一 定義
背景:在推出GPT-4o之前,使用語音模式與ChatGPT交流的延遲較長,無法直接觀察語調、多個說話者或背景噪音,且無法輸出笑聲、歌唱或表達情感。
GPT-4o作為OpenAI推出的一款多模態大型語言模型,代表了這一交互技術的重要發展方向。
GPT-4o是OpenAI推出的最新旗艦級人工智能模型,它是GPT系列的一個重要升級,其中的"o"代表"Omni",中文意思是“全能”,凸顯了其多功能特性。該模型被設計為能夠實時對音頻、視覺和文本進行推理,是邁向更自然人機交互的重要一步。
強調這是一個全能或多模態的模型。GPT-4o的一大特點是其能夠處理多種類型的數據輸入和輸出,包括文本、音頻和圖像,實現了跨模態的理解和生成能力。這意味著它不僅能理解和生成文本,還能理解音頻內容(如語音)和圖像信息,并能將這些不同模態的信息綜合處理和輸出,極大地擴展了AI的應用場景和交互方式。
解決方案:通過訓練一個全新的端到端模型,GPT-4o可以跨越文本、視覺和音頻的多模態,將所有輸入和輸出都由同一個神經網絡處理(圖像音頻兩個模態對齊于語言大模型),從而提高了對多模態數據的理解和處理能力。
核心特點:GPT-4o接受任何文本、音頻和圖像的組合作為輸入,并生成任何文本、音頻和圖像的組合輸出。它在語音輸入方面的響應速度為232毫秒,平均為320毫秒,與人類對話的響應時間相似。
優勢:GPT-4o在文本、推理和編碼智能方面表現出與GPT-4 Turbo相當的性能水平,同時在多語言、音頻和視覺能力方面創下新的高水平。
安全性和限制:GPT-4o在設計上跨越多種模態,并通過過濾訓練數據和后期訓練調整模型行為等技術來確保安全性。對于新添加的模態,如音頻,GPT-4o認識到存在各種新的風險,并采取了相應的安全干預措施。
總體而言,GPT-4o代表了深度學習在實際可用性方面的最新進展,提供了更加靈活、高效和安全的多模態智能解決方案。
二 關鍵特點
? ? ? ?GPT-4o基于Transformer架構,這是一種深度學習模型,特別適合處理序列數據,如文本、音頻波形和圖像像素序列。它利用了大規模的預訓練方法,在互聯網上抓取的海量多模態數據集上進行訓練,學習到語言、聲音和視覺世界的復雜模式。通過自注意力機制,模型能夠理解輸入數據中的長程依賴關系,并在生成輸出時考慮上下文的全面信息。
? ? ? 與之前的單模態模型相比,GPT-4o通過聯合訓練實現了跨模態的表示學習,使得模型能夠理解不同模態之間的聯系,實現更自然、更綜合的人機交互。此外,它還優化了推理速度和成本效率,使其更加實用和廣泛適用。
以下是GPT-4o的一些關鍵特點和原理,它們揭示了下一代人機交互技術的可能面貌:
-
多模態交互:GPT-4o支持文本、圖像、音頻和視頻等多種輸入模態,能夠理解和生成跨模態的內容。這意味著用戶可以通過語音、文字、圖片或視頻與系統交互,而系統也能夠以相應的形式提供反饋。
-
實時處理:GPT-4o能夠實時處理語音、視覺和文本信息,響應速度接近人類自然對話的速度4。這為即時交互提供了可能,使得人機對話更加流暢和自然。
-
端到端訓練:GPT-4o實現了多模態端到端訓練,所有的輸入和輸出都由同一個神經網絡處理。這種設計減少了信息在不同處理階段之間的丟失,提高了交互的準確性和效率。
-
性能和效率:GPT-4o在性能上取得了顯著提升,運行速度是前代模型的兩倍,同時成本減半。這使得它能夠被更廣泛地應用于各種場景,包括客戶服務、教育、娛樂等領域。
-
情緒識別與響應:GPT-4o能夠檢測和響應用戶的情緒狀態,調整其語氣和響應方式,使得交互更加自然和有同理心。
-
安全性:GPT-4o在設計時考慮了安全性,雖然語音模態帶來了新的安全挑戰,但OpenAI表示已將風險控制在中等水平以下。
-
可擴展性:GPT-4o的API定價比前代產品便宜,速度更快,調用頻率上限更高,這使得開發者和企業能夠更容易地將GPT-4o集成到他們的應用程序中。
-
特殊任務的token:GPT-4o可能采用了特殊的token來標記不同的任務,以便模型能夠生成對應的內容,這有助于提高模型在特定任務上的表現。
通過這些特點和原理,我們可以看到下一代人機交互技術正朝著更加智能、直觀和個性化的方向發展。GPT-4o作為這一趨勢的代表,展示了未來人機交互的潛力和可能性。
下一代人機交互技術的核心在于實現更自然、更直觀的交互方式,讓機器能夠更好地理解和響應人類的指令和需求。
三 基本原理
? ? ? 根據Open-AI公開的信息,他們訓練了一個跨越了音頻、視覺、文本模態的端到端模型,這表明所有的輸入與輸出都經過同一個神經網絡。這個技術路線與現有的一些開源模型(比如LLAVA、Qwen等多模態模型)不同。Google在23年底公布的Gemini多模態模型,就采用的是這種端到端的方案,并且在當時取得了非常好的效果,不過關于模型的內部以及訓練過程,并沒有透露相關細節。
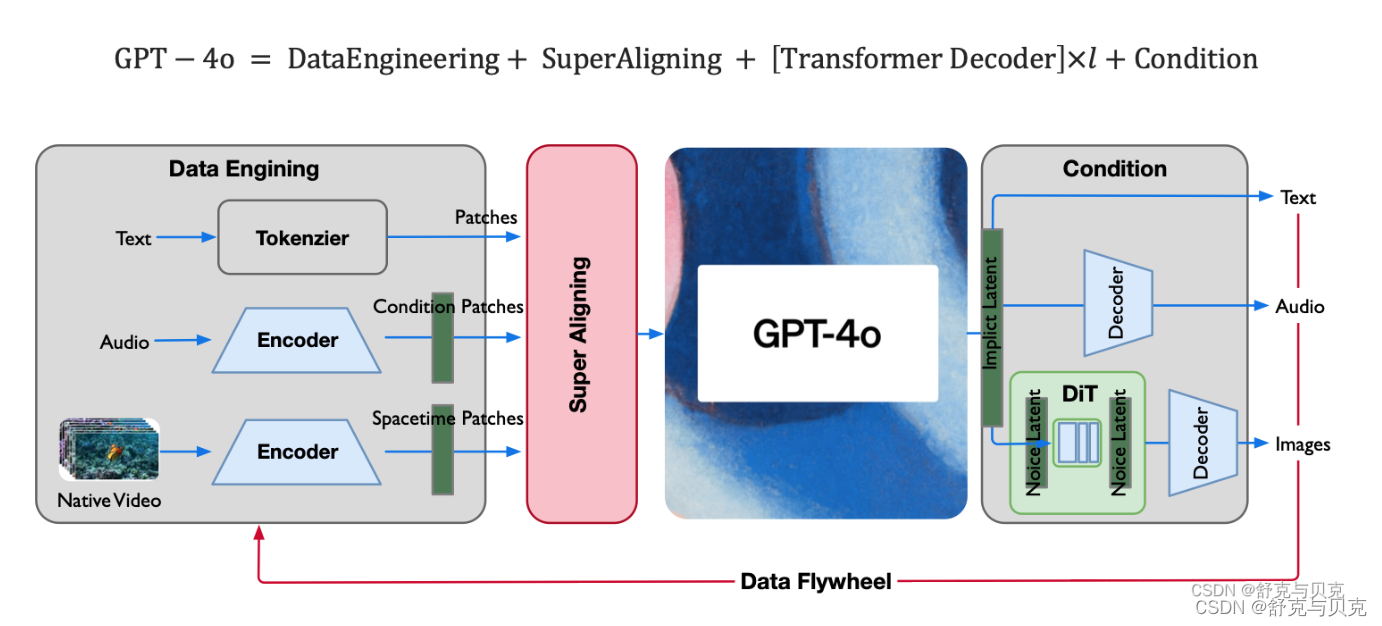
? ? ? ?從相關技術報告中推測,或許他們針對不同的輸入,除了類似于文本token化等輸入之前的操作外,針對音頻、視覺、文本都有一個專業的token標記開頭以及結尾,然后按照順序組合成輸入來避免了采用模態融合方法帶來的某些信息丟失的缺陷。也許GPT-4o模型在結構上大概率與Gemini相似,但為了有更好的效果以及更快的速度,表明其最終的方案與Gemini又有很大不同。
1. Data Engineering(輸入)
- 語音輸入:通過語音識別系統將用戶的語音轉換成文本, 參考 Whisper v3 與 Text 結合作為 Multitask training format 再編碼
- 圖像輸入:使用圖像識別技術來解析和理解輸入的圖像內容,借鑒 Sora 的 Spacetime Patches 極致編碼壓縮
- 文本輸入:LLM 仍然是主戰場,投入人力超1/2,將用戶的文本輸入新的 Tokenizer直接送入模型。
? ? ? 對于文本、視覺、音頻信息,若按照LLM的處理思想,也即預測下一個token的路線,那么,需要對各個模態數據tokenizer,這是一種很普遍的思路。若回顧Gemini多模態模型,會發現Google選用了Flagmni作為視覺Tokenizer,USM作為音頻tokenizer,然后針對文本也有對應的Tokenizer,最終或許按照大語言模型的訓練思路,來訓練多模態模型。鑒于Open-AI的技術積累以及資源,他們肯定有針對各個模態的Tokenizer,只不過很大概率他們的模型比現有開源模型效果更強。
2. Super Aligning(模態融合)
將不同模態的信息轉換為統一的內部表示,將語音識別后的文本、圖像識別的特征向量等融合。?https://openai.com/index/introducing-superalignment/?utm_source=tldrai
- 端到端 E2E 的 MLM 大模型,對齊不同模態的輸入,統一作為 Transformer 結構的長序列輸入;
- 讓能力弱的大模型監督能力強的大模型(LLM supervise MLM)
3. Transformer Decoder(模型)
- 純 Transformer Decoder 架構,更加方便訓練進行千卡、萬卡規模的并行;
- 推理使用大融合算子(Flash Attention)進行極致加速;
- 符合 OpenAI 一貫 Everything Scaling Law 的方式;
4. Output
- 輸出可配置、可選擇 text/audio/images,因此是 Conducting 的case,統一 Transformers Tokens 輸入可實現;
- Images 依然借鑒 SORA 使用 DiT 作為生成,但此處生成的為 Images not Videos;
- Audio 與 Text 應該會有對齊,保持同聲傳譯;
多模態數據工程:
1.LLM tokens 減少,讓大模型的輸入序列 Tokens 結合多模態統一為 Signal 長序列;
2.詞表增大 Token 減少, 分詞從 100K 到 200K,LLM 編碼率進一步增強;
3.Video 借鑒 SORA 對 spacetime patch 對時序極高編碼率;
模型訓練:
1.弱監督/自監督為主,否則多模態對齊進行統一模式訓練非常難;
模型結構與訓練:
1.通過 Super Aligning 對 Text、Audio、Video 三種模態進行對齊;
2.仍然以 LLM(GPT4) 能力為主,加入多模態維度 Tokens 形成一個大模型;
三?下一代對話式人機交互
什么是對話式人機交互(對話式人工智能)?
對話式智能人機交互是一套技術,允許計算機通過自動表達信息與人類用戶進行類人互動。對話式智能人機交互可幫助機器人引導人類用戶實現特定目標,并允許機器與人類進行大規模的類人對話。
從本質上講,對話式人機交互可以定義為負責機器人交流背后邏輯的元素,它是聊天機器人的大腦和靈魂,也是一系列應用的靈魂。
對話式人工智能用于改善人類用戶與計算機之間的自然語言處理能力
對話式人工智能由自然語言處理(NLP)提供支持。NLP 專注于解釋人類語言,而開發人員則開發對話如何展開的基本框架。簡單地說,對話式人工智能與人類合作,通過對話平臺實時創建虛擬對話體驗。這是人工智能的進化,它已經學會了說話和傾聽。
對話式人工智能是如何工作的?
對話式人工智能的工作原理是,應用程序接收人類輸入的數據,這些數據可以是書面或口語形式。如果是口語信息,則使用自動語音識別(ASR)將口語轉錄為文本。
1. 由人類用戶生成輸入
人類用戶向對話式人工智能提供語音或文字輸入,通常是通過虛擬助手或chatbots 。
2. 對話式人工智能的輸入分析
會話式人工智能在分析文本輸入時使用 NLU,在處理語音信息時使用 ASR,通過對所提供數據的深入分析來確定用戶信息背后的意圖。這需要高級語言分析,只有會話式人工智能才能做到。
3. 由虛擬助理進行對話管理以創建回復
一旦聊天機器人或虛擬助手分析了用戶的信息并確定了互動背后的意圖,就會根據自然語言生成(NLG)或從工作流/問答中選擇做出回應。
4. 不斷提高對話式人工智能的能力
對話式人工智能每次與客戶或消費者互動,都會增加用于訓練的數據集的規模,從而提高其理解和響應用戶輸入的精確度。因此,對話式人工智能將不斷提高性能,為用戶提供更好的服務和客戶體驗。
5. 對話式人工智能依賴于 NLP、NLU、NLG 和強化學習
應用程序使用作為 NLP 一部分的自然語言理解(NLU)來確定文本的含義及其背后的意圖。一旦理解了對話內容,系統就會使用對話管理,以便根據對文本含義的理解做出回應。它還可以使用自然語言生成(NLG),即 NLP 的另一個要素,以便將其回復轉換為人類可以理解的格式。完成這一步驟后,應用程序會將其回復發送給用戶(通過文本或語音合成)。
最后,機器學習可以讓應用程序不斷學習并改進其性能。深度學習讓機器在每次交互中變得更加智能,從而不斷改進與人類的交互。
對話式人工智能使用了哪些技術?
對話式人工智能使用以下技術來理解、反應和學習互動
自動語音識別 (ASR)
自動語音識別(ASR)技術的核心是將口語轉錄為書面文本。其實現過程通常包括以下幾個關鍵步驟:
-
信號處理:將語音信號轉換為可以被處理的數字形式。這包括采樣、量化、預處理(如去除噪聲、歸一化等)。
-
特征提取:從語音信號中提取特征參數,如梅爾頻率倒譜系數(MFCC)、線性預測編碼(LPC)等,這些特征用于表示語音信號的短時能量、頻率和時域信息。
-
聲學模型:利用深度神經網絡(如卷積神經網絡、循環神經網絡)或傳統的隱馬爾可夫模型(HMM),將特征參數映射到音素概率分布上。
-
語言模型:利用n-gram模型或基于深度學習的語言模型(如LSTM、Transformer),結合上下文信息,提高識別精度。語言模型可以預測給定上下文下最可能的詞序列。
-
解碼:將聲學模型和語言模型的輸出結合起來,使用維特比算法或束搜索算法生成最有可能的文本序列。
-
后處理:對識別結果進行處理,包括拼寫檢查、語法修正等,以提高識別文本的可讀性。
實例:Whisper v3 是一個先進的開源ASR模型,通過結合 Transformer 架構和大量預訓練語音數據,實現了高精度的語音轉錄。
圖像識別系統
圖像識別系統通過解析圖像數據,從中提取有用的信息,如物體、場景、人物等。其實現過程通常包括以下幾個關鍵步驟:
-
圖像預處理:包括圖像縮放、裁剪、歸一化、去噪等步驟,以保證輸入圖像的一致性和質量。
-
特征提取:使用卷積神經網絡(CNN)提取圖像的空間特征。這些網絡通常由多個卷積層、池化層和全連接層組成,用于捕捉圖像的層次結構特征。
-
對象檢測與分類:通過進一步處理提取的特征,可以進行對象檢測(如使用R-CNN、YOLO、SSD等算法)和圖像分類(如ResNet、Inception等架構),從而識別圖像中的特定對象或場景。
-
后處理:對檢測或分類結果進行優化,如非極大值抑制(NMS)以去除冗余檢測框、結果過濾等。
實例:Sora 是一個圖像解析和特征提取系統,可以識別圖像中的多種物體并進行分類。
自然語言處理(NLP)
自然語言處理(NLP)涉及對文本數據的理解和生成,其實現過程通常包括以下幾個關鍵步驟:
-
文本預處理:包括分詞、去停用詞、詞干提取、詞形還原等步驟,旨在規范化文本數據。
-
特征表示:將文本轉換為機器可處理的格式,如詞袋模型(BoW)、詞嵌入(Word2Vec、GloVe)、上下文嵌入(BERT、GPT)。
-
語法和句法分析:使用依存分析或成分分析解析句子的語法結構,以理解句子的主謂賓關系。
-
語義分析:包括詞義消歧、命名實體識別、共指消解等技術,旨在理解文本的實際含義和上下文關系。
-
情感分析:通過分類器(如LSTM、CNN、Transformer)分析文本的情感極性(正面、負面、中性),以理解用戶的情感狀態。
-
意圖識別:通過分類模型或序列標注模型(如CRF、LSTM-CRF)識別用戶的意圖,如詢問、抱怨、建議等。
實例:NLP 技術用于對話式 AI 中的意圖識別和情感分析,如識別用戶詢問的內容和情感態度。
深度學習框架
深度學習框架用于構建和訓練神經網絡模型,常見的包括:
-
TensorFlow:由谷歌開發的開源框架,支持多種神經網絡結構和分布式訓練,廣泛應用于工業界和學術界。
-
PyTorch:由Facebook開發的開源框架,以其靈活性和易用性受到廣泛歡迎,支持動態計算圖和自動微分,適合研究和生產環境。
這些框架提供了豐富的工具和庫,用于構建、訓練和部署深度學習模型,包括數據處理、模型定義、訓練控制、性能優化等功能。
文本到語音(TTS)系統
將書面文本轉換為自然流暢的語音輸出。其實現過程通常包括以下幾個關鍵步驟:
-
文本分析:對輸入文本進行語言學分析,包括分詞、詞性標注、語法分析等。
-
文本規范化:處理縮寫、數字、符號等,將其轉換為標準文本形式。
-
語音合成:使用前端處理生成的文本表示,經過聲學模型和聲碼器生成語音波形。常用的模型包括基于深度學習的Tacotron、WaveNet等。
-
后處理:對生成的語音波形進行處理,如平滑、降噪等,以提高語音的自然度和可懂度。
實例:Text-to-Speech API 提供多種語言和聲音選擇,可以將文本內容轉換為高質量的語音輸出。
多模態融合框架
?多模態融合框架用于整合來自不同模態(如文本、語音、圖像、視頻)的信息,以實現更復雜和智能的AI應用。其實現過程通常包括以下幾個關鍵步驟:
-
特征提取:從不同模態的數據中提取特征,使用各自適合的技術(如CNN用于圖像,RNN用于文本,Transformer用于多模態融合)。
-
特征融合:將不同模態的特征進行融合,可以是簡單的拼接、加權平均,或使用更復雜的模型(如多模態Transformer)進行融合。
-
聯合建模:通過聯合訓練模型來學習不同模態之間的相關性和相互作用,以提高整體性能。
-
決策融合:在推理階段,將來自不同模態的決策結果進行融合,可以是簡單的投票、加權平均,或使用更多元的融合策略。
實例:自定義或開源的多模態融合框架,可以用于整合圖像、語音和文本信息,實現綜合分析和決策。
API網關
?API網關用于管理和路由API請求,是微服務架構中的關鍵組件。其功能通常包括:
-
請求路由:根據請求的路徑、方法、頭信息等,將請求路由到合適的后端服務。
-
負載均衡:將請求分配到多個后端服務實例上,以實現高可用性和負載均衡。
-
身份驗證和授權:使用OAuth、JWT等標準進行用戶身份驗證和授權,確保API訪問的安全性。
-
速率限制和配額:控制每個用戶或應用的請求速率和配額,以防止濫用和資源耗盡。
-
日志和監控:記錄請求日志和性能指標,方便監控和故障排除。
實例:API Gateway 是一個流行的API管理工具,支持各種功能,如請求路由、負載均衡、身份驗證等。
數據存儲和處理
詳細解釋與技術細節: 數據存儲和處理系統用于管理和處理大量數據,常見技術包括:
-
MongoDB:一種NoSQL數據庫,支持靈活的文檔存儲和查詢,適合存儲結構化和半結構化數據。
-
Redis:一種內存數據庫,支持高速讀寫操作,適合做緩存和實時數據處理。
-
Elasticsearch:一個分布式搜索引擎,支持全文搜索和復雜查詢,適合處理日志和分析數據。
-
Apache Kafka:一個分布式消息系統,支持高吞吐量的實時數據流處理,適合數據管道和事件驅動架構。
-
Hadoop/Spark:分布式數據處理平臺,支持大規模數據處理和分析,適合批處理和流處理任務。
機器學習平臺
機器學習平臺用于模型的訓練、部署和管理,常見平臺包括:
-
AI Platform:谷歌云的機器學習服務,支持分布式訓練、自動化機器學習、模型部署等功能。
-
AWS SageMaker:亞馬遜云的機器學習服務,提供端到端的機器學習工作流,包括數據準備、模型訓練、超參數調優、部署和監控。
-
Azure Machine Learning:微軟云的機器學習服務,支持自動化機器學習、分布式訓練、模型管理和部署。
-
Databricks:基于Apache Spark的統一數據分析平臺,支持機器學習、數據工程和數據科學工作流。
這些平臺提供豐富的工具和服務,幫助開發者和數據科學家更高效地構建、訓練和部署機器學習模型。
安全和隱私保護
?確保數據安全和用戶隱私是AI應用的重要方面,常見技術包括:
-
OAuth:一種開放標準的授權協議,允許第三方應用訪問用戶資源而無需暴露用戶憑據。
-
JWT:JSON Web Token,用于在網絡應用間傳遞驗證信息,具有自包含性和安全性。
-
加密技術:使用對稱加密(如AES)、非對稱加密(如RSA)、哈希函數(如SHA)等技術保護數據的機密性和完整性。
-
訪問控制:定義和管理用戶權限,確保只有授權用戶才能訪問敏感數據和功能。
-
數據匿名化:通過數據脫敏、偽匿名化等技術保護用戶隱私,防止數據泄露。
-
隱私計算:包括差分隱私、聯邦學習等技術,在保證數據隱私的前提下進行數據分析和模型訓練。
實例:使用OAuth、JWT進行API認證和授權,結合加密技術和數據匿名化措施,確保數據安全和用戶隱私。
對話式人工智能應用有哪些不同類型?
對話式人工智能應用多種多樣:
讓客戶輸入關鍵字,以獲得對其詢問的適當回答。人工智能使用自然語言處理(NLP)來分析、理解和處理人類語音。常見的有基于規則的聊天機器人、基于檢索的聊天機器人和基于生成的聊天機器人。
什么是基于規則的聊天機器人?
基于規則的人工智能聊天機器人會根據一組預定義的規則回答人類的問題,這些規則可能很簡單,也可能非常復雜。這種類型的在線聊天機器人受其規則集的限制,在回答不符合其規則的問題時效率會很低,因為它沒有經過訓練。因此,這類在線聊天機器人并不總能滿足客戶的期望,通常只能回答簡單的問題。
什么是基于檢索的聊天機器人?
基于檢索的人工智能聊天機器人擁有一個預定義問題數據庫,會使用啟發式方法為用戶或客戶的問題找到最合適的答案。搜索結果是通過從簡單算法到復雜的機器學習和深度學習等不同手段生成的。該系統擅長預測一組關鍵詞,但不會生成新內容。
什么是基于生成式的聊天機器人?(下一代聊天機器人)
生成模型聊天機器人 "是一種不使用任何預定義數據庫的聊天機器人,而深度學習是一種基于機器翻譯技術的模型。"生成模型 "通常基于機器翻譯,不是將一種語言翻譯成另一種語言,而是將請求 "翻譯 "成輸出。
它最初是為了解決機器翻譯問題而發明的,不過后來在摘要和問題解答等過程中也證明了它的成功。它們能夠幫助消費者解決各種各樣的問題。
基于人工智能的對話工具面臨哪些挑戰?
如果正在使用聊天機器人,你可能至少遇到過以下一種挑戰:
隱私和安全
在處理敏感數據和消費者個人信息時,對話式人工智能應用必須以非常安全的方式設計,以確保隱私得到尊重。
通過改變交流模式找到適當的對策
影響機器與人類對話的因素有很多,如語言、諷刺、俚語等。人工智能對話系統必須適應交流中的不斷變化,才能跟上人類對話的節奏。


特點和規格)
7-5 sdut-C語言實驗-鏈表的逆置)





)









