摘要
本文章系統闡述了深層語義在自然語言處理(NLP)領域的定義、特征及其與知識圖譜和大型預訓練語言模型的融合方法。基于截至2025年8月的最新研究成果,報告深入分析了深層語義的多維度特性、技術實現路徑以及面臨的挑戰,為研究人員和學術作者提供全面的理論框架和實踐指南。
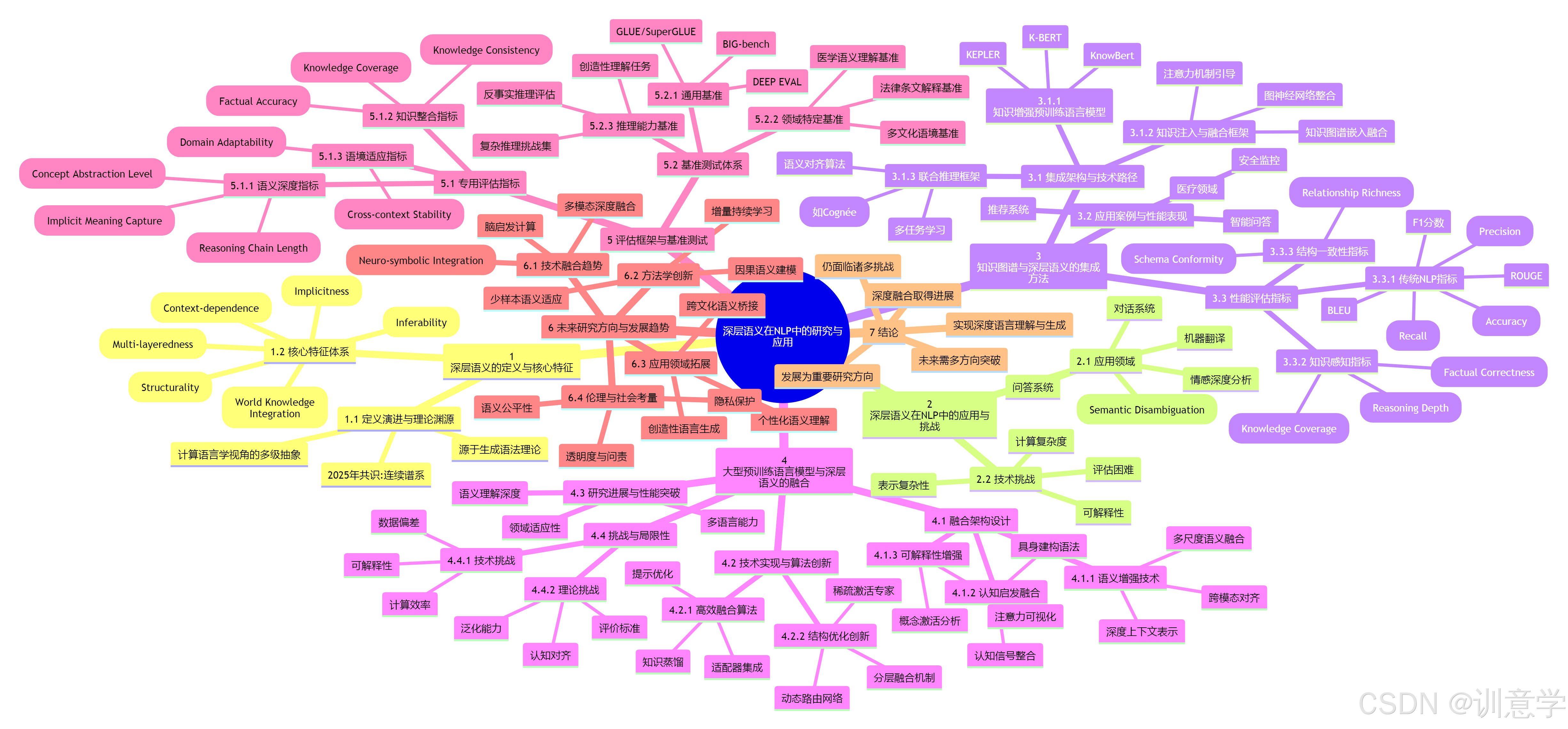
1 深層語義的定義與核心特征
1.1 定義演進與理論淵源
深層語義在自然語言處理中缺乏統一的標準化定義,但根據多學科研究可將其概括為:超越表面詞匯和語法結構,蘊含于語言使用中的隱含意義、語境依賴關系和世界知識的綜合語義表征?。這一概念源于語言學中的生成語法理論,其中深層結構(Deep Structure)與語義解釋密切相關?。
從計算語言學視角,深層語義涉及多級抽象層次:第一級為概念意義,第二級為操作意義,涉及上下文、語用學和世界知識的整合?。2025年的學術共識傾向于將深層語義視為連續譜系而非二元劃分,其深度取決于具體應用場景和所需的推理復雜度。
1.2 核心特征體系
基于現有研究,深層語義呈現以下關鍵特征:
隱含性(Implicitness):深層語義不直接體現在表面詞匯中,而是通過語言使用暗示的語義或語境因素?
語境依賴性(Context-dependence):語義解釋高度依賴語言使用的具體情境,同一表層表達在不同語境中可能激活不同的深層含義?
多層次性(Multi-layeredness):包含從詞匯概念到語用推理的多級語義表示,需要整合語法、語義和語用信息?
結構性(Structurality):具有內在的語義結構關系,如深層語義角色和語法特征,這些關系對語義角色預測至關重要?
可推理性(Inferability):需要通過推理過程才能完全揭示,涉及對語言輸入的深度分析和解釋?
世界知識整合(World Knowledge Integration):依賴于語言外的常識和領域知識,超越純粹的語言學信息?
2 深層語義在NLP中的應用與挑戰
2.1 應用領域
深層語義處理已成為NLP的核心挑戰和重點研究方向,主要應用包括:
- 語義排歧(Semantic Disambiguation):消除語言表達中的歧義,準確捕捉特定語境下的意圖含義?
- 情感深度分析:超越表面情感傾向,理解情感表達的深層原因和隱含態度?
- 問答系統:理解問題的深層意圖,提供符合實際需求的精準答案
- 機器翻譯:捕捉源語言的深層語義結構,生成符合目標語言習慣的表達?
- 對話系統:理解對話中的隱含意義和語用意圖,實現自然流暢的交互
2.2 技術挑戰
深層語義處理面臨多項技術挑戰:
- 表示復雜性:深層語義的抽象性和多樣性使其難以用統一框架表示?
- 計算復雜度:深層語義分析需要大量計算資源,特別是在處理長文本和復雜語境時?
- 評估困難:缺乏專門針對深層語義的評估指標和基準數據集,難以客觀衡量系統性能?
- 可解釋性:深度學習模型雖在處理復雜語義方面表現突出,但常被視為黑箱,缺乏透明度?
3 知識圖譜與深層語義的集成方法
3.1 集成架構與技術路徑
知識圖譜(KG)與深層語義的集成主要通過以下技術路徑實現:
3.1.1 知識增強預訓練語言模型(Knowledge-Enhanced Pre-trained LMs)
這種方法將知識圖譜信息注入預訓練過程,增強模型對事實性知識的理解能力?。具體實現方式包括:
- KnowBert:通過實體鏈接和自監督學習結合,將知識庫嵌入到BERT中,提升事實召回和關系提取性能?
- K-BERT:通過可編輯的知識圖譜進行調整,使模型適應特定領域的需求?
- KEPLER:在預訓練目標中融入知識圖譜嵌入損失,聯合學習文本表示和知識表示?
3.1.2 知識注入與融合框架
在模型推理階段動態整合知識圖譜信息:
- 知識圖譜嵌入融合:將知識圖譜中的實體和關系嵌入與文本表示相結合,捕獲三元組的深層語義聯系?
- 圖神經網絡整合:利用GNN處理知識圖譜結構信息,與Transformer編碼的文本表示進行深度融合?
- 注意力機制引導:通過注意力權重選擇相關知識三元組,獲取有用的知識表示?
3.1.3 聯合推理框架
實現知識圖譜與語言模型的協同推理:
- 模塊化框架(如Cognée):通過端到端的KG構建和檢索,實現復雜推理任務?
- 語義對齊算法:利用知識圖譜、語義對齊算法和Transformer模型進行認知語義通信?
- 多任務學習:在多任務設置中聯合端到端訓練,同時優化語言理解和知識推理能力?
3.2 應用案例與性能表現
知識圖譜與深層語義集成已在多個領域取得顯著成果:
- 智能問答:在開放域問答中,知識融合和語義知識排名模型顯著提升答案準確性和豐富性?
- 推薦系統:利用知識圖譜增強的語義表示,改善個性化推薦效果和可解釋性
- 醫療領域:ClinicalBERT等專業模型利用醫學知識圖譜處理醫學語義,提升臨床決策支持能力?
- 安全監控:在水電工程施工安全領域,應用NLP和深度學習進行安全隱患治理的智能決策?
3.3 性能評估指標
知識圖譜與深層語義集成系統的評估采用多維度指標:
3.3.1 傳統NLP指標
- 準確率(Accuracy)、精確率(Precision)、召回率(Recall)、F1分數:用于分類和抽取任務評估?
- BLEU、ROUGE:用于生成任務評估?
3.3.2 知識感知指標
- 事實正確性(Factual Correctness):衡量生成內容的事實準確性
- 知識覆蓋率(Knowledge Coverage):評估系統利用的知識范圍完整性
- 推理深度(Reasoning Depth):度量系統進行深層推理的能力
3.3.3 結構一致性指標
- 關系豐富度(Relationship Richness):知識圖譜中關系的多樣性和復雜性?
- 模式一致性(Schema Conformity):輸出與知識圖譜模式的一致性程度
4 大型預訓練語言模型與深層語義的融合
4.1 融合架構設計
大型預訓練語言模型(如BERT、GPT)本身具備強大的深層語義捕捉能力,其融合技術主要圍繞增強、解釋和優化三個維度:
4.1.1 語義增強技術
- 深度上下文表示:BERT通過雙向自注意力機制捕捉上下文信息,提供豐富的上下文表示?
- 多尺度語義融合:結合不同層次的表示,捕獲從詞匯到 discourse 的多粒度語義信息
- 跨模態對齊:在多模態大型語言模型(MLLM)中實現視覺與語言語義的深度融合?
4.1.2 認知啟發融合
- 認知信號整合:將人類認知處理信號整合到語言模型中,增強語義理解能力?
- 具身建構語法:采用認知語言學方法(如Embodied Construction Grammar)處理深層語義和組合性問題?
4.1.3 可解釋性增強
- 注意力可視化:分析自注意力權重,揭示模型關注的語言現象和語義線索
- 概念激活分析:探究不同網絡層如何獲取和表示知識和概念?
4.2 技術實現與算法創新
2025年的研究在技術實現層面呈現多項創新:
4.2.1 高效融合算法
- 適配器集成:通過輕量級適配器注入領域知識,避免全模型微調的計算開銷
- 提示優化:連接大型語言模型與進化算法以產生強大的提示優化器?
- 知識蒸餾:將大型模型的知識壓縮到較小模型中,保持深層語義理解能力
4.2.2 結構優化創新
- 分層融合機制:在不同網絡層次集成不同類型的知識和語義表示
- 動態路由網絡:根據輸入內容動態選擇處理路徑,優化深層語義處理效率
- 稀疏激活專家:使用混合專家模型(MoE)架構,針對不同語義任務激活特定參數子集
4.3 研究進展與性能突破
截至2025年,大型預訓練模型與深層語義融合已取得顯著進展:
- 語義理解深度:最新模型在深層語義理解任務上接近人類水平,特別是在常識推理和隱含意義理解方面?
- 多語言能力:大規模語言模型(如MaLA-500)展現出強大的多語言適應和跨語言檢索能力?
- 領域適應性:領域特定模型(如ClinicalBERT)在專業領域的深層語義處理表現突出?
4.4 挑戰與局限性
盡管取得進展,該領域仍面臨多項挑戰:
4.4.1 技術挑戰
- 計算效率:模型規模不斷擴大,訓練和推理需要大量計算資源?
- 可解釋性:深度學習模型在處理復雜語義時仍缺乏透明度和可解釋性?
- 數據偏差:訓練數據中的偏差會影響深層語義處理的公平性和準確性
4.4.2 理論挑戰
- 評價標準:缺乏專門針對深層語義的評估指標和基準測試?
- 泛化能力:模型在訓練分布外的泛化能力有限,難以處理新穎的語義組合
- 認知對齊:機器與人類在深層語義處理上仍存在差距,特別是在創造性理解和推理方面?
5 評估框架與基準測試
5.1 專用評估指標
針對深層語義集成的評估需要超越傳統指標,采用多維度評估框架:
5.1.1 語義深度指標
- 概念抽象度(Concept Abstraction Level):衡量處理抽象概念和能力
- 推理鏈長度(Reasoning Chain Length):評估多步推理能力的指標
- 隱含意義捕獲率(Implicit Meaning Capture):量化對語言隱含意義的理解程度
5.1.2 知識整合指標
- 知識一致性(Knowledge Consistency):輸出與知識圖譜的一致性程度
- 事實準確性(Factual Accuracy):生成內容的真實性和準確性
- 知識覆蓋廣度(Knowledge Coverage):涉及的知識領域和范圍的廣泛性
5.1.3 語境適應指標
- 跨語境穩定性(Cross-context Stability):在不同語境中保持語義理解一致性的能力
- 領域適應性(Domain Adaptability):適應新領域和專業術語的能力
5.2 基準測試體系
2025年的深層語義評估主要依賴以下基準測試:
5.2.1 通用基準
- GLUE/SuperGLUE:評估通用語言理解能力,包含多種語義任務?
- BIG-bench:大規模基準,包含超越當前模型能力的挑戰性任務?
- DEEP EVAL:專門評估深層語義理解的基準,重點關注模型對圖像和文本深層語義的理解能力?
5.2.2 領域特定基準
- 醫學語義理解基準:評估在醫療領域的專業語義處理能力
- 法律條文解釋基準:測試對法律文本深層含義的理解能力
- 多文化語境基準:評估跨文化語義理解能力
5.2.3 推理能力基準
- 復雜推理挑戰集:包含需要多步推理和世界知識的復雜問題
- 反事實推理評估:測試模型對反事實情境的理解和推理能力
- 創造性理解任務:評估對隱喻、類比等創造性語言的理解能力
6 未來研究方向與發展趨勢
基于2025年的研究現狀,深層語義處理未來可能向以下方向發展:
6.1 技術融合趨勢
- 神經符號融合(Neuro-symbolic Integration):深度融合神經網絡與符號推理,增強可解釋性和推理能力
- 多模態深度融合:整合視覺、語音和文本等多模態信息,實現更全面的語義理解
- 腦啟發計算:借鑒人類大腦的語義處理機制,設計更符合認知規律的計算模型?
6.2 方法學創新
- 因果語義建模:從相關關系向因果關系演進,實現更深入的語義理解
- 增量持續學習:開發可持續學習新語義知識的系統,避免災難性遺忘
- 少樣本語義適應:實現用少量樣本適應新領域和新語言的深層語義模式
6.3 應用領域拓展
- 個性化語義理解:根據用戶背景和偏好提供個性化的語義解釋
- 跨文化語義橋接:幫助克服不同文化背景下的語義理解障礙
- 創造性語言生成:不僅理解深層語義,還能生成具有豐富深層含義的語言表達
6.4 倫理與社會考量
- 語義公平性:確保深層語義處理系統不會強化或產生偏見
- 隱私保護:在深度語義分析中保護個人隱私和敏感信息
- 透明度與問責:提高系統的透明度和可解釋性,建立有效的問責機制
7 結論
深層語義處理作為自然語言理解的核心挑戰,已從單純的理論探索發展為具有豐富技術路徑和實踐應用的重要研究方向。通過與知識圖譜和大型預訓練語言模型的深度融合,深層語義處理在準確性、深度和實用性方面取得了顯著進展。
然而,該領域仍面臨諸多挑戰,包括可解釋性、計算效率、評估標準和泛化能力等方面。未來的研究需要從神經符號融合、多模態整合、腦啟發計算等方向尋求突破,同時重視倫理考量和社會影響。
2025年的研究共識表明,深層語義處理正朝著更加深入、全面和人性化的方向發展,有望在未來實現真正意義上的深度語言理解和生成,為人類與機器的自然交互奠定堅實基礎。


)





 - LeetCode】437. 路徑總和 III)
 方法詳解)
控制器局域網總線(二))

的簡介、安裝和使用方法、案例應用之詳細攻略)






