自動編碼器
自動編碼器(Autoencoders)是無監督學習領域中一種重要的神經網絡架構,它們主要用于數據壓縮和特征學習。
-
自動編碼器的定義:
自動編碼器是一種無監督機器學習算法,它通過反向傳播進行訓練,目標值被設置為與輸入值相等。其核心目標是對輸入數據進行壓縮,轉換成一個更小的表示形式,如果需要原始數據,可以從壓縮后的數據中重建。 -
自動編碼器的組成:
自動編碼器由三個主要部分組成:- 編碼器(Encoder):負責將輸入數據壓縮成低維表示形式,即潛在空間(latent space)表示。
- 潛在空間(Code或Bottleneck):表示壓縮后的數據,該數據隨后被送入解碼器。
- 解碼器(Decoder):負責將編碼后的表示重建成原始數據維度,重建的數據是對原始輸入的一個有損近似。
-
自動編碼器的工作流程:
- 數據首先被輸入到自動編碼器中。
- 編碼器將數據編碼并壓縮成較小的潛在表示。
- 然后,解碼器學習如何從這個壓縮的表示中重建原始數據。
-
訓練目的:
訓練自動編碼器的目的不單是復制輸入數據,而是讓網絡學習輸入數據的本質特征。通過最小化損失函數,網絡學習到如何從壓縮表示中有效地重建數據。 -
應用場景:
- 圖像去噪:自動編碼器可以被訓練來識別并去除圖像中的噪聲。
- 數據降維:自動編碼器用于降低數據的維度,同時盡可能保留重要信息。
- 特征提取:自動編碼器可以提取數據中的關鍵特征,這些特征可以用于其他機器學習任務。
- 圖像上色:將黑白圖像轉換為彩色圖像。
- 水印去除:從圖像或視頻中去除不需要的對象或水印。
-
為何使用自動編碼器:
與主成分分析(PCA)等傳統技術相比,自動編碼器能夠學習非線性轉換,可以利用非線性激活函數和多層結構。此外,自動編碼器可以使用卷積層來學習圖像、視頻和序列數據,這比PCA更有效。 -
自動編碼器的類型:
- 卷積自動編碼器(Convolutional Autoencoders):適用于圖像數據,可以用于圖像重建、上色等。
- 稀疏自動編碼器(Sparse Autoencoders):通過懲罰隱藏層的激活來引入信息瓶頸。
- 深度自動編碼器(Deep Autoencoders):由多層編碼和解碼網絡組成,可以學習更復雜的數據表示。
- 合同自動編碼器(Contractive Autoencoders):通過懲罰隱藏層激活相對于輸入的大幅度變化來幫助網絡編碼未標記的訓練數據。
自動編碼器架構
先來看看 自動編碼器的架構。 :
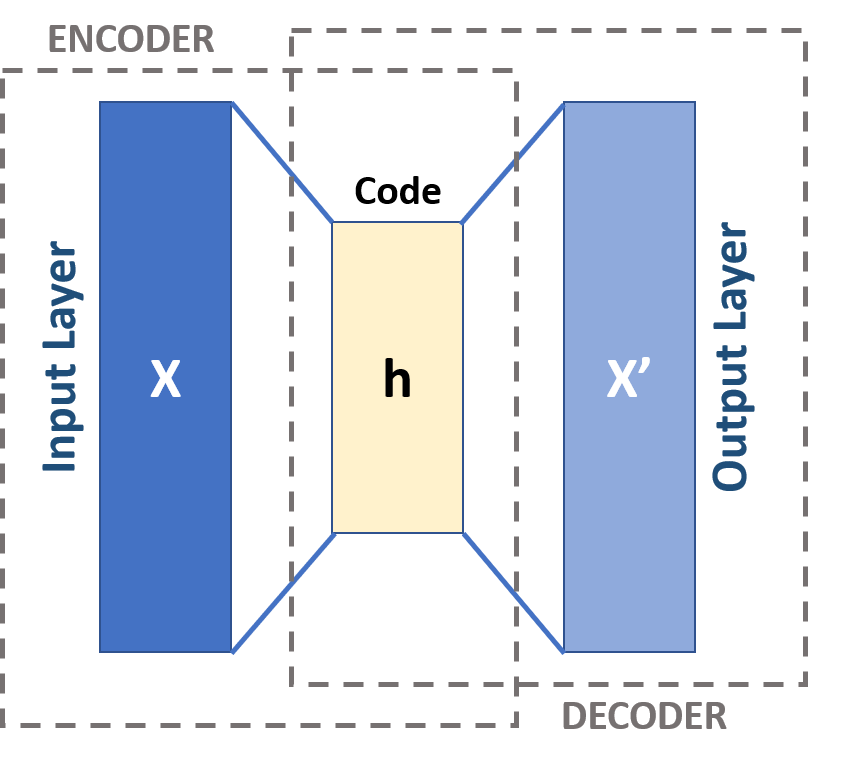
自動編碼器的架構可以概括為三個核心組件:編碼器、瓶頸(或潛在空間),以及解碼器:
-
編碼器(Encoder):
編碼器是自動編碼器的輸入部分,通常由前饋、密集連接的網絡層組成。它的任務是接收原始輸入數據,并通過一系列的變換,將其轉換成一個低維的內部表示。這個過程涉及到數據壓縮,目的是提取輸入數據中的關鍵特征,并將其編碼到一個較小的潛在空間中。 -
瓶頸(Bottleneck):
瓶頸層,也稱為潛在表示或潛在變量,是自動編碼器中編碼過程的結果。這一層捕捉了輸入數據的壓縮表示,它包含了重建原始數據所必需的最重要信息。瓶頸層的設計至關重要,因為它需要決定哪些數據特征是信息豐富且需要保留的,哪些是可以丟棄的。瓶頸層通過逐元素的激活函數處理網絡的權重和偏差,以實現這種壓縮和特征選擇。 -
解碼器(Decoder):
解碼器是自動編碼器的輸出部分,它的任務是將瓶頸層的壓縮表示重新轉換成原始數據的高維表示。解碼器通常由一系列解壓縮的層組成,這些層逐步增加數據的維度,直到達到與原始輸入數據相同的維度。解碼器的目標是從潛在空間表示中重建數據,盡可能地恢復輸入數據的原始特征和結構。
自動編碼器的訓練通常采用反向傳播算法,這是一種監督學習技術,用于最小化輸入數據和重建數據之間的差異,通常通過損失函數來衡量。損失函數的常見選擇包括均方誤差(MSE)或二元交叉熵(Binary Cross-Entropy, BCE),具體取決于數據的性質和范圍。
自動編碼器的屬性
自動編碼器有多種類型,但它們都具有將它們結合在一起的某些屬性。自動編碼器自動學習。 它們不需要標簽,如果給定足夠的數據,很容易讓自動編碼器在特定類型的輸入數據上達到高性能。自動編碼器是特定于數據的。 這意味著它們只能壓縮與自動編碼器已經訓練過的數據高度相似的數據。 自動編碼器也是有損的,這意味著模型的輸出與輸入數據相比將會降低。
在設計自動編碼器時,機器學習工程師需要注意四個不同的模型超參數:代碼大小、層數、每層節點和損失函數。
代碼大小決定了有多少節點開始網絡的中間部分,節點越少,數據壓縮得越多。 在深度自動編碼器中,雖然層數可以是工程師認為合適的任何數量,但層中的節點數應該隨著編碼器的繼續而減少。 同時,解碼器中的情況正好相反,這意味著隨著解碼器層接近最后一層,每層的節點數量應該增加。 最后,自動編碼器的損失函數通常是二進制交叉熵或均方誤差。 二元交叉熵適用于數據輸入值在 0 – 1 范圍內的情況。
自動編碼器類型
如上所述,經典自動編碼器架構存在變體。 讓我們研究一下不同的自動編碼器架構。
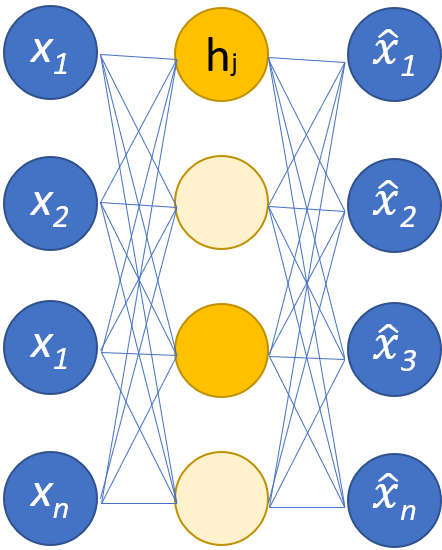
雖然自動編碼器通常存在通過減少節點來壓縮數據的瓶頸, 稀疏自動編碼器s 是典型操作格式的替代方案。 在稀疏網絡中,隱藏層保持與編碼器和解碼器層相同的大小。 相反,給定層內的激活會受到懲罰,對其進行設置,以便損失函數更好地捕獲輸入數據的統計特征。 換句話說,雖然稀疏自動編碼器的隱藏層比傳統自動編碼器具有更多的單元,但在任何給定時間只有一定比例的隱藏層處于活動狀態。 最有影響力的激活函數被保留,其他激活函數被忽略,這種約束有助于網絡確定輸入數據最顯著的特征。
收縮性
收縮自動編碼器 旨在對數據中的微小變化具有彈性,從而保持數據的一致表示。 這是通過對損失函數應用懲罰來實現的。 該正則化技術基于輸入編碼器激活的雅可比矩陣的 Frobenius 范數。 這種正則化技術的效果是,模型被迫構建一種編碼,其中相似的輸入將具有相似的編碼。
卷積
卷積自動編碼器 通過將數據分成多個子部分,然后將這些子部分轉換為簡單信號,將這些信號相加以創建新的數據表示,對輸入數據進行編碼。 與卷積神經網絡類似,卷積自動編碼器專門研究圖像數據的學習,它使用一個在整個圖像上逐節移動的濾波器。 編碼層生成的編碼可用于重建圖像、反映圖像或修改圖像的幾何形狀。 一旦網絡學習了濾波器,它們就可以用于任何足夠相似的輸入來提取圖像的特征。
去噪

去噪自動編碼器 將噪聲引入編碼中,導致編碼成為原始輸入數據的損壞版本。 這個損壞的數據版本用于訓練模型,但損失函數將輸出值與原始輸入而不是損壞的輸入進行比較。 目標是網絡將能夠重現圖像的原始、未損壞版本。 通過將損壞的數據與原始數據進行比較,網絡可以了解數據的哪些特征最重要以及哪些特征不重要/損壞。 換句話說,為了讓模型對損壞的圖像進行去噪,它必須提取圖像數據的重要特征。
變分
變分自動編碼器 通過假設數據的潛在變量如何分布來進行操作。 變分自動編碼器為訓練圖像/潛在屬性的不同特征生成概率分布。 訓練時,編碼器為輸入圖像的不同特征創建潛在分布。
 由于該模型將特征或圖像學習為高斯分布而不是離散值,因此它能夠用于生成新圖像。 對高斯分布進行采樣以創建一個向量,該向量被饋送到解碼網絡,解碼網絡根據該樣本向量渲染圖像。 本質上,該模型學習訓練圖像的共同特征,并為其分配一些發生的概率。 然后,概率分布可用于對圖像進行逆向工程,生成與原始訓練圖像相似的新圖像。
由于該模型將特征或圖像學習為高斯分布而不是離散值,因此它能夠用于生成新圖像。 對高斯分布進行采樣以創建一個向量,該向量被饋送到解碼網絡,解碼網絡根據該樣本向量渲染圖像。 本質上,該模型學習訓練圖像的共同特征,并為其分配一些發生的概率。 然后,概率分布可用于對圖像進行逆向工程,生成與原始訓練圖像相似的新圖像。
訓練網絡時,分析編碼數據,識別模型輸出兩個向量,得出圖像的平均值和標準差。 根據這些值創建分布。 這是針對不同的潛在狀態完成的。 然后,解碼器從相應的分布中獲取隨機樣本,并使用它們來重建網絡的初始輸入。
自動編碼器應用
自動編碼器可用于廣泛 多種應用,但它們通常用于降維、數據去噪、特征提取、圖像生成、序列到序列預測和推薦系統等任務。
數據去噪是使用自動編碼器從圖像中去除顆粒/噪聲。 同樣,自動編碼器可用于修復其他類型的圖像損壞,例如模糊圖像或圖像缺失部分。 降維可以幫助高容量網絡學習圖像的有用特征,這意味著自動編碼器可用于增強其他類型神經網絡的訓練。 使用自動編碼器進行特征提取也是如此,因為自動編碼器可用于識別其他訓練數據集的特征來訓練其他模型。
在圖像生成方面,自動編碼器可用于生成假人類圖像或動畫角色,這可用于設計人臉識別系統或自動化動畫的某些方面。
序列到序列預測模型可用于確定數據的時間結構,這意味著自動編碼器可用于生成序列中的下一個偶數。 因此,可以使用自動編碼器來生成視頻。 最后,深度自動編碼器可用于通過拾取與用戶興趣相關的模式來創建推薦系統,編碼器分析用戶參與數據,解碼器創建適合已建立模式的推薦。

)
)





)







)


