目錄
1. 條件概率:上下文預測的基礎
2. LLM 是如何“看著上下文寫出下一個詞”的?
補充說明(重要)
📌 Step 1: 輸入處理
📌 Step 2: 概率計算
📌 Step 3: 決策選擇
🤔 一個有趣的細節:為什么 ChatGPT 有時“拼字很差”?
3. 溫度 (Temperature) 的妙用
4. 小結:LLM 的核心運作機制
1. 條件概率:上下文預測的基礎
“條件概率” 是理解 LLM 的第一步,也是預測邏輯的底層支撐。換句話說,模型是在已知上下文的基礎上預測下一個詞出現的概率,這是一個“給定 A,求 B”的問題,即 P(下一個詞 | 上下文)。在 LLM 中,上下文越豐富,模型對后續詞語的預測就越精準。
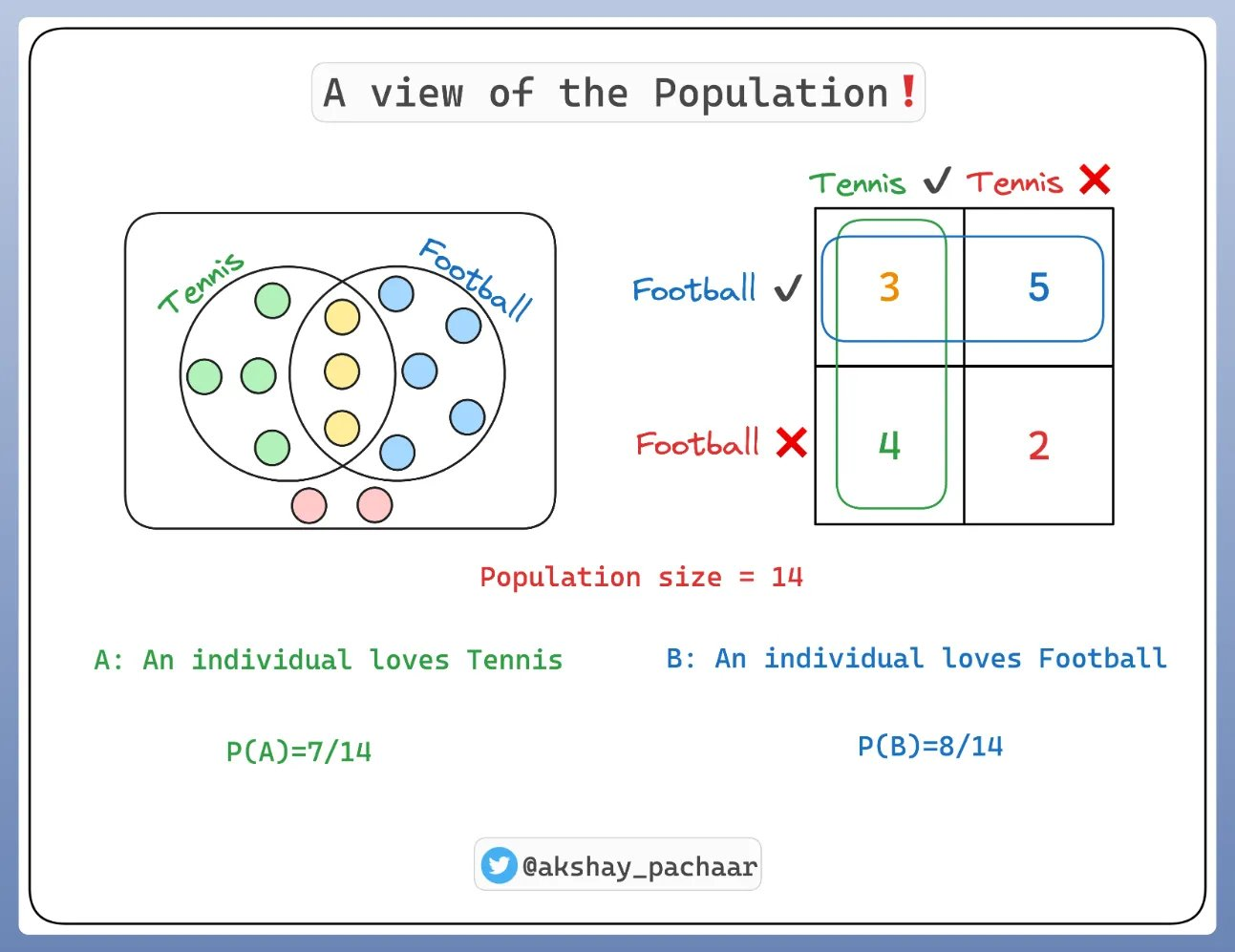
在深入探討 LLM之前,我們必須理解條件概率。 讓我們考慮一個包含 14 個人的群體:其中一些人喜歡網球(7人)其中一些人喜歡足球(8人)有些喜歡網球和足球(3人) 有些全部都不喜歡(2人)。如下圖所示。
????
那么條件概率是什么呢?這是在另一個事件發生的情況下,某事件發生的概率度量。 如果事件是 A 和 B,我們表示為 P(A|B)。 這讀作"給定 B 的 A 的概率"。
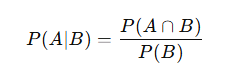
這里:
-
A:喜歡籃球
-
B:喜歡足球
-
P(A∣B):已知喜歡足球的前提下,喜歡籃球的概率
舉例說明:如果我們正在預測今天是否會下雨(事件 A),知道天是多云的(事件 B)可能會影響我們的預測(下雨概率增大)。 由于多云時下雨的可能性更大,我們會說條件概率 P(A|B)很高。 這就是條件概率!
2. LLM 是如何“看著上下文寫出下一個詞”的?
LLM 從海量文本中學習一個高維的“詞序列概率分布”,其內部參數(以巨大的權重矩陣形式存在)就是訓練的成果,它讓模型能夠評估在不同上下文中、每個詞出現的概率。
那么,這個如何應用于像 GPT-4 這樣的 LLMs這些模型的任務是預測序列中的下一個詞。 這是一個條件概率的問題:在已知之前出現過的詞的情況下,哪個詞最有可能成為下一個詞?

為了預測下一個詞,模型會根據之前的詞(上下文)計算每個可能下一個詞的條件概率。 條件概率最高的詞被選為預測結果。
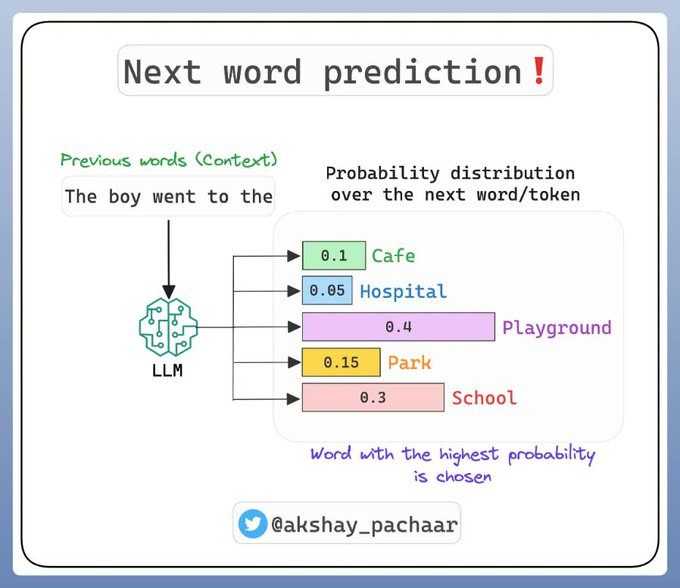
LLM 學習一個高維的詞序列概率分布。 而這個分布的參數就是訓練好的權重! 訓練或者說預訓練是監督式的。
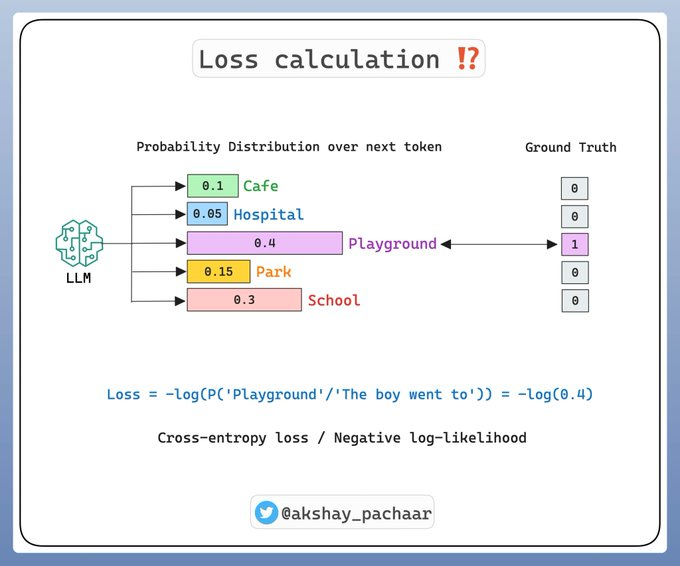
補充說明(重要)
在前面我們提到,LLM 的任務就是“根據上下文預測下一個詞”。但更準確地說,LLM 的工作原理是:
👉 模型會把輸入文本轉化為一系列 token,然后基于上下文重復預測下一個 token 的概率分布。
📌 Step 1: 輸入處理
-
文本會先經過 分詞器(Tokenizer) 轉換成 token 序列;
-
每個 token 會被映射為數字 ID,再轉為向量輸入模型。
舉例:
-
"Learning new things is fun!"→ 被分詞后,每個常見的單詞通常會變成一個 token; -
"prompting"這樣的長單詞,會被拆解為多個 token:"prom"、"pt"、"ing"。
因此,LLM 實際上預測的不是一個完整的單詞,而是一個個 token。
📌 Step 2: 概率計算
-
模型通過 自注意力機制(Self-Attention),結合上下文信息,計算出每個 token 作為下一個輸出的條件概率;
-
舉例:在
"I love machine"之后,模型會評估"learning"、"apple"、"gun"等 token 出現的概率,通常"learning"的概率最高。
📌 Step 3: 決策選擇
-
如果模型每次都選擇概率最高的 token,輸出可能會“死板”且容易重復;
-
因此在實際生成時,會引入 溫度(Temperature) 參數和 采樣(Sampling)策略,讓結果既合理又有一定多樣性。
🤔 一個有趣的細節:為什么 ChatGPT 有時“拼字很差”?
當你讓 ChatGPT 顛倒 "lollipop" 的字母時,它可能會輸出錯誤。
原因是:
-
分詞器將
"lollipop"分解為三個 token:"l"、"oll"、"ipop"; -
模型處理的單位是 token,而不是單個字母,自然就難以逐字母反轉。
? 小技巧:
如果你寫成 "l - o - l - l - i - p - o - p",分詞器會把它們分解為單個字母 token,
這樣 ChatGPT 就能逐字處理,從而更容易得到正確的結果。
3. 溫度 (Temperature) 的妙用
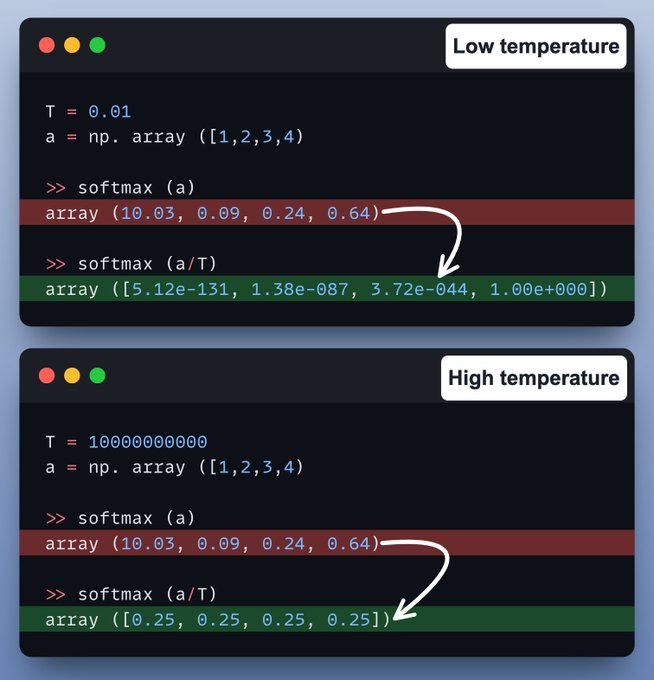
但是有一個問題? 如果我們總是選擇概率最高的詞,最終會得到重復的輸出,使 LLM幾乎毫無用處,并扼殺它們的創造力。 這就是溫度(Temperature)發揮作用的地方。
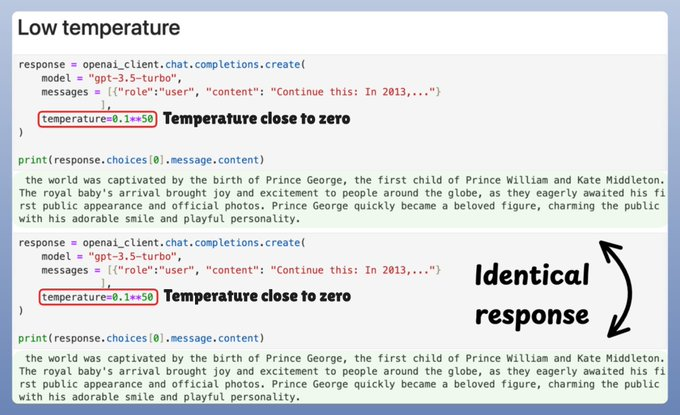
然而,過高的溫度值會產生亂碼。

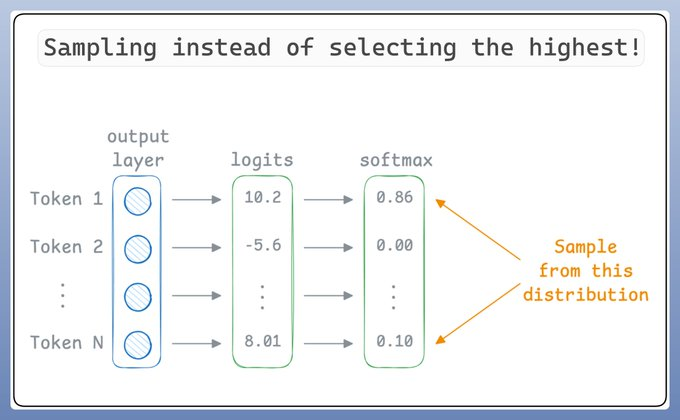
所以,LLM不是選擇最佳詞元(為了簡化,我們可以將詞元視為單詞),而是對預測進行"采樣"。 所以即使“詞元 1”得分最高,也可能不會被選擇,因為我們正在進行采樣。
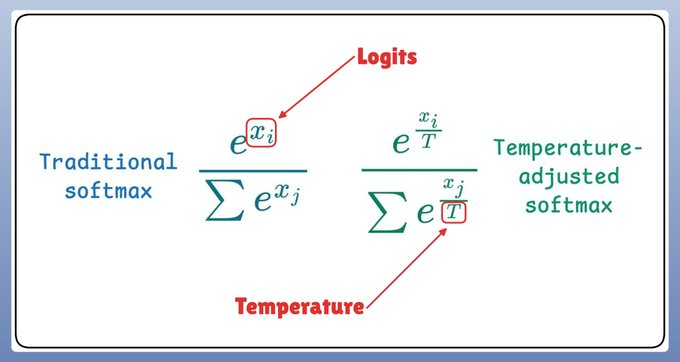
現在,溫度在 softmax 函數中引入了以下調整,進而影響了采樣過程:
讓我們來看一個代碼示例!
在低溫下,概率集中在最可能的標記周圍,導致生成幾乎貪婪的結果。
在高溫下,概率變得更加均勻,產生高度隨機和隨機的輸出。
4. 小結:LLM 的核心運作機制
| 核心概念 | 通俗類比 / 理解 | 技術要點及作用 |
|---|---|---|
| 條件概率 | 看天氣圖預測是否下雨 | 模型預測下一個詞的可能性,依賴上下文 |
| 概率模型 | 訓練出的“大腦”,幫你判斷哪個詞最可能出現 | 權重矩陣構成預測核心,來自大規模語料預訓練 |
| 溫度控制+采樣? | 留有余地,不死板,讓生成更“有痕跡”或“有趣” | 控制輸出“保守”或“多樣性”之間的平衡 |
?原文鏈接:Akshay 🚀 on X: "How LLMs work, clearly explained:" / X





)


的討論)





任務執行)



:發布)
