深度學習的本質是用數學語言描述并處理真實世界中的信息,而線性代數正是這門語言的基石。它不僅提供了高效的數值計算工具,更在根本上定義了如何以可計算、可組合、可度量的方式表示和變換數據。
1 如何描述世界
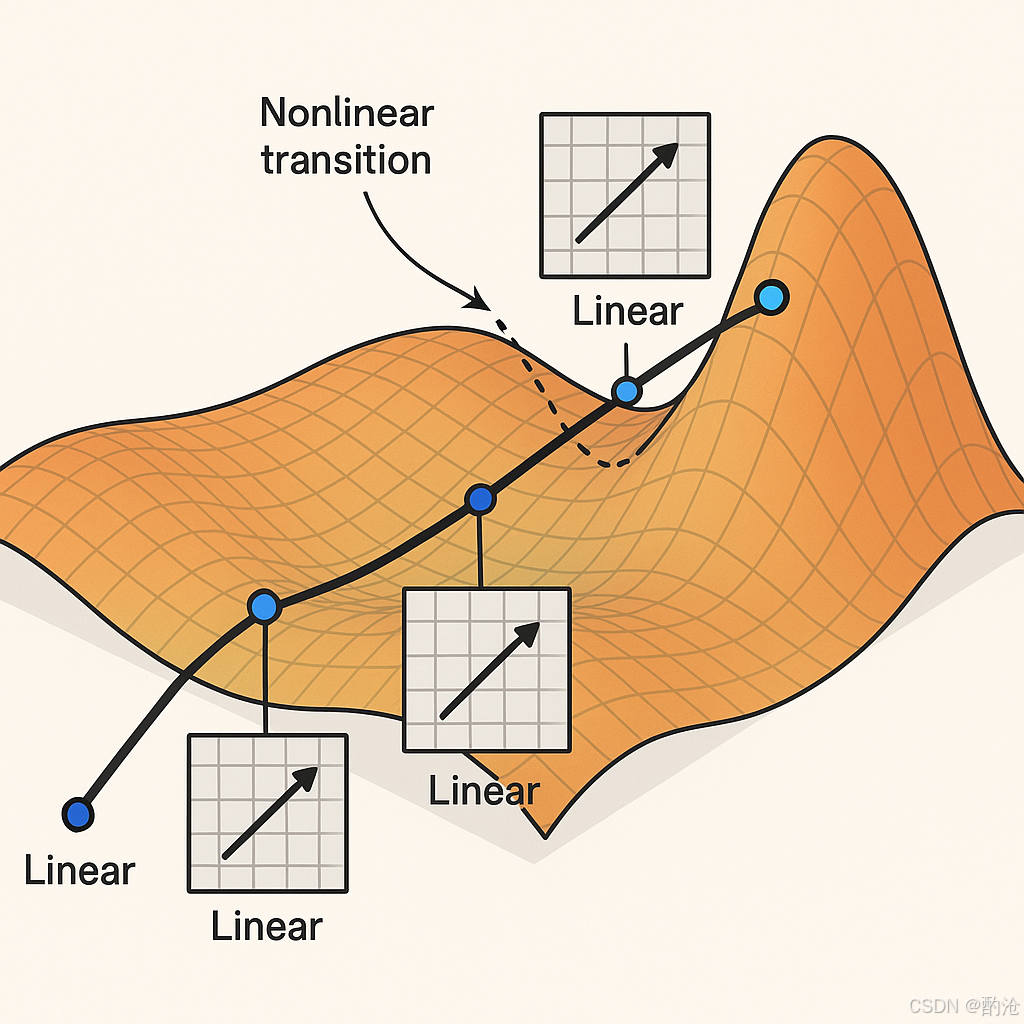
📊 真實世界的數據(圖片、語音、文本)分布在在一個像“地毯”一樣彎曲的表面上。你從入口出發,沿著地毯走到終點(比如從一張圖片走到“貓”這個標簽)。你的路線可能經過很多彎曲的部分,每段直線對應著矩陣乘法(線性變換),每個拐彎對應著非線性激活切換。這樣一路走下去,你就完成了一次從輸入到輸出的旅程,這個過程在神經網絡里就是推理。
深入思考
如果世界僅由數字構成,我們如何唯一地描述一幅圖像、一段語音,或一次梯度更新?答案必須同時滿足:可計算、可組合、可度量。這逼迫我們尋找能被算術閉包、向量空間運算、范數度量共同支持的載體:張量。在線性代數中,向量與矩陣便是這種載體的最簡形態。深度學習把世界的結構落在三件事上:可計算(能被有限步算子執行)、可組合(小模塊可堆疊)、可度量(相似/距離可定義)。能同時滿足三者并與現代硬件高效耦合的,正是向量空間與線性映射。
📊 如果世界僅由數字構成,我們如何唯一地描述一幅圖像、一段語音,或一次梯度更新?答案必須同時滿足:可計算、可組合、可度量。這逼迫我們尋找能被算術閉包、向量空間運算、范數度量共同支持的載體:張量。深度學習把世界的結構落在三件事上:可計算(能被有限步算子執行)、可組合(小模塊可堆疊)、可度量(相似/距離可定義)
2 基礎元素-標量
標量:度量世界的起點,只含大小
標量是一維空間中的基本元素,只擁有大小而無方向。例如溫度、學習率等均是標量。
- 記號:普通小寫 xxx,定義域 x∈Rx \in \mathbb{R}x∈R
- 代碼示例:
torch.tensor(3.0)
標量在深度學習中通常用作超參數或單一輸出(如分類概率),為更高階的數據表示提供度量基準。
3 基礎元素-向量
向量:信息的緊湊表達,有方向與幅值
向量通過有序的標量集合形成,擁有大小與方向,能高效地描述多維狀態。
- 記號:粗體小寫 x,維度為 nnn,即 x ∈ ??
- 實踐用途:用戶畫像、一幀心電圖、詞嵌入等
- 代碼示例:
torch.arange(4)→tensor([0,1,2,3])
向量通過維度的長度直觀表示信息量,成為深度學習模型輸入特征的基本單位。
4 基礎元素-矩陣
矩陣:批量運算的萬能載體,向量的有序集合
矩陣是一組向量的集合,以二維表格形式表達數據。
-
記號:粗體大寫 A ∈ ?^{m×n},其中行代表樣本,列代表特征。
-
常用操作:轉置 ATA^TAT、索引 A[i,j]A[i,j]A[i,j]、對稱性檢查 A=ATA = A^TA=AT
-
代碼示例:權重矩陣的批量處理
矩陣實現了數據批量處理,讓深度學習模型高效利用 GPU 并行計算能力。
5 基礎元素-張量
張量:多維數據的統一表達
張量是矩陣概念的自然延伸,能表示任意維度的數據結構。
- 舉例:3D 圖像 (C,H,W),視頻 (T,C,H,W)
- 代碼示例:
torch.arange(24).reshape(2,3,4)
張量在深度學習框架中具有一等地位,支持廣播、切片、視圖變換等操作,讓數據與算法自然融合。
6 核心運算-Hadamard積
Hadamard 積:特征的高效交互
Hadamard 積指兩個同形狀張量逐元素相乘,捕捉特征間的局部交互。
- 記號:A⊙BA \odot BA⊙B
- GPU 并行高效實現:
A * B - 實踐示例:在推薦系統中,用戶向量與物品向量逐元素相乘,以快速捕捉用戶偏好。
7 核心運算-降維
降維:聚焦重要信息
降維技術通過沿某一軸匯總(如求和或平均)來減少數據冗余,突出關鍵信息。
- 常見操作:
A.sum(axis=0)、mean、cumsum - 實踐示例:卷積神經網絡中的全局平均池化,壓縮圖像特征。
8 核心運算-點積
點積:相似度度量之基石
向量點積通過累加逐元素乘積來量化向量間的相似性。
- 公式:x?y=∑xiyix \cdot y = \sum x_i y_ix?y=∑xi?yi?
- 應用實例:注意力機制、Word2Vec、余弦相似度
- 代碼示例:
torch.dot(x,y) - 實踐示例:在搜索引擎中,利用余弦相似度衡量文檔與查詢詞的相關性。
9 核心運算-矩陣向量乘法
矩陣-向量乘法:快速線性變換
矩陣-向量乘積(Ax)實現了高效的線性變換。
- 代碼示例:
torch.mv(A,x) - 實踐示例:神經網絡全連接層將輸入特征映射到隱藏層。
10 核心運算-矩陣矩陣乘法
矩陣-矩陣乘法:批量線性映射
矩陣-矩陣乘法(AB)可視作一系列矩陣-向量乘法的集合。
- 形狀要求:A(n×k)?B(k×m)=C(n×m)A(n \times k) \cdot B(k \times m) = C(n \times m)A(n×k)?B(k×m)=C(n×m)
- 代碼示例:
torch.mm(A,B) - 實踐示例:Transformer 模型中多頭注意力機制的批量計算。
11 核心運算-高維張量運算
在實際神經網絡中,我們往往需要對多個矩陣進行批量乘法,例如:
A = torch.randn(3, 3, 2) # 3個[3x2]矩陣
B = torch.randn(3, 2, 4) # 3個[2x4]矩陣
C = torch.matmul(A, B) # -> C.shape = [3, 3, 4]
每組進行 [3,2] × [2,4] 的矩陣乘法,最終得到 3 個 [3,4] 的矩陣,結果為 [3, 3, 4]。
僅最后兩維按矩陣乘法計算:[…, m, k] @ […, k, n] -> […, m, n]。其余前綴維度 廣播對齊。
12 廣播機制
從右向左對齊維度,兩個維度相等,或其中一個為 1,才允許廣播。常見廣播是用于加偏置(行向量/列向量)。
a = torch.empty(3, 3, 2)
b = torch.empty(2, 4)
result = a @ b # 自動廣播為 [3, 3, 4]
a.shape = [3, 3, 2]b.shape = [2, 4]→ 自動變成[1, 2, 4]→ 廣播成[3, 2, 4]- 執行
[3,3,2] @ [3,2,4] = [3,3,4]
13 核心運算-范數
范數:度量數據差異的標尺
范數為向量提供了量身定制的度量工具,直觀表示向量的大小和稀疏性。
-
L2 范數 ∥x∥2\|x\|_2∥x∥2?:歐式距離與正則化。
-
L1 范數 ∥x∥1\|x\|_1∥x∥1?:強調稀疏性,對異常數據更魯棒。
-
實踐示例:L2 正則化在神經網絡訓練中防止過擬合。
綜上,線性代數以向量、矩陣、張量等核心概念為工具,深刻且全面地支撐了深度學習從數據表達到模型訓練的全過程,成為了所有AI技術發展的根本語言與方法論。





)

)!)




)


![第十六屆藍橋杯青少組C++省賽[2025.8.10]第二部分編程題(6、魔術撲克牌排列)](http://pic.xiahunao.cn/第十六屆藍橋杯青少組C++省賽[2025.8.10]第二部分編程題(6、魔術撲克牌排列))



)