10分鐘了解什么是多模態大模型(MM-LLMs)
1. 什么是多模態 Multimodality
多模態(Multimodality)是指集成和處理兩種或兩種以上不同類型的信息或數據的方法和技術。在機器學習和人工智能領域,多模態涉及的數據類型通常包括但不限于文本、圖像、視頻、音頻和傳感器數據。多模態系統的目的是利用來自多種模態的信息來提高任務的性能,提供更豐富的用戶體驗,或者獲得更全面的數據分析結果。
本文較長,建議點贊收藏,以免遺失。更多AI大模型開發 學習視頻/籽料/面試題 都在這>>Github<< >>Gitee<<
2. Multimodal Large Language Models 為什么還是Language Models?
多模態大型語言模型(Multimodal Large Language Models,簡稱MLLMs)是一類結合了大型語言模型(Large Language Models,簡稱LLMs)的自然語言處理能力與對其他模態(如視覺、音頻等)數據的理解與生成能力的模型。這些模型通過整合文本、圖像、聲音等多種類型的輸入和輸出,提供更加豐富和自然的交互體驗。
MLLMs的核心優勢在于它們能夠處理和理解來自不同模態的信息,并將這些信息融合以完成復雜的任務。例如,MLLMs可以分析一張圖片并生成描述性的文本,或者根據文本描述生成相應的圖像。這種跨模態的理解和生成能力,使得MLLMs在多個領域,如自動駕駛、智能助理、內容推薦系統、教育和培訓等,都有廣泛的應用前景
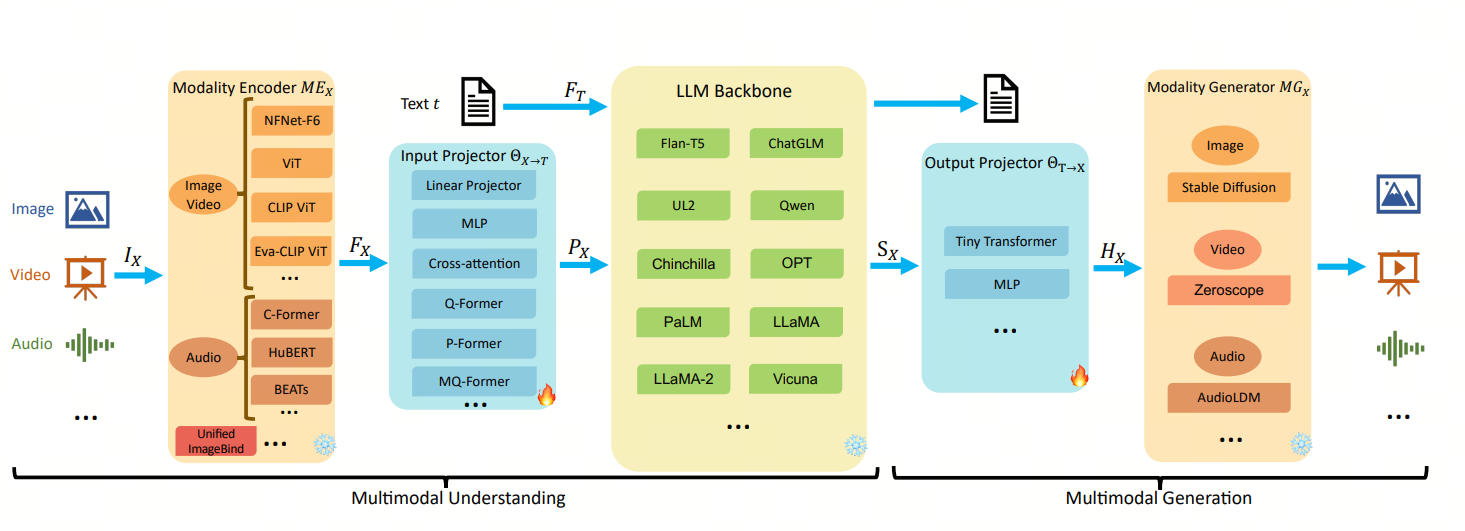
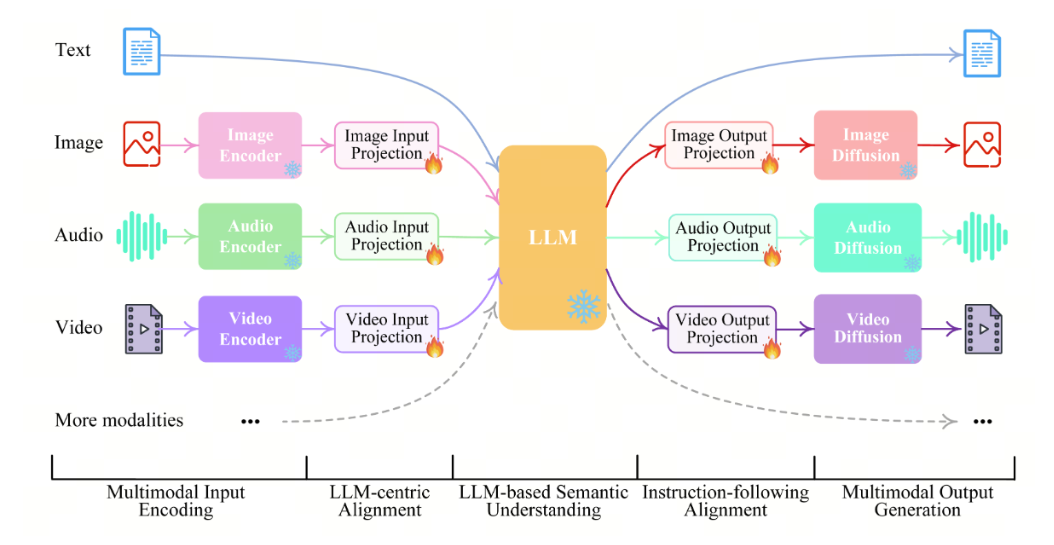
上圖中,我們可以看到MLLMs的核心組成部分,包括:
- Modality Encoder:負責將不同模態的輸入數據編碼為模型可理解的表示;
- Input Projector:將不同模態的輸入數據映射到共享的語義空間;
- LLMs:大型語言模型,用于處理文本數據;
- Output Projector:將模型生成的輸出映射回原始模態的空間;
- Modality Generator:根據輸入數據生成對應的輸出數據
可以看到LLMs還是處于核心位置,多模態是在LLMs的基礎上進行擴展的。擴展的方式是找到一個方法將不同模態的數據映射到LLMs可以接收的語義空間。接下來我們分別看看這幾個組成部分的具體內容。
3. Modality Encoder 模態編碼器
模態編碼器(Modality Encoder)是多模態大模型中的一個關鍵組件,它的主要任務是將不同模態的輸入數據轉換成模型能夠進一步處理的特征表示。這些輸入數據可以包括圖像、文本、音頻、視頻等多種形式,而模態編碼器的作用就像是翻譯官,將這些不同語言(模態)的信息轉換成一種共同的“語言”,以便模型能夠理解和處理。
在多模態大模型中,常見的模態編碼器包括:
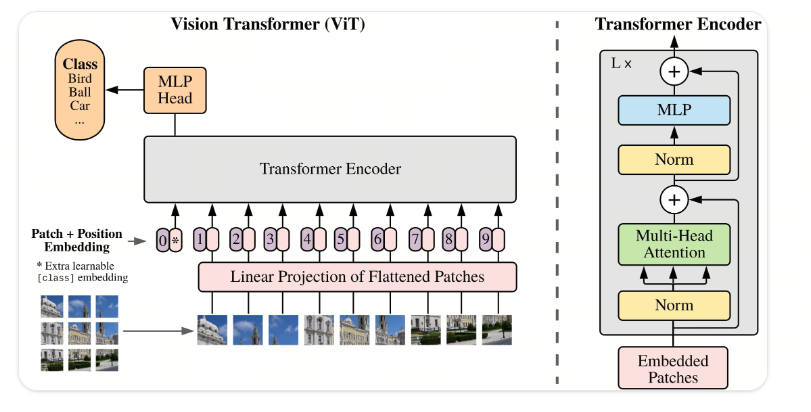
- 圖像編碼器:負責處理視覺信息,將圖像數據轉換成特征向量。常用的圖像編碼器包括NFNet、ViT(Vision Transformer)、CLIP ViT等。
-
音頻編碼器:處理聲音數據,將音頻信號轉換成頻域表示,如使用傅里葉變換或梅爾頻率倒譜系數(MFCCs)。音頻編碼器可以幫助模型識別語音、音樂或其他聲音特征。在多模態模型中,主流的音頻編碼器包括Whisper、CLAP等。
-
視頻編碼器:更為復雜,需要同時處理圖像和時間序列數據。視頻編碼器不僅需要提取每一幀的視覺特征,還需要理解幀與幀之間的時間變化,例如運動信息。視頻編碼器可能會使用類似于圖像編碼器的技術來處理每一幀,同時還會使用額外的技術來處理幀與幀之間的關系,如ViViT、VideoPrism等。
模態編碼器的設計對于多模態大模型的性能至關重要,因為它們直接影響到模型能否準確地理解和生成跨模態的內容。通過高效的模態編碼器,多模態大模型能夠在各種復雜的任務中展現出更加強大和靈活的能力。
4. Input Projector 輸入投影器
輸入投影器(Input Projector, IP)是多模態大模型中的一種關鍵組件,它的主要作用是將不同模態的編碼特征投影到一個共同的特征空間,以便這些特征可以被模型的其他部分,如大型語言模型(LLM Backbone)統一處理和理解。
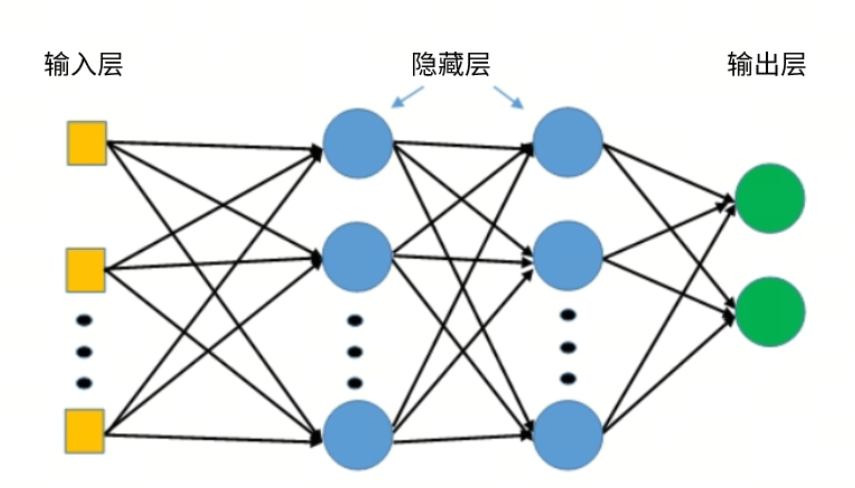
在多模態大模型中,不同類型的輸入數據,如圖像、文本、音頻等,首先會被相應的模態編碼器(Modality Encoder, ME)處理,轉換成特征表示。然而,這些特征可能存在于不同維度的空間中,直接將它們混合使用會遇到兼容性問題。輸入投影器的作用就是解決這個問題,它通過特定的變換方法(如線性變換、多層感知器(MLP)、交叉注意力等),將不同模態的特征映射到一個統一的特征空間中。
輸入投影器的設計對于多模態大模型的性能至關重要,因為它直接影響到模型如何處理和理解不同類型數據的語義信息。通過有效的輸入投影,模型能夠更好地進行跨模態的信息融合和任務執行,例如在圖像描述生成、視覺問答等應用中。
5. Output Projector 輸出投影器
輸出投影器(Output Projector, OP)是多模態大模型中的一種關鍵組件,它的主要任務是將大型語言模型(LLM)的輸出信號轉換成適合不同模態生成器使用的特征表示。這些生成器可能是用于生成圖像、視頻、音頻或其他模態的模型。
在多模態大模型中,LLM 負責處理和理解各種模態的輸入特征,并生成對應的輸出。然而,LLM 的輸出通常是文本形式的,而其他模態的生成器需要特定格式的輸入信號。這時,輸出投影器就起到了橋梁的作用,它將 LLM 的文本輸出轉換為其他模態生成器能夠理解和處理的特征表示。
輸出投影器的實現可以采用多種技術,包括但不限于 Tiny Transformer、多層感知器(MLP)等。這些技術通過學習將 LLM 的輸出映射到目標模態的特征空間,從而實現跨模態的特征轉換。通過輸出投影器的設計,多模態大模型能夠更好地實現不同模態之間的信息交互和生成任務。
例如,在 NExT-GPT 模型中,輸出投影器包括圖像輸出投影、音頻輸出投影和視頻輸出投影,它們共同構成了所謂的“指令跟隨對齊”(Instruction-following Alignment)機制。這一機制確保了模型能夠根據 LLM 的輸出在多種模態之間進行無縫轉換和高效生成,從而實現多模態內容的生成.
6. Modality Generator 模態生成器
模態生成器(Modality Generator, MG)是多模態學習系統中的一個關鍵組件,它的主要作用是生成不同模態的輸出,例如圖像、視頻或音頻。
模態生成器的具體實現可能包括但不限于以下幾種技術或模型:
- 圖像生成:如 Stable Diffusion,這是一種基于擴散模型的圖像生成技術;
- 視頻生成:如 Zeroscope,專注于視頻內容的生成;
- 音頻生成:如 AudioLDM,用于生成音頻信號。
在多模態大模型中,模態生成器是實現模態轉換和內容生成的關鍵技術,它使得模型能夠靈活地處理和生成多種類型的數據,為用戶提供更加豐富和自然的交互體驗。














:Kubernetes架構-原理-組件)

類型和Option類型)


