


MySQL(五)索引
一、索引的減I/O設計
1.讀取量
2.搜索樹
2.1方向
2.2有序
3.分多叉
3.1B樹
弊端:
3.2B+樹
3.2.1非葉子-搜索字段
3.2.1.1海量分叉
3.2.1.1.1最大式
3.2.1.1.2最快式
3.2.1.2緩存內存
3.2.1.2.1字段總量小
3.2.1.2.2時間復雜度
3.2.1.3區間搜索向下保留
3.2.1.3.1過程
3.2.1.3.2模式
3.2.1.3.3效果
3.2.2葉子-對應記錄
3.2.2.1全集鍵值對
3.2.2.2鏈表物理連續
3.2.2.3開鍵穩定查詢
二、索引的操作
1.查看
2.創建
2.1創建時機
2.2大表索引的創建
2.2.1直接創建過程
2.2.2危險性
2.2.3正確創建做法
3.刪除
索引 是以字段為鍵、記錄為值的 B+搜索樹
一、索引的減I/O設計
從硬盤搜索讀取 查詢記錄時,由于 一次硬盤讀取數據到內存的時間 是內存里操作數據時間的 10萬倍,MySQL通過 索引?數據結構的設計 減少了查詢記錄的硬盤I/O的次數
1.讀取量
保持著硬盤 單次最大讀取量-頁 最大量地進行讀取 以減少讀取I/O次數,每個B+搜索樹節點的存儲空間 是一個頁,即對應每次讀取完 一個B+搜索樹節點的 總頁存儲空間的內容量
2.搜索樹
2.1方向
在搜索樹中,查詢時 會避免遍歷地 每次往?正確范圍、正向增長搜索到概率 的方向進行搜索 直到最后搜索到 也會精確匹配
2.2有序
搜索樹結構?維護了 記錄值 以字段鍵的有序性,支持 以字段的范圍查詢記錄與 以字段的排序記錄
對比哈希表:?
哈希表雖然能實現 一次硬盤讀取 就可O(1)地查詢到記錄,但只能精確匹配,內部是 以哈希函數維護的?無序數組,無法范圍查詢,也無法進行排序
3.分多叉
在一次讀取的一個節點中 放多個排布搜索對象 分多叉 能一次更多對象的排布完、一次更多對象的搜索完、一次搜索接往到 更加細致確定的 范圍區間里來
3.1B樹
鍵值對 單位存儲
鍵值對?合空間 如果很小,節點可以直接 大量存儲鍵值對,每個節點 排布海量N個鍵值對?N+1次方地 向下分支排布搜索數據 來完成 海量鍵值對數據的 入樹的排布
弊端:
- 存儲少-> 排布少-分支少-樹高-I/O高
但在數據庫中,一個值記錄的空間很大,一個鍵字段的空間很小,鍵值對的合空間很大:
一個節點一個頁的存儲量 放不了多幾個鍵值對 排布分叉的,每個節點能存儲下來的排布數據少 向下分支少 向下搜索的區間廣?,需要往下分支很多次 才可分布排完數據,樹的高度會很高, 處在葉子節點的大部分鍵值對?要硬盤從頂層 多次讀取搜索到底層 才可搜索到,硬盤I/O總體會很高
-
記錄在全節點-> 不穩定
作為查詢搜索的結果的 鍵值對里的值記錄,與鍵一塊 直接存儲在 出現的樹節點中,少部分的 在非葉子節點的鍵值對 可以少量I/O地 往下讀取搜索到,大部分的在葉子節點的鍵值對 需要大量I/O地讀取到底層,查詢的時間開銷不穩定
3.2B+樹
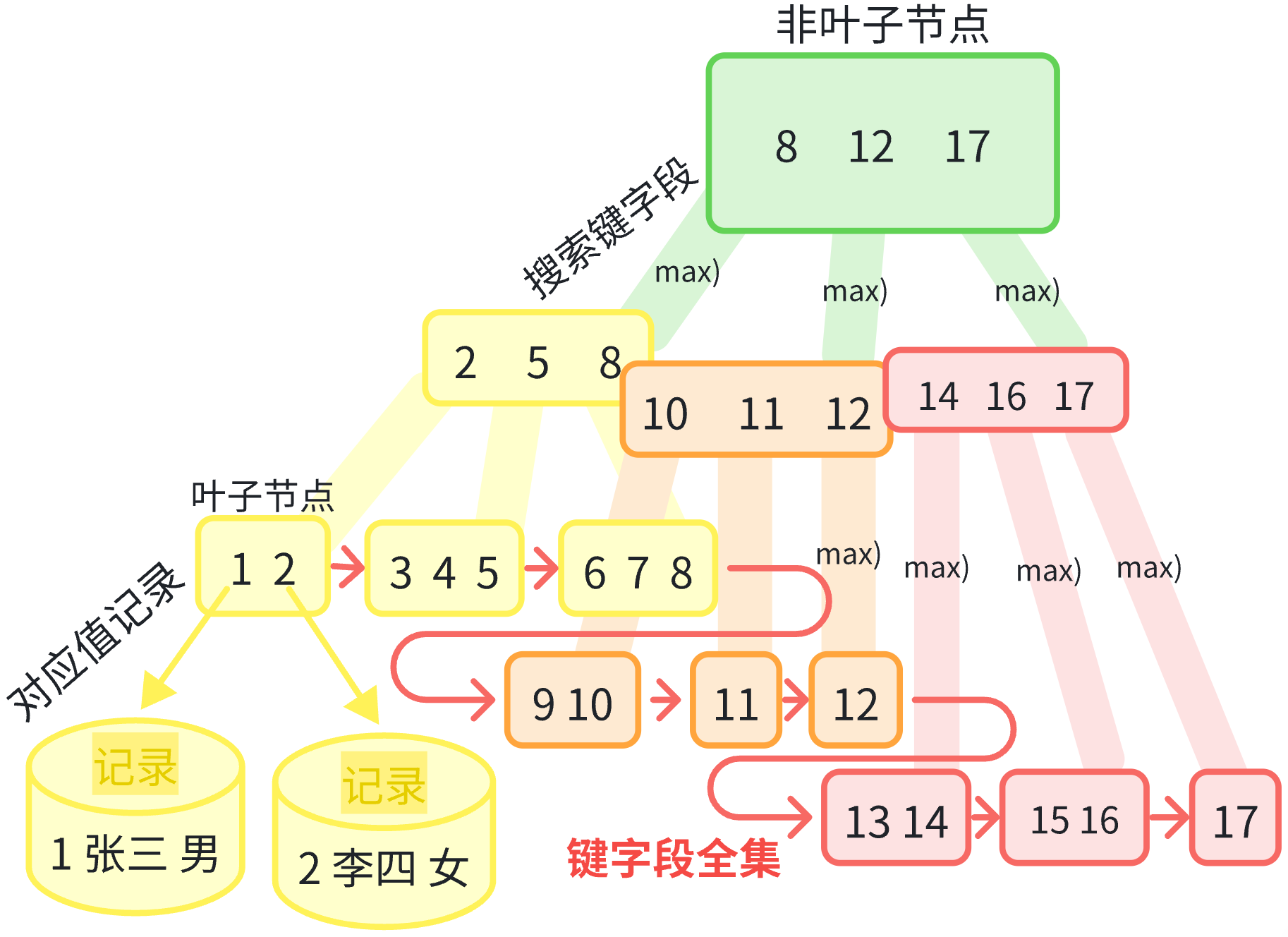
鍵與值 分開存儲
B+樹 針對數據庫里?值記錄空間很大,一個搜索樹節點 無法存下過多個鍵值對?去海量分叉排布,將鍵與值分開存儲,鍵在非葉子節點搜索,值在葉子節點對應
3.2.1非葉子-搜索字段
3.2.1.1海量分叉
3.2.1.1.1最大式
非葉子搜索階段 每個非葉子節點?只放無記錄值對應的 海量鍵字段,一個節點一個頁 就可最多放 多達1600個鍵字段地 大量排布搜索數據 細致劃出排往范圍 地搜索
3.2.1.1.2最快式
內存中 操作數據的速度雖然快,但一次從硬盤讀取到內存的數據 如果處理的單位個數過多,一時間內 內存里也無法快速比較完 個數過多的數據,所以每個節點 放1000個鍵字段 以1000的次方 向下分支排布 存儲搜索的數據,3層 對應3次硬盤讀取 就可排查地搜索完 分支排布到億級的 字段量
3.2.1.2緩存內存
3.2.1.2.1字段總量小
非葉子節點內的 億級總記錄個數的 字段量,由于字段的空間很小,能確保 所有全記錄對應的 字段總空間 是很小的,況且緩存只對非葉子節點?并未對分支到最后一層的葉子節點 的記錄里的 字段量進行緩存,所以非葉子節點里 也不會有 所有記錄個數對應的 總字段量 那么多,非葉子節點字段總空間很小 可以緩存到內存中的
3.2.1.2.2時間復雜度
首次查詢:
非葉子節點字段量 在首次查詢時 B+搜索樹高度次硬盤讀取?從硬盤 把此搜索樹的所有非葉子節點 全部讀取加載到緩存中存放
后續查詢:
在后續查詢時,非葉子節點的字段數據 都已加載在緩存內存中有 不用再硬盤讀取 直接繼續在緩存中 對字段進行搜索 常數時間,然后搜索出指定葉子節點后 再對存儲在硬盤的葉子節點鍵值對?硬盤讀取一次 固定一次硬盤I/O的常數時間,時間復雜度也就成了O(1)
3.2.1.3區間搜索向下保留
3.2.1.3.1過程
非葉子節點的所有鍵字段 都開區間地隱藏?搜索不到,每次對它們搜索完 都作為查詢的?可能的結果鍵 以子區間最大值的形式 往搜索子區間的N叉區域 分別向下傳遞
3.2.1.3.2模式
形成了非葉子節點的 只往區間搜索鍵、鍵字段數據向下保留傳遞的 搜索模式
3.2.1.3.3效果
到葉子節點時 整棵樹所有出現過的 父節點區間鍵?與整棵樹在葉子節點 最后剩余出的區間鍵 會構成整棵樹的 從左往右有序的 鍵字段全集
3.2.2葉子-對應記錄
3.2.2.1全集鍵值對
葉子節點層,鍵字段全集的葉子節點 對應存上值記錄 成全集的鍵值對
3.2.2.2鏈表物理連續
葉子節點之間 再左右相連地 連接成鏈表 使搜索樹邏輯上的有序 再套上了 物理相鄰存儲的有序,大大優化了磁盤I/O:
搜索樹 范圍查詢數值時,避免了B樹的 范圍查詢回溯節點的硬盤I/O時間開銷,而每到下一個連續數值的鏈表節點 就對應一次硬盤I/O
3.2.2.3開鍵穩定查詢
B+搜索樹都是在葉子節點閉鍵,鍵在葉子節點時?才可以去搜索查詢到的,查詢 會在且只能在 葉子節點搜索查詢到,固定了查詢的時間開銷
二、索引的操作
1.查看
show index from tb_name;show create table tb_name;查看表中所有的索引
2.創建
create index idx_name on tb_name(col);為表的指定列字段創建索引?,primary key、unique、foreign key字段 在創建表時 就會自動創建出索引維護
2.1創建時機
在表創建數據空時 或在表的數據量較小時 就要將 要創建的索引創建好
2.2大表索引的創建
2.2.1直接創建過程
為一個記錄量很大的表 創建指定字段的索引
第一層:
從創建的 第1個頂層根節點出發,每個節點里面 都有存儲1000個字段
第二層:
第二層 為第一層根節點里面存儲的1000個排布鍵 分出的1000個字段區域 往下為每個區域 分叉都創建一個 對分到的區域再次存儲有1000個排布鍵的 排布劃分的節點,因此第二層就共創建了1000個節點
第三層:
第三層 為第二層的1000個節點 每個節點 都會分叉1000個區域 每個區域 對應去創建存儲有1000個排布值的 1個節點,第三層就會總共去創建1000*1000個節點
第四層:
再往下層就會去創建1000*1000*1000個節點
第N層:
以1000的次方量 往下創建節點,直到葉子所有節點 總共存儲的字段 覆蓋字段全集時,該字段的B+搜索樹 才創建好
2.2.2危險性
工作量巨大,會使服務器 一時間全盤去創建索引的B+搜索樹 而呈掛機狀態
2.2.3正確創建做法
如果就要為一個海量數據的表 創建索引,正確的做法是:
- 在另一個mysql服務器上 創建相同結構的空表 創建索引
- 再將數據 控制量地 可正常維護索引地 導入建樹,B+搜索樹創建好索引創建好后
- 最后對服務器更換轉到使用 此索引創建好的 mysql服務器
3.刪除
drop index idx_name on tb_name;刪除表中的指定索引






![論文閱讀 2025-8-9 [DiC, DropKey]](http://pic.xiahunao.cn/論文閱讀 2025-8-9 [DiC, DropKey])







)
)



