高斯混合模型,簡稱GMM,對數據可以進行聚類或擬合,多用于傳統語音識別。他會將每個數據看做多個高斯分布混合生成的。
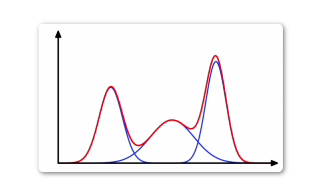
對于無標簽的數據進行聚類,一般采用高斯混合模型處理。
算法過程
1.首先進行初始猜測,假設有n個簇,然后隨機選擇數據點,作為聚類中心點。
2.EM算法多次迭代,每次迭代更新中心點,并且還會計算每個數據點屬于每個簇的概率。
3.迭代完成
高斯混合模型,簡稱GMM,對數據可以進行聚類或擬合,多用于傳統語音識別。他會將每個數據看做多個高斯分布混合生成的。
對于無標簽的數據進行聚類,一般采用高斯混合模型處理。
算法過程
1.首先進行初始猜測,假設有n個簇,然后隨機選擇數據點,作為聚類中心點。
2.EM算法多次迭代,每次迭代更新中心點,并且還會計算每個數據點屬于每個簇的概率。
3.迭代完成
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/bicheng/92067.shtml 繁體地址,請注明出處:http://hk.pswp.cn/bicheng/92067.shtml 英文地址,請注明出處:http://en.pswp.cn/bicheng/92067.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!

)


![[spring-cloud: 負載均衡]-源碼分析](http://pic.xiahunao.cn/[spring-cloud: 負載均衡]-源碼分析)







)


?? 的開源庫詳解)


堆)