目錄
1.機器字長,存儲字長與指令字長
2.指令周期,機器周期,時鐘周期
3.CPI,IPS,MIPS
4.翻譯程序和匯編程序
5.計算機體系結構和計算機組成的區別和聯系
6.基準程序執行得越快說明機器的性能越好嗎?
1.機器字長,存儲字長與指令字長
不同的機器三者在數值上可以相等也可以不等:
機器字長:CPU內部用于整數運算的數據通路的寬度(也就是CPU一次可以處理的二進制代碼的位數)。通常等于ALU的寬度或通用寄存器的位數。
數據通路是指數據在指令執行過程中所經過的路徑及路徑上的部件,主要是CPU內部進行數據運算,存儲和傳送的部件,這些部件的寬度基本上要一致才能相互匹配。因此機器字長等于ALU的寬度或通用寄存器的位數。
存儲字長:一個存儲單元中包含的二進制代碼的位數,它等于MDR的位數。
補充:MDR的位數:存儲單元的位數? ? ? ? MAR的位數反映了最多可尋址的存儲單元的個數,如MAR:10位,那么最多有2^10個存儲單元,MAR的長度與PC的長度相等。
指令字長:一個指令字中包含的二進制代碼的位數。
指令字長一般取存儲字長的整數倍,若指令字長等于存儲字長的2倍,則需要2個訪存周期來取出一條指令,若指令字長等于存儲字長,則只需要1個訪存周期取指令,指令周期等于機器周期。
早期的存儲字長一般與指令字長、字長相等,因此訪問一次主存儲器便可取出一條指令或一個數據。隨著計算機的發展,指令字長、存儲字長都可變,但必須都是字節的整數倍。
機器字長會直接影響加法器(ALU),內部總線寬度(數據通路的寬度)及寄存器的位數,進而影響數據的精度和表示范圍;如果提高機器字長,一個數能表示的精度和范圍就越高,但隨之而來的是成本的增加
2.指令周期,機器周期,時鐘周期
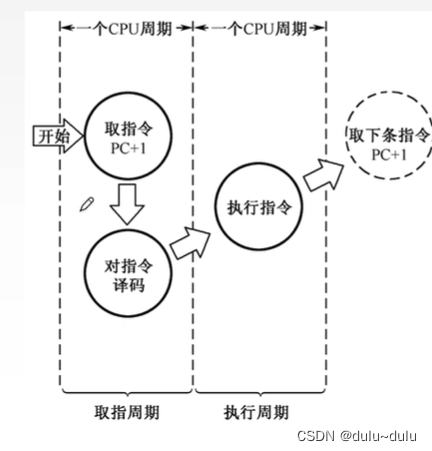
指令周期:CPU從主存中取出并執行一條指令所需的全部時間
取出并執行一條指令包括:取出指令-->分析指令-->執行指令,如下圖所示:
對指令譯碼的過程就是分析指令的過程
機器周期:
機器周期又稱CPU周期,一個指令周期常用多個機器周期表示。一個如上圖所示,取指操作算一個機器周期,執行指令操作也算一個機器周期。
時鐘周期:一個機器周期又包含若干時鐘周期(也稱為節拍、T周期或CPU時鐘周期,它是CPU操作的最基本單位)
CPU上標注的主頻,例如主頻=3.0GHz,就表示每秒鐘可以發送3.0G次的時鐘周期
若想了解得更加詳細,推薦看看這篇:指令執行過程
3.CPI,IPS,MIPS
CPU時鐘周期:上面講過,時鐘周期是CPU工作的最小時間單位。
主頻:機器內部主時鐘的頻率,即時鐘周期的導數(1/CPU時鐘周期)。對于同一型號的計算機,主頻越高,完成指令的一個執行步驟所用時間越短,執行指令的速度越快。
CPI(Cycle Per Instruction):執行一條指令所需要的時鐘周期數。不同指令的時鐘周期數可能不同,因此對于一個程序或一臺機器來說,其CPI指該程序或該機器指令集中的所有指令執行所需的平均時鐘周期數,此時CPI是一個平均值。
指令執行速度:主頻/平均CPI,主頻表示CPU內部主時鐘的頻率,例如主頻1.5GHz說明1s有1.5G=1.5*10^9個時鐘周期。平均CPI表示一條指令的時鐘周期數,所以?指令執行速度=主頻/平均CPI,即1s執行的指令數。
用戶CPU時間:總時鐘周期數/主頻,總時鐘周期數=CPI(一條指令的時鐘周期數)*指令條數,主頻:1s的時鐘周期數,所以用戶CPU時間=總時鐘周期數/主頻
一定不要記,看題目理解即可!
IPC:表示每個時鐘周期運行多少條指令,機CPI的倒數(1/CPI)。
IPS(Instructions Per Second):每秒執行多少條指令,IPS=主頻/平均PCI。
CPU執行時間:CPU時鐘周期數/主頻=指令條數*CPI*時鐘周期的長度=(指令條數*CPI)/主頻
CPU執行時間取決于三個要素:CPI,主頻和指令條數。三個條件下過戶制約,例如,更改指令集可以減少程序所含指令條數,但同時可能引起CPU結構的調整,從而可能會增加時鐘周期的寬度(降低主頻)。
MIPS(Million Instructions Per Second):每秒執行多少萬條指令。
MIPS=指令條數/(執行時間*10^6)=主頻/(CPI*10^6)
MIPS 對不同機器進行性能比較是有缺陷的。因為不同機器的指令集不同,指令的功能也就不同,比如在機器M1上某條指令的功能也許在機器M2上要用多條指令來完成;不同機器的CPI 和時鐘周期也不同,因而同一條指令在不同機器上所用的時間也不同。
FLOPS(Floating-point Operations Per Second):每秒執行多少次浮點運算。

注意:
在描述存儲容量、文件大小等時,K、M、G、T通常用2的冪次表示,如1Kb=2^10b;在描述速率、頻率等時,K、M、G、T通常用10的冪次表示。如 1kb/s=10^3b/s。通常前者用大寫的K,后者用小寫的k,但其他前綴均為大寫,表示的含義取決于所用的場景。
例題:
1.程序P在機器M上的執行時間是 20s,編譯優化后,P執行的指令數減少到原來的 70%,而 CPI增加到原來的1.2倍,則P在M上的執行時間是()
解答:
假設原來的指令條數為x,則執行時間=指令條數*每條指令的時鐘周期數*時鐘周期的長度=
x*CPI*1/f? ? ? ? 得到:20=(x*CPI)/f? ? ? ? 所以原來的CPI=20f/x
經過編譯優化后,指令條數減少為原來的70%,即指令條數為0.7x,而CPI增加到原來的1.2倍,即24f/x,則現在P在M上的執行時間=(0.7x * 24f/x) / f =24*0.7=16.8s
2.假定計算機 M1和M2具有相同的指令集體系結構,M1的主頻為2GHz,程序P在M1上的運行時間為 10s。M2采用新技術可使主頻大幅提升,但平均 CPI也增加到 M1 的 1.5 倍,則 M2的主頻至少提升到多少才能使程序P在M2上的運行時間縮短為6s?
解答:
程序P在M1上的時鐘周期數=指令條數xCPI=CPU執行時間x主頻=10s*2GHz=2*10^10。M2的平均CPI為 M1 的1.5倍,因此程序P在 M2 上的時鐘周期數 =1.5*2*10^10=3x10^10。
要使程序 P在 M2上的運行時間縮短到6s,則M2 的主頻至少應為:程序P所含時鐘周期數/CPU執行時間=3x10^10/6s=5GHz
由此可見,M2的主頻是 M1的 2.5 倍,但 M2 的速度卻只是 M1 的 1.67 倍。
所以,這也可以看出主頻高的CPU不一定比主頻低的CPU快:
主頻和實際的運算速度存在一定的關系,但目前還沒有一確定的公式能夠定量兩者的數值關系,因為 CPU 的運算速度還要看 CPU 的流水線的各方面的性能指標(架構、緩存、指令集、CPU 的位數、Cache 大小等)。由于主頻并不直接代表運算速度,因此在一定情況下很可能會出現主頻較高的 CPU 實際運算速度較低的現象。
4.翻譯程序和匯編程序
翻譯程序有兩種:一種是編譯程序,它將高級語言源程序一次全部翻譯成目標程序,只要源程序不變,就無須重新翻譯。另一種是解釋程序,它將源程序的一條語句翻譯成對應的機器目標代碼,并立即執行,然后翻譯下一條源程序語句并執行,直至所有源程序語句全部被翻譯并執行完。所以解釋程序的執行過程是翻譯一句執行一句,并且不會生成目標程序。
匯編程序也是一種語言翻譯程序,它把匯編語言源程序翻譯為機器語言程序。
編譯程序與匯編程序的區別:若源語言是諸如C、C++、Java 等“高級語言”,而目標語言是諸如匯編語言或機器語言之類的“低級語言”,則這樣的一個翻譯程序稱為編譯程序。若源語言是匯編語言,而目標語言是機器語言,則這樣的一個翻譯程序稱為匯編程序。
5.計算機體系結構和計算機組成的區別和聯系
計算機體系結構是指機器語言或匯編語言程序員所看得到的傳統機器的屬性,包括指令集、數據類型、存儲器尋址技術等,大都屬于抽象的屬性。
計算機組成是指如何實現計算機體系結構所體現的屬性,它包含許多對程序員來說透明的硬件細節。例如,指令系統屬于結構的問題,但指令的實現即如何取指令、分析指令、取操作數、如何運算等都屬于組成的問題。因此,當兩臺機器的指令系統相同時,只能認為它們具有相同的結構,至于這兩臺機器如何實現其指令,則完全可以不同,即可以認為它們的組成方式是不同的。例如,一臺機器是否具備乘法指令是一個結構的問題,但實現乘法指令采用什么方式則是一個組成的問題。許多計算機廠商提供一系列體系結構相同的計算機,而它們的組成卻有相當大的差別。即使是同一系列的不同型號機器,其性能和價格差異也很大。
6.基準程序執行得越快說明機器的性能越好嗎?
一般情況下,基準測試程序能夠反映機器性能的好壞。但是,由于基準程序中的語句存在頻度的差異,因此運行結果并不能完全說明問題。


)


的mysql驅動(附帶編譯好的文件))




)




-全文解析器-MeCab)



)