目錄
- spark基礎&rdd
- docs
- RDD
- spark架構
- Spark 對比 hadoop MapReduce
- spark maven依賴
- Spark的checkpoint
- transformations、shuffle、actions
- reduceByKey的用法
- groupByKey的用法
- count / count distinct
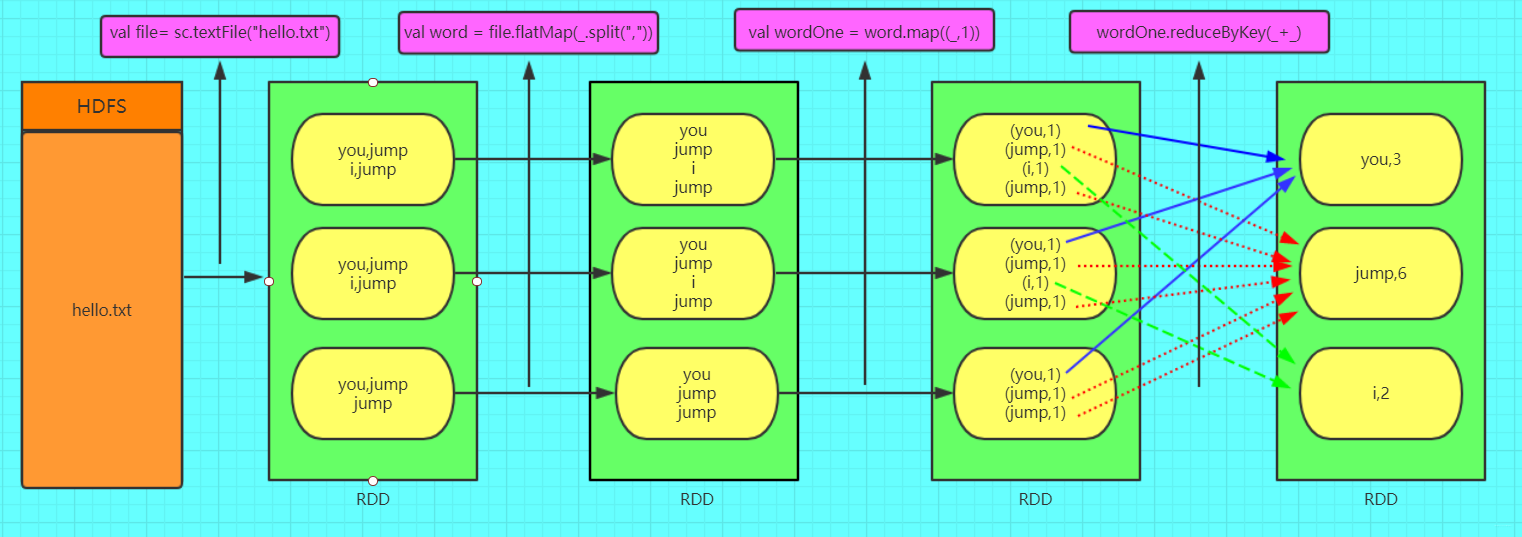
- 例子:單詞計數
- 例子:一批人員年齡數據求平均(rdd)
- 例子:求不同性別的最大/最小身高(Sql)
- map/reduce求平均身高(rdd)
spark基礎&rdd
docs
docs: https://archive.apache.org/dist/spark/docs/3.1.1/
RDD
RDD(Resilient Distributed Dataset)叫做彈性分布式數據集,是 Spark 中最基本的數據抽象,它代表一個不可變、可分區、里面的元素可并行計算的集合。(不可變、自動容錯、位置感知性調度和可伸縮性)
RDD is a collection of elements partitioned across the nodes of the cluster that can be operated on in parallel
resilient 英[r??z?li?nt]
adj. 有彈性(或彈力)的;有適應力的;能復原的;可迅速恢復的;
- 一組分片(Partition),即數據集的基本組成單位。對于 RDD 來說,每個分片都會被一個計算任務處理,并決定并行計算的粒度。用戶可以在創建 RDD 時指定 RDD 的分片個數,如果沒有指定,那么就會采用默認值。默認值就是程序所分配到的 CPU Core 的數目。
- 一個計算每個分區的函數。Spark 中 RDD 的計算是以分片為單位的,每個 RDD 都會實現 compute 函數以達到這個目的。compute 函數會對迭代器進行復合,不需要保存每次計算的結果。
- RDD 之間的依賴關系。RDD 的每次轉換都會生成一個新的 RDD,所以 RDD 之間就會形成類似于流水線一樣的前后依賴關系。在部分分區數據丟失時,Spark 可以通過這個依賴關系重新計算丟失的分區數據,而不是對 RDD 的所有分區進行重新計算。
- 一個 Partitioner,即 RDD 的分片函數。當前 Spark 中實現了兩種類型的分片函數,一個是基于哈希的 HashPartitioner,另外一個是基于范圍的 RangePartitioner。只有對于于 key-value 的 RDD,才會有 Partitioner,非 key-value 的 RDD 的 Parititioner 的值是 None。Partitioner 函數不但決定了 RDD 本身的分片數量,也決定了 parent RDD Shuffle 輸出時的分片數量。
- 一個列表,存儲存取每個 Partition 的優先位置(preferred location)。對于一個 HDFS 文件來說,這個列表保存的就是每個 Partition 所在的塊的位置。按照“移動數據不如移動計算”的理念,Spark 在進行任務調度的時候,會盡可能地將計算任務分配到其所要處理數據塊的存儲位置。
spark架構
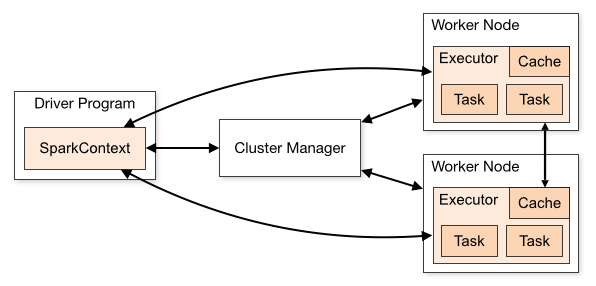
- Driver(驅動程序)?: 作為應用程序的主控進程,負責解析用戶代碼、生成DAG(有向無環圖)并劃分Stage。
- Cluster Manager(集群管理器)?:管理集群資源,支持Standalone、YARN、Mesos和Kubernetes等模式
- Worker(工作節點)?:在集群節點上運行,負責啟動Executor進程并監控其狀態。??
- ?Executor(執行器):在Worker節點上執行具體任務,管理內存緩存和磁盤I/O,定期向Driver發送心跳。??
- ?Task(任務)?:最小執行單元,由Executor并行處理,每個Stage被拆分為多個Task。??
特點
- 內存計算?:中間結果存儲在內存中,相比Hadoop MapReduce減少磁盤I/O,部分速度能提升10-100倍。??
- 彈性分布式數據集(RDD)?:基礎數據結構,支持容錯和并行計算,通過Lineage(血統、依賴鏈、依賴關系)機制恢復數據。??
- 多模式支持?:兼容批處理、流處理(Spark Streaming)、SQL查詢(Spark SQL)及機器學習(MLlib)。??
Spark 對比 hadoop MapReduce
spark例子參考:https://xie.infoq.cn/article/71e6677d03b59ce7aa5eec22a
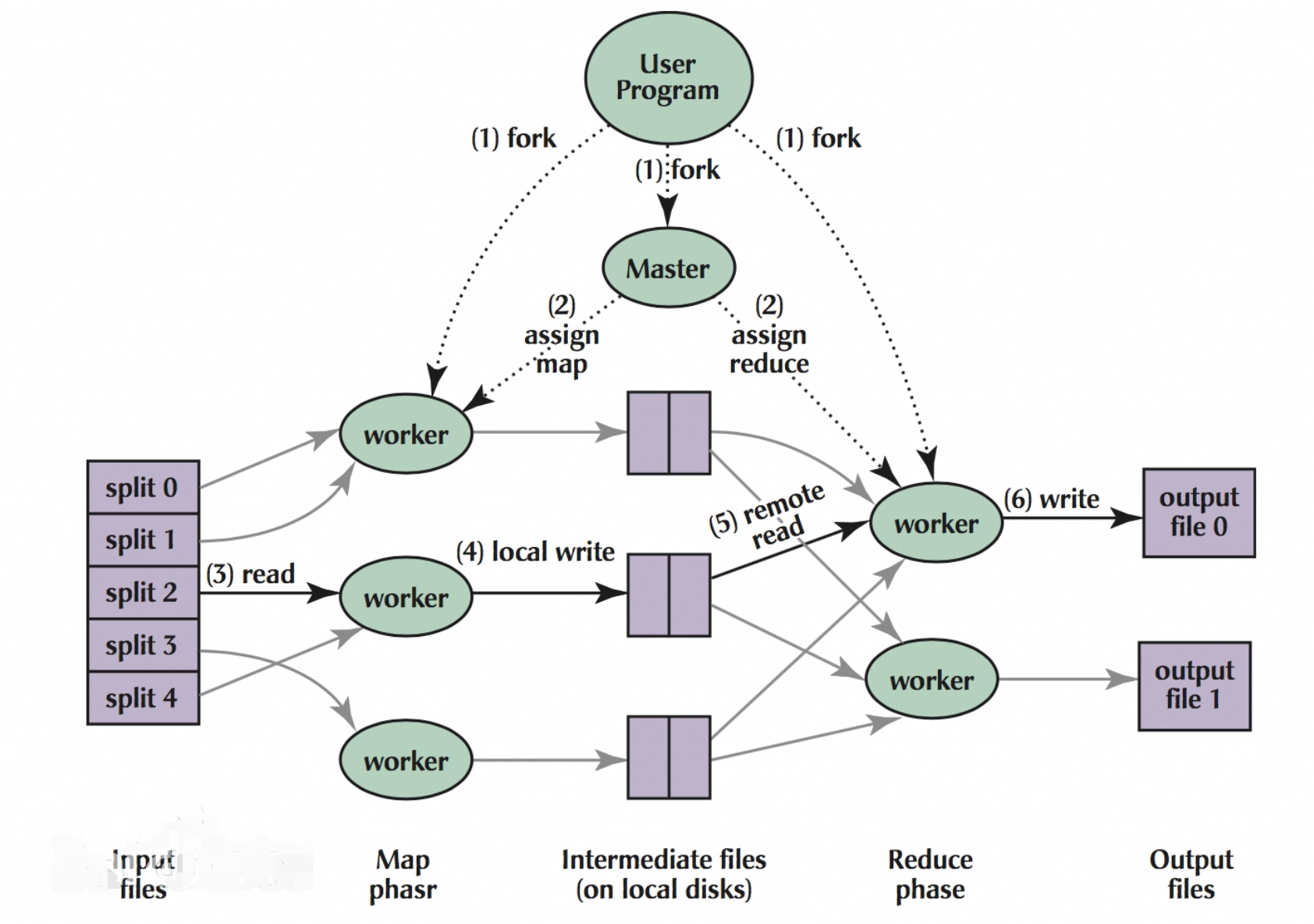
hadoop MapReduce參考:https://doctording.blog.csdn.net/article/details/78467216
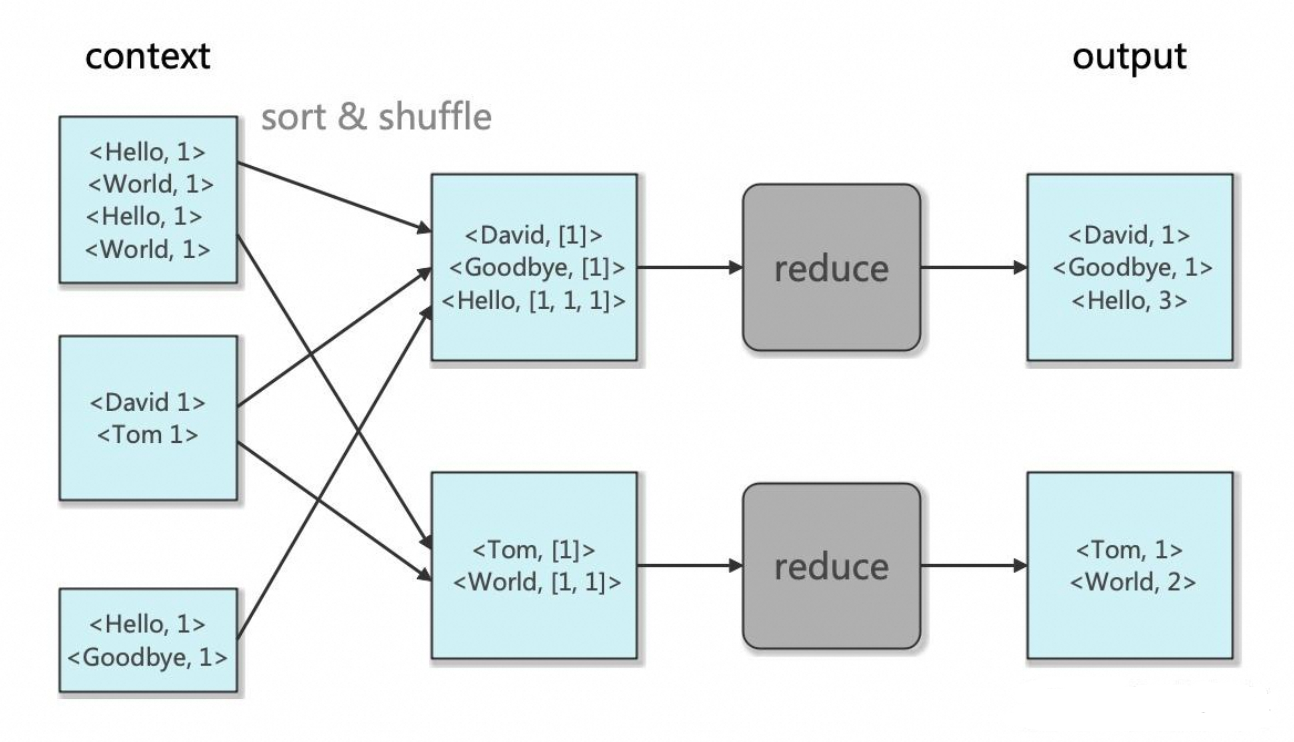
對比hadoop MapReduce:
Map:
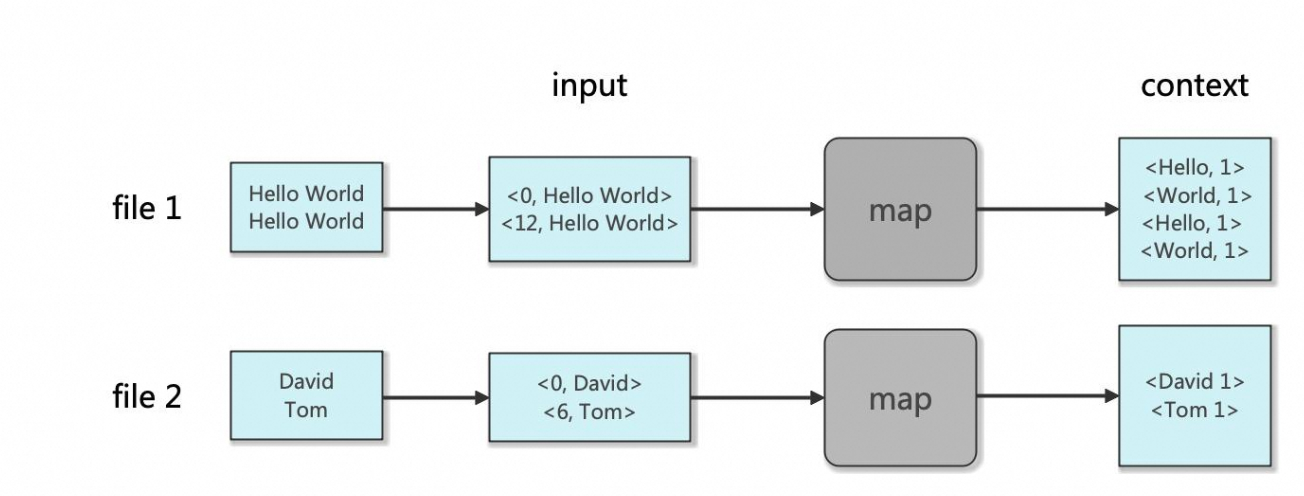
Reduce:
spark maven依賴
<!-- Spark core --><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.12</artifactId><version>3.1.1</version></dependency><!-- Spark SQL --><dependency><groupId>org.apache.spark</groupId><artifactId>spark-sql_2.12</artifactId><version>3.1.1</version></dependency><!-- 如果需要使用 MLlib --><dependency><groupId>org.apache.spark</groupId><artifactId>spark-mllib_2.12</artifactId><version>3.1.1</version></dependency>
Spark的checkpoint
spark 中 Checkpoint 的主要作用是斬斷 RDD 的依賴鏈。
Checkpoint 的兩種方式
- 可靠的將數據存儲在可靠的存儲引擎中,例如 HDFS。要將 RDD 緩存在本地 block manager 中,在 exquator中。如果 work 崩潰,數據消失。而 RDD 也能存儲在 HDFS 中,即一種 checkpoint 可靠的方式,即將 RDD 的數據緩存到 HDFS 中。
- 本地的將數據存儲在本地,稱為 Local checkpoint,較少使用,和 RDD 的區別比較小。本地存儲方式不太符合checkpoint 的思想。
https://developer.aliyun.com/article/1086764
https://developer.aliyun.com/article/1329824
transformations、shuffle、actions
transformation 英[?tr?nsf??me??n]
n. (徹底的)變化,改觀,轉變,改革;轉型;(用于南非)民主改革;
- map
- filter
- flatMap
- mapPartitions
- mapPartitionsWithIndex
- sample
- union
- intersection
- distinct
- groupByKey
- reduceByKey
- aggregateByKey
- sortByKey
- join
- cogroup
- cartesian
- pipe
- coalesce
- repartition
- repartitionAndSortWithinPartitions
shuffle 英[???fl]
v. 洗牌;洗(牌);拖著腳走;坐立不安;把(紙張等)變換位置,打亂次序;(笨拙或尷尬地)把腳動來動去;
n.洗牌;拖著腳走;曳步舞;
Operations which can cause a shuffle include repartition operations like repartition and coalesce, ‘ByKey operations (except for counting) like groupByKey and reduceByKey, and join operations like cogroup and join.
actions
- collect()
- count()
- first()
- take(n)
- takeSample(withReplacement, num, [seed])
- takeOrdered(n, [ordering])
- saveAsTextFile(path)
- saveAsSequenceFile(path)
- saveAsObjectFile(path)
- countByKey()
- foreach(func)
reduceByKey的用法
值可合并的聚合操作
- scala
val data = List(("a", 1), ("b", 2), ("a", 3), ("b", 4))
val rdd = sc.parallelize(data)
val result = rdd.reduceByKey(_ + _) // 對相同key的值求和
result.collect().foreach(println)
- 輸出
(a,4)
(b,6)
核心特點
- 本地聚合優化?:先在分區內合并數據(類似MapReduce的combiner),減少shuffle數據量?
- 函數要求?:聚合函數需滿足結合律(如加法、最大值等)
- 性能對比?:比groupByKey更高效,因后者不進行預聚合
典型場景
- 統計詞頻(單詞計數)
- 分組求和/求平均值
- 數據去重后的聚合計算
groupByKey的用法
Spark中的groupByKey是一個針對鍵值對RDD的核心轉換算子
核心機制
- 分組邏輯?:將相同key的所有value合并為迭代器(Iterable),輸出格式為(K, Iterable)。與reduceByKey不同,它僅進行分組而不執行聚合操作?
- 執行過程?:直接對全量數據進行shuffle,不進行本地預聚合,導致網絡傳輸量較大。例如處理(“a”,1), (“a”,2)會直接傳輸所有鍵值對,而reduceByKey會先在分區內合并為(“a”,3)再shuffle。
典型應用場景
- 需保留所有值的場景?:如統計每個用戶的完整行為序列
- 非聚合操作?:例如對分組后的值進行復雜處理(排序、去重等)
缺點
- 數據傾斜風險:單個key對應的value過多會導致OOM,如某key關聯百萬級記錄:使用reduceByKey或aggregateByKey替代(若允許預聚合);對傾斜key單獨處理(如加鹽分片)
- 內存消耗:未壓縮的迭代器對象會占用更多內存,建議配合mapValues轉換為緊湊數據結構
例子
val data = sc.parallelize(Seq(("a",1), ("b",2), ("a",3)))
val grouped = data.groupByKey() // 輸出: (a, [1,3]), (b, [2])
grouped.foreach(println)
輸出
(a,CompactBuffer(1, 3))
(b,CompactBuffer(2))
count / count distinct
count:
- 觸發計算?:count是行動算子,會立即觸發作業執行
- 全量掃描?:默認會掃描全表數據,大數據集可能耗時較長。
- 優化建議?:
- 對過濾后的數據統計(先filter再count)
- 使用緩存(cache())避免重復計算
scala> val rdd = sc.parallelize(Seq(1, 2, 3))
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[4] at parallelize at <console>:24scala> val total = rdd.count() // 輸出:3
total: Long = 3scala>
- count distinct例子
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.RowFactory;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.types.DataTypes;
import org.apache.spark.sql.types.StructField;
import org.apache.spark.sql.types.StructType;import java.util.Arrays;
import java.util.List;/*** @Author mubi* @Date 2025/8/14 23:39*/
public class Main {public static void main(String[] args) throws Exception {// 初始化SparkSessionSparkSession spark = SparkSession.builder().appName("countDistinct").master("local[*]").getOrCreate();// 定義SchemaStructType schema = new StructType(new StructField[]{DataTypes.createStructField("id", DataTypes.IntegerType, false),DataTypes.createStructField("fruit", DataTypes.StringType, false)});// 創建Row數據List<Row> data = Arrays.asList(RowFactory.create(1, "apple"),RowFactory.create(2, "banana"),RowFactory.create(3, "apple"),RowFactory.create(4, "orange"),RowFactory.create(5, "banana"));// 構建DataFrameDataset<Row> df = spark.createDataFrame(data ,schema);// 計算不同水果數量long distinctFruitsCount = df.select("fruit").distinct().count();System.out.println("Number of distinct fruits: " + distinctFruitsCount);spark.stop();}
}
例子:單詞計數
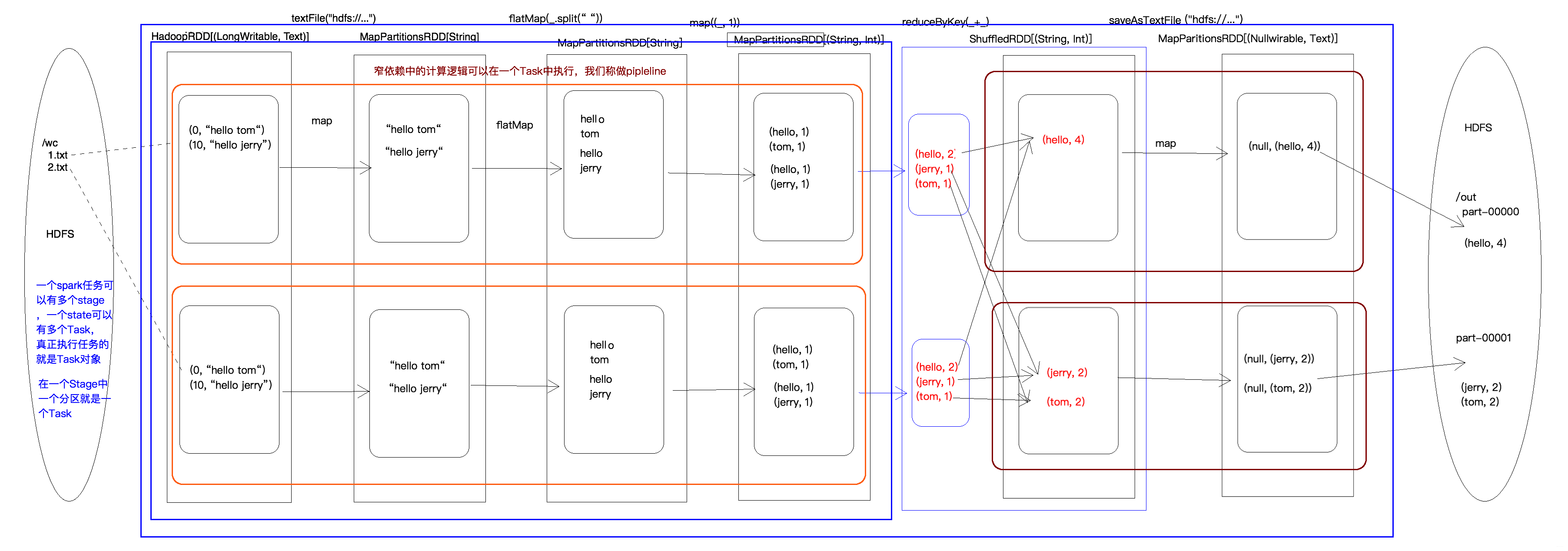
- java程序
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import scala.Tuple2;import java.util.Arrays;
import java.util.List;/*** @Author mubi* @Date 2025/8/14 23:39*/
public class Main {public static void main(String[] args) throws Exception {// 創建Spark配置和上下文SparkConf conf = new SparkConf().setAppName("JavaWordCount").setMaster("local");JavaSparkContext sc = new JavaSparkContext(conf);// 讀取文本文件,這里使用Spark自帶的示例文本文件JavaRDD<String> input = sc.textFile("src/main/resources/words.txt");// 將每行文本拆分成單詞,并對單詞進行計數JavaRDD<String> words = input.flatMap(s -> Arrays.asList(s.split(" ")).iterator());JavaPairRDD<String, Integer> wordCounts = words.mapToPair(s -> new Tuple2<>(s, 1)).reduceByKey((a, b) -> a + b);// 收集結果并打印List<Tuple2<String, Integer>> output = wordCounts.collect();for (Tuple2<?,?> tuple : output) {System.out.println(tuple._1() + ": " + tuple._2());}// 關閉Spark上下文sc.close();}}
- 輸入
hello how are you
fine
hello you
- 輸出
are: 1
fine: 1
you: 2
how: 1
hello: 2
例子:一批人員年齡數據求平均(rdd)
- java程序
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2;import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
import java.util.Random;/*** @Author mubi* @Date 2025/8/14 23:39*/
public class Main {public static void main(String[] args) throws Exception {SparkConf conf = new SparkConf();conf.setMaster("local");conf.setAppName("AvgAge");JavaSparkContext sc = new JavaSparkContext(conf);//剛從文件讀出來的RDD已經是一行一行的字符串,所以可以直接進行mapToPairJavaRDD<String> fileRDD = sc.textFile("src/main/resources/peopleAges.txt");final long peopleCnt = fileRDD.count();// map: <年齡,數量1>JavaPairRDD<Integer, Integer> ageOneRdd = fileRDD.mapToPair(new PairFunction<String, Integer, Integer>() {@Overridepublic Tuple2<Integer, Integer> call(String s) throws Exception {Integer age = Integer.parseInt(s.split("\\s+")[1]);return new Tuple2(age, 1);}});// reduce: <年齡,總數量>JavaPairRDD<Integer, Integer> ageCountRDD = ageOneRdd.reduceByKey((v1, v2) -> v1 + v2).sortByKey();ageCountRDD.saveAsTextFile("src/main/resources/ageAnalysis");//求總年齡和long totalAgeSum = ageCountRDD.map(tuple -> (long)tuple._1() * (long)tuple._2()).reduce((a, b) -> a + b);System.out.println("totalAgeSum:" + totalAgeSum + ",peopleCnt:" + peopleCnt);//求平均年齡System.out.println("all people avg age is:" + totalAgeSum * 1.0d / peopleCnt);}//生成年齡數據,格式"序號 年齡"public static void makeAgeData() throws IOException {File newFile = new File("src/main/resources/peopleAges.txt");if (newFile.exists()){newFile.delete();}newFile.createNewFile();FileWriter fw = new FileWriter(newFile,true);Random rand = new Random();for (int i = 1; i <= 1000000; i++) {fw.append(i + " " + (rand.nextInt(100) + 1) + "\n");fw.flush();}fw.close();System.out.println("makeAgeData finish");}
}
例子文件:
1 20
2 30
3 40
4 50
5 60
6 60
7 50
8 40
例子輸出
totalAgeSum:350, peopleCnt:8
all people avg age is:43.75
例子:求不同性別的最大/最小身高(Sql)
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.functions;import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
import java.util.Random;/*** @Author mubi* @Date 2025/8/14 23:39*/
public class Main {public static void main(String[] args) throws Exception {SparkSession spark = SparkSession.builder().appName("HeightAnalysis").master("local[*]").getOrCreate();Dataset<Row> df = spark.read().option("delimiter", " ").option("header", "false").csv("src/main/resources/peopleSexHeight.txt").toDF("id", "gender", "height").withColumn("height", functions.col("height").cast("int"));System.out.println("=== 數據 ===");df.show();// 男性身高統計Dataset<Row> maleStats = df.filter("gender = 'M'").agg(functions.max("height").alias("max_height"),functions.min("height").alias("min_height"));System.out.println("=== 男性身高統計 ===");maleStats.show();// 女性身高統計Dataset<Row> femaleStats = df.filter("gender = 'F'").agg(functions.max("height").alias("max_height"),functions.min("height").alias("min_height"));System.out.println("=== 女性身高統計 ===");femaleStats.show();spark.stop();}public static void makeData() throws IOException {File newFile = new File("src/main/resources/peopleSexHeight.txt");if (newFile.exists()){newFile.delete();}newFile.createNewFile();FileWriter fw = new FileWriter(newFile,true);Random rand = new Random();final int N = 1_000_000;for (int i = 1; i <= N; i++) {String gender = getRandomGender();int height = rand.nextInt(220);if (height < 100 && gender.equals("M")) {height = height + 100;}if (height < 100 && gender == "F") {height = height + 50;}fw.append(i + " " + gender + " " + height + "\n");fw.flush();}fw.close();System.out.println("makeAgeData finish");}static String getRandomGender() {Random rand = new Random();int randNum = rand.nextInt(2) + 1;if (randNum % 2 == 0) {return "M";} else {return "F";}}
}
- 數據
1 M 153
2 F 64
3 M 107
4 F 83
5 F 131
6 M 174
7 F 86
8 M 115
9 M 191
10 F 208
- 輸出
=== 男性身高統計 ===
+----------+----------+
|max_height|min_height|
+----------+----------+
| 191| 107|
+----------+----------+=== 女性身高統計 ===
+----------+----------+
|max_height|min_height|
+----------+----------+
| 208| 64|
+----------+----------+附rdd:
public static void main(String[] args) throws Exception {SparkConf conf = new SparkConf();conf.setMaster("local");conf.setAppName("maxMinHeight");JavaSparkContext sc = new JavaSparkContext(conf);//剛從文件讀出來的RDD已經是一行一行的字符串,所以可以直接進行mapToPairJavaRDD<String> dataRdd = sc.textFile("src/main/resources/peopleSexHeight.txt");// 處理男性數據JavaRDD<Integer> maleHeights = dataRdd.filter(line -> line.split(" ")[1].equalsIgnoreCase("M")).map(line -> Integer.parseInt(line.split(" ")[2]));// 處理女性數據JavaRDD<Integer> femaleHeights = dataRdd.filter(line -> line.split(" ")[1].equalsIgnoreCase("F")).map(line -> Integer.parseInt(line.split(" ")[2]));// 計算并打印結果System.out.println("男性最高身高: " + maleHeights.max(Comparator.naturalOrder()));System.out.println("男性最低身高: " + maleHeights.min(Comparator.naturalOrder()));System.out.println("女性最高身高: " + femaleHeights.max(Comparator.naturalOrder()));System.out.println("女性最低身高: " + femaleHeights.min(Comparator.naturalOrder()));}
map/reduce求平均身高(rdd)
public static void main(String[] args) throws Exception {SparkConf conf = new SparkConf();conf.setMaster("local");conf.setAppName("maxMinHeight");JavaSparkContext sc = new JavaSparkContext(conf);//剛從文件讀出來的RDD已經是一行一行的字符串,所以可以直接進行mapToPairJavaRDD<String> dataRdd = sc.textFile("src/main/resources/peopleSexHeight.txt");// 處理男性數據JavaRDD<Integer> maleHeights = dataRdd.filter(line -> line.split(" ")[1].equalsIgnoreCase("M")).map(line -> Integer.parseInt(line.split(" ")[2]));long count = maleHeights.count();// 計算總和和計數int totalHeight = maleHeights.reduce((a, b) -> a + b);// 計算并打印平均身高double average = (double) totalHeight / count;System.out.printf("男性平均身高: %.2f cm\n", average);
}

)





|結構體與枚舉(面向對象、模式匹配))


![[微服務]ELK Stack安裝與配置全指南](http://pic.xiahunao.cn/[微服務]ELK Stack安裝與配置全指南)

)




:RKNN-ToolKit-lite2板端推理)

