主成分分析(PCA)和數據降維是機器學習和統計學中處理高維數據的核心工具。下面用清晰的結構解釋其概念、原理和應用:
一、數據降維(Dimensionality Reduction)
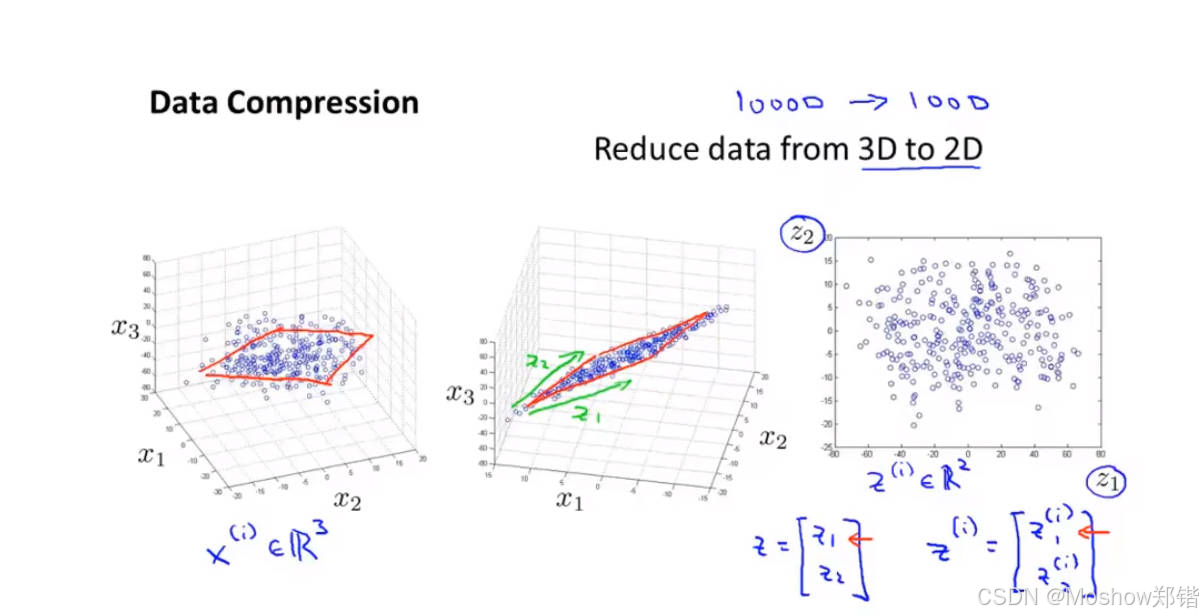
1. 是什么?
-
目標:將高維數據(特征多)轉換為低維表示(特征少),同時保留關鍵信息。
-
為什么需要?
-
維度災難(Curse of Dimensionality):特征過多導致計算效率低、模型過擬合、噪聲放大。
-
可視化需求:人類只能理解 ≤3 維空間,降維后可直觀展示數據。
-
去除冗余:許多特征可能高度相關(如“身高(cm)”和“身高(inch)”)。
-
2. 兩類常用方法
| 類型 | 代表方法 | 核心思想 |
|---|---|---|
| 特征選擇 | 過濾法、嵌入法 | 直接篩選原始特征(保留部分列) |
| 特征提取 | PCA、t-SNE | 創建新特征組合(生成新特征列) |
二、主成分分析(PCA)
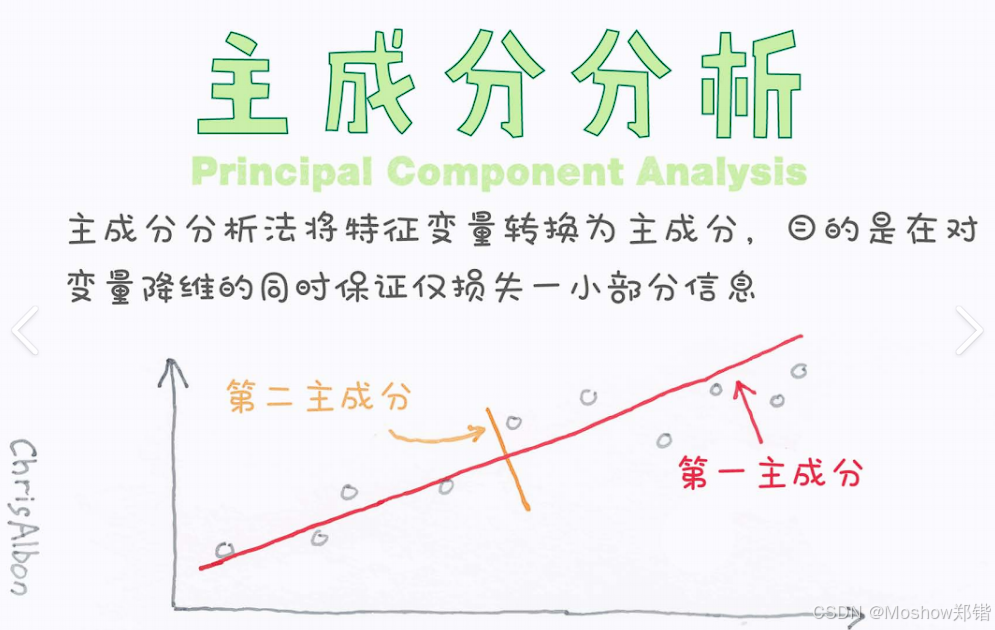
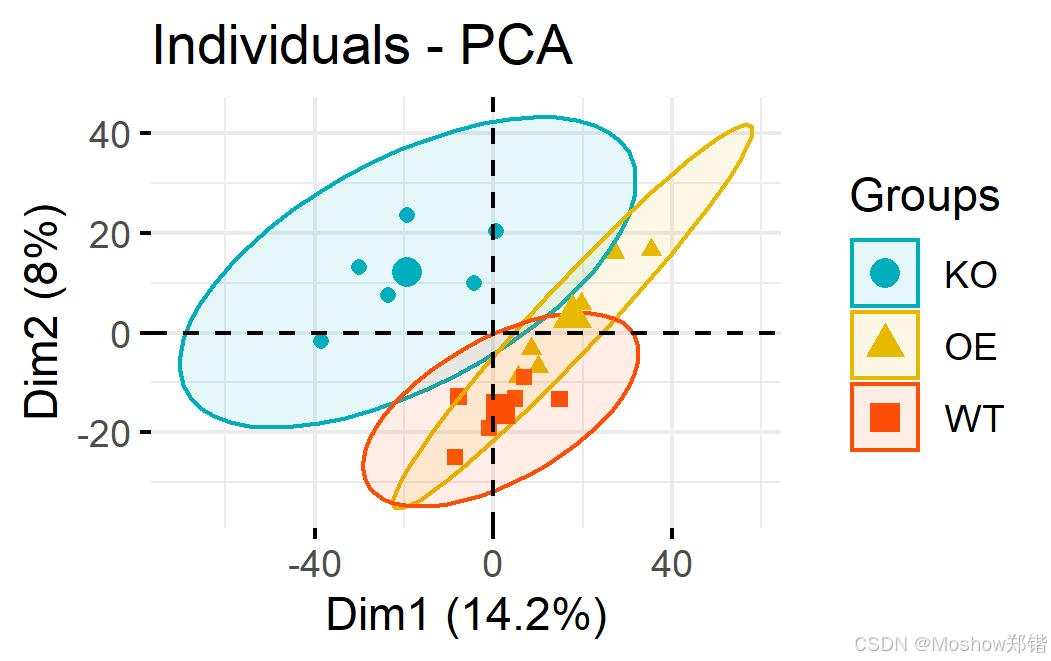
1. 是什么?
-
本質:一種線性特征提取方法,通過正交變換將原始特征重組為互不相關的“主成分”。
-
目標:找到數據方差最大的方向(即信息最集中的方向),作為新坐標軸。
2. 核心思想
-
最大化方差:新坐標軸(主成分)的方向是數據投影后方差最大的方向。
-
正交性:每個主成分與前一主成分正交(無相關性)。
-
重要性排序:第一主成分(PC1)保留最多信息,后續依次遞減。
3. 數學原理(關鍵步驟)
-
中心化數據:將每個特征減去其均值(使數據均值為0)。
-
計算協方差矩陣:反映特征間的線性相關性。
-
特征值分解:
-
協方差矩陣的特征向量 →?主成分方向
-
特征值 →?主成分的方差大小(特征值越大,保留信息越多)
-
-
選擇主成分:
-
按特征值從大到小排序,選擇前?kk?個主成分(k<k<?原始維度)。
-
-
投影數據:將原始數據投影到選定的?kk?個主成分上,得到降維后的數據。
4. 可視化理解
-
原始數據:分布在傾斜的橢圓中(特征相關)。
-
PC1:沿橢圓長軸方向(方差最大)。
-
PC2:沿短軸方向(與PC1正交,方差次大)。
→ 若只保留PC1,數據從2維降至1維,但保留了主要結構。
https://miro.medium.com/v2/resize:fit:1400/1*Upj7eTtSLsK0yFjDwYfGJA.gif
三、PCA的實際應用
1. 典型場景
-
圖像處理:將像素壓縮(如人臉識別中的特征提取)。
-
基因數據分析:處理數萬個基因表達維度。
-
金融風控:降低股票收益率相關性維度。
-
數據預處理:為SVM、回歸等模型減少噪聲和過擬合。
2. 輸出結果解讀
-
主成分(PC):新特征,是原始特征的線性組合(如?PC1=0.7×身高+0.3×體重PC1=0.7×身高+0.3×體重)。
-
解釋方差比:每個主成分保留原始信息的百分比(累計達80%~95%即足夠)。
四、PCA的優缺點
| 優點 | 缺點 |
|---|---|
| 減少過擬合,提升模型泛化能力 | 僅捕獲線性關系(非線性需用核PCA) |
| 去除特征間的相關性 | 降維后特征失去物理意義(難解釋) |
| 計算高效(基于線性代數) | 對異常值敏感(需提前標準化數據) |
| 無需標簽(無監督方法) | 方差小但重要的特征可能被丟棄 |
五、關鍵注意事項
-
標準化先行:若特征量綱不同(如身高 vs 收入),必須先標準化(均值為0,標準差為1),否則高方差特征會主導結果。
-
選擇?kk?的方法:
-
肘部法則:繪制累計解釋方差比曲線,選擇拐點。
-
保留閾值:通常保留累計方差 ≥85% 的主成分。
-
-
PCA ≠ 特征選擇:
PCA生成的是新特征(原始特征的線性組合),而非篩選原始特征。
六、代碼示例(Python)
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler# 1. 標準化數據
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)# 2. 執行PCA(保留95%方差)
pca = PCA(n_components=0.95)
X_pca = pca.fit_transform(X_scaled)# 輸出結果
print("保留主成分數量:", pca.n_components_)
print("各主成分解釋方差比:", pca.explained_variance_ratio_)七、題目解析
主成分分析(PCA)的主要用途在于()
A數據清洗
B數據降維
C數據預測
D數據分類
正確答案:B
解析:
A. 數據清洗:錯誤。雖然主成分分析可以幫助識別異常值或噪聲,但它不是專門用于數據清洗的工具。數據清洗通常涉及處理缺失值、糾正錯誤等操作。C. 數據預測:錯誤。主成分分析本身不直接進行數據預測。它是一種探索性數據分析方法,主要目的是減少數據的維度,而不是預測未來的趨勢或結果。D. 數據分類:錯誤。主成分分析也不是一種分類算法。盡管它可以作為預處理步驟在機器學習分類任務中使用,以降低特征空間的維度,但它的主要目的并不是進行分類。綜上所述,主成分分析的主要用途是數據降維,因此正確答案是B。
總結
-
數據降維:高維數據 → 低維表示,提升效率并保留信息。
-
PCA:通過線性變換找到方差最大的正交方向(主成分),按重要性保留前?kk?個。
-
核心價值:用少量不相關的新特征替代大量原始特征,解決維度災難問題。
- 主成分分析(PCA)在特征構造中的主要目的是什么(減少特征的數量以降低模型的復雜度 - 這是主成分分析的主要目的之一。通過降維,PCA可以去除冗余信息,從而簡化模型,使其更易于解釋和理解,同時可能提高計算效率。)。
單源賦權最短路徑算法實現(BFS實現))


)
)

)


到Word2Vec:自然語言處理中的詞向量學習)





——pandas庫)
![第十六屆藍橋杯青少組C++省賽[2025.8.9]第二部分編程題(1 、慶典隊列)](http://pic.xiahunao.cn/第十六屆藍橋杯青少組C++省賽[2025.8.9]第二部分編程題(1 、慶典隊列))

)
