(x, y, test_size=0.2, random_state=1000)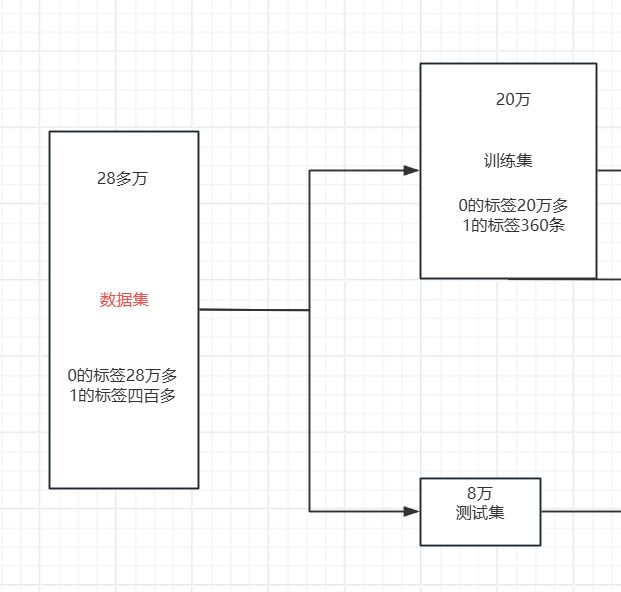
2.?數據準備
data_train_temp = x_train_w.copy()
data_train_temp['Class'] = y_train_w- 首先復制特征數據
x_train_w到data_train_temp - 然后將標簽數據
y_train_w作為新列Class添加到data_train_temp中 - 這樣就創建了一個包含特征和對應標簽的完整數據集
3.分離正負樣本
positive_eg = data_train_temp[data_train_temp['Class'] == 0] # 正常樣本
negative_eg = data_train_temp[data_train_temp['Class'] == 1] # 欺詐樣本Class=0表示正常樣本(positive_eg)Class=1表示欺詐樣本(negative_eg)
4.?下采樣處理
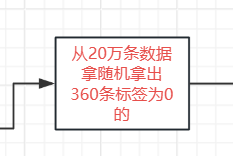
positive_eg = positive_eg.sample(len(negative_eg))- 這是下采樣的核心操作
- 從正常樣本中隨機抽樣,抽樣數量等于欺詐樣本的數量
- 這樣處理后,正常樣本和欺詐樣本的數量將保持一致
5.組合數據集
data_c = pd.concat([positive_eg, negative_eg])- 將下采樣后的正常樣本和原始欺詐樣本組合起來
- 得到一個類別平衡的新數據集
6.拆分特征和標簽
x_new = data_c.drop('Class', axis=1)
y_new = data_c.Class- 從平衡后的數據集
data_c中拆分出新的特征集x_new和標簽集y_new - 這些新數據可以用于后續的模型訓練
?7.交叉驗證、訓練、驗證、得到結果
scores = []
c_param_range = [0.01, 0.1, 1, 10, 100]
for i in c_param_range:lr = LogisticRegression(C=i, penalty="l2", solver='lbfgs', max_iter=10000)# 使用平衡后的數據集進行交叉驗證score = cross_val_score(lr,x_new, y_new, cv=5, scoring="recall")score_mean = sum(score) / len(score)scores.append(score_mean)print(f"C等于{i}的召回率為{score_mean}")best_c = c_param_range[np.argmax(scores)]
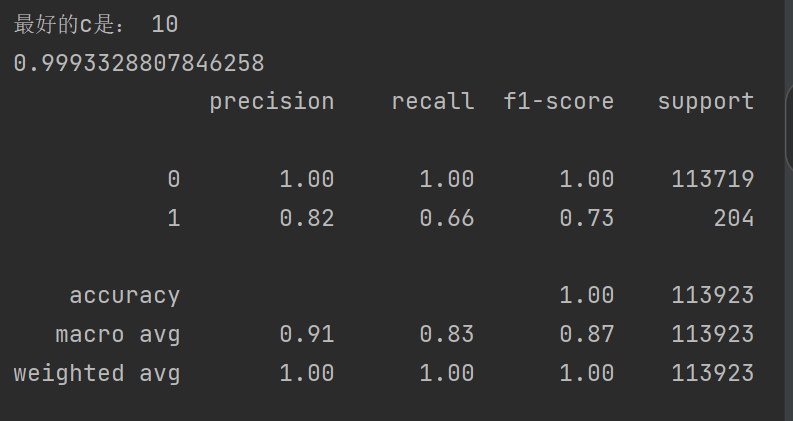
print("最好的C是:", best_c)# 使用最佳參數構建模型并訓練
estimator = LogisticRegression(C=best_c, max_iter=100)
estimator.fit(x_new,y_new ) # 使用原始訓練特征(不含額外添加的Class列)# 在測試集上進行預測和評估
test_predicted = estimator.predict(x_test_w)
print("訓練集準確率:", estimator.score(x_train_w, y_train_w))
print(metrics.classification_report(y_test_w, test_predicted))
8.結果
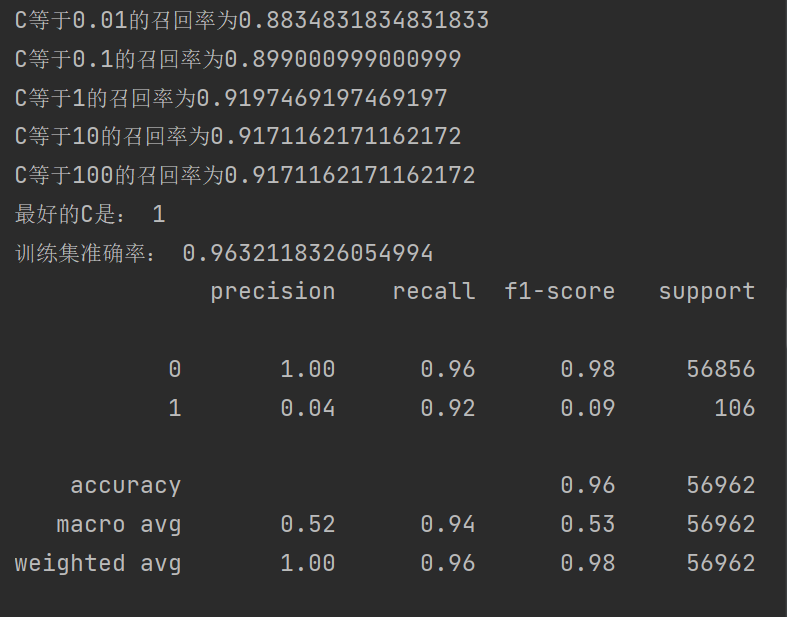
????????可以發現我們的召回率到達92%,效果得到很大的提升 ,對于準確率有些稍微下降,但是對于銀行來說是可以接受的,之前也說過最主要的是看召回率的高低。
2.過采樣?
針對少樣本類生成新的數據樣本參與訓練。
那我們依據什么擬合增加那么多數據呢 ?這就使用到了SMOTE 算法。
????????SMOTE 算法是一種用于解決分類問題中數據類別不平衡問題的技術。在很多實際的分類場景中,比如欺詐檢測、疾病診斷等,少數類樣本(如欺詐交易、患病樣本)的數量往往遠少于多數類樣本(如正常交易、健康樣本)。這種不平衡的數據分布會導致模型在訓練時偏向于多數類,而對少數類的預測效果不佳。
????????SMOTE 算法的核心思想是通過對少數類樣本進行分析,然后人工合成新的少數類樣本并添加到數據集中,從而增加少數類樣本的數量,使數據分布更加平衡。具體來說,SMOTE 算法會為每個少數類樣本找到其在特征空間中的 k 個最近鄰,然后在這些最近鄰之間隨機插值,生成新的合成樣本。這些合成樣本具有與原始少數類樣本相似的特征分布,從而可以幫助模型更好地學習少數類的特征,提高對少數類樣本的分類準確率。
SMOTE 算法:
- 對于少數類中每一個樣本x,以歐氏距離為標準計算它到少數類樣本集
中所有樣本的距離,得到其k近鄰。
- 根據樣本不平衡比例設置一個采樣比例以確定采樣倍率N,對于每一個少數類樣本x,從其k近鄰中隨機選擇若干個樣本,假設選擇的近鄰為xn。
- 對于每一個隨機選出的近鄰xn,分別與原樣本按照如下的公式構建新的樣本
?
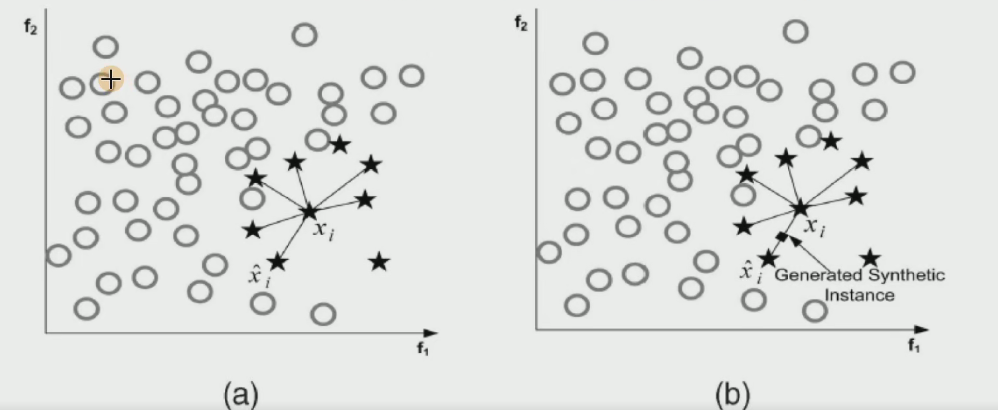 ?新生成的這些數據點都是在這些線上
?新生成的這些數據點都是在這些線上
?代碼分析:
1.導入 SMOTE 類
from imblearn.over_sampling import SMOTE從imblearn庫的過采樣模塊中導入SMOTE類,該類實現了合成少數類過采樣技術。
2.初始化 SMOTE 對象?
oversampler = SMOTE(random_state=0)?創建一個 SMOTE 過采樣器實例,random_state=0設置隨機種子,確保結果的可重復性。
3.執行過采樣?
os_x_train, os_y_train = oversampler.fit_resample(x_train_w, y_train_w)fit_resample方法是 SMOTE 的核心操作,它會對少數類樣本進行分析并合成新樣本x_train_w是原始訓練特征數據,y_train_w是對應的標簽- 處理后返回
os_x_train(過采樣后的特征數據)和os_y_train(過采樣后的標簽) - 此時的數據集已經通過合成少數類樣本達到了類別平衡
4.劃分訓練集和測試集?
經過過采樣后得到的數據比較多,我們可以再一次進行數據集劃分。
os_x_train_w, os_x_test_w, os_y_train_w, os_y_test_w = train_test_split(os_x_train, os_y_train, test_size=0.2, random_state=0
)- 使用
train_test_split將過采樣后的數據集劃分為新的訓練集和測試集 test_size=0.2表示將 20% 的數據作為測試集,80% 作為訓練集random_state=0保證劃分結果的可重復性- 返回四個變量分別為:過采樣后的訓練特征、過采樣后的測試特征、過采樣后的訓練標簽、過采樣后的測試標簽
完整代碼:
只有中間部分跟下采樣有所不同,其他步驟都是相同的
import numpy as np
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn import metricsfrom sklearn.model_selection import cross_val_scoredata=pd.read_csv("creditcard.csv")scaler=StandardScaler()
data["Amount"]=scaler.fit_transform(data[["Amount"]])
data=data.drop(["Time"],axis=1)x=data.iloc[:, :-1]
y=data.iloc[:, -1]x_train_w,x_test_w,y_train_w,y_test_w=train_test_split(x,y,test_size=0.2,random_state=0)from imblearn.over_sampling import SMOTE
oversampler=SMOTE(random_state=0)
os_x_train,os_y_train=oversampler.fit_resample(x_train_w,y_train_w)
os_x_train_w,os_x_test_w,os_y_train_w,os_y_test_w=train_test_split(os_x_train,os_y_train,test_size=0.2,random_state=0)scores = []
c_param_range = [0.01, 0.1, 1, 10, 100]
for i in c_param_range:lr = LogisticRegression(C=i, penalty="l2", solver='lbfgs', max_iter=10000)# 使用平衡后的數據集進行交叉驗證score = cross_val_score(lr,os_x_train_w, os_y_train_w, cv=8, scoring="recall")score_mean = sum(score) / len(score)scores.append(score_mean)print(f"C等于{i}的召回率為{score_mean}")best_c=c_param_range[np.argmax(scores)]
print("最好的c是:",best_c)estimator=LogisticRegression(C=best_c)
estimator.fit(os_x_train_w,os_y_train_w)
test_predicted=estimator.predict(x_test_w)print(metrics.classification_report(y_test_w,test_predicted))
?結果:
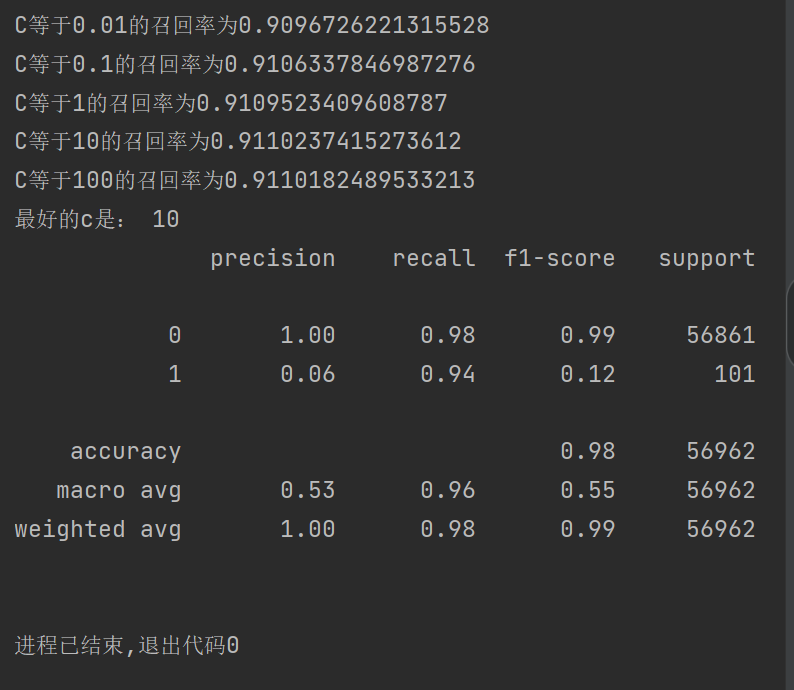
?可以發現我們的召回率到達94%,效果又得到很大的提升 ,


)
:CountDownLatch 與 Semaphore 的協作應用)

)

軟件架構設計)


![[特殊字符] Ubuntu 下 MySQL 離線部署教學(含手動步驟與一鍵腳本)](http://pic.xiahunao.cn/[特殊字符] Ubuntu 下 MySQL 離線部署教學(含手動步驟與一鍵腳本))


)


)


