1. LangGraph圖結構概念說明
??在以圖構建的框架中,任何可執行的功能都可以作為對話、代理或程序的啟動點。這個啟動點可以是大模型的 API 接口、基于大模型構建的 AI Agent,通過 LangChain 或其他技術建立的線性序列等等,即下圖中的 “Start” 圓圈所示。無論哪種形式,它都首先處理用戶的輸入,并決定接下來要做什么。下圖展示了在 LangGraph 概念下,最基本的一種代理模型:👇
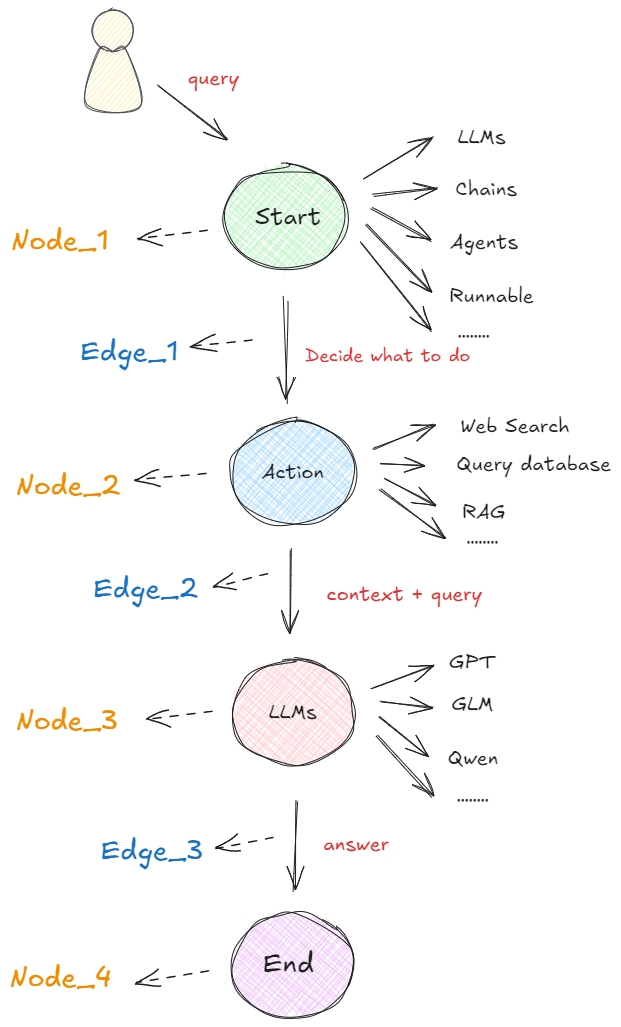
??如上圖所示,在啟動點定義的可運行功能會根據收到的輸入決定是否進行檢索以及如何響應。 比如在執行過程中,如果需要檢索信息,則可以利用搜索工具來實現,如Web Search(網絡搜索)、Query Database(查詢數據庫)、RAG等獲取必要的信息(圖中的 “Action” 圓圈)。接下來,再使用一個大語言模型(“LLM”)處理工具提供的信息,結合用戶最初傳入的初始查詢,生成最終的響應(圖中的 “LLMs” 圓圈)。最終,這個響應被傳遞至終點節點(圖中的 “End” 圓圈)。
??這個流程就是在LangGraph框架中一個非常簡單的代理構成形式。非常關鍵且我們必須清楚的概念是:每個圓圈代表一個“節點”(Nodes),每個箭頭表示一條“邊”(Edges)。在 LangGraph 中,無論代理的構建是簡單還是復雜,它最終都是由節點和邊通過特定的組合形成的圖。這樣的構建形式形成的工作流原理就是:當每個節點完成工作后,通過邊告訴下一步該做什么,所以也就得出了:LangGraph的底層圖算法就是在使用消息傳遞來定義通用程序。當節點完成其操作時,它會沿著一條或多條邊向其他節點發送消息。然后,這些接收節點執行其功能,將結果消息傳遞給下一組節點,然后該過程繼續。如此循環往復。
??這就是LangGraph底層架構設計中圖算法的根本思想。
??LangGraph框架是通過組合Nodes和Edges去創建復雜的循環工作流程,通過消息傳遞的方式串聯所有的節點形成一個通路。那么維持消息能夠及時的更新并向該去的地方傳遞,則依賴langGraph構建的State概念。 在LangGraph構建的流程中,每次執行都會啟動一個狀態,圖中的節點在處理時會傳遞和修改該狀態。這個狀態不僅僅是一組靜態數據,而是由每個節點的輸出動態更新,然后影響循環內的后續操作。如下所示:👇
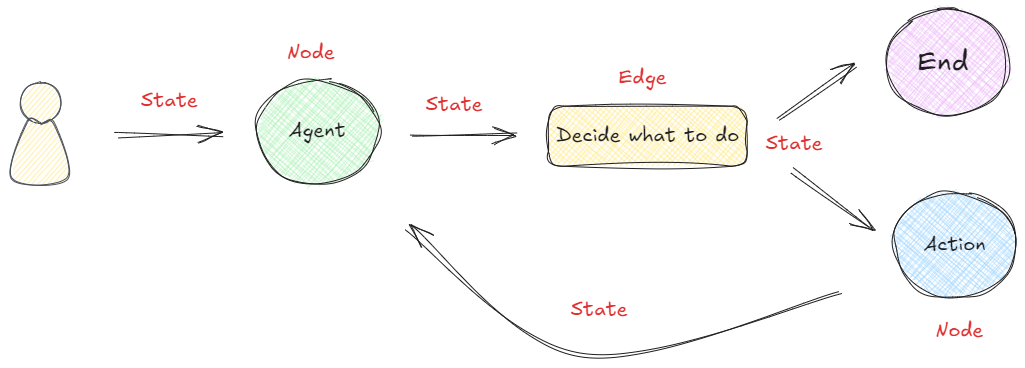
??為了幫助大家更好的理解,我們先嘗試在不接入大模型的情況下,構建一個如上圖所示的簡單工作流。
2.手動構建圖流程
??定義圖時要做的第一件事是定義圖的State。狀態表示會隨著圖計算的進行而維護和更新的上下文或記憶。它用來確保圖中的每個步驟都可以訪問先前步驟的相關信息,從而可以根據整個過程中積累的數據進行動態決策。這個過程通過狀態圖StateGraph類實現,它是由LangGraph框架提供的核心類之一,專門用來創建state狀態。
構建state的方法非常簡答。我們可以將圖的狀態設計為一個字典,用于在不同節點間共享和修改數據,然后使用StateGraph類進行圖的實例化。代碼如下:
pip install langgraph -i https://pypi.tuna.tsinghua.edu.cn/simple
pip show langgraph
from langgraph.graph import StateGraph# 使用 stategraph 接收一個字典
builder = StateGraph(dict)
這里需要注意的是,builder也是后面要用到的圖構建器(Graph Builder)對象,用于逐步添加節點、邊、控制流邏輯,最終編譯成可執行的 LangGraph 圖。而這個圖構建器需要通過帶入一個狀態對象來創建。
??接下來,定義兩個節點。addition節點是一個加法邏輯,接收當前狀態StateGraph(dict),將字典中x的值增加1,并返回新的狀態。而subtraction節點是一個減法邏輯,接收從addition節點傳來的狀態StateGraph(dict),從字典中的x值減去2,創建并返回一個新的鍵y。代碼如下:
def addition(state):# 注意:這里接收到的是初始狀態print(f"init_state: {state}")return {"x": state["x"] + 1}def subtraction(state):# 注意:這里接收到的是上一個節點的狀態print(f"addition_state: {state}")return {"x": state["x"] - 2}
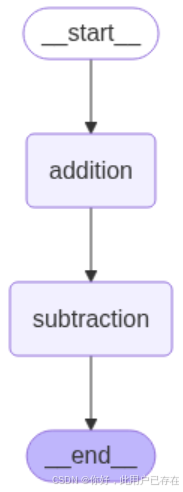
??然后,進行圖結構的設計。具體來看,我們添加名為addition和subtraction的節點,并關聯到上面定義的函數。設定圖的起始節點為addition,并從addition到subtraction設置一條邊,最后從subtraction到結束節點設置另一條邊。代碼如下:
# START 和 END 是兩個特殊的節點,分別表示圖的開始和結束。
from langgraph.graph import START, END# 向圖中添加兩個節點
builder.add_node("addition", addition)
builder.add_node("subtraction", subtraction)# 構建節點之間的邊
builder.add_edge(START, "addition")
builder.add_edge("addition", "subtraction")
builder.add_edge("subtraction", END)
??最后,執行圖的編譯。需要通過調用compile()方法將這些設置編譯成一個可執行的圖。代碼如下所示:
graph = builder.compile()
??除了上述通過打印的方式查看構建圖的結構,LangGraph還提供了多種內置的圖形可視化方法,能夠將任何Graph以圖形的形式展示出來,幫助我們更好地理解節點之間的關系和流程的動態變化。可視化最大的好處是:直接從代碼中生成圖形化的表示,可以檢查圖的執行邏輯是否符合構建的預期。
pip install pyppeteer ipython -i https://pypi.tuna.tsinghua.edu.cn/simple
??生成圖結構的可視化非常直接。具體代碼如下:
png_data = graph.get_graph(xray=True).draw_mermaid_png()with open("graph.png", "wb") as f:f.write(png_data)display(Image("graph.png"))
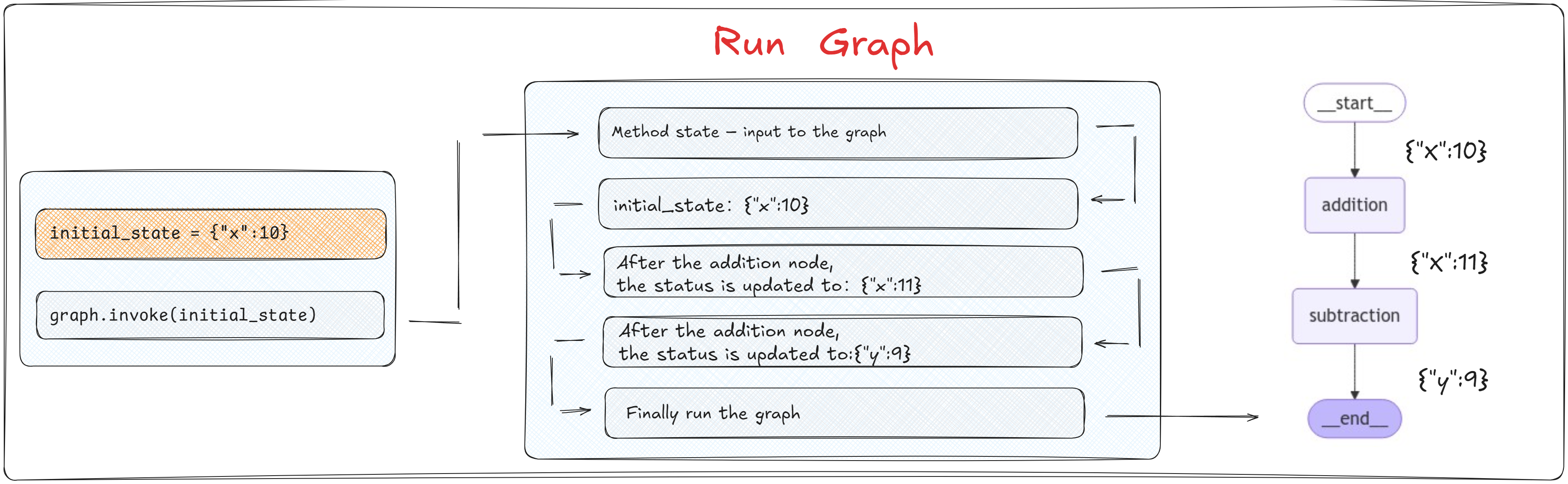
當通過 builder.compile() 方法編譯圖后,編譯后的 graph 對象提供了 invoke 方法,該方法用于啟動圖的執行。我們可以通過 invoke 方法傳遞一個初始狀態(如 initial_state = {"x": 10}),這個狀態將作為圖執行的起始輸入。代碼如下:
# 定義一個初始化的狀態
initial_state = {"x":10}graph.invoke(initial_state)
LangGraph 的執行模型并不強制要求圖中必須有 END 節點。只要執行路徑在某個節點“無后繼邊”(即到達“終點”),那么該節點就被視為隱式終點。
也就是說,將一個字典作為狀態對象帶入到圖中,即可進行圖的實際運行。
??在圖的執行過程中,每個節點的函數會被調用,并且接收到前一個節點返回的狀態作為輸入。每個函數處理完狀態后,會輸出一個新的狀態,傳遞給下一個節點。
??上述代碼執行過程中圖的運行狀態如下圖所示:👇
這里需要注意的一個關鍵信息是:節點函數不需要返回整個狀態,而是僅返回它們更新的部分。 也就是說:在每個節點的函數內部邏輯中,需要使用和更新哪些State中的參數中,只需要在return的時候指定即可,不必擔心未在當前節點處理的State中的其他值會丟失,因為LangGraph的內部機制已經自動處理了狀態的合并和維護。
# 定義一個初始化的狀態
initial_state = {"x":10, "y": 9}graph.invoke(initial_state)
??總體來看,該圖設置了一個簡單的工作流程。其中值首先在第一個節點通過加法函數增加,然后在第二個節點通過減法函數減少。這一流程展示了節點如何通過圖中的共享狀態進行交互。需要注意的是,狀態在任何給定時間只包含來自一個節點的更新信息。這意味著當節點處理狀態時,它只能訪問與其特定操作直接相關的數據,從而確保每個節點的邏輯是隔離和集中的。 使用字典作為狀態模式非常簡單,由于缺乏預定義的模式,節點可以在沒有嚴格類型約束的情況下自由地讀取和寫入狀態,這樣的靈活性有利于動態數據處理。 然而,這也要求開發者在整個圖的執行過程中保持對鍵和值的一致性管理。因為如果在任何節點中嘗試訪問State中不存在的鍵,會直接中斷整個圖的運行狀態。
3. 借助Pydantic對象創建圖
??Pydantic 是一個用于創建“數據模型”的 Python 庫,它可以自動校驗數據類型,并將字典數據轉換為結構化對象。它就像是給字典加了一個“類型安全 + 自動驗證”的外殼,是現代 Python 項目中最主流的“數據結構定義工具”。
我們可以在 StateGraph(MyState) 傳入一個 Pydantic 模型:
from pydantic import BaseModel
from langgraph.graph import StateGraph, START, END# ? 1. 定義結構化狀態模型
class CalcState(BaseModel):x: int# ? 2. 定義節點函數,接收并返回 CalcState
def addition(state: CalcState) -> CalcState:print(f"[addition] 初始狀態: {state}")return CalcState(x=state.x + 1)def subtraction(state: CalcState) -> CalcState:print(f"[subtraction] 接收到狀態: {state}")return CalcState(x=state.x - 2)# ? 3. 構建圖
builder = StateGraph(CalcState)builder.add_node("addition", addition)
builder.add_node("subtraction", subtraction)builder.add_edge(START, "addition")
builder.add_edge("addition", "subtraction")
builder.add_edge("subtraction", END)graph = builder.compile()# ? 4. 執行圖:傳入結構化狀態對象
initial_state = CalcState(x=10)
final_state = graph.invoke(initial_state)# ? 5. 打印最終結果
print("\n[最終結果] ->", final_state)
但是需要注意的是,無論輸入端輸入什么結構的對象,最終圖計算返回結果是一個字典類型對象。
4.創建條件分支圖
from typing import Optional
from pydantic import BaseModel
from langgraph.graph import StateGraph, START, END
from IPython.display import Image, display# ? 定義結構化狀態
class MyState(BaseModel):x: intresult: Optional[str] = None# ? 定義各節點處理邏輯(接受 MyState,返回 MyState)
def check_x(state: MyState) -> MyState:print(f"[check_x] Received state: {state}")return statedef is_even(state: MyState) -> bool:return state.x % 2 == 0def handle_even(state: MyState) -> MyState:print("[handle_even] x 是偶數")return MyState(x=state.x, result="even")def handle_odd(state: MyState) -> MyState:print("[handle_odd] x 是奇數")return MyState(x=state.x, result="odd")def build_graph() -> StateGraph:# ? 構建圖builder = StateGraph(MyState)builder.add_node("check_x", check_x)builder.add_node("handle_even", handle_even)builder.add_node("handle_odd", handle_odd)# ? 添加條件分支builder.add_conditional_edges("check_x", is_even, {True: "handle_even",False: "handle_odd"})# ? 銜接起始和結束builder.add_edge(START, "check_x")builder.add_edge("handle_even", END)builder.add_edge("handle_odd", END)# ? 編譯圖graph = builder.compile()return graphdef display_graph(graph: StateGraph) -> None:"""顯示或保存圖形"""try:png_data = graph.get_graph(xray=True).draw_mermaid_png()with open("graph.png", "wb") as f:f.write(png_data)display(Image("graph.png"))except Exception as e:print(f"無法顯示圖形: {e}")if __name__ == "__main__":# ? 構建圖graph = build_graph()# ? 執行測試print("\n? 測試 x=4(偶數)")graph.invoke(MyState(x=4))print("\n? 測試 x=3(奇數)")graph.invoke(MyState(x=3))# ? 顯示圖形display_graph(graph)在本示例中,我們基于 LangGraph 框架構建了一個簡單的有狀態條件分支圖,用于演示如何使用結構化狀態(通過 Pydantic 模型定義)在多步驟的決策流程中進行狀態傳遞與條件控制。
我們首先定義了一個名為 MyState 的 Pydantic 模型,用于描述圖中每個節點共享的上下文狀態信息。該狀態包含兩個字段:x 表示輸入數值,result 表示最終處理結果。通過使用 Pydantic,能夠顯著增強狀態管理的類型安全性、可讀性和擴展性。
圖的結構由三個核心節點組成:
- check_x:作為圖的第一步處理節點,接收初始狀態并進行輸出轉發,不修改任何字段;
- handle_even:處理偶數情況,標記
result = "even"; - handle_odd:處理奇數情況,標記
result = "odd"。
在 check_x 節點之后,我們引入了基于 is_even 判斷函數的條件分支控制邏輯。LangGraph 提供的 add_conditional_edges 方法允許我們根據狀態中的值動態跳轉至不同的執行路徑,從而實現類似于傳統編程語言中的 if-else 分支控制。
整體流程圖如下:
START → check_x → [判斷 x 是否為偶數]├─ True → handle_even → END└─ False → handle_odd → END
該圖的編排邏輯清晰地展現了 LangGraph 的優勢所在:即在狀態流轉的基礎上,靈活地控制流程分支,并通過結構化模型傳遞和管理上下文信息,為構建具備復雜控制流的智能體(Agent)打下了基礎。
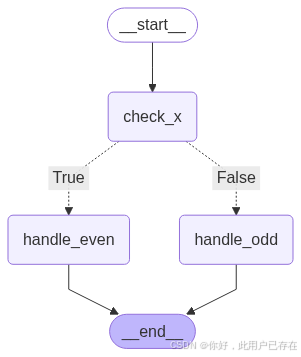
其中
# ? 定義結構化狀態
class MyState(BaseModel):x: intresult: Optional[str] = None
代碼解釋如下
| 字段 | 類型定義 | 是否必填 | 默認值 | 含義 |
|---|---|---|---|---|
x | int | ? 必填 | 無默認值 | 必須提供的整數字段 |
result | Optional[str] = Union[str, None] | ? 可選 | 默認是 None | 表示一個可選的字符串,常用于延遲賦值或非必要字段 |
而完整的圖結構執行流程如下:
| 參數位置 | 傳入值 | 含義 |
|---|---|---|
| 第1個參數 | "check_x" | 當前執行完的節點名稱(分支判斷起點) |
| 第2個參數 | is_even | 一個接收狀態 state 并返回布爾值的函數,用于判斷分支條件 |
| 第3個參數 | {True: "handle_even", False: "handle_odd"} | 條件結果 → 目標節點的映射表 |
4.創建條件循環圖
from pydantic import BaseModel
from langgraph.graph import StateGraph, START, END# ? 1. 定義結構化狀態模型
class LoopState(BaseModel):x: int# ? 2. 定義節點邏輯
def increment(state: LoopState) -> LoopState:print(f"[increment] 當前 x = {state.x}")return LoopState(x=state.x + 1)def is_done(state: LoopState) -> bool:return state.x > 10# ? 3. 構建圖
builder = StateGraph(LoopState)
builder.add_node("increment", increment)# ? 4. 設置循環控制:is_done 為 True 則結束,否則繼續
builder.add_conditional_edges("increment", is_done, {True: END,False: "increment"
})builder.add_edge(START, "increment")
graph = builder.compile()# ? 5. 測試執行
print("\n? 執行循環直到 x > 10")
final_state = graph.invoke(LoopState(x=6))
print(f"[最終結果] -> x = {final_state['x']}")
注意,這里需要注意,add_conditional_edges中構建了循環
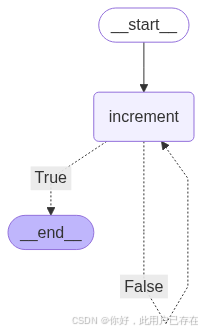
除了使用api構建循環圖,我們也可以自己使用節點和邊構建循環,如下所示
from pydantic import BaseModel
from typing import Optional
from langgraph.graph import StateGraph, START, END# ? 1. 定義狀態模型
class BranchLoopState(BaseModel):x: intdone: Optional[bool] = False# ? 2. 定義各節點邏輯
def check_x(state: BranchLoopState) -> BranchLoopState:print(f"[check_x] 當前 x = {state.x}")return statedef is_even(state: BranchLoopState) -> bool:return state.x % 2 == 0def increment(state: BranchLoopState) -> BranchLoopState:print(f"[increment] x 是偶數,執行 +1 → {state.x + 1}")return BranchLoopState(x=state.x + 1)def done(state: BranchLoopState) -> BranchLoopState:print(f"[done] x 是奇數,流程結束")return BranchLoopState(x=state.x, done=True)# ? 3. 構建圖
builder = StateGraph(BranchLoopState)builder.add_node("check_x", check_x)
builder.add_node("increment", increment)
builder.add_node("done_node", done)builder.add_conditional_edges("check_x", is_even, {True: "increment",False: "done_node"
})# ? 4. 循環邏輯:偶數 → increment → check_x
builder.add_edge("increment", "check_x")# ? 5. 起始與終點
builder.add_edge(START, "check_x")
builder.add_edge("done_node", END)graph = builder.compile()# ? 6. 測試執行
print("\n? 初始 x=6(偶數,進入循環)")
final_state1 = graph.invoke(BranchLoopState(x=6))
print("[最終結果1] ->", final_state1)print("\n? 初始 x=3(奇數,直接 done)")
final_state2 = graph.invoke(BranchLoopState(x=3))
print("[最終結果2] ->", final_state2)
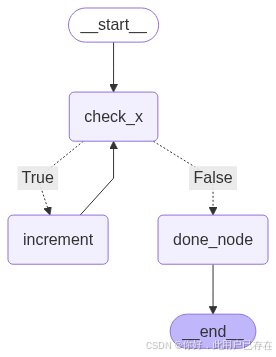
LangGraph 會把所有節點名、狀態字段、通道名放在一個命名空間中處理,為了避免歧義,它會嚴格檢查有沒有沖突,最保險的做法是:節點名不要與字段名重復,既如果使用 state.result = “done”,也不要有 “result” 這個節點。
理解了LangGraph構建圖的基本流程后,接下來我們就嘗試接入大模型構建一個對話機器人。
二、搭建基于LangGraph的多輪對話問答機器人
1. LangGraph中多輪對話實現方法
??在接下來的這個案例中,我們進一步將大模型接入到 LangGraph 工作流程中,并允許動態消息處理以及與模型的交互。
大模型應用都是接受消息列表作為輸入,就像LangChain中的Chat Model,需要接收Message對象列表作為輸入。這些消息有多種形式,例如HumanMessage (用戶輸入)或AIMessage ( 大模型響應)。這種消息格式其實就與我們之前介紹的StateGraph(dict)結構有一些區別。
??因此對于消息序列格式的state,一種更簡單的方法就是使用LangGraph預構建的add_messages函數,這個更高級的狀態所實現的是:對于全新的消息,它會附加到現有列表,同時它也會正確處理現有消息的更新。 代碼如下所示:
from typing import Annotatedfrom typing_extensions import TypedDictfrom langgraph.graph import StateGraph
from langgraph.graph.message import add_messagesclass State(TypedDict):messages: Annotated[list, add_messages]graph_builder = StateGraph(State)
??add_messages的核心邏輯是合并兩個消息列表,按 ID 更新現有消息。默認情況下,狀態為“僅附加”,當新消息與現有消息具有相同的 ID時,進行更新。具體參數是:
- left ( Messages ) – 消息的基本列表。
- right ( Messages ) – 要合并到基本列表中的消息列表(或單個消息)。
??其返回值是一個消息列表,其中的合并邏輯則是:如果right的消息與left的消息具有相同的 ID,則right的消息將替換left的消息,否則作為一條新的消息進行追加。通過這種形式維護一個messages列表,可以很方便的實現消息的合并和更新。其基本形式如下:
messages = [HumanMessage(content="你好,請你詳細的介紹一下你自己。"),AIMessage(content="我是一個智能助手,我可以幫助你回答問題。"),HumanMessage(content="請問什么是大模型?"),AIMessage(content="大模型是一種基于深度學習的自然語言處理模型,它能夠理解和生成自然語言文本。"),.....]
??我們可以使用add_messages函數來進行快速驗證。 如果消息的ID不一樣,則會進行追加。代碼如下:
from langgraph.graph.message import add_messages
from langchain_core.messages import AIMessage, HumanMessagemsgs1 = [HumanMessage(content="你好。", id="1")]
msgs2 = [AIMessage(content="你好,很高興認識你。", id="2")]add_messages(msgs1, msgs2)
[HumanMessage(content='你好。', additional_kwargs={}, response_metadata={}, id='1'),AIMessage(content='你好,很高興認識你。', additional_kwargs={}, response_metadata={}, id='2')]
??如果ID相同,則會對消息內容進行更新。代碼如下:
msgs1 = [HumanMessage(content="你好。", id="1")]
msgs2 = [HumanMessage(content="你好呀。", id="1")]add_messages(msgs1, msgs2)
[HumanMessage(content='你好呀。', additional_kwargs={}, response_metadata={}, id='1')]
需要注意的是,不能直接在普通 Python 代碼中測試 add_messages 的合并功能。
原因是:
? add_messages 并不會在你創建 State 字典時自動生效,
? 它只會在 LangGraph 的內部狀態更新系統中被識別和調用。
??因此,當通過messages: Annotated[list, add_messages]去定義狀態時,我們就可以很方便的實現聊天機器人場景下消息序列的處理和維護。
from typing import Annotatedfrom typing_extensions import TypedDictfrom langgraph.graph import StateGraph, START
from langgraph.graph.message import add_messagesclass State(TypedDict):messages: Annotated[list, add_messages]graph_builder = StateGraph(State)
| 元素 | 含義 | 是什么? |
|---|---|---|
list | 字段的數據類型 | ? Python 內置的類型(列表類型) |
add_messages | 字段的“附加語義” | ? LangGraph 提供的特殊函數(合并器/reducer),不是 list 的方法 |
??接下來我們需要創建一個大模型節點,接收用戶的輸入,并返回大模型的響應。因此首先需要準備一個可以進行調用的大模型,這里我們選擇使用DeepSeek的大模型,并使用DeepSeek官方的API_KEK進行調用。如果初次使用,需要現在DeepSeek官網上進行注冊并創建一個新的API_Key,其官方地址為:https://platform.deepseek.com/usage
??注冊好DeepSeek的API_KEY后,首先在項目同級目錄下創建一個env文件,用于存儲DeepSeek的API_KEY,如下所示:
接下來通過python-dotenv庫讀取env文件中的API_KEY,使其加載到當前的運行環境中,代碼如下:
pip install python-dotenv -i https://pypi.tuna.tsinghua.edu.cn/simple
import os
from dotenv import load_dotenv
load_dotenv(override=True)DeepSeek_API_KEY = os.getenv("DEEPSEEK_API_KEY")# print(DeepSeek_API_KEY) # 可以通過打印查看
pip install openai -i https://pypi.tuna.tsinghua.edu.cn/simple
from openai import OpenAI# 初始化DeepSeek的API客戶端
client = OpenAI(api_key=DeepSeek_API_KEY, base_url="https://api.deepseek.com")# 調用DeepSeek的API,生成回答
response = client.chat.completions.create(model="deepseek-chat",messages=[{"role": "system", "content": "你是樂于助人的助手,請根據用戶的問題給出回答"},{"role": "user", "content": "你好,請你介紹一下你自己。"},],
)# 打印模型最終的響應結果
print(response.choices[0].message.content)
??如果可以正常收到DeepSeek模型的響應,則說明DeepSeek的API已經可以正常使用且網絡連通性正常。
對于LangGraph框架,接入大模型最簡單的方法就是借助langChain中的ChatModel組件。因此,我們首先需要安裝LangChain的DeepSeek組件,安裝命令如下:
pip install langchain-deepseek
??安裝好LangChain集成DeepSeek模型的依賴包后,需要通過一個init_chat_model函數來初始化大模型,代碼如下:
import asyncio
import os
from dotenv import load_dotenv
from langchain.chat_models import init_chat_modelload_dotenv()
DeepSeek_API_KEY = os.getenv("DEEPSEEK_API_KEY")model = init_chat_model(model="deepseek-chat", model_provider="deepseek",api_key=DeepSeek_API_KEY) # 等待輸出
def invoke_tool():question = "你好,請你介紹一下你自己。"result = model.invoke(question)print(result.content)
# 流式輸出
async def invoke_tool_async():chunks = []async for chunk in model.astream("你好,請你詳細的介紹一下你自己。"):chunks.append(chunk)print(chunk.content, end="|", flush=True)if __name__ == "__main__":# invoke_tool()asyncio.run(invoke_tool_async())??其中model用來指定要使用的模型名稱,而model_provider用來指定模型提供者,當寫入deepseek時,會自動加載langchain-deepseek的依賴包,并使用在model中指定的模型名稱用來進行交互。
這里可以看到,僅僅通過兩行代碼,我們便可以在LangChain中順利調用DeepSeek模型,并得到模型的響應結果。相較于使用DeepSeek的API,使用LangChain調用模型無疑是更加簡單的。同時,不僅僅是DeepSeek模型,LangChain還支持其他很多大模型,如OpenAI、Qwen、Gemini等,我們只需要在init_chat_model函數中指定不同的模型名稱,就可以調用不同的模型。其工作的原理是這樣的:
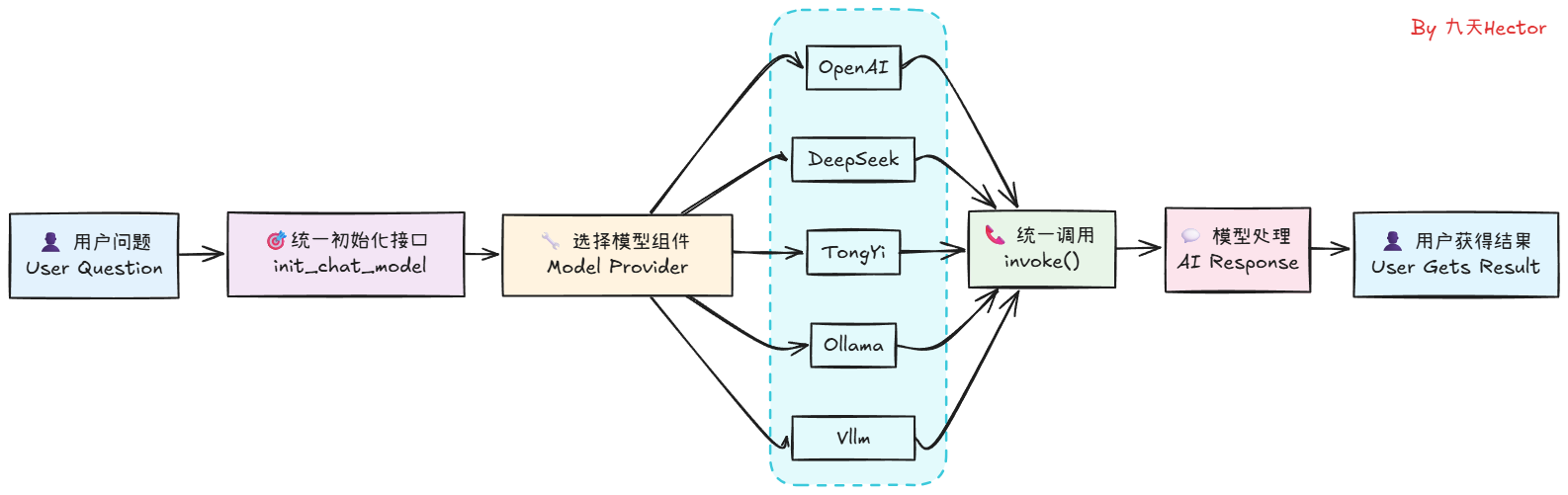
??理解了這個基本原理,如果大家想在用LangChain進行開發時使用其他大模型如Qwen3系列,則只需要先獲取到Qwen3模型的API_KEY,然后安裝Tongyi Qwen的第三方依賴包,即可同樣通過init_chat_model函數來初始化模型,并調用invoke方法來得到模型的響應結果。關于LangChain都支持哪些大模型以及每個模型對應的是哪個第三方依賴包,大家可以在LangChain的官方文檔中找到,訪問鏈接為:https://python.langchain.com/docs/integrations/chat/
??當然,除了在線大模型的接入,langChain也只是使用Ollama、vLLM等框架啟動的本地大模型,關于如何使用不同的框架啟動如DeepSeek R1、Qwen3等模型
??掌握了如何使用langChain接入大模型后,接下來我們可以直接把langChain的Chat Model接入LangGraph中作為一個圖節點(Node), 并使用LangGraph的StateGraph來管理消息序列。代碼如下:
def chatbot(state: State):return {"messages": [model.invoke(state["messages"])]}
??接下來,添加一個chatbot節點,將當前State作為輸入并返回一個字典,該字典中更新了messages中的狀態信息。
# 添加節點
graph_builder.add_node("chatbot", chatbot)# 添加邊
graph_builder.add_edge(START, "chatbot")
graph = graph_builder.compile()
這個圖的基本邏輯是:第一個節點調用大模型并生成一個輸出,該輸出是一個AIMessage對象類型,然后,第二個節點直接將前一個節點的 AIMessage 提取為具體的JSON格式,完成JSON的解析。
final_state = graph.invoke({"messages": ["你好,我叫陳明,好久不見。"]})
print(final_state)
- 借助MemorySaver高效搭建多輪對話機器人
🧠 MemorySaver 的核心功能
-
短期記憶(線程級記憶)
MemorySaver 為每個thread_id保存和恢復對話狀態(State),實現在同一會話中的歷史上下文記憶。 -
狀態持久化
在每個節點運行后,State 會自動存儲;再次調用時,如果使用相同的thread_id,MemorySaver 會恢復此前保存的狀態,無需手動傳遞歷史信息 。 -
多會話隔離
通過不同的thread_id可實現會話隔離,允許多個用戶并發交互且各自的對話互不干擾。 -
圖狀態快照與恢復
不僅包括對話歷史,還保存整個工作流狀態,可用于錯誤恢復、時間旅行、斷點續跑、Human?in?the?loop 等高級場景 。
from typing import Annotated
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
from langchain.chat_models import init_chat_model
import os
from dotenv import load_dotenv
from langgraph.checkpoint.memory import MemorySaver# 1. 定義狀態類(會自動合并 messages)
class State(TypedDict):messages: Annotated[list, add_messages]load_dotenv()
DeepSeek_API_KEY = os.getenv("DEEPSEEK_API_KEY")
# 2. 初始化模型
model = init_chat_model(model="deepseek-chat", model_provider="deepseek", api_key=DeepSeek_API_KEY)# 3. 定義聊天節點
def chatbot(state: State) -> State:reply = model.invoke(state["messages"])return {"messages": [reply]}# 4. 構建帶 MemorySaver 的圖
builder = StateGraph(State)
builder.add_node("chatbot", chatbot)
builder.add_edge(START, "chatbot")
memory = MemorySaver()
graph = builder.compile(checkpointer=memory)# 5. 運行多輪對話,使用相同 thread_id 實現記憶
thread_config = {"configurable": {"thread_id": "session_10"}}# 第一輪對話
state1 = graph.invoke({"messages": [{"role":"user","content":"你好,好久不見,我叫陳明。"}]}, config=thread_config)
print(state1['messages'][-1].content)# 第二輪對話
state2 = graph.invoke({"messages": [{"role":"user","content":"你好,你還記得我的名字么?"}]}, config=thread_config)
print(state2['messages'][-1].content)# 使用不同 thread_id,會開啟全新對話
state3 = graph.invoke({"messages":[{"role":"user","content":"記得我的名字嗎?"}]}, config={"configurable":{"thread_id":"session_2"}})
state3['messages'][-1].content# 查看記憶
latest = graph.get_state(thread_config)
print(latest.values["messages"]) # 包含全部輪次對話
最后有關流式輸出可參考
from typing import Annotated
from typing_extensions import TypedDict
from langgraph.graph.message import add_messages
from langchain_core.messages import AIMessage, HumanMessage
from langgraph.graph import StateGraph
from langgraph.graph.message import add_messages
import os
from dotenv import load_dotenv
from langchain.chat_models import init_chat_model
from langchain_core.messages import AIMessage, HumanMessage, SystemMessage
from langgraph.graph import START, END
import asynciodef msg_test():# 當消息id不同時,會自動合并消息msgs1 = [HumanMessage(content="你好。", id="1")]msgs2 = [AIMessage(content="你好,很高興認識你。", id="2")]msg=add_messages(msgs1, msgs2)print(msg)# 當消息id相同時,會更新當前消息msgs3 = [HumanMessage(content="你好。", id="3")]msgs4 = [HumanMessage(content="你好呀。", id="3")]msg1=add_messages(msgs3, msgs4)print(msg1)load_dotenv()
DeepSeek_API_KEY = os.getenv("DEEPSEEK_API_KEY")
model = init_chat_model(model="deepseek-chat", model_provider="deepseek",api_key=DeepSeek_API_KEY)class State(TypedDict):messages: Annotated[list, add_messages]graph_builder = StateGraph(State)def chatbot(state: State):return {"messages": [model.invoke(state["messages"])]}# 添加節點
graph_builder.add_node("chatbot", chatbot)
# 添加邊
graph_builder.add_edge(START, "chatbot")
graph = graph_builder.compile()def test_chatbot():final_state = graph.invoke({"messages": ["你好,我叫陳明,好久不見。"]})print(final_state['messages'][0].content)def invoke_chatbot():messages_list = [HumanMessage(content="你好,我叫陳明,好久不見。"),AIMessage(content="你好呀!我是小智,一名樂于助人的AI助手。很高興認識你!"),HumanMessage(content="請問,你還記得我叫什么名字么?"),]final_state = graph.invoke({"messages": messages_list})print(final_state['messages'][-1].content)async def async_invoke_chatbot():async for msg, metadata in graph.astream({"messages": ["你好,請你詳細的介紹一下你自己"]}, stream_mode="messages"):if msg.content and not isinstance(msg, HumanMessage):print(msg.content, end="", flush=True)if __name__ == '__main__':# invoke_chatbot()asyncio.run(async_invoke_chatbot())參考
https://www.bilibili.com/video/BV1Kx3CzyE6Q/?spm_id_from=333.337.search-card.all.click&vd_source=23fecc1a0310f387371490d0c2975c12
![[逆向知識] AST抽象語法樹:混淆與反混淆的邏輯互換(一)](http://pic.xiahunao.cn/[逆向知識] AST抽象語法樹:混淆與反混淆的邏輯互換(一))





)
)




![[go] 橋接模式](http://pic.xiahunao.cn/[go] 橋接模式)



模擬實現)


,110. 字符串接龍(卡碼網),105. 有向圖的完全聯通(卡碼網))