博主會經常分享自己在人工智能階段的學習筆記,歡迎大家訪問我滴個人博客!(都不白來!)
小牛壯士 - 個人博客![]() https://kukudelin.top/
https://kukudelin.top/
前言
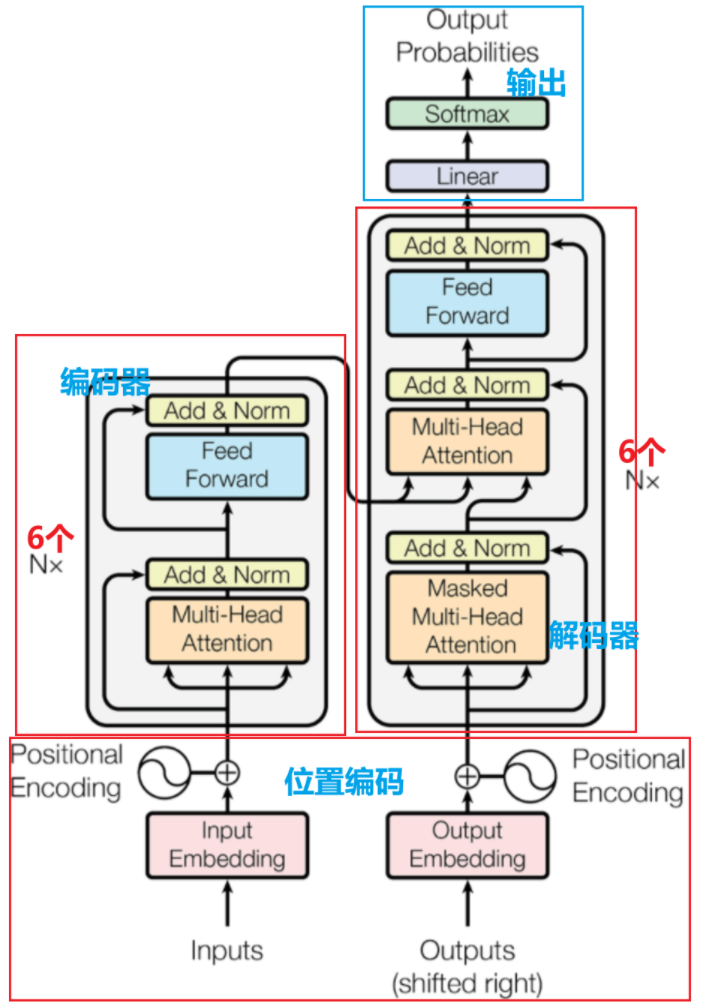
Transformer 廣泛應用于自然語言處理(如機器翻譯、文本生成)等領域,是BERT、GPT等大模型的基礎架構
-
以自注意力機制為核心:讓模型關注輸入序列中不同位置的關聯
-
具備強并行化能力:徹底擺脫了RNN等模型的序列依賴,能并行處理輸入數據
-
采用編碼器 - 解碼器架構:分別負責處理輸入序列為上下文表示及據此生成輸出序列。
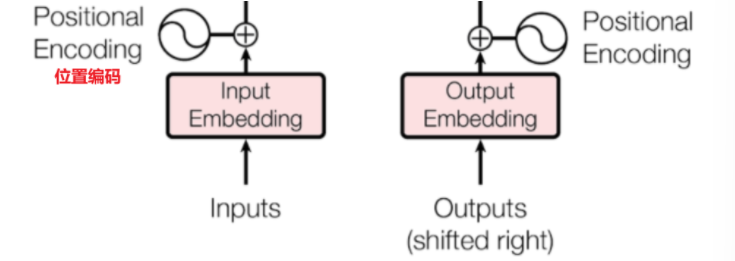
一、位置編碼Position Encoding
1.1 因
自注意力機制在計算關聯時,本質上是對序列中所有元素進行 “全局配對” 計算,沒有辦法考慮到元素的輸入順序,因此在輸入之前我們需要使用位置編碼來使自注意力機制區分序列中不同位置的元素
1.2 果
在輸入到 Transformer 模型之前,每個詞的詞嵌入向量(包含語義信息的原始維度數據)會與對應的位置編碼向量(模型根據這個編碼來區分輸入特征的前后位置)進行逐元素相加,形成一個新的向量。這個新向量同時包含了詞的語義信息和它在序列中的位置信息。
1.2.1 固定函數生成位置編碼
對于一個長度為N,詞向量維度為d的句子,他在長度索引為i,維度索引為j的位置編碼計算公式如下
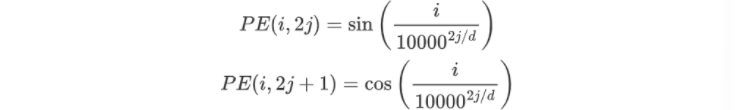
例如步長為5的句子“I am a handsome boy”,經過嵌入層得到4個維度的詞向量,那么對應的位置編碼為:

最終得到的位置編碼與詞嵌入向量逐元素相加,得到最終輸入模型的矩陣
二、層歸一化
與批歸一化不同,層歸一化是對神經網絡某一層的所有輸入特征按樣本計算均值和方差,再進行標準化以穩定訓練的技術,他的范圍是一個輸入詞向量在神經網絡中的某一層的所有特征維度。
![]()
相當于對句子中每一個詞對應的行向量求歸一化,可以看看這個案例:

三、編碼器Encoder
編碼器主要負責對輸入序列進行深度處理和信息提取,將原始輸入(如一句話、一段文本)轉換為包含豐富上下文信息的向量表示
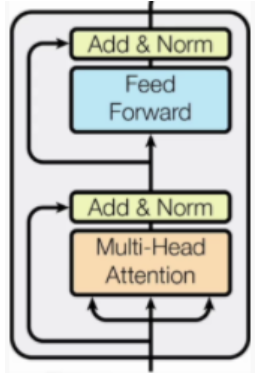
模塊組成部分:
-
Multi-Head Attention:多頭注意力機制
-
Feed Forward:前饋神經網絡,就是一個線性層
-
Add&Norm:殘差連接和歸一化(經過注意力機制和歸一化后的輸出和最初輸入進行逐元素相加,輸入→處理→輸出 + 輸入)
四、掩蔽多頭自注意力Masked Multi-Head
4.1、掩碼Mask
在文本生成任務中,由于模型需按順序生成內容且遵循“僅基于歷史內容預測下一個詞”的自回歸邏輯,即生成第n個詞時只能受前n-1個詞影響,因此需引入掩碼來限制模型對后續未生成內容的關注。
掩碼操作是加在Q與K轉置相乘后的原始注意力得分矩陣(每個元素表示 “查詢向量 Q 對鍵向量 K 的關聯強度”),從而限制模型關注范圍,下圖所示的掩碼矩陣中綠色部分值為0,按位相加后原得分矩陣值不變,表示模型需要關注的范圍,黃色部分為-∞,按位相加后仍為-∞,模型不關注這部分
-
第一步

最終得到的掩碼得分矩陣再與V進行加權求和,得到最后Z矩陣,他 “融合了上下文的語義向量”(比如第 0 行 Z 融合了第 0 個位置能關注到的信息)
-
第二步
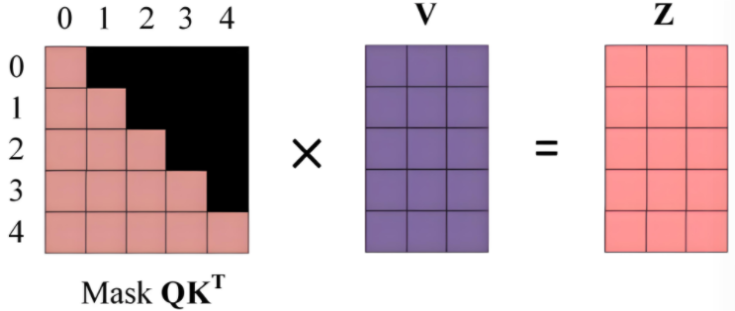
以第0行為例,掩碼得分舉證只顯現了第一個詞的語義信息,那么當Z處理第 0 個位置的詞時,模型只能看到自己的語義,然后把‘自己的語義’作為輸出
而對比第1行,Z處理第 1 個詞時,模型可以參考‘第 0 個詞(歷史)’和‘自己(第 1 個詞)’的語義,融合后輸出
五、解碼器Decoder
Transformer 通過編碼器輸出的全局語義信息結合自回歸機制(通過掩碼限制僅關注歷史生成內容),逐詞生成目標序列
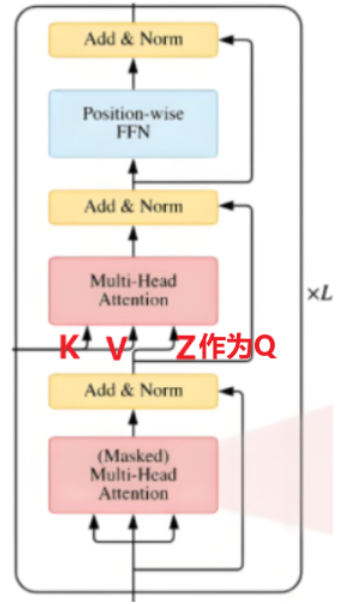
注意在解碼器的第二個多頭注意力機制上融合了編碼器的信息,依據 Encoder 輸出 ( C ) 得到 ( K )、( V ),并以上一個 Decoder block 輸出 ( Z ),構建注意力交互基礎 。
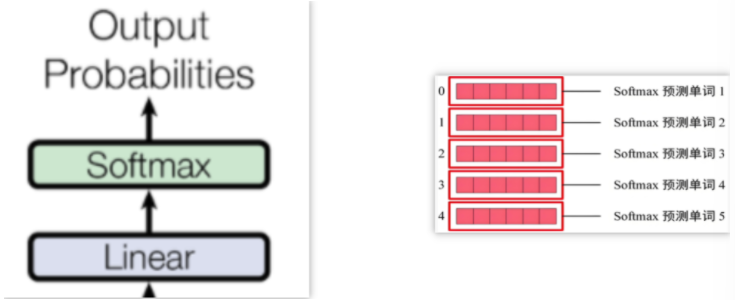
六、預測輸出
始終通過前一個詞來預測后一個詞,保持模型的自回歸屬性

)




、增加/修改其中的網絡層(修改為10分類))






和數據降維)
單源賦權最短路徑算法實現(BFS實現))


)
)
