背景
????????最近負責了一個審批流程新項目,帶領了幾個小伙伴,哼哧哼哧的干了3個月左右,終于在三月底完美上線了,好消息是線上客戶用的很絲滑,除了幾個非常規的業務提單之外,幾乎沒有什么大的問題,但是美中不足的是,發現每個pod的GC頻率非常高,基本上30分鐘就會有一次FGC,導致每次流量高峰的時候,會有一部分客戶反饋,系統有些卡頓,觀察監控平臺發現,每天流量高峰的時候FGC竟然達到了驚人的5分鐘每次,每次GC的時間差不多有400-700ms,此時,部分接口的耗時達到了5s,因此接口優化和參數調優迫在眉睫;
????????因為本項目是基礎服務,每個業務方都會調用,所以當時申請節點內存大小的時候就富裕了一點,共部署了4個pod,每個pod資源是8核16G,但是觀察監控平臺發現,每個pod內存只使用不到2G,其中eden 200M old 500m survivor更是只有可憐的96m左右,導致年輕代很容易就占滿了,存活的對象就被轉移到老年代了,由于老年代分配的內存也特別少,QPS一高就會頻繁的觸發FullGC,導致系統卡頓甚至接口超時。
????????排查代碼發現有一個占比60%量一個接口雖然查詢的表比較單一,但是查詢了所有字段,其中一個字段存儲的是一個JSON,但業務中卻又沒有使用到。
JVM常見參數
一、配置垃圾收集器
1、Serial垃圾收集器(新生代)
?????????開啟:-XX:+UseSerialGC
?????????關閉:-XX:-UseSerialGC
?????????//新生代使用Serial ?老年代則使用SerialOld
??
?2、ParNew垃圾收集器(新生代)
?????????開啟 -XX:+UseParNewGC
?????????關閉 -XX:-UseParNewGC
?????????//新生代使用功能ParNew 老年代則使用功能CMS
??
?3、Parallel Scavenge收集器(新生代)
?????????開啟 -XX:+UseParallelOldGC
?????????關閉 -XX:-UseParallelOldGC
?????????//新生代使用功能Parallel Scavenge 老年代將會使用Parallel Old收集器
??
?4、ParallelOld垃圾收集器(老年代)
????????開啟 -XX:+UseParallelGC
????????關閉 -XX:-UseParallelGC
????????//新生代使用功能Parallel Scavenge 老年代將會使用Parallel Old收集器
??
?5、CMS垃圾收集器(老年代)
????????開啟 -XX:+UseConcMarkSweepGC
????????關閉 -XX:-UseConcMarkSweepGC
??
?6、G1垃圾收集器
?????????開啟 -XX:+UseG1GC
?????????關閉 -XX:-UseG1GC
二、堆內存相關配置
設置堆初始值
?????????指令1:-Xms2g
??
?設置堆區最大值
?????????指令1:-Xmx2g
??
?新生代內存配置
?????????指令1:-Xmn512m
??
?2個survivor區和Eden區大小比率
?????????指令:-XX:SurvivorRatio=6 ?//S區和Eden區占新生代比率為1:6,兩個S區2:6(默認是8,即8:1:1)
??
?新生代和老年代的占比
?-XX:NewRatio=4 ?//表示新生代:老年代 = 1:4 即老年代占整個堆的4/5;默認值=2
三、GC并行執行線程數
????????-XX:ParallelGCThreads=16
四、進入老年代的GC年齡
?????????-XX:InitialTenuringThreshol=7 //年輕代對象轉換為老年代對象最小年齡值,默認值7,對象在堅持過一次Minor GC之后,年齡就加1,每個對象在堅持過一次Minor GC之后,年齡就增加1
??
?????????-XX:MaxTenuringThreshold=15 //年輕代對象轉換為老年代對象最大年齡值,默認值15
五、GC日志信息配置
????????-Xloggc:/data/gclog/gc.log//固定路徑名稱生成
?????????-Xloggc:/home/GCEASY/gc-%t.log //根據時間生成
????????打印GC的詳細日志?
????????開啟 -XX:+PrintGCDetails
????????關閉 -XX:-PrintGCDetails
六、在Full GC時生成dump文件
????????-XX:+HeapDumpBeforeFullGC ? ? ? //實現在Full GC前dump
????????-XX:+HeapDumpAfterFullGC ? ? ? ?//實現在Full GC后dump。
????????-XX:HeapDumpPath=e:\dump ? ? ? ?//設置Dump保存的路徑
調優過程
? ? 一、業務調優
? ? ? ?業務調優就不展開講述了,主要是用到了arthas這個調優工具,trace了耗時比較久的接口,排除不優雅的編碼之后,就來到了數據層面,由于項目使用的是postgres sql,并且已經分庫+分區了,核心表的數據量級也是百萬級別,所以最終關注的是索引,使用explain查看核心sql的執行計劃,看其是否命中索引;
????????補充一點,由于項目有一張歷史表的數據量比較大,8000萬左右,并且業務中也需要使用到,每個單據號對應的審批流程一般是流程節點的10倍左右,比如某個審批流程10個節點,那么改流程結束后就會產生100+條數據,在列表中使用到了改表中的某些數據,起初直接根據單據號進行查詢,那么分頁條數為1000的時候每次就會查詢1000*100條記錄,而業務真正需要關注的只是10個節點的審批結果而已,白白浪費90%的查詢記錄,因此,在業務中冗余了一個節點字段,標識是否是節點的審批結果,每次查詢除了使用單據號之外,加上該字段,就大大的過濾了記錄數量,這樣做法有如下好處:
? ? ? ? ①減少網絡傳輸量
? ? ? ? ②降低內存使用(起初是內存過濾,高cpu操作)
? ? ? ? ③防止OOM
二、JVM參數調優
? ? ? ? 第一版
? ? ? ? ? ? ? ? 第一版比較偷懶,直接上了G1,因此G1不用配置過多的參數,很多就自適應調節,但是一上線發現cpu就很容易飆升到80以上,并且接口耗時也慢了一倍,起初每個接口的耗時到該200ms,G1之后就變成400ms,終于在運行3天之后,就有監控告警有大量的接口請求超時,觀察到jvm堆內存使用長時間100%,導致健康檢查機制強行將節點重啟了(5s檢查一次,15未檢查到就重啟)為了不影響業務先增加了兩個節點,降低QPS,從而降低堆內存使用。
? ? ? ? ? ? ? ? 具體的參數配置
-XX:+UseContainerSupport -XX:MaxRAMPercentage=75.0 -XX:+PrintGC -Xloggc:/data/logs/gc.log -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/data/logs/ -XX:+UseG1GC -Xmx9G -Xms9G -XX:MaxDirectMemorySize=1g -XX:ConcGCThreads=8 -XX:MaxGCPauseMillis=500 ? ? ? ? 第二版
????????由于公司所有的項目都是K8s集群部署,所以JVM參數基本都用的是默認參數,這一次只是設置了Xms=11g,Xmx=10g,Xmn=4g,但是發現年輕代的from和to的比例不對,按照正常的默認8:1:1,應該是410m左右,但是監控上面顯示的始終是121m,這樣的話QPS達到高峰的時候,老年代上升的速率就比較快,3.76G,基本上12h就用完觸發了FGC,這顯然是不合理的,因為業務邏輯中沒有需要常駐內存的對象,基本上朝生夕滅的,在年輕代就應該被回收,而導致出現這個原因是from和to的內存太小了,存貨了15次之后的對象就被轉移到老年代了。
? ? ? ? 開始的時候使用-XX:-UseAdaptiveSizePolicy?–XX:SurvivorRatio=8,確實改變年輕代的具體分配內存,但是使用 jmsp -heap 1命令發現,jvm的垃圾回收器是ParallelGC,并不是我們想要的CMS,因此不論年輕代from和to的設置了多大空間,其使用始終不會超過121m,老年代還是晉升的速率比較快,并沒有徹底解決問題。具體參數配置如下
-XX:+UseContainerSupport -XX:MaxRAMPercentage=75.0 -Xmx11g -Xms11g -Xmn5g -XX:PermSize=1g -XX:MaxPermSize=1g -XX:SurvivorRatio=8 -XX:-UseAdaptiveSizePolicy -XX:+PrintGC -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintGCTimeStamps? ? ? ? 第三版 最終版本
? ? ? 開啟CMS收集參數? -XX:+UseConcMarkSweepGC,監控和運行變得正常,堆空間各個區域的分配也是正常的。
-XX:+UseContainerSupport -XX:MaxRAMPercentage=75.0 -XX:+UseConcMarkSweepGC -Xmx11g -Xms11g -Xmn5g -XX:PermSize=1g -XX:MaxPermSize=1g -XX:+PrintGC -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintGCTimeStamps -Xloggc:/data/logs/gc.log -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/data/logs????????小結
? ? ? ? 容器部署節點只分配1G,具體原因可以參考這篇文章頻繁 GC 問題排查以及UseContainerSupport與MaxRAMPercentage的正確使用-CSDN博客
????????按照理論上第二次調優就已經能夠滿足業務需求了,但是依據《深入理解Java虛擬機》講的,jdk8默認的垃圾收集器是CMS,那么年輕代的eden、from和to分配內存空間的比例應該是8:1:1,顯然目前我的數據不正確,進入到pod節點發現jvm使用的是ParallelGC,如下圖所示
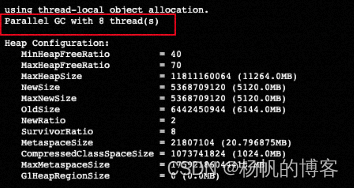
jvm調優常見問題
? ? ? ? 常用命令
? ? ? ? jmap -heap pid 查看內存使用情況
推薦配置
????????8C16G下的參數配置
綜上所述,8C16G下,推薦使用如下的參數設置:
-Xmx12g -Xms12g
-XX:ParallelGCThreads=8
-XX:ConcGCThreads=2
-XX:+UseConcMarkSweepGC
-XX:+UseCMSInitiatingOccupancyOnly
-XX:CMSInitiatingOccupancyFraction=70
-XX:MaxGCPauseMillis=100 ?// 按業務情況來定
-XX:+PrintGCTimeStamps
-XX:+PrintGCDetails
-XX:+PrintGCDateStamps




)





——Imagic)







 二叉搜索樹(BST)底層和模擬實現)
)