
原文地址
摘要
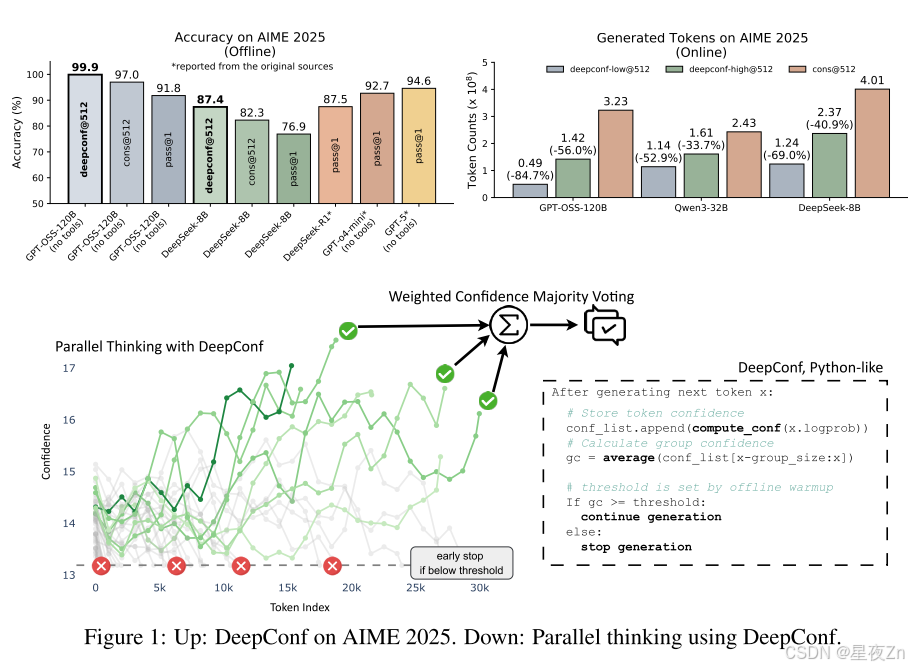
大型語言模型(LLM)通過自我一致性和多數投票等測試時間縮放方法,在推理任務中顯示出巨大的潛力。然而,這種方法經常導致精度回報遞減和高計算開銷。為了應對這些挑戰,我們引入了深度自信思考(DeepConf),這是一種簡單但強大的方法,可以提高推理效率和測試時的性能。DeepConf利用模型內部置信度信號,在生成過程中或生成后動態過濾掉低質量的推理痕跡。它不需要額外的模型訓練或超參數調整,并且可以無縫地集成到現有的服務框架中。我們通過各種推理任務和最新的開源模型來評估DeepConf,包括Qwen 3和GPT-OSS系列。值得注意的是,在AIME 2025等具有挑戰性的基準上,DeepConf@512實現了高達99.9%的準確率,與完全并行思維相比,生成的令牌減少了高達84.7%。
文章目錄
- 摘要
- 1 INTRODUCTION
- 2 CONFIDENCE AS AN INDICATOR OF REASONING QUALITY
- 3 DEEP THINK WITH CONFIDENCE
- 3.1 CONFIDENCE MEASUREMENTS
- 3.2 OFFLINE THINKING WITH CONFIDENCE
- 3.3 ONLINE THINKING WITH CONFIDENCE
- 4 EXPERIMENTS
- 4.1 EXPERIMENTAL SETUP
- 4.2 OFFLINE EVALUATIONS
- 4.3 ONLINE EVALUATIONS
- 5 FUTURE WORK
1 INTRODUCTION
大型語言模型(LLM)已經顯示出非凡的推理能力,特別是當配備了在測試時推理期間增強其性能的方法時。一種突出的技術是自我一致性,它對多條推理路徑進行采樣,并通過多數投票聚集最終答案(Wang等人,2023)。這種類型的方法,也稱為并行思維,顯著提高了推理精度,但會產生大量的計算開銷:每個查詢生成大量推理軌跡會線性地擴大推理開銷,限制實際部署(薛等人,2023)。例如,在AIME 2025上使用標準多數投票將PASS@1的準確率從68%提高到82%,需要使用Qwen3-8B為每個問題增加511個額外的推理軌跡,消耗1億個額外的令牌。此外,與多數投票并行的思維表現出回報遞減–績效往往隨著蹤跡數量的增加而飽和或下降(Chen等人,2024a)。一個關鍵的限制是,標準多數投票平等對待所有推理痕跡,忽略質量變化(Pal等人,2024;Wang等人,2025)。當低質量跟蹤在投票過程中占據主導地位時,這可能會導致性能不佳。最近的工作利用下一個令牌分布統計來評估推理跟蹤質量(Geng等人,2024;Fadeeva等人,2024;Kang等人,2025)。較高的預測置信度通常與較低的熵和減少的不確定性相關。通過聚合令牌級統計數據,如熵和置信度分數,現有方法計算整個跟蹤的全局置信度度量,以識別和過濾低質量跟蹤,以提高多數投票性能(Kang等人,2025)。
然而,全球信心指標在實踐中存在幾個局限性。首先,它們可能會掩蓋局部推理步驟中的置信度波動,這可以為估計軌跡質量提供足夠的信號。對跟蹤中的整個令牌進行平均可以掩蓋在特定中間步驟發生的關鍵推理故障。其次,全局置信度測量需要在計算之前生成完整的推理軌跡,這防止了低質量軌跡的提前停止。
我們介紹了DeepConf,一種簡單但有效的測試時間方法,它結合了并行思維和基于局部置信度測量的置信度過濾。DeepConf在離線和在線模式下運行,在生成過程中或生成后識別和丟棄低置信度推理痕跡。這種方法減少了不必要的令牌生成,同時保持或提高了最終答案的準確性。我們在多個推理基準(AIME 2024/2025、HMMT 2025、BRUMO25、GPQA-Diamond)和模型(DeepSeek-8B、Qwen3-8B/32B、GPT-OSS-20B/120B)上評估DeepConf。通過對每個設置平均重復次數的大量實驗,我們證明了DeepConf獲得了優越的推理性能,并且與標準多數投票相比,所需生成的令牌顯著減少。在可以訪問所有推理軌跡的離線模式下,DeepConf@512使用GPT-OSS-120B(無工具)在AIME 2025上達到99.9%的準確率,與CONS@512(多數投票)的97.0%和PASS@1的91.8%相比,飽和了這一基準。在具有實時生成控制的在線模式下,DeepConf在保持或超過準確性的同時,與標準并行思維相比,最高可減少84.7%的令牌生成。圖1突出顯示了我們的主要結果。
2 CONFIDENCE AS AN INDICATOR OF REASONING QUALITY
最近的工作表明,使用從模型的內部令牌分布導出的度量,可以有效地估計推理跟蹤質量。(2025)。這些度量提供了模型固有的信號,用于區分高質量的推理軌跡和錯誤的推理軌跡,而不需要外部監督。令牌熵。給定語言模型在位置i處的預測令牌分布PI,令牌熵被定義為:
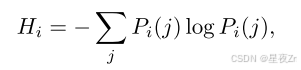
其中,PI(J)表示第j個詞匯標記的概率。低熵表示具有較高模型確定性的峰值分布,而高熵表示預測中的不確定性。
Token Confidence. 我們將令牌置信度Ci定義為位置i處的前k個令牌的負平均對數概率:
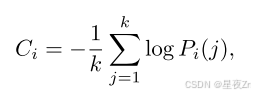
其中k表示所考慮的頂級令牌的數量。高置信度對應于峰值分布和更大的模型確定性,而低置信度表示令牌預測中的不確定性。
Average Trace Confidence. 令牌級指標需要聚合來評估整個推理痕跡。追隨Kang等人的研究。(2025),我們使用平均跟蹤置信度(也稱為自信度)作為跟蹤級別的質量衡量標準:
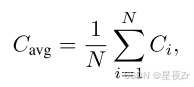
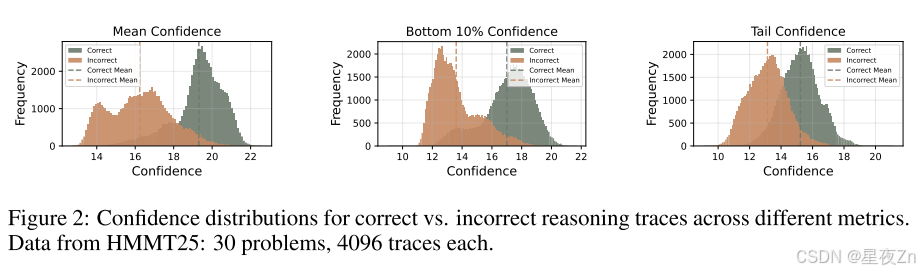
其中N是生成的令牌總數。如圖2所示,平均跟蹤置信度有效地區分正確和不正確的推理路徑,值越高表示正確的可能性越大。盡管它是有效的,但平均跟蹤置信度有顯著的局限性。首先,全局聚合掩蓋了中間推理失敗:幾個高置信度令牌可以掩蓋大量低置信度片段,潛在地隱藏關鍵錯誤。其次,這種方法需要對質量評估進行完整的跟蹤,防止過早終止低質量的生成并導致計算效率低下。
3 DEEP THINK WITH CONFIDENCE
在這一部分中,我們將介紹如何更有效地利用置信度度量來提高推理性能和思維效率。我們的目標是兩個主要場景:線下和在線思維。離線思維通過評估和聚合來自完成的推理痕跡的信息來利用信心來提高推理性能。在線思維在令牌生成過程中結合了置信度,以實時提高推理性能和/或計算效率。
3.1 CONFIDENCE MEASUREMENTS
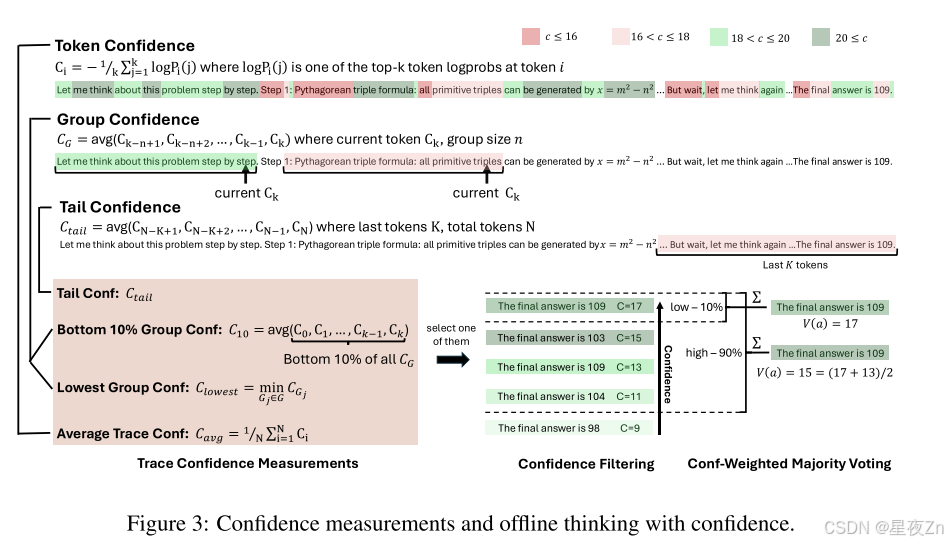
為了解決像自信這樣的全局置信度度量的局限性,我們引入了幾種替代的置信度度量,它們捕獲了局部中間步驟質量,并提供了對推理痕跡的更細粒度的評估。
團體自信心。我們使用群體置信度來量化中間推理步驟的置信度。通過在推理軌跡的重疊跨度上平均標記置信度,群體置信度提供了更局部化和更平滑的信號。每個令牌與滑動窗口組Gi相關聯,滑動窗口組Gi由具有重疊的相鄰窗口的n個先前令牌(例如,n=1024或2048)組成。對于每個組GI,組信任度定義為:
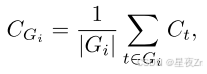 其中,|gi|是組gi中的令牌數。
其中,|gi|是組gi中的令牌數。
估計推理軌跡質量需要從群體置信度中聚合信號。我們觀察到,跟蹤可信度極低的中間步驟會顯著影響最終解的正確性。例如,當在推理過程中,當置信度急劇下降時,使用重復的低置信度標記,如“等待”、“然而”和“再想一想”,就會擾亂推理流程,并導致后續錯誤。
Bottom 10% Group Confidence。為了捕捉極低置信度組的影響,我們提出了最低10%的組置信度,其中跟蹤置信度由跟蹤內最低10%的組置信度的平均值確定:
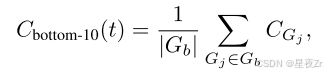
其中,GB是具有最低10%置信度分數的組的集合。經驗上,我們發現10%有效地捕獲了不同模型和數據集中最有問題的推理片段。
Lowest Group Confidence. 我們還考慮了最低群體置信度,它代表了推理軌跡中最不自信的群體的置信度–最低10%的群體置信度的特殊情況。此測量僅基于最低置信度組來評估跟蹤質量:
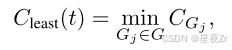
Tail Confidence. 除了基于組的度量之外,我們還提出了尾部置信度,它通過關注最后一部分來評估推理跟蹤的可靠性。這一衡量標準的動機是觀察到,推理質量通常會在長鏈思維的末端降級,而最后幾步對于正確的結論至關重要。在數學推理中,最終答案和結論步驟尤其重要:盡管中間推理前景看好,但開始強勁但結束薄弱的軌跡可能會產生不正確的結果。尾部置信度尾部定義為:
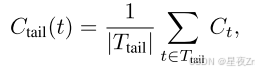
其中Tail表示固定數量的令牌(例如,2048)。圖2比較了不同的置信度度量,說明與平均置信度方法相比,底部10%和尾部置信度度量都更好地分離不正確和正確的跟蹤分布,這表明這些度量對于跟蹤質量估計更有效。
3.2 OFFLINE THINKING WITH CONFIDENCE
我們現在描述如何應用各種置信度度量來提高離線設置下的推理性能。在離線思考中,每個問題的推理軌跡都已經生成,關鍵挑戰是從多個軌跡中聚合信息,以更好地確定最終答案。雖然最近的工作提出了使用LLMS來總結和分析推理軌跡的先進方法,但我們專注于標準的多數投票方法。
Majority Voting. 在標準多數投票中,來自每個推理軌跡的最終答案對最終決定的貢獻是平等的。設T是所有生成的軌跡的集合,對于每個t答案T,設∈(T)是從軌跡t中提取的答案串。每個候選答案a的投票計數為:
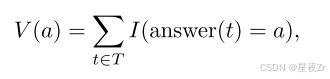
其中 I{?}I\{\cdot\}I{?} 是指示函數。最終答案通過最高票數選出:
a^=arg?max?aV(a).\hat{a} = \arg \max_a V(a).a^=argamax?V(a).
置信度加權多數投票
不同于對每條推理軌跡的投票平等對待,我們根據相應軌跡的置信度對每個最終答案進行加權。對于每個候選答案 aaa,其總投票權重定義為:
V(a)=∑t∈TCt?I(answer(t)=a),V(a) = \sum_{t \in T} C_t \cdot I(\text{answer}(t) = a),V(a)=t∈T∑?Ct??I(answer(t)=a),
其中 CtC_tCt? 是從前文討論的置信度度量方法中選取的軌跡級置信度。我們選擇獲得最高加權票數的答案。這種投票機制傾向于支持高置信度軌跡產生的答案,從而降低不確定或低質量推理結果的影響。
置信度過濾
除了加權多數投票外,我們還采用置信度過濾機制以集中關注高置信度的推理軌跡。該機制根據軌跡置信度分數篩選前 η\etaη% 的軌跡,確保只有最可靠的路徑對最終答案產生貢獻。我們為所有置信度度量提供兩個選項:η=10%\eta = 10\%η=10% 和 η=90%\eta = 90\%η=90%。
選擇前10%的方案側重于最高置信度分數,適用于僅需少量可靠軌跡即可獲得準確結果的情況。但過度依賴極少數量軌跡會因模型偏差而導致錯誤答案。選擇前90%的方案提供了更平衡的策略,通過納入更廣泛的軌跡保持多樣性并降低模型偏差。這在置信度分布趨于均勻時尤為重要,能確保替代推理路徑得到充分考慮。圖3展示了置信度度量的示意圖及離線思考機制與置信度的協同工作原理。算法II提供了具體實現細節。
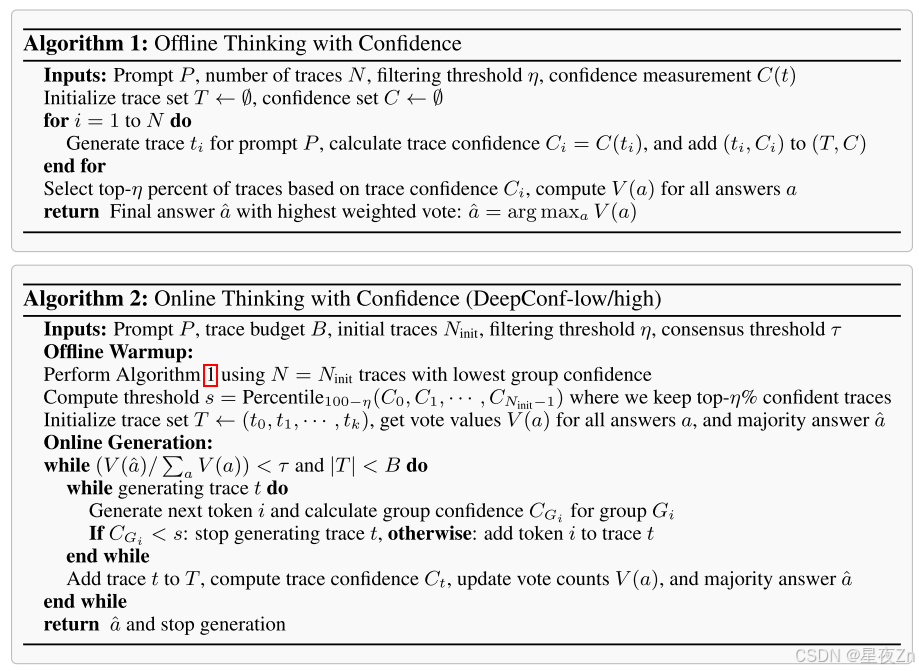
3.3 ONLINE THINKING WITH CONFIDENCE
在在線思考期間評估可信度,可以在生成過程中實時估計痕跡質量,從而動態終止不看好的痕跡。此方法在資源受限的環境中或需要快速響應時特別有用。在此在線設置中可以有效地應用最低組置信度度量。當令牌組置信度低于關鍵閾值時,我們可以停止跟蹤生成,從而確保此類跟蹤很可能在置信度過濾期間被排除。
我們提出DeepConf-low和DeepConf-high這兩種基于最低組置信度的算法,它們能在在線思考過程中自適應地停止生成并調整軌跡預算。該方法包含兩個主要組件:離線預熱和自適應采樣。
離線預熱
DeepConf需要離線預熱階段來建立用于在線判定的停止閾值sss。對于每個新提示,我們生成NinitN_{\text{init}}Ninit?條推理軌跡(例如Ninit=16N_{\text{init}} = 16Ninit?=16)。停止閾值sss定義為:
s=Percentile100?η({Ct:t∈Twarmup}),s = \text{Percentile}_{100-\eta} (\{ C_t : t \in T_{\text{warmup}} \}),s=Percentile100?η?({Ct?:t∈Twarmup?}),
其中TwarmupT_{\text{warmup}}Twarmup?表示所有預熱軌跡,CtC_tCt?是軌跡ttt的置信度,η\etaη為預設保留比例。具體而言,DeepConf-low統一采用前η=10%\eta = 10\%η=10%(對應第90百分位數),DeepConf-high統一采用前η=90%\eta = 90\%η=90%(對應第10百分位數)。該閾值確保在線生成過程中,當軌跡置信度低于預熱階段最高置信度前η%\eta\%η%軌跡的水平時即終止生成。
自適應采樣
在DeepConf中,我們采用跨所有方法的自適應采樣機制,根據問題難度動態調整生成軌跡數量(Xue等[2023])。難度通過已生成軌跡的共識度評估,量化為多數投票權重V(a^)V(\hat{a})V(a^)與總投票權重∑aV(a)\sum_a V(a)∑a?V(a)的比值:
β=V(a^)∑aV(a).\beta = \frac{V(\hat{a})}{\sum_a V(a)}.β=∑a?V(a)V(a^)?.
其中τ\tauτ是預設共識閾值。當β<τ\beta < \tauβ<τ時,模型對當前問題未達成共識,繼續生成軌跡直至達到固定軌跡預算BBB;否則立即停止軌跡生成,并基于現有軌跡確定最終答案。
由于采用最低組置信度機制,足夠大的預熱集能準確估計停止閾值sss——任何在線終止的軌跡其組置信度均低于sss,因而會被離線過濾器排除。因此在線過程近似模擬離線最低組置信度策略,且隨著NinitN_{init}Ninit?增大,其準確度逐漸逼近離線準確度(詳見附錄B.2)。圖4展示了在線生成過程,算法2提供了具體實現細節。
4 EXPERIMENTS
4.1 EXPERIMENTAL SETUP
Models。我們評估了來自三個模型家族的五個開源推理LLM:DeepSeek8B1(Guo等人,2025)、Qwen3-8B、Qwen3-32B(Yang等人,2025a)、GPT-OSS-20B和GPTOSS-120B(OpenAI,2025)。這些模型以強大的數學推理和長期的思維鏈性能而被公認,在可重復性方面完全開源,并涵蓋多個參數范圍以測試穩健性。附錄F提供了完整的生成超參數和提示模板。
基準。我們在五個具有挑戰性的數據集上進行評估:AIME24(問題解決的藝術,2024a;b)、AIME25(問題解決的藝術,2025a;b)、BRUMO25(Bru,2025)、HMMT25(HMMT,2025)和GPQA(Rein等人,2024)。前四個是高難度的數學競賽問題,而GPQA包括研究生級別的STEM推理任務。所有基準都被廣泛采用在最近的頂級推理LLM的評估中(例如,Grok-4(Xai,2025),Qwen3(Yang等人,2025a),GPT-5(OpenAI,2025)),并出現在MathArena排行榜(Balunoviüc等人,2025)中。
基線。我們采用自我一致性(Wang等人,2023年),多數投票作為我們的主要基線。每個LLM對T條獨立推理路徑進行采樣,并通過未加權多數投票選擇最終答案,如SEC中形式化的。3.2.
實驗設置。對于每個問題,我們通過預先生成一個由4,096個完整推理軌跡組成的池來建立一個通用的采樣框架;該池作為離線和在線評估的基礎。離線實驗在每次運行時從該池中重新采樣大小為K(例如,K=512)的工作集,并應用指定的投票方法。在線實驗類似地對工作集進行重新采樣,以通過提前停止來驅動即時生成;該池確保了跨方法的一致采樣。
我們報告了四種關鍵方法:(I)PASS@1(單跡精度),(Ii)CONS@K(具有K個跡線的未加權多數投票準確率),(Iii)MEASure@K(置信度加權多數表決準確度),以及(Iv)MEASure+TOP-η%@K,它在應用加權多數表決之前保留樣本工作集中按置信度最高的η%跡(我們使用η∈{10,90})。具體的置信度衡量標準因設置而異。我們還報告生成的令牌總數。所有指標都是獨立運行的平均值,并帶有新的重新采樣;除非特別說明,否則會對所有生成的軌跡進行端到端的計數,而提前終止的軌跡只會貢獻停止前生成的令牌。
對于在線評估,我們使用最低組置信度(等式)實例化DeepConf-Low和DeepConf-High6)具有2,048個令牌的重疊窗口。每個問題都以NINIT=16條用于離線預熱的完整軌跡開始;然后我們設置特定于運行的停止閾值S=MINT∈Ttop Ct,其中Ttop包含置信度最高的百分位數軌跡(η=10用于深度會議低,η=90用于深度會議高;秒。3.3)。在生成過程中,提前終止當前群體置信度低于S的軌跡;通過信任度加權多數投票聚合完成的軌跡,并在達成共識≥τ或預算K時自適應地停止生成。
對于離線評估,我們對SEC的三個跟蹤級別置信度定義進行了基準測試。3.1:(I)平均跟蹤置信度(Eq.3)、(Ii)最低10%的群體置信度(等式5),以及(Iii)最后2,048個令牌的尾置信度(等式7)。對于每個指標,我們使用η{10,90}報告MEASure@K和MEASure+TOP-η∈%@K,其中每次運行時都會在采樣工作集中重新計算TOP-η%截止值(3.2)。
4.2 OFFLINE EVALUATIONS
在表1中,我們在投票大小為K=512的五個數據集上提供了三個模型的離線結果。我們比較了以下方法:PASS@1=單軌跡精度;CONS@512=具有512個軌跡的未加權多數投票;Mean Conf@512=使用平均軌跡置信度(Eq.3);Bottom-10%Conf@512和Tail Conf@512=使用(I)最低10%重疊組信任度的平均值(等式)進行的信心加權多數投票5)和(Ii)最后2,048個令牌的平均置信度(等式7)。90%/10%子列表示置信度篩選中的保留率η:我們在投票前將最高η%的最高置信度跟蹤保留在樣本工作集中。例如,當K=512時,η=10%時,我們保留了大約51個軌跡用于投票。
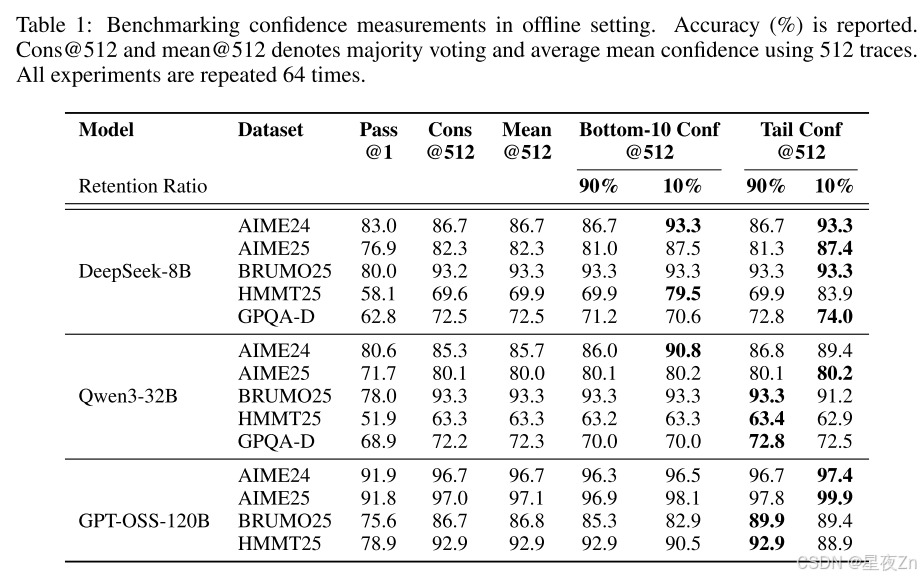
總體而言,在大多數設置中,信心感知加權和過濾始終優于標準多數投票(Cons@512)。η=10%的過濾效果最好,AIME25上的DeepSeek-8B(82.3%→87.4%)和AIME24上的Qwen3-32B(85.3%→90.8%)都有顯著的改善,AIME25上的GPT-OSS-120B甚至達到99.9%。局部(Tail Conf和Bottom-10%)和全局(Average Trace Conf)置信度測量在識別有信心的蹤跡方面都顯示出令人振奮的結果。然而,過濾涉及到重要的權衡:雖然積極過濾(η=10%)在大多數情況下可以最大限度地提高精度,但有時會由于模型對錯誤問題過于自信而損害性能,就像GPT-OSS-120B所看到的那樣。在這種情況下,保守過濾(η=90%)提供了更安全的選擇。與PASS@1相比,在所有方法中都觀察到了實質性的改進,證實了集合方法的價值。我們在附錄B.4中提供了詳細的置信度比較。
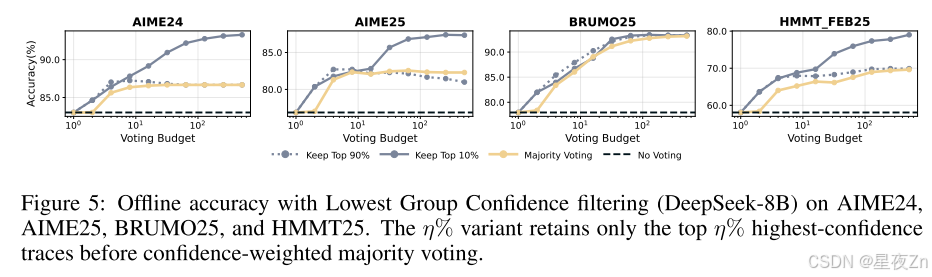
然后,我們證明了最低組置信度也是有效的。圖5使用最低組置信度(等式)報告離線結果6)捕獲每個蹤跡內最不可信的令牌組(窗口大小2,048)。在每個采樣的工作集內,我們保留最高η%的最高置信度跟蹤,然后應用置信度加權多數投票。在使用DeepSeek-8B的AIME24、AIME25、BRUMO25和HMMT25中,保留最高η=10%的結果比多數投票獲得的最佳準確率有一致的提高:+0.26%到+9.38%(平均+5.27%),比單一跟蹤(或不投票)的準確率有很大提高(+10.26%到+20.94個百分點;平均+14.30%)。保守的η=90%設置符合或略高于所有四個數據集的最佳多數投票精度(+0.16%至+0.57%;平均+0.29),同時仍比單道精度(平均+9.31%)有很大改進。這些結果激發了在線變量:關注最不可信的部分可靠地識別出具有局部推理故障的痕跡,為離線過濾提供了強烈的信號,并在在線生成期間提供了一個自然停止的標準。除了這些結果之外,我們在附錄B.3中去除了保留率η,并在附錄C中提供了完整的脫機結果。
4.3 ONLINE EVALUATIONS
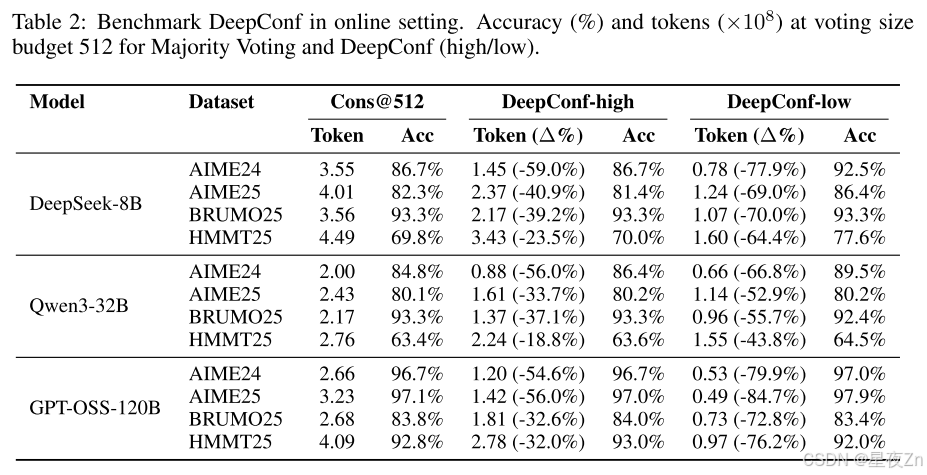
在這一部分中,我們通過改變預算K∈{32,,128,256,512}來評估在線算法的精度和成本之間的權衡,其中成本計算所有生成的標記,包括來自早期停止的跟蹤的部分標記。遵循SEC。3.3.我們使用NINIT=16個軌跡執行預熱,以設置使用最低組置信度(窗口大小2,048)的停止閾值S:我們按置信度將S設置在最高η%的預熱軌跡上(η∈{10,90}),然后一旦其當前的組置信度降到S以下,就終止任何新的軌跡。在每個新的軌跡完成后,我們重新應用相同的閾值S進行過濾,以便該過程與最低組置信度過濾器的離線版本相匹配,同時節省了早期停止的軌跡的成本。我們考慮兩個在線變量:DeepConf-Low(η=10%)和DeepConf-High(η=90%),它們將繼續采樣,直到達到共識≥τ(我們使用τ=0.95%)或預算上限K。我們比較了僅預算的變量(總是運行到上限K而不一致停止)和附錄B.1中不同的τ值。
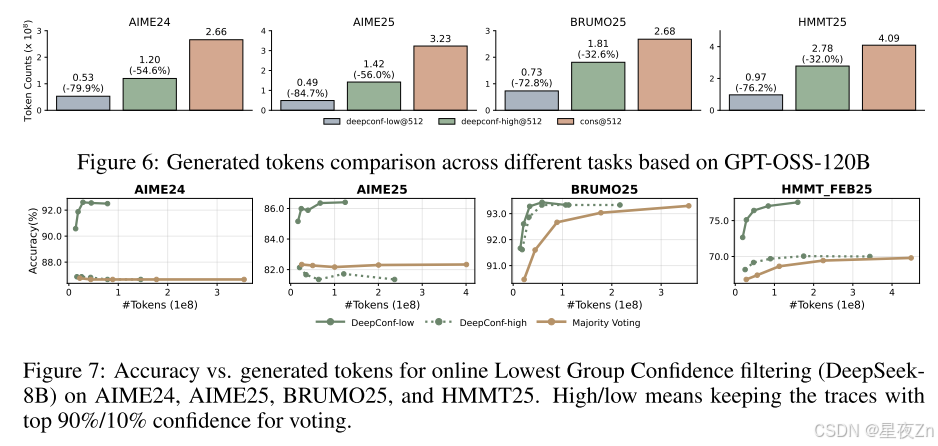
表2顯示了在投票大小預算為K=512的DeepSeek-8B/Qwen3-32B/GPT-OSS-120B上DeepConf的自適應采樣版本的性能。與多數投票基準相比,DeepConf-Low在AIME24/AIME25/BRUMO25/HMMT25中減少了43%-79%的令牌。雖然它在大多數情況下匹配或提高了精度(例如,DeepSeek-8B AIME24:+5.8%),但它在一些設置中經歷了顯著的精度下降(例如,Qwen3-32B BRUMO25:?0.9%)。更保守的DeepConf-HIGH在這些集合上節省了18%-59%的令牌,同時保持了幾乎相同的精度,或者只會導致最小的性能下降。圖6可視化了GPT-OSS-120B的令牌減少模式,說明了DeepConf如何在保持跨不同數學推理任務的競爭性準確性的同時實現大量的計算節省(即,高達85.8%)。
圖7比較了DeepConf和DeepSeek-8B上的多數投票基線。DeepConf方法在保持同等精度的同時顯示出明顯的效率優勢:與相同精度水平的多數投票基線相比,DeepConf-low實現了62.88%的平均令牌節省,DeepConf-High實現了47.67%的平均令牌節省。在性能方面,DeepConf的行為反映了離線設置:η=10%(低)過濾在大多數情況下產生最高的精度提升,盡管它有時可能會導致特定數據集的精度下降(例如,表2中HMMT25上的GPT-OSS-120B)。
這些結果支持我們的設計:使用最不可信的段來選通跟蹤,為提前終止提供了強烈的本地信號,而自適應共識停止在不犧牲精度的情況下進一步壓縮了令牌。此外,我們在附錄B.2中提供了預熱尺寸NINIT的消融,并在附錄D中報告了完整的在線結果。
5 FUTURE WORK
我們相信,從這項工作中可以得出幾個有希望的方向。首先,將DeepConf擴展到強化學習環境可以利用基于信心的提前停止來指導策略探索,并在培訓期間提高樣本效率。第二,解決模型在不正確的推理路徑上表現出高度置信度的情況,這是我們在實驗中觀察到的一個關鍵限制。未來的工作還可以探索更穩健的置信度校準技術和不確定性量化方法,以更好地識別和緩解過度自信但錯誤的預測。
我們提出了DeepConf,這是一種簡單而有效的方法,在集成投票場景中顯著提高了推理性能和計算效率。通過在最先進的推理模型和具有挑戰性的數據集上進行廣泛的實驗,DeepConf展示了顯著的準確性改進,同時實現了有意義的令牌節省,在從8B到120B參數的模型范圍內觀察到了一致的好處。我們希望這種方法突出了測試時間壓縮作為一種實用和可擴展的有效LLM推理解決方案的潛力。
以上內容全部使用機器翻譯,如果存在錯誤,請在評論區留言。歡迎一起學習交流!
鄭重聲明:
- 本文內容為個人對相關文獻的分析和解讀,難免存在疏漏或偏差,歡迎批評指正;
- 本人尊重并致敬論文作者、編輯和審稿人的所有勞動成果,若感興趣,請閱讀原文并以原文信息為準;
- 本文僅供學術探討和學習交流使用,不適也不宜作為任何權威結論的依據。
- 如有侵權,請聯系我刪除。xingyezn@163.com









:『混沌工程的定義與實踐』)









