一、啟動模式
1、standalone
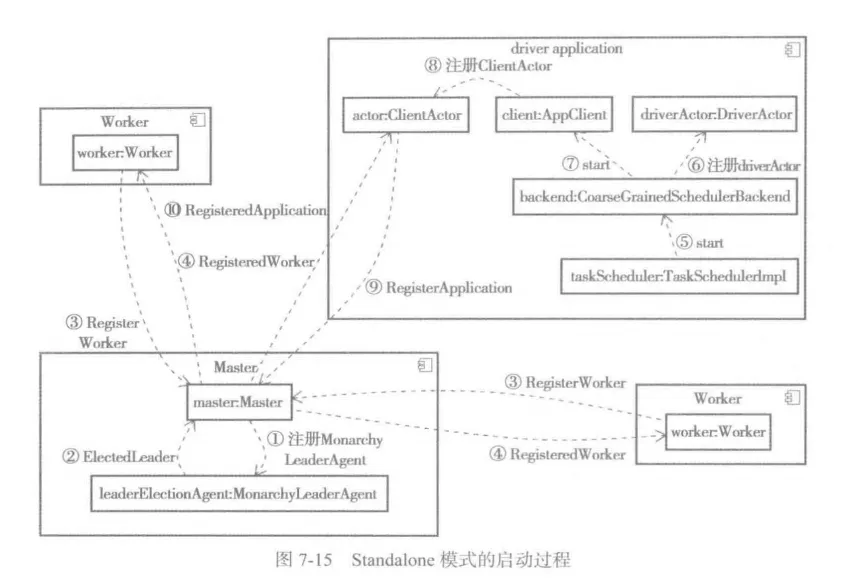
- 資源申請:Driver向Master申請Executor資源
- Executor啟動:Master調度Worker啟動Executor
- 注冊通信:Executor直接向Driver注冊
2、YARN
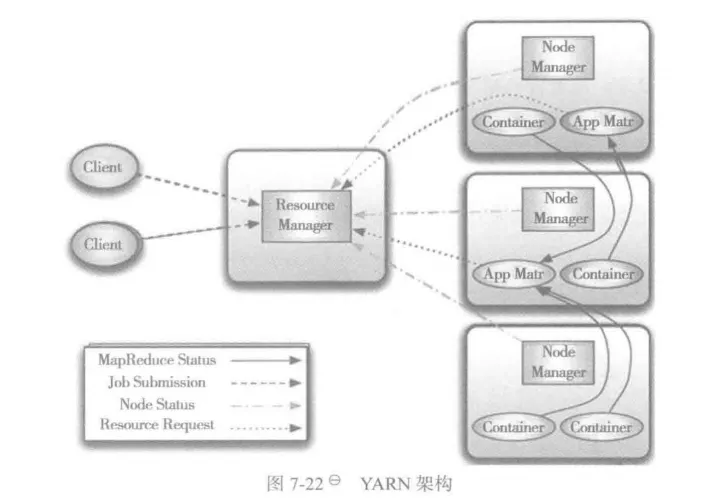
-
Driver向YARN ResourceManager(RM)申請AM容器
-
RM分配NodeManager(NM)啟動AM(yarn-client 僅資源代理,不運行用戶代碼)
-
AM向RM注冊
-
AM根據申請Executor容器
5.RM分配多個NM
6.每個NM啟動ExecutorBackend進程
**7.**注冊通信:Executor向AM內的Driver注冊
二、Executor端任務執行的核心組件
- Driver 端組件
- CoarseGrainedSchedulerBackend:負責與Executor通信
- TaskSchedulerImpl:任務調度核心邏輯
- DAGScheduler:DAG調度與Stage管理
- BlockManagerMaster:塊管理器協調器
- MapOutputTrackerMaster:Shuffle輸出跟蹤器
- Executor 端組件
- CoarseGrainedExecutorBackend:Executor的通信端點
- Executor:任務執行引擎
- TaskRunner:任務執行線程封裝
- BlockManager:本地數據塊管理
- ShuffleManager:Shuffle讀寫控制
- ExecutorSource:指標監控
三、Executor 端任務執行核心流程
1、任務接收與初始化
- CoarseGrainedExecutorBackend 接收任務
case LaunchTask(data) =>if (executor == null) {exitExecutor(1, "Received LaunchTask command but executor was null")} else {val taskDesc = TaskDescription.decode(data.value)logInfo(log"Got assigned task ${MDC(LogKeys.TASK_ID, taskDesc.taskId)}")executor.launchTask(this, taskDesc)}
Executor任務啟動
def launchTask(context: ExecutorBackend, taskDescription: TaskDescription): Unit = {val taskId = taskDescription.taskIdval tr = createTaskRunner(context, taskDescription)runningTasks.put(taskId, tr)val killMark = killMarks.get(taskId)if (killMark != null) {tr.kill(killMark._1, killMark._2)killMarks.remove(taskId)}threadPool.execute(tr)if (decommissioned) {log.error(s"Launching a task while in decommissioned state.")}}
2、任務執行
TaskRunner.run
// 1. 類加載與依賴管理
updateDependencies(taskDescription.artifacts.files,taskDescription.artifacts.jars,taskDescription.artifacts.archives,isolatedSession)
// 2. 反序列化任務
task = ser.deserialize[Task[Any]](taskDescription.serializedTask, Thread.currentThread.getContextClassLoader)
// 3. 內存管理
val taskMemoryManager = new TaskMemoryManager(env.memoryManager, taskId)
task.setTaskMemoryManager(taskMemoryManager)// 4. 任務執行
val value = Utils.tryWithSafeFinally {val res = task.run(taskAttemptId = taskId,attemptNumber = taskDescription.attemptNumber,metricsSystem = env.metricsSystem,cpus = taskDescription.cpus,resources = resources,plugins = plugins)threwException = falseres} {// block 釋放val releasedLocks = env.blockManager.releaseAllLocksForTask(taskId)// memory 釋放val freedMemory = taskMemoryManager.cleanUpAllAllocatedMemory()if (freedMemory > 0 && !threwException) {val errMsg = log"Managed memory leak detected; size = " +log"${LogMDC(NUM_BYTES, freedMemory)} bytes, ${LogMDC(TASK_NAME, taskName)}"if (conf.get(UNSAFE_EXCEPTION_ON_MEMORY_LEAK)) {throw SparkException.internalError(errMsg.message, category = "EXECUTOR")} else {logWarning(errMsg)}}if (releasedLocks.nonEmpty && !threwException) {val errMsg =log"${LogMDC(NUM_RELEASED_LOCKS, releasedLocks.size)} block locks" +log" were not released by ${LogMDC(TASK_NAME, taskName)}\n" +log" ${LogMDC(RELEASED_LOCKS, releasedLocks.mkString("[", ", ", "]"))})"if (conf.get(STORAGE_EXCEPTION_PIN_LEAK)) {throw SparkException.internalError(errMsg.message, category = "EXECUTOR")} else {logInfo(errMsg)}}}// 5. 狀態上報
execBackend.statusUpdate(taskId, TaskState.FINISHED, serializedResult)
- Task run
// hadoop.caller.context.enabled = true
// 添加 HDFS 審計日志 , 用于問題排查 。
// e.g. 小文件劇增 定位spark 任務
new CallerContext("TASK",SparkEnv.get.conf.get(APP_CALLER_CONTEXT),appId,appAttemptId,jobId,Option(stageId),Option(stageAttemptId),Option(taskAttemptId),Option(attemptNumber)).setCurrentContext()// 任務啟動
context.runTaskWithListeners(this)
3、shuffle處理
ShuffleMapTask
為下游 Stage 準備 Shuffle 數據(Map 端輸出),生成 MapStatus(包含數據位置和大小信息)。
val threadMXBean = ManagementFactory.getThreadMXBean
val deserializeStartTimeNs = System.nanoTime()
val deserializeStartCpuTime = if (threadMXBean.isCurrentThreadCpuTimeSupported) {threadMXBean.getCurrentThreadCpuTime
} else 0L
val ser = SparkEnv.get.closureSerializer.newInstance()
// 從廣播 序列化 rdd 、 dep
val rddAndDep = ser.deserialize[(RDD[_], ShuffleDependency[_, _, _])](ByteBuffer.wrap(taskBinary.value), Thread.currentThread.getContextClassLoader)
_executorDeserializeTimeNs = System.nanoTime() - deserializeStartTimeNs
_executorDeserializeCpuTime = if (threadMXBean.isCurrentThreadCpuTimeSupported) {threadMXBean.getCurrentThreadCpuTime - deserializeStartCpuTime
} else 0Lval rdd = rddAndDep._1
val dep = rddAndDep._2
// While we use the old shuffle fetch protocol, we use partitionId as mapId in the
// ShuffleBlockId construction.
val mapId = if (SparkEnv.get.conf.get(config.SHUFFLE_USE_OLD_FETCH_PROTOCOL)) {partitionId
} else {context.taskAttemptId()
}
dep.shuffleWriterProcessor.write(rdd.iterator(partition, context),dep,mapId,partitionId,context)
ResultTask
override def runTask(context: TaskContext): U = {// Deserialize the RDD and the func using the broadcast variables.val threadMXBean = ManagementFactory.getThreadMXBeanval deserializeStartTimeNs = System.nanoTime()val deserializeStartCpuTime = if (threadMXBean.isCurrentThreadCpuTimeSupported) {threadMXBean.getCurrentThreadCpuTime} else 0Lval ser = SparkEnv.get.closureSerializer.newInstance()val (rdd, func) = ser.deserialize[(RDD[T], (TaskContext, Iterator[T]) => U)](ByteBuffer.wrap(taskBinary.value), Thread.currentThread.getContextClassLoader)_executorDeserializeTimeNs = System.nanoTime() - deserializeStartTimeNs_executorDeserializeCpuTime = if (threadMXBean.isCurrentThreadCpuTimeSupported) {threadMXBean.getCurrentThreadCpuTime - deserializeStartCpuTime} else 0Lfunc(context, rdd.iterator(partition, context))
}
四、核心通信機制
| 消息類型 | 方向 | 內容 |
|---|---|---|
| RegisterExecutor | Executor→Driver | executorId, hostPort |
| RegisteredExecutor | Driver→Executor | 注冊成功確認 |
| LaunchTask | Driver→Executor | 序列化的TaskDescription |
| StatusUpdate | Executor→Driver | taskId, state, result data |
| KillTask | Driver→Executor | 終止指定任務 |
| StopExecutor | Driver→Executor | 關閉Executor指令 |
| Heartbeat | Executor→Driver | 心跳+指標數據 |
五、Executor 線程模型
Executor JVM Process
├── CoarseGrainedExecutorBackend (netty)
├── ThreadPool (CacheThreadPool)
│ ├── TaskRunner 1
│ ├── TaskRunner 2
│ └── ...
├── BlockManager
│ ├── MemoryStore (on-heap/off-heap)
│ └── DiskStore
└── ShuffleManager├── SortShuffleWriter└── UnsafeShuffleWriter



:發布)




)






——資料分析、數量(強化訓練))



