VideoMaker:零樣本定制化視頻生成,依托于視頻擴散模型的內在力量
paper title:VideoMaker: Zero-shot Customized Video Generation with the Inherent Force
of Video Diffusion Models
paper是ZJU發布在Arxiv 2024的工作
Code:鏈接

圖1. 我們的 VideoMaker 可視化結果。我們的方法基于 AnimateDiff [26],實現了高保真零樣本定制化人物和物體視頻生成。
Abstract
零樣本定制化視頻生成因其巨大的應用潛力而備受關注。現有方法依賴于額外的模型來提取和注入參考主體特征,假設僅憑視頻擴散模型(VDM)不足以實現零樣本定制化視頻生成。然而,這些方法由于特征提取和注入技術不夠理想,往往難以保持主體外觀的一致性。在本文中,我們揭示了 VDM 本身就具備提取和注入主體特征的內在能力。不同于以往的啟發式方法,我們提出了一種新穎的框架,利用 VDM 的內在力量來實現高質量的零樣本定制化視頻生成。具體而言,在特征提取方面,我們直接將參考圖像輸入 VDM,并利用其內在的特征提取過程,這不僅提供了細粒度的特征,還能顯著契合 VDM 的預訓練知識。在特征注入方面,我們設計了一種創新的雙向交互機制,通過 VDM 內部的空間自注意力在主體特征與生成內容之間建立聯系,從而保證 VDM 在保持生成視頻多樣性的同時具有更好的主體保真度。在人物和物體定制化視頻生成上的實驗結果驗證了我們框架的有效性。
1. Introduction
視頻擴散模型(VDMs)[5, 9, 19, 57, 70] 可以根據給定的文本提示生成高質量視頻。然而,這些預訓練模型無法從特定主體生成對應視頻,因為這種定制化主體僅通過文本提示難以準確描述。這個問題被稱為定制化生成,已有研究通過個性化微調 [6, 53, 65, 67] 進行探索。然而,耗時的主體特定微調限制了其在現實中的應用。最近,一些基于 [58, 71] 的方法 [23, 32] 開始探索零樣本定制化視頻生成,但這些方法仍未能保持與參考主體一致的外觀。
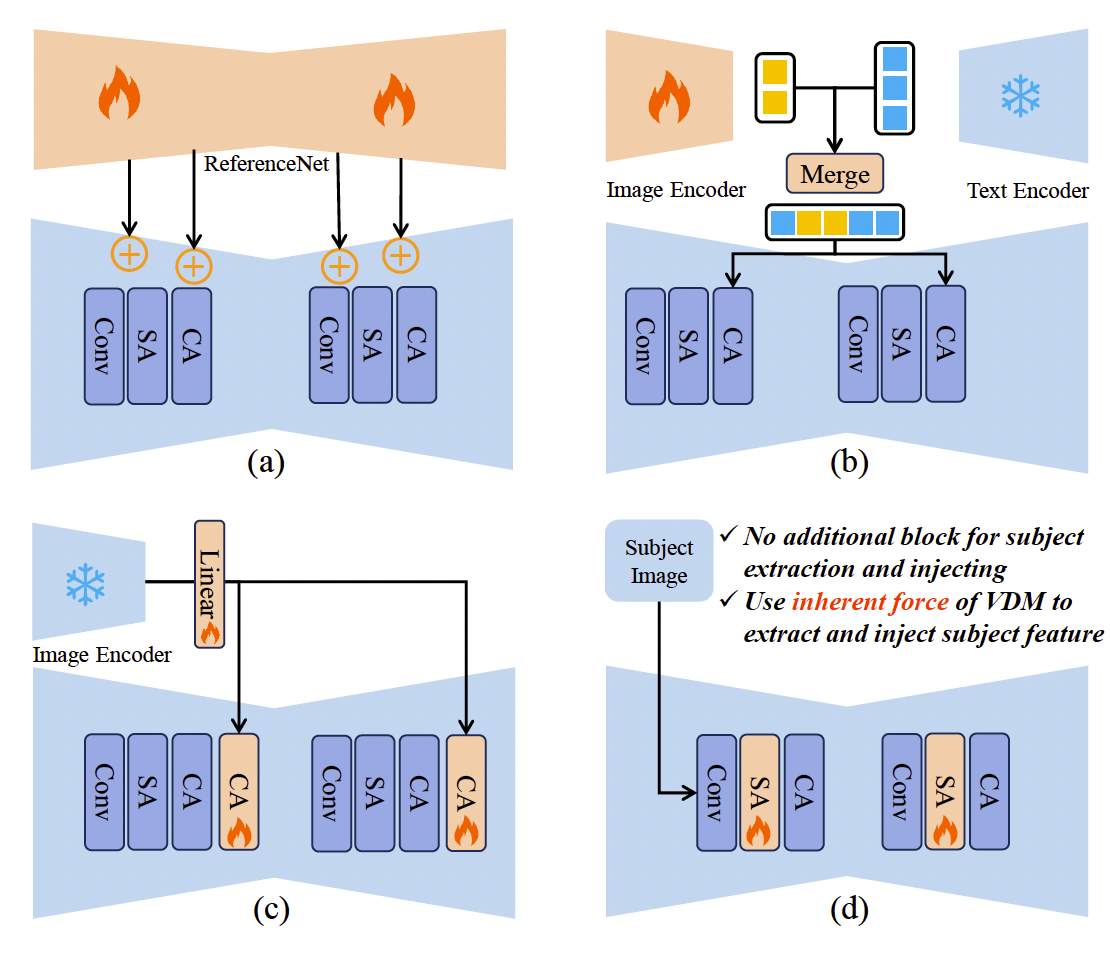
圖2. 與現有零樣本定制化生成框架相比,我們的框架無需任何額外模塊來提取或注入主體特征。它只需要將參考圖像與生成視頻進行簡單拼接,并利用 VDM 的內在能力生成定制化視頻。
定制化視頻生成的兩個關鍵在于主體特征提取與主體特征注入。當前方法依賴額外的模型進行特征提取和注入,往往忽視了 VDM 的內在能力。例如,一些方法 [26, 58, 68] 受到 [79] 啟發,采用額外的 ReferenceNet 進行特征提取,并將主體特征直接加入 VDM 中進行注入(圖2 (a))。然而,這些方法引入了大量額外訓練參數,并且這種像素級注入方式顯著限制了生成視頻的多樣性。其他方法 [23, 32, 38, 71] 則采用預訓練的跨模態對齊模型 [43, 45, 50, 69] 作為特征提取器,并通過跨注意力層注入主體特征(圖2 (b,c))。然而,這些方法從預訓練提取器中獲得的僅是粗粒度的語義級特征,難以捕捉主體的細節。因此,這些精心設計的啟發式方法并未在定制化視頻生成中取得令人滿意的效果。一個自然的問題是:或許 VDM 本身就具備提取和注入主體特征的能力,我們只需通過一種簡單方式激活并利用這種力量,就能實現定制化生成?
重新審視 VDM,我們發現了一些潛在的內在能力。在主體特征提取方面,由于輸入無噪聲的參考圖像可以視為時間步 t=0t=0t=0 的特殊情況,預訓練的 VDM 已經能夠在無需額外訓練的情況下提取其特征。在主體特征注入方面,VDM 的空間自注意力主要建模幀內不同像素之間的關系,因此更適合注入與生成內容緊密相關的主體參考特征。此外,空間自注意力的自適應特性使其能夠選擇性地與這些特征交互,從而避免過擬合并促進生成視頻的多樣性。因此,如果我們利用 VDM 本身作為細粒度的主體特征提取器,并通過空間自注意力機制將主體特征與生成內容交互,就能利用 VDM 的內在力量實現定制化生成。
基于上述動機,我們提出了 VideoMaker,一個新穎的框架,利用 VDM 的內在能力實現高質量的零樣本定制化生成。我們將參考圖像作為模型輸入的一部分,直接使用 VDM 進行特征提取。所提取的特征不僅細粒度,而且與 VDM 的內在知識高度契合,避免了額外的對齊過程。在主體特征注入方面,我們利用 VDM 的空間自注意力,在逐幀生成內容時顯式地將主體特征與生成內容進行交互,使其與 VDM 的內在知識保持緊密聯系。此外,為了確保模型在訓練過程中能夠有效區分參考信息與生成內容,我們設計了一種簡單的學習策略以進一步提升性能。我們的框架采用原生方法完成主體特征的提取與注入,無需增加額外模塊,僅需對預訓練的 VDM 進行輕量微調以激活其內在力量。通過大量實驗,我們在定性與定量結果上均驗證了方法在零樣本定制化視頻生成中的優越性。
我們的貢獻總結如下:
- 我們利用視頻擴散模型的內在力量提取主體的細粒度外觀特征,這些外觀信息對視頻擴散模型的學習更為友好。
- 我們革新了以往的信息注入方式,創新性地利用視頻擴散模型中原生的空間自注意力計算機制完成主體特征注入。
- 我們的框架優于現有方法,僅通過微調部分參數就實現了高質量的零樣本定制化視頻生成。
2. Related Work
2.1. Text-to-video diffusion models
隨著擴散模型和圖像生成 [12, 28, 29, 46–49, 51, 52, 66, 76, 82] 的進展,文本生成視頻(T2V)取得了顯著突破。由于高質量視頻-文本數據集 [4, 33] 的有限性,許多研究者嘗試基于已有的文本生成圖像(T2I)框架來開發 T2V 模型。一些研究 [3, 13, 20, 60, 61, 75, 77, 80, 83] 專注于改進傳統 T2I 模型,通過引入時序模塊并訓練這些新組件,將 T2I 模型轉化為 T2V 模型。具有代表性的例子包括 AnimateDiff [19]、Emu Video [17]、PYoCo [16] 和 Align your Latents [4]。此外,LVDM [24]、VideoCrafter [7, 9]、ModelScope [57]、LAVIE [62] 和 VideoFactory [59] 等方法采用了類似的架構,利用 T2I 模型進行初始化,并在空間和時序模塊上進行微調,從而獲得更優的視覺效果。除此之外,Sora [5]、CogVideoX [70]、Latte [44] 和 Allegro [84] 通過融合基于 Transformer 的骨干網絡 [44, 73] 并結合 3D-VAE 技術,在視頻生成方面也取得了重要進展。這些基礎模型的發展為定制化視頻生成奠定了堅實的基礎。
2.2. Customized Image/Video Generation
與基礎模型的發展歷程類似,文本生成圖像技術的快速進步也推動了圖像領域中定制化生成的顯著發展。能夠適應用戶偏好的定制化圖像生成,正受到越來越多的關注 [8, 10, 21, 22, 27, 30, 37, 39, 41, 42, 54, 55, 58, 64]。這些工作大體可以分為兩類,依據在更換主體時是否需要對整個模型進行重新訓練。第一類方法包括 Textual Inversion [14]、DreamBooth [53]、Custom Diffusion [35] 和 Mix-of-Show [18]。這類方法通過學習一個文本 token 或直接微調模型的全部或部分參數,實現完全定制化。盡管這些方法通常能生成與指定主體高度一致的高保真內容,但在主體變化時仍需重新訓練。第二類方法包括 IP-Adapter [71]、InstantID [58] 和 PhotoMaker [38]。這些方法采用不同的信息注入技術,并利用大規模訓練,從而在主體更換時無需參數重訓。在這些方法的基礎上,定制化視頻生成也隨著基礎模型的進展而發展起來。DreamVideo [65]、CustomVideo [63]、Animate-A-Story [25]、Still-Moving [6]、CustomCrafter [67] 和 VideoAssembler [81] 通過微調視頻擴散模型的部分參數實現定制化。然而,這相較于圖像定制化生成帶來了更高的訓練成本,對用戶而言造成了顯著的不便。一些研究,如 VideoBooth [32] 和 ID-Animator [23],嘗試采用類似 IP-Adapter 的訓練方法,但尚未達到與定制化圖像生成相同的成功水平。
3. Preliminary
視頻擴散模型(VDMs)[9, 19, 24, 57] 旨在通過擴展圖像擴散模型以適應視頻數據,從而完成視頻生成任務。VDMs 通過對從高斯分布采樣的變量逐步去噪來學習視頻數據分布。首先,一個可學習的自編碼器(由編碼器 E\mathcal{E}E 和解碼器 D\mathcal{D}D 組成)被訓練用于將視頻壓縮到一個更小的潛在空間表示。然后,潛在表示 z=E(x)z = \mathcal{E}(x)z=E(x) 被訓練替代視頻 xxx。具體來說,擴散模型 ?θ\epsilon_\theta?θ? 旨在根據文本條件 ctextc_{text}ctext? 在每個時間步 ttt 預測加入的噪聲 ?\epsilon?,其中 t∈U(0,1)t \in \mathcal{U}(0,1)t∈U(0,1)。訓練目標可以簡化為一個重建損失:
Lvideo=Ez,c,?~N(0,I),t[∥???θ(zt,ctext,t)∥22],(1)\mathcal{L}_{video} = \mathbb{E}_{z, c, \epsilon \sim \mathcal{N}(0, I), t} \Big[ \lVert \epsilon - \epsilon_\theta (z_t, c_{text}, t) \rVert_2^2 \Big], \tag{1} Lvideo?=Ez,c,?~N(0,I),t?[∥???θ?(zt?,ctext?,t)∥22?],(1)
其中 z∈RF×H×W×Cz \in \mathbb{R}^{F \times H \times W \times C}z∈RF×H×W×C 是視頻數據的潛在編碼,F,H,W,CF, H, W, CF,H,W,C 分別表示幀數、高度、寬度和通道。ctextc_{text}ctext? 是輸入視頻的文本提示。一個帶噪潛在編碼 ztz_tzt? 由真實潛在編碼 z0z_0z0? 生成,形式為 zt=λtz0+σt?z_t = \lambda_t z_0 + \sigma_t \epsilonzt?=λt?z0?+σt??,其中 σt=1?λt2\sigma_t = \sqrt{1 - \lambda_t^2}σt?=1?λt2??,λt\lambda_tλt? 和 σt\sigma_tσt? 是控制擴散過程的超參數。在本文中,我們選擇 AnimateDiff [19] 作為基礎視頻擴散模型。
4. Method
給定一張主體的照片,我們的目標是訓練一個模型,該模型能夠提取主體的外觀并生成相同主體的視頻。此外,在更換主體時,該模型不需要重新訓練。我們在第 4.1 節討論了方法的關鍵思想,并在第 4.2 節詳細說明了如何利用 VDM 的內在能力來提取主體特征并使 VDM 學習主體。在第 4.3 節中,我們介紹了所提出的訓練策略,以更好地區分參考信息與生成內容。此外,我們在第 4.4 節中補充了有關訓練和推理的細節。
4.1. Explore Video Diffusion Model
為了實現定制化視頻生成,需要解決兩個核心問題:主體特征提取和特征注入。在主體特征提取方面,一些工作采用跨模態對齊模型,例如 CLIP [50]。然而,由于其訓練任務的限制,這些模型僅能生成粗粒度特征,無法細致地捕捉主體的外觀。一些研究嘗試訓練 ReferenceNet,但這顯著增加了訓練開銷。我們提出了一種新方法,利用預訓練的 VDM 進行主體特征提取。當將主體參考圖像直接輸入 VDM 且不添加噪聲時,可以將其視為 t=0t=0t=0 時 VDM 的特殊情況。因此,VDM 能夠準確地處理并提取無噪聲參考圖像的特征。這種方法不僅能夠在不增加額外訓練開銷的情況下提取細粒度主體特征,還能減少所提取特征與 VDM 內在知識之間的域差異。
在特征注入方面,空間交叉注意力通常用于 VDM 在圖像和文本之間的跨模態交互。受這種設計的影響,現有方法啟發式地采用交叉注意力來注入主體特征。然而,VDM 中的空間自注意力主要用于建模幀內像素之間的關系。在定制化視頻生成中,一個關鍵目標是確保主體“出現在”幀中。因此,在構建幀內像素關系時注入主體特征是一種更直接的方法。此外,空間自注意力能夠選擇性地與這些特征交互,從而有助于提升生成視頻的多樣性。受益于 VDM 自身執行的特征提取,我們可以直接利用 VDM 的內在空間自注意力建模能力來實現更直接的信息交互。
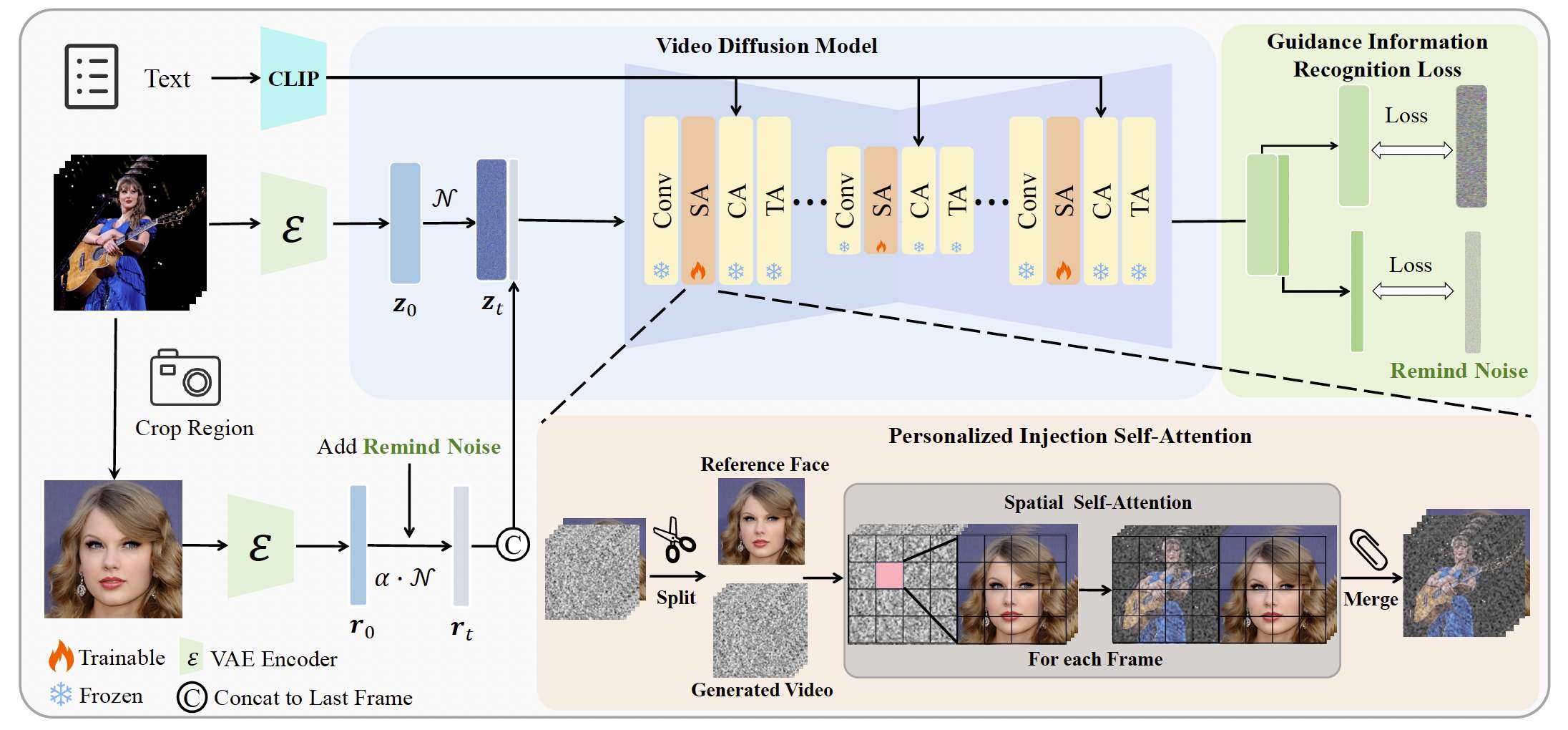
圖3. VideoMaker 的整體流程。我們將參考圖像直接輸入 VDM,并利用 VDM 的模塊進行細粒度特征提取。同時,我們修改了空間自注意力的計算方式以實現特征注入。此外,為了區分參考特征與生成內容,我們設計了引導信息識別損失(Guidance Information Recognition Loss)來優化訓練策略。
4.2. Personalized Injection Self Attention
主體特征提取。與以往的方法不同,我們利用 VDM 的現有網絡結構來實現這一點,即基于單元的 VDM 中的 Resblock。如圖3所示,給定一個視頻 xxx,它被編碼到潛在空間中并加噪得到 zt∈RF×H×W×Cz_t \in \mathbb{R}^{F \times H \times W \times C}zt?∈RF×H×W×C。同時,對于特定主體的參考圖像 RRR,我們首先通過 VAE 編碼參考圖像 RRR,在不添加噪聲的情況下獲得 rrr。然后我們將編碼后的參考圖像潛在空間 rrr 與 ztz_tzt? 沿幀維度進行拼接,得到 zt′∈R(F+1)×H×W×Cz_t' \in \mathbb{R}^{(F+1) \times H \times W \times C}zt′?∈R(F+1)×H×W×C,作為模型的實際輸入。接下來,我們使用 Resblock 作為特征提取器,從 zt′z_t'zt′? 中提取特征,得到輸入 f∈R(F+1)×h×w×cf \in \mathbb{R}^{(F+1) \times h \times w \times c}f∈R(F+1)×h×w×c,供空間自注意力層使用。然后我們將特征 fff 分離,得到對應于生成視頻的噪聲部分 fz∈RF×h×w×cf_z \in \mathbb{R}^{F \times h \times w \times c}fz?∈RF×h×w×c,以及對應于參考信息的部分 fr∈R1×h×w×cf_r \in \mathbb{R}^{1 \times h \times w \times c}fr?∈R1×h×w×c。至此,我們完成了針對特定主體的特征提取。
主體特征注入。在提取到特定主體特征后,接下來需要將這些特征注入到 VDM 中。對于 fzf_zfz? 中的每一幀 fzif_z^ifzi?,在計算空間自注意力之前,它會被轉換為 h×wh \times wh×w 個 tokens。我們將 frf_rfr? 與 fzif_z^ifzi? 拼接,使得每幀的空間自注意力輸入變為 2×h×w2 \times h \times w2×h×w 個 tokens。我們將這些 tokens 記為 XXX。然后,我們通過空間自注意力來融合這些信息:
X′=Attention(Q,K,V)=Softmax(QK?d)V(2)X' = \text{Attention}(Q,K,V) = \text{Softmax}\left(\frac{QK^\top}{\sqrt{d}}\right)V \tag{2} X′=Attention(Q,K,V)=Softmax(d?QK??)V(2)
其中 X′X'X′ 表示輸出的注意力特征,Q,K,VQ, K, VQ,K,V 分別表示查詢、鍵和值矩陣。具體來說,Q=XWQ,K=XWK,V=XWVQ = XW_Q, K = XW_K, V = XW_VQ=XWQ?,K=XWK?,V=XWV?。WQ,WK,WVW_Q, W_K, W_VWQ?,WK?,WV? 分別是對應的投影矩陣,ddd 是鍵特征的維度。在計算注意力后,我們將輸出注意力特征 X′X'X′ 分離為 fz′f_z'fz′? 和 fr′f_r'fr′?。由于 fr′f_r'fr′? 被重復 FFF 次,我們對 FFF 個對應結果取平均,作為最終的 fr′f_r'fr′?。最后,我們將得到的 fr′f_r'fr′? 與 fz′f_z'fz′? 拼接,得到更新后的 f′f'f′,并將其輸入到后續的模型層進行進一步處理。
4.3. Guidance Information Recognition Loss
由于我們框架的實際輸入 zt′z_t'zt′? 相比于公式 (1) 的輸入多了一幀,因此輸出 ?θ∈R(F+1)×H×W×C\epsilon_\theta \in \mathbb{R}^{(F+1)\times H \times W \times C}?θ?∈R(F+1)×H×W×C 也相對于公式 (1) 的輸出多了一幀。一個直接的訓練目標是去掉對應參考信息 rrr 的輸出,只對剩余幀計算損失。這種方法鼓勵模型專注于學習帶有指定主體的定制化視頻生成。然而,我們在實驗中發現,如果對參考信息沒有監督,模型會難以準確識別參考信息 rrr 是一張未加噪聲的圖像,從而導致生成結果不穩定。為了解決這個問題,我們引入了引導信息識別損失(Guidance Information Recognition Loss),用于對參考信息進行監督,使模型能夠準確區分參考信息與生成內容,從而提升定制化生成的質量。具體來說,在訓練過程的時間步 ttt,我們為參考信息 rrr 添加一個提醒噪聲:
rt=λt′r+1?λt′2?,(3)r_t = \lambda_{t'} r + \sqrt{1 - \lambda_{t'}^2}\,\epsilon, \tag{3} rt?=λt′?r+1?λt′2???,(3)
其中 t′=α?tt' = \alpha \cdot tt′=α?t,α\alphaα 是一個手動設置的超參數。
為了防止加入的噪聲嚴重破壞參考信息,α\alphaα 被設置為一個較小的值,以確保提醒噪聲保持在最小水平。在計算損失函數時,我們還會像公式 (1) 那樣對參考信息 rrr 計算損失:
Lreg=Er,c,?~N(0,I),t[∥???θ(rt,ctext,t)∥22].(4)\mathcal{L}_{reg} = \mathbb{E}_{r,c,\epsilon \sim \mathcal{N}(0,I),t} \Big[ \lVert \epsilon - \epsilon_\theta(r_t, c_{text}, t) \rVert_2^2 \Big]. \tag{4} Lreg?=Er,c,?~N(0,I),t?[∥???θ?(rt?,ctext?,t)∥22?].(4)
我們將 Lreg\mathcal{L}_{reg}Lreg? 作為輔助優化目標,與主要目標結合起來,引導模型的訓練:
L=Lvideo+β?Lreg,(5)\mathcal{L} = \mathcal{L}_{video} + \beta \cdot \mathcal{L}_{reg}, \tag{5} L=Lvideo?+β?Lreg?,(5)
其中 β\betaβ 是一個超參數。為了避免干擾主要的定制化視頻生成任務的優化,β\betaβ 被選擇為一個相對較小的值。
4.4. Training and Inference Paradigm
訓練。我們框架的簡潔設計使得在訓練過程中無需額外的主體特征提取器。由于我們只是調整了輸入 tokens 的數量到模型原有的空間自注意力層,將主體信息注入 VDM 并不會增加參數量。我們假設預訓練 VDM 中的 ResBlock 已經足夠提取參考圖像中的特征信息。因此,我們的模型只需要在訓練過程中微調原始 VDM 的空間自注意力層,同時凍結其余部分的參數。此外,為了使時序注意力能夠更好地區分參考信息與生成視頻,我們建議在訓練時同步微調 motion block 的參數。即使不微調 motion block,該方法也能實現定制化視頻生成。我們還會在訓練階段隨機丟棄圖像條件,以便在推理階段實現無分類器引導(classifier-free guidance):
?^θ(zt,ct,r,t)=w?θ(zt,ct,r,t)+(1?w)?θ(zt,t).(6)\hat{\epsilon}_\theta(z_t, c_t, r, t) = w \epsilon_\theta(z_t, c_t, r, t) + (1-w)\epsilon_\theta(z_t, t). \tag{6} ?^θ?(zt?,ct?,r,t)=w?θ?(zt?,ct?,r,t)+(1?w)?θ?(zt?,t).(6)
推理。在推理過程中,對于模型的輸出,對應參考信息的輸出會被直接丟棄。此外,雖然我們在訓練時對主體參考圖像添加了輕微噪聲,以顯式幫助模型區分引導信息,但在推理過程中我們選擇去除參考圖像的噪聲添加。這保證了生成的視頻不會受到噪聲影響,從而保持輸出的質量與穩定性。

)





反序列化漏洞)

)


![【光照】[光照模型]發展里程碑時間線](http://pic.xiahunao.cn/【光照】[光照模型]發展里程碑時間線)



)
![[光學原理與應用-332]:ZEMAX - 序列模式與非序列模式的本質、比較](http://pic.xiahunao.cn/[光學原理與應用-332]:ZEMAX - 序列模式與非序列模式的本質、比較)
)
