目錄
·前言
一、索引
1.索引概述
(1)基本概念
(2)索引作用
(3)索引特點
(4)適用場景
2.索引的操作
(1)查看索引
(2)創建索引
(3)刪除索引
3.索引底層數據結構
(1)概述
(2)B樹的基本概念
(3)B+樹的基本概念
二、事務
1.事務的概念
2.事務的特性
(1)原子性
(2)一致性
(3)持久性
(4)隔離性
3.有關事務典型問題
(1)臟讀問題
(2)不可重復讀問題
(3)幻讀問題
4.隔離級別
(1)read?uncommitted
(2)read?committed
(3)repeatable?read
(4)serializable
5.事務的使用
·尾聲
·前言
? ? ? ? 談到MySQL,避不開索引與事務這兩個十分重要的概念,索引使MySQL在查詢時效率更高,事務則是為了MySQL能更安全無誤的運行,下面就由我來為大家進行今天的知識介紹吧。
一、索引
1.索引概述
(1)基本概念
????????索引是一種特殊的文件,包含著對數據表里所有記錄的引用指針。可以對表中的一列或多列創建索引, 并指定索引的類型,各類索引有各自的數據結構實現。索引的英文名是index(更多被翻譯成下標),可以理解成目錄。
(2)索引作用
? ? ? ? 假設你有一本書,如何快速定位某個章節所在的位置,這就需要使用目錄進行查找了,在數據庫中,進行條件查詢的時候經常需要遍歷表,由于數據庫是把數據存儲在硬盤上,所以在數據庫上進行遍歷表的操作時間復雜度O(N)會比咱們平時說的O(N)要慢很多,因此我們可以給數據庫引入索引,從而提高我們的查詢速度。
- 數據庫中的表、數據、索引直接的關系,就類似于書架上圖書,圖書內容和圖書目錄的關系
- 索引所起的作用就類似于圖書目錄,可以快速定位、檢索數據
- 索引對于提高數據庫性能有很大的幫助
(3)索引特點
- 加快查詢的速度;
- 索引自身是一定的數據結構,也要占據內存空間;
- 當我們需要進行新增、刪除、修改操作的時候,也需要針對索引進行更新(額外開銷)。
? ? ? ? 需要注意的是,進行刪除、修改操作時,搭配條件語句,需要先根據條件查找,再進行修改。如果沒有使用條件進行查找或者使用條件查找但是沒有利用索引的時候,刪除、修改操作的速度肯定會慢,并且在修改、刪除之后,還需要進行維護索引,這個過程是比較慢的。
(4)適用場景
- 存儲空間比較充裕(索引會占用額外的空間);
- 應用場景中,涉及查詢較多,增加、刪除、修改都不多。(減少維護成本)
? ? ? ? 對于讀多寫少的場景,是比較常見的,很多web程序(網站)都是這樣的。
? ? ? ? 滿足以上條件,可以考慮對表中的這些字段創建索引,這樣可以提高查詢的效率,反之,如果使用非條件查詢列,或者經常做插入、修改操作,或者磁盤空間不足時,不考慮創建索引。
2.索引的操作
(1)查看索引
????????語法格式:
show index from 表名;? ? ? ? 在前面文章介紹約束時,曾提過創建主鍵約束(PRIMARY?KEY)、唯一約束(UNIQUE)、外鍵約束(FOREIGN?KEY)時會自動創建對應列的索引,下面通過示例進一步介紹與演示: ????????在一個表中,索引可以有多個,每個索引都是根據某個具體的列來展開的,后續按照這個列進行查詢,這個時候才能提高效率。
????????在一個表中,索引可以有多個,每個索引都是根據某個具體的列來展開的,后續按照這個列進行查詢,這個時候才能提高效率。
(2)創建索引
? ? ? ? 語法格式:?
create index 索引名 on 表名(字段名);? ? ? ? ?創建索引的這個操作是一個比較危險的操作,如果表中沒有數據,或者數據比較少,此時創建索引是沒有危險的,如果表本身就有很多數據,此時創建索引操作就會觸發大量的硬盤IO。創建索引的具體操作與效果如下: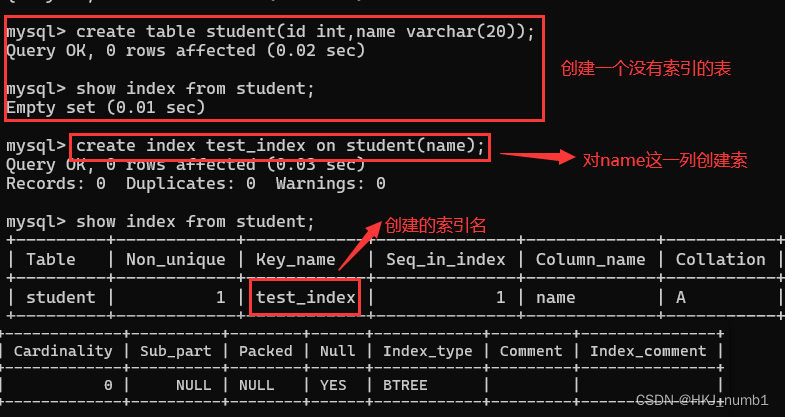
? ? ? ? 為了減少上述創建索引引起的危險情況,就需要我們在建表之初,做好規劃,在創建表時就把需要的索引創建好。?
(3)刪除索引
? ? ? ? 語法格式:
drop index 索引名 on 表名;? ? ? ? 刪除索引也是一個比較危險的操作,邏輯與創建索引邏輯相似,這里演示示例就是將上面剛創建的索引進行刪除,具體操作與效果如下: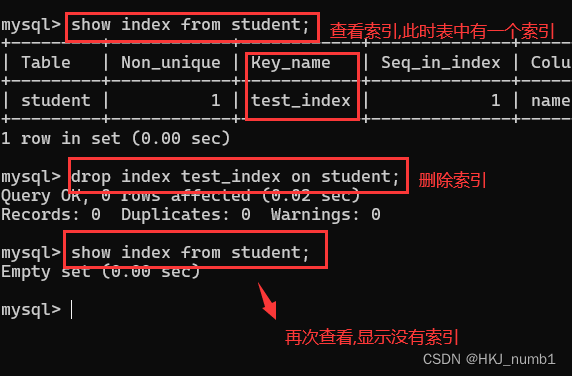 ?
?
3.索引底層數據結構
(1)概述
????????索引其實就是通過額外的數據結構,來針對表里的數據進行重新組織,使用什么樣樣的數據結構對于查詢的時間,表的占用空間都有很大的影響,在學習數據結構時,有一個數據結構在查詢時,時間復雜度是O(1),這個數據結構是哈希表,由于自身復雜的實現邏輯,保證了它是查詢速度最快的,可是,在數據庫查詢的時候,經常是指定條件進行查詢,進行一些范圍查詢,這時候使用哈希表就十分不友好了,因為哈希表查詢是把key通過一定的hash函數轉換成數組下標,再在對應下標中進行查找,這里只能比較相等查詢一個數據,因此,數據庫的索引使用的是B+樹作為數據結構,B+樹這個數據結構相當于是針對數據庫這個場景量身定做的。
(2)B樹的基本概念
????????再介紹B+樹之前,先介紹一下B樹的邏輯,因為B+樹就是在B樹上進行的調整。
? ? ? ? B樹是一個N叉搜索樹,只不過這里要求數據是有序的,B樹就是在二叉搜索樹這里進行了擴展,一個節點上可能包含N個值,這N個值就劃分出了N+1個區間,這樣同樣高度的樹,B樹能表示的元素個數就比二叉搜索樹多很多很多了,同時使用B樹進行查詢的時候,每一輪比較次數比二叉搜索樹要更多,但是,這里關鍵在與同一個節點的這些key都是一次硬盤IO就讀出來了,所以即使總的比較次數增加了,但是硬盤IO的次數減少了,進行一次硬盤IO相當于內存中進行1萬次的比較,由此可以看出B樹相比與二叉搜索樹更有優勢用在數據庫的索引上,B樹的大致結構如下: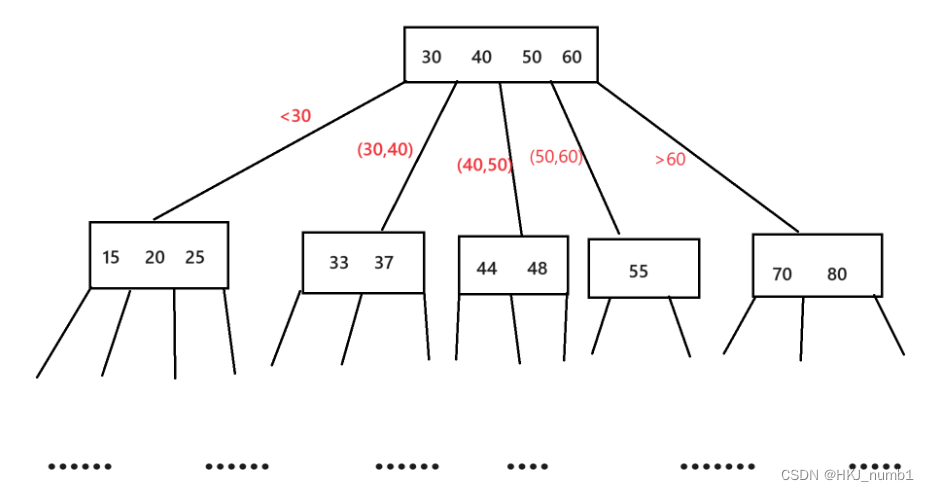
(3)B+樹的基本概念
? ? ? ? B+樹,是在B樹的基礎上進行了改進,B樹同樣也是N叉搜索樹,每個節點包含多個key,N個key劃分出N個區間。
? ? ? ? B+樹的特點:
- N叉搜索樹,每個節點上包含N個key,N個key劃分出N個區間;
- 每個節點的N個key中,會存在一個“最大值”(設定成最小值也一樣);
- 每個節點中的key,都會在子樹中重復出現;
- 把葉子節點之間使用鏈式結構進行相連。
? ? ? ? B+樹大致結構如下: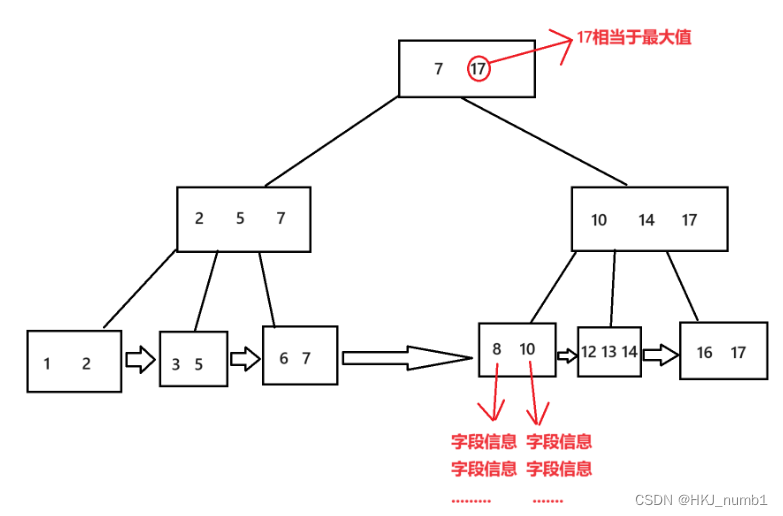
????????B+樹的優點:
- B+樹每個節點中的key,都會在子樹中重復出現,這一特性中,“重復出現”帶來一個好處,就是所有數據都包含在葉子節點這一層中,這樣葉子節點就有著數據全集,并且B+樹的葉子節點之間使用鏈式結構進行相連,“重復出現”與鏈式結構互相配合就使范圍查詢變得十分簡單,高效,舉一個例子:進行范圍查詢id >= 4?and?id <= 10,此時根據4找到對應的位置,在沿著鏈表往后遍歷找到10就可以了,如果沒有這個鏈式結構,就要反復對樹進行回溯,那就會比較慢了;
- 針對B+樹,查詢的時間是很穩定的,因為B+樹進行查詢任何元素都是需要從根節點查詢到葉子節點的,過程中經過的硬盤IO次數都是一樣的(B樹,有時候硬盤IO多,有時少),穩定比單純的快更有用;
- 按照這個特點,存儲數據只需要在葉子節點存儲每個字段具體數據信息即可,其他非葉子節點只存儲key即可,比如,我們創建了一個學生表(id,name,gender,classid.......),此時對id使用索引,因此非葉子節點只存儲了id,由于id占用空間比較小,所以這些非葉子節點的數據可以緩存到內存,這樣在查詢的時候,只進行內存的比較,就大幅度減少了硬盤的IO次數了。
? ? ? ? ?此處對B+樹只是粗略的介紹,在后面文章中,我會再對B+樹進行更詳細的介紹。
二、事務
1.事務的概念
????????事務指邏輯上的一組操作,組成這組操作的各個單元,要么全部成功,要么全部失敗。 在不同的環境中,都可以有事務。對應在數據庫中,就是數據庫事務。
? ? ? ? 對于數據庫事務中有一個非常經典的場景:轉賬,例如有一天張三給李四轉賬500,這時數據庫就需要修改張三的余額減少500,然后再修改李四的余額增加500,但是在其中修改張三余額之后數據庫出現問題崩潰了,沒有執行修改李四余額增加500的操作,等數據庫好了之后就會發現,張三的余額少了,但是李四的余額并沒有多,為了解決這種問題,所以引用了事務,這就是事務應用的一個經典場景。
2.事務的特性
(1)原子性
? ? ? ? 原子性,就是指通過事務把多個操作打包到一起,這也是事務最重要的特性,也是事務的初心。
(2)一致性
? ? ? ? 一致性,就相當于原子性的延伸,當數據庫中間出現了問題,不會產生像上述轉賬場景中“錢憑空消失”這種不科學的情況,并且還可以通過約束,來避免數據出現一些非法的情況。
(3)持久性
? ? ? ? 持久性,就是事務的任何修改都是持久化存在的(寫入硬盤),這樣無論是重啟程序,還是重啟主機,所進行的修改都不會丟失(數據庫本身就是為了持久化存儲)。
(4)隔離性
? ? ? ? 隔離性,就是多個事務并發執行的時候,可能會帶來一些問題,通過隔離性來對這里的問題進行權衡,這時就看你希望數據盡量準確還是希望速度盡量更快了。
3.有關事務典型問題
(1)臟讀問題
? ? ? ? 當前有兩個事務a和b:
事務a:修改了某個數據,但是事務還沒有“提交”(提交是指告訴服務器當前指令執行完畢)
事務b:讀取了同一個數據。
? ? ? ? 此時,事務b讀到的數據很可能是一個臟的數據,因為事務a后續可能還要修改這個數據。
? ? ? ? 解決臟讀問題,核心思路就是降低事務的并發程度,給寫操作加鎖(加鎖,意味著釋放鎖之前,你是不能訪問的),寫的時候不能讀,寫完并且提交事務之后(釋放鎖),才能讓別人讀。
(2)不可重復讀問題
? ? ? ? 不可重復讀問題與臟讀問題有點像,但不可重復讀是在“寫操作加鎖”的前提下導致的問題,這里雖然寫操作加鎖了,但是可以分成多個事務,多次提交的方式來修改數據。
? ? ? ? 當前有事務a、事務b和事務c:
事務a:先修改某個數據(加鎖),此時別的事務想讀數據,得等事務a提交完。
事務b:事務a提交完,事務b開始讀數據(事務b中可能會多次讀取數據)。
事務c:進行修改上述數據。
? ? ? ? ?此時,在事務c修改完數據,事務b還在讀數據,就會導致事務b在一次事務中讀到的數據結果不一樣,就好比在買東西時,開始看還是30元,等再看時變成60元了,這樣就會導致購物體驗很不好。
? ? ? ? 解決不可重復讀問題,就需要給“讀操作加鎖”,相當于在事務b讀取數據時,別的事務不能對這個數據進行修改,這樣就使并發程度降低了,數據的準確性提高了。
(3)幻讀問題
? ? ? ? 有事務a、事務b和事務c三個事務:
事務a:先修改某個數據(加鎖)。
事務b:等事務a提交完,開始讀數據(加鎖),此時不能修改數據。
事務c:新增一個其他數據。
? ? ? ? ?此時,事務c新增了一個其他數據,導致事務b在進行多次讀取數據時,兩次讀到“結果集”不一樣(結果集就類似查詢的時候查詢的行數)。
? ? ? ? 解決幻讀問題,可以使所有操作串行化,不再進行任何并發了,每個事務都是串行執行(執行完第一個,再執行第二個……)此時并發程度最低,同時數據的準確性最高。
4.隔離級別
? ? ? ? 在MySQL配置中,提供了“隔離級別”這樣的選項,我們可以根據需要調整隔離級別,以適應不同的情況。通常事務之間影響越小,隔離程度就越高。
(1)read?uncommitted
? ? ? ? 讀未提交,這是并行程度最高的,隔離程度最低的,效率是最高的,數據是最不靠譜的。此時就可能出現:臟讀、不可重復讀、幻讀這些問題。
(2)read?committed
? ? ? ? 讀已提交,相當于給寫操作加鎖,并行程度降低了,隔離程度提高了,效率會降低一些,數據會更靠譜一些。此時可能會出現:不可重復讀與幻讀這些問題。
(3)repeatable?read
? ? ? ? 可重復讀,相當于給讀操作和寫操作都加鎖。并行程度降低了,隔離程度提高了,效率再降低一些,數據更加靠譜。此時可能出現:幻讀這種問題。repeatable?read是MySQL中默認的隔離級別。
(4)serializable
? ? ? ? 串行化,相當于讓所有事務都串行執行。并發程度最低,隔離程度最高,效率最低,數據最靠譜。
5.事務的使用
? ? ? ? 有關事務的使用,在這我只簡單的介紹一下有關事務使用的幾個關鍵字:
start?transaction;? ?--執行事務之前,開啟事務
commit;? ? ?--告訴服務器,事務完畢
rollback;? ? ?--告訴服務器,要進行回滾,把開始事務之后執行的SQL恢復回去
? ? ? ? ?關于rollback操作,一般不會在控制臺使用,以Java為例,會在Java代碼中使用,Java代碼開始事務,執行SQL,某個SQL拋出異常,在catch語句中捕獲到異常時使用rollback。
·尾聲
? ? ? ? 文章到此就要結束了,上述有關索引與事務的介紹是比較基礎的,事實上,有關索引與事務,兩個概念都有很多的內容,在本篇文章中就是先簡單讓大家知道索引與事務是什么,介紹了一些基礎的概念,一些基礎的使用還有一些需要注意的事項,后續文章還會對這兩個重要概念進一步介紹,如果本篇文章對你有所幫助,希望能點贊收藏支持一下咯~~~~您的支持是我最大的動力,讓我們在下一篇文章見吧~~






)


-選做)




)



小結練習)
