文章目錄
- 一、環境
- 二、題目1
- 三、題目2
- 四、題目3
- 五、函數參數
資料:
https://paddlets.readthedocs.io/zh-cn/latest/source/api/paddlets.models.base.html#paddlets.models.base.BaseModel.recursive_predict
https://aistudio.baidu.com/projectdetail/5866171?contributionType=1&sUid=90149&shared=1&ts=1680491732413
一、環境
paddlets時序預測,paddlets環境只能用docker,不然不太好安裝:
docker run -it -p 18888:18888 -v C:\Users\Administrator\PycharmProjects\paddlets:/pro registry.baidubce.com/paddlets/paddlets:latest bash# 或者docker run -it -p 18889:18888 --gpus all -v /ssd/xiedong/paddlets:/pro registry.baidubce.com/paddlets/paddlets:latest-gpu-cuda11.2-cudnn8 bashapt-get install -y openssh-serverapt install openssh-server --fix-missing # 不斷執行export http_proxy=192.168.3.2:10811
export https_proxy=192.168.3.2:10811apt-get updatevim /etc/ssh/sshd_configPort 18888 # 根據需求設置,容器Linux開啟SSH服務的默認端口是22
PermitRootLogin yes # 允許root用戶登錄(可選,根據需要設置)
PasswordAuthentication yes # 允許密碼身份驗證ssh-keygen -t rsa -b 2048passwd root
nihao123service ssh start二、題目1
(1)請分析所提供的 10 個地區的功率數據,并繪制功率時序曲線,分析 10 個地區
功率變化特點,初步判斷哪個地區的功率可以獲得更好的預測結果,說明你的理由。
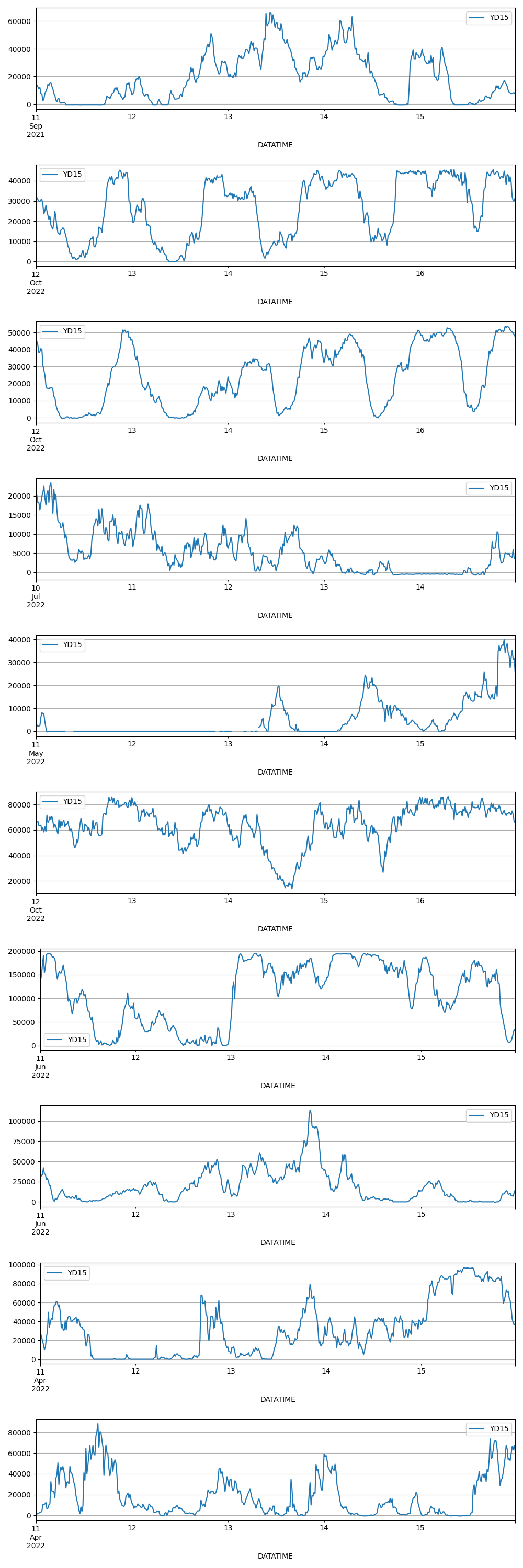
執行程序d1t1.py可以獲得下面的圖,這是5天中,10個地區的功率YD15的曲線。從趨勢變換上來看,只有’02.csv’、'03.csv’的趨勢變化非常具有周期性,應該是可以獲得更好的預測結果的。
三、題目2
(2)分別對風速(預測風速和實際風速)、風向、溫度、濕度、氣壓與功率(兩個功率預測目標)的關系進行分析,如果要用這些氣象因素來提高功率時序預測的結果,你優先推薦哪個(或哪幾個)?簡要說明理由。
選取02.csv的數據來對比02.csv中各個特征的關系。只有圖最為直觀,相關度之類的數值可以在更復雜難分析的情況使用。
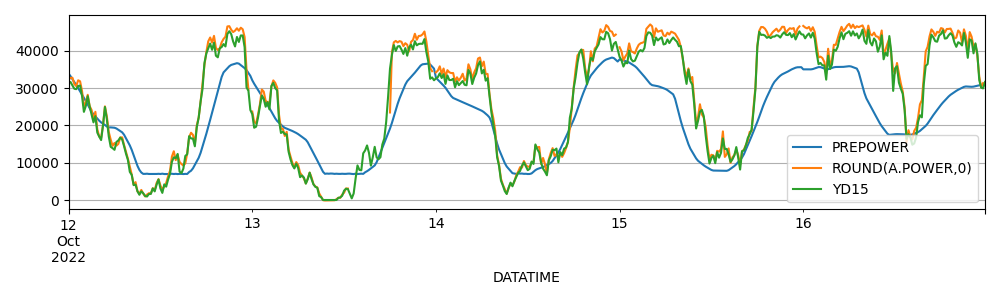
下圖是預測功率(系統生成)、實際功率(計量口徑一)、 實際功率(預測目標,計量口徑二)的圖。變化趨勢有周期性,每天都有頂峰數值。
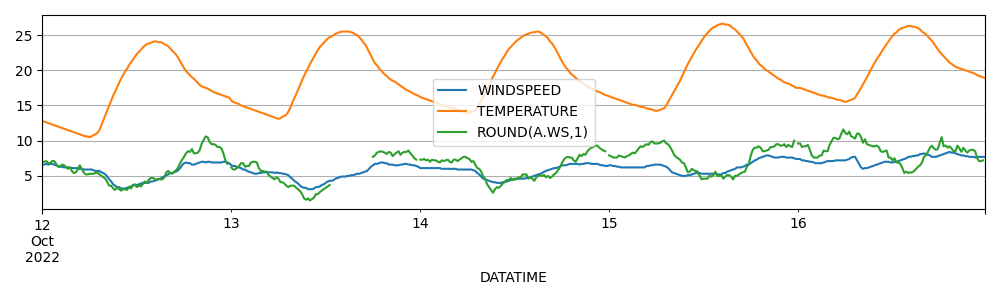
下圖是WINDSPEED 預測風速、TEMPERATURE 溫度、ROUND(A.WS,1) 實際風速的變化圖,周期性非常明顯,從物理意義上來說也和風力發電功率非常相關。
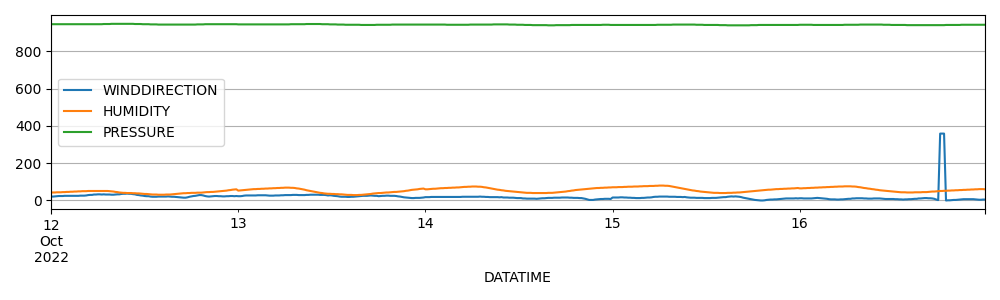
下圖是WINDDIRECTION 風向、HUMIDITY 濕度、PRESSURE 氣壓的變化圖,數值過于平穩單調,和風力發電功率沒有太大關聯性。
如果要用這些氣象因素來提高功率時序預測的結果,優先選擇TEMPERATURE 溫度、ROUND(A.WS,1) 實際風速這2個特征。
四、題目3
(3)請根據已知的氣象數據與歷史功率數據,劃分訓練集和測試集(將數據集中最后 3 天數據作為測試集),設計方法(不限使用神經網絡等)構建預測模型,對 10 個地區的數據集內功率進行預測分析。并與原有的真實結果相比,做出誤差分析,并分析不同氣候因素對預測結果的影響。
五、函數參數
lstm = LSTNetRegressor(in_chunk_len=(24 + 19) * 7 * 4,out_chunk_len=(24 + 19) * 4, # 預測05:00之后到次日23:45的實際功率max_epochs=200,optimizer_params=dict(learning_rate=5e-3),
)
-
in_chunk_len (int): 反饋窗口的大小,即輸入到模型的時間步數。 -
out_chunk_len (int): 預測范圍的大小,即模型輸出的時間步數。 -
skip_chunk_len (int): 可選,單個樣本中輸入塊和輸出塊之間的時間步數。跳過的塊既不作為特征(即 X),也不作為標簽(即 Y)。默認情況下,不會跳過任何時間步。 -
sampling_stride (int): 相鄰樣本之間的采樣間隔。 -
loss_fn (Callable[..., paddle.Tensor]|None): 損失函數。 -
optimizer_fn (Callable[..., Optimizer]): 優化算法。 -
optimizer_params (Dict[str, Any]): 優化器參數。 -
eval_metrics (List[str]): 模型的評估指標。 -
callbacks (List[Callback]): 自定義回調函數。 -
batch_size (int): 每批次的樣本數。 -
max_epochs (int): 訓練期間的最大輪數。 -
verbose (int): 詳細模式。 -
patience (int): 在終止訓練前等待改進的輪數。 -
seed (int|None): 全局隨機種子。 -
skip_size (int): 跳過 RNN 層的跳躍大小。 -
channels (int): 第一層 Conv1D 的通道數。 -
kernel_size (int): 第一層 Conv1D 的卷積核大小。 -
rnn_cell_type (str): RNN 單元類型,可以是 GRU 或 LSTM。 -
rnn_num_cells (int): 每層的 RNN 單元數。 -
skip_rnn_cell_type (str): 跳過層的 RNN 單元類型,可以是 GRU 或 LSTM。 -
skip_rnn_num_cells (int): 跳過部分每層的 RNN 單元數。 -
dropout_rate (float): Dropout 正則化參數。 -
output_activation (str|None): 輸出使用的最后激活函數。可以是 None(默認無激活),sigmoid 或 tanh。

)









)


-選做)




)