論文鏈接:SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
官方實現:Stability-AI/generative-models
非官方實現:huggingface/diffusers
Stable Diffusion XL (SDXL) 是 Stablility AI 對 Stable Diffusion 進行改進的工作,主要通過一些工程化的手段提高了 SD 模型的生成能力。相比于 Stable Diffusion,SDXL 對模型架構、條件注入、訓練策略等都進行了優化,并且還引入了一個額外的 refiner,用于對生成圖像進行超分,得到高分辨率圖像。
Stable Diffusion XL
模型架構改進
SDXL 對模型的 VAE、UNet 和 text encoder 都進行了改進,下面依次介紹一下。
VAE
相比于 Stable Diffusion,SDXL 對 VAE 模型進行了重新訓練,訓練時使用了更大的 batchsize(256,Stable Diffusion 使用的則是 9),并且使用了指數移動平均,得到了性能更強的 VAE。
需要注意的是,SD 2.x 的 VAE 相對 SD 1.x 只對 decoder 進行了微調,而 encoder 不變。因此兩者的 latent space 是相同的,VAE 可以互相交換使用。但 SDXL 對 encoder 也進行了微調,因此 latent space 發生了變化,SDXL 不能用 SD 的 VAE,SD 也不能用 SDXL 的 VAE。另外,由于 SDXL 的 VAE 在 fp16 下會發生溢出,所以其必須在 fp32 類型下進行推理。
UNet
SDXL 使用了更大的 UNet 模塊,具體來說做了以下幾個變化:
- 為了提高效率,使用了更少的 3 個 stage,而不是 SD 使用的 4 個 stage;
- 將 transformer block 移動到更深的 stage,第一個 stage 沒有 transformer block;
- 使用更多的 transformer block。
詳情可以看下邊的表格,可以看到第二個 stage 和第三個 stage 分別使用了 2 個和 10 個 transformer block,最后 UNet 的整體參數量變成了大約 3 倍。
| 模型 | SDXL | SD1.4/1.5 | SD 2.0/2.1 |
|---|---|---|---|
| UNet 參數量 | 2.6 B | 860 M | 865 M |
| Transformer block 數量 | [0, 2, 10] | [1, 1, 1, 1] | [1, 1, 1, 1] |
| 通道倍增系數 | [1, 2, 4] | [1, 2, 4, 4] | [1, 2, 4, 4] |
Text Encoder
SDXL 還使用了更強的 text encoder,其同時使用了 OpenCLIP ViT-bigG 和 OpenAI CLIP ViT-L,使用時同時用兩個 encoder 處理文本,并將倒數第二層特征拼接起來,得到一個 1280+768=2048 通道的文本特征作為最終使用的文本嵌入。
除此之外,SDXL 還使用 OpenCLIP ViT-bigG 的 pooled text embedding 映射到 time embedding 維度并與之相加,作為輔助的文本條件注入。
其與 SD 1.x 和 2.x 的比較如下表所示:
| 模型 | SDXL | SD 1.4/1.5 | SD 2.0/2.1 |
|---|---|---|---|
| 文本編碼器 | OpenCLIP ViT-bigG & CLIP ViT-L | CLIP ViT-L | OpenCLIP ViT-H |
| 特征通道數 | 2048 | 768 | 1024 |
| Pooled text emb. | OpenCLIP ViT-bigG | N/A | N/A |
Refine Model
除了上述結構變化之外,SDXL 還級聯了一個 refine model 用來細化模型的生成結果。這個 refine model 相當于一個 img2img 模型,在模型中的位置如下所示:
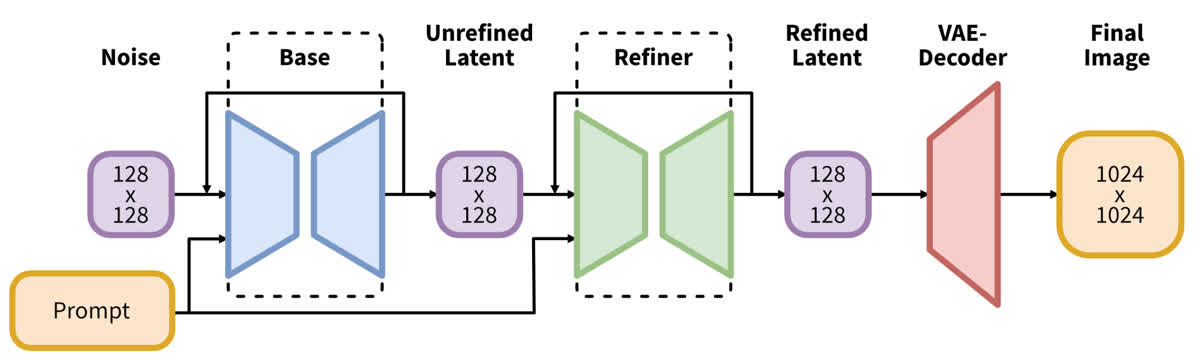
這個 refine model 的主要目的是進一步提高圖像的生成質量。其是單獨訓練的,專注于對高質量高分辨率數據的學習,并且只在比較低的 noise level 上(即前 200 個時間步)進行訓練。
在推理階段,首先從 base model 完成正常的生成過程,然后再加一些噪音用 refine model 進一步去噪。這樣可以使圖像的細節得到一定的提升。
Refine model 的結構與 base model 有所不同,主要體現在以下幾個方面:
- Refine model 使用了 4 個 stage,特征維度采用了 384(base model 為 320);
- Transformer block 在各個 stage 的數量為 [0, 4, 4, 0],最終參數量為 2.3 B,略小于 base model;
- 條件注入方面:text encoder 只使用了 OpenCLIP ViT-bigG;并且同樣也使用了尺寸和裁剪的條件注入(這個下文會講);除此之外還使用了 aesthetic score 作為條件。
條件注入的改進
SDXL 引入了額外的條件注入來改善訓練過程中的數據處理問題,主要包括圖像尺寸和圖像裁剪問題。
圖像尺寸條件
Stable Diffusion 的訓練通常分為多個階段,先在 256 分辨率的數據上進行訓練,再在 512 分辨率的數據上進行訓練,每次訓練時需要過濾掉尺寸小于訓練尺寸的圖像。根據統計,如果直接丟棄所有分辨率不足 256 的圖像,會浪費大約 40% 的數據。如果不希望丟棄圖像,可以使用超分辨率模型先將圖像超分到所需的分辨率,但這樣會導致數據質量的降低,影響訓練效果。
為了解決這個問題,作者加入了一種額外的圖像尺寸條件注入。作者將原圖的寬高進行傅立葉編碼,然后將特征拼接起來加到 time embedding 上作為額外條件。
在訓練時直接使用原圖的寬高作為條件,推理的時候可以自定義寬高,生成不同質量的圖像,下面的圖是一個例子,可以看到當以較小的尺寸為條件時,生成的圖比較模糊,反之則清晰且細節更豐富:

圖像裁剪條件
在 SD 訓練時使用的是固定尺寸(例如 512x512),使用時需要對原圖進行處理。一般的處理流程是先 resize 到短邊為目標尺寸,然后沿著長邊進行裁剪。這種裁剪會導致圖像部分缺失的問題,例如生成的圖像部分會出現部分缺失,就是因為裁剪后的數據是不完整的。
為了解決這個問題,SDXL 在訓練時把裁剪位置的坐標也當作條件注入進來。具體做法是把左上角的像素坐標值也進行傅立葉編碼+拼接,再加到 time embedding 上,這樣模型就能得知使用的數據是在什么位置進行的裁剪。
在推理階段,只需要將這個條件設置為 (0, 0) 即可得到正常圖像。如果設置成其他的值則能得到裁剪圖像,例如下邊圖里的效果。(感覺還是很神奇的,竟然這種條件能 work,而且沒有和圖像尺寸的條件混淆)

訓練策略的改進
多比例微調
在訓練階段使用的都是正方形圖像,但是現實圖像很多都是有一定的長寬比的圖像。因此在訓練后的微調階段,還使用了一種多比例微調的策略。
具體來說,這種方法預先將訓練集按照圖像長寬比不同分成多個 bucket,在微調時每次隨機選取一個 bucket,并從中采樣出一個 batch 的數據進行訓練。在原論文中給出了一個表格,從表中可以看到選取的長寬比從 0.25(對應 512×2048512\times2048512×2048 分辨率) 到 4(對應 2048×5122048\times5122048×512 分辨率)不等,并且總像素數基本都維持在 102421024^210242 左右。
在這個微調階段,除了使用尺寸和裁剪條件注入,還使用了 bucket size(也就是生成的目標大小) 作為一個條件,用相同的方式進行了注入。經過這樣的條件注入和微調,模型就能生成多種長寬比的圖像。
Noise Offset
在多比例微調的階段,SDXL 還使用了一種 noise offset 的方法,來解決 SD 只能生成中等亮度圖像、而無法生成純黑或者純白圖像的問題。這個問題出現的原因是在訓練和采樣階段之間存在一定的 bias,訓練時在最后一個時間步的時候實際上是沒有加噪的,所以會出現一些問題,解決方案也比較簡單,就是在訓練的時候給噪聲添加一個比較小的 offset 即可。
SDXL 代碼解析
這里依然以 diffusers 提供的訓練代碼為主進行分析,模型架構的改變主要體現在加載的預訓練模型中(之后應該會出一期怎么看 huggingface 里的那些文件以及 config.json 的教程),這里主要分析一下各種條件注入和訓練策略是怎么實現的。
各種條件注入
首先是尺寸和裁剪的條件注入,在圖像進行預處理的階段就記錄下了每張圖的原始尺寸以及裁剪位置:
def preprocess_train(examples):images = [image.convert("RGB") for image in examples[image_column]]original_sizes = []all_images = []crop_top_lefts = []for image in images:# 在這里記錄原始尺寸original_sizes.append((image.height, image.width))# 調整圖片大小image = train_resize(image)# 以 0.5 的概率進行隨機翻轉if args.random_flip and random.random() < 0.5:image = train_flip(image)# 進行裁剪if args.center_crop:y1 = max(0, int(round((image.height - args.resolution) / 2.0)))x1 = max(0, int(round((image.width - args.resolution) / 2.0)))image = train_crop(image)else:y1, x1, h, w = train_crop.get_params(image, (args.resolution, args.resolution))image = crop(image, y1, x1, h, w)# 在這里記錄裁剪位置crop_top_left = (y1, x1)crop_top_lefts.append(crop_top_left)image = train_transforms(image)all_images.append(image)examples["original_sizes"] = original_sizesexamples["crop_top_lefts"] = crop_top_leftsexamples["pixel_values"] = all_imagesreturn examples
隨后原始尺寸和裁剪位置被進行編碼,可以看到下邊這部分包含了三部分的條件注入:
def compute_time_ids(original_size, crops_coords_top_left):target_size = (args.resolution, args.resolution)# 包括三部分的條件注入,分別為:# 1. 原始尺寸;2. 裁剪位置;3. 目標尺寸add_time_ids = list(original_size + crops_coords_top_left + target_size)add_time_ids = torch.tensor([add_time_ids])add_time_ids = add_time_ids.to(accelerator.device, dtype=weight_dtype)return add_time_idsadd_time_ids = torch.cat([compute_time_ids(s, c) for s, c in zip(batch["original_sizes"], batch["crop_top_lefts"])]
)
最后把 pooled prompt embedding 也加入進來:
unet_added_conditions = {"time_ids": add_time_ids}
unet_added_conditions.update({"text_embeds": pooled_prompt_embeds})
這樣四種條件注入就都準備好了,在 forward 時直接傳到 UNet 的 added_cond_kwargs 參數即可參與計算。這些參數在 get_aug_embed 中被組合起來添加到 time embedding 上:
# pooled text embedding
text_embeds = added_cond_kwargs.get("text_embeds")
# 1. 原始尺寸;2. 裁剪位置;3. 目標尺寸
time_ids = added_cond_kwargs.get("time_ids")
# 處理得到最終加到 time embedding 上的條件嵌入
time_embeds = self.add_time_proj(time_ids.flatten())
time_embeds = time_embeds.reshape((text_embeds.shape[0], -1))
add_embeds = torch.concat([text_embeds, time_embeds], dim=-1)
add_embeds = add_embeds.to(emb.dtype)
aug_emb = self.add_embedding(add_embeds)
在上邊的代碼里用到了兩個對象 self.add_time_proj 和 self.add_embedding,定義為:
self.add_time_proj = Timesteps(addition_time_embed_dim, flip_sin_to_cos, freq_shift)
self.add_embedding = TimestepEmbedding(projection_class_embeddings_input_dim, time_embed_dim)
這兩個對象中,Timesteps 應該是負責傅立葉編碼,TimestepEmbedding 則負責對編碼后的結果進行嵌入。
Noise Offset
這個實現很簡單,就在加噪前對 noise 隨機偏移一下即可:
if args.noise_offset:# https://www.crosslabs.org//blog/diffusion-with-offset-noisenoise += args.noise_offset * torch.randn((model_input.shape[0], model_input.shape[1], 1, 1), device=model_input.device)
多尺度微調
根據我的觀察,diffusers 里沒有直接提供多尺度微調相關的代碼,應該是默認在訓練之前已經自行處理好了各個 bucket 的圖像。印象中前段時間某個組織開源了一份分 bucket 的代碼,不過因為當時沒保存所以現在找不到了,能找到的主要是 kohya-ss/sd-scripts 的一個實現。
大體的原理是先創建一系列桶,然后對于每張圖片,選擇長寬比最接近的一個桶,然后進行裁剪,裁剪到和這個桶對應的分辨率相同。由于相鄰兩個桶之間的分辨率之差為 64,所以最多裁剪 32 像素,對訓練的影響并不大。在將圖片分桶之后,則可以按照每個桶的數據比例作為概率進行采樣。如果某些桶中的數據量不足一個 batch,則把這個桶中的數據都放入一個公共桶中,并以標準的 1024×10241024\times10241024×1024 分辨率進行訓練。
如果讀者有興趣自己閱讀代碼,可以先看 library.model_util 模塊中的 make_bucket_resolutions,這個方法創建了一系列分辨率的 bucket,并在 library.train_util.BucketManager 中調用,用來創建 bucket。這個 BucketManager 提供了一個方法 select_bucket,用來為某個特定分辨率的圖像選擇 bucket。最后在 library.train_util.BaseDataset 中,會對每張圖片調用 select_bucket 選擇 bucket,再將對應的圖片加入到選擇的 bucket 中。
總結
感覺 SDXL 是一個比較工程的工作,尤其是對模型架構的修改,比較大力出奇跡。除此之外感覺對數據的理解還是很重要的,除了修改模型架構之外的其他工作都是圍繞著數據展開的,這也是比較值得學習的思路。
參考資料:
- 深入淺出完整解析Stable Diffusion XL(SDXL)核心基礎知識
- 擴散模型(七)| SDXL
本文原文以 CC BY-NC-SA 4.0 許可協議發布于 筆記|擴散模型(一一):Stable Diffusion XL 理論與實現,轉載請注明出處。

)







![[vibe coding-lovable]lovable是不是ai界的復制忍者卡卡西?](http://pic.xiahunao.cn/[vibe coding-lovable]lovable是不是ai界的復制忍者卡卡西?)

)







