SelfKG: Self-Supervised Entity Alignment in Knowledge Graphs
SelfKG:知識圖中的自監督實體對齊
ABSTRACT
實體對齊旨在識別不同知識圖譜(KG)中的等效實體,是構建網絡規模知識圖譜的基本問題。在其發展過程中,標簽監督被認為是準確對準所必需的。受到自監督學習最近進展的啟發,我們探索了在多大程度上可以擺脫實體對齊的監督。通常,標簽信息(正實體對)用于監督將每個正實體對中對齊的實體拉近的過程。然而,我們的理論分析表明,實體對齊的學習實際上可以通過將未標記的負對相互遠離而不是拉近標記的正對來受益更多。通過利用這一發現,我們開發了實體對齊的自我監督學習目標。我們向 SelfKG 提供了有效的策略來優化這一目標,從而在沒有標簽監督的情況下協調實體。對基準數據集的大量實驗表明,沒有監督的 SelfKG 可以與最先進的監督基線相匹配或達到可比的結果。SelfKG 的表現表明,自我監督學習為知識圖譜中的實體對齊提供了巨大的潛力。代碼和數據可在 https://github.com/THUDM/SelfKG 獲取。
1 INTRODUCTION
知識圖譜(KG)已在各種 Web 應用程序中得到廣泛采用,例如搜索、推薦和問答。 建設大型知識圖譜是一項非常具有挑戰性的任務。 雖然我們可以從頭開始提取新的事實,但對于現實世界的應用場景來說,將現有的(不完整的)KG 對齊在一起實際上是必要的。 在過去的幾年里,實體對齊問題,或者說本體映射和模式匹配,一直是Web研究界的一個基本問題。
最近,基于表示學習的對齊方法由于其卓越的靈活性和準確性而成為實體對齊的主流解決方案。然而,它們的成功在很大程度上依賴于人工標簽提供的監督,而對于網絡規模的知識圖譜來說,這種監督可能會存在偏差并且成本高昂。鑒于這一基本挑戰,我們的目標是探索在沒有標簽監督的情況下跨知識圖譜對齊實體的潛力(即自我監督的實體對齊)。
為了實現這一目標,我們重新審視已建立的監督實體對齊方法的通用流程。從概念上講,對于來自兩個知識圖譜的每個配對實體,現有學習目標的目標是,如果它們實際上是相同的實體(即正對),則使它們彼此更加相似,否則如果它們是不同的實體(即負對),則使它們不相似。在嵌入空間中,通過將對齊的實體拉得更近并將不同的實體推得更遠來實現這一目標。
我們確定在此過程中需要監督的部分。首先,監督有助于拉近對齊實體的距離。其次,出現的另一個問題是生成標簽感知負對的過程。對于知識圖譜中的每個實體,在訓練中,其負對是通過從其他知識圖譜中隨機采樣實體而形成的,同時排除真實值。如果沒有監督,隱式對齊的實體可能會被采樣為負對,從而破壞訓練(即碰撞)。
貢獻。我們引入了知識圖譜中自監督的實體對齊問題。為了解決這個問題,我們提出了SelfKG框架,它不依賴于標記實體對來對齊實體。它由三個技術組件組成:1)相對相似性度量,2)自負采樣,3)多個負隊列。
為了擺脫標簽監督,我們從理論上發展了相對相似度度量(RSM)的概念,它可以實現自監督學習目標。RSM的核心思想是,它不是直接將對齊的實體在嵌入空間中拉得更近,而是嘗試將未對齊的負實體推得更遠,從而避免使用正實體對的監督。從相對意義上來說,在優化 RSM 時,(隱式)對齊的實體可以被認為是被拖到一起的。
SelfKG通過設計提出了一種自負采樣策略,以解決在知識圖譜中進行有監督標簽意識負采樣和無監督負采樣中假陰性樣本碰撞的困境。具體來說,對于知識圖譜中的每個實體,我們通過直接從相同的知識圖譜中采樣實體來形成其負對。換句話說,SelfKG完全依賴于從輸入的知識圖譜中隨機采樣的負實體對。我們從理論上證明了這種策略對于跨知識圖譜對齊實體仍然是有效的。
最后,我們的理論分析還表明,隨著負樣本數量的增加,自監督損失的誤差項衰減得更快,即大量的負樣本可以使SelfKG受益。然而,動態編碼大量負樣本在計算上非常昂貴。我們通過擴展MoCo技術來解決這個問題,支持兩個負隊列,每個負隊列對應兩個KG進行比對,確保負樣本的有效增加。
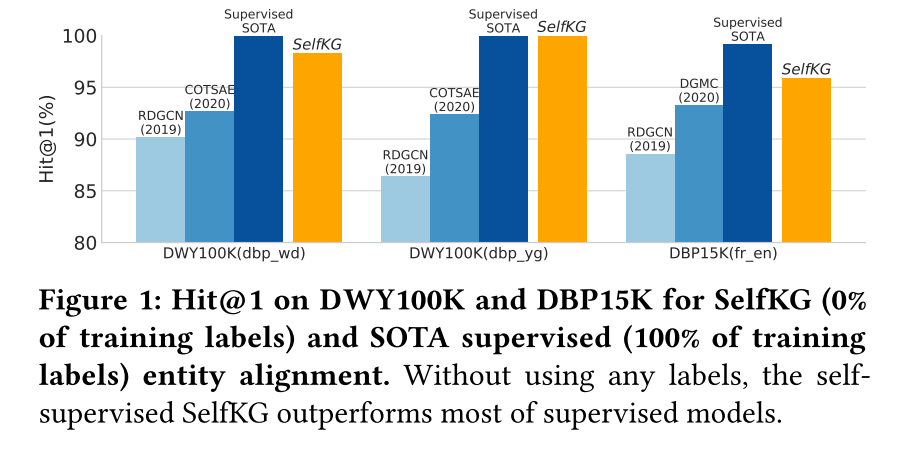
根據經驗,我們進行了大量的實驗來證明知識圖譜中自監督實體對齊的前提。我們將所提出的 SelfKG 方法與兩個廣泛使用的實體對齊基準數據集(DWY100K 和 DBP15K)上的 24 個監督基線和 1 個無監督基線進行了比較。結果表明,在不使用任何標簽的情況下,SelfKG 可以與最先進的監督基線相匹配或達到可比的性能(參見圖 1)。這證明了自我監督學習在實體對齊方面的力量以及我們對 SelfKG 的設計選擇。
2 PROBLEM DEFINITION
我們引入了知識圖譜中的實體對齊問題。從概念上講,KG 可以表示為一組三元組 T T T,每個三元組表示兩個實體 x i ∈ E x_i\in E xi?∈E 和 x j ∈ E x_j\in E xj?∈E 之間的關系 r i j ∈ R r_{ij}\in R rij?∈R。在這項工作中,我們將 KG 表示為 G = { E , R , T } G = \{E, R, T\} G={E,R,T},其中 E E E、 R R R 和 T T T分別是其實體集、關系集和三元組。
給定兩個 KG, G x = { E x , R x , T x } G_{x} = \{E_{x},R_{x},T_{x}\} Gx?={Ex?,Rx?,Tx?} 和 G y = { E y , R y , T y } G_{y} = \{E_{y},R_{y},T_{y}\} Gy?={Ey?,Ry?,Ty?},現有對齊實體對的集合定義為 S = { ( x , y ) ∣ x ∈ E x , y ∈ E y , x ? y } S=\{(x,y)|x\in E_{x},y\in E_{y},x\Leftrightarrow y\} S={(x,y)∣x∈Ex?,y∈Ey?,x?y},其中 ? \Leftrightarrow ? 表示等價。 G x G_x Gx? 和 G y G_y Gy? 之間實體對齊的目標是為 E y E_y Ey? 中的每個實體(如果存在)從 E x E_x Ex? 找到等效實體。
最近,一個重要的工作重點是基于嵌入的技術,用于在向量空間中對齊實體,例如,訓練神經編碼器 f f f 將每個實體 x ∈ E x\in E x∈E 投影到潛在空間中。在這些嘗試中,大多數都集中在(半)監督設置上,即 S S S 的一部分用于訓練對齊模型。由于現實世界中 KG 之間的對齊標簽有限,我們建議研究實體對齊任務在無監督或自監督的環境中可以在多大程度上解決,在這種情況下, S S S 中的現有對齊都不可用。
3 SELF-SUPERVISED ENTITY ALIGNMENT
3 自我監督的實體協調
在本節中,我們討論監督在實體對齊中扮演的角色,然后提出可以幫助在沒有標簽監督的情況下對齊實體的策略。為此,我們提出了 SelfKG 框架,用于跨 KG 的自我監督實體對齊。
3.1 The SelfKG Framework
為了實現無標簽信息的學習,SelfKG的主要目標是設計一個可以指導其學習過程的自我監督目標。為了實現這一目標,我們提出了跨兩個 KG 的實體之間的相對相似性度量的概念(參見第 3.2 節)。為了進一步提高 SelfKG 的自監督優化,我們引入了自負采樣技術(參見第 3.3 節)和多個負隊列技術(參見第 3.4 節)。
接下來,我們介紹 SelfKG 中實體嵌入的初始化,它很大程度上建立在現有技術的基礎上,包括統一空間學習和基于 GNN 的鄰域聚合器。
統一空間學習。 單空間學習的思想已被最近的(半)監督實體對齊技術所采用。 在此,我們介紹如何利用它來支持 SelfKG 的自我監督學習設置。
簡單地說,將來自不同知識圖譜的實體嵌入到統一空間中可以極大地有利于對齊任務。通過標記實體對,很自然地利用監督將不同的空間對齊到一個空間中,例如,合并對齊的實體進行訓練,或者學習具有豐富訓練標簽的投影矩陣,將來自不同嵌入空間的實體投影到統一空間中。
就多語言數據集(例如 DBP15K)而言,問題更具挑戰性。得益于預先訓練的語言模型,現在可以使用高質量的多語言初始嵌入。例如,多語言 BERT 已在最近的工作中使用。在 SelfKG 中,我們采用 LaBSE——一種最先進的多語言預訓練語言模型,在 109 種不同語言上進行訓練——將不同的知識圖嵌入到統一空間中。
鄰域聚合器。 為了進一步改進實體嵌入,使用鄰域聚合將鄰居實體的信息聚合到中心實體。 在這項工作中,我們直接使用具有一層的單頭圖注意網絡來聚合一跳鄰居的預訓練嵌入。
請注意,最近已經探索利用多跳圖結構來解決實體對齊問題。盡管一些研究聲稱它們受益于多跳鄰居,但其他研究認為一跳鄰居為大多數情況提供了足夠的信息。在我們的消融研究中(參見第 4.2 節),我們發現多跳信息實際上損害了 SelfKG 的性能,這可能是由于在自我監督環境中可能不可忽略的遙遠鄰居噪聲造成的。因此,為了演示實體對齊自監督的最低要求,我們在聚合過程中僅涉及一跳鄰居實體。
3.2 Relative Similarity Metric
3.2 相對相似度度量
我們提出了跨 KG 的實體對齊的自監督損失。首先,我們分析實體對齊的監督 NCE 損失。然后,我們引入相對相似度度量來避免標記對。我們最終推導出 SelfKG 的自監督 NCE。
在表示學習中,邊際損失和交叉熵損失已被廣泛采用作為相似性度量。不失一般性,它們可以以噪聲對比估計(NCE)的形式表達。
在實體對齊的背景下,NCE 損失可以形式化如下。令 p x , p y p_x,p_y px?,py? 為兩個 KG G x , G y G_x,G_y Gx?,Gy? 的分布, p p o s p_{pos} ppos? 表示正實體對 ( x , y ) ∈ R n × R n (x,y) \in \mathbb{R}^{n}\times\mathbb{R}^{n} (x,y)∈Rn×Rn 的表示分布。 給定一對對齊實體 ( x , y ) ~ p p o s (x, y) \sim p_{pos} (x,y)~ppos?,負樣本 { y i ? } i = 1 M ~ i . i . d . p y \{y_{i}^{-}\}_{i=1}^{M}\stackrel{\mathrm{i.i.d.}}{\sim}p_{y} {yi??}i=1M?~i.i.d.py?,溫度 τ \tau τ,編碼器 f f f 滿足 ∥ f ( ? ) ∥ = 1 \|f(\cdot)\|=1 ∥f(?)∥=1,我們有 監督 NCE 損失為
L N C E ? ? log ? e f ( x ) T f ( y ) / τ e f ( x ) T f ( y ) / τ + ∑ i e f ( x ) T f ( y i ? ) / τ = ? 1 τ f ( x ) T f ( y ) ? a l i g n m e n t + log ? ( e f ( x ) T f ( y ) / τ + ∑ i e f ( x ) T f ( y i ? ) / τ ) ? u n i f o r m i t y . ( 1 ) \begin{aligned}\mathcal{L}_{\mathrm{NCE}}&\triangleq-\log\frac{e^{f(x)^{\mathsf{T}}f(y)/\tau}}{e^{f(x)^{\mathsf{T}}f(y)/\tau}+\sum_{i}e^{f(x)^{\mathsf{T}}f(y_{i}^{-})/\tau}}\\&=\underbrace{-\frac{1}{\tau}f(x)^{\mathsf{T}}f(y)}_{\mathrm{alignment}}+\underbrace{\log(e^{f(x)^{\mathsf{T}}f(y)/\tau}+\sum_{i}e^{f(x)^{\mathsf{T}}f(y_{i}^{-})/\tau})}_{\mathrm{uniformity}}\:.\end{aligned}\quad\quad(1) LNCE????logef(x)Tf(y)/τ+∑i?ef(x)Tf(yi??)/τef(x)Tf(y)/τ?=alignment ?τ1?f(x)Tf(y)??+uniformity log(ef(x)Tf(y)/τ+i∑?ef(x)Tf(yi??)/τ)??.?(1)
其中“alignment”項是將正對拉近,“uniformity”項是將負對推開。
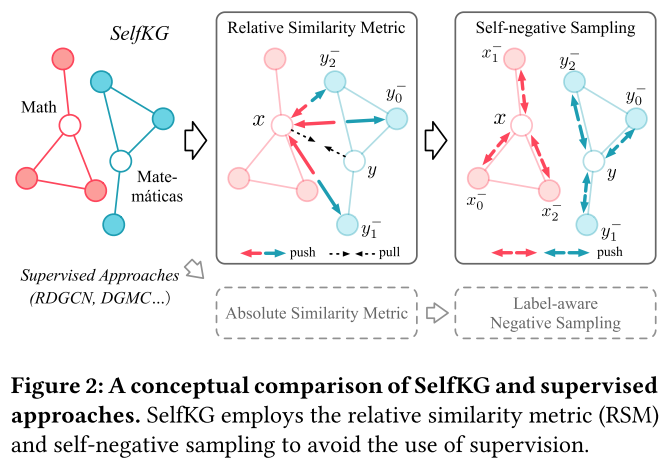
我們說明了如何針對自我監督設置進一步調整 NCE 損失。KG 中“pulling”和“pushing”實體對的示例如圖 2(左)所示。 之前的研究表明,NCE損失具有以下漸近特性:
定理 1.(絕對相似度度量(ASM)) 對于固定的 τ > 0 \tau>0 τ>0,當負樣本數 M → ∞ M \rightarrow \infty M→∞,(歸一化)對比損失 L N C E \mathcal L_{NCE} LNCE?(即 L A S M \mathcal L_{ASM} LASM?)以絕對偏差收斂到其極限 在 O ( M ? 2 / 3 ) O(M^{-2/3}) O(M?2/3) 內衰減。如果存在完美均勻的編碼器 𝑓,它會形成均勻性項的精確最小值。
定理 1 使 NCE 損失成為需要監督的絕對相似性度量。然而,請注意,盡管 KG 中的實體存在潛在的歧義和異質性,但對齊的對即使名稱不完全相同,也應該具有相似的語義含義。此外,已知預先訓練的詞嵌入通過將相似實體投影到嵌入空間中來捕獲這種語義相似性,從而可以確保等式(1)中相對較大的 f ( x ) T f ( y ) f(x)^Tf(y) f(x)Tf(y)。 在等式1中,即“對齊”術語。
因此,為了優化 NCE 損失,主要任務是優化式(1)中的“均勻性”項而不是“對齊”術語。考慮到 f f f 的有界性,我們可以立即繪制 L A S M \mathcal L_{ASM} LASM? 的無監督上限,如下所示。
命題1.相對相似度度量(RSM)。 對于固定的 τ > 0 \tau > 0 τ>0 且編碼器 f f f 滿足 ∥ f ( ? ) ∥ = 1 \|f(\cdot)\|=1 ∥f(?)∥=1,我們始終具有以下相對相似性度量加上由常數控制的絕對偏差作為 L A S M \mathcal L_{ASM} LASM? 的上限:
L R S M = ? 1 τ + E { y i ? } i = 1 M ~ i . i . d . p γ [ log ? ( e 1 / τ + ∑ i e f ( x ) T f ( y i ? ) / τ ) ] ≤ L A S M ≤ L R S M + 1 τ [ 1 ? min ? ( x , y ) ~ p p o s ( f ( x ) T f ( y ) ) ] . ( 2 ) \begin{aligned}\mathcal{L}_{\mathrm{RSM}}& =-\frac{1}{\tau}+\mathbb{E}_{\{y_{i}^{-}\}_{i=1}^{M}\stackrel{\mathrm{i.i.d.}}{\sim}p_{\gamma}}\biggl[\log(e^{1/\tau}+\sum_{i}e^{f(x)^{\mathsf{T}}f(y_{i}^{-})/\tau})\biggr] \\&\leq \mathcal{L}_{\mathrm{ASM}} \leq \mathcal{L}_{\mathrm{RSM}}+\frac{1}{\tau}\left[1-\min_{(x,y)\sim p_{\mathrm{pos}}}\left(f(x)^{\mathsf{T}}f(y)\right)\right].\end{aligned}\quad\quad(2) LRSM??=?τ1?+E{yi??}i=1M?~i.i.d.pγ??[log(e1/τ+i∑?ef(x)Tf(yi??)/τ)]≤LASM?≤LRSM?+τ1?[1?(x,y)~ppos?min?(f(x)Tf(y))].?(2)
通過優化 L R S M \mathcal L_{RSM} LRSM?,通過將不對齊的實體推得更遠,對齊的實體相對靠近。換句話說,如果我們不能將對齊的實體拉近(例如,沒有正標簽),我們可以將那些未對齊的實體推得足夠遠。
通過分析實體對齊常用的 NCE 損失,我們發現將那些隨機采樣的(負)對推得遠比拉近對齊的(正)對對訓練更有好處。因此,在 SelfKG 中,我們只專注于嘗試將負面數據推得遠遠的,這樣我們就可以擺脫正面數據(即標簽)的使用。
3.3 Self-Negative Sampling
3.3 自負采樣
在上面的分析中,我們證明了為了在沒有監督的情況下對齊實體,SelfKG 的重點是采樣負實體對——一個來自 KG G x G_x Gx?,另一個來自 KG G y G_y Gy?。在負采樣期間,如果沒有對標簽感知負采樣的監督,底層對齊的實體對很可能被采樣為負實體對,即發生沖突。通常,如果采樣的負數較少,則可以忽略此碰撞概率; 但我們發現大量的負樣本對于SelfKG的成功至關重要(參見圖4),在這種情況下,碰撞概率是不可忽略的(參見表4),導致性能相對地下降高達7.7%。為了緩解這個問題,考慮到我們正在從 G x G_x Gx? 和 G y G_y Gy? 的單空間中學習,我們建議從 G x G_x Gx? 中對實體 x ∈ G x x \in G_x x∈Gx? 采樣負數 x i ? x^-_i xi??。通過這樣做,我們可以通過簡單地排除 x x x 來避免沖突,即自負抽樣。
然而,由此可能會引發另外兩個問題。首先,由于現實世界的噪聲數據質量, G x G_x Gx?中經常可能存在多個重復的 x x x,這些重復的 x x x可能會被采樣為負數。請注意,這也是監督設置面臨的挑戰,其中 G y G_y Gy? 中也可能存在一些重復的 y y y。 通過遵循[38]中的證明概要,我們表明一定量的噪聲不會影響 NCE 損失的收斂。
定理 2. (Noisy ASM) 令平均重復因子 λ ∈ N + , τ ∈ R + \lambda\in\mathbb{N}^{+},\tau\in\mathbb{R}^{+} λ∈N+,τ∈R+ 為常數。 噪聲 ASM 表示如下,它仍然收斂到 ASM 的相同極限,絕對偏差在 O ( M ? 2 / 3 ) O(M^{-2/3}) O(M?2/3) 中衰減。
L A S M ∣ λ , x ( f ; τ , M , p Y ) = ∑ ( x , y ) ~ p p o s [ ? log ? e f ( x ) T f ( y ) / τ λ e f ( x ) T f ( y ) / τ + ∑ i e f ( x ) T f ( y i ? ) / τ ] { y i ? } i = 1 M ~ i . i . d . p y ( 3 ) \begin{aligned}\mathcal{L}_{\mathrm{ASM}|\lambda,x}(f;\tau,M,p_{Y})&=\sum_{(x,y)\sim p_{\mathrm{pos}}}\left[-\log\frac{e^{f(x)^{\mathsf{T}}f(y)/\tau}}{\lambda e^{f(x)^{\mathsf{T}}f(y)/\tau}+\sum_{i}e^{f(x)^{\mathsf{T}}f(y_{i}^{-})/\tau}}\right]\\&\{y_{i}^{-}\}_{i=1}^{M}\overset{\mathrm{i.i.d.}}{\sim}p_{y}\end{aligned}\quad\quad(3) LASM∣λ,x?(f;τ,M,pY?)?=(x,y)~ppos?∑?[?logλef(x)Tf(y)/τ+∑i?ef(x)Tf(yi??)/τef(x)Tf(y)/τ?]{yi??}i=1M?~i.i.d.py??(3)
第二個問題是,通過將負樣本從 y i ? ∈ G y y_i^-\in G_y yi??∈Gy? 更改為 x i ? ∈ G x x_i^-\in G_x xi??∈Gx?,我們需要確認 L R S M \mathcal L_{RSM} LRSM? 對于實體對齊是否仍然有效。根據經驗,對于選定的負樣本 y i ? ∈ G y y_i^-\in G_y yi??∈Gy?,我們可以預期存在一些部分相似的 x i ? ∈ G x x_i^-\in G_x xi??∈Gx?。由于編碼器 f f f 是 G x G_x Gx? 和 G y G_y Gy? 共享的,因此 f ( x i ? ) f(x^-_i) f(xi??) 的優化也將有助于 f ( y j ? ) f(y^-_j) f(yj??) 的優化。為了證明這一點,我們提供以下定理。
定理 3.(帶自負采樣的噪聲 RSM) 令 Ω x , Ω y \Omega_{x},\Omega_{y} Ωx?,Ωy? 分別為 KG 三元組的空間, { x i ? : Ω x → R n } i = 1 M , { y i ? : Ω y → R n } i = 1 M \{x_{i}^{-}:\Omega_{\mathrm{x}}\to\mathbb{R}^{n}\}_{i=1}^{M},\{y_{i}^{-}:\Omega_{\mathrm{y}}\to\mathbb{R}^{n}\}_{i=1}^{M} {xi??:Ωx?→Rn}i=1M?,{yi??:Ωy?→Rn}i=1M? 分別為獨立同分布分布為 p x , p y p_x,p_y px?,py? 的隨機變量, S d ? 1 S^{d-1} Sd?1 表示 R n \mathbb R^n Rn 中的單球體。 如果存在隨機變量 f : R n → S d ? 1 s . t . f ( x i ? ) f : \mathbb{R}^n \to S^{d-1} \mathrm{s.t.} f(x_i^-) f:Rn→Sd?1s.t.f(xi??) 和 f ( y i ? ) f(y_i^-) f(yi??) 在 S d ? 1 , 1 ≤ i ≤ M . S^{d-1},1\leq i\leq M. Sd?1,1≤i≤M.上滿足相同的分布,則我們有:
lim ? M → ∞ ∣ L R S M ∣ λ , x ( f ; τ , M , p x ) ? L R S M ∣ λ , x ( f ; τ , M , p y ) ∣ = 0. ( 4 ) \operatorname*{lim}_{M\to\infty}|\mathcal{L}_{\mathrm{RSM}|\lambda,x}(f;\tau,M,p_{x})-\mathcal{L}_{\mathrm{RSM}|\lambda,x}(f;\tau,M,p_{y})|=0.\quad\quad(4) M→∞lim?∣LRSM∣λ,x?(f;τ,M,px?)?LRSM∣λ,x?(f;τ,M,py?)∣=0.(4)
王等人表明,在 p x = p y p_x=p_y px?=py? 的條件下,編碼器 f f f 可以近似為均勻損失的最小化。具體來說, f f f 遵循超球面上的均勻分布。在SelfKG中,統一空間學習條件確保了兩個KG的最終統一表示。 最初的 p x p_x px? 和 p y p_y py?相似但不相同,這表明自負抽樣是必要的。然而,隨著訓練的繼續,編碼器將會得到改進,因為定理 2 保證使兩個 KG 更加對齊。換句話說, G x G_x Gx? 和 G y G_y Gy? 的實體嵌入可以被視為來自更大空間中的單個分布的樣本,即 p x = p y p_x=p_y px?=py?。這反過來又使得 f f f 的存在變得更加可實現。
在實踐中,我們如下聯合優化 G x G_x Gx? 和 G y G_y Gy? 上的損失,如圖 2(右)和圖 3 所示。
L = L R S M ∣ λ , x ( f ; τ , M , p x ) + L R S M ∣ λ , y ( f ; τ , M , p y ) . ( 5 ) \mathcal{L}=\mathcal{L}_{\mathrm{RSM}|\lambda,x}(f;\tau,M,p_{x})+\mathcal{L}_{\mathrm{RSM}|\lambda,y}(f;\tau,M,p_{y}).\quad\quad(5) L=LRSM∣λ,x?(f;τ,M,px?)+LRSM∣λ,y?(f;τ,M,py?).(5)
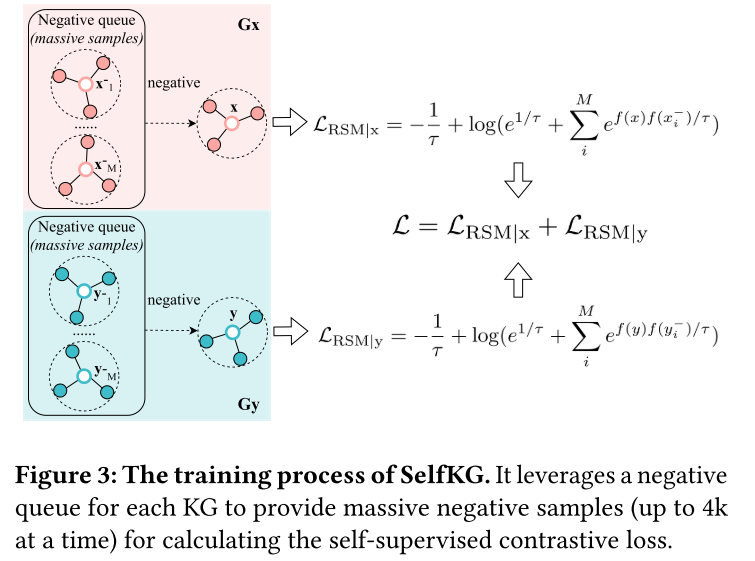
此外,由于 L λ ( f ; τ , M , p x ) \mathcal{L}_{\lambda}(f;\tau,M,p_{\mathrm{x}}) Lλ?(f;τ,M,px?) 的誤差項在 O ( M ? 2 / 3 ) O(M^{-2/3}) O(M?2/3) 中衰減(參見定理 2),我們使用相對大量的負樣本來提高性能。
3.4 Multiple Negative Queues
3.4 多個負隊列
增加負樣本的數量自然會導致額外的計算成本,因為動態編碼大量負樣本非常昂貴。為了解決這個問題,我們建議擴展 SelfKG 的 MoCo 技術。在MoCo中,維護了一個負隊列來將先前編碼的批次存儲為編碼負樣本,該隊列以有限的成本托管數千個編碼負樣本。
為了適應SelfKG中的自負采樣策略,我們實際上維護了兩個負隊列,分別與兩個輸入KG相關聯。圖 3 顯示了一個說明性示例。一開始,我們不會實現梯度更新,直到其中一個隊列達到預定義長度 1 + K 1+K 1+K,其中“1”表示當前批次, K K K 表示之前使用的批次數量 作為負樣本。給定 ∣ E ∣ |E| ∣E∣ 因為 KG 中的實體數量 K K K、和批量大小 N N N 受到以下約束
( 1 + K ) × N < min ? ( ∣ E x ∣ , ∣ E y ∣ ) , ( 6 ) (1+K)\times N<\min(|E_x|,|E_y|),\quad\quad\quad(6) (1+K)×N<min(∣Ex?∣,∣Ey?∣),(6)
保證我們不會在當前批次中抽取實體。因此,當前批次使用的負樣本的實際數量為 ( 1 + K ) × N ? 1 (1+K)\times N-1 (1+K)×N?1。
Momentum update. 負隊列帶來的主要挑戰是編碼樣本過時,特別是在訓練早期編碼的樣本,在此期間模型參數變化很大。因此,僅使用一個頻繁更新的編碼器的端到端訓練實際上可能會損害訓練。為了緩解這個問題,我們采用動量訓練策略,該策略維護兩個編碼器——在線編碼器和目標編碼器。雖然在線編碼器的參數 θ o n l i n e \theta_{online} θonline? 通過反向傳播立即更新,但用于編碼當前批次然后推入負隊列的目標編碼器 θ t a r g e t \theta_{target} θtarget?通過動量異步更新:
θ t a r g e t ← m ? θ t a r g e t + ( 1 ? m ) ? θ o n l i n e , m ∈ [ 0 , 1 ) ( 7 ) \theta_{\mathrm{target}}\leftarrow m\cdot\theta_{\mathrm{target}}+(1-m)\cdot\theta_{\mathrm{online}},m\in[0,1)\quad\quad(7) θtarget?←m?θtarget?+(1?m)?θonline?,m∈[0,1)(7)
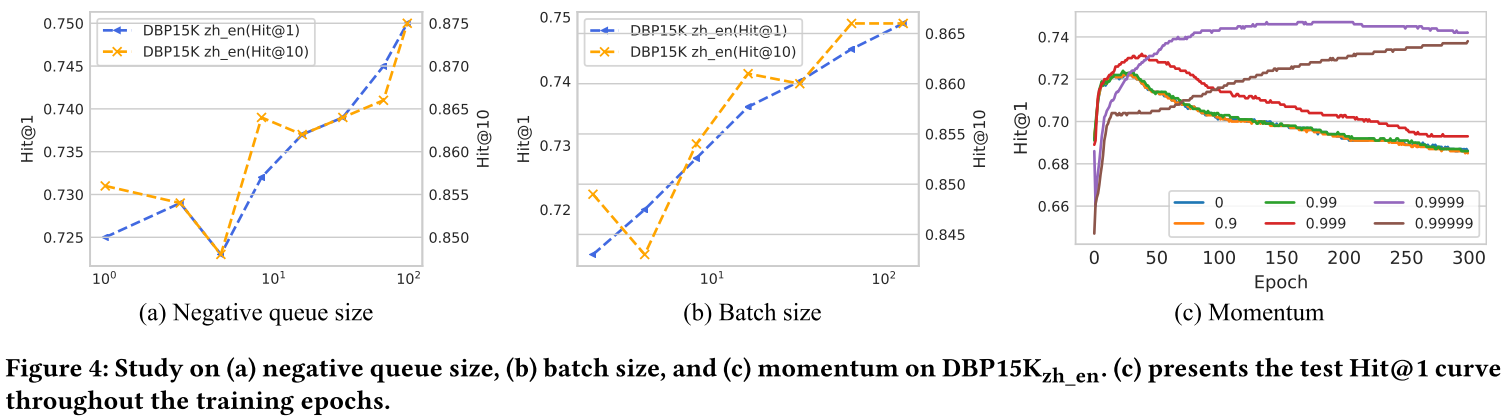
適當的動量不僅對于穩定的訓練很重要,而且還可能通過避免表示崩潰來影響最終的表現(參見圖 4)。我們在第 4 節中介紹了一系列相關的超參數研究。
總結。 我們提出了 SelfKG 用于自我監督的實體對齊。圖 2 說明: 1. 相對相似度度量 (RSM) 將 x x x 的非對齊實體( y 0 ? y^-_0 y0??、 y 1 ? y^-_1 y1?? 和 y 2 ? y^-_2 y2?? )推得足夠遠,而不是直接將底層對齊的 y y y 拉近 x x x(標記為對),無需標簽監督即可進行學習; 2. 自負采樣從 G x G_x Gx?中采樣負實體 x x x,以避免將真實 y y y采樣為其負數。 圖3說明了SelfKG的訓練。 它利用現有技術(來自預訓練語言模型和鄰域聚合器的嵌入)將實體嵌入初始化到統一空間中。 SelfKG的技術貢獻在于:
(1) 式2中自監督損失的設計通過 KG 中的相對相似度度量 (RSM) 啟用;
(2)自負抽樣策略進一步推進了方程2代入方程5避免樣本出現假陰性;
(3)將MoCo擴展到兩個負隊列以支持大量負樣本的有效使用。
4 EXPERIMENT
我們根據兩個廣泛認可的公共基準評估SelfKG:DWY100K 和 DBP15K。DWY100K 是單語言數據集,DBP15K 是多語言數據集。
DWY100K。 這里使用的 DWY100K 數據集最初由[31]構建。DWY100K 由兩個大型數據集組成: D W Y 100 K d b p _ w d DWY100K_{dbp\_wd} DWY100Kdbp_wd?(DBpedia 到 Wikidata)和 D W Y 100 K d b p _ y g DWY100K_{dbp\_yg} DWY100Kdbp_yg?(DBpedia 到 YAGO3)。 每個數據集包含 100,000 對對齊的實體。 然而, D W Y 100 K d b p _ w d DWY100K_{dbp\_wd} DWY100Kdbp_wd? 的“wd”(維基數據)部分中的實體由索引(例如 Q123)表示,而不是包含實體名稱的 URL,我們通過 Wikidata API for python 搜索它們的實體名稱。
DBP15K。 DBP15K 數據集最初由 [30] 構建,并由 [42] 翻譯成英文。DBP15K由三個跨語言數據集組成: D B P 15 K z h _ e n DBP15K_{zh\_en} DBP15Kzh_en?(中文到英語)、 D B P 15 K j a _ e n DBP15K_{ja\_en} DBP15Kja_en?(日語到英語)和 D B P 15 K f r _ e n DBP15K_{fr\_en} DBP15Kfr_en?(法語到英語)。 所有三個數據集均由多語言 DBpedia 創建,每個數據集包含 15,000 對對齊實體。我們報告原始版本和翻譯版本的結果。
我們在工作中使用的 DWY100K 和 DBP15K 的統計數據如表 1 所示。除了基本信息之外,我們還對數據集的平均(1 跳)鄰居相似度進行了研究,即一對對齊鄰居的對齊鄰居的比率 實體,表明鄰域信息的噪聲程度。我們觀察到 DWY100K 的鄰域信息非常有用,而 DBP15K 的鄰域信息可能非常嘈雜。
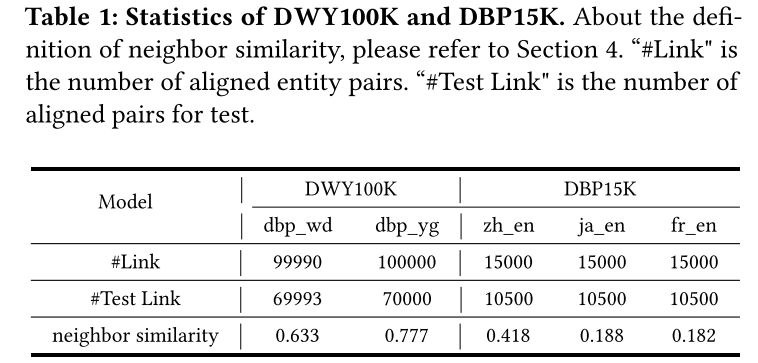
實驗設置。 我們遵循表1所示的DWY100K和DBP15K的原始分割。對于SelfKG,我們從原始訓練集中隨機取出5%作為早期停止的開發集。像大多數作品一樣,我們使用 H i t @ k ( k = 1 , 10 ) Hit@k(k = 1, 10) Hit@k(k=1,10) 來評估我們模型的性能。相似度分數是使用兩個實體嵌入的 ? 2 \ell_2 ?2? 距離計算的。批量大小設置為 64,動量 m m m 設置為 0.9999,溫度 τ \tau τ 設置為 0.08,隊列大小設置為 64。我們在配備 NVIDIA V100 GPU(32G) 的 Ubuntu 服務器上對 Adam 使用 1 0 ? 6 10^{?6} 10?6 的學習率。
4.1 Results
在這一部分中,我們報告 SelfKG 的結果以及 DWY100K 和 DBP15K 的基線。對于所有基線,我們從相應的論文中獲取報告的分數,或者直接從 BERT-INT、CEAFF或 NAEA的表格中獲取。根據訓練標簽的使用比例,我們將所有模型分為兩類:
- 受監督:訓練集中 100% 的對齊實體鏈接得到利用
- 無監督和自監督:利用了 0% 的訓練集。
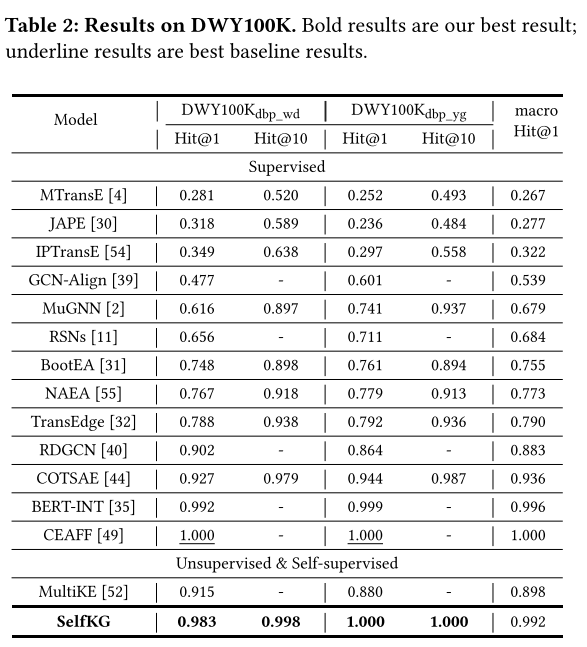
DWY100K 的整體性能。 從表 2 中,我們觀察到 SelfKG 優于除監督 CEAFF 和 BERT-INT 之外的所有監督和無監督模型。然而,在沒有任何監督的情況下,SelfKG 在 D W Y 100 K d b p _ w d DWY100K_{dbp\_wd} DWY100Kdbp_wd? 上僅落后于受監督的最先進的 CEAFF 1.2%。 D W Y 100 K d b p _ y g DWY100K_{dbp\_yg} DWY100Kdbp_yg?? 之所以能夠使 SelfKG 達到如此高的準確率,是因為其對齊的實體對的名稱分別具有很大的相似性,這使得這個數據集更加容易。這一鼓舞人心的結果意味著,至少對于像 DWY100K 這樣的單語言數據集,監督對于實體對齊來說并不是完全必要的。
DBP15K 的整體性能。 對于 DBP15K 數據集,我們發現不同的基線在實現中使用不同版本的 DBP15K。例如,BERT-INT 使用[30]構建的原始多語言版本,而其他一些方法包括RDGCN 和DGMC 使用機器翻譯(谷歌翻譯)來翻譯非英語數據集( 即 DBP15K 的 zh、ja、fr) 轉換為英文。 如果 DBP15K 被翻譯,則在某種程度上不應將其視為多語言設置。為了公平比較,我們報告了 SelfKG 在兩種設置下的結果。
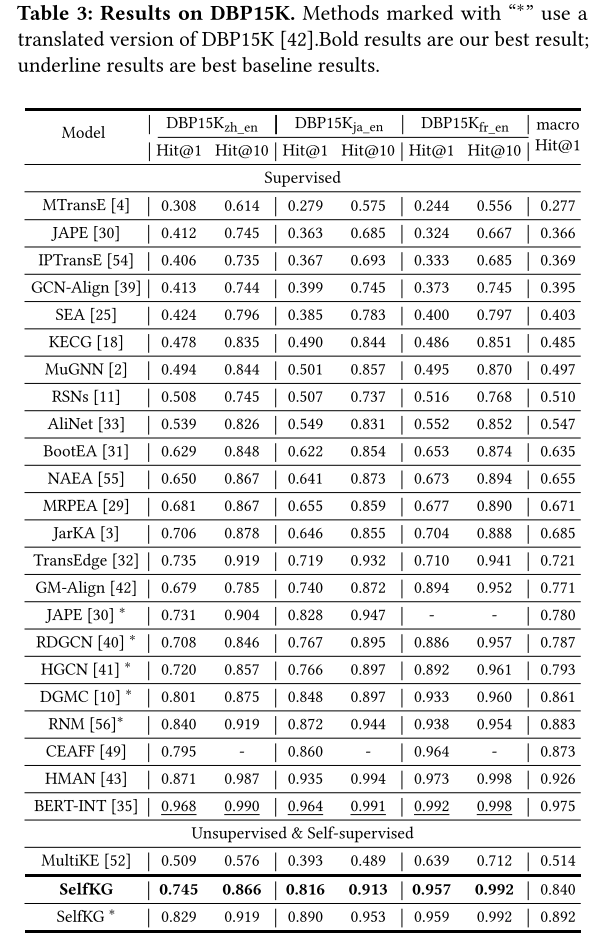
我們觀察到,SelfKG 擊敗了除 HMAN 、CEAFF 和 BERT-INT 之外的所有先前監督模型。最先進的監督技術與 SelfKG 之間存在差距,這表明多語言對齊肯定比單語言設置更復雜。我們還觀察到不同語言數據集之間存在明顯的差距。 D B P 15 K z h _ e n DBP15K_{zh\_en} DBP15Kzh_en? 的 Hit@1 最低, D B P 15 K j a _ e n DBP15K_{ja\_en} DBP15Kja_en?居中, D B P 15 K f r _ e n DBP15K_{fr\_en} DBP15Kfr_en?得分最高。然而,如果我們回想表1中給出的鄰居相似度得分,則 D B P 15 K z h _ e n DBP15K_{zh\_en} DBP15Kzh_en? 具有最高的鄰居相似度。這一發現表明,性能差異主要歸因于多語言環境帶來的挑戰,而不是結構相似性。
4.2 Ablation Study
我們分別對 SelfKG 的 DWY100K 和 DBP15K 進行了廣泛的消融研究。我們根據其引入的不同類型的信息消融了組件。此外,我們以 D B P 15 K z h _ e n DBP15K_{zh\_en} DBP15Kzh_en?數據集為例對一些重要的超參數進行了研究。
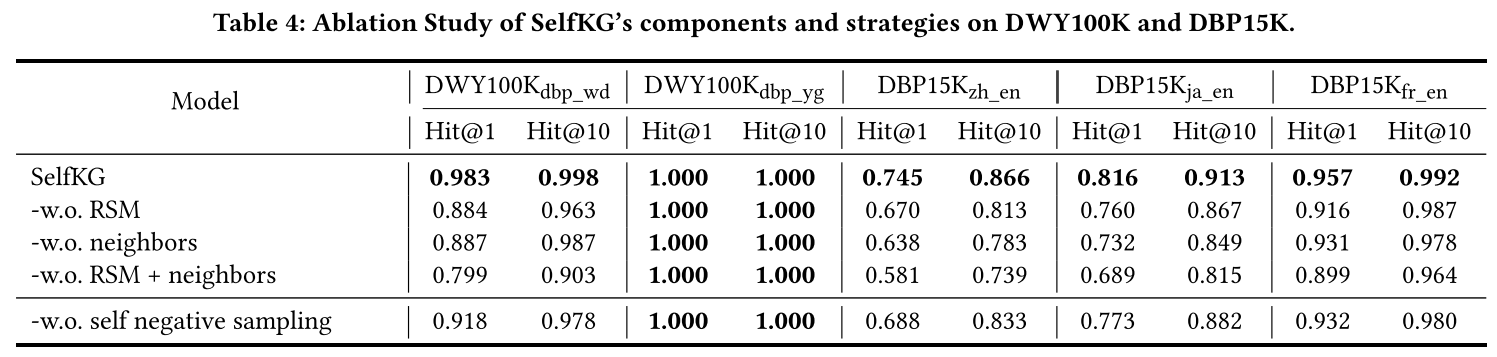
在表 4 中,我們提出了在 DWY100K 和 DBP15K 上對 SelfKG 進行的消融研究,包括鄰域聚合器的消融和基于相對相似性度量(RSM)的自監督對比訓練目標的消融(即使用LaBSE)。 我們首先觀察到 LaBSE 提供了相當好的初始化。然而,僅有 LaBSE 還不夠。 正如我們所看到的,在 DWY100K 上,LaBSE 從我們的 RSM 中受益匪淺,在 D W Y 100 K d b p _ w d DWY100K_{dbp\_wd} DWY100Kdbp_wd? 上絕對增益超過 10%,在 DBP15K 上絕對增益超過 5%。鄰域聚合器的使用在 DWY100K 和 DBP15K 上都提高了 SelfKG,這表明引入鄰域信息的重要性。
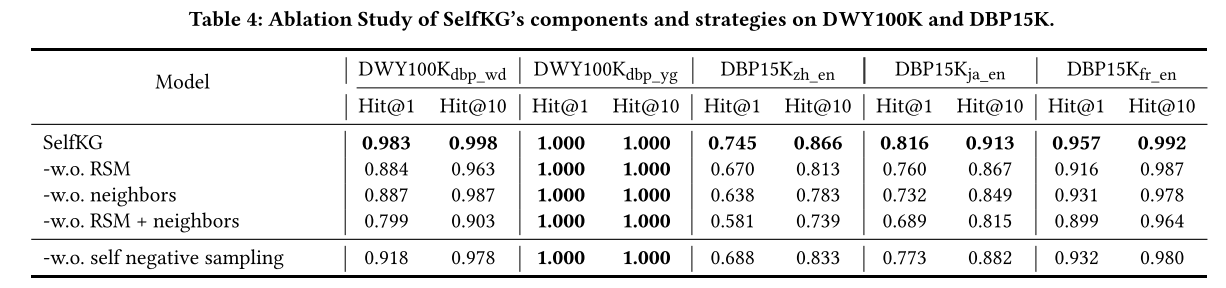
此外,我們在沒有自負采樣策略的情況下測試 SelfKG 的性能,這意味著我們像大多數基線一樣從目標 KG 中采樣負實體,但沒有標簽(這可能會引入真正的正實體)。 結果表明,自負采樣對于SelfKG來說是必要的,它帶來了2-7%的絕對增益。雖然策略性能的提高可以部分歸因于避免碰撞,但細心的讀者可能會想到為什么可能存在的重復實體的危害不如碰撞那么嚴重。可以潛在地解釋,實體對齊任務評估不同 KG(例如 G x G_x Gx?和 G y G_y Gy?)之間的對齊準確性,而不是在一個 KG 內(例如 G x G_x Gx?)。即使我們可能對 G x G_x Gx? 中的重復實體進行采樣并將它們推開,它可能只會對其與 G y G_y Gy? 中的目標實體 y y y 的相似性產生有限的影響。
預訓練單空間嵌入質量的影響。 為了闡明不同預訓練詞嵌入的影響,我們進行了一項實驗,用基線方法中廣泛使用的 FastText 嵌入替換 SelfKG 中使用的 LaBSE 嵌入。
首先,比較有訓練和沒有訓練的 FastText 結果,表 5 中訓練后的結果始終比訓練前的結果高 8.5% - 17.2%。這些結果也優于之前所有的無監督基線,表明 SelfKG 在應用時的有效性 任何嵌入初始化。
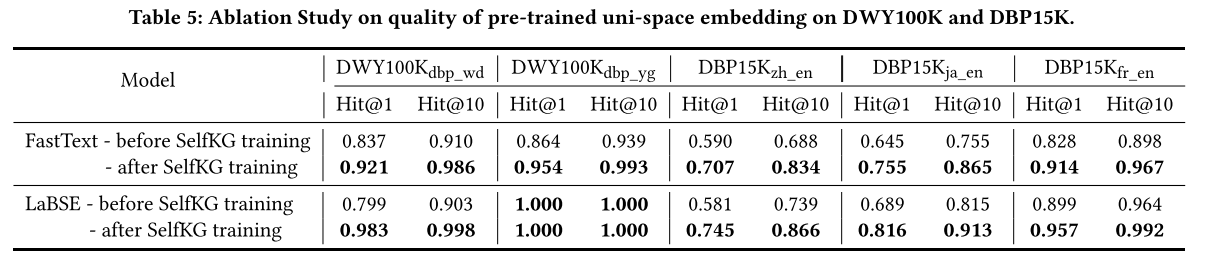
其次,將 FastText 結果與 LaBSE 結果進行比較,我們還證實,與 FastText 詞嵌入相比,LaBSE 等更強的預訓練語言模型將提高 SelfKG 的性能。基線方法也是如此,例如 HMAN 和 BERT-INT,它們利用多語言 BERT 作為編碼器。 盡管有更好的預訓練嵌入,但在我們的消融研究中(參見表 4 和表 5),我們表明“-w.o. RSM + nrighbors”(即 SelfKG 訓練之前的 LaBSE)可以顯著提高 6.4% - 28.2% SelfKG,它展示了我們方法的有用性。
關系信息和多跳結構信息的影響。 為了更好地檢驗關系結構信息是否有助于自監督環境(這可能與之前的監督觀察結果不同),我們首先進行合并多跳信息的實驗,然后整合關系信息。表 6 顯示了當利用多跳鄰居(更具體地說,20 個最近鄰居子圖)而不是 1 跳鄰居時 DBP15K 上的結果。我們觀察到性能實際上更差。這可能是因為不同知識圖譜的異質性,也因為鄰居噪聲可能在自我監督的環境中被放大。
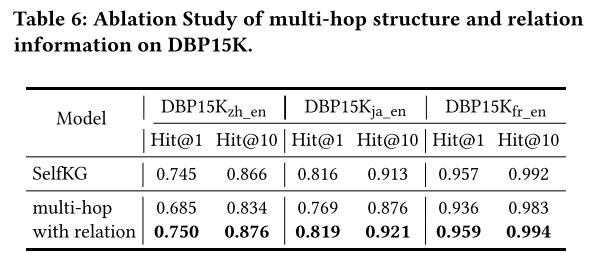
基于1跳限制,對于合并關系信息,我們將關系名稱嵌入及其相應的尾實體名稱嵌入作為新的1跳鄰居嵌入。我們可以看到,使用關系信息,結果略有改善,這表明關系信息有一點用處。
超參數的影響。 SelfKG中的主要超參數是(1)負隊列大小和批量大小(影響負樣本的容量),(2)控制SelfKG訓練穩定性的動量系數 m m m。
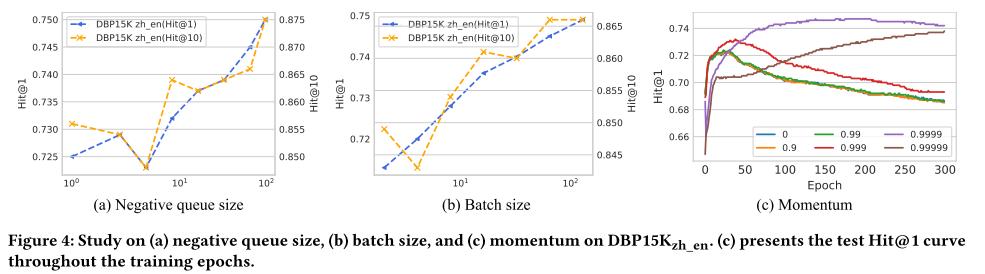
正如定理1和定理2所指出的,對比損失的誤差項隨 O ( M ? 2 / 3 ) O(M^{-2/3}) O(M?2/3)衰減,這表明擴大負樣本數量的重要性。將batch size固定為64,改變負隊列的大小,得到如圖4所示的曲線。當隊列大小在100到101之間時,性能提升并不明顯;當隊列大小在100到101之間時,性能提升不明顯;但當它增長到 102 時,改進就變得顯著了。 將隊列大小固定為64,隨著batch size的增加,提升更加穩定,從101到102。
對于動量系數 m m m,我們發現適當大的 m m m(例如 0.9999)通常對 SelfKG 更好。此外,適當的 m m m 對于更好的訓練穩定性也至關重要(參見圖 4)。 小動量會導致更快的收斂,但也會導致表示崩潰和隨之而來的較差性能。太大的動量(例如 0.99999)收斂太慢。
4.3 SelfKG v.s. Supervised SelfKG
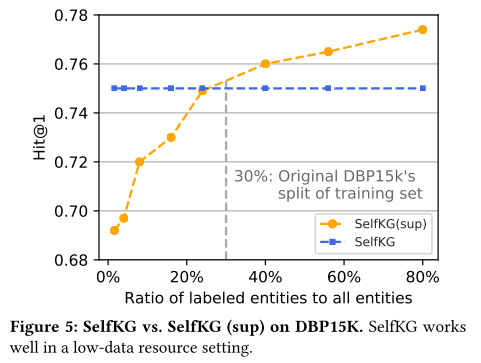
在實踐中,我們經常遇到數據資源低、監管非常有限的情況。為了證明 SelfKG 的可擴展性,我們在不同的數據資源設置上將自監督 SelfKG 與 D B P 15 K z h _ e n DBP15K_{zh\_en} DBP15Kzh_en? 上的監督對應 SelfKG (sup) 進行比較。 SelfKG (sup) 遵循傳統的監督實體對齊方法,使用絕對相似度度量,如式 3所示。
在我們的初步實驗中,我們發現原始 DBP15K 的數據分割(30% 標簽用于訓練,70% 用于測試)不足以展現 SelfKG (sup) 的優勢,導致 SelfKG (sup) 的 Hit@1 為 0.744 )和 SelfKG 為 0.745。 因此,我們構建了 D B P 15 K z h _ e n DBP15K_{zh\_en} DBP15Kzh_en? 的新分割,其中 20% 用于測試,80% 用于構建不同大小的訓練集。結果如圖 5 所示,其中橫軸表示 SelfKG (sup) 的訓練標記實體與所有實體的比率。我們觀察到 SelfKG 與使用 25% 標記實體量的 SelfKG (sup) 大致相當,這與我們在上述初步實驗中的觀察結果一致。當使用少于 25% 的標記實體量時,SelfKG 的表現比 SelfKG (sup) 好得多,這證明了 SelfKG 在低監督數據資源設置中的有效性。
5 RELATED WORK
實體對齊。 實體對齊,也稱為實體解析、本體對齊或模式匹配,是知識圖譜社區中的一個基本問題,已經研究了幾十年。在深度學習時代之前,大多數方法都專注于設計適當的相似性因子和基于貝葉斯的概率估計。[34]提出了將一致性轉變為最小化決策風險的想法。RiMOM提出了一種多策略本體對齊框架,該框架利用笛卡爾積的主要相似性因素來無監督地對齊概念。主張基于規則的鏈接并設計規則發現算法。[53]開發了一種基于因子圖模型的高效多網絡鏈接算法。
最近,基于嵌入的方法因其靈活性和有效性而引起了人們的關注。TransE是最開始引入嵌入方法來表示關系數據的。開發了基于TransE的知識圖譜對齊策略。[30]主張跨語言實體對齊任務并從 DBpedia 構建數據集。[51]建議將實體自我網絡嵌入到向量中以進行對齊。[39]引入GCN對知識圖中的實體和關系進行建模以執行對齊。[36]認為我們可以使用屬性和結構來相互監督。BERT-INT提出了一種基于BERT的交互式實體對齊策略,并顯著提高了公共基準上的監督實體對齊性能。[50]設計異構圖注意網絡來跨開放學術圖執行大規模實體鏈接。
然而,現在大多數基于嵌入的方法嚴重依賴監督數據,阻礙了它們在真實網絡規模噪聲數據中的應用。作為先前的努力,在[22]中,作者提出了概念鏈接的自監督預訓練,但具有下游監督分類。在這項工作中,我們努力研究不使用標簽的完全自我監督方法的潛力,以降低實體對齊成本,同時提高性能。
自我監督學習。 自監督學習無需人工監督即可學習數據中的共現關系,是一種數據高效且功能強大的機器學習范式。我們可以將它們分為兩類:生成式和對比式。
生成式自監督學習通常與預訓練有關。例如BERT、GPT、XLNet等開拓了語言模型預訓練領域,推動了自然語言處理的發展。最近 MoCo 和 SimCLR在計算機視覺領域提出了對比自監督學習來進行成功的視覺預訓練。利用實例辨別和對比損失的核心思想已被證明對于下游分類任務特別有用。自監督學習也被應用于圖預訓練任務,例如在GCC中,作者使用對比學習來預訓練子圖的結構表示,并將模型轉移到其他圖上。[47]建議按照 SimCLR 的策略向采樣圖添加增強,以提高圖預訓練性能。
6 CONCLUSION
在這項工作中,我們重新審視了實體對齊問題中監督的使用和效果,該問題的目標是在不同知識圖譜中對齊具有相同含義的實體。基于我們得出的三個見解 - 單空間學習、相對相似性度量和自負采樣,我們開發了一種自監督實體對齊算法 - SelfKG - 無需訓練標簽即可自動對齊實體。在兩個廣泛使用的基準 DWY100K 和 DBP15K 上的實驗表明,SelfKG 能夠擊敗或匹配大多數利用 100% 訓練數據集的監督對齊方法。我們的發現表明在實體對齊問題中擺脫監督的巨大潛力,并且預計會有更多的研究來更深入地理解自監督學習。
論文鏈接:
https://arxiv.org/pdf/2203.01044
GitHub倉庫:
https://github.com/THUDM/SelfKG









)

)

系列-管理查詢調整)
)




