SMMA-NET: AN AUDIO CLUE-BASED TARGET SPEAKER EXTRACTION NETWORK
WITH SPECTROGRAM MATCHING AND MUTUAL ATTENTION
第二章 目標說話人提取之《Smma-net:一種基于音頻線索的目標說話人提取網絡,具有譜圖匹配和相互關注功能》
文章目錄
- SMMA-NET: AN AUDIO CLUE-BASED TARGET SPEAKER EXTRACTION NETWORK
- 前言
- 一、任務
- 二、動機
- 三、挑戰
- 四、方法
- 1.TSE任務
- 2.譜圖匹配
- 3. 多尺度自適應編碼器
- 4.精細階段
- 五、實驗評價
- 1.數據集
- 2.實驗
- 3.客觀評價
- 4.主觀評價
- 六、結論
- 七、知識小結
前言
語音新手入門,學習讀懂論文。
本文作者機構是信號檢測與處理新疆省重點實驗室,烏魯木齊2新疆大學計算機科學與技術學院,烏魯木齊3海思科技有限公司4清華大學電子工程系

一、任務
我們提出了一種具有譜圖匹配和相互關注的目標說話人提取網絡(SMMA-Net)。我們提出了一種譜圖匹配策略來獲得輔助段,該輔助段在長度和特征上與混合段匹配。設計相互注意塊,在混合語和輔助語融合過程中有效利用匹配的輔助語段。
二、動機
通過捕捉目標說話人語音特征的說話人編碼器,池化操作生成嵌入向量,然后通過加法、乘法等運算將其與混合后的特征映射融合。
三、挑戰
一方面,由于嵌入向量不能保持目標說話人的動態變化特征,可能會扭曲目標說話人的音色和輔助語音的內在相干性。另一方面,剛才提到的融合操作,雖然是一種有效而不矯飾的方式,但人類大腦的選擇性聽覺注意機制并不一致。
四、方法
1.TSE任務

2.譜圖匹配
提出了一種頻譜圖匹配策略,直接在幀級計算輔助語音頻譜圖與混合語音的余弦相似度。當混合語音的譜圖長度大于輔助語音的譜圖長度,即T > T '時,輔助語音將被復制和截斷,以保持與混合語音相同的長度。否則,后者將被分割成多個長度為T,跳數為p的段。在輔助語音的開頭和結尾填充零后生成。通過計算每段Ai與混合語音Y之間的余弦相似度d:
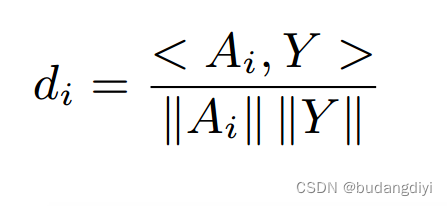
其中<·,·>為內積,得到M個相似矩陣。選取相似矩陣中位數最大的段作為匹配的輔助段Am(t, f)。
3. 多尺度自適應編碼器
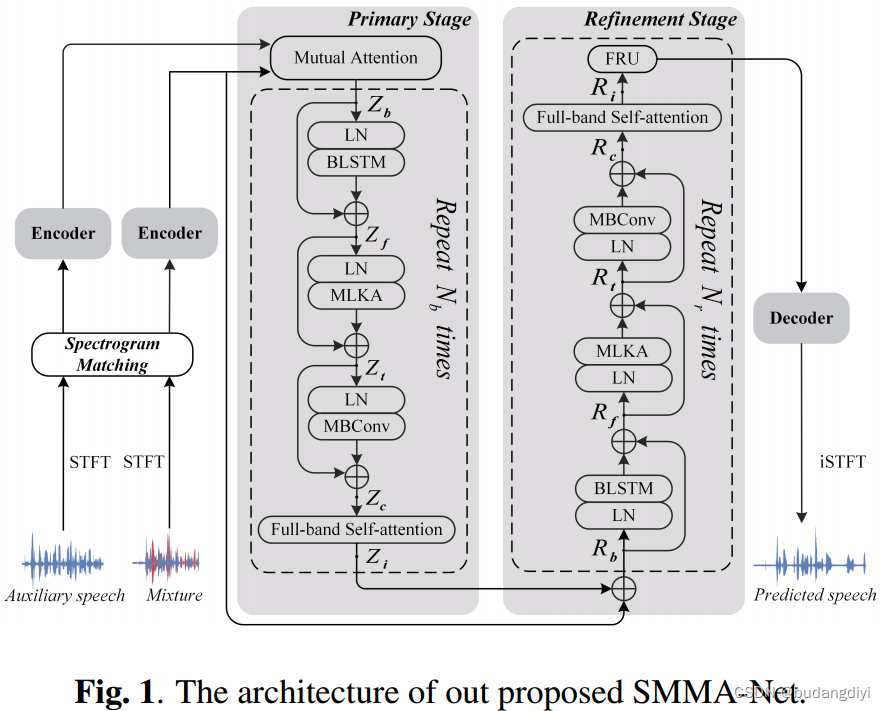
我們設計了一種基于非對稱卷積的多尺度自適應編碼器,其輸入為混合或匹配輔助段的頻譜圖。輸入經過一個核大小為3×3的Conv2D,得到特征映射J。它將被送入三組核大小分別為3、5和7的非對稱卷積中,以獲得其在不同尺度上的上下文關系。在每個集合中,垂直和水平卷積操作之后是一個投影層(Proj),該投影層由Conv2D、參數整流線性單元(PReLU)和層歸一化(LN)組成。對Proj2和Proj3的輸出進行求和,并將結果通過線性層和sigmoid線性單元(SiLU)激活操作生成先聚合的特征圖,再將其與Proj1的輸出進行求和,以同樣的方式生成二次聚合的特征圖。J與二次聚合的feature map之間以卷積的方式存在殘差連接。混合語音和匹配的輔助語音的頻譜圖分別被送入具有相同結構的單獨編碼器中,生成混合語音和輔助語音的中間特征映射Em和Ea。
將Em和Ea兩個編碼器的輸出送入互注意塊,得到融合特征,作為后續迭代過程的輸入。圖1所示,初級階段的橫線框內的操作分量將被重復Nb次,由雙向長短期記憶(BLSTM)、多重大核注意(MLKA)、移動反向瓶頸卷積(MBConv)和全波段自注意組成,分別得到Zf、Zt、Zc和Zi。(BLSTM和全頻段自關注遵循TF-GridNet的設計原則)
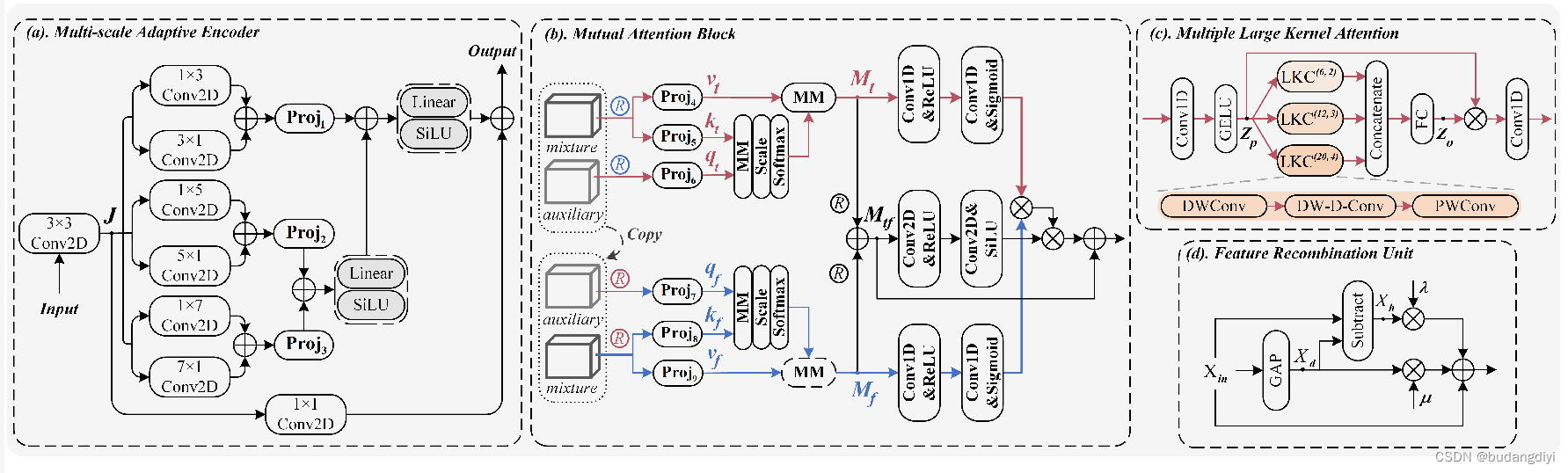
(a)多尺度自適應編碼器原理圖,(b)互注意塊,?多個大核注意,(d)特征重組單元。R為藍色或紅色,表示通過消除頻率或時間維度將三維張量(3D)重塑為二維張量,帶黑色的R表示將張量重塑回三維張量。MM表示矩陣乘法,?表示元素積。LKC(K,d)表示核大小為K,展開為d的大核卷積運算。
相互注意:
助語和混合語中的一個將作為查詢,而另一個將同時作為鍵和值。輸入分別沿著頻率和時間維度重構為T和F個獨立序列。然后將單獨的序列分別投影到查詢、鍵和值上,分別記為q、k和v。投影層由一維(1D)卷積(Conv1D)、PReLU和LN組成。然后,利用縮放后的點積關注得到加權特征Mt和Mf。
多重大核注意:
核大小為(K, K)的大核卷積(Large Kernel convolution, LKC)運算可以分解為展開d的[K/d × K/d]深度展開卷積(DW-D-Conv)、(2d?1)× (2d?1)深度卷積(DWConv)和點向卷積(PWConv)[27]。如圖2 ?所示,Zp將被輸入到三個LKC操作中,其中(K, d)為(6,2)、(12,3)和(20,4),以捕獲不同時間分辨率下Zp的長期依賴關系。經過一個串聯和全連接(FC)層,可以得到一個有效的融合特征Zo,并將其應用到Zp上。
移動倒瓶頸卷積(MBConv):不同通道之間特征圖具有高度相似性的現象。為了減少由高相似性引起的信道間冗余,作者利用MBConv來聚合和重加權信道信息。
4.精細階段
隨著模型的深入,自我注意的重復應用會稀釋高頻分量,因此精化階段的每個迭代過程都包含一個額外的特征重組單元,該單元用于放大高頻分量。
Feature Recombination Unit (FRU):
首先將輸入特征X送入global average pooling (GAP)層,生成直流分量Xd。將Xin減去Xd,得到高頻分量Xh,引入兩個可學習參數λ和μ,分別對高頻分量和直流分量進行重加權。
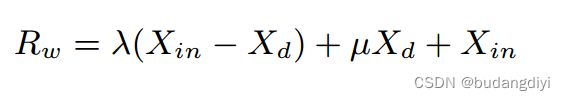
五、實驗評價
1.數據集
WSJ02mix dataset1模擬了一個雙說話人混合數據庫。訓練子集(20,000個話語覆蓋101個說話人,持續時間為30小時),驗證子集(5,000個話語覆蓋101個說話人,持續時間為10小時)和測試子集(3,000個話語覆蓋18個說話人,持續時間為5小時),其中所有樣本的采樣率為8kHz。輔助發言的平均時長為7.3秒。
2.實驗
利用平方根Hann窗口,窗口大小為32 ms,跳長為8 ms。將譜圖匹配過程中的跳數P設為126,D設為24。初級和細化階段的重復次數設置為Nb = 4, Nr = 4。兩個階段的blstm中隱藏單元的數量都設置為192。
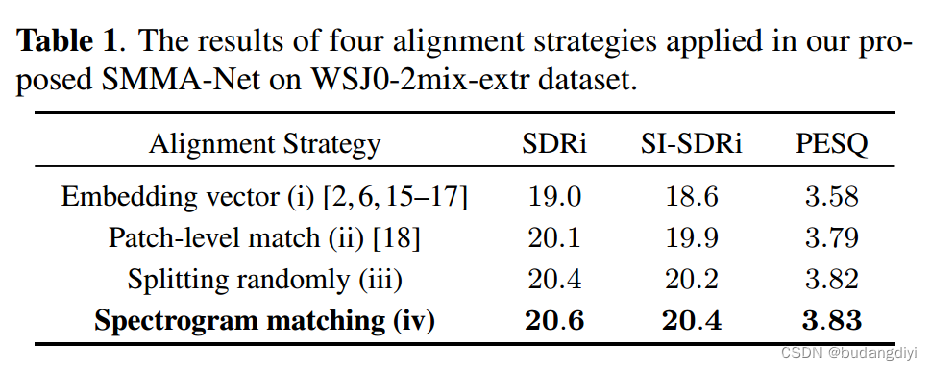
為了有效地利用輔助語音,提出了譜圖匹配策略。為了驗證其有效性,我們采用了基于我們提出的整體架構的其他三種策略來對齊輔助語音和混合語音:
(i)嵌入向量:重復從揚聲器編碼器生成的揚聲器嵌入向量。
(ii)補丁級匹配:在補丁級選擇幾個相似度較高的輔助片段進行拼接[18]。
(iii)隨機分割:從輔助語中隨機分割一段,使其在長度上與混合語匹配。
表1的結果表明,我們提出的SM策略在尺度不變信失真比改進(SI-SDRi)指標上顯著優于傳統的嵌入向量方法,提高了1.8dB。我們將這種顯著的增益歸因于輔助語音在時間維度上的動態變化特征。與補丁級匹配相比,SM在Si-SDRi指標上的性能提高了0.5dB,這進一步證明了輔助語音動態變化特征對基于音頻線索的TSE任務的重要性。(iii)和(iv)都使用了助語的連續段,而(iii)缺乏“余弦相似度計算”的匹配過程。結果表明,匹配過程對SI-SDRi的貢獻為0.2dB。
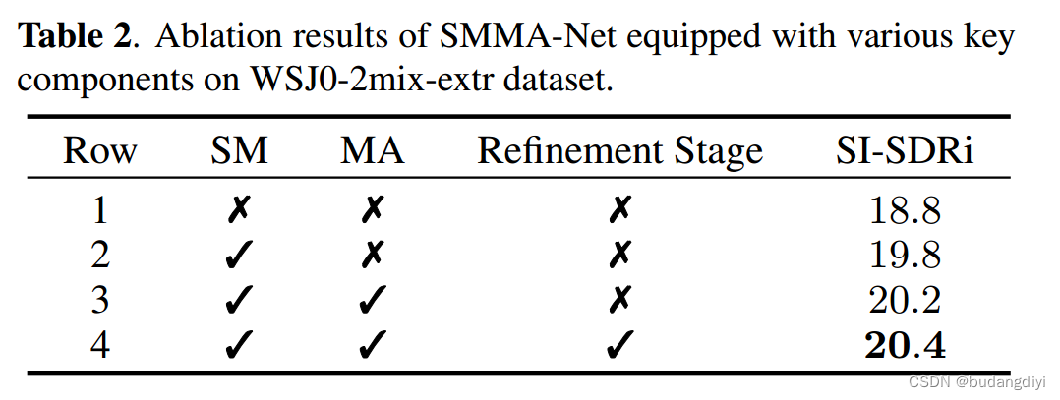
表2列出了我們模型在不同設備下的SI-SDRi結果。當不使用SM時,SMMA-Net使用傳統的嵌入向量,當不使用互注意(MA)時,使用簡單的加法運算。在沒有精化階段的情況下,兩個階段將合并為一個階段,在沒有FRU的情況下重復8次。
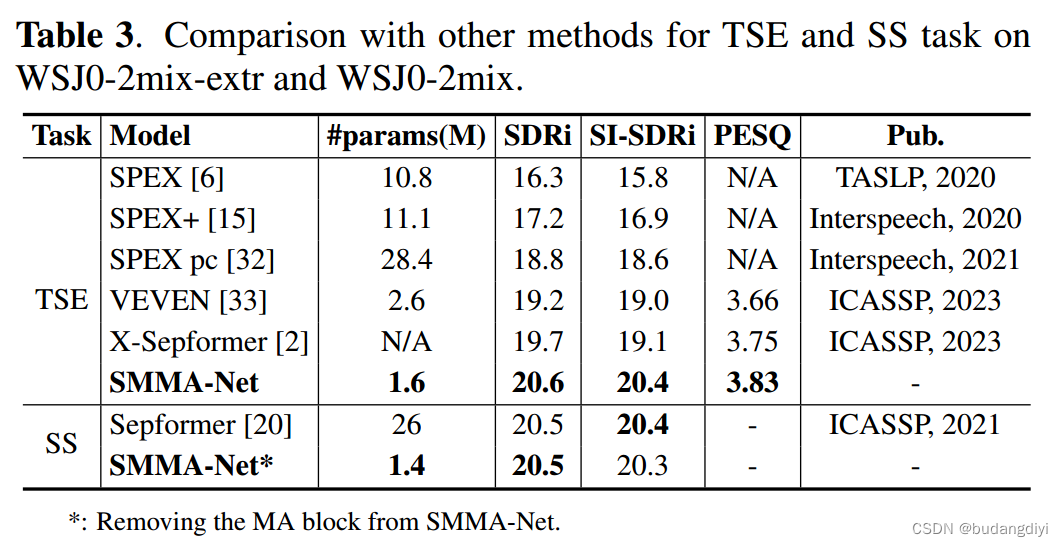
我們首先在WSJ0-2mix-extr數據集上評估了SMMA-Net在TSE任務中的性能。SMMA-Net以最少的參數數量實現了最佳性能,在SI-SDRi指標上優于最先進的方法。我們還在WSJ0-2mix數據集上評估了SMMA-Net用于說話人分離(SS)任務的性能。SMMA-Net*采用與SMMA-Net類似的架構,主要區別是MA塊被刪除。此外,SM策略也沒有被利用。
3.客觀評價
4.主觀評價
六、結論
本文提出了基于音頻線索的TSE任務的SMMA-Net。
實驗結果表明了所提出的SM策略和MA塊的有效性。SMMA-Net在TSE任務中優于最先進的方法,并在Si-SDRi度量上實現了1.3 dB的改進。據我們所知,我們提出的用于TSE任務的SMMA-Net首先超越了具有相同架構的用于SS任務的模型。

題解與代碼)




)

)









)
