我認為知識是一定要系統化的學習,結構化梳理,這樣在運用或思考的時候,能夠回憶起自己在這一塊梳理的知識結構,如果有記錄那么能快速回憶并理解,如果沒有記錄,那么說明對自己來說超綱了,把知識進行分類,寫入自己的知識庫,那就對知識點有了一個快速的定位和理解。能夠梳理清晰自己所學的知識,并定位知識點。這就是我認為系統化知識的意義。
我在學習過程中發現,我自己的思維方式和理解方式,想要學會和理解一個知識點,使用它是最快的方式,將這個知識點實戰一次,就基本知道了這東西的作用。
- 使用層面
1)起步入門:粗讀是什么?有什么用?解決了什么問題? 怎么用?(來一個快速實戰,上手做一做)
2)運用核心功能:也是基礎功能、核心知識點,學習運用功能以及掌握核心知識為主。
3)最佳實踐:核心知識要實踐,知識運用有無數種方式,最佳實踐能避免錯誤的運用知識。理論是在原理層面指導實踐。如果有最佳實踐的總結,那便是最好的理論。比如:【關系型數據庫設計理論】就是指導如何設計出高質量的關系型數據庫。
4)小總結:技術優缺點,適用場景。
學到這里,我可以說我會用 CRUD 了。
當然僅僅會用是不夠的,要想用的好、用的靈活,必須要知道它的內部結構和工作原理,比如MySQL ,如果僅僅停留在使用層面,那可能只會CRUD, 如果深入學習了MySQL 內部是B+樹索引,二級索引等,那么在創建表時會酌情新增索引,畢竟每新增一個索引就要創建一棵新的B+樹,另外在查詢表的時候知道如何利用索引高效查詢,如果了解MySQL內部有redo log ,DoubleWrtie pool , 就不那么擔心 SQL 語句執行過程中斷電的問題。知道了 buffer pool ,就明白 InnoDB 是由緩存的,緩存優先存儲最常用的數據,這可能為編寫SQL 帶來一些便利,不過學習到最后明白了 MySQL 調優有限,不如 redis 或者業務優化來的更快更高效。
這便是深入學習和僅僅停留在使用層面的不同之處,我們想要用好一個技術,自然是要學習技術內部原理,明白技術內部是如何工作的,這就是我最喜歡的兩個學習思維,學習技術內部層次結構和工作流程,這兩個方面弄明白了,思維就通暢了。
以今天學到的 MySQL 為例,看看內部層次結構和工作流程。直接上圖了
這是通用關系型數據庫的內部結構圖
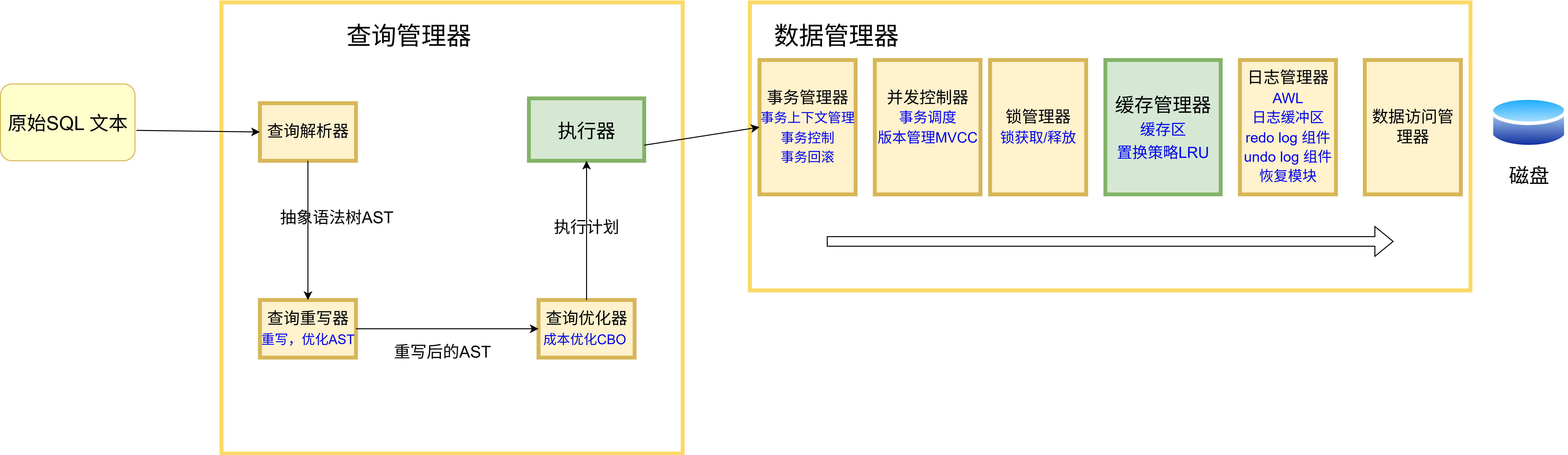
這是MySQL 內部結構圖
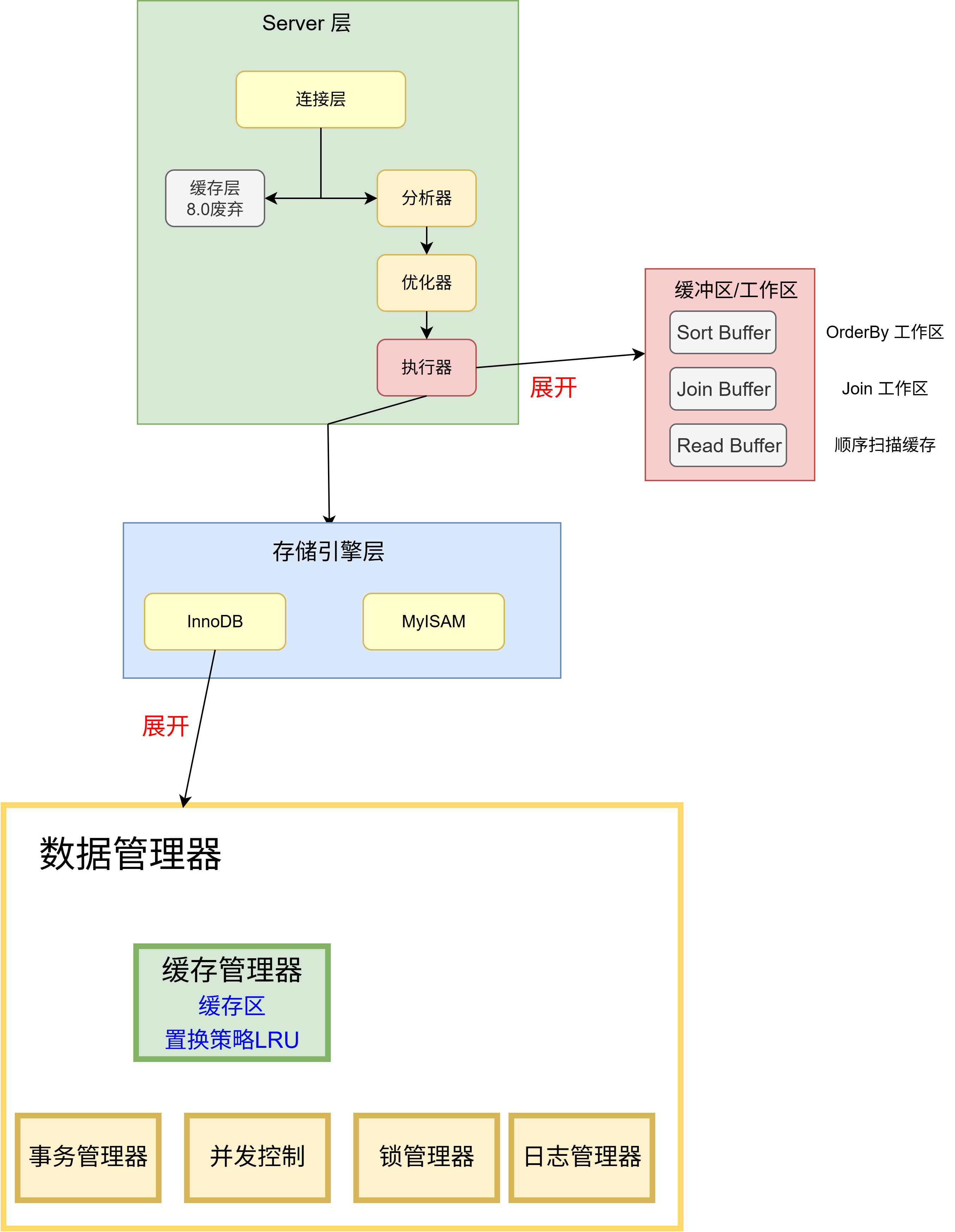
這是 InnoDB 內部存儲結構圖

畫出了這三張圖,我基本上了解 MySQL 內部結構的全貌,當然以上的圖并沒有畫出 MySQL 的所有結構,所有的部分,隨著我對 MySQL 知識面的擴展,我會繼續追加,這些圖有助于我定位正在學習知識點屬于 MySQL 結構的哪一個部分。比如 Doublewrite buffer, 將它定位到結構中,看三分鐘文檔我就理解了。
我另一個熱愛的學習方式是工作流程,看看這玩意是咋工作的,就能把內部結構串起來,理解MySQL 各個結構的作用。當然它的工作流程不止一種,不同情況會有不同的工作流程,可能很多很復雜。不過我們先掌握正常運轉的工作流程,意外情況掌握幾個經典的~
再拿 MySQL 舉例,我們來看看工作原理:
左邊紅色的塊是 Java 程序,集成了 MYSQL 驅動并且引用線程池,避免頻繁創建和銷毀連接帶來的損耗。
中間是發送網絡請求,java 應用發送的 SQL 語句的請求在 MySQL 中是由一個個的線程去處理的。
那么可以得出, 一個 SQL 請求會產生 兩個活躍的線程:一個在 Java 應用側等待/處理結果,一個在 MySQL 側執行 SQL。 注意不是占用哈,占用的意思是拿著不放,活躍的線程是可以調度,切換,阻塞。
右邊是MySQL 數據庫,同樣用一個連接池接收 SQL 請求,線程讀取網絡請求后在MySQL內部執行。
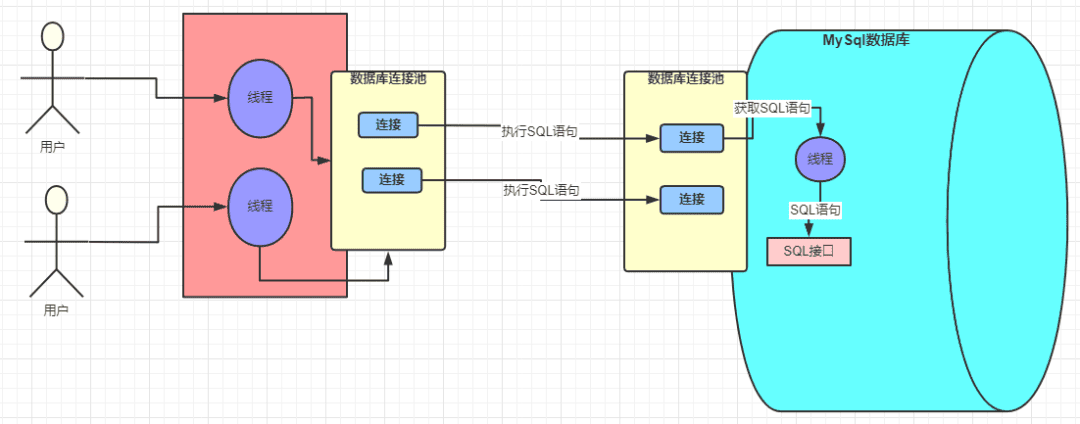
Java 程序通過網絡請求將 SQL 語句字符串發送給 MySQL 服務后,我們看看MySQL 服務內部怎么處理。
1. MYSQL 處理請求流程
- SQL 接口:MySQL 中處理請求的線程在獲取到請求以后獲取 SQL 語句去交給 SQL 接口去處理。
- SQL 解析器:他會將 SQL 接口傳遞過來的 SQL 語句進行解析,翻譯成 MySQL 自己能認識的語言
- SQL 優化器:MySQL 會幫我去使用他自己認為的最好的方式去優化這條 SQL 語句,并生成一條條的執行計劃
- 存儲引擎:查詢優化器會調用存儲引擎的接口,去執行 SQL,也就是說真正執行 SQL 的動作是在存儲引擎中完成的。
- 執行器:前面那些組件的操作最終必須通過執行器去調用存儲引擎接口才能被執行
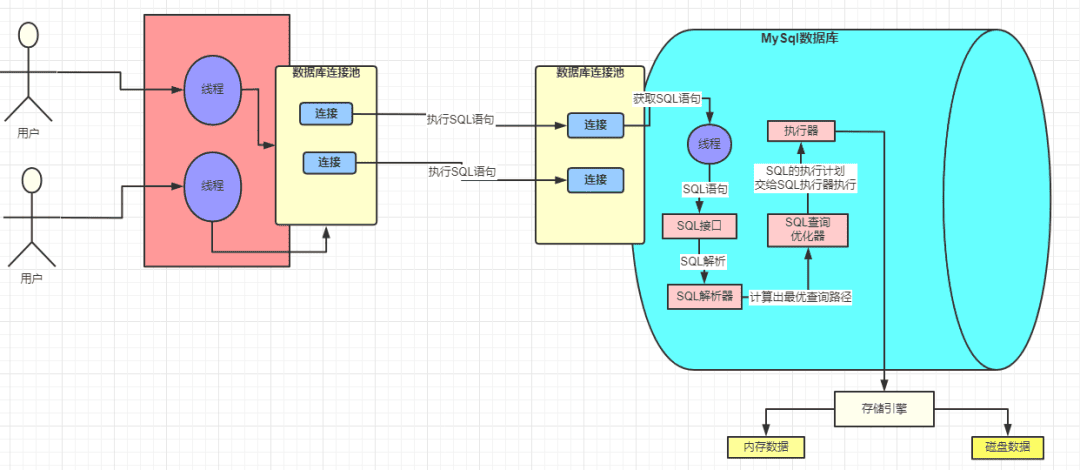
接下來看看存儲引擎做了什么!
2. 存儲引擎執行 SQL 流程
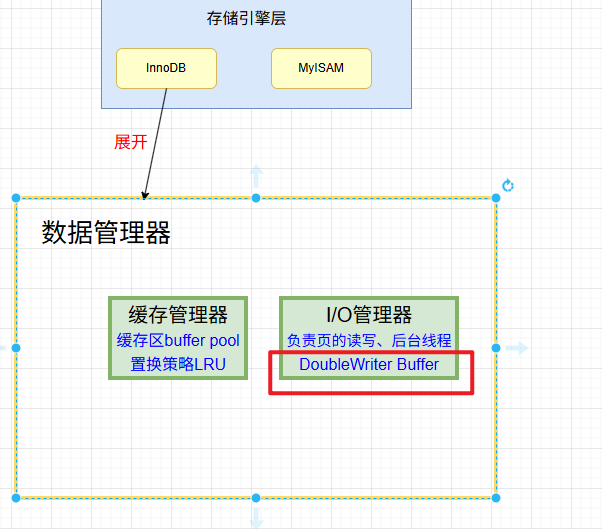
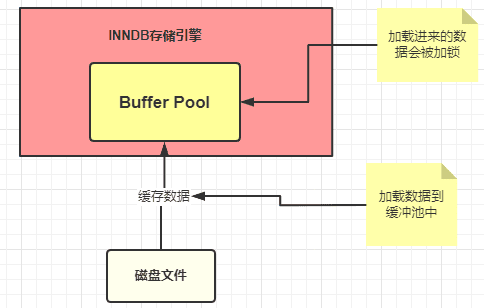
1)Buffer Pool (緩沖池)是 InnoDB 存儲引擎中非常重要的內存結構, InnoDB 級別的緩存。緩沖池中的數據和數據庫(磁盤)中的數據不一致時候,我們就認為緩存中的數據是臟數據,
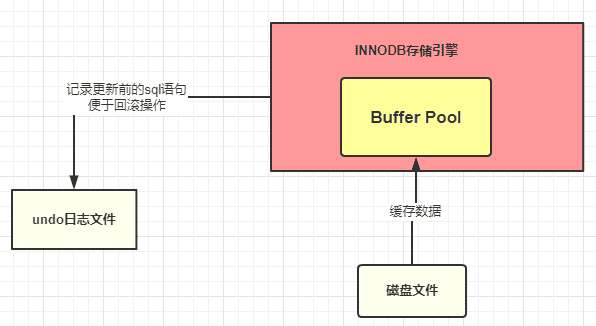
2)undo 日志文件:記錄數據被修改前的樣子,事務回滾時發揮作用。我們程序是正常運作,這里僅僅記錄。
3)redo 日志文件:記錄數據被修改后的樣子,redo 日志文件是 InnoDB 特有的,他是存儲引擎級別的,不是 MySQL 級別的,緩存池更新后記錄到緩存日志中,緩存日志默認是立刻寫入磁盤。緩存池數據是延遲。
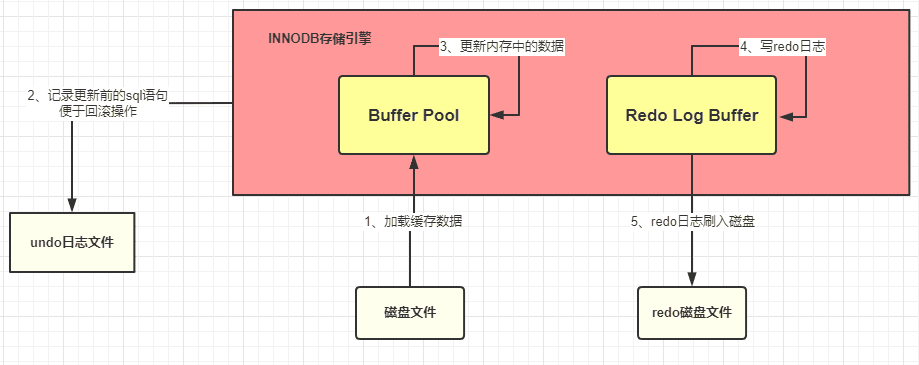
InnoDB 目前整體執行流程:
- 準備更新一條 SQL 語句
- MySQL(innodb)會先去緩沖池(BufferPool)中去查找這條數據,沒找到就會去磁盤中查找,如果查找到就會將這條數據加載到緩沖池(BufferPool)中
- 在加載到 Buffer Pool 的同時,會將這條數據的原始記錄保存到 undo 日志文件中
- innodb 會在 Buffer Pool 中執行更新操作
- 更新后的數據會記錄在 redo log buffer 中
- MySQL 提交事務的時候,會將 redo log buffer 中的數據寫入到 redo 日志文件中 刷磁盤可以通過 innodb_flush_log_at_trx_commit 參數來設置
- 值為 0 表示不刷入磁盤
- 值為 1 表示立即刷入磁盤
- 值為 2 表示先刷到 os cache
- myslq 重啟的時候會將 redo 日志恢復到緩沖池中
4) binlog : 記錄整個操作過程,bin log 通過追加的方式記錄,當文件大小大于給定值后,后續的日志會記錄到新的文件上,bin log 適用于主從復制和數據恢復。
bin log 刷盤有三種模式
- STATMENT :基于 SQL 語句的復制(statement-based replication, SBR),每一條會修改數據的 SQL 語句會記錄到 bin log 中
- ROW:基于行的復制(row-based replication, RBR),不記錄每條SQL語句的上下文信息,僅需記錄哪條數據被修改了
- MIXED:基于 STATMENT 和 ROW 兩種模式的混合復制( mixed-based replication, MBR ),一般的復制使用 STATEMENT 模式保存 bin log ,對于 STATEMENT 模式無法復制的操作使用 ROW 模式保存 bin log
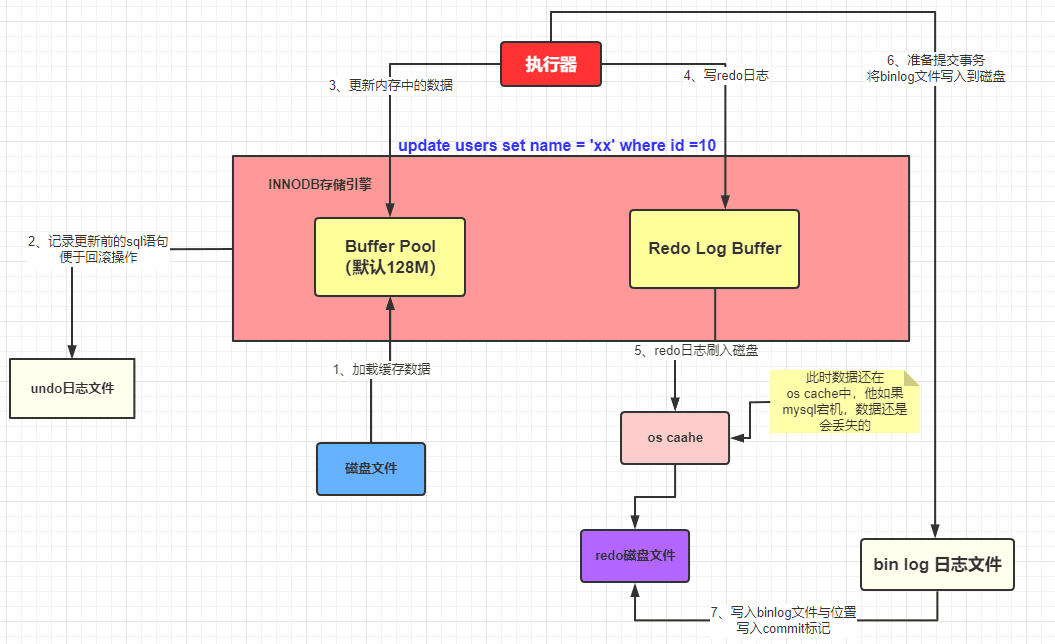
5) MySQL 會有一個后臺線程,它會在某個時機從 Buffer Pool 中挑選出臟數據刷到 MySQL 數據庫中

如果在數據被寫入到bin log文件的時候,剛寫完,數據庫宕機了,數據會丟失嗎?
首先可以確定的是,只要redo log最后沒有 commit 標記,說明本次的事務一定是失敗的。但是數據是沒有丟失了,因為已經被記錄到redo log的磁盤文件中了。在 MySQL 重啟的時候,就會將 redo log 中的數據恢復(加載)到Buffer Pool中。
最后返回到查詢執行器,經過封裝后發回給調用的客戶端。
從這兩個角度學習新技術,基本上就能掌握技術,但是并不能掌握高級使用場景,比如知道了MySQL 以上內容,當碰到主從復制,讀寫分離、分庫分表的場景還是手足無措。這些都屬于MySQL的優化,一門技術核心功能掌握了,肯定要想還能怎么優化,優化到上限是什么?優化的代價又是什么?
當使用分庫分表,比如將數據庫做了一個水平分庫,把一個庫分成多個庫,這樣的數據存在多個數據庫中,在高并發場景下,對多個數據庫讀寫肯定比對一個庫讀寫要快不少,做了一個性能優化,這是一種 MySQL 的高階使用。
分庫的代價是什么呢?
此時思維要切換到管理多個數據庫帶來了什么麻煩?
我們都知道 SQL 語句是在數據庫中執行的,也就是說 SQL 中的 Order By 排序僅僅是對于單個數據庫排序,而我的數據庫有多個,這并不算是對我系統的全部數據排序。
另外還有 count(*) , START TRANSACTION 都會出現這種情況。這是第一個代價,管理數據庫變得更復雜。
第二個代價,要把思維切換到存儲數據層面,你能想到什么?
ID 要保持唯一性,多個數據庫就有可能發生 ID 重復,那么 ID 失去了唯一性還能叫 ID 嗎?根據一個ID 查出兩個人這合理嗎?我不希望有人跟我的身份證同號呀,可想而知這個問題會帶來多少麻煩。
問題的解決辦法不加以探索了,我要學習一些更核心的知識,畢竟我還是太菜了。

![NSSCTF每日一題_Web_[SWPUCTF 2022 新生賽]奇妙的MD5](http://pic.xiahunao.cn/NSSCTF每日一題_Web_[SWPUCTF 2022 新生賽]奇妙的MD5)










![[論文閱讀] 人工智能 + 軟件工程 | 別讓AI寫的代碼帶“漏洞”!無觸發投毒攻擊的防御困境與啟示](http://pic.xiahunao.cn/[論文閱讀] 人工智能 + 軟件工程 | 別讓AI寫的代碼帶“漏洞”!無觸發投毒攻擊的防御困境與啟示)

- H2 Database Console 未授權訪問)

更新中......)


